5自建AI模型
目录
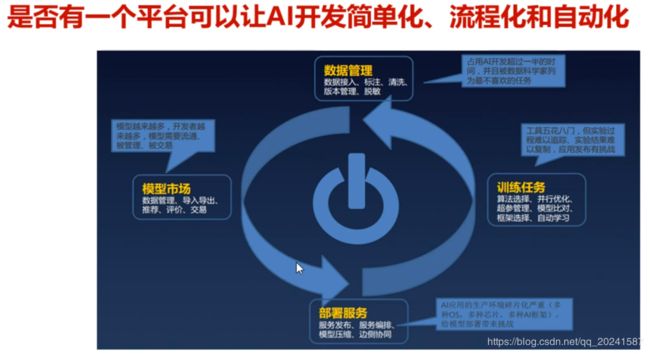
痛点分析
ModelArts介绍
基于ModelArts的一个图像分类Demo
数据集选择
配置选择
数据预处理
准备训练模型的代码文件
基于ModelArts构建训练作业
查看训练结果
导入训练完成的模型
创建模型
模型在线部署和使用
优点总结
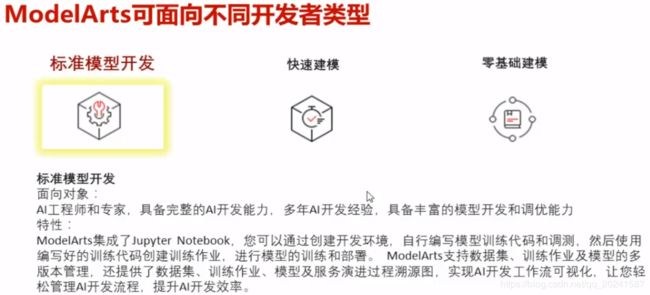
非AI工程师角色使用框架构建模型的例子
非AI工程师非编码人员使用框架的例子
物体分类实例
1 图片有可视化界面提供上传功能
2可视化界面给上传的图片打标签
3 提交任务
4一键部署
5 上传测试集并测试
物体检测实例
3 提交任务
4一键部署
5 上传测试集并测试
自动学习Demo
总结
ModelArts亮点
ModelArts应用场景
一些牛拍的点
痛点分析

数据标注,分析和提取是非常繁琐和耗时耗力的
机器要求很高,GPU很贵,云资源一定程度上可以解决
学习成本高,框架,算法,语言都很难学
多层的模型构建困难很慢,优化也很非常困难的。
训练也是非常耗时慢和困难的。
训练好的模型的部署也是很慢很困难的。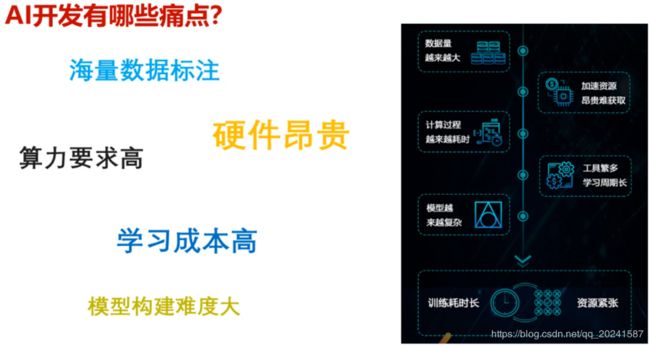
ModelArts介绍
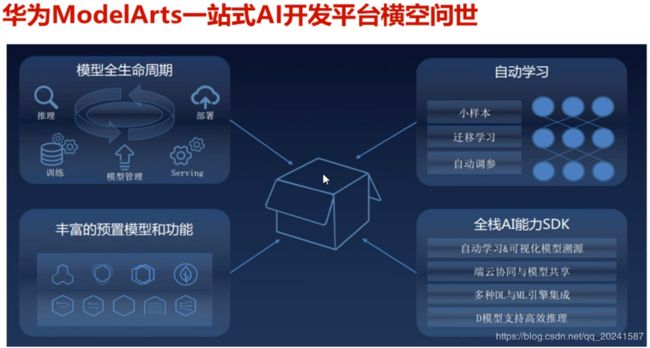

