空间众包:现状与未来方向
Spatial Crowdsourcing: Current State and Future Directions
- 作者
- 摘要
- 介绍
- 空间众包的独特挑战
- 空间众包分类
- 工人模型
- 任务模型
- 回答模型
- 优化目标和约束
- 未来研究方向
- 结论
- 参考文献
作者
Yongjian Zhao and Qi Han
摘要
众包依靠大量工人的贡献来完成空间任务,近年来越来越受到人们的关注。许多众包任务都是在网上完成的,因为它方便快捷。然而,由于涉及实际物理位置的特殊要求,这种传统方法有时可能无法工作。因此,在过去几年中出现了一种新的数据收集模式,称为空间众包。空间众包由特定位置的任务组成,这些任务要求人们实际在特定位置完成。在本文中,我们讨论了空间众包所面临的独特挑战,通过引入分类法对这一新范式进行了全面的阐述,并给出了未来的发展方向。
介绍
众包”一词最早是由Jeff Howe于2006年6月在Wired杂志一篇名为“众包的兴起”的文章中提出:“众包是指本应该由公司或机构的工人履行的职责,以公开招募的方式将其外包给一个未知的(通常是大量的)人群网络的行为。众包任务可以由个人完成,也可以通过合作完成。根据这个定义,大量的人群和公开招募是众包的两个关键组成部分。各种各样的术语被用于众包,包括社交计算、集体智能、人类计算[1]、众包感知、众包计算、对等生产用户驱动系统、众包智慧、智能群和大规模协作。
传统上,众包被用于数据挖掘,以确保获得足够的数据,排除不良数据,或获得更精确的答案。它也被用于软件工程以支持各种活动。通常,众包是在网上进行的,因为它可以很容易地吸引到很多人。例如,Amazon Mechanical Turk(AMT)是一个基于web的市场,它让人们完成由个人或公司发布的任务。在线众包可以用于各种目的,如寻找失踪人员和社会科学实验(如人口学)。通常,接收或请求任务的工人根据自己的知识回答问题,而不需要出现在特定的物理位置。移动设备的日益普及使得移动众包成为可能,即移动用户可以在一个位置完成各种无法完成的任务。特别是,由于移动设备通常有各种内置传感器,众包感知(crowdsensing)是众包的一个子类,现在,许多用户可以通过使用内置在移动设备中的传感器感知和报告某些信息来完成任务。
在本文中,我们特别关注一种移动众包:空间众包(spatial crowdsourcing,空间众包)。空间众包要求工人在特定地点完成任务。在这种群体智慧中,人们在现实世界中收集、分析和传播地理和/或社会信息。空间众包有时被称为位置感知或地理众包。关于众包的研究已经有很多,但是对于空间众包的关注却很少,很多应用都能从中受益。例如,政府希望在不同的时间(即小时、日、月、年)从城市的不同地点收集空气质量信息,而每个地点都需要几个工人提供数据。由于工人分布在城市的地理位置,一个传统的众包系统,工人只是在他们选择的时间上传他们附近的数据,可能无法提供城市空气质量状况的完整图片。这是因为当时某些地区没有足够的工人而导致在这些地点或时间报告的数据可能不够。相比之下,一个主动派遣工人的空间众包系统将解决这个问题。近年来,地理数据或地理空间数据的收集引起了各国政府的重视。例如,美国和英国政府已经批准了收集、生产和许可地理空间数据的项目,以作为国家战略的一部分。Grassroots Mapping是利用气球测绘平台采集航空影像的项目。收集到的图像然后进行地理注册并共享给公众。此外,Open Street Map(OSM)、Google MapMaker和Wikimapia都是使用空间众包的优秀地理项目,因此,开发完善的空间众包技术来支持这些应用是非常重要的。
本文对空间众包进行了全面的回顾,将空间众包与传统众包进行了比较,确定了空间众包的独特性,并对空间众包进行了分类,以帮助更好地理解空间众包中的关键问题和该领域的研究现状。最后,我们讨论了未来的几个方向。
空间众包的独特挑战
