hadoop yarn
目录
- 前言
- hadoop 1.0 JobTracker
- 计算模型理解
- yarn( Yet Another Resource Negotiator)
- 对比 hadoop1.0 架构
- 知识
- 类比图理解架构
- 源码走读
- 任务提交/准备的流程图
- submitter.submitJobInternal(Job.this, Job.this.cluster)
- YARNRunner submitJob
- About the Cluster
- 单机版
- HA(High Available)
- 调度器/调度方法
前言
先看书,看视频,写demo,总结已有经验和学习;再进一步阅读源码,实践,加深对这一知识的认识;一个月 // TODO
核心思想:The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons.
hadoop 1.0 JobTracker
hadoop 1.0,图书《Hadoop技术内幕:深入理解MapReduce架构设计与实现原理》
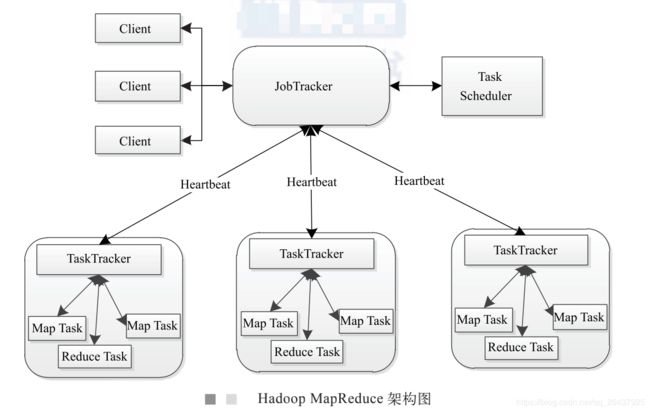
计算模型理解
- JobTracker
- 资源管理
- 任务调度
- TaskTracker
- 任务管理
- 资源汇报(心跳 JobTracker)
- 客户端(前期准备工作&计算的发起)
(MapReduce, jar)
- 根据计算数据,返回 split 清单(咨询Name Node 获取元数据),即得到了MapTask的数量,
计算向数据移动可以支持了 - 生成计算程序未来运行时的一些配置文件
- 客户端把准备的东西传到hdfs(这种数据移动是可靠的),未来TaskTracker去hdfs拉取要计算的数据
- 客户端调用JobTracker, 发起计算程序,并且准备的东西也告知了JobTracker
JobTracker & TaskTracker(对一个任务的运行)
- JobTracker收到启动程序之后: a. 获取到split 清单;b. 确定split计算分配给哪些个TaskTracker;c: 未来,心跳TaskTracker获取任务运行信息相关
- TaskTracker 心跳获取任务:从hdfs中获取配置文件到本机,然后启动MapTask 或者 ReduceTask (逻辑代码就在jar中)
多个任务发到JobTracker ?(单点)
- 资源管理
- 任务调度问题
缺点:
- JobTracker 存在单点故障;能力有限,扩容有限
- JobTracker 耦合了【资源管理和任务调度】,如果一个新的计算框架过来,则不能利用原来的资源管理了,不利于扩展
- TaskTracker端,以Map/Reduce task的数目作为资源的表示过于简单,没有考虑CPU,内存(即真正的计算资源)
- 只能运行MapReduce;TaskTracker端, 把资源强制划分为了Map task slot 和 Reduce task slot
yarn( Yet Another Resource Negotiator)
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
https://www.edureka.co/blog/hadoop-yarn-tutorial/
-
YARN enabled the users to perform operations as per requirement by using a variety of tools like Spark for real-time processing, Hive for SQL, HBase for NoSQL and others.
(yarn 能够让 spark, hive, hbase等数据处理任务调度运行起来,不单单只是MapReduce任务) -
架构图
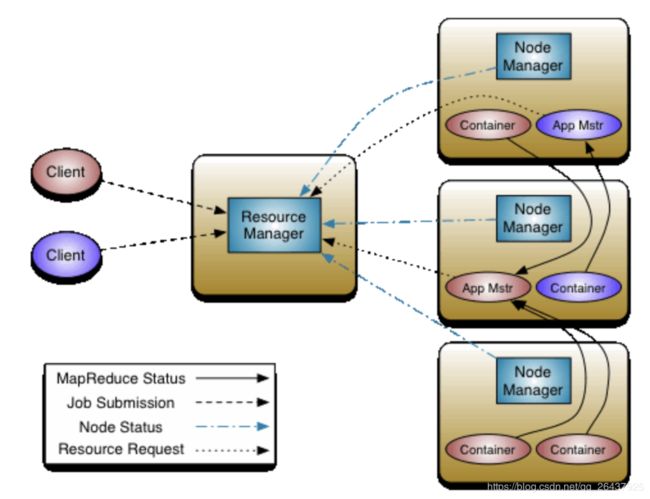
-
Resource Manager: Runs on a master daemon and manages the resource allocation in the cluster.
