每天3个面试题精研 - 前端 - 第7-9天
目录
- 29JavaScript 中的循环遍历方法
- 28数据存储
- 27简述下你理解的面向对象?
- 26TCP和UDP的区别以及tcp3次握手和4次挥手。
- 25说说position,display
- 24盒子模型
- 23非构造函数的继承
- 22构造函数的继承
- 21封装
29JavaScript 中的循环遍历方法
1、for 循环
2、for in 循环 - 遍历普通对象
let obj = {
name:'lxf',
age:24
}
for(let i in obj){
console.log(i,obj[i]);
}
for in 循环主要用于遍历普通对象,i 代表对象的 key 值,obj[i] 代表对应的 value,当用它来遍历数组时候,多数情况下也能达到同样的效果,但是你不要这么做,这是有风险的,因为 i 输出为字符串形式,而不是数组需要的数字下标,这意味着在某些情况下,会发生字符串运算,导致数据错误,比如:‘52’+1 = ‘521’ 而不是我们需要的 53。
另外 for in 循环的时候,不仅遍历自身的属性,还会找到 prototype 上去,所以最好在循环体内加一个判断,就用 obj[i].hasOwnProperty(i),这样就避免遍历出太多不需要的属性。
3、while 循环 - 遍历数组
cars=["BMW","Volvo","Saab","Ford"];
var i=0;
while (cars[i])
{
console.log(cars[i])
i++;
};
white循环类型for循环
4、do while 循环 - 遍历数组
cars=["BMW","Volvo","Saab","Ford"];
var i=0;
do{
console.log(cars[i]);
i++;
}while(cars[i]);
do while 循环是 while 循环的一个变体,它首先执行一次操作,然后才进行条件判断,是 true 的话再继续执行操作,是 false 的话循环结束。
5、Array forEach 循环 - 遍历数组
let arr = [1,2,3];
arr.forEach(function(i,index){
console.log(i,index)
})
// 1 0
// 2 1
// 3 2
forEach循环,循环数组中每一个元素并采取操作, 没有返回值, 可以不用知道数组长度,他有三个参数,只有第一个是必需的,代表当前下标下的 value。
另外请注意,forEach 循环在所有元素调用完毕之前是不能停止的,它没有 break 语句,如果你必须要停止,可以尝试 try catch 语句,就是在要强制退出的时候,抛出一个 error 给 catch 捕捉到,然后在 catch 里面 return,这样就能中止循环了,如果你经常用这个方法,最好自定义一个这样的 forEach 函数在你的库里。
6、Array map()方法 - 数组
let arr = [1,2,3];
let tt = arr.map(function(i){
console.log(i) //1,2,3
return i*2;
})
console.log(tt);// [2,4,6]
map() 方法返回一个新数组,数组中的元素为原始数组元素调用函数处理后的值。
注意:map 和 forEach 方法都是只能用来遍历数组,不能用来遍历普通对象。
7、Array filter() 方法(过滤) - 数组
let arr = [1,2,3];
let tt = arr.filter(function(i){
return i>1;
})
console.log(tt);// [2,3]
filter 方法是 Array 对象内置方法,它会返回通过过滤的元素,不改变原来的数组。
8、Array some() 方法 - 数组
let arr = [1,2,3];
let tt = arr.some(function(i){
return i>2;
})
console.log(tt);// true,只要有一个元素符合即true,否则为false
