性能压测与调优
性能压测是当服务上线前,或者之后重要需求发布流程中,需要做的必要测试;以模拟真实流量的方式,获取当前系统的性能指标、是否存着高并发隐患、瓶颈等信息的手段。
性能压测处于什么位置?或者说什么时候去做呢?如何做?
如何做好线上环境的性能压测、全链路压测,如何做到压测结果准确无误,不影响外部环境、不污染数据,需要深入思考。
一、测试分类
按照上线流程:
- 单元测试
- 集成测试
- 兼容性测试(前端、客户端)
- 性能测试
运维阶段:
- 安全测试
- 容灾测试(故障恢复测试)
由上可以看出,性能测试是应用服务在上线过程中的一个流程,除非是内部系统,访问量少,否则都应当做一下性能测试。
安全测试又叫渗透测试,是运维和研发需要关注的问题;尤其是对数据安全要求高的系统。当一个服务稳定运行后,模拟一些攻击手段,防止SQL注入、网络攻击、脚本攻击等。
容灾测试是容灾方式的验证,容灾方式包括:双机房建设、异地多活、两地三中心。
二、压测目的
- 了解吞吐量
- 瓶颈值
- 系统隐患
可用:一次请求,到达服务器,有回应;那么针对这次请求,服务是可用的,无论返回成功或者失败。
不可用是指请求没有返回,长时间等待,没有应答,客户端不知道结果。
高可用级别:99%、99.9%、99.99%、99.999%
大家经常说的系统可用性达到三个9,就是指99.9%。
高可靠:是指服务可靠,数据可靠。请求返回是成功,数据写入正确,分布式环境下数据一致性等。
三、压测指标

四、实现流程
1. 压测工具选型
2.压测环境准备
- 服务环境
- 压测机
- 数据库
- Redis
- MQ
3.压测数据准备
- 日活数据:数据要真实、流量真实,结果才能越接近线上真实性能指标。
- 数据隔离:防止污染真实用户数据
- 数据恢复
- 热点数据
- 压测预热:尽量模拟线上真实环境情况,如缓存命中率
4.压测开发设计
- 挡板
- Mock数据
- 流量识别
- 压测场景
- 加压策略
挡板:是用来拦截调用第三方的请求,防止压测对第三方造成影响;提前设计好挡板逻辑,识别压测流量,执行挡板逻辑,并且为了真实,还可以合理延迟一定时间再返回Mock数据。
流量识别:nginx做负载均衡,upstream 转发服务器ip 时,可以获取http请求Header的参数,我们可以给压测流量header加标记参数,nginx获取参数判断后,转发压测流量到压测机器。
5.监控
监控很重要,可以说是压测中最为重要的地方,如果没有监控,或者监控不准确,会严重影响压测本身准确性。监控数据不详细,也会影响性能调优。
一般我们需要监控的如下:
- CPU、内存
- IO:网络、磁盘
- Http请求、接口方法
- JVM
- 中间件
- 数据库负载
- 带宽占用
其中对接口和方法的监控需要有,而且要准确,是定位性能问题的有效手段,越细化越好。
以下是一些监控工具:
1. Grafana 监控 (CPU、内存、成功率、http请求的RT)

2. Sentinel 监控 (接口、方法级别)

3. Visualvm 监控JVM
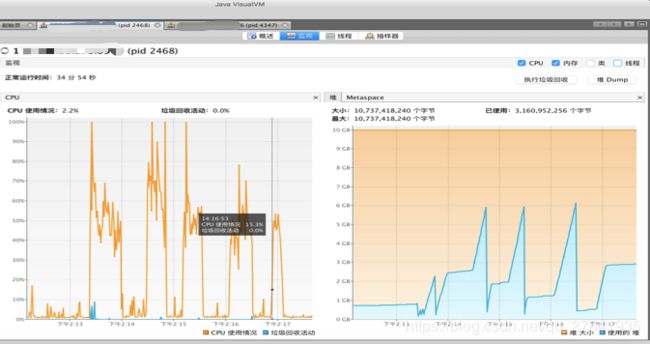
通过上图可以直观的看出JVM堆内存的增长情况和GC回收频率、回收后内存大小。如果回收后的内存在持续增高,且当前请求没有增长,说明有内存泄露,具体什么对象泄漏,需要通过jmap等命令,查看堆内存heap的详情。
如以下命令:

对比GC前后的对象数量,分析是哪些没有回收。
五、性能优化
注意:
- 慎重优化,谨记二八原则 和 Amdahl定律。
- 优化一定要伴随着压测,通过性能指标、数据对比来论证和调整,否则没有意义。
优化目标
- 提升吞吐量
- 降低 RT
优化方向
- 硬件层面:CPU、内存扩容、换SSD固态硬盘
- 软件层面:集群扩容、代码优化、存储优化(缓存、数据库)、减少IO
优化方式
- 代码优化:请求合并、异步、Cache、池化
- JVM调优
- Linux调优
JVM调优
1. 调优关注点
- 减少JVM不可用时间:STW(Stop the word)
- GC 频率
- 安全点SafePoint
安全点是需要注意的问题,很多初学者会忽略安全点线程等待时间,其实STW时间包括安全点等待时间。
2. 常用GC回收器
- ParNew + CMS (低延迟、低核、小内存场景)
- G1 (高吞吐量、高核、大内存)
G1只有在多核CPU,大内存情况下,才能体现出它的优势,如果内存过小,表现反而不如ParNew+CMS。
那么到底多大算大内存呢?
根据R大给出的建议是:以堆内存8g为限,大于8g用G1,小于8g用CMS。
3. JVM参数分类
- -:标准参数,所有JVM都必须实现,且向后兼容。
- -X :非标准参数,默认JVM实现该参数,不保证向后兼容。
- -XX:非stable参数,不同JVM有所不同,将来可能会取消。
4. G1关键参数
-Xms16g -Xmx16g
-XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:InitiatingHeapOccupancyPercent=60
-verbose:gc -Xloggc:logs/gc_%p.log -XX:+DisableExplicitGC
-XX:-UseLargePages -XX:+PrintGCApplicationStoppedTime -XX:-OmitStackTraceInFastThrow
-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1需要注意的是,G1最好不要加新生代大小参数 -Xmn ,如果固定了新生代大小,G1就没法根据 -XX:MaxGCPauseMillis 设定的最大期望GC时间,动态调整堆内存的新生代和老年代大小,相当于-XX:MaxGCPauseMillis 失效了。除非你很熟悉G1原理,加了新生代大小,配合其他参数,也可以调优出一个不错的结果。否则还是交给G1本身的自动调整吧。
5. GC 日志
2020-01-09T11:05:34.836+0800: [GC pause (G1 Evacuation Pause) (young) ……
[Eden: 8576.0M(8576.0M)->0.0B(8576.0M) Survivors: 16.0M->16.0M Heap: 8643.7M(14.0G)->68.2M(14.0G)]
[Times: user=0.05 sys=0.04, real=0.02 secs]
2020-01-09T11:05:34.863+0800: 2043140.818: Total time for which application threads were stopped:0.0286394 seconds, Stopping threads took: 0.0002674 seconds
2020-01-09T12:01:10.488+0800: 2046476.443: Application time: 3335.6250688 seconds
2020-01-09T12:01:10.490+0800: 2046476.444: [GC pause (G1 Evacuation Pause) (young) 2046476.444:
gc日志中 Stopping threads took 就是安全点时,线程的等待时间,所以STW时间应该是:GC时间 + 安全点等待时间。
如果 Stopping threads took 较大,说明代码程序是有问题的,需要深入查看;
具体什么情况会导致安全点时间过长,请参考:
JVM安全点介绍
HBase实战:记一次Safepoint导致长时间STW的踩坑之旅
Linux调优
我在对业务项目、RocketMQ、Redis、codis集群、Elasticsearch、Hbase等进行优化过程中,经常遇到一些相同的问题,我总结了下,主要有以下:
- 慎用交换区swap
优化方式:禁止swapping 或者设置 swappiness = 1
swapping会导致gc过程从毫秒级变成分钟级
- 善用 /dev/shm/
/dev/shm/ 是linux的文件内存系统,是共享内存,直接从物理内存中开辟,根据使用情况会动态扩容。
针对一些写入文件,IO性能要求高的场景,可以使用/dev/shm/,例如gc日志存放。
高并发场景下,如果打开安全点日志,安全点日志是在安全点内打印,是同步的,所以日志写入文件速度,会严重影响gc快慢;应当将gc日志配置改为:
-Xloggc:/dev/shm/gc_%p.log 其他linux调优,一般大点的公司,都会有自己的运维团队,运维就会做基本的优化,例如tcp连接优化等,这里只介绍运维可能忽略的,不知道的点,这时候就需要研发同学介入,找运维做好应用相关的Linux内核优化。