基于ModelArts的一个图像分类Demo
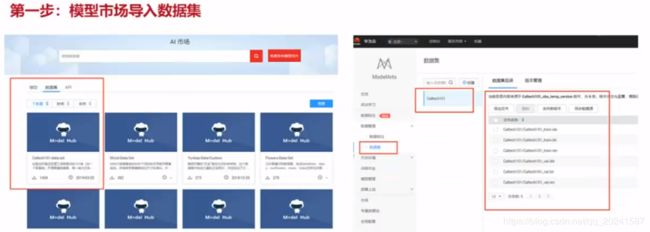
数据集选择
华为官方已经收集,我们可以直接导入到我们的工程中

配置选择
选的框架是MXNet ,之前手写数字识别用的是TensorFlow
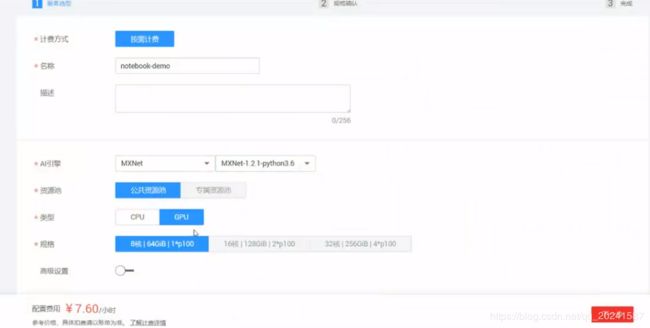
使用的仍然是jupyter这个交互式的记事本编辑工具:
数据预处理
Caltech官网提供的原始数据是一个压缩包,解压开来是:
根据不同类别分类(比如面包,蝴蝶,人,狗等)的多个文件夹,每个文件夹内有若干对应类型的 .jpg 的图片
把Caltech官网提供的原始数据包下下来;
利用im2rec.py这个脚本,对原始文件进行处理。会生成一个带有索引的list 文件。list 文件包含了图片的标签及其对应的文件路径,
然后使用这个list 文件去创建一个叫做 record io的文件,它就是一个压缩好的图像数据包,里面是数组类型表示的图片数据方便机器做学习的输入。

这个生成的文件会保存在某某位置,构建模型训练的时候可以使用 Io.ImageRecordIter 把压缩好的图片加载到训练平台上。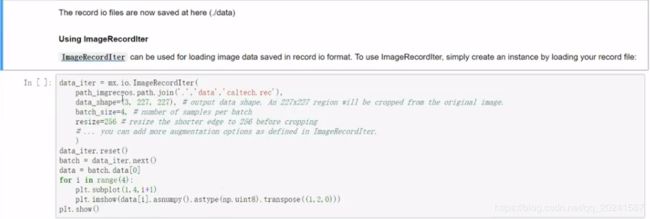
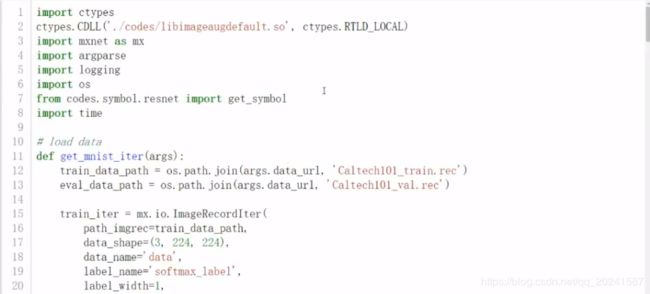
准备训练模型的代码文件
下图中OBS是一个云存储资源服务

resnet是一个中等量级的常用分类模型
训练代码如下:

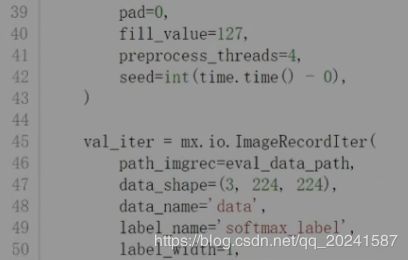
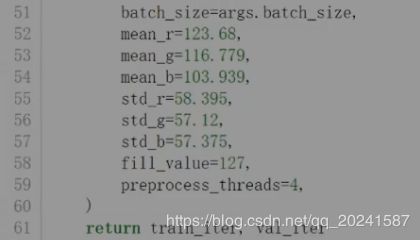
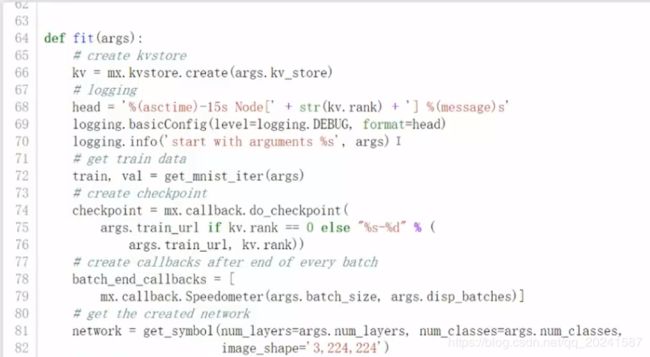
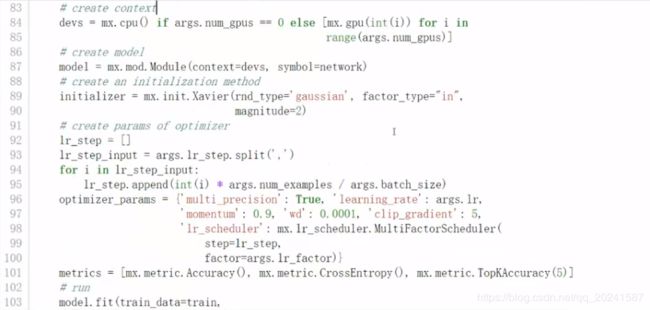

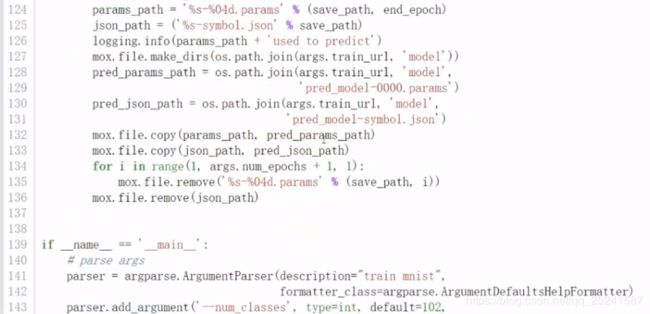
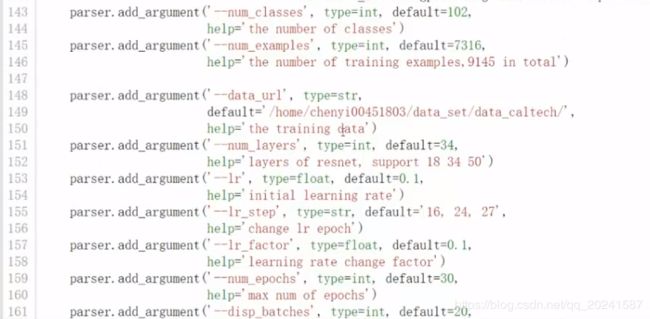
resnet网络结构,这里用的是一个18层的,自行百度。
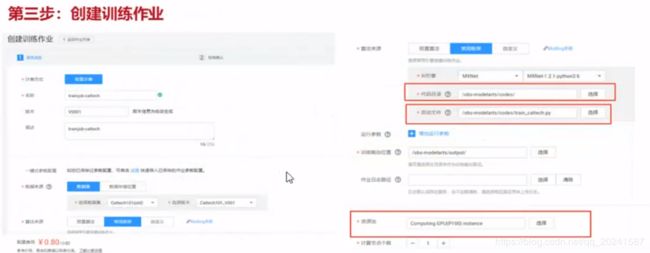
基于ModelArts构建训练作业
注意选择
数据集来源,选之前的分类图片位置
开发框架,MXNet
代码目录,
启动文件,上文那个160+行的.py
训练输出位置也放在OBS桶中,这个输出模型是一个(或一堆)文件,也就是最后的成果