some() 方法用于检测数组中的元素是否满足指定条件(函数提供),返回 boolean 值,不改变原数组。
9、Array every() 方法 - 数组
let arr = [1,2,3];
let tt = arr.every(function(i){
return i>1;
})
console.log(tt);// false
// 检测数组中元素是否都大于1
every() 方法用于检测数组所有元素是否都符合指定条件(通过函数提供),返回 boolean 值,不改变原数组。
10、Array reduce()方法 - 数组
let arr = [1,2,3];
let ad = arr.reduce(function(i,j){
return i+j;
})
console.log(ad);// 6
reduce() 方法接收一个函数作为累计操作计,数组中的每个值(从左到右)开始缩减,最终计算为一个值。
11、Array reduceRight()方法 - 数组
let arr = [1,2,3];
let ad = arr.reduceRight(function(i,j){
return i+j;
})
console.log(ad);
// 6
reduceRight()方法,和 reduce() 功能是一样的,它是从数组的末尾处向前开始计算。
12、for of 循环 - 数组和对象等均可 - 具有较好兼容性,主推使用
let arr = ['name','age'];
for(let i of arr){
console.log(i)
}
// name
// age
for of 循环是 Es6 中新增的语句,用来替代 for in 和 forEach,它允许你遍历 Arrays(数组), Strings(字符串), Maps(映射), Sets(集合)等可迭代(Iterable data)的数据结构,注意它的兼容性。
注意:2个循环对象的操作的区别:
for in
- 一般用于遍历对象的可枚举属性。以及对象从构造函数原型中继承的属性。对于每个不同的属性,语句都会被执行。
- 不建议使用for in 遍历数组,因为输出的顺序是不固定的。
- 如果迭代的对象的变量值是null或者undefined, for in不执行循环体,建议在使用for
in循环之前,先检查该对象的值是不是null或者undefined
for of
- for…of 语句在可迭代对象(包括 Array,Map,Set,String,TypedArray,arguments
对象等等)上创建一个迭代循环,调用自定义迭代钩子,并为每个不同属性的值执行语句
28数据存储
sessionStorage(会话存储) 、localStorage(本地存储) 和 cookie 之间的共同点:
都是保存在浏览器端,且同源的。(同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。如果两个页面的协议,端口(如果有指定)和主机都相同,则两个页面具有相同的源。)
sessionStorage 、localStorage 和 cookie 之间的区别:
1cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递。而sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下。
2存储大小限制也不同,cookie数据不能超过4k,同时因为每次http请求都会携带cookie,所以cookie只适合保存很小的数据,如会话标识。sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
3数据有效期不同,sessionStorage:仅在当前浏览器窗口关闭前有效,自然也就不可能持久保持;localStorage:始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;cookie只在设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭。
