etcd集群数据定时备份以及恢复
etcd集群数据定时备份以及恢复
- 1.etcd集群备份
- 2.etcd集群恢复
- 2.1 数据恢复
- 2.2 重启etcd服务
- 2.3 查看etcd状态
- 2.4 重启flanneld服务
- 2.5 重启其他相关服务
- 2.6 查看k8s集群信息
- 3.常用命令
- 3.1 写入数据
- 3.2 读取数据
- 3.3 查看key
- 3.4 删除key
- 3.5 查看集群成员
- 3.6 查看集群健康状态
- 3.7 查看节点状态
- 4. 定时备份
- 4.1创建备份的脚本
- 4.2 测试执行脚本
- 4.3 加入定时任务
- 4.4 查看是否备份成功
1.etcd集群备份
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
snapshot save /data/kubernetes/etcd/datas_bak/mysnapshot.db

--endpoints 集群所有节点的ip地址:2379,端口不变
/data/k8s/etcd/data_bak/mysnapshot.db为备份的文件路径
注:
我们这里使用的是etcd 3.0的api,故备份的数据也只备份了使用3.0添加的数据,2.0添加的数据是没有做备份的。
2.etcd集群恢复
2.1 数据恢复
需要在每个节点上执行,可以先将备份文件分发到各个节点上面。
恢复数据之前需要先将etcd的旧工作目录清空,例如/data/kubernetes/etcd/datas文件夹跟/data/kubernetes/etcd/wals文件夹,如果不清空这两个文件夹,可能会导致恢复失败。
注意需要修改相关参数(下面的图片中已经用箭头指出来需要更改的地方)
ETCDCTL_API=3 etcdctl \
--name=node01 \
--endpoints="https://192.168.137.231:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
--initial-cluster-token=etcd-cluster-0 \
--initial-advertise-peer-urls=https://192.168.137.231:2380 \
--initial-cluster=node01=https://192.168.137.231:2380,node02=https://192.168.137.232:2380,node03=https://192.168.137.233:2380 \
--data-dir=/data/kubernetes/etcd/datas \
--wal-dir=/data/kubernetes/etcd/wals \
snapshot restore /data/kubernetes/etcd/datas_bak/mysnapshot.db
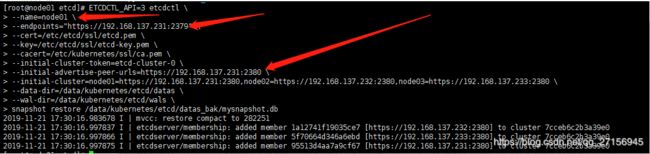
