python3练习题:并发编程(21-25)
关于python3中的并发编程,经过这些天的学习,归纳如下:
#practice21:多线程
- 线程的定义

- 方法一:直接Thread()构造
- 方法二:构造Thread的子类
#多线程的使用
from urllib.request import urlretrieve
import csv
from xml.etree.ElementTree import ElementTree,Element
from threading import Thread
def download(sid,filename):
'''下载csv文件'''
url = 'http://quotes.money.163.com/service/chddata.html?code=%s&start=20150104&end=20160108' % str(sid)
response = urlretrieve(url,filename)
def convert(filename):
'''csv文件转换为xml文件'''
with open(filename,'rt',encoding='GB2312')as rf:
if rf:
reader = csv.reader(rf)
header = next(reader)
root = Element('data')
for row in reader:
line = Element('row')
root.append(line)
for key,value in zip(header,row):
e = Element(key)
e.text = value
line.append(e)
et = ElementTree(root)
et.write('%s.xml' % filename,encoding='utf-8')
def handle(sid):
print("downloading %s :" % str(sid))
download(sid,'demo%s.csv' % str(sid))
print("converting %s :" % str(sid))
convert('demo%s.csv' % str(sid))
#方法一
threads = []
for i in range(1000001,1000010):
#注意,args不能是(i),因为必须是元组
t = Thread(target=handle,args=(i,))
threads.append(t)
t.start()
#线程等待
for t in threads:
t.join()
print("main thread")
#方法二
class Mythread(Thread):
def __init__(self,sid):
Thread.__init__(self)
self.sid = sid
def run(self):
handle(self.sid)
print('*'*20)
threads = []
for i in range(1000001,1000010):
t = Mythread(i)
threads.append(t)
t.start()
#线程等待
for t in threads:
t.join()
print("main thread")执行结果:
downloading 1000001 :
downloading 1000002 :
downloading 1000003 :
downloading 1000004 :
downloading 1000005 :
downloading 1000006 :
downloading 1000007 :
downloading 1000008 :
downloading 1000009 :
converting 1000003 :
converting 1000006 :
converting 1000004 :
converting 1000009 :
converting 1000001 :
converting 1000005 :
converting 1000008 :
converting 1000002 :
converting 1000007 :
main thread
********************
downloading 1000001 :
downloading 1000002 :
downloading 1000003 :
downloading 1000004 :
downloading 1000005 :
downloading 1000006 :
downloading 1000007 :
downloading 1000008 :
downloading 1000009 :
converting 1000003 :
converting 1000002 :
converting 1000005 :
converting 1000004 :
converting 1000001 :
converting 1000009 :
converting 1000008 :
converting 1000006 :
converting 1000007 :
main thread
[Finished in 0.9s]#practice22:线程间通信
- .Queue,该队列是线程安全的;
- 一个进程内的多个线程共用地址空间,这是线程间通信的基本依据;
- 本例采用生产者/消费者模型,有多个生产者和一个消费者,每个生产者占用一个线程
- 消费者只有一个,故必须使用循环来处理生产者生产的数据
from urllib.request import urlretrieve
import csv
from xml.etree.ElementTree import ElementTree,Element
from threading import Thread
from queue import Queue
class DownloadThread(Thread):
'''下载线程'''
def __init__(self,sid,queue):
Thread.__init__(self)
self.sid = sid
self.filename = 'demo{}'.format(str(sid))
self.queue = queue
def download(self,sid,filename):
'''下载csv文件'''
url = 'http://quotes.money.163.com/service/chddata.html?code=%s&start=20150104&end=20160108' % str(sid)
response = urlretrieve(url,filename)
def run(self):
print("downloading %s :" % str(self.sid))
self.download(self.sid,self.filename)
self.queue.put(self.filename)
class ConvertThread(Thread):
'''转换现场'''
def __init__(self,queue):
Thread.__init__(self)
self.queue = queue
def convert(self,filename):
'''csv文件转换为xml文件'''
with open(filename,'rt',encoding='GB2312')as rf:
if rf:
reader = csv.reader(rf)
header = next(reader)
root = Element('data')
for row in reader:
line = Element('row')
root.append(line)
for key,value in zip(header,row):
e = Element(key)
e.text = value
line.append(e)
et = ElementTree(root)
et.write('%s.xml' % filename,encoding='utf-8')