通常,众包系统关注以下问题。
- 任务制定. 正确地制定任务是很重要的。例如,如果一个任务需要人们回答一个问卷,那么设计好的问题来收集详细的回答是至关重要的;如果一个任务太大,最好将它分成多个子任务。
- 任务分配或工人选择. 这个问题的目标是哪些任务应该分配给多少志愿者和哪些志愿者。从任务发布者的角度来看,任务应该分配给尽可能多的志愿者,并且总预算最小,可靠性最高。有些任务有更严格的时间限制;那么目标就是最大限度地在最后期限内完成任务。
- 激励机制. 在空间众包中,工人往往不是无条件地愿意接受任务,而是以报酬为导向,因此,设计一种激励机制来引起人们的关注具有重要意义。设计一个激励机制需要考虑几个方面,包括薪酬、利他主义、享受乐趣、声誉和隐性工作[1]。薪酬包括像金钱一样的奖励,这是最常见的激励方法。基于奖励的激励可以被描述为一个博弈,并且可以用博弈论算法来求解。对于某些领域,如政治和体育,声誉常常被用作一种激励。
- 可扩展性. 无论用户数量和任务数量如何,设计一个能够很好地运行的系统是至关重要的。众包吸引了大量的工人。例如,Amazon Mechanical Turk需要数百万人执行任务。因此,设计一个能够支持大量任务请求和工作响应的平台非常重要。
- 用户贡献数据的质量. 数据质量可以定义为属性准确度、语义准确度和时间质量,在空间众包中,要求系统保证用户贡献数据的质量。它们分为用户质量、特性质量和相互依赖性[2]。一些用户贡献的数据可能质量不高,甚至是恶意的;因此,排除不良数据并确保数据质量非常重要。另一个有趣的问题是,所收集数据的测量质量需要与系统所不具备的真值进行比较。系统如何从数据流中推断真值(其中一些可能是误导性的或不可靠的)是一个有趣的话题。
- 隐私保护. 众包需要工人报告他们的数据。然而,有些数据可能是敏感的,不应该泄露给其他人,因此,保护工人的隐私是很重要的。
所有这些问题并不是相互独立的;相反,它们常常相互影响。例如,工人的选择往往需要考虑工人的可靠性、贡献数据的质量和激励;激励机制也不能忽视工人的可靠性和数据质量。
除了这些问题,空间众包还带来了新的挑战,因为它要求人们在某个地方亲自到场完成任务。空间众包可以很容易地透露工人的位置,这引起了严重的隐私问题。PriGeoCrowd[3]是一个交互式可视化开发的,用于保护隐私的空间众包的调整工具箱。系统设计人员可以通过PriGeoCrowd来研究分配策略、任务分配启发算法、隐私预算、私有任务匹配的数据集密度等参数的影响。只有隐私得到保护,才能鼓励人们参与空间众包应用程序。此外,还应处理其他几个问题。
- 位置感知. 位置感知是空间众包最独特的特征,位置感知的独特在于它涉及到用户的移动。这不同于志愿地理信息(volunteered geographic information,VGI)[4],其目标是收集个人和用户自愿参与随机提供的地理信息数据。在VGI中,虽然用户贡献的数据是基于位置的,但并不要求用户去特定的物理位置执行任务;他们可能只是用已有的信息做出回答。与VGI类似,Twitter上基于位置的众包查询也涉及地理信息。它使用基于位置的服务来寻找合适的人来回答给定的查询。系统根据用户的Foursquare签到历史,选择最相关的用户。然而,被选中回答问题的用户不必故意移动到位置,他们只需根据自己现有的知识来回答问题。与上述两个项目不同的是,gMission[6]是一个通用的平台,用于各种与位置相关的众包任务,用户可以在其中发布、回答和验证不同的问题。由于基于位置的验证,系统会检查工作进程是否真正到达了特定的位置。只有当用户在发布答案时靠近该位置时,它才接受用户的答案;因此,工人必须前往活动地点。
- 工人路径选择. 由于用户应该前往事件地点并执行任务,因此用户选择最佳路径并智能地安排任务序列是至关重要的。经典的旅行商问题(traveling salesman problem,TSP)和车辆路径问题(vehicle routing problem,VRP)是求解最小花费路径问题的常用方法。在VRP中,所有的工人都从同一个位置开始,工人的数量是固定的。然而,在空间众包中,找到正确的路径更具挑战性,因为:
- 工人们从不同的地方开始工作。
- 志愿者的数量可能因任务而异,也可能随时间而变化。
- 数据集. 在某些假设下,只能使用少数真实世界的数据集。例如,Gowalla和Brightkite是两个基于位置的社交网络,用户可以在这两个网络中查看其附近的不同位置。签到包括用户进入站点的位置和时间,用户通过签到共享自己的位置。如果我们将用户视为工人,将签到点视为任务,则这两个数据集都可以用于空间众包。Yelp数据集在亚利桑那州大凤凰城地区获取,包括11537家企业(酒店等)、43873名用户和229907条评论的位置。对于这个数据集,我们可以将Yelp用户视为工人,将消费视为空间任务,将具有与相同类别的消费数据集视为复杂的空间任务,并将评论消费视为接受空间任务。对于工人 i i i,我们从数据集中知道他在不同时间的位置: ( l o c i , t i ) (loc_i, t_i) (loci,ti)。我们使用一定的移动模型根据这些位置生成他的轨迹。这可以看作是工人的常规轨迹。当一个空间任务被分配给工人时,如果工人可以接受,我们就让工人偏离他的轨迹来执行任务。如果工人能够在截止日期之前完成任务,我们将考虑这个工人来完成的任务。包含感兴趣的位置和轨迹的其他数据集也可用于空间众包。感兴趣的位置是任务的位置,用户轨迹可被视为任务调度路线。
由于没有可直接用于空间众包的真实数据集,空间众包算法通常使用综合数据集进行评估:使用分布函数生成用户和任务位置,然后使用用户移动模型模拟用户行为。为科研人员设计一个通用的空间众包数据采集平台,对促进空间众包领域的研究具有巨大的潜力。
空间众包分类
为了帮助识别未来应用的需求,我们开发了潜在应用的分类法(图1)。第一个部分涉及空间众包工人的建模方式,第二个部分涉及众包任务的需求,第三个部分涉及工人提供的各种类型的回答,第四部分是应用程序希望优化什么以及它面临什么约束。在图1中,阴影框显示需要修改以适合空间众包的问题,而其他框显示空间众包和一般众包中常见的问题。
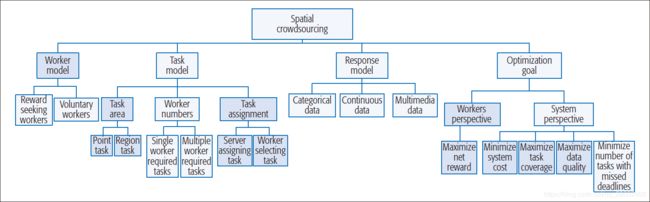
图1. 空间众包的分类法
工人模型
空间众包系统由一组工人组成。每个工人 w i w_i wi都与一组属性相关联,这些属性表示为 { i d i , l a t i , l o n g i , d i , e x p i , r e l i , p u n c i , t r a i } \{id_i, lat_i, long_i, d_i, exp_i, rel_i, punc_i, tra_i\} {idi,lati,longi,di,expi,reli,punci,trai},其中 i d i id_i idi表示工人的唯一标识符, l a t i lat_i lati和 l o n g i long_i longi表示用户的地理坐标, d i d_i di表示用户在 e x p i exp_i expi方面的熟练程度。例如,专业摄影师可以提供比业余摄影师更高质量的照片。用户可靠性表示为 r e l i rel_i reli,它反映了工人提供准确答案的可能性, p u n c i punc_i punci表示用户准时性,它衡量用户在最后期限内到达任务位置的可能性。 t r a i tra_i trai代表工人过去的轨迹,可以用来预测工人未来的位置。
据工人的动机,我们可以将工人分为两类:寻求奖励和志愿。
- 寻求奖励的工人. 寻求奖励的工人完成任务以获得奖励。在大多数情况下,奖励是一定数量的金钱或商品。如果工人正确、准时地完成任务,他们会得到一定的奖励[7]。