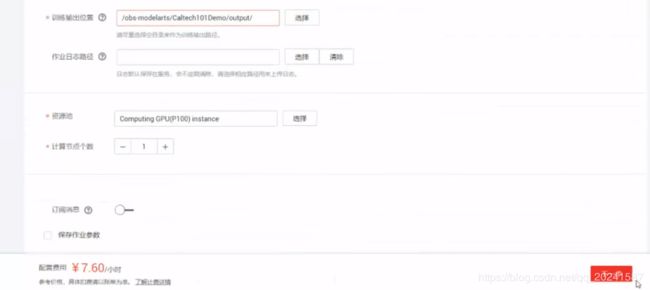
查看训练结果
可看到运行时间,AI引擎等等信息,几万张图片的分类训练,这个21分钟算是超级快的……
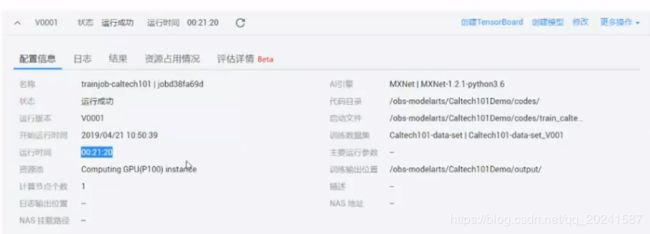
看到日志文件,每次迭代的准确率等信息(看到这个日志文件,真是痛苦的回忆涌上心头):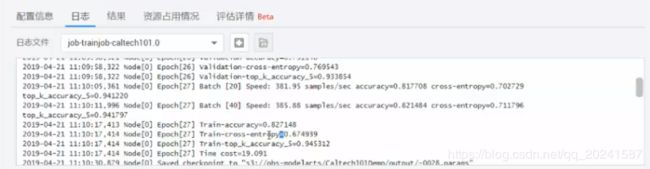
资源占用情况
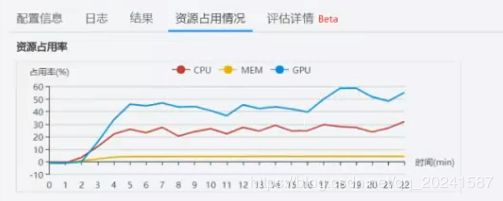
想更加直观的看到训练结果,可以创建一个TensorBoard
由于这个模型有点复杂,这个tensor Board不支持查看……
我们可以回看之前讲的手写数字识别的例子,
那个例子的模型优化之后得到的模型也还比较简单的,在modelArts上也可以OK的进行训练。下面基于这个例子介绍一下华为的一个自研框架,通过这个介绍我们可以对比主流框架,更清晰的弄清楚深度学习常见整个流程,直观的看到工程的目录结构。
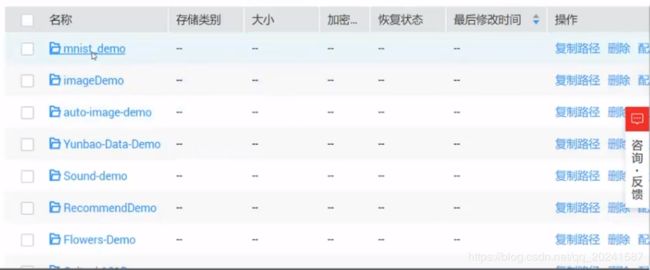
mnist_demo进入,包含三种框架(TensorFlow,MXNet,MoXing)的输出文件夹,Code文件夹等
Code文件夹里长这样,包含三种框架对应的模型结构的代码文件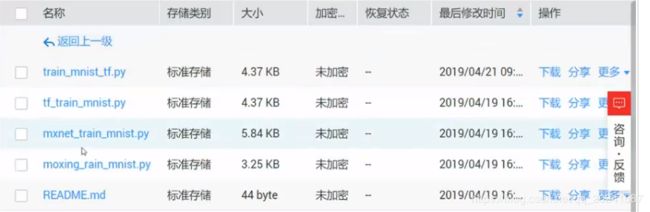
下面介绍一哈MoXing这个框架 (可以去官网看)