def run(self):
while True:
filename = self.queue.get()
if filename == False:
break
print("converting %s :" % str(filename))
self.convert(filename)
if __name__ == '__main__':
#线程使用队列通信
q = Queue()
threads = []
#创建并开启全部线程,包括9个下载线程和一个转换线程
for i in range(1000001,1000010):
t = DownloadThread(i,q)
threads.append(t)
t.start()
ct = ConvertThread(q)
ct.start()
#等待下载线程完毕,通知转换线程结束
for i in threads:
i.join()
q.put(False)程序优化:(三处)
1. StringIO的使用替代文件
2. sid的构造
3. 列表推导式构造线程列表
from urllib.request import urlretrieve
import csv
from xml.etree.ElementTree import ElementTree,Element
from threading import Thread
from queue import Queue
from io import StringIO
import requests
class DownloadThread(Thread):
'''下载线程'''
def __init__(self,sid,queue):
Thread.__init__(self)
self.sid = sid
self.filename = 'demo{}'.format(str(sid))
self.queue = queue
def download(self,sid):
'''下载csv文件'''
#变化3:使用rjust来调整字符串,使得sid只输入一到两位即可
url = 'http://quotes.money.163.com/service/chddata.html?code=1%s&start=20150104&end=20160108' % str(sid).rjust(6,'0')
response = requests.get(url)
#变化1:用类文件对象(内存对象)来存储csv字符串数据,而非文件
self.data = StringIO(response.text)
def run(self):
print("downloading %s :" % str(self.sid))
self.download(self.sid)
self.queue.put((self.sid,self.data))
class ConvertThread(Thread):
'''转换现场'''
def __init__(self,queue):
Thread.__init__(self)
self.queue = queue
def convert(self,sid,data):
'''csv文件转换为xml文件'''
#变化1:csv模块可直接使用stringio对象来获取reader
if data:
reader = csv.reader(data)
header = next(reader)
root = Element('data')
for row in reader:
line = Element('row')
root.append(line)
for key,value in zip(header,row):
e = Element(key)
e.text = value
line.append(e)
et = ElementTree(root)
et.write('1%s.xml' % str(sid).rjust(6,'0'),encoding='utf-8')
def run(self):
while True:
sid,data = self.queue.get()
if data == False:
break
print("converting %s :" % str(sid))
self.convert(sid,data)
if __name__ == '__main__':
q = Queue()
#变化2:使用列表推导式代替for循环,简化代码
threads = [DownloadThread(i,q) for i in range(1,10)]
for thread in threads:
thread.start()
ct = ConvertThread(q)
ct.start()
for i in threads:
i.join()
q.put((100,False))
感觉还不是很熟练,来个实例:程序设计要求如下:
1、调用OTCBTC的API,获取所有买家、卖家出价数据
2、涉及的币种有:EOS、ETH、BCH、NEO
3、将获取到的json数据转换成xml格式并保存
4、要求使用多线程
from threading import Thread
import requests
from xml.etree.ElementTree import ElementTree,Element
from queue import Queue
class DownloadThread(Thread):
'''下载当前某种货币的卖单与买单'''
def __init__(self,coin_id,queue):
Thread.__init__(self)
self.coin_id = coin_id
self.queue = queue
self.url = "https://bb.otcbtc.com/api/v2/depth?market=%s&limit=1000"
self.url %= coin_id
def download(self,url):
'''下载json数据,存储为data'''
response = requests.get(url)
return response.json()
def run(self):
print('downloading %s' % self.coin_id)
data = self.download(self.url)
self.queue.put((self.coin_id,data))
class ConvertThread(Thread):
'''把请求响应转化为xml文件'''
def __init__(self,queue):
Thread.__init__(self)
self.queue = queue
def setchildtree(self,superelement_tag,spec_dict):
'''
构建asks tree或者bids tree. superelement_tag是子树的根节点名,
spec_dict是整个json字符串转换后的python字典
'''
e =Element(superelement_tag)
for list_item in spec_dict[superelement_tag]:
e1 = Element('item')
e.append(e1)
e2_price = Element('price')
e2_price.text = list_item[0]
e1.append(e2_price)
e2_volumn = Element('volumn')
e2_volumn.text = list_item[1]
e1.append(e2_volumn)
return e
def convert(self,coin_id,spec_dict):
'''将请求响应body的字典转换为xml文件'''
root = Element('data')
e_timestamp = Element('timestamp')
#必须在xml中把数字变成字符串!否则报错:TypeError: cannot serialize 1530197213 (type int),序列化错误!
