【PTM】ELMo:通过预训练语言模型生成词向量
今天学习的是 AllenNLP 和华盛顿大学 2018 年的论文《Deep contextualized word representations》,是 NAACL 2018 best paper。
这篇论文提出的 ELMo 模型是 2013 年以来 Embedding 领域非常精彩的转折点,并在 2018 年及以后的很长一段时间里掀起了迁移学习在 NLP 领域的风潮。
ELMo 是一种基于语境的深度词表示模型(Word Representation Model),它可以捕获单词的复杂特征(词性句法),也可以解决同一个单词在不同语境下的不同表示(语义)。
ELMo 本身思想不难,但是很多细节在论文中都没有给出,而是给出其他论文的引用,大大增加了阅读难度。翻阅了很多博客但是写得好的没几篇,大部分博客都只是介绍了 ELMo 的多层双向 LSTM 结构,而忽视其预训练方式和使用方式。
本文在书写过程中尽量涵盖一些我认为很重要的一些细节,也希望抛砖引玉得到大佬们更详细的见解。
1. Introduction
以 Word2Vec 和 GloVe 为代表的词表示模型通过训练为每个单词训练出固定大小的词向量,这在以往的 NLP 任务中都取得了不错的效果,但是他们都存在两个问题:
- 没法处理复杂的单词用法,即语法问题;
- 没办法结合语境给出正确词向量,即一词多义;
为了解决这个问题,作者提出了一个新的深层语境词表示模型——ELMo。
区别于传统模型生成的固定单词映射表的形式(为每个单词生成一个固定的词向量),ELMo使用了预训练的语言模型(Language Model),模型会扫面句子结构,并更新内部状态,从而为句子中的每个单词都生成一个基于当前的句子的词向量(Embedding)。这也是就是 ELMo 取名的由来:Embeddings from Language Models。
此外,ELMo 采用字符级的多层 BI-LM 模型作为语言模型,高层的 LSTM 能够捕获基于语境的词特征(例如主题情感),而低层的 LSTM 可以学到语法层次的信息(例如词性句法),前者可以处理一词多义,后者可以被用作词性标注,作者通过线性组合多层 LSTM 的内部状态来丰富单词的表示。
2. ELMo
ELMo 是一种称为 Bi-LM 的特殊类型的语言模型,它是两个方向上的 LM 的组合,如下图所示:
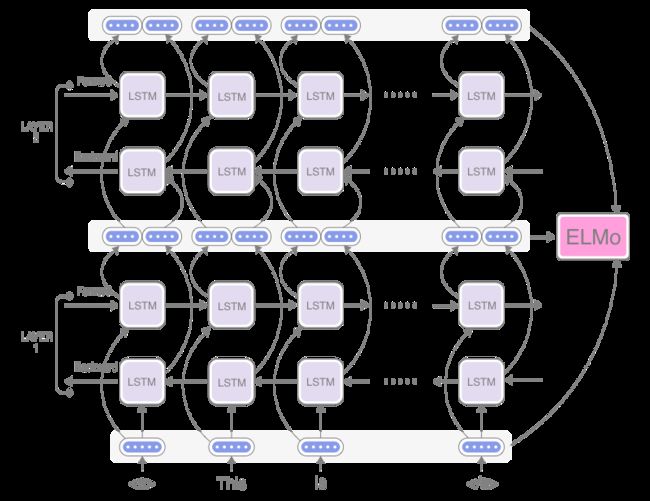
ELMo 利用正向和反向扫描句子计算单词的词向量,并通过级联的方式产生一个中间向量(下面会给出具体的级联方式)。通过这种方式得到的词向量可以捕获到当前句子的结构和该单词的使用方式。
值得注意是,ELMo 使用的 Bi-LM 与 Bi-LSTM 不同,虽然长得相似,但是 Bi-LM 是两个 LM 模型的串联,一个向前,一个向后;而 Bi-LSTM 不仅仅是两个 LSTM 串联,Bi-LSTM 模型中来自两个方向的内部状态在被送到下层时进行级联(注意下图的 out 部分,在 out 中进行级联),而在 Bi-LM 中,两个方向的内部状态仅从两个独立训练的 LM 中进行级联。
2.1 Bi-LM
设一个序列有 N 个 token ( t 1 , t 2 , . . . , t N ) (t_1,t_2,...,t_N) (t1,t2,...,tN) (这里说 token 是为了兼容字符和单词,EMLo 使用的是字符级别的 Embedding)
对于一个前向语言模型来说,是基于先前的序列来预测当前 token:
p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . , t k − 1 ) p (t_1 ,t_2 ,...,t_N )=\prod_{k=1}^{N}{p( t_k|t_1 ,t_2 ,...,t_{k-1} )} \\ p(t1,t2,...,tN)=k=1∏Np(tk∣t1,t2,...,tk−1)