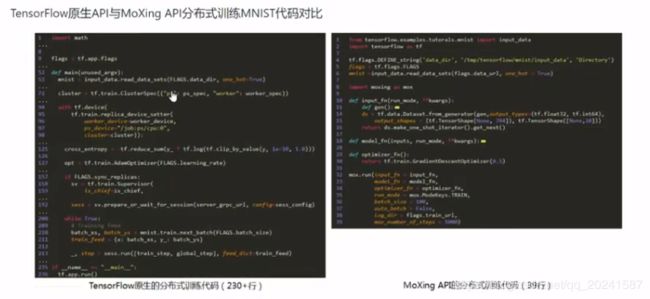
tensor Board可视化这个训练过程

导入训练完成的模型
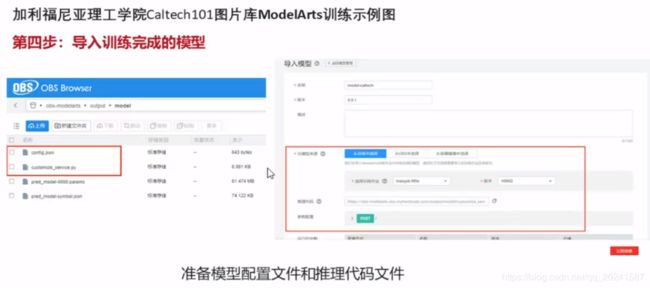
回到加利福尼亚大学图片分类这个实验,看一下训练后得到的output内容:
81M的那个(第四个文件)就是训练的得到的模型;
第二个文件是要基于该模型开发所需要用到的配置文件;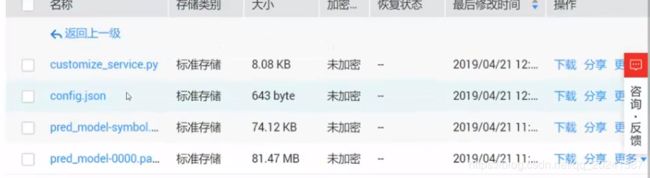
用记事本打开config.jason如下:
模型类型(NXNet),准确率等
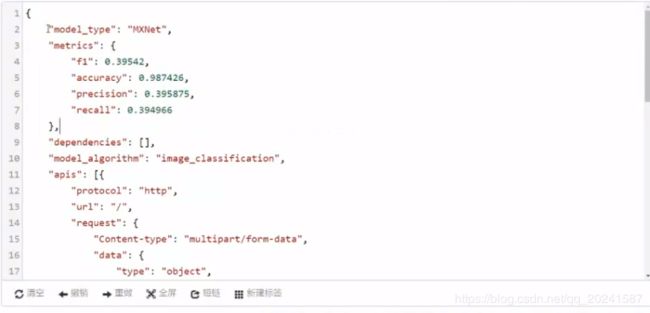
模型算法是 image_classification
要通过API使用模型,协议是Htttp,输入参数是一个file类型的image
请求类型是post,出参返回的是一个scores类型

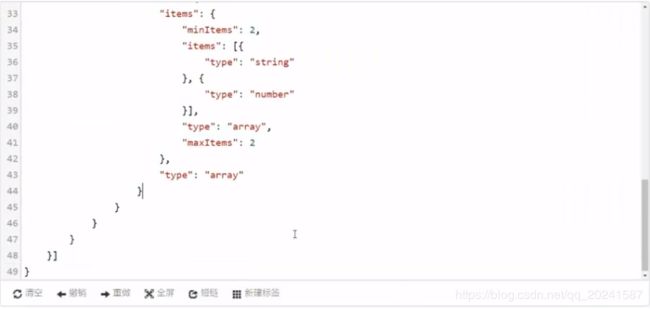
第一个生成那个.py文件(这个文件应该是要工程师自己写的),要基于该模型开发使用,所需要用到的推理代码;
模型要被我们部署到终端上,通过配置文件我们已经发现模型试用的方式是上传图片,这份推理代码会对上传的图片进行处理。比如对输入图片的校验,对模型的初始化,加载待检测图片到模型中,然后通过模型输出的结果,告诉使用者预测出来的标签和对应的预测准确率。这个也是有AI工程师所编写的py脚本文件。
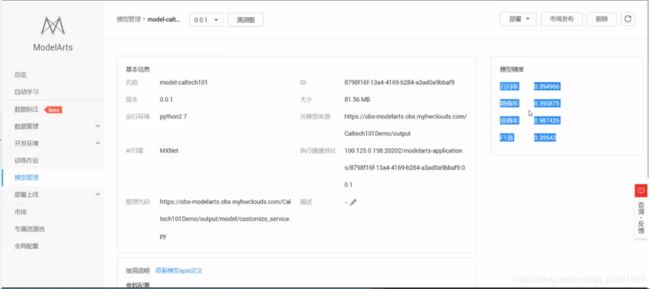
创建模型
上面介绍了训练作业得到的训练模型,配置文件和推理代码。现在基于这些创建模型: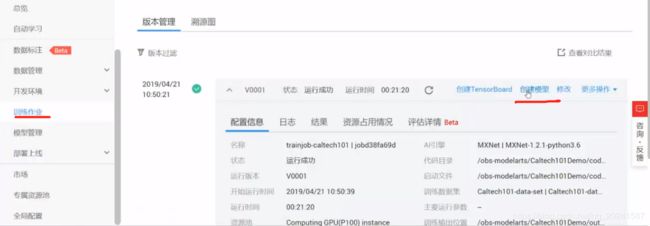


