大型系统分布式日志采集系统ELK+Kafka 2020版
大型系统分布日志采集系统ELK+Kafka
- 概述
- 传统系统日志收集问题
- 分布式日志收集ELK原理
- ELK+Kafka整体架构
- 准备环境
- ES集群安装配置
- ES安装
- 配置参数
- 启动
- ES集群
- ES-head插件安装
- Logstach工作原理
- Logstach介绍
- Logstash环境安装
- 安装并测试连接ES集群
- 日志文件通过Logstash向Es集群写数据
- Kafka集群安装配置
- 下载
- 配置Zookeeper集群
- Kafka配置
- 启动Kafka服务
- Kafka集群安装配置-kafka to ES
- Kibana安装
- 安装好的虚拟机服务器重启一遍的步骤
本博客参考了以下博客:
- https://cloud.tencent.com/developer/article/1376678
- https://www.cnblogs.com/JetpropelledSnake/p/9893566.html
- https://www.cnblogs.com/JetpropelledSnake/p/9893550.html
- https://segmentfault.com/a/1190000020134018
概述
传统系统日志收集问题
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下。
通常,日志被分散储存在不同的设备上。如果你管理数十台上百台服务器,你还在使用以此登录每台机器的传统方法查阅日志。这样不仅繁琐而且效率低下。当务之急是我们如果集中化的管理日志,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更好的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
命令方式
tail -n 300 myes.log | grep 'node-1'
tail -100f myes.log
分布式日志收集ELK原理
- 每台服务器集群节点安装Logstash日志收集系统插件
- 每台服务器节点将日志输入到Logstash中
- Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
- 浏览器使用Kibana查询日志信息
ELK工作原理介绍图:
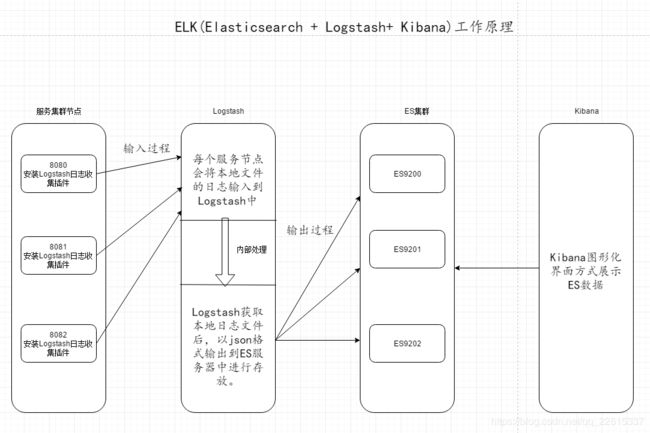
ELK+Kafka整体架构
基于以上ELK架构的基础,结合Kafka队列,实现了ELK+Kafka集群,整体架构如下:

# 1. 两台es组成es集群;( 以下对elasticsearch简称es )
# 2. 中间三台服务器就是我的kafka(zookeeper)集群啦; 上面写的 消费者/生产者 这是kafka(zookeeper)中的概念;
# 3. 最后面的就是一大堆的生产服务器啦,上面使用的是logstash,当然除了logstash也可以使用其他的工具来收集你的应用程序的日志,例如:Flume,Scribe,Rsyslog,Scripts……
# 双ES备份集群: CentOS1+CentOS2
# Kafka+LogStash集群:CentOS3+CentOS4+CentOS5
# ES-Header+Kibina+LogStash/Beats采集:CentOS6+CentOS7
服务器列表
| 主机名 | IP地址 | 系统信息 | 角色 | 安装的软件 |
|---|---|---|---|---|
| CentOS7-S-EN1 | 192.168.20.161 | CentOS Linux release 7.4.1708 (Core) | ES集群 | jdk1.8、elasticsearch7.6.2 |
| CentOS7-S-EN2 | 192.168.20.162 | CentOS Linux release 7.4.1708 (Core) | ES集群 | jdk1.8、elasticsearch7.6.2、elasticsearch-head、logstash7.6.2、kibana7.6.2 |
| CentOS7-S-EN3 | 192.168.20.163 | CentOS Linux release 7.4.1708 (Core) | Kafka+Zookeeper集群 | jdk1.8、kafka2.13、logstash7.6.2 |
| CentOS7-S-EN4 | 192.168.20.164 | CentOS Linux release 7.4.1708 (Core) | Kafka+Zookeeper集群 | jdk1.8、kafka2.13、logstash7.6.2 |
| CentOS7-S-EN5 | 192.168.20.165 | CentOS Linux release 7.4.1708 (Core) | Kafka+Zookeeper集群 | jdk1.8、kafka2.13、logstash7.6.2 |
| CentOS7-S-EN6 | 192.168.20.166 | CentOS Linux release 7.4.1708 (Core) | 日志采集 | jdk1.8、logstash7.6.2 、tomcat8.5 |
| CentOS7-S-EN7 | 192.168.20.167 | CentOS Linux release 7.4.1708 (Core) | 日志采集 | jdk1.8、 logstash7.6.2 、tomcat8.5 |
使用软件:
# Elasticsearch 7.6.2
# Kibana 7.6.2
# Logstash 7.6.2
# elasticsearch-head(从github直接clone)
# node-v6.0.0-linux-x64.tar.gz (记住文件夹路径,需要增加到bash_profile中)
# kafka_2.13-2.4.1.tgz(该版本已经包含ZooKeeper服务)
部署步骤:
# 准备环境
# ES集群安装配置;
# Logstash客户端配置(直接写入数据到ES集群,写入系统messages日志);
# Kafka(zookeeper)集群配置;(Logstash写入数据到Kafka消息系统);
准备环境
- 七台centos7服务器(最少三台)
- java环境
- Selinux关闭
- 本次环境搭建用到的JDK & ELK+Kafka安装文件下载地址:
链接:https://pan.baidu.com/s/15RQpJmCKROVRxM5X00Q5kw
提取码:vmfo
ES集群安装配置
elasticsearch的系统和jvm要求参考:https://www.elastic.co/cn/support/matrix
Elasticsearch默认使用自带的jvm,但是如果本地安装配置了jvm,则会自动使用本地的jvm,本地的jvm版本不能太低,可以向下兼容1.8
安装参考博客:https://segmentfault.com/a/1190000020134018
https://www.elastic.co/guide/cn/elasticsearch/guide/current/running-elasticsearch.html
ES安装
下载ES
- 可在服务器上通过wget直接下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz - 可以通过浏览器下载后传到服务器上,下载地址:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz
安装
服务器需要2G的内存,其中1G内存会被elasticsearch锁定,1G用来运行系统,内存过小的时候会导致虚拟机内存溢出elasticsearch起不起来- elasticsearch-head安装
因为ES主要通过restful api对外提供服务,所以一般安装ES时顺带安装elasticsearch-head,它提供了web控制台。
elasticsearch-head通过源码的方式托管在git上,所以需要安装下git,直接yum安装即可 yum install git
同时elasticsearch-head是一个nodejs应用,所以还需要具有node, 需要安装phantomjs。(安装教程可以参考这篇博客)
- 上传到服务器后解压,如下图:

