员工离职分析预测
一、摘要
通过员工离职情况数据来分析数据集内哪些特征变量会对员工离职造成影响,以及其背后可能的原因,并利用逻辑回归和决策树算法构建预测模型。
员工对公司的满意度、岗位类别、以及优秀人才能否得到满意的薪酬和晋升空间,都是影响离职与否的主要因素。
二、分析背景
员工离职,似乎已经成为每一家企业都要面对的问题,优秀人才的离职会对公司的运营产生巨大的负面影响。一家大型企业希望能搞清楚为什么企业内的一些优秀员工会选择离职,此外,还希望能利用收集的员工数据建立一个预测模型以便提前预测哪些优秀员工有离职倾向。
三、分析过程
数据理解
分析所用数据集 HR_comma_sep 来源于kaggle网站,为某公司员工的离职数据,包含有14999个样本以及10个特征,这10个特征分别为:
satisfaction_level(员工对公司满意度)
last_evaluation(最新考核评估)
number_project(参与过项目数)
average_montly_hours(平均每月工作时长)
time_spend_company(工作年限)
Work_accident(是否发生过工作事故)
promotion_last_5years(过去5年是否晋升)
posts(岗位类别)
salary(薪资水平)
left(是否离职)。
本次分析着重针对数据集中的各个特征变量对员工是否离职的影响进行分析。
数据处理
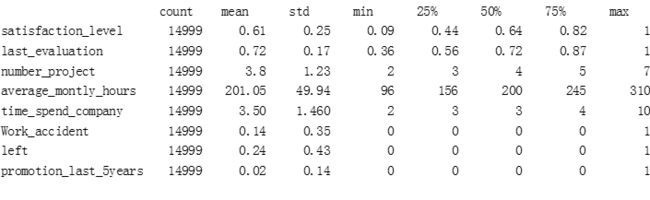
各个特征的描述性统计如下表所示, 全部14999个记录中所有变量值都是齐全的没有空值,而且各个变量的范围都是合理的,与实际环境相符,数据质量很高因而不需要进行数据清洗的处理。
特征工程
这部分的工作主要是对posts(岗位类别)与salary(薪资水平)这两个字符型特征变量进行处理,即需要将字符型数据转换成数值型数据。
特征salary共有low、medium、high3个类别,并且这3个类型是有顺序结构的,故分别将其转换为数值1、2、3。
特征posts共有IT、RandD、accounting、hr等10个类别,这10个类型不具有像特征salary有顺序结构,故应将其转换onehot变量。
分析过程
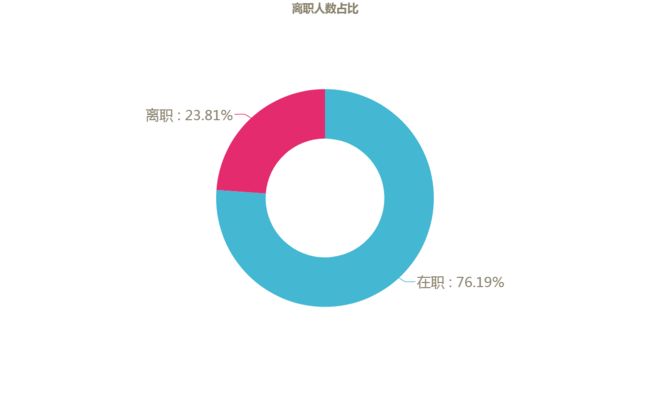
该公司员工的离职总体情况如何?
下图是离职员工的占比情况,离职员工人数共3571人,占总员工数的23.81%。
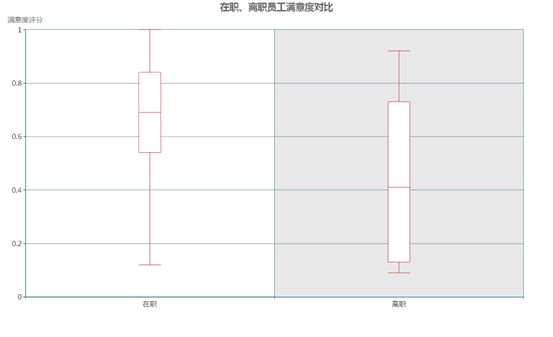
员工对公司的满意度是否影响了其离职?