模型在线部署和使用
配置名称和计算节点性能参数即可
部署完之后,我们就可直接使用我们部署得到的API接口,然后将这个接口集成到我们的业务系统
华为这个ModelArts提供了一些较为方便的操作,比如说:
将这个http请求绑定域名;
直接在这个管理界面进行文件上传进行预测测试;
测试过程中的各类监控等……所以说这个平台是对开发者友好的平台,作为AI服务集成者我们可以方便的使用它选择数据集,选择模型,训练模型,创建部署训练好的模型,作为AI工程师我们也可以在上面进行输出预处理,模型设计和优化调整测试,很多常见功能步骤都被平台集成起来,算是比较好用的。
相比之前的经验,此平台提供了较为方便的部署流程,也就是集成部署使用训练得到的模型,这是我以前所缺少的东西,诚然,这些工作我们也可以自己去写代码搭环境实现,但是平台集成一定程度上让我们的操作变得更加简单。
优点总结
总结一下这个 Moxing 平台的优点:
第一是提供了一个AI开发的自动化,流程化平台;
第二是训练速度显著提升,提现在如下三点:
OK上面的例子介绍了一个AI开发工程师角色是如何使用MoXing框架的,下面介绍一个非AI开发工程师是如何使用MoXing框架的。
非AI工程师角色使用框架构建模型的例子
首先,两个角色的区别,前者熟悉AI的常见框架和算法,具备框架使用和模型调优能力,后者可能仅仅明白概念,但不具备上述能力或者能力不足。MoXing框架也可以让后者有较为OK的使用体验。
下面是非AI角色使用不同的地方:
1 使用预置算法而不是常用框架。
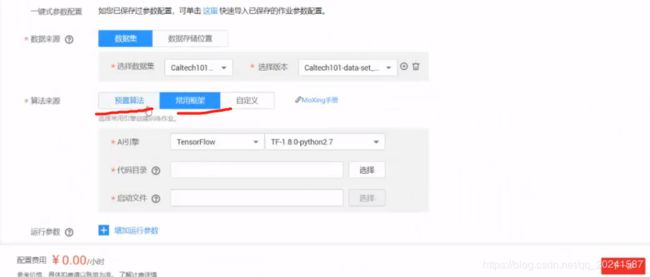
预置算法,别说,还真有几个我听过的,比如 yolo darknet 和 faster_RCNN,这些算法基本上是个大研究院或者学校研究出来的,作为框架我们对它进行了集成。