e_timestamp.text = str(spec_dict['timestamp'])
root.append(e_timestamp)
asks_childtree = self.setchildtree('asks',spec_dict)
root.append(asks_childtree)
bids_childtree = self.setchildtree('bids',spec_dict)
root.append(bids_childtree)
et = ElementTree(root)
et.write('%s.xml' % coin_id)
def run(self):
while True:
#获取队列中已经下载好的数据
coin_id,data = self.queue.get()
#判断队列是否已经收到哨符!
if data == False:
break
print('converting %s' % coin_id)
self.convert(coin_id,data)
if __name__ == '__main__':
queue = Queue()
markets = ['eosbtc','ethbtc','bchbtc','neobtc']
threads = [DownloadThread(market,queue) for market in markets]
for thread in threads:
thread.start()
ct = ConvertThread(queue)
ct.start()
#等待所有下载线程完毕
for thread in threads:
thread.join()
#添加终止convert线程的哨符
queue.put(('xxx',False))#practice23:线程间事件通知
1、 Event的使用
+ Event.wait与Event.set
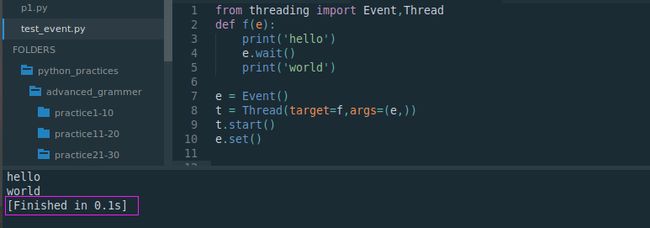
from threading import Event,Thread
def f(e):
print('hello')
e.wait()
print('world')
e = Event()
t = Thread(target=f,args=(e,))
t.start()
可以看出,e.wait方法相当于阻塞函数,阻塞程序继续执行,直到等到触发信号e.set()
从运行框可以看出,程序并未执行完。
from threading import Event,Thread
def f(e):
print('hello')
e.wait()
print('world')
e = Event()
t = Thread(target=f,args=(e,))
t.start()
e.set()由于e.set(),线程被触发继续执行,程序最后运行完退出。
- Event.clear()
Event对象调用一对wait/set方法后就不能再次调用这对方法了,若想再次调用,必须先对Event对象调用clear方法!
from threading import Event,Thread
def f(e):
while True:
print('hello')
e.wait()
print('world')
e = Event()
t = Thread(target=f,args=(e,))
t.start()
e.set()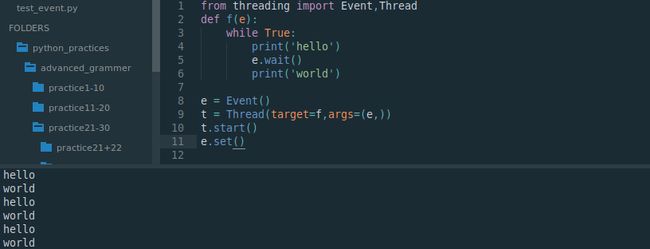
由于e.set()使得线程内的阻塞函数e.wait()失效,故循环无限往复
from threading import Event,Thread
import time
def f(e):
while True:
print('hello')
e.wait()
e.clear()
print('world')
e = Event()
t = Thread(target=f,args=(e,))
t.start()
e.set()
time.sleep(1)
print('*'*40)
e.set()
主线程与子线程共同维护Event对象e
e.start()启动子线程,对应输出hello,然后开始阻塞;主线程e.set()结束子线程的阻塞,e.clear()使得e.start()可以重新生效,输出world与hello,然循环再次被e.wait()阻塞;
等待一秒,e.set()使得阻塞再次被解除!