对公司是否满意无疑是影响员工去留的主要因素之一,员工的离职往往可以从过往对公司的满意度评分中看出端倪。
对比员工对公司的满意度评分,离职员工的评分明显偏低,中位数为0.41,比在职员工0.69的评分中位数低40%,差距非常明显。此外,有至少25%的离职员工评分在0.2以下的低水平。
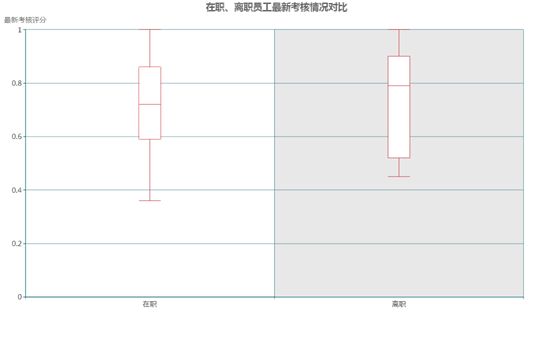
离职员工是否属于工作表现较好的员工?
一个公司的优秀员工,如果认为公司的待遇或职位与自身能力不匹配,发展通道受限,他们就很有可能选择离职,那么是否离职员工的工作表现总体上就会好于在职员工呢?
下图显示了在职与离职员工在最近一次员工考核评分的情况对比。可以看出有一半的离职员工的考核评分在0.8以上的优秀水平,离职员工的评分总体上看起来确实要好于在职员工。
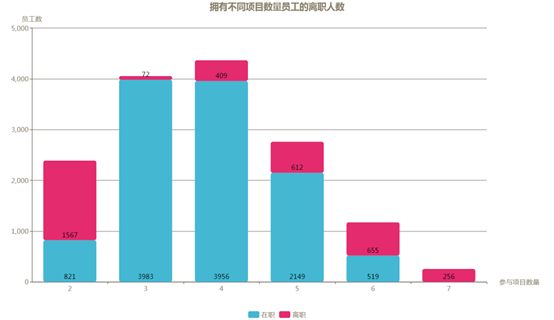
员工的工作经验和离职有关系吗?
员工的工作经验丰富程度由其参与过的项目数量直接决定,而参与项目数量不同的员工群体的离职占比的确存在差异。
从下图统计的各个群体的离、在职人数可以看到,离职人数最多的群体是参与过2个项目的员工,达到1567人,离职占比65.6%。参与过7个项目的员工虽然离职人数仅有256人,排在倒数第二,但是离职占比却达到了100%,此外参与过6个项目的员工离职占比也在55.8%,公司工作经验最为丰富的员工流失十分严重!其他参与项目数量在3到5个的员工的离职人数占比则都处于较低水平。
造成这种差异的原因可能在于公司没有能提供可预见的晋升空间,从而造成经验丰富的员工更愿意选择另谋高就来拓展自己的职业空间,而只参与过2个项目的员工大量离职则更可能是由于其自身未能适应公司的管理制度或企业文化导致。
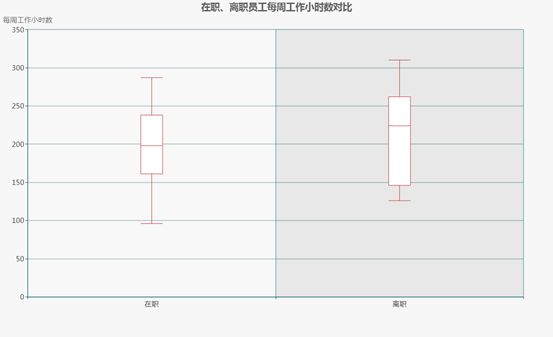
每月工作时长
高强度的工作强度会造成压力过大,进而产生各种心理或生理上的问题,这也是导致员工离职的主要原因之一。
下图对在、离职两类员工的平均每月工作小时数进行了对比,离职员工的总体水平要高于在职员工。离职员工的工作时长中位数为224小时,比在职员工的198小时高出11.6%,以每月22个工作日计算,离职员工平均每天工作10个小时以上,工作强度较大。
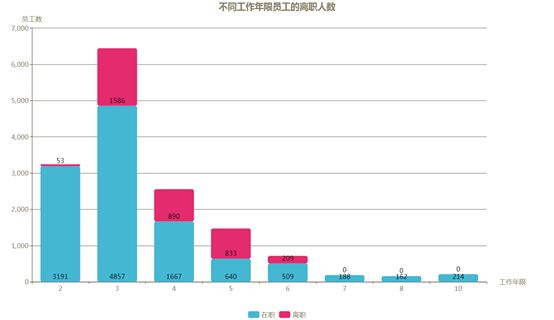
在公司工作几年的员工更容易离职?
