HBase的put流程源码分析
https://blog.csdn.net/bryce123phy/article/details/51279878
hbase是一个nosql型数据库,本文我们会分析一下客户的数据是通过什么样的路径写入到hbase的。
HBase作为一种列族数据库,其将相关性较高的列聚合成一个列族单元,不同的列族单元物理上存储在不同的文件(HFile)内。一个表的数据会水平切割成不同的region分布在集群中不同的regionserver上。客户端访问集群时会首先得到该表的region在集群中的分布,之后的数据交换由客户端和regionserver间通过rpc通信实现,下面我们从hbase源码里探究客户端put数据的流程。本文参考的源码是1.1.2版本的hbase
1)客户端
put在客户端的操作主要分为三个步骤,下面分别从三个步骤展开解释:
(一)、客户端缓存用户提交的put请求


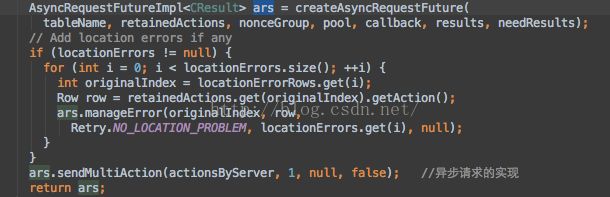
- while (!batchOp.isDone()) { //操作未完成前一直循环
- if (!batchOp.isInReplay()) {
- checkReadOnly(); //判断是否是只读状态
- }
- checkResources(); //检查相关资源
- if (!initialized) {
- this.writeRequestsCount.add(batchOp.operations.length); //更新写请求计数器
- if (!batchOp.isInReplay()) {
- doPreMutationHook(batchOp);
- }
- initialized = true;
- }
- long addedSize = doMiniBatchMutation(batchOp); //最终的put操作是落在这里的
- long newSize = this.addAndGetGlobalMemstoreSize(addedSize); //以原子操作的方式增加Region上的MemStore内存的大小
- if (isFlushSize(newSize)) { //判断memstore的大小是否达到阈值,决定是否flush
- requestFlush();
- }
- }
总结上面hbase的写路径可以发现在hbase的写入过程中应用到了如下的一些技术:
首先,客户端的rpc请求传递到服务端时,函数AsyncRequestFutureImpl()是一个Lazy优化,或者说是一个异步的优化,虽然函数声明了一个对服务端的rpc调用,但是它并没有马上呼叫服务端,而是在需要时才真正呼叫服务端。
第二,数据提交时采用了group commit技术,理解group commit可以用挖煤做比喻,是一铲子一铲子挖比较快,还是一次挖出一车比较省力。
第三,MVCC即多版本并发控制
限于篇幅和本人的知识有限,以上所说的只是简单描述了hbase的写事务的主干路径,并简要指出了其中的关键技术点,此外还有幂等控制、回滚操作、错误处理以及写入线程模型等等等等,即便是提到的mvcc、group commit也只是蜻蜓点水,如果展开还有很多很精彩的内容值得大家研究,如果你也对hbase感兴趣,欢迎与我一起讨论,共同提高。
Hbase-0.98.6源码分析--Put写操作Client端流程
客户端程序写数据通过HTable和Put进行操作,我们从客户端代码开始分析写数据的流程:

可以看到,客户端写数据最终的调用了HTableInterface的put()方法,因为HTableInterface只是一个接口,所以最终调用的是它的子类HTable的put()方法。进入HTable.put():
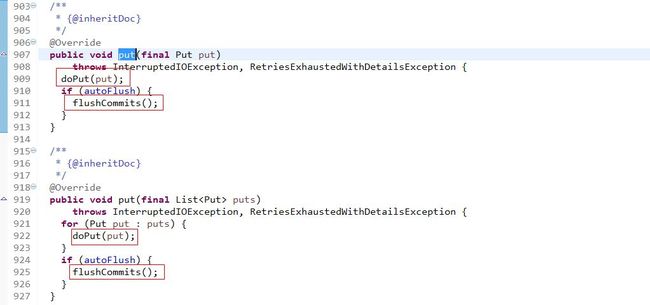
从上面代码可以看出:你既可以一次put一行记录也可以一次put多行记录,两个方法内部都会调用doPut方法,最后再来根据autoFlush(默认为true),即自动提交,判断是否需要flushCommits刷写提交,在autoFlush为false的时候,如果当前容量超过了缓冲区大小(默认值为:2097152=2M),也会调用flushCommits方法。也就是说,在自动提交情况下,你可以手动控制通过一次put多条记录,然后将这些记录flush,以提高写操作吞吐量。
首先看下flushCommits()方法:

只是简单地调用了backgroundFlushCommits()方法,该方法会在后面讲到。
进入doPut()方法:

从上面的代码可以看出,backgroundFlushCommits()这个刷新操作可以是制定异步提交还是同步提交,从doPut方法中来看默认是以异步的方式进行,这里的ap是AsyncProcess类的一个实例,该类使用多线程的来实现异步的请求,也就是说,并非每一次put操作都是直接往HBase里面写数据的,而是等到缓存区域内的数据多到一定程度(默认设置是2M),再进行一次写操作。当然这次操作在Server端应当还是要排队执行的,具体执行机制这里不作展开。可以确定的是,HConnection在HTable的put操作中,只是起到一个定位RegionServer的作用,在定位到RegionServer之后,操作都是由cilent端通过rpc调用完成的。这个结论在插入/查询/删除中是一致的。
writeAsyncBuffer.add(put)就是向一个异步缓冲区添加该操作,然后当一定条件的时候进行flash,当发生flash操作的时候,才会真正的去执行该操作,这主要是提高系统的吞吐率,接下来我们去看看这个flush的操作内部。

看下waitUntilDone()方法:


由这个waitForMaximumCurrentTasks()方法,可以清晰了了解到waitUntilDone()方法的操作流程,具体要等待到什么时候呢?等到tasksSent的值减去tasksDone的值等于0,tasksSent表示提交的任务数,tasksDone表示完成的任务数。
现在就可以重新总结一下backgroundFlushCommits()方法,在第965行,submit()方法传入的参数是true,表示需要等待rpc调用结束。第980行,如果有部分数据提交失败,同时没有设置清空失败的数据时,把数据重新添加到writeAsyncBuffer列表中。最后在finally块中,清空当前currentWriteBufferSize的大小,如果有数据没有提交成功,
重新把未提交的数据的大小计算起来添加到currentWriteBufferSize中。
比较doPut()和flushCommits(),如果在doput的过程中,也就是调用htable.put(Put)的时候,如果缓存大小超过了客户端写缓存大小的限制,调用backgroundFlushCommits()方法方法是异步的;而在flushcommit方法中,backgroundFlushCommits()这个方法是同步的。
接下来就是重要的提交过程,submit()方法:


进入sendMultiAction()方法,看它是如何发送put请求的:
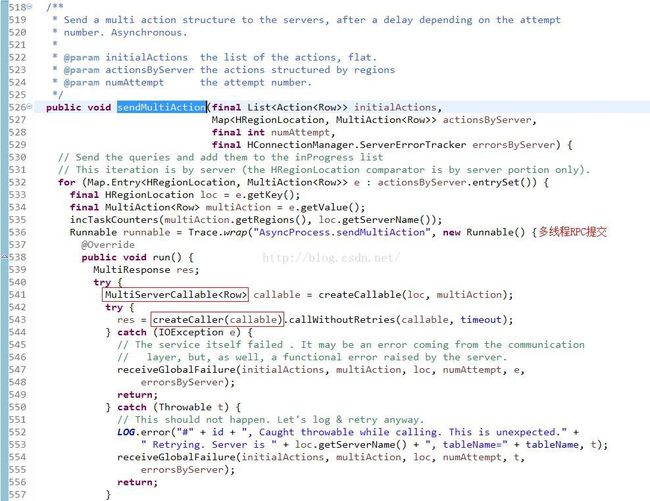

从上面的代码可以看出,每个任务都是通过HBase的RPC框架与服务器进行通信,并获取返回的结果。其中最重要的两个组件我用红色方框已经圈出,看下他俩的具体实现:
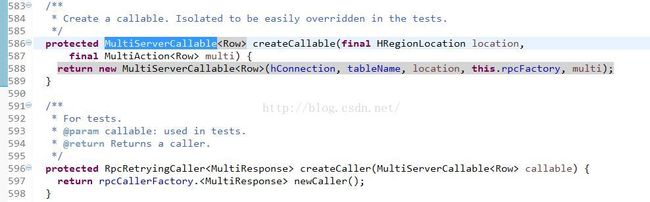
先构造一个MultiServerCallable,然后再通过rpcCallerFactory将其封装为RpcRetryingCaller做最后的call操作。
查看MultiServerCallable:

注释里就说的很明白了,client端通过MultiServerCallable.call()方法调用res的rpc的multi()方法,来实现put提交请求。可以想象,根据讲过的《Hadoop RPC机制-原理篇》,HRegionServer端必定也有一个multi()方法。
总结put操作:
(1)把put操作添加到writeAsyncBuffer队列里面,符合条件(自动flush或者超过了阀值writeBufferSize)就通过AsyncProcess异步批量提交。
(2)在提交之前,我们要根据每个rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的,然后再把这些rowkey按照HRegionLocation分组。在获得具体region位置的时候,会对最近使用的region server做缓存,如果缓存中保存了相应的region server信息,就直接使用这个region信息,连接这个region server,否则会对master进行一次rpc操作,获得region server信息,客户端的操作put、get、delete等操作每次都是封装在一个Action对象中进行提交操作的,都是一系列的的action一起提交,这就是MultiAction。
(3)通过多线程,一个HRegionLocation构造MultiServerCallable
下篇文章将会介绍HRegionServer如何响应客户端发出的Put请求。
在《Hbase-0.98.6源码分析--Put写操作Client端流程》中,介绍了put操作的流程,最后client端是通过MultiServerCallable.call()调用multi()方法来进行rpc请求的。追踪multi()方法,进入ClientProtos.ClientService.BlockingInterface接口的multi()抽象方法,再次追踪该方法,进入实现该方法的HRegionServer实例,查看multi()方法的具体实现:
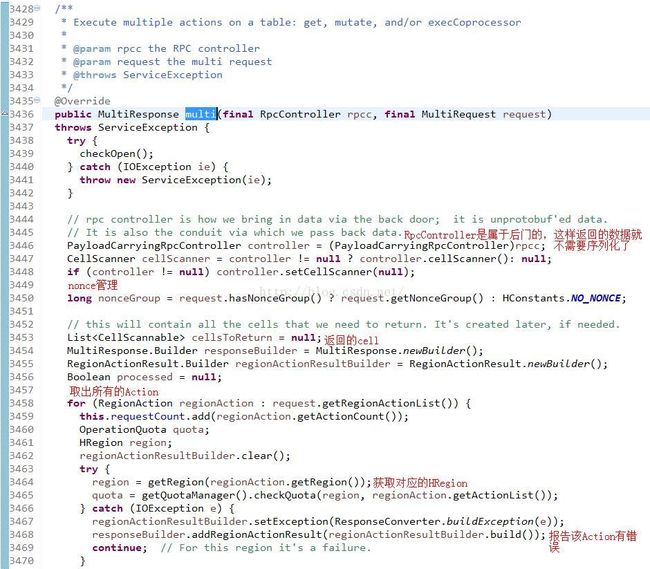