4作用域不同,sessionStorage不在不同的浏览器窗口中共享,即使是同一个页面;localStorage 在所有同源窗口中都是共享的;cookie也是在所有同源窗口中都是共享的。
27简述下你理解的面向对象?
万物皆对象,把一个对象抽象成类,具体上就是把一个对象的静态特征和动态特征抽象成属性和方法,也就是把一类事物的算法和数据结构封装在一个类之中,程序就是多个对象和互相之间的通信组成的。面向对象具有封装性,继承性,多态性。
封装:隐蔽了对象内部不需要暴露的细节,使得内部细节的变动跟外界脱离,只依靠接口进行通信.封装性降低了编程的复杂性. 通过继承,使得新建一个类变得容易,一个类从派生类那里获得其非私有的方法和公用属性的繁琐工作交给了编译器. 而继承和实现接口和运行时的类型绑定机制 所产生的多态,使得不同的类所产生的对象能够对相同的消息作出不同的反应,极大地提高了代码的通用性。
总之,面向对象的特性提高了大型程序的重用性和可维护性。
JS的对象组成:方法 和 属性
+解释构造函数,工厂模型,原型链全面介绍面向对象。
26TCP和UDP的区别以及tcp3次握手和4次挥手。
TCP(Transmission Control Protocol) 是传输控制协议,提供的是面向连接、可靠的数据流传输。当客户端和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能顺序地从一端传到另一端。TCP传输数据就像打电话,你必须知道对方的电话号码,电话打通之后才能进行对话,先说的话先到,后说的话后到,是有顺序的。对方没听清你的说的话时你可以重说一遍。
UDP(User Datagram Protocol)是用户数据报协议,提供的是非面向连接的、不可靠的数据流传输。它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。UDP在传输数据前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,不保证数据按顺序传递,故而传输速度很快。UDP传输数据就像寄一封信,发信的人只管发,不管到,但必须在信封上写明对方的地址。发信者和收信者不需要建立连接,全靠邮电局联系,信发到是可能已经过了很久了,也可能根本没发到。先发的信件未必先到,后发的信件也未必后到。
TCP一般用于文件传输(ftp http 对数据准确性要求高,速度可以相对慢),发送或接收邮件(pop imap smtp 对数据准确性要求高,非紧急应用),远程登录(telnet ssh 对数据准确性有一定要求,有连接的概念)等等;UDP一般用于即时通信(qq聊天 对数据准确性和丢包要求比较低,但速度必须快)

三次握手:建立连接
建立连接时,客户端发送SYN包到到服务器,服务器收到SYN包时,向客户端发送ACK包,同时发送一个自己的SYN包,客户端收到服务器的SYN+ACK包后向服务器发送ACK这样就建立三次握手连接。
四次挥手:断开连接
断开连接可以是客户端发起,也可以是服务器端发起。假设客户端发起中断连接请求。客户端首先发送FIN报文给服务器端,表示客户端这边已完成发送数据的任务。服务器接到FIN报文后,如何此时服务器端还有数据没有发送完成,可以继续发送数据,所以服务器先发送ACK包给客户端。 当服务器端确定数据已经发送完成,则向客户端发送FIN 报文,告诉客户端,服务器这边数据发送完了。 客户端接收到FIN报文后,就知道可以断开连接了。但是他还是不相信网络,所以发送ACK包给服务器进入TIME_WAIT状态,服务器端收到ACK后就断开连接了。 客户端在等待了一段时间后没有收到来自服务器的回复,则证明,服务器端已经正常关闭,最后客户端关闭连接,最终完成了4次挥手的断开连接。
SYN:同步序列编号(Synchronize Sequence Numbers)。是TCP/IP建立连接时使用的握手信号。
ACK (Acknowledgement):即是确认字符,在数据通信中,接收站发给发送站的一种传输类控制字符。表示发来的数据已确认接收无误。