2、 实例:
要求:
+ 多线程下载股票csv数据(生产者)
+ 单线程转换为xml文件(消费者)
+ 单线程打包xml文件(每当生成3个xml文件便打包为一个tar.gz包)
import csv
from xml.etree.ElementTree import ElementTree,Element
from threading import Thread,Event
from queue import Queue
from io import StringIO
import requests
import os
import tarfile
class DownloadThread(Thread):
'''下载线程'''
def __init__(self,sid,queue):
Thread.__init__(self)
self.sid = sid
self.filename = 'demo{}'.format(str(sid))
self.queue = queue
def download(self,sid):
'''下载csv文件'''
url = 'http://quotes.money.163.com/service/chddata.html?code=1%s&start=20150104&end=20160108' % str(sid).rjust(6,'0')
response = requests.get(url)
self.data = StringIO(response.text)
def run(self):
print("downloading %s :" % str(self.sid))
self.download(self.sid)
self.queue.put((self.sid,self.data))
class ConvertThread(Thread):
'''转换线程'''
def __init__(self,queue,cevent,tevent):
'''转换线程与打包线程共同维护两个事件:转换事件cevent与打包事件tevent'''
Thread.__init__(self)
self.queue = queue
self.cevent = cevent
self.tevent = tevent
#生成xml文件的计数器
self.count = 0
def convert(self,sid,data):
'''csv文件转换为xml文件'''
if data:
reader = csv.reader(data)
header = next(reader)
root = Element('data')
for row in reader:
line = Element('row')
root.append(line)
for key,value in zip(header,row):
e = Element(key)
e.text = value
line.append(e)
et = ElementTree(root)
et.write('1%s.xml' % str(sid).rjust(6,'0'),encoding='utf-8')
def run(self):
while True:
sid,data = self.queue.get()
if data == False:
#当终止哨符发出后,可能最后的xml文件不足3个,但也要打包
#必须先设置终止信后,后开始打包
global tarstop
tarstop = True
self.tevent.set()
break
print("converting %s :" % str(sid))
self.convert(sid,data)
#每转换一个xml文件,计数器加1
self.count += 1
if self.count == 3:
self.count = 0
#通知打包线程开始打包
self.tevent.set()
#停止转换,要想循环使用事件,clear()需要紧跟wait()
#注意:必须先通知打包线程,再停止转换,反过来不行
self.cevent.wait()
self.cevent.clear()
class TarThread(Thread):
'''打包线程'''
def __init__(self,cevent,tevent):
'''转换线程与打包线程共同维护两个事件:转换事件cevent与打包事件tevent'''
Thread.__init__(self)
#tar包名称的初始id
self.count = 0
self.cevent = cevent
self.tevent = tevent
#任何一个循环执行的线程必须要有出口,设置为守护线程,主线程结束后,该线程自动退出,可能未完成打包任务!经测试不可行!
# self.setDaemon(True)
def tar(self):
'''寻找当前文件夹下xml文件,生成打包文件,同时将源文件删除!'''
self.count += 1
filename = '%s.tar.gz' % str(self.count)
with tarfile.open(filename,'w:gz') as tar:
for file in os.listdir('.'):
#注意函数名字:endswith不是endwith
if file.endswith('.xml'):
tar.add(file)
os.remove(file)