这个方法里面还包括了PayloadCarryingRpcController和CellScanner可以看得出来它不只是被Put来用的,但是这些我们不管我们只看Put如何处理就行了。在该方法的3464行调用了getRegion()方法,来获取对应的HRegion,简单看一下:
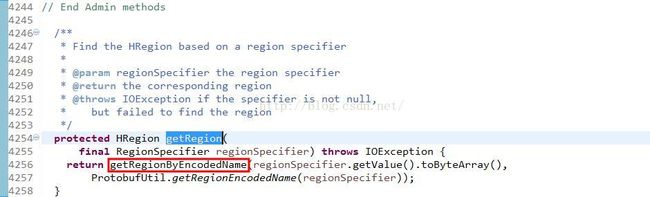
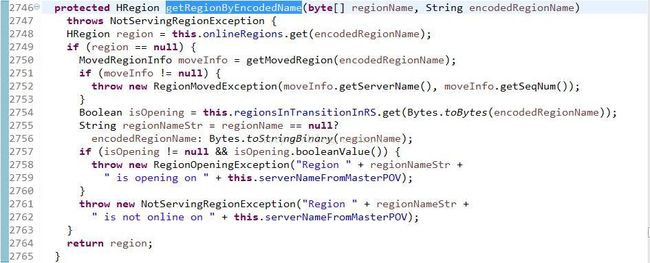
分析下getRegionByEncodedName()方法流程,看它如何从当前regionserver中的onlnieRegions中得到请求的region.:
1.从onlineRegions中取出HRegion实例
2.如果onlineRegions列表中不包含此region,从movedRegions列表中拿到region,region的moved超时是2分钟,
如果movedRegions列表中能拿到此region,同时move时间超时,并从movedRegions列表中移出引region返回null,
否则返回正在moved的region,如果movedRegions中返回的region不为null,throwRegionMovedException
3.从regionsInTransitionInRS中获取此region,如果能拿到,同时拿到的值为true,表示region还在做opening操作,
Throw RegionOpeningException
4.如果以上得到的值都为null,表示此server中没有此region,throw NotServingRegionException
此时基本上只有一个可能,region在做split.或者move到其它server(刚完成move,client请求时不在此server)
总结下multi()方法的操作:
1、取出来所有的action(Put),这里主要是put,因为我们调用客户端就是这么调用的,其实别的类型也可以支持,获取他们对应的region。
2、根据action的原子性来判断走哪个方法,原子性操作走mutateRows,非原子性操作走doNonAtomicRegionMutation方法,我查了一下这个Atomic到底是怎么回事,我搜索了一下代码,发现在调用HTable的mutateRow方法的时候,它设置了Atomic为true,这个是应该是支持一行数据的原子性的,有这个需求的童鞋可以尝试用这个方法,也是可以提交多个,包括Put、Delete操作。
接下来看doNonAtomicRegionMutation()方法,用于处理非原子性的put/delete/get操作,这是我们常用的方式:


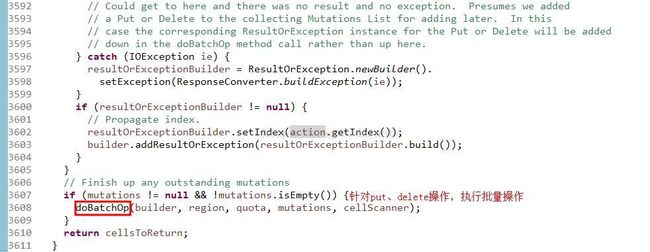
这里面代码很多,也适配了很多种类型,是个大而全的方法,但是我们这里用到的只是把Put、Delete等的类型转换添加到mutations的列表里,然后走最后的圈出的doBatchOp()这个批量操作,然而这个代码也比较长,简单说一下该方法的思路:
1、还是得把Put、Delete给转换类型,这里的批量操作只支持全是Delete或者全是Put。
2、用HRegion.batchMutate方法来执行操作,返回OperationStatus数组,记录每个action的状态,是成功,还是失败,或者是别的状态。
在batchMutate()里面首先就是检查是否是只读状态,然后检查是否是Meta Region的,是否执行MemStore检查了。




9、先异步添加日志,这里为什么是异步的,因为之前给上锁了,暂时不能读了。
10、释放之前创建的锁。

12、结束该批次的操作。