--name 该节点的名称
--endpoints 该节点的ip地址:2379,端口不变
--initial-cluster-token 固定的etcd-cluster-0
--initial-advertise-peer-urls 所有集群节点的ip地址:2380,端口固定不变
/data/kubernetes/etcd/datas_bak/mysnapshot.db 备份文件的路径
2.2 重启etcd服务
systemctl start etcd
2.3 查看etcd状态
systemctl status etcd
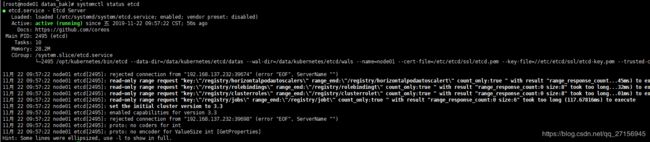
2.4 重启flanneld服务
此时如果重启flanneld服务会发现重启失败。错误信息如下:
11月 22 10:01:30 node01 flanneld[2869]: timed out
11月 22 10:01:30 node01 flanneld[2869]: E1122 10:01:30.669515 2869 main.go:382] Couldn't fetch network config: 100: Key not found (/k8s) [7]
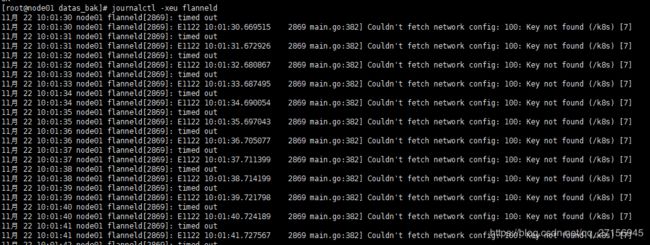
Key not found (/k8s)
这个错误说明此时etcd的数据中没有/k8s这个key,这个key是做什么用的呢。我们回想到之前创建k8s集群时的操作:向 etcd 写入集群 Pod 网段信息
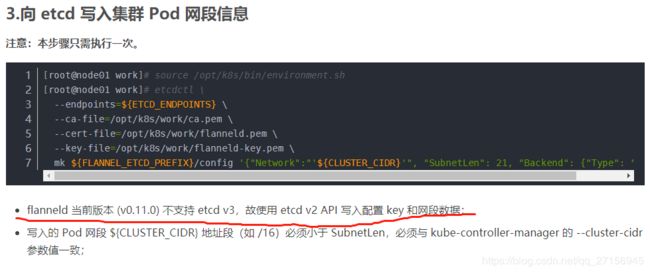
然后因为flanneld的网段信息是使用etcd2.0的api添加的,我们没做备份,所以要重新添加。
该步骤中${FLANNEL_ETCD_PREFIX}/config的值我们查看配置文件:
![]()
可以知道他的值就是/k8s/network/config,说明flanneld启动时报的错误就是缺少了这个部分。我们现在向etcd集群中重新加入这个数据。
向 etcd 写入集群 Pod 网段信息
source /opt/kubernetes/bin/environment.sh
etcdctl \
--endpoints=${ETCD_ENDPOINTS} \
--ca-file=/opt/kubernetes/work/ca.pem \
--cert-file=/opt/kubernetes/work/flanneld.pem \
--key-file=/opt/kubernetes/work/flanneld-key.pem \
mk ${FLANNEL_ETCD_PREFIX}/config '{"Network":"'${CLUSTER_CIDR}'", "SubnetLen": 21, "Backend": {"Type": "vxlan"}}'
![]()
mk命令跟put命令是相似的。他是创建一个新key并写入value