FIN(ISH):为TCP报头的码位字段,该位置为1的含义为发送方字节流结束,用于关闭连接。
25说说position,display
1、display属性的值与作用
常用的值有none、inline、block、inline-block
none
1)表示该元素不会显示,并且该元素的空间也不存在,可理解为已删除;
2)visibility:hidden只是将元素隐藏,但不会改变页面布局,但也不会触发该元素已经绑定的事件;
3)opacity:0,将元素隐藏,不会改变页面布局,但会触发该元素绑定的事件。
inline
1)内联元素,与其他元素在一行;
2)不可设置宽高;
3)margin-top与margin-bottom无效,但margin-left与margin-right有效;
4)padding-left与padding-right同样有效,但是padding-top与padding-bottom不会影响元素高度,会影 响背景高度;
5)常见的有、、
、、、。
block
块级元素,常见的有、、
...、、、
inline-block
1)行内块元素,即是内联元素,又可设置宽高以及行高及顶和底边距;
2)常见的有![]() 、。
、。
2.position属性的值和作用
position属性有四个可选值,分别为static、relative、absolute、fixed。
static
默认值,元素出现在正常的文档流中,不会受left、top、right、bottom的影响。
relative
相对定位,相对自身位置定位,可通过设置left、top、right、bottom的值来设置位置;
并且它原本所占的空间不变,即不会影响其他元素布局;
经常被用来作绝对元素的容器块。
absolute
绝对定位,相对于最近的除static定位以外的元素定位,若没有,则相对于html定位;
脱离了文档流,不占据文档空间;
若设置absolute,但没有设置top、left等值,其位置不变;
若设置absolute,会影响未定义宽度的块级元素,使其变为包裹元素内容的宽度。
fixed
固定定位 相对于浏览器窗口定位,脱离文档流,不会随页面滚动而变化。
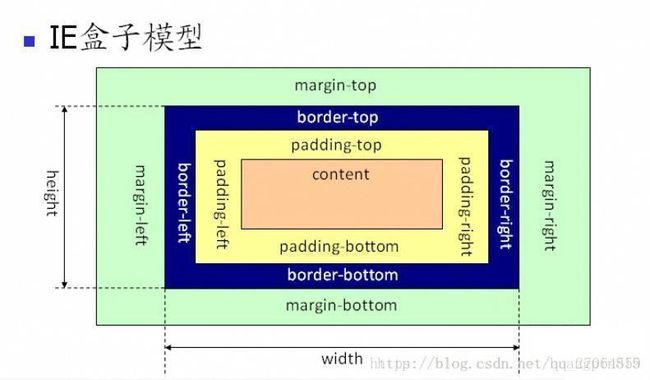
24盒子模型
盒子模型(分2个而已嘛):IE盒子模型(怪异盒模型)和W3C盒子模型
相关box-sizing的属性。
box-sizing: border-box;
width = content+padding+border (横向相关)
box-sizing: content-box;
width = content (横向相关)
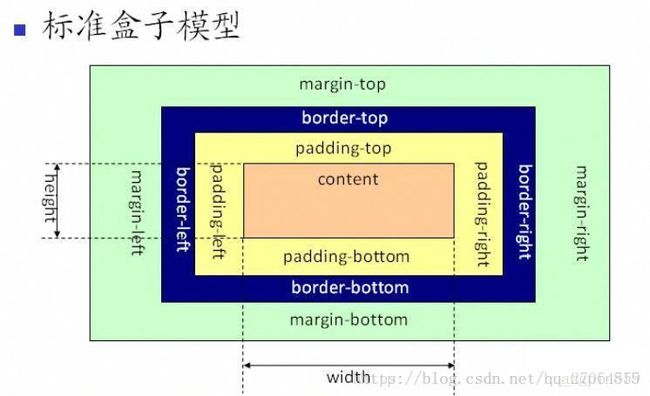
这两个模型的唯一区别是计算width和height时,IE盒子模型包含padding和border, W3C盒子模型则不包括。
放个测试demo,没效果来砍我
html:
111
css:
.box {
box-sizing: border-box;
/*box-sizing: content-box;*/ /*切换看看就知道2个的区别*/
height: 30px;
width: 70px;
margin: 10px;
padding: 5px;
background-color: yellowgreen;
}
为了使页面在不同浏览器下呈现相同的效果,必须统一盒子模型,因为设置width或者height一般是必须用到的。
那么必须设置浏览器的渲染模式是标准模式,在标准模式下,IE6+和其他现代浏览器会以W3C盒子模型渲染。(在怪异模式下,IE中只有IE9+会用W3C盒子模型。
常用下语句规范整个页面的盒子
*{box-sizing:border-box;}
23非构造函数的继承
一、什么是"非构造函数"的继承?
比如,现在有一个对象,叫做"中国人"。
var Chinese = {
nation:'中国'
};
还有一个对象,叫做"医生"。
var Doctor ={
career:'医生'
}
请问怎样才能让"医生"去继承"中国人",也就是说,我怎样才能生成一个"中国医生"的对象?