下图统计的是不同工作年限员工的离职情况,很明显离职的主要集中在工作年限为3至6年的员工,工作2年的新员工离职率很低仅为1.6%,而7年及以上的员工离职率为零。结合离职员工在参与项目数量上的分布情况,可看出离职的很大一部分属于公司内中生代且工作经验丰富的员工。
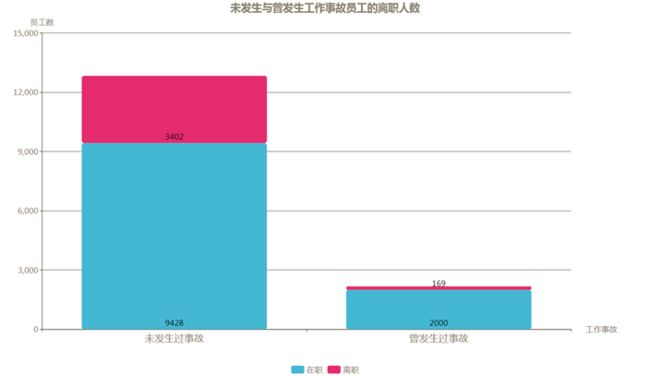
发生过工作事故是否会增加员工离职的可能性?
从下图未发生过工作事故和曾发生过工作事故的员工离职情况可以看到,曾发生过工作事故的员工离职的人数和比例都要远低于未发生过工作事故的员工,因此,发生过工作事故并不会增加员工离职的可能性。
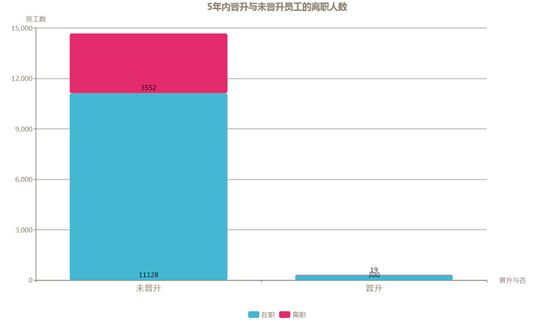
职位晋升情况
没有清晰的晋升渠道和空间是导致员工离职的重要因素,从下图离职员工在过去5年是否得到晋升的分布来看,差距非常明显,高达99.5%的离职员工在过去五年未能得到晋升。虽然得到晋升的员工本身很少,但其离职比例仅为6.0%,远低于未能晋升员工的24.2%。
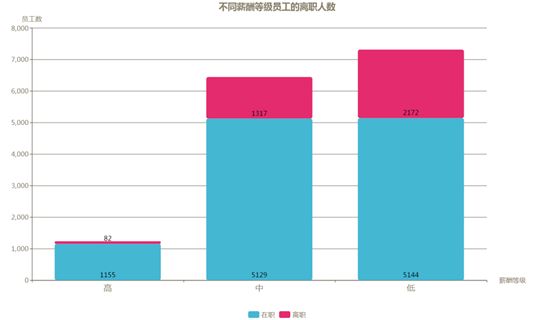
薪酬
下图是离职员工在不同薪酬等级员工的分布情况,低等级的离职人数和占比均为最高,中级次之,高级的离职率最低仅为6.6%,可见薪酬是决定员工去留的又一大重要因素。
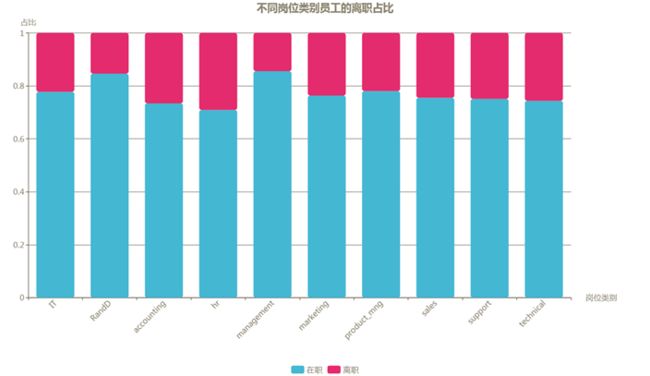
哪种岗位的员工更容易离职呢?
