从kernel层面分析synchronized、volatile,进大厂必备硬核小伎俩(上)
synchronized、volatile对于java程序员来说再熟悉不过了,但
是你知道这两个关键字底层是如何实现的吗(甚至在操作系层面是
通过什么指令来实现的)?以及与其相关的术语:诸如用户态与内核
态、cas、锁升级、内存一致性协议、内存屏障都是什么,下面我来一
一揭秘。本专题将分为两篇文章进行讲解,此篇主要介绍关于
synchronized和volatile在kernel层面涉及的一些核心概念,下一篇
会详细说明synchronized和volatile实现原理,包括内存屏障、
锁升级过程(偏向、轻量、重量)、重入锁、线程可见性、指令重排等
核心原理,其中也不乏DCL单例是否需要volatile修饰等有趣问题。
用户态和内核态
一般的操作系统对操作指令进行了权限控制,在intel x86 cpu中将级别分为0-3,0为最高执行权限,3为最低执行权限,0和3分别代表内核态和用户态,简单来说就是需要与操作系统,比如操作系统硬件打交道时,就需要调用内核态来完成,而jvm是运行在用户态的,或者说运行在用户空间的。
运行在用户空间的是干活的,权利小,内核空间才是操作系统老大,做
大事需要向内核空间申请权限。
CAS
compare and swap(比较并交换),即有2个线程A和B,同时对int i = N进行加1操作,当线程A将i+1后的结果写入主内存赋值给i前,首先会比较当前主内存中i的值是否为N,如果为N就执行赋值操作,否则有可能是B线程执行了对i的修改操作(如目前i=N+1),A线程就不执行赋值操作,A线程再次从主内存中读取最新的i的值,然后再执行i+1操作,然后再次将结果赋值给i,在赋值之前同样比较当前主内存中的i的值是否为N+1,如果为N+1,就将线程A修改的i的值赋值给i,否则再次执行上述操作,直至修改成功为止。我们可以把这个操作成为自旋操作。
AtomicInteger就是cas的实现:
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
也就是最后会调用一个native方法compareAndSwapInt函数。这个方法依次会调用操作系统代码unsafe.cpp,atomic.cpp和atomic_windows_x86.inline.hpp/atomic_linux_x86.inline.hpp:
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
上面的代码就是操作系统级别执行cas操作执行的指令代码,简单来说就是会执行lock_if_mp cmpxchg来完成cas操作的。其中cmpxchg就是执行cas操作的,lock_if_mp是指如果是多核cpu,就将cmpxchg指令进行加锁执行,否则就不加锁。从而可以看出cmpxchg并不是原子操作,需要加lock后才是原子操作,其实锁住的是北桥信号。上面就是cas在操作系统层面的执行原理。
缓存行
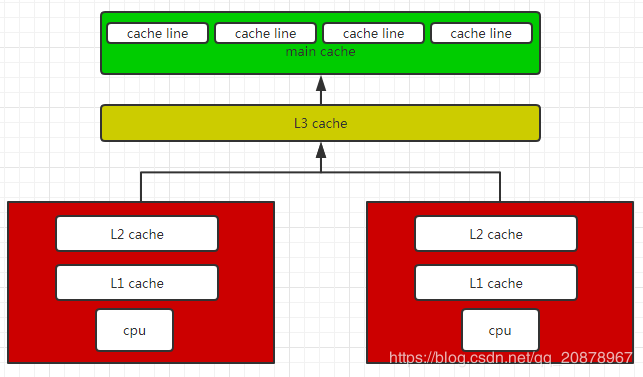
上面是最常见的缓存简图。main cache为主内存,L1 cache、L2 cache、L3 cache分别为1级缓存、2级缓存、3级缓存。cahe line为缓存行。那么缓存行是什么?缓存行就是保存了我们需要执行的指令代码,大多数一个缓存行为64个字节,cpu一次也会读取64个字节指令到cpu中进行使用。
下面我们来看一个比较有意思的两段代码片段:
代码片段1:
public class TestCacheLingOne {
static volatile Long[] l = new Long[2];
public static void main(String[] args) throws InterruptedException {
Thread threadOne = new Thread(){
@Override
public void run() {
for (long i=0;i<1000_000_000L;i++) {
l[0] = 1L;
}
}
};
Thread threadTwo = new Thread(){
@Override
public void run() {
for (long i=0;i<1000_000_000L;i++) {
l[1] = 2L;
}
}
};
long time = System.currentTimeMillis();
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