这里要注意,这两个对象都是普通对象,不是构造函数,无法使用构造函数方法实现"继承"。
二、object()方法
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
这个object()函数,其实只做一件事,就是把子对象的prototype属性,指向父对象,从而使得子对象与父对象连在一起。
使用的时候,第一步先在父对象的基础上,生成子对象:
var Doctor = object(Chinese);
然后,再加上子对象本身的属性:
Doctor.career = '医生';
这时,子对象已经继承了父对象的属性了。
alert(Doctor.nation); //中国
三、浅拷贝
除了使用"prototype链"以外,还有另一种思路:把父对象的属性,全部拷贝给子对象,也能实现继承。
var Chinese = {
nation:'中国'
};
var Doctor ={
career:'医生'
}
function extendCopy(p) {
var c = {};
for (var i in p) {
c[i] = p[i];
}
c.uber = p;
return c;
}
//使用的时候,这样写:
var Doctor = extendCopy(Chinese);
Doctor.career = '医生';
alert(Doctor.nation); // 中国
但是,这样的拷贝有一个问题。那就是,如果父对象的属性等于数组或另一个对象,那么实际上,子对象获得的只是一个内存地址,而不是真正拷贝,因此存在父对象被篡改的可能。
Chinese.birthPlaces = ['北京','上海','香港'];
var Doctor = extendCopy(Chinese); //虽然上面已经继承过了,但此时不能省,否则报错找不到birthPlaces属性
Doctor.birthPlaces.push('厦门');
alert(Doctor.birthPlaces); //北京, 上海, 香港, 厦门
alert(Chinese.birthPlaces); //北京, 上海, 香港, 厦门
所以,extendCopy()只是拷贝基本类型的数据,我们把这种拷贝叫做"浅拷贝"。这是早期jQuery实现继承的方式。
四、深拷贝
所谓"深拷贝",就是能够实现真正意义上的数组和对象的拷贝。它的实现并不难,只要递归调用"浅拷贝"就行了。
var Chinese = {
nation: '中国',
add:function(){
console.log(888);
}
}
var Doctor = {
career: '医生'
}
function deepCopy(p, c) {
var c = c || {};
for (var i in p) {
if (typeof p[i] == 'object') {
c[i] = (p[i].constructor == Array ? [] : {});
deepCopy(p[i], c[i]);
} else {
c[i] = p[i];
}
}
return c;
}
Chinese.birthPlaces = ['北京', '上海', '香港'];
var Doctor = deepCopy(Chinese);
Doctor.birthPlaces.push('厦门');
console.log(Doctor.birthPlaces); //北京, 上海, 香港, 厦门
console.log(Chinese.birthPlaces); //北京, 上海, 香港
console.log(Doctor);
console.log(Chinese);
Doctor.add(); //888
目前,jQuery库使用的就是这种继承方法。
22构造函数的继承
一、 构造函数绑定
第一种方法也是最简单的方法,使用call(后面可带多个单参数)或apply(只能带2个参数,后面参数必须数组Array)方法,将父对象的构造函数绑定在子对象上,即在子对象构造函数中加一行:
function Father(countryName) {
this.country = countryName;
}
//使用call继承,后面可带多个单参数
// function Son(countryName) {
// Father.call(this, countryName);
// this.name = 'lxf';
// }
//使用apply继承,只能带2个参数,后面参数要数组Array
function Son(countryName){
Father.apply(this,[countryName]);
this.name = 'lxf';
}
var son1 = new Son('china')
console.log(son1.country);//china
二、 prototype模式
第二种方法更常见,使用prototype属性。
function Animal(){
this.species = "动物";
}
function Cat(name,color){
this.name = name;
this.color = color;
}
Cat.prototype = new Animal(); //我们将Cat的prototype对象指向一个Animal的实例。
Cat.prototype.constructor = Cat; //不加会导致继承链的紊乱(cat1明明是用构造函数Cat生成的),因此我们必须手动纠正,将Cat.prototype对象的constructor值改为Cat。将这个属性指回原来的构造函数。
var cat1 = new Cat("大毛","黄色");
alert(cat1.species); // 动物
三、 直接继承prototype
第三种方法是对第二种方法的改进。由于Animal对象中,不变的属性都可以直接写入Animal.prototype。所以,我们也可以让Cat()跳过 Animal(),直接继承Animal.prototype。
function Animal(){ }
Animal.prototype.species = "动物";
function Cat(name,color){
this.name = name;
this.color = color;
}
Cat.prototype = Animal.prototype;
Cat.prototype.constructor = Cat;
var cat1 = new Cat('lxf','red');
console.log(cat1.species);
console.log(Animal.prototype.constructor); //Cat
与前一种方法相比,这样做的优点是效率比较高(不用执行和建立Animal的实例了),比较省内存。缺点是 Cat.prototype和Animal.prototype现在指向了同一个对象,那么任何对Cat.prototype的修改,都会反映到Animal.prototype。
所以,上面这一段代码其实是有问题的。请看第二行
Cat.prototype.constructor = Cat;
这一句实际上把Animal.prototype对象的constructor属性也改掉了!