而对于一个后向语言模型来说,是基于后面的序列来预测当前 token:
p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) p (t_1 ,t_2 ,...,t_N )=\prod_{k=1}^{N}{p( t_k|t_{k+1} ,t_{k+2} ,...,t_{N} )}\\ p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,tk+2,...,tN)
可以用 h k , j → \overrightarrow{h_{k,j}} hk,j 和 h k , j ← \overleftarrow{h_{k,j}} hk,j 分别表示前向和后向语言模型。
ELMo 用的是多层双向的 LSTM,所以我们联合前向模型和后向模型给出对数似然估计:
∑ k = 1 N ( log p ( t k ∣ t 1 , . . . , t k − 1 ; Θ x , Θ → L S T M , Θ s ) + log p ( t k ∣ t k + 1 , . . . , t N ; Θ x , Θ ← L S T M , Θ s ) ) \sum_{k=1}^{N}(\log p(t_k | t_1,...,t_{k-1}; \Theta_x, \overrightarrow{\Theta}_{LSTM},\Theta_s) + \log p(t_k | t_{k+1},...,t_{N}; \Theta_x, \overleftarrow{\Theta}_{LSTM},\Theta_s)) \\ k=1∑N(logp(tk∣t1,...,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,...,tN;Θx,ΘLSTM,Θs))
其中, Θ x \Theta_x Θx 表示 token 的向量, Θ s \Theta_s Θs 表示 Softmax 层对的参数, Θ → L S T M \overrightarrow{\Theta}_{LSTM} ΘLSTM 和 Θ ← L S T M \overleftarrow{\Theta}_{LSTM} ΘLSTM 表示前向和后向的 LSTM 的参数。
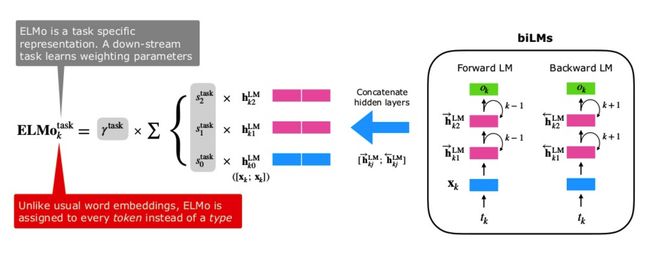
我们刚说 ELMo 通过级联的方式给出中间向量(这边要注意两个地方:一个是级联,一个是中间向量),现在给出符号定义:
对每一个 token t k t_k tk 来说,一个 L 层的 ELMo 的 2L + 1 个表征:
R k = { x k L M , h k , j → , h k , j ← ∣ j = 1 , . . , L } = { h k , j ∣ j = 0 , . . . , L } R_k=\{x_k^{LM},\overrightarrow{h_{k,j}},\overleftarrow{h_{k,j}} | j=1,..,L\} \\ =\{h_{k,j}| j=0,...,L\}\\ Rk={xkLM,hk,j,hk,j∣j=1,..,L}={hk,j∣j=0,...,L}
其中, h k , 0 h_{k,0} hk,0 表示输入层, h k , j = [ h k , j → ; h k , j ← ] h_{k,j} = [\overrightarrow{h_{k,j}}; \overleftarrow{h_{k,j}}] hk,j=[hk,j;hk,j] 。(之所以是 2L + 1 是因为把输入层加了进来)
对于下游任务来说,ELMo 会将所有的表征加权合并为一个中间向量:
E L M o k = E ( R k ; Θ ) = γ ∑ j = 0 L s j h k , j L M ELMo_k=E(R_k;\Theta) = \gamma\sum_{j=0}^{L}s_jh_{k,j}^{LM} \\ ELMok=E(Rk;Θ)=γj=0∑Lsjhk,jLM
其中, s s s 是 Softmax 的结果,用作权重; γ \gamma γ 是常量参数,允许模型缩放整个 ELMo 向量,考虑到各个 Bi-LSTM 层分布不同,某些情况下对网络的 Layer Normalization 会有帮助。
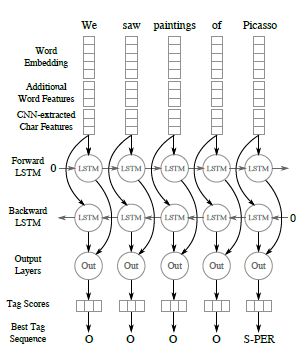
2.2 Supervised NLP task
我们来看下 ELMo 在有监督学习中应用,这里假设 ELMo 模型已经完成预训练。
对于给定的一个监督学习 NLP 任务,我们只需为每个句子中的单词记录下 ELMo 各层的词表征,然后用端到端的任务来学习这些表示的线性组合(学习向量的权重)。
对于大多数 NLP 任务而言,靠近输入端的结构所含信息基本一致(例如词法句法,想象下 CV 浅层网络的可视化都是一些线条),所以这就允许我们直接把训练好的 ELMo 加到现有的 NLP 的监督任务模型中(因为底层结构相似,所以直接用 ELMo 提取上下文的浅层信息也可以)。通常来说,会使用预训练的 Word Embedding(或者是字符级别的 Embedding)来为每个位置生成一个上下文无关的词表示 $x_k $,然后拼接 EMLo 后会生成一个上下文相关的词表示(即,通过 ELMo 提取单词及周围的上下文信息,然后拼接原本的单词向量)。
为了将 ELMo 加到监督学习的模型中,我们有两种拼接方式:
- 固定 BiLM 的权重,并用 x k x_k xk 拼接 ELMo 的向量 E L M o k ELMo_k ELMok ,使用拼接后的向量 [ x k ; E L M o k ] [x_k;ELMo_k] [xk;ELMok] 传递给下游任务;
- 或者利用模型的隐藏输出层,比如 RNN 的 h k h_k hk 来和 E L M O k ELMO_k ELMOk 拼接 [ h k ; E L M o k ] [h_k;ELMo_k] [hk;ELMok] 。
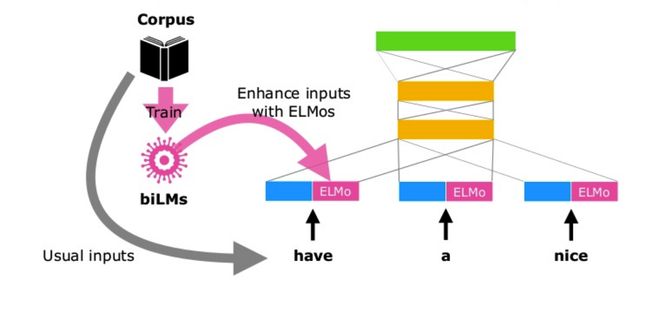
最后,对 ELMo 适当加入一些 Dropout,或者在某些情况下在损失函数中加入 λ ∣ ∣ w ∣ ∣ 2 \lambda||w||^2 λ∣∣w∣∣2 ,都有可能带来效果提升。
2.3 Pre-trained
预训练的架构采用类似下图 c 的架构,下图来自《Exploring the Limits of Language Modeling》。
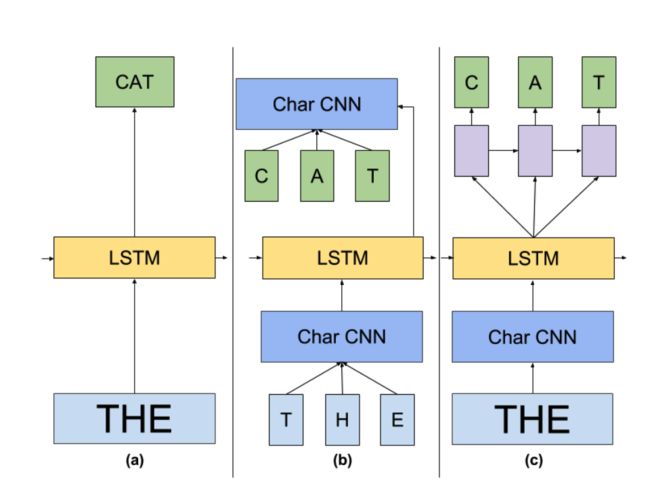
简单解释下这张图,a 是普通的基于 LSTM 的语言模型,b 是用字符级别的 CNN 来代替原本的输入和 Softmax 层,c 是用 LSTM 层代替 CNN Softmax 层并预测下一个单词。(这里的 CNN Softmax 层区别于 Word2Vec 中的 Softmax,并不是直接预测词汇表,而是计算 z w = h T e w z_w = h^Te_w zw=hTew 的 Logistic 值,其中 h 为单词上下文向量, e w = C N N ( c h a r s w ) e_w=CNN(char \; s_w) ew=CNN(charsw))
作者在论文中指出: ELMo 使用 CNN-BIG-LSTM 的架构进行预训练(这里的 BIG 只是想说多很多 LSTM),并且为了平衡 LM 的复杂度、模型大小和下游任务的计算需求,同时保持纯粹基于字符的输入表示,ELMo 只使用了两层的 LSTM 层,每层 4096 个隐藏单元和 512 维的词向量大小,以及跨一层的残差连接。