- Elasticsearch 7.6.1 目录结构如下:
bin :脚本文件,包括 ES 启动 & 安装插件等等
config : elasticsearch.yml(ES 配置文件)、jvm.options(JVM 配置文件)、日志配置文件等等
JDK : 内置的 JDK,JAVA_VERSION="12.0.1"
lib : 类库
logs : 日志文件
modules : ES 所有模块,包括 X-pack 等
plugins : ES 已经安装的插件。默认没有插件
data : ES 启动的时候,会有该目录,用来存储文档数据。该目录可以设置
配置参数
- elasticsearch配置
- 主节点配置
vim config/elasticsearch.yml
# 集群名称,可修改
cluster.name: ES-cluster
# 本机的主机名
node.name: es-node-1
#
# 如果目录不存在,需要先创建
# 数据目录路径
path.data: /usr/local/software/elasticsearch/elasticsearch-7.6.2/es/data
# 日志文件路径
path.logs: /usr/local/software/elasticsearch/elasticsearch-7.6.2/es/logs/elasticsearch/logs/
# 支持远程访问
network.host: 0.0.0.0
# 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.publish_host: 192.168.20.161
# 集群主机列表
discovery.seed_hosts: ["192.168.20.161", "192.168.20.162"]
# restful api访问接口,可更改
http.port: 9200
# 集群内的主机(主机名,不一定全部都要写)
cluster.initial_master_nodes: ["es-node-1", "es-node-2"]
# 节点是否被选举为 master
node.master: true
# 内存不向 swap 交互
bootstrap.memory_lock: true
# 是否开启跨域访问
http.cors.enabled: true
#开启跨域访问后的地址限制,*表示无限制
http.cors.allow-origin: "*"
- 设置elasticsearch内存
调整config下的jvm.options文件vim config/jvm.options
#最小占用内存,默认为1g,这里我采用默认配置,可自行根据需要修改
-Xms1g
#最大占用内存,默认为1g,这里我采用默认配置,可自行根据需要修改
-Xmx1g
- 从节点配置
vim config/elasticsearch.yml
# 集群名称,可修改
cluster.name: ES-cluster
# 本机的主机名
node.name: es-node-2
#
# 如果目录不存在,需要先创建
# 数据目录路径
path.data: /usr/local/software/elasticsearch/elasticsearch-7.6.2/es/data
# 日志文件路径
path.logs: /usr/local/software/elasticsearch/elasticsearch-7.6.2/es/logs/elasticsearch/logs/
# 支持远程访问
network.host: 0.0.0.0
# 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.publish_host: 192.168.20.162
# 集群主机列表
discovery.seed_hosts: ["192.168.20.161", "192.168.20.162"]
# restful api访问接口,可更改
http.port: 9200
# 集群内的主机(主机名,不一定全部都要写)
cluster.initial_master_nodes: ["es-node-1", "es-node-2"]
# 节点是否被选举为 master
node.master: false
# 内存不向 swap 交互
bootstrap.memory_lock: true
# 是否开启跨域访问
http.cors.enabled: true
#开启跨域访问后的地址限制,*表示无限制
http.cors.allow-origin: "*"
- 设置elasticsearch内存
调整config下的jvm.options文件vim config/jvm.options
#最小占用内存,默认为1g,这里我采用默认配置,可自行根据需要修改
-Xms1g
#最大占用内存,默认为1g,这里我采用默认配置,可自行根据需要修改
-Xmx1g
elasticsearch用户拥有的内存权限太小,至少需要262144错误
参考博客:https://www.cnblogs.com/yidiandhappy/p/7714489.html
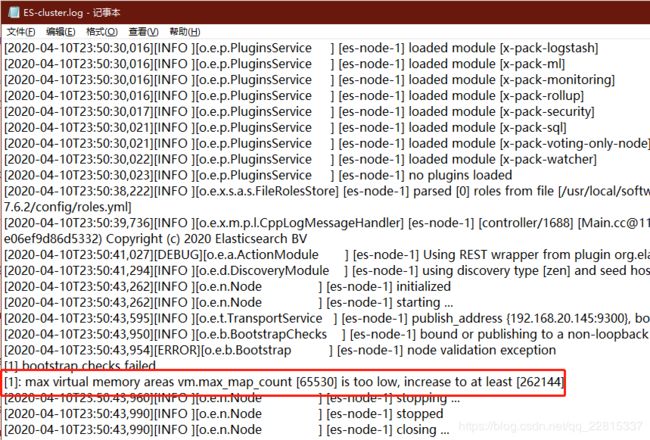
解决:
切换到root用户
su root
执行命令:
sysctl -w vm.max_map_count=262144
查看结果:
sysctl -a|grep vm.max_map_count
显示:
vm.max_map_count = 262144
启动
elasticsearch不允许root用户直接去启动,否则会报以下错误
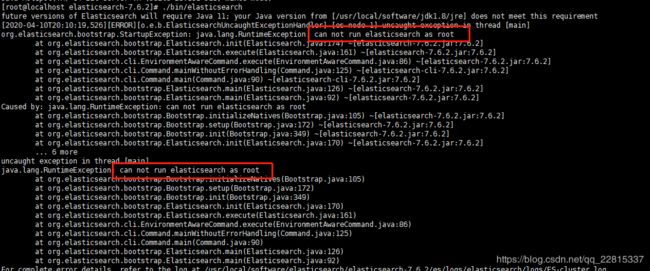
- 设置es用户
新增es用户
groupadd es
useradd es -g es
我这里的es可以改成自己创建的用户。
设置用户密码
passwd es
切换用户
su es
-
root用户下给新建的用户elasticsearch目录赋权
chown -R es:es /usr/local/software/elasticsearch/elasticsearch-7.6.2 -
内存交互错误解决方案:https://blog.csdn.net/zhanyu1/article/details/88927194
记得重启系统 -
启动Elasticsearch
执行命令:./bin/elasticsearch
启动成功:

-
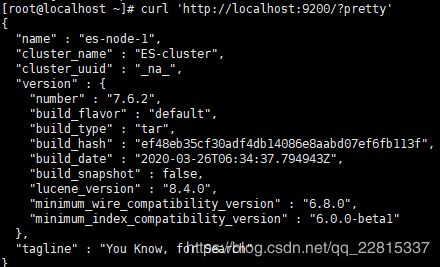
测试是否启动成功
执行命令:curl 'http://localhost:9200/?pretty'
测试结果:
ES集群
参考博客:https://www.jianshu.com/p/b9613b5dc26f
- 一个简单的 ElasticSearch 就搭建好了,如果要部署一个ES集群,那么只需要在所有主机上部署好 Java 环境,以及在所有主机上的 /etc/hosts 解析主机,如下:
[root@seichung ] vim /etc/hosts
192.168.20.161 es-node-1
192.168.20.162 es-node-2
- es-node-2安装
- 创建安装目录
mkdir elasticsearch - 进入创建的目录
cd elasticsearch, 完整的目录地址:/usr/local/software/elasticsearch - 执行scp命令将161服务器上的elasticsearch解压文件传输到162上:
scp -r [email protected]:/usr/local/software/elasticsearch/elasticsearch-7.6.2 ./
把192.168.20.161上的/usr/local/software/elasticsearch/elasticsearch-7.6.2文件copy到当前目录中,具体修改点击跳转 - 更改用户名,
vim config/elasticsearch.yml,如下图:

- 新增es用户并赋权,点击跳转
- 分配用户内存大小权限,点击跳转
- 启动
- 如果没有关闭防火墙,需要开放9200端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent开放9200端口
firewall-cmd --zone=public --remove-port=9200/tcp --permanent关闭9200端口
firewall-cmd --reload配置立即生效
firewall-cmd --zone=public --list-ports查看防火墙所有开放的端口
防火墙常用命令:
启动: systemctl start firewalld
查看状态: systemctl status firewalld
停止: systemctl disable firewalld
禁用: systemctl stop firewalld
执行开机禁用防火墙自启命令 : systemctl disable firewalld.service
防火墙随系统开启启动 : systemctl enable firewalld.service
-
从节点启动的时候如果报错:java.lang.IllegalStateException: failure when sending a validation request to node
解决方案:
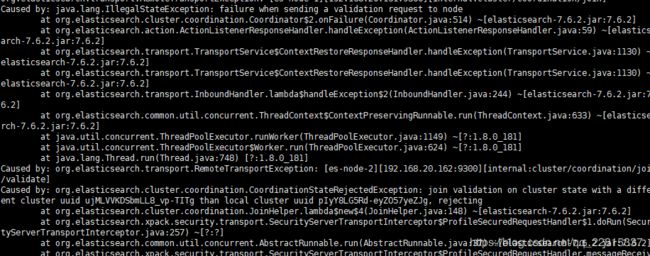
原因:从节点无法加入主节点
解决办法:删除data文件夹
rm -rf es/data -
查看集群是否搭建成功:
-
浏览器通过地址查看集群节点信息:
http://192.168.20.161:9200/_cat/nodes?v