#如果当前文件夹下没有xml文件,但执行上一步任然会生成tar包,需要把空的tar包删除
if not tar.members:
os.remove(filename)
def run(self):
global tarstop
while not tarstop and True:
#阻塞等待打包命令,一旦阻塞被解除,执行完动作后应当立即调用clear(),使得下一次调用wait方法有效
self.tevent.wait()
self.tar()
self.tevent.clear()
#一旦打包完成,应当立即通知转换线程继续转换
self.cevent.set()
if __name__ == '__main__':
#定义线程安全队列,用于下载与转换线程间通信
dcqueue = Queue()
tarstop = False
#定义转换事件与打包事件
cevent,tevent = Event(),Event()
#定义下载、转换、打包线程
threads = [DownloadThread(i,dcqueue) for i in range(1,11)]
ct = ConvertThread(dcqueue,cevent,tevent)
tt = TarThread(cevent,tevent)
#开启所有线程
for thread in threads:
thread.start()
ct.start()
tt.start()
#等待下载线程执行完毕,发出转换线程的终止哨符
for i in threads:
i.join()
dcqueue.put((100,False))
不足之处:tar线程 最终的退出方式使用了全局变量,不太优雅;守护线程感觉又不满足条件
#practice24:线程池
concurrent.futures 函数库有一个 ThreadPoolExecutor 类,可以构建多线程(异步执行多个调用)。

1、 多线程的使用方法
from concurrent.futures import ThreadPoolExecutor
def handle(a,b):
print('hello world',str(a*b))
return a*b
#构建多线程对象:executor
executor = ThreadPoolExecutor(max_workers=3)
#调用submit方法,提交任务给线程池,默认一次submit使用一个线程
#线程执行结果由Future对象保存
future = executor.submit(handle,3,4)
#调用result方法提取结果,如果线程未结束,则阻塞起来,直到有结果
result = future.result()
print(result)
#除了submit,还有更高效的提交任务方法map,返回迭代器,每次迭代返回函数的执行结果,不是future对象
#使用3个线程,依次执行handle(1,1) handle(2,2) handle(3,3)
for result in executor.map(handle,[1,2,3],[1,2,3]):
print(result)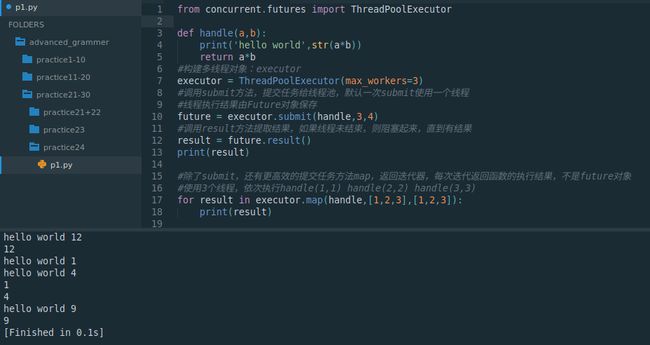
2、实例
要求:
1. 构建echo TCP服务器,响应客户端的请求,即直接返回客户端发来的数据。
2. TCP服务器开启10个线程异步处理客户端请求。
3. 构建echo客户端,发送请求验证多线程。
- 服务端
import socket
from concurrent.futures import ThreadPoolExecutor
HOST = 'localhost'
PORT = 12345
def handle_request(conn):
with conn as subsock:
while True:
data = subsock.recv(1024)
if not data:
break
subsock.sendall(data)
def server(address):
pool = ThreadPoolExecutor(10)
ip,port = address
with socket.socket() as s:
s.bind(address)
s.listen(5)
while True:
conn,address = s.accept()
print('Client ' + ip + ":" + str(port) + ' connected')
pool.submit(handle_request,conn)
server(('',12345))- 客户端
import socket
def run_sockets(addr):
with socket.socket() as s:
s.connect(addr)
s.sendall(b'hello world')
data = s.recv(1024)
print(data)
for i in range(7):
run_sockets(('localhost',12345))【运行结果】
- 客户端
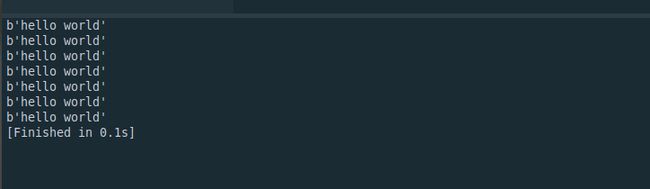
- 服务端
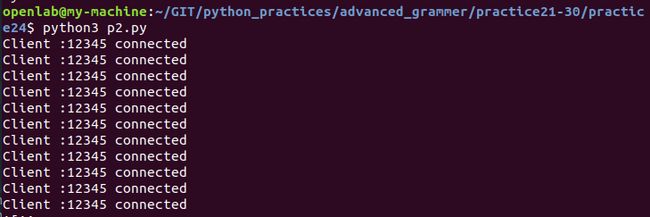
先运行服务端代码,作为服务器是无限循环,等待请求
sendall,recv,accept无数据时都会阻塞
必须先运行服务器代码,再运行多个客户端!
