Python 爬取周杰伦歌曲信息,爬取豆瓣top250的电影,并保存至excel中
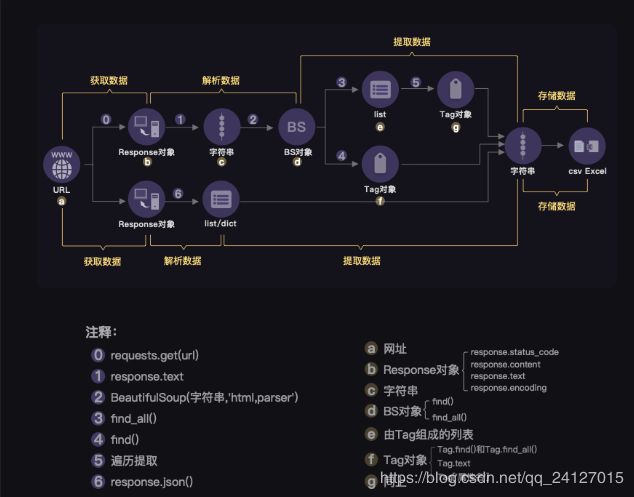
使用requests、BeautifulSoup模块,在网上爬取信息。有的网页可以直接爬取到,有些则需要分步加载,这时就需要使用network进行分析找到信息对应的请求。
有的会反爬虫,则需要添加headers信息,user-agent会存放访问网站的浏览器,我们需要伪装成浏览器进行爬取。
有时候返回的信息是个json文件,则需要将json转换成dict字典。
1.爬取周杰伦歌曲
示例1:需要用到request headers,network,query string parameters,json,csv,openpyxl等知识
import requests,openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'song'
sheet['A1'] = '歌曲名'
sheet['B1'] = '所属专辑'
sheet['C1'] = '播放时长'
sheet['D1'] = '播放链接'
# 获取前五页的歌曲
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'origin': 'https://y.qq.com',
'referer': 'https://y.qq.com/portal/search.html',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
for i in range(5):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'txt.yqq.song',
'searchid': '71605763533364392',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': str(i+1),
'n': '10',
'w': '周杰伦',
'g_tk_new_20200303': '322019968',
'g_tk': '322019968',
'loginUin': '156883371',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
res_music = requests.get(url,headers=headers,params=params)
json_music = res_music.json()
list_music = json_music['data']['song']['list']
for songinfo in list_music:
name = songinfo['name']
album = songinfo['album']['name']
time = songinfo['interval']
address = 'https://y.qq.com/n/yqq/song/' + songinfo['mid']
songinfolist =[name,album,time,address]
sheet.append(songinfolist)
wb.save('Jay Songs.xlsx')2.爬取豆瓣top250电影
示例:
import openpyxl,csv,requests,bs4
# 找到豆瓣网top250的电影信息:序号,电影名,评分,推荐语,链接,并保存在excel文件中
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'Top250 films'
sheet.append(['序号','电影名','评分','推荐语','链接'])
# 获取电影信息,一共10页,每页有25个电影
url = 'https://movie.douban.com/top250?start=0&filter='
# 需要设置浏览器信息,要不然访问会被拒绝
headers = {
'Host': 'movie.douban.com',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
# 第二页的地址为:https://movie.douban.com/top250?start=25&filter=,可见每次变化的数字是 N*25,N从0到9
for i in range(10):
url = 'https://movie.douban.com/top250?start=' +str(i*25) + '&filter='
res_films = requests.get(url,headers = headers)
print(res_films.status_code)
bs = bs4.BeautifulSoup(res_films.text,'html.parser')
bs = bs.find('ol',class_='grid_view')
for titles in bs.find_all('div',class_='item'):
# 查找序号
num = titles.find('em',class_='').text
# 查找电影名
title = titles.find('span',class_='title').text
# 查找推荐语
if titles.find('span',class_='inq') != None:
tes = titles.find('span',class_='inq').text
else:
tes = ""
# 查找评分
comment= titles.find('span',class_='rating_num').text
# 查找链接
ulr_movie = titles.find('a')['href']
sheet.append([num,title,comment,tes,ulr_movie])
wb.save('top250films.xlsx')