可以看到主节点是es-node-1 -
通过浏览器查看集群健康:
http://192.168.20.161:9200/_cluster/health?pretty
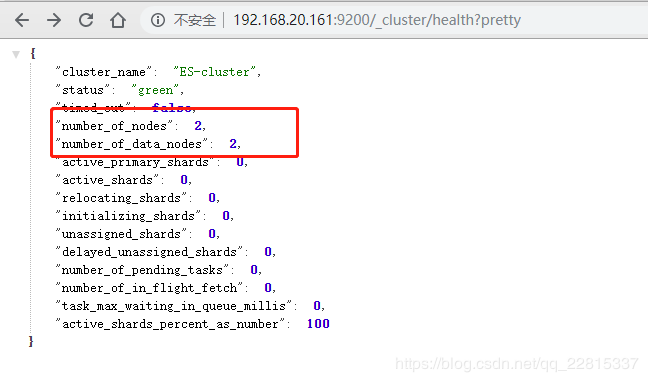
-
通过命令直接查看:
curl -X GET "localhost:9200/_cat/health?v"

- window环境下集群搭建参考博客:
https://blog.csdn.net/csdn565973850/article/details/104772551?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4
ES-head插件安装
具体步骤参考博客:https://blog.csdn.net/Mr_Mocha/article/details/89175469
注意:
- nodejs版本是v6.0.0
- 安装的时候如果速度比较慢,可以换成淘宝镜像,具体步骤参考:https://blog.csdn.net/xuesheng1610748/article/details/98182768
- 启动命令 :
nohup grunt server & - 搭建完成后,我的head插件装在162上,效果如下:
http://192.168.20.162:9100/

Logstach工作原理
Logstach介绍
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取防范,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作再一并发往elasticsearch上去。
核心流程:Logstash事件处理有三个阶段:inputs --> filters --> outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Logstash环境安装
安装并测试连接ES集群
- 上传logstash安装包
- 解压
tar -zxvf logstash-7.6.2.tar.gz - 在config目录下logstash-sample.conf 文件 copy 一份,重命名为 logstash-testEs.conf,命令如下:
copy config/logstash-sample.conf logstash-testEs.conf
用vi编辑配置elasticsearch地址:vi config/logstash-testEs.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
stdin {}
}
output {
elasticsearch {
hosts => ["http://192.168.20.161:9200", "http://192.168.20.162"]
index => "%{+YYYY.MM.dd}"
user => "es"
password => "123456"
}
}
- 配置jvm
vi config/jvm.options
-Xms256m
-Xmx256m
- 测试配置文件是否有语法问题:
/usr/local/software/logstash-7.6.2/bin/logstash -f /usr/local/software/logstash-7.6.2/config/logstash-testEs.conf -t --verbose

- 启动并测试logstash
./bin/logstash -f ./config/logstash-testEs.conf

测试结果已经写入集群
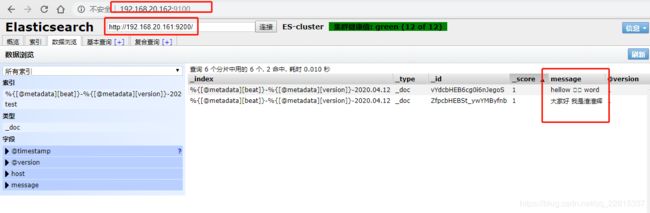
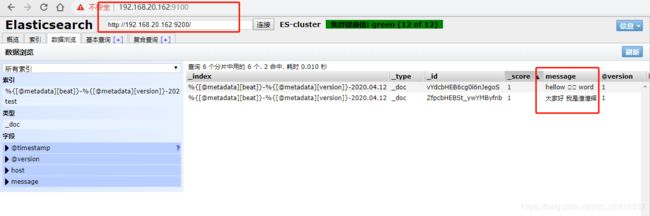
日志文件通过Logstash向Es集群写数据
测试,暂未通过Kafka队列传递
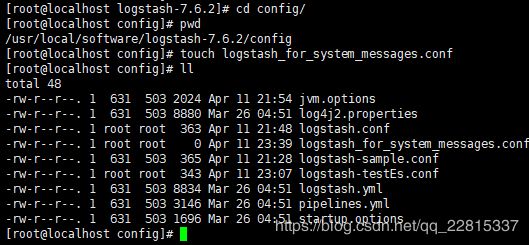
- 新建
logstash_for_system_messages.conf文件
touch logstash_for_system_messages.conf
- 编辑logstash_for_system_messages.conf文件:
vi logstash_for_system_messages.conf
input {
file{
path => "/var/log/messages" #这是日志文件的绝对路径
start_position=>"beginning" #这个表示从 messages 的第一行读取,即文件开始处
}
}
output { #输出到 es
elasticsearch { #这里将按照这个索引格式来创建索引
hosts=>["192.168.20.161:9200","192.168.20.162:9200"]
index=>"system-messages-%{+YYYY-MM}"
}
}
记得把后面的注释删掉