但是在这里我们不需要关心算法细节和实现,这是需要不浅的基础的,我们使用即可,如果要看算法细节也可以去官网上看。
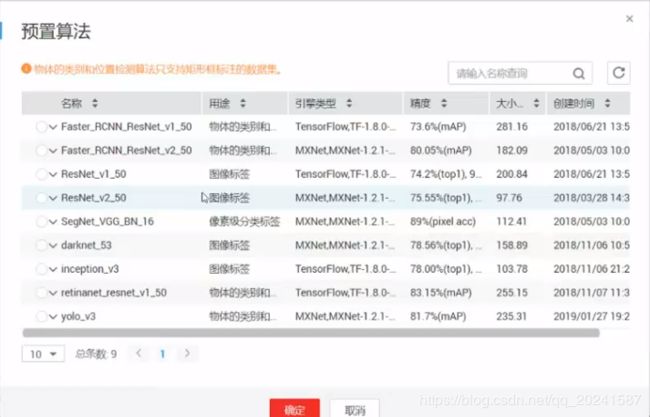
输出位置,资源,创建训练,训练结果查看,模型创建和部署(推理代码是自动生成的)等都差不多……
OK上面的例子介绍了非AI开发工程师是如何使用MoXing框架的。现在介绍一个零基础的建模例子,其实我觉得这个教程是不是该反着写……
非AI工程师非编码人员使用框架的例子
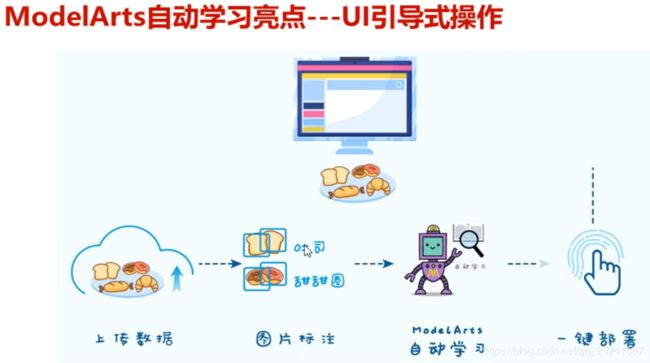
其实可以脑补出来,下面将介绍的这个使用过程肯定是一堆UI界面引导,算法框架隐式自动选择,到处点点就OK了的那种。
物体分类实例
搞一个物体分类的例子(分别一张图是给定的几个标签中的哪一个):
1 图片有可视化界面提供上传功能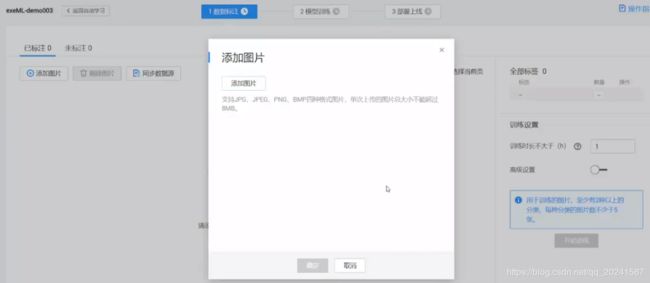
2可视化界面给上传的图片打标签
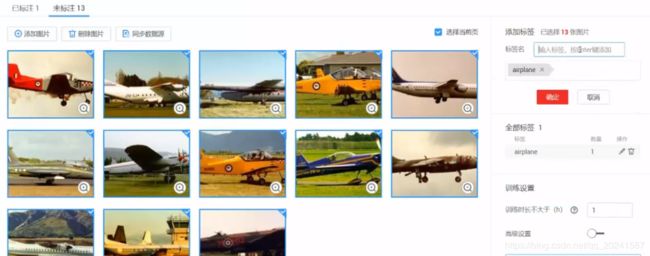
3 提交任务
提交任务,平台会自动选择算法,分类模型,参数调优等。并进行训练。
4一键部署
训练好的模型一件部署,有个按钮点一下就行了,自动把训练好的模型部署起来。
5 上传测试集并测试
可视化界面提供上传图片并给出分类结果
物体检测实例
搞一个物体检测的例子:
1 图片有可视化界面提供上传功能
2 图片标签
可视化界面给上传的图片打标签,和上一个例子不同的是,用户要在图片中把需要检测出来的东西所在的位置框起来,然后给这个物体一个标签
3 提交任务
平台会自动选择算法,分类模型,参数调优等
4一键部署
训练好的模型一件部署,有个按钮点一下就行了,自动把训练好的模型部署起来。
5 上传测试集并测试
可视化界面提供上传图片并给出检测结果,下面是一个检测测试的例子:一张图有好几个待检测物体也是可以检测出来的。

