count(distinct xxx) 和 group by 做去重隐藏的坑
不说废话,直接上代码。
以下查询是基于mysql自带的country,city,countrylanguage三个样例表做的:
select count(*) from country
union all
SELECT count(distinct Code, Name, Continent, Region, SurfaceArea, IndepYear, Population, LifeExpectancy, GNP, GNPOld, LocalName, GovernmentForm, HeadOfState, Capital, Code2)
FROM world.country
union all
select count(*) from
(
SELECT Code, Name, Continent, Region, SurfaceArea, IndepYear, Population, LifeExpectancy, GNP, GNPOld, LocalName, GovernmentForm, HeadOfState, Capital, Code2
FROM world.country
group by Code, Name, Continent, Region, SurfaceArea, IndepYear, Population, LifeExpectancy, GNP, GNPOld, LocalName, GovernmentForm, HeadOfState, Capital, Code2
) a;查询结果如下:
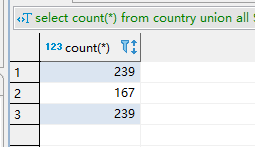
发现使用count(distinct xxx)后的结果居然和group by 去重的数据不一致;
不用怀疑,就是NULL引起的,以下为证:
SELECT distinct Code, Name, Continent, Region, SurfaceArea, IndepYear, Population, LifeExpectancy, GNP, GNPOld, LocalName, GovernmentForm, HeadOfState, Capital, Code2
FROM world.country注意序号
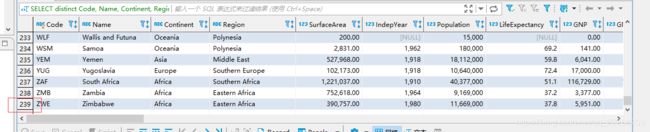
SELECT distinct Code, Name, Continent, Region, SurfaceArea, IndepYear, Population, LifeExpectancy, GNP, GNPOld, LocalName, GovernmentForm, HeadOfState, Capital, Code2
FROM world.country
where
Code is not null and
Name is not null and
Continent is not null and
Region is not null and
SurfaceArea is not null and
IndepYear is not null and
Population is not null and
LifeExpectancy is not null and
GNP is not null and
GNPOld is not null and
LocalName is not null and
GovernmentForm is not null and
HeadOfState is not null and
Capital is not null and
Code2 is not null 
到这里大家应该明白了吧
使用count(distinct xxx) 时会自动过滤字段为NULL的值,而group by 不会,所以两个结果不一致。