-
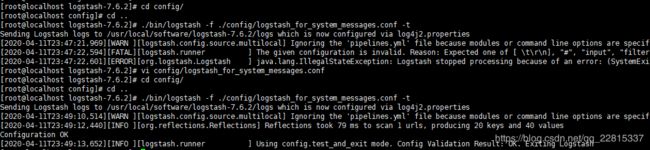
测试ogstash_for_system_messages.conf文件
./bin/logstash -f ./config/logstash_for_system_messages.conf -t
-
启动测试
# 注意,系统日志需要权限,命令行前面使用 sudo
#[root@localhost logstash-7.6.2]$ sudo ./bin/logstash -f ./config/logstash_for_system_messages.conf
- 启动成功后编辑目标日志文件测试

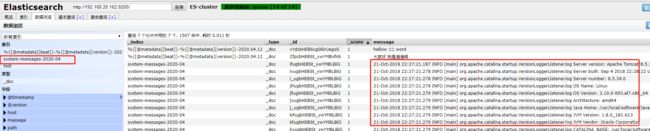
常见问题参考:https://blog.csdn.net/sqandczm/article/details/89420108
系统日志我们已经成功的收集,并且已经写入到es集群中.
上面的演示是logstash直接将日志写入到es集群中的,这种场合我觉得如果量不是很大的话直接像上面已将将输出output定义到es集群即可.
如果量大的话需要加上消息队列Kafka来缓解es集群的压力,下面就在三台server上面安装kafka集群。
Kafka集群安装配置
下载
kafka_2.13-2.4.1 (该版本已经包含ZooKeeper服务)
从官网获取装包,https://kafka.apache.org/downloads
配置Zookeeper集群
配置Zookeeper集群,修改配置文件
在config目录执行命令: vim zookeeper.properties
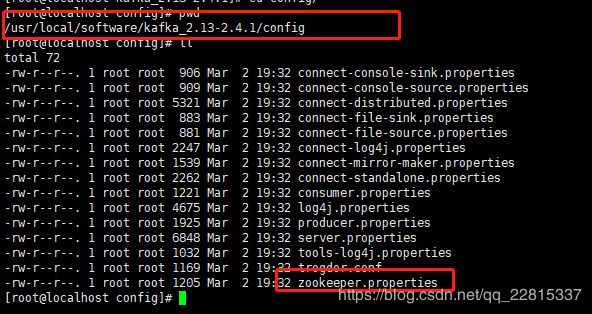
具体配置如下:
dataDir=/usr/local/software/kafka_2.13-2.4.1/zookeeperDir
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=1024
# 作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.20.163:2888:3888
server.2=192.168.20.164:2888:3888
server.3=192.168.20.165:2888:3888
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
# 说明:
tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。
创建Zookeeper所需的目录
进入Kafka目录内
![]()
创建目录zookeeperDir mkdir zookeeperDir
进入zookeeperDir目录 cd zookeeperDir
在zookeeperDir目录下创建myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper是没法启动的
在zookeeperDir目录下创建myid文件 touch myid
写入zookeeper的唯一序号 echo 1 > myid
需要与配置文件汇总中的序号一致

以上就是zookeeper集群的配置,下面等我配置好kafka之后直接复制到其他两个节点即可
Kafka配置
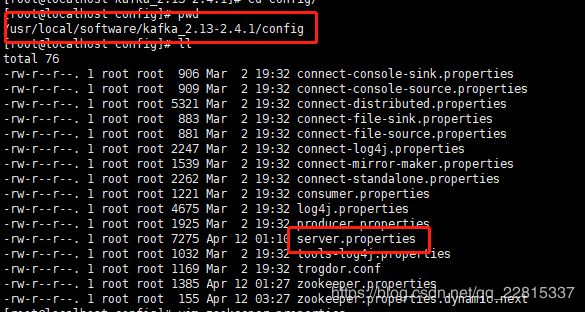
修改内容如下:
# 唯一,填数字,本文中分别为 1 / 2 / 3
broker.id = 1
# 这个 broker 监听的端口
prot = 9092
# 唯一,填本机服务器 IP
host.name = 192.168.20.163
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
/socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
# 该目录可以不用提前创建,在启动时自己会创建
log.dirs = /usr/local/software/kafka_2.13-2.4.1/logs
# 这个就是 zookeeper 集群的 ip 及端口
zookeeper.connect = 192.168.2.22 : 2181 , 192.168.2.23 : 2181 , 192.168.2.24 :2181
# 需要配置较大 分片影响读写速度
num.partitions = 16
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 时间按需求保留过期时间 避免磁盘满
log.retention.hours = 168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
没有注释的都是默认配置
将kafka(zookeeper)的程序目录全部拷贝至其他两个节点
scp -r kafka_2.13-2.4.1 [email protected]:/usr/local/software
scp -r kafka_2.13-2.4.1 [email protected]:/usr/local/software
修改两个节点的配置,注意这里除了以下两点不同外,都是相同的配置
# zookeeper 的配置
mkdir zookeeperDir
echo "x" > zookeeperDir/myid # “x”这里是2或者3,前面已经使用过1了
# kafka 的配置
broker.id = x # “x”这里是2或者3,前面已经使用过1了
host.name = 192.168.20.163 # ip改为20.164或者20.165
修改完毕配置之后我们就可以启动了,这里先要启动zookeeper集群,才能启动kafka
我们按照顺序来,kafka1 –> kafka2 –>kafka3
#zookeeper启动命令
./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
#zookeeper停止命令
./bin/zookeeper-server-stop.sh
注意,如果zookeeper有问题 nohup的日志文件会非常大,把磁盘占满,这个zookeeper服务可以通过自己些服务脚本来管理服务的启动与关闭。
后面两台执行相同操作,在启动过程当中会出现以下报错信息
[2020-04-12 08:36:05,540] WARN Unexpected exception, tries=0, remaining init limit=39997, connecting to /192.168.20.164:2888 (org.apache.zookeeper.server.quorum.Learner)
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at org.apache.zookeeper.server.quorum.Learner.sockConnect(Learner.java:233)
at org.apache.zookeeper.server.quorum.Learner.connectToLeader(Learner.java:262)
at org.apache.zookeeper.server.quorum.Follower.followLeader(Follower.java:77)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:1253)
由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
其他节点也可能会出现类似的情况,属于正常。
Zookeeper服务检查
在Kafka三台Server上执行如下命令netstat -nlpt | grep -E "2181|2888|3888"
显示如下端口和信息,说明Zookeeper运行正常