(处理客户端请求,负责集群资源的管理和调度) -
Node Manager: They run on the slave daemons and are responsible for the execution of a task on every single Data Node.
(负责自己所在节点的应用资源的使用情况,并向RM汇报。接收并处理来自RM,AM的各种命令) -
Application Master: Manages the user job lifecycle and resource needs of individual applications. It works along with the Node Manager and monitors the execution of tasks.
(每个application都对应一个AM. 主要负责应用程序的管理,向RM申请资源,并分配给task。AM与NM通信,来启动或停止task) -
Container: Package of resources including RAM, CPU, Network, HDD etc on a single node.
(封装了CPU,内存等资源的一个容器,相当于一个任务环境的抽象)
对比 hadoop1.0 架构
客户端变化不大, 做的事情相同;不过原来客户端联系JobTracker, 现在联系Resource Manager (独立的资源管理)
-
RM 知晓所有 NodeManager 的资源使用情况, 要执行计算的时候,RM会选择一个NodeManager来启动一个Application Master (即为客户端启动一个计算程序的主节点)
-
AM(类似原来的TaskTracker,但没有资源管理)来启动任务:仍然是根据客户端上传到HFDF的split清单,配置等; 且必须向 RM 申请资源,去哪些节点跑任务
-
AM 要处理任务,由RM来决策;RM 通信 NM 来计算资源,分配Container(计算资源的抽象); Container反向注册给AM,AM就知道有多少个container归自己使用
-
接着AM来分配MapTask, ReduceTask 到 container,即一个应用任务跑起来了
知识
- container 容器
- 资源抽象: cpu,内存,磁盘等的一个量,归属于某个Node Manager
- 物理上:一个JVM进程(a. NodeManager用线程监控container资源情况,比如资源使用超过,container 被 kill 掉;重试; b. 内核cgroup技术:在启动jvm进程,有kernel约束死)
- 新的框架
- ResourceManager 负责整体资源的管理
- NodeManager 心跳 RM,提交自己的资源使用情况
MapReduce 在 yarn 中运行 ?
- 客户端提交任务,仍然是jar,配置等上传到HDFS,要访问RM,去申请AppMaster
- RM会选择一个不忙的NodeManager启动一个container,在里面
反射一个MRAppMaster - 启动MRAppMaster,从HDFS下载splits相关,向RM申请资源
- RM来确定资源的使用,通知NM去启动container
- container启动后会反向注册到已经启动的MRAppMaster进程
- MRAppMaster会将任务发送给container(启动Map任务,Reduce任务)
- container会反射相应的Task为对象,调用执行,让业务代码跑起来
- Task失败有重试
类比图理解架构

-
客户端请求看成一个外界请求,比如需要造一个购物APP微信小程序
-
这些需求由Boss(RM角色)来接,决定怎么做,且Boss是拥有各种资源的
-
Boss 发现 某几个部门配合就能完成,找到 部门负责人; 部门负责人(NM角色)要负责自己部门的资源使用情况,同时要汇报Boss
-
部门负责人下面有项目经理(AM角色),来负责各种任务;为了完成任务,需要的各种资源,向RM申请就好了,当然也要通知NM
-
资源(可以任务是各种人员,设备之类的)即完成某个任务必备的(Container角色)
源码走读
当使用yarn的时候,我们在mapred-site.xml中配置了如下的实践版本:hadoop 2.7.2,当然还有别的配置)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
整个就是沿着job.waitForCompletion(true);这么简单的一句走下去
任务提交/准备的流程图

job.waitForCompletion(true)-> (Job)this.submit();->submitter.submitJobInternal(Job.this, Job.this.cluster)
submitter.submitJobInternal(Job.this, Job.this.cluster)
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
this.ensureState(Job.JobState.DEFINE);
this.setUseNewAPI();
this.connect();
final JobSubmitter submitter = this.getJobSubmitter(this.cluster.getFileSystem(), this.cluster.getClient());
this.status = (JobStatus)this.ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {
return submitter.submitJobInternal(Job.this, Job.this.cluster);
}
});
this.state = Job.JobState.RUNNING;
LOG.info("The url to track the job: " + this.getTrackingURL());
}
cluster new出来的时候执行了this.initialize(jobTrackAddr, conf);,其中ClientProtocol使用的YarnClientProtocolProvider的create方法
@Override
public ClientProtocol create(Configuration conf) throws IOException {
if (MRConfig.YARN_FRAMEWORK_NAME.equals(conf.get(MRConfig.FRAMEWORK_NAME))) {
return new YARNRunner(conf);
}
return null;
}
- submitJobInternal 大概做的几件事情
/**
* Internal method for submitting jobs to the system.