各个岗位的离职占比如下图所示,占比都比较接近,进一步对每个岗位类别进行卡方检验,各个类别的检验显著性如表格所示,其中统计差异最大的是‘hr’、‘management’、‘RanD’三个岗位,结合‘hr’离职占比较高,而‘management’、‘RanD’较低的特点,可看出担任‘hr’岗位的员工比其他岗位更趋向于离职,而‘management’、‘RanD’两个岗位的员工则更趋于留下,其他岗位没有明显的趋向。

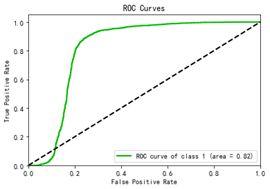
构建模型
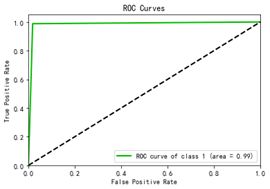
分别用逻辑回归和决策树算法对数据集进行建模,并调整至最佳参数,其中逻辑回归算法的预测准确率为82.2%,决策树算法的准确率为98.3%。两种算法的ROC曲线如下图所示,右侧的决策树AUC值较大,优于左侧的逻辑回归,故最终选择决策树作为员工离职预测的算法。(详细代码见后附代码)
所构建的模型除了能预测员工是否会离职,还能给出离职的概率大小,人力资源部门可根据结果对预测概率较高的员工优先采取挽留措施。
四、分析总结
1、该公司员工的总体离职率为23.81%。
2、离职员工的对公司的满意度评分明显低于在职员工,对公司是否满意是影响员工去留的主要因素之一。
3、离职员工的评分总体上看起来确实要好于在职员工,有一半的离职员工的考核评分在0.8以上的优秀水平,这些员工在就业市场会更受企业欢迎,更容易得到更高的薪酬或更好的工作环境,因而离职可能性较高。
4、离职员工平均每月工作时间的总体水平要高于在职员工。平均计算每天工作10个小时以上,高强度的工作强度会造成压力过大,进而产生各种心理或生理上的问题,这也是导致员工离职的主要原因之一。
5、曾发生过工作事故的员工离职的人数和比例都要远低于未发生过工作事故的员工,故发生过工作事故并不会增加员工离职的可能性。
6、薪酬在低等级的离职人数和占比均为最高,中级次之,高级的离职率最低,薪酬是决定员工去留的又一大重要因素。
7、参与项目数量最多的员工是离职率最高,而工作年限3至6年又是离职员工最为集中的范围,他们是公司内的中生代且工作经验丰富,但是高达99.5%的离职员工在过去五年未能得到晋升,说明公司不能为这部分属于中生代且工作经验丰富的员工提供满意的薪酬或可预见的晋升空间,从而导致这些员工选择另谋高就。
8、担任‘hr’岗位的员工比其他岗位更趋向于离职,可能与公司内优秀人才流失严重导致人力资源工作压力较大的原因有关。
9、可利用所构建的决策树模型给出的员工离职的概率,对相应员工提前采取针对性的挽留措施。
五、参考信息
卡方检验:通常用在检验某个特征变量(分类变量)是不是和因变量(分类变量)有显著相关关系。
六、数据来源
https://www.kaggle.com/jiangzuo/hr-comma-sep/version/1
七、Python代码
导入需要的工具库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
读取数据集
data = pd.read_csv(r'D:\360安全浏览器下载\hr-comma-sep\HR_comma_sep.csv')
进行描述性统计
data.describe()
将特征salary转换为数值型变量
from sklearn.preprocessing import OrdinalEncoder
OE = OrdinalEncoder()
data['salary'] = OE.fit_transform(data['salary'])
将特征posts转换为onehot变量,并与原数据集拼接
from sklearn.preprocessing import OneHotEncoder
OHE = OneHotEncoder(categories='auto').fit(data['posts'].to_frame())
result = OHE.transform(data['posts'].to_frame())
result = pd.DataFrame(result.toarray())
result.columns = ['IT', 'RandD', 'accounting', 'hr', 'management', 'marketing',
'product_mng', 'sales', 'support', 'technical']
data = pd.concat([data,result],axis=1)
生成特征变量和标签变量
X = data.drop(['left','posts'],axis=1)
Y = data['left']
计算离职、在职员工人数的占比。
data['left'].value_counts()/data['left'].count()
构建参与不同项目数量、工作年限、5年内是否晋升、是否发生过工作事故、薪酬等级、岗位类别的离、在职员工人数的透视表,并计算各个数量的离、在职员工占比。
pd.pivot_table(data,index='left',columns='number_project',values='posts',aggfunc='count')
pd.pivot_table(data,index='left',columns='time_spend_company',values='posts',aggfunc='count')
pd.pivot_table(data,index='left',columns='promotion_last_5years',values='posts',aggfunc='count')