可以看出,如果哪台是Leader,那么它就拥有2888这个端口

启动Kafka服务
这时候zookeeper集群已经启动起来了,下面启动kafka,也是依次按照顺序启动,kafka1 –> kafka2 –>kafka3
# 进入kafka目录
cd /usr/local/software/kafka_2.13-2.4.1
# 启动kafka服务:
./bin/kafka-server-start.sh ./config/server.properties &
# 停止kafka服务:
./bin/kafka-server-stop.sh
此时三台上面的zookeeper及kafka都已经启动完毕,下面来测试一下
建立一个主题(在Kafka Server 192.168.20.163)
# 注意:factor大小不能超过broker的个数
./bin/kafka-topics.sh --create --zookeeper 192.168.20.163:2181 --replication-factor 3 --partitions 1 --topic test1test2test
![]()
查看已经创建的topics(Kafka Server :192.168.20.163)
./bin/kafka-topics.sh --list --zookeeper 192.168.20.163:2181
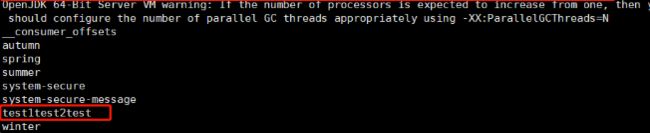
查看test1test2test这个主题的详情(Kafka Server :192.168.20.163)
./bin/kafka-console-producer.sh --broker-list 192.168.20.136:9092 --topic test1test2test

#主题名称:test1test2test
#Partition:只有一个,从0开始
#leader :id为4的broker
#Replicas 副本存在于broker id为2,3,4的上面
#Isr:活跃状态的broker
以上是Kafka生产者和消费者的测试,基于Kafka的Zookeeper集群就成功了。
下面我们将ES Server:192.168.20.137上面的logstash的输出改到kafka上面,将数据写入到kafka中
137服务器上创建LogStash结合Kafka使用的.conf文件,注意文件目录
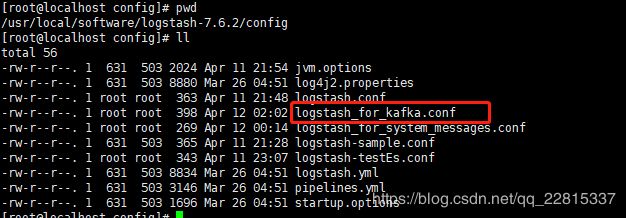
编辑输入到Kafka的.conf文件 vim logstash_for_kafka.conf
#这里的输入还是定义的是从日志文件输入
input {
file {
type => "system-message"
path => "/usr/local/software/tomcat8.5/logs/catalina.out"
start_position => "beginning"
}
}
output {
#这是标准输出到终端,可以用于调试看有没有输出,注意输出的方向可以有多个
stdout { codec => rubydebug }
#输出到kafka
kafka {
#他们就是生产者
bootstrap_servers => "192.168.20.163:9092, 192.168.20.164:9092, 192.168.20.165:9092"
#这个将作为主题的名称,将会自动创建
topic_id => "system-secure"
#压缩类型
compression_type => "snappy"
}
}

测试输入到Kafka的配置文件 ./bin/logstash -f ./config/logstash_for_kafka.conf -t

使用该配置文件启动LogStash
注意采集系统日志需要权限,命令行前面必须加sudo, root用户可以不用
./bin/logstash -f ./config/logstash_for_kafka.conf
验证数据是否写入到kafka,这里我们检查是否生成了一个叫system-secure的主题
./bin/kafka-topics.sh --describe --zookeeper 192.168.20.163:2181 --topic system-secure

对于logstash输出的我们也可以提前先定义主题,然后启动logstash 直接往定义好的主题写数据就行啦,命令如下:
./bin/kafka-topics.sh --create --zookeeper 192.168.20.163:2181 --replication-factor 3 --partitions 3 --topic TOPIC_NAME
好了,我们将logstash收集到的数据写入到了kafka中了
Kafka集群安装配置-kafka to ES
那如何将数据从kafka中读取然后给ES集群呢?
那下面我们在kafka集群上安装Logstash,可以通过上面的方法,先配置一台的logstash,然后通过scp命令通过网络拷贝,安装路径是/usr/local/software/logstash-7.6.2
三台上面的logstash的配置如下,作用是将kafka集群的数据读取然后转交给es集群,这里为了测试我让他新建一个索引文件,注意这里的输入日志是secure,主题名称是system-secure
-
如上所说,在三台Kafka集群的Server上分别安装LogStash,并在如下目录新建
logstash_kafka2ES.conf