*
* The job submission process involves:
*
* -
* Checking the input and output specifications of the job. (检查任务的输入输出)
*
* -
* Computing the {@link InputSplit}s for the job.(计算任务的splits)
*
* -
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
*
* -
* Copying the job's jar and configuration to the map-reduce system (把任务的jar,配置等拷贝到hdfs中)
* directory on the distributed file-system.
*
* -
* Submitting the job to the
JobTracker and optionally (任务提交到JobTracker,并监控)
* monitoring it's status.
*
*
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
- 整个源码方法
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
// 生成JobId, 类似: `application_1517538889175_2550` 这种
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
// 把任务相关的文件,配置,jars上传
copyAndConfigureFiles(job, submitJobDir);
// 获取配置文件job.xml的路径
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// 输入文件的splits,配置信息写入job信息中, map数量也即splits数量
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// 设置job使用的资源队列
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
// submitClient.submitJob 真正提交作业
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
YARNRunner submitJob

@Override
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
addHistoryToken(ts);
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);
String diagnostics =
(appMaster == null ?
"application report is null" : appMaster.getDiagnostics());
if (appMaster == null
|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED
|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {
throw new IOException("Failed to run job : " +
diagnostics);
}
return clientCache.getClient(jobId).getJobStatus(jobId);
} catch (YarnException e) {
throw new IOException(e);
}
}
/**
* {@code ApplicationSubmissionContext} represents all of the
* information needed by the {@code ResourceManager} to launch
* the {@code ApplicationMaster} for an application.
*
* It includes details such as:
*
* - {@link ApplicationId} of the application.
* - Application user.
* - Application name.
* - {@link Priority} of the application.
* -
* {@link ContainerLaunchContext} of the container in which the
*
ApplicationMaster is executed.
*
* -
* maxAppAttempts. The maximum number of application attempts.
* It should be no larger than the global number of max attempts in the
* YARN configuration.
*
* -
* attemptFailuresValidityInterval. The default value is -1.
* when attemptFailuresValidityInterval in milliseconds is set to
* {@literal >} 0, the failure number will no take failures which happen
* out of the validityInterval into failure count. If failure count
* reaches to maxAppAttempts, the application will be failed.
*
* - Optional, application-specific {@link LogAggregationContext}
*
*
* @see ContainerLaunchContext
* @see ApplicationClientProtocol#submitApplication(org.apache.hadoop.yarn.api.protocolrecords.SubmitApplicationRequest)
*/
@Public
@Stable
public abstract class ApplicationSubmissionContext {
About the Cluster
单机版
- 集群描述

- 节点
- 所有的任务
HA(High Available)
主备模式:一个主RM,另外的备用RM(平时主RM干事情,备用RM基本废物;如果有问题,备用RM会切换成主RM, 依靠zk心跳和选举)【学过druid.io,与druid.io的coordinator 和 overlord类似 】
调度器/调度方法
- FIFO Scheduler
- Capacity Scheduler
- FairScheduler
调度这个事情,太多地方有了, 还是得按照实际业务需求自定义一些:多业务线,多策略。
eg: 进程调度算法,有类似如下
- 先来先服务调度算法FCFS
- 短作业(进程)优先调度算法SJF(非抢占)/SPF(抢占)
- 高响应比优先调度算法HRRN
- 优先权高者优先(HPF)
- 基于时间片的轮转调度算法RR
eg: druid.io middle 分配策略
- Equal Distribution
- Fill Capacity
- JavaScript