pd.pivot_table(data,index='left',columns='Work_accident',values='posts',aggfunc='count')
pd.pivot_table(data,index='left',columns='salary',values='posts',aggfunc='count')
pd.pivot_table(data,index='left',columns='posts',values='Work_accident',aggfunc='count')
将特征和标签数据集划分为训练和测试数据集。
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3)
初步考察逻辑回归模型的预测效果
from sklearn.linear_model import LogisticRegression as LR
LR1 = LR(random_state=20).fit(X_train,Y_train)
print(LR1.score(X_train,Y_train),LR1.score(X_test,Y_test))
循环迭代逻辑回归模型的正则化参数来选择最佳参数,得到最佳正则化参数为C=0.0013
from sklearn.model_selection import cross_val_score
for i in np.linspace(0.01,0.21,20):
error.append(cross_val_score(LR(solver='liblinear',C=i,random_state=30),X_train,Y_train,cv=10).mean())
plt.plot(np.linspace(0.001,0.021,20),error,label='准确率')
plt.legend()
plt.show()
print(max(error),(error.index(max(error))+1)*0.001)
error=[]
for i in np.linspace(0.0001,0.0021,20):
error.append(cross_val_score(LR(solver='liblinear',C=i,random_state=30),X_train,Y_train,cv=10).mean())
plt.plot(np.linspace(0.0001,0.0021,20),error,label='准确率')
plt.legend()
plt.show()
print(max(error),(error.index(max(error))+1)*0.0001)
循环迭代逻辑回归模型的最大迭代次数来选择最佳参数,得到最佳次数为21。
error=[]
for i in range(1,201,20):
error.append(cross_val_score(LR(solver='liblinear',C=0.0013,random_state=30,max_iter=i),X_train,Y_train,cv=10).mean())
plt.plot(range(1,201,20),error,label='准确率')
plt.legend()
plt.show()
print(max(error),(error.index(max(error))*20)+1)
error=[]
for i in range(1,31):
error.append(cross_val_score(LR(solver='liblinear',C=0.0013,random_state=30,max_iter=i),X_train,Y_train,cv=10).mean())
plt.plot(range(1,31),error,label='准确率')
plt.legend()
plt.show()
print(max(error),(error.index(max(error))+1))
评估得到的逻辑回归模型,准确率为82.2%。
LR1 = LR(solver='liblinear',C=0.0013,random_state=30,max_iter=12).fit(X_train,Y_train)
LR1.score(X_test,Y_test)
用决策树模型拟合训练数据,并用测试数据集评估其预测效果,准确率为98.3%
from sklearn.tree import DecisionTreeClassifier as DTC
DTC1 = DTC().fit(X_train,Y_train)
DTC1.score(X_test,Y_test)
用正确率评估分类模型并不客观,更合适的使用ROC曲线和AUC值。
import scikitplot as skplt
Y_pred_proba_LR = pd.DataFrame(LR1.predict_proba(X_test))
Y_pred_proba_DTC = pd.DataFrame(DTC1.predict_proba(X_test))
skplt.metrics.plot_roc(Y_test,Y_pred_proba_LR,classes_to_plot=1,plot_micro=False,plot_macro=False)
skplt.metrics.plot_roc(Y_test,Y_pred_proba_DTC,classes_to_plot=1,plot_micro=False,plot_macro=False)
plt.show()