alert(Animal.prototype.constructor); // Cat
四、 利用空对象作为中介
由于"直接继承prototype"存在上述的缺点,所以就有第四种方法,利用一个空对象作为中介。
function Animal(){ }
Animal.prototype.species = "动物";
function Cat(name,color){
this.name = name;
this.color = color;
}
//F是空对象,所以几乎不占内存。这时,修改Cat的prototype对象,就不会影响到Animal的prototype对象。
var F = function(){};
F.prototype = Animal.prototype;
Cat.prototype = new F();
Cat.prototype.constructor = Cat;
alert(Animal.prototype.constructor); // Animal
我们将上面的方法,封装成一个函数,便于使用。
function Animal(){ }
Animal.prototype.species = "动物";
function Cat(name,color){
this.name = name;
this.color = color;
}
function extend(Child, Parent) {
var F = function(){};
F.prototype = Parent.prototype;
Child.prototype = new F();
//指向后不加会丢失constructor属性,造成错误
Child.prototype.constructor = Child;
Child.uber = Parent.prototype;
}
extend(Cat,Animal);
var cat1 = new Cat("大毛","黄色");
alert(cat1.species); // 动物
这个extend函数,就是YUI库如何实现继承的方法。
另外,说明一点,函数体最后一行
Child.uber = Parent.prototype;
意思是为子对象设一个uber属性,这个属性直接指向父对象的prototype属性。(uber是一个德语词,意思是"向上"、“上一层”。)这等于在子对象上打开一条通道,可以直接调用父对象的方法。这一行放在这里,只是为了实现继承的完备性,纯属备用性质。
五、 拷贝继承(此例子只可继承prototype的属性和方法
上面是采用prototype对象,实现继承。我们也可以换一种思路,纯粹采用"拷贝"方法实现继承。简单说,如果把父对象的所有属性和方法,拷贝进子对象,不也能够实现继承吗?这样我们就有了第五种方法。
function Animal(){ }
Animal.prototype.species = "动物";
function Cat(name,color){
this.name = name;
this.color = color;
}
function extend2(Child, Parent) { //这个函数的作用,就是将父对象的prototype对象中的属性,一一拷贝给Child对象的prototype对象。
var p = Parent.prototype;
var c = Child.prototype;
for (var i in p) {
c[i] = p[i];
}
c.uber = p;
}
extend2(Cat, Animal);
var cat1 = new Cat("大毛","黄色");
alert(cat1.species); // 动物
21封装
封装,即隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别
把"属性"(property)和"方法"(method),封装成一个对象,甚至要从原型对象生成一个实例对象,我们应该怎么做呢?