而在提取静态字符时,使用两层具有 2048 个卷积过滤器的 highway layer 和一个含有 512 个隐藏单元的 linear projection layer。
这里的 highway layer 由《Training Very Deep Networks》论文中给出,可以简单理解为该网络层只处理一部分输入,而另外一部分直接通过。所以相比于传统的网络,HighwayNet 可以有更深的网络,而试验结果也表明其更容易训练。
相比其他模型只提供一层 Representation 而言,作者提供了三层 Representations:单词原始的 Embedding,第一层双向 LSTM 中对应单词位置的 Embedding (包含句法信息)和第二层双向 LSTM 中对应单词位置的 Embedding(包含语义信息)。
下面这张图看的可能更清楚一点。
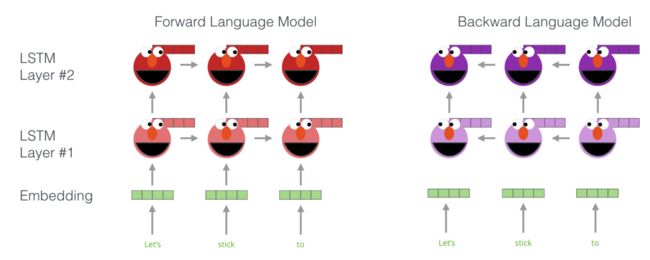
在训练了 10 个 epochs 后,前向和后向的平均困惑度(perplexities)分别是 39.7,而 CNN-BIG-LSTM 的困惑度为 30.0。总体看前向和后向困惑度相当,后向稍微低一些。
困惑度(perplexities):如果每个时间步都根据语言模型计算的概率分布随机挑词,那么平均情况下,挑多少个词才能挑到正确的那个。
显然,困惑度越小越好。
完成预训练后可以得到训练好的 Bi-LM 模型和单词的 Embedding 向量。对于下游任务来说可以对 Bi-LM 进行微调,也可以直接使用。
3. Experiments
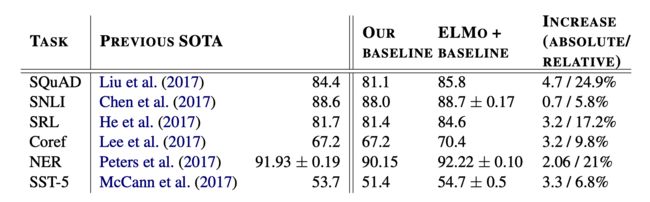
简单看下实验,下图显示了不同任务下,ELMo 相对 baseline 的提升程度:
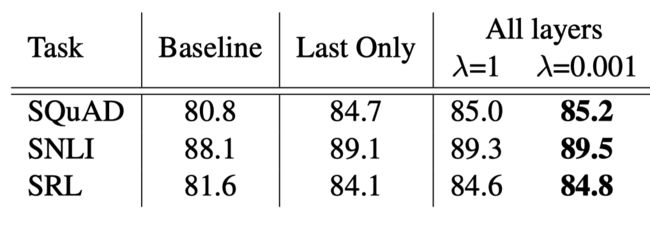
正则化系数的影响:
模型训练效率:

4. Conclusion
总结:ELMo 采用预训练的方式得到原始 Embedding 向量和双层 Bi-LSTM 模型,同时 ELMo 会为每个单词提供三个 Embedding 向量并学习具体任务下线性组合后的中间向量,与原始向量拼接后即可为下游任务提供基于语境的 Word Embedding。
第一次看 ELMo 时的想法是:为什么要用 LSTM 而不用类似 Transformer 的结构?毕竟 Transformer 在发表于 2017 年,早于 ELMo;
其次,ELMo 采用的并不是真正的双向 LSTM,而是两个独立的 LSTM 分别训练,并且只是在 Loss Function 中通过简单相加进行约束,只能一定程度上学习到单词两边句子的特征。
当然,虽然这会在 BERT 一文中给出解答。
这里有一个好玩的 Tip,ELMO 是芝麻街里的人物,而 BERT 也是芝麻街里的人物。

5. Reference
- 《Deep contextualized word representations》
- 《Exploring the Limits of Language Modeling》
- 《Training Very Deep Networks》
- 《A Review of Deep Contextualized Word Representations (Peters+, 2018)》
- 《The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)》
- 《NAACL2018 一种新的embedding方法–原理与实验 Deep contextualized word representations (ELMo)》
- 《Improving a Sentiment Analyzer using ELMo — Word Embeddings on Steroids》
关注公众号跟踪最新内容:阿泽的学习笔记。