#practice25:多进程

1、 多进程的定义
- 创建子进程
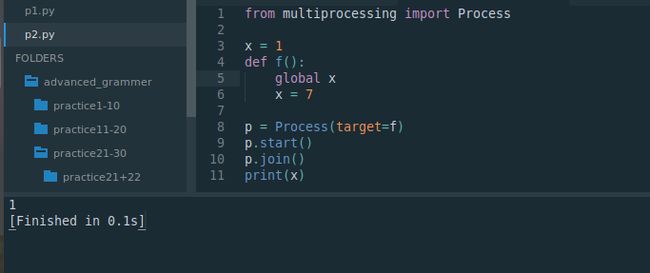
from multiprocessing import Process
def f(a,b):
print(a*b)
p = Process(target=f,args=(1,5))
p.start()
print('main process')
p.join()
print('main1 process')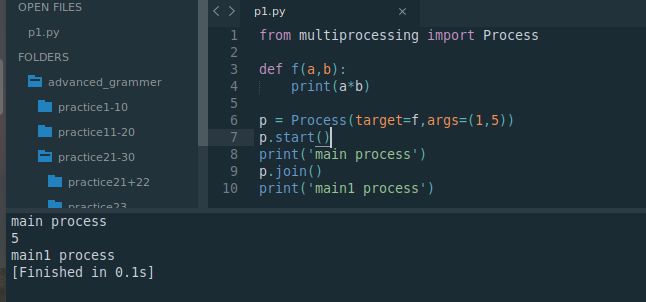
- 与线程的区别
虽然进程与线程的很多方法相似,但最大的不同是,进程之间占用不同的地址空间。所以不能使用之前线程共用全局变量的方法进通信!
 2、 进程间通信
2、 进程间通信
- 使用multiprocessing.Queue
from multiprocessing import Process,Queue,Pipe
#进程安全Queue的基本使用
q = Queue()
def f(q):
print('hello')
#当队列内容为空,get操作会阻塞!,直到传入data
print(q.get())
print('world')
p = Process(target=f,args=(q,))
p.start()
q.put('yes it is')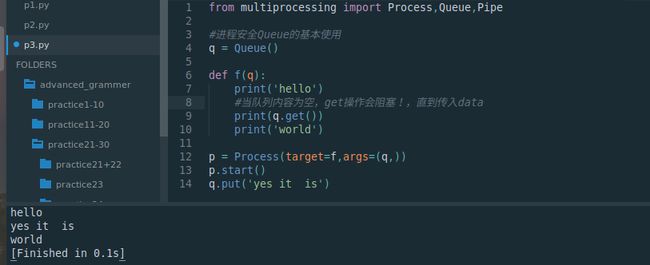
- 使用multiprocessing.Pipe
from multiprocessing import Process,Pipe
def f(c):
#无数据会阻塞在这里
data = c.recv()
print(data)
c1,c2 = Pipe()
p = Process(target=f,args=(c2,))
p.start()
c1.send('hello world')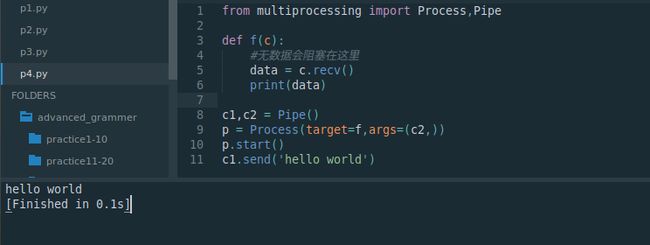
3、 多进程使用场景:cpu密集型操作
from threading import Thread
from multiprocessing import Process
def isarmstrong(n):
'''求n是不是水仙花数,返回bool结果(无须关注具体算法)'''
a,t = [],n
while t > 0:
a.append(t % 10)
t /= 10
k = len(a)
return sum(x * k for x in a) == n
def findarmstrong(a,b):
'''在a-b间寻找水仙花树'''
result = [x for x in range(a,b) if isarmstrong(x)]
print(result)
def run_multithreads(*args):
'''采用多线程处理寻找水仙花树的任务,args传入的是多个查找范围'''
threads = [Thread(target=findarmstrong,args=(a,b)) for a,b in args]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
def run_multiprocess(*args):
'''采用多线程处理寻找水仙花树的任务,args传入的是多个查找范围'''
proceses = [Process(target=findarmstrong,args=(a,b)) for a,b in args]
for process in proceses:
process.start()
for process in proceses:
process.join()
if __name__ == '__main__':
import time
start = time.time()
# run_multiprocess((200000,300000),(300000,400000))
run_multithreads((200000,300000),(300000,400000))
end = time.time()
print(end-start)多进程明显比多线程快