-
配置logstash_kafka2ES.conf,logstash的config目录下执行命令
vim logstash_kafka2ES.conf
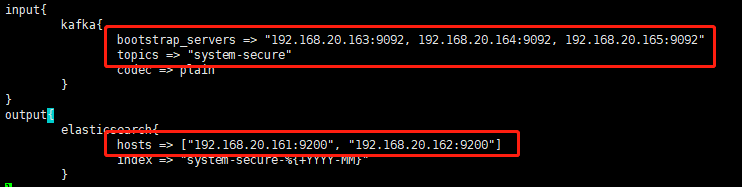
-
在三台Kafka Server上按顺序分别启动LogStash,启动命令三台是通用的
./bin/logstash -f ./config/logstash_kafka2ES.conf -
测试通过Kafka队列传递消息到ES集群
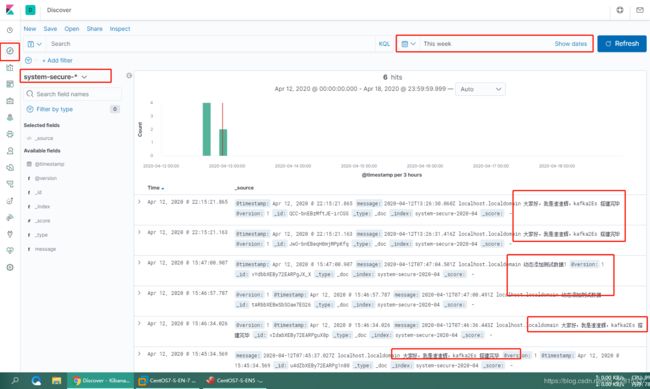
在ES Server:192.168.20.167上写入测试内容,利用secure这个文件来测试

可以看到消息已经分散的写入ES及集群中
ES Server 192.168.20.161

ES Server 192.168.20.162

Kibana安装
该节参考博客:https://www.cnblogs.com/JetpropelledSnake/p/9893566.html
- 下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
- 编辑配置文件
vim kibana.yml
确保下列配置正确
server.port: 5601
# 本机ip
server.host: "192.168.20.162"
# elasticsearch集群地址
elasticsearch.hosts: ["http://192.168.20.162:9200", "http://192.168.20.161:9200"]

上述配置完成后,就可以启动了 ./bin/kibana

注意:1.Kibana默认不能用root用户启动,需要切到es用户,没有权限需要给es用户赋权
访问下http://192.168.20.162:5601
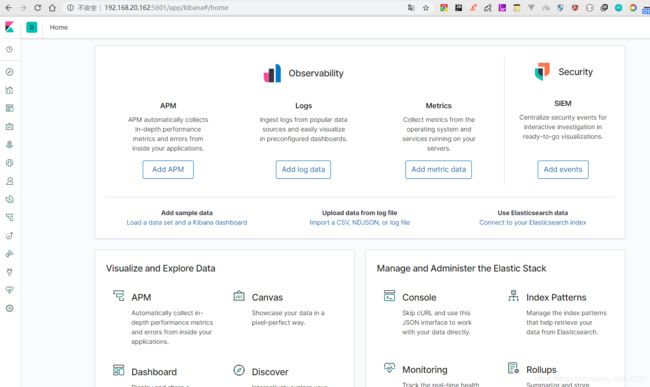
第一次访问的时候,会要求设置Index Pattern,因为我们在logstash-es.conf中设置为logstash-%{+YYYY-MM},所以设置为logstash-*就可以了。
# 这里有可能会遇到要求你创建Index的情况,请参考官网的指导文件和该博客导入json文件即可
# 官网指导文件 https://www.elastic.co/guide/en/kibana/6.x/tutorial-load-dataset.html
# 如何批量导入数据到Kibana,https://www.cnblogs.com/hai-ping/p/6068946.html
Discover是主要的查询交互界面,如下所示:

有时候在访问discover的时候,提示no results found,如下所示:
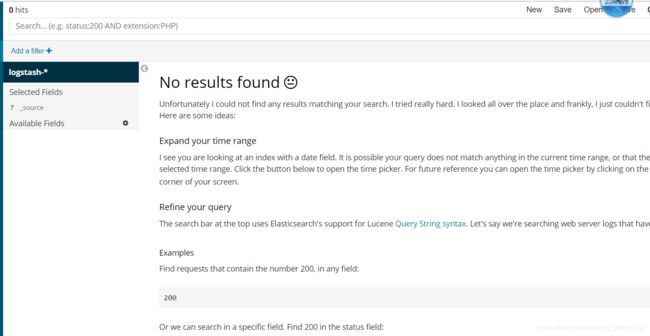
这通常是由于默认的查询时间范围太短的原因,可以通过右上角的TimeRange来设置查询的时间范围。
到这里,ELK+k的环境搭建与基本配置就完成了。
更多的配置与优化参见各官方文档。