此时再重启 flanneld 服务就可以成功了。
2.5 重启其他相关服务
systemctl restart kube-proxy kube-apiserver
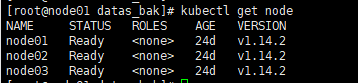
2.6 查看k8s集群信息
kubectl get node
3.常用命令
3.1 写入数据
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
put /test/1 1111

3.2 读取数据
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
get /test/1

3.3 查看key
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
get /test --prefix --keys-only

get /为查询所有key
--prefix 指前缀匹配
--keys-only 指仅打印key,不打印value
3.4 删除key
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
del "/test/1" --prefix

del "" 为删除所有key
--prefix 指开启前缀匹配
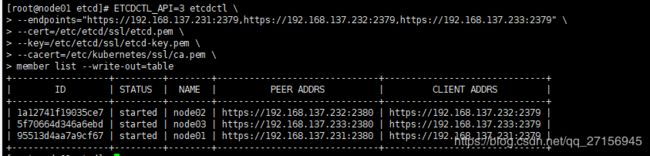
3.5 查看集群成员
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
member list --write-out=table
3.6 查看集群健康状态
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
endpoint health

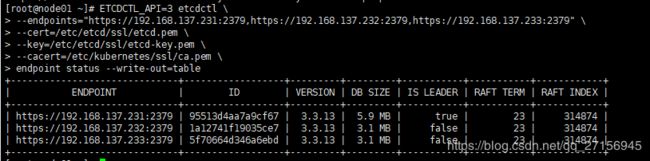
3.7 查看节点状态
ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379" \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
--cacert=/etc/kubernetes/ssl/ca.pem \
endpoint status --write-out=table
4. 定时备份
4.1创建备份的脚本
vim /opt/kubernetes/work/etcd-backup.sh
#!/bin/bash
#时间戳,用来区分不同备份
timestamp=`date +%Y%m%d-%H%M%S`
#备份到哪个文件夹
back_dir="/data/kubernetes/etcd/datas_bak"
#etcd集群列表
endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379"
#etcd证书路径
cert_file="/etc/etcd/ssl/etcd.pem"
#etcd证书的key路径
key_file="/etc/etcd/ssl/etcd-key.pem"
#ca证书路径
cacert_file="/etc/kubernetes/ssl/ca.pem"
mkdir -p $back_dir
ETCDCTL_API=3 etcdctl \
--endpoints="${endpoints}" \
--cert=$cert_file \
--key=$key_file \
--cacert=$cacert_file \
snapshot save $back_dir/snapshot_$timestamp.db
赋予可执行权限:
chmod +x /opt/kubernetes/work/etcd-backup.sh
4.2 测试执行脚本
/opt/kubernetes/work/etcd-backup.sh
![]()
显示已经保存到指定目录下。
4.3 加入定时任务
注:
crond默认不会加载该用户的.profile和.bashrc文件,它的执行环境只能有一些最基本的环境变量
修改脚本文件:
我们需要修改下/opt/kubernetes/work/etcd-backup.sh脚本文件
vim /opt/kubernetes/work/etcd-backup.sh
#!/bin/bash
#时间戳,用来区分不同备份
timestamp=`date +%Y%m%d-%H%M%S`
#备份到哪个文件夹
back_dir="/data/kubernetes/etcd/datas_bak"
#etcd集群列表
endpoints="https://192.168.137.231:2379,https://192.168.137.232:2379,https://192.168.137.233:2379"
#etcd证书路径
cert_file="/etc/etcd/ssl/etcd.pem"
#etcd证书的key路径
key_file="/etc/etcd/ssl/etcd-key.pem"
#ca证书路径
cacert_file="/etc/kubernetes/ssl/ca.pem"
mkdir -p $back_dir
ETCDCTL_API=3 /opt/kubernetes/bin/etcdctl \
--endpoints="${endpoints}" \
--cert=$cert_file \
--key=$key_file \
--cacert=$cacert_file \
snapshot save $back_dir/snapshot_$timestamp.db
ETCDCTL_API=3 etcdctl修改为ETCDCTL_API=3 /opt/kubernetes/bin/etcdctl,即修改成etcdctl的执行文件全路径。
加入crontab:
crontab -e
新增一行:
*/1 * * * * sh /opt/kubernetes/work/etcd-backup.sh
这行命令让**/opt/kubernetes/work/etcd-backup.sh**脚本在每分钟执行一次
启动crond服务并查看状态:
service crond start && service crond status
如果出现如下错误:
11月 22 11:32:01 node01 crond[3080]: sendmail: fatal: parameter inet_interfaces: no local interface found for ::1
则需要修改/etc/postfix/main.cf文件
vim /etc/postfix/main.cf
修改:inet_interfaces = all

重启postfix服务
service postfix restart
这时候crond服务可以正常使用。
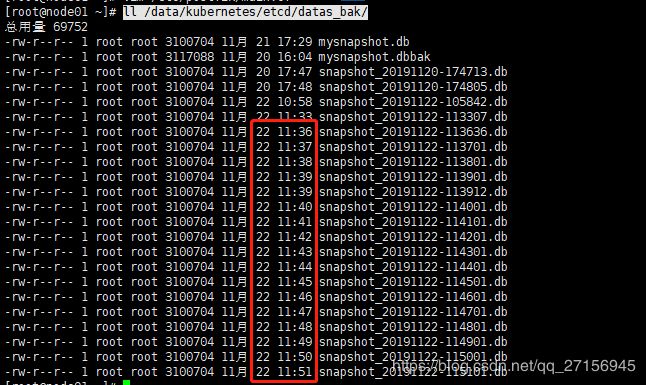
4.4 查看是否备份成功
ll /data/kubernetes/etcd/datas_bak/
可以看到每分钟都有新的备份文件出现。
当我们需要投入使用的时候,可以更改定时策略,将每分钟改成适当的时间。crond语法可以自行百度。