一、 生成实例对象的原始模式
假定我们把猫看成一个对象,它有"名字"和"颜色"两个属性。
var Cat = {
name : '',
color : ''
}
现在,我们需要根据这个原型对象的规格(schema),生成两个实例对象。
var cat1 = {}; // 创建一个空对象
cat1.name = "大毛"; // 按照原型对象的属性赋值
cat1.color = "黄色";
var cat2 = {};
cat2.name = "二毛";
cat2.color = "黑色";
这就是最简单的封装了,把两个属性封装在一个对象里面。但是,这样的写法有两个缺点,一是如果多生成几个实例,写起来就非常麻烦;二是实例与原型之间,没有任何办法,可以看出有什么联系。
二、 原始模式的改进
我们可以写一个函数,解决代码重复的问题。
function Cat(name,color) {
return {
name:name,
color:color
}
}
然后生成实例对象,就等于是在调用函数:
var cat1 = Cat("大毛","黄色");
var cat2 = Cat("二毛","黑色");
这种方法的问题依然是,cat1和cat2之间没有内在的联系,不能反映出它们是同一个原型对象的实例。
三、 构造函数模式
为了解决从原型对象生成实例的问题,Javascript提供了一个构造函数(Constructor)模式。
所谓"构造函数",其实就是一个普通函数,但是内部使用了this变量。对构造函数使用new运算符,就能生成实例,并且this变量会绑定在实例对象上。
比如,猫的原型对象现在可以这样写
function Cat(name,color){
this.name=name;
this.color=color;
}
我们现在就可以生成实例对象了。
var cat1 = new Cat("大毛","黄色");
var cat2 = new Cat("二毛","黑色");
alert(cat1.name); // 大毛
alert(cat1.color); // 黄色
这时cat1和cat2会自动含有一个constructor属性,指向它们的构造函数。
alert(cat1.constructor == Cat); //true
alert(cat2.constructor == Cat); //true
Javascript还提供了一个instanceof运算符,验证原型对象与实例对象之间的关系。
alert(cat1 instanceof Cat); //true
alert(cat2 instanceof Cat); //true
四、构造函数模式的问题
构造函数方法很好用,但是存在一个浪费内存的问题。
请看,我们现在为Cat对象添加一个不变的属性type(种类),再添加一个方法eat(吃)。那么,原型对象Cat就变成了下面这样:
function Cat(name,color){
this.name = name;
this.color = color;
this.type = "猫科动物";
this.eat = function(){alert("吃老鼠");};
}
还是采用同样的方法,生成实例:
var cat1 = new Cat("大毛","黄色");
var cat2 = new Cat ("二毛","黑色");
alert(cat1.type); // 猫科动物
cat1.eat(); // 吃老鼠
表面上好像没什么问题,但是实际上这样做,有一个很大的弊端。那就是对于每一个实例对象,type属性和eat()方法都是一模一样的内容,每一次生成一个实例,都必须为重复的内容,多占用一些内存。这样既不环保,也缺乏效率。
alert(cat1.eat == cat2.eat); //false
能不能让type属性和eat()方法在内存中只生成一次,然后所有实例都指向那个内存地址呢?回答是可以的。
五、 Prototype模式
Javascript规定,每一个构造函数都有一个prototype属性,指向另一个对象。这个对象的所有属性和方法,都会被构造函数的实例继承。
这意味着,我们可以把那些不变的属性和方法,直接定义在prototype对象上。
function Cat(name,color){
this.name = name;
this.color = color;
}
Cat.prototype.type = "猫科动物";
Cat.prototype.eat = function(){alert("吃老鼠")};
然后,生成实例。
var cat1 = new Cat("大毛","黄色");
var cat2 = new Cat("二毛","黑色");
alert(cat1.type); // 猫科动物
cat1.eat(); // 吃老鼠
这时所有实例的type属性和eat()方法,其实都是同一个内存地址,指向prototype对象,因此就提高了运行效率。
alert(cat1.eat == cat2.eat); //true
六、 Prototype模式的验证方法
为了配合prototype属性,Javascript定义了一些辅助方法,帮助我们使用它。,
6.1 isPrototypeOf()
这个方法用来判断,某个proptotype对象和某个实例之间的关系。
alert(Cat.prototype.isPrototypeOf(cat1)); //true
alert(Cat.prototype.isPrototypeOf(cat2)); //true
6.2 hasOwnProperty()
每个实例对象都有一个hasOwnProperty()方法,用来判断某一个属性到底是本地属性,还是继承自prototype对象的属性。
alert(cat1.hasOwnProperty("name")); // true
alert(cat1.hasOwnProperty("type")); // false
6.3 in运算符
in运算符可以用来判断,某个实例是否含有某个属性,不管是不是本地属性。
alert("name" in cat1); // true
alert("type" in cat1); // true
in运算符还可以用来遍历某个对象的所有属性。
for(var prop in cat1) { alert("cat1["+prop+"]="+cat1[prop]); }