- 志愿工作者. 志愿工作者愿意无偿完成与地点有关的任务。这些人出于各种各样的原因,比如提升文化和政治声誉,或者仅仅是享受赏识,都有参与的积极性。例如,在一个参与性的感知活动中,一群人愿意报告交通信息,如事故或使用配备传感器的设备记录地理信息。现有的空间众包系统大多依赖于志愿参与者。、
任务模型
每个任务 j j j都与一组属性关联: { i d j , d e a d l i n e j , l o c j , q u e j , n u m j , i n c e n t i v e j i , b u d g e t j } \{id_j,deadline_j,loc_j,que_j,num_j,incentive_{ji},budget_j\} {idj,deadlinej,locj,quej,numj,incentiveji,budgetj}。 i d j id_j idj表示任务的唯一标识符, d e a d l i n e j deadline_j deadlinej表示任务的截止日期,这意味着任务具有实时约束, q u e j que_j quej是工人需要回答的问题。可以是“是/否”问题来验证某些信息;也可以要求工人拍摄某个地方的照片,等等。 l o c j loc_j locj代表任务的物理位置。如果位置是二维坐标,则将任务视为点任务;否则,位置可能由区域(如校园或城市)表示,在这种情况下,任务被视为区域任务。例如,VGI[4]正在众包一个区域任务,在该任务中,工人自愿收集某个区域的地理空间信息,以提高数据质量。 n u m j num_j numj是指完成任务所需的工人数量。在某些系统中,工人被认为是可信和准确的;因此,任务只分配给单个工人。然而,在现实世界中,用户可能并不总是可靠的,因此最好将一个任务分配给多个工人,以确保收到的回答集合的质量。 i n c e n t i v e j i incentive_{ji} incentiveji表示完成任务 j j j时对工人 i i i的奖励,而 b u d g e t j budget_j budgetj表示任务的总预算。
根据任务是否需要单个或多个工人,我们可以将任务分为以下两类。
- 需要单个工人的任务. 这类任务假设工人是可信的、可靠的,这样工人就可以准确地完成空间任务,而不会有任何恶意。仅将任务分配给一个工人就足够了,例如,最近的、最可靠的或最便宜的工人[8]。
- 需要多个工人的任务. 众包的成功依赖于大众的智慧,因此将一个任务分配给多个工人更为合理。亚马逊的Mechanical Turk就是一个使用多个工人执行一项任务的例子。在实践中,并非所有的工人都是值得信赖或守时的。然而,假设大多数工人都可以信任是合理的。因此,多数投票通常是从所有收到的回复中提取基本真相的一种常见方式。尽管让多个工人参与同一个任务的成本更高,但恶意数据更容易被排除。
一旦建立了任务模型和工人模型,我们就可以考虑任务分配或工人选择。一般来说,主要有两种模式:一种是让服务器分配任务,另一种是让工人选择任务。
- **服务器分配任务。**在收集了所有工人的位置后,服务器根据系统优化目标(如最小化总行程)将每个任务分配给工人。这通常会导致系统的全局优化。然而,工人的位置可能会暴露出来。现有的空间众包系统大多将任务分配给工人[8]。
- 工人选择任务. 在此模式下,服务器在线发布各种空间任务,工人可以根据自己的偏好选择任何任务,而无需提前通知服务器[9]。这样做的好处是,工人不需要透露自己目前的工作地点,也有更多的自由选择自己喜欢的工作。但是,这种模式的一个缺点是服务器无法控制空间任务的分配。这可能会导致负载不平衡问题;换句话说,有些任务没有参与者,而其他任务可能有太多志愿者。此外,由于工人根据自己的目标选择任务,例如选择最接近、最简单或报酬更高的任务,因此从系统的角度来看,并不总是会导致全局优化的任务分配。