根据ES集群中存入的数据,在Kibana中建立Index
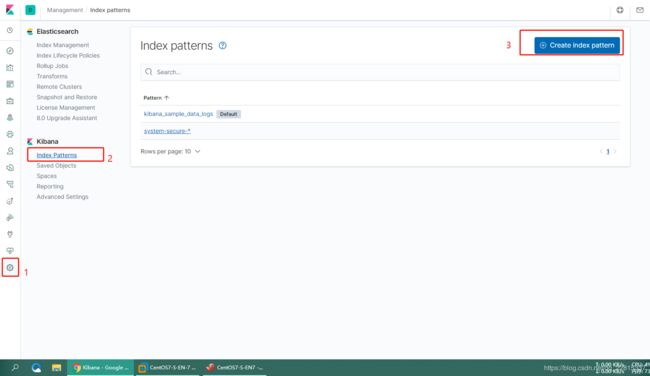

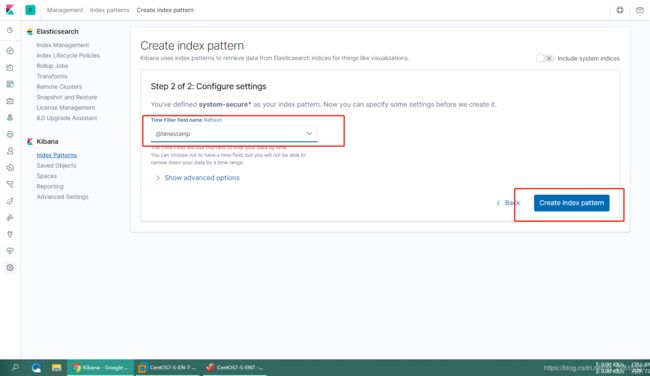
建立好index后,就可以在Discover这里查询介入的数据了
ES集群采用的查询语言是DSL语言,该语言采用json的格式组织查询语句。
Kibana可以多样化展示ES集群中介入的数据,github上有很多定制好的格式,针对常见生产环境可以直接配置,十分方便。
最终测试

历经三昼夜,终于搞定了┐(´∀`)┌
安装好的虚拟机服务器重启一遍的步骤
- 191服务器上需要执行的命令如下:
# 1. 启动elasticsearch
# 进入elasticsearch目录
cd /usr/local/software/elasticsearch/elasticsearch-7.6.2
# 切换到es用户
su es
# 启动
./bin/elasticsearch &
# 通过浏览器访问下面的地址查看是否启动成功:
http://192.168.20.161:9200/_cluster/health?pretty
- 192服务器上需要执行了命令步骤
# 1. 启动elasticsearch
# 进入elasticsearch目录
cd /usr/local/software/elasticsearch/elasticsearch-7.6.2
# 切换到es用户
su es
# 启动
./bin/elasticsearch &
# 通过浏览器访问下面的地址查看是否启动成功:
http://192.168.20.161:9200/_cluster/health?pretty
# 2. 启动 elasticsearch-head-master
# 进入elasticsearch-head-master目录
cd /usr/local/software/elasticsearch/elasticsearch-head-master
# 切换成root用户回车并输入root密码
su root
# 启动 elasticsearch-head-master
nohup grunt server &
# 通过浏览器访问下面的地址查看是否启动成功:
http://192.168.20.162:9100/
3. 启动kibana
# 进入kibana目录
cd /usr/local/software/kibana-7.6.2-linux-x86_64
# 切换到es用户,kibana不能用root启动
su es
# 启动
./bin/kibana
# 通过浏览器访问下面的地址查看是否启动成功:
http://192.168.20.162:5601/
- 193、194、195服务器上需要执行了命令步骤
# 1.启动zookeeper
# 进入kafka目录
cd /usr/local/software/kafka_2.13-2.4.1
# 启动(zookeeper需要 193->194->195 上的三个按照顺序启动)
./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
# 2.启动kafka
# kafka目录启动kafka服务(kafka需要 193->194->195 上的三个按照顺序启动)
./bin/kafka-server-start.sh ./config/server.properties &
# 3.启动logstash
# 进入logstash目录
cd /usr/local/software/logstash-7.6.2
# 启动logstash(三个都要启动)
./bin/logstash -f ./config/logstash_kafka2ES.conf &
- 196、197服务器上需要执行的命令步骤
# 1.启动logstash
# 进入logstash目录
cd /usr/local/software/logstash-7.6.2
# 启动logstash_for_kafka
./bin/logstash -f ./config/logstash_for_kafka.conf &
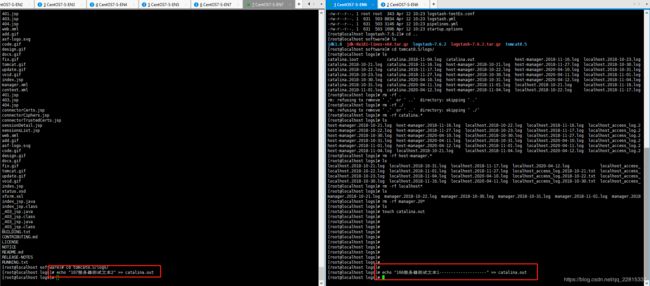
- 手动测试166/167tomcat日志数据
# 手动想Catalina.out文件输入测试数据
# 进入目标目录
cd /usr/local/software/tomcat8.5/logs
echo "166服务器测试日志----------" >> catalina.out
echo "167服务器测试日志*********" >> catalina.out
# 写入测试数据