代码笔记--朴素贝叶斯
1.贝叶斯决策理论的核心思想:选择具有最高概率的决策。
2.贝叶斯公式
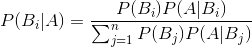
3.朴素贝叶斯的两个假设:
第一,特征之间相互独立;第二,每个特征同等重要。
4.使用python进行文本分类
4.1准备数据:从文本中构建词向量
#词表到向量的转换函数
def loadDataSet():
positingList=[['my','dog','has,''flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']]
classVec=[0,1,0,1,0,1] #1 代表侮辱性文字,0代表正常言论
return positingList,classVec
def createVocabList(dataSet):
vocabSet=set([]) #创建一个空集
for document in dataSet:
vocabSet=vocabSet|set(document) #创建两个集合的并集
return list(vocabSet)
def setofWords2Vec(vocabList,inputSet):
returnVec=[0]*len(vocabList) #创建一个其中所含元素都为0的向量
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]=1
else:print "the word: %s is not in my Vocabulary!" %word
return returnVec4.2训练算法:从词向量计算概率
伪代码:
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中->增加该词条的计数值
增加所有词条的计数值
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到条件概率
返回每个类别的条件概率#朴素贝叶斯分类器训练函数
def trainNBO(trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix)
numWords=len(trainMatrix[0])
pAbusive=sum(trainCategory)/float(numTrainDocs) #初始化概率
# p0Num=zeros(numWords);p1Num=zeros(numWords)
p0Num=ones(numWords);p1Num=ones(numWords)
# p0Denom=0.0;p1Denom=0.0
p0Denom = 2.0;p1Denom = 2.0
for i in range(numTrainDocs): #向量相加
if trainCategory[i]==1:
p1Num+=trainMatrix[i]
p1Denom+=sum(trainMatrix[i])
else:
p0Num+=trainMatrix[i]
p0Denom+=sum(trainMatrix[i])
# p1Vect=p1Num/p1Denom #change to log()
# p0Vect=p0Num/p0Denom #change to log()
p1Vect=log(p1Num/p1Denom) #change to log() #对每个元素做除法
p0Vect=log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive4.3测试算法:根据显示情况修改分类器
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1=sum(vec2Classify*p1Vec)+log(pClass1) #元素相乘
p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1)
if p1>p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses=loadDataSet()
myVocabList=createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
trainMat.append(setofWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNBO(trainMat, listClasses)
testEntry=['love','my','dalmation']
thisDoc=array(setofWords2Vec(myVocabList,testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry=['stupid','garbage']
thisDoc=array(setofWords2Vec(myVocabList,testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)