自动学习Demo
声音也可以做分类训练吗? 答案是肯定的。
使用手机或者其他类型的声音收集工具,固定在森林各处收集声音,声音传到云端计算服务器上,服务器使用AI技术识别这些声音,监控人为破坏或其他危害环境情况的发生。=============
总结
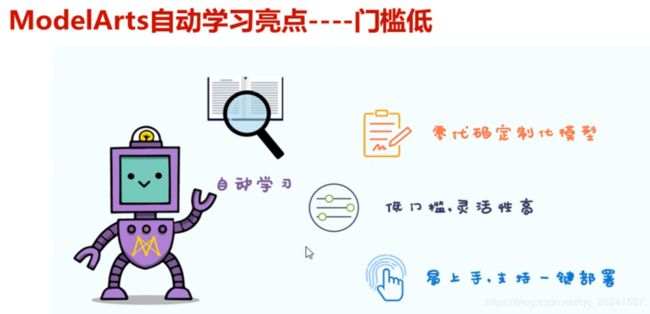
ModelArts亮点

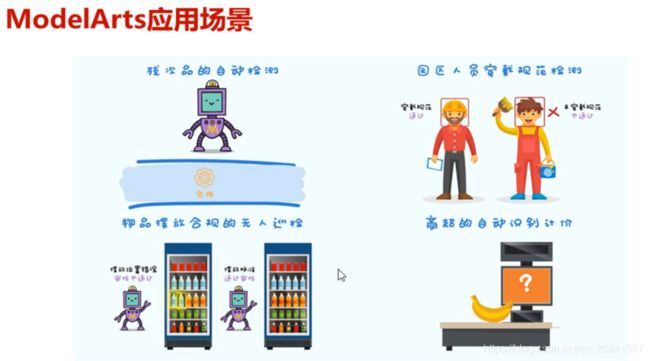
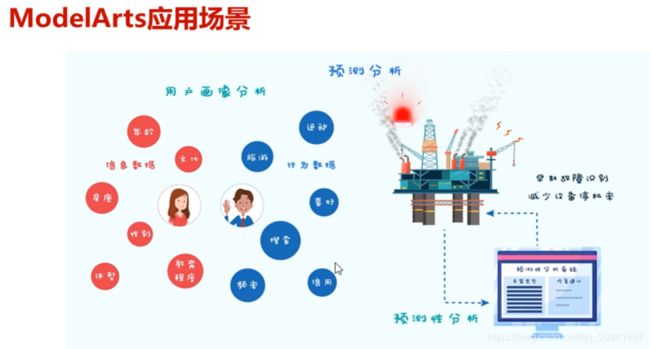
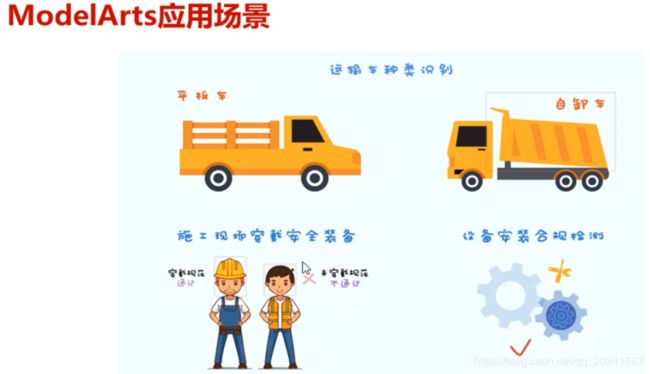
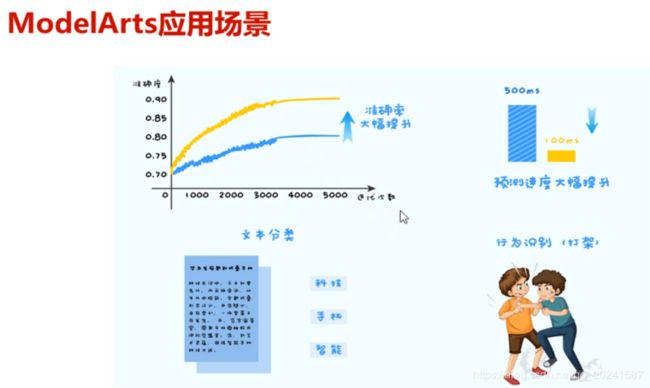
ModelArts应用场景


一些牛拍的点



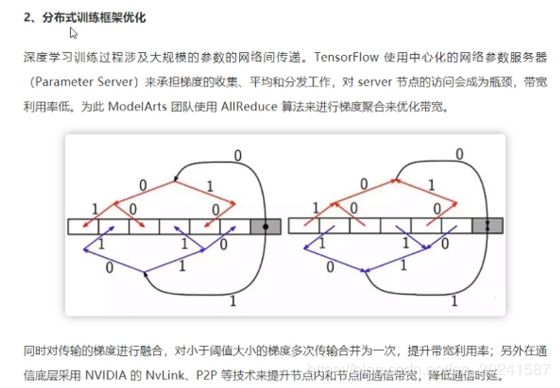
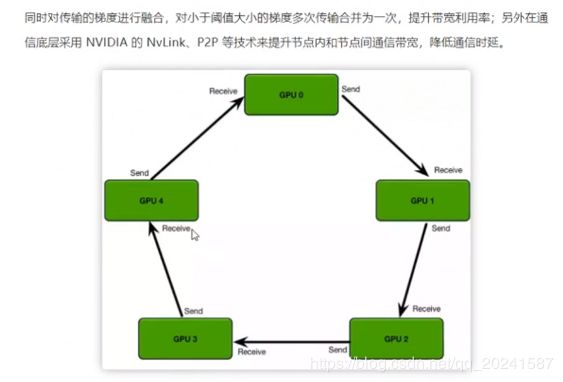


GPU芯片是自研的……