System.out.println((System.currentTimeMillis() - time) /1000d);
}
}
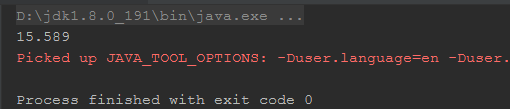
代码片段2:
public class TestCacheLineTwo {
static volatile Long[] l = new Long[9];
public static void main(String[] args) throws InterruptedException {
Thread threadOne = new Thread(){
@Override
public void run() {
for (long i=0;i<1000_000_000L;i++) {
l[0] = 1L;
}
}
};
Thread threadTwo = new Thread(){
@Override
public void run() {
for (long i=0;i<1000_000_000L;i++) {
l[8] = 2L;
}
}
};
long time = System.currentTimeMillis();
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
System.out.println((System.currentTimeMillis() - time) /1000d);
}
}
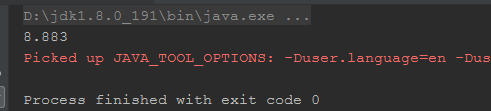
上面的两段程序都是2个线程对同一个volatile修饰的Long类型数组进行10亿次值修改操作,那么执行用时差别还是很明显的,这是为什么呢?这是由于cpu读取缓存行字节数和下面我要说的缓存一致性有关,在下一篇内容中会进行具体说明。
缓存一致性协议
其实缓存一致性协议和synchronized、volatile本身没有关系,缓存一致性是操作系统层面的概念。目前一致性协议有MESI、MSI、Dragon等等,我们常说的MESI其实是intnel x86的缓存一致性协议,MESI即:Modified(修改)、Exclusive(独享)、Shared(共享)、Invalid(失效),指的就是缓存行的4种状态。
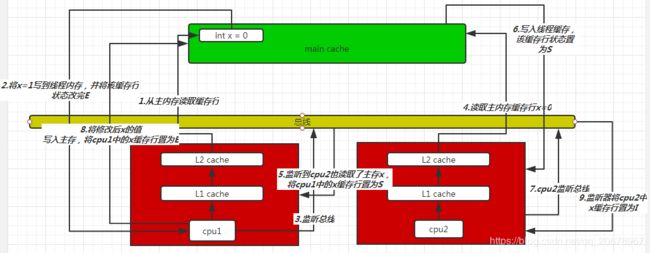
上图说明了2个线程对主内存中同一个缓存行的操作过程。
- cpu1即线程1,读取主内存中的数据x,将x写入当前线程缓存,缓存行状态为E(共享),同时cpu1监听总线(嗅探)。
- 此时cpu2即线程2读取主内存中的数据x,此时cpu1监听器发现线程2读取了主内存中的x缓存行,则将cpu1中的x缓存行置为S(共享)
- 线程2将x缓存行从主内存读取到线程2缓存中,将x缓存行状态置为S(共享),并监听总线。
- 此时线程1修改了x值,通知总线,此时将线程2中的x缓存行置为I(无效),将线程1中的x缓存行置为E(独享)。
- 此时线程2如果想操作x,那么需要再次从主内存中读取x缓存行。
CPU指令乱序
cpu指令乱序是指cpu为了提高其执行效率,在操作系统层面会将指令乱序执行(不是按照程序编写顺序执行)。但是这种cpu指令乱序会导致在多线程情况下,产生问题。看如下代码,证明cpu存在乱序执行:
public class Test {
static int a,b,c,d;
public static void main(String[] args) throws InterruptedException {
int x = 0;
for(;;) {
x++;
a = 0;
b = 0;
c = 0;
d = 0;
Thread threadOne = new Thread(new Runnable() {
@Override
public void run() {
a = 1;
c = b;
}
});
Thread threadTwo = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
d = a;
}
});
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
if (c == 0 && d == 0) {
System.out.println("执行第" + x + "次,证明cpu是可以乱序执行的");
break;
}
}
}
}

如果cpu没有指令乱序执行存在,那么不可能打印出同时满足c=0,d=0,所以说cpu存在乱序问题。
最后
下一篇将接着本篇讲解,会介绍内存屏障问题,及锁升级过程、线程可见性、指令重排等相关技术。如果本篇对你有用,欢迎点赞、关注、转载,由于水平有限,如有问题请留言。