在这两种模式下,都需要考虑工人的出行路线。当一个工人分配或选择多个任务时,这个问题变得更加突出。这是因为这些任务可能不在同一个位置,所以我们需要通过仔细选择路径和调度任务来避免不必要的位置间旅行。例如,可以使用协调任务分配方法[10],其中系统将任务序列分配给每个工人,同时考虑到从个人历史移动预测的预期轨迹。
回答模型
不同的空间众包应用程序可能会带来不同的任务。在每个任务中,工作者可以贡献不同类型的数据,例如分类数据、连续数据或多媒体数据。有些人可能会要求工人在特定位置验证某些信息,因此回答只是“是/否”;另一些人可能会提出需要更详细回答的问题;还有一些人可能会要求工人使用图片或视频等多媒体数据进行回答。照片可以在不同的时间,从不同的角度,从不同的距离,等等。考虑回答的一个有趣的方法是引入“多样性”的概念的基于可靠多样性的空间众包(RDB-空间众包)[11]。它将时间受限的空间任务分配给动态移动的工人,使得任务能够以高可靠性和时空多样性完成,其中多样性值被表示为所提供回答的熵。由于该问题是NP难问题,因此提供了三个近似解(贪婪、采样和分治)。
优化目标和约束
不同的空间众包系统有不同的焦点,这些焦点从工人或系统的角度可以有所不同。从一个工人的角度来看,他的目标通常是使他的总净报酬最大化,即他从系统中获得的报酬与成本(如旅行成本)之间的差额。为了达到这个目标,一个工人可能会在他的旅行路线上寻求尽可能多的任务,然后工人可能会互相竞争。这可以通过使用不同的博弈论模型来实现帕累托最优(Pareto Optimality)。为了降低成本,工人可以选择最佳路径来完成所有任务,因此在选择任务时需要综合考虑任务调度和路径选择。
从系统的角度来看,目标往往是以最小的成本最大化任务覆盖率,获得最大的质量。
-
最大化任务覆盖率. 这是为了最大化分配任务的数量。为了实现这一目标,服务器首先收集工人的所有位置,然后设计一个策略,以最大化分配的任务的总数。有些系统不考虑工人的不同专业水平,所以他们对工人一视同仁。然后将任务分配问题表示为匹配问题[12],其中工人和任务形成一个二分图;工人和任务之间的边的权重为1。考虑工人的技能水平其他系统通过定义一个专业技能匹配分数来向专家分配任务[13]。专家匹配的得分高于非专家匹配。该问题可以表示为一个加权b-匹配问题。
由于空间众包中固有的旅行性质,任务分配问题往往需要考虑任务调度问题。一旦将一组任务分配给工人,工人必须确定完成任务的最佳方式。例如,为了使分配给每个工人的任务数量最大化,两个精确算法使用动态规划和分支定界策略开发了来解决任务调度问题[9]。此外,还开发了一个基于对分的LALS框架[14],该框架迭代地执行自上而下的递归对分和自下而上的合并过程,以便可以在更小的有希望的空间中本地执行分配和调度。
- 最小化系统成本. 成本可以定义为支付给选定工人的总奖励或所有选定工人的总旅行距离。除了尽量减少总成本外,还可以使用预算作为约束,以最大限度地扩大任务覆盖范围。
- 最大化数据质量. 根据如何定义数据质量,可以应用不同的策略来最大化数据质量。一些人的目标是通过应用多数投票来获得真值,从而使提供正确答案的总人数最大化[2],另一些人的目标是最大化获得正确答案聚合的概率[15],还有一些人的目标是最大化预期的时空多样性[11]。
- 尽可能减少错过最后期限的任务数. 空间任务可能有时间限制,因此工人需要在截止日期前完成任务。在这种情况下,系统可能希望最小化在截止日期内未完成的任务数。再次,任务调度和工人路径选择成为任务分配的关键部分。
图2显示了空间众包的流程。最初,每个工人下载空间众包应用程序,并能够看到任务发布者发布的所有任务。如果服务器将分配任务,则服务器将收集所有工人的信息并招募适当的工人;如果工人将选择任务,则工人将选择适当的任务集以使其报酬最大化。工人选择和任务选择都利用来自工人模型和任务模型的信息。设计了一种激励机制来激励工人完成任务。任务完成后,任务发布者将从工人收集数据。系统从贡献质量、用户可靠性等方面衡量用户的贡献。结果进一步用于调整激励措施。例如,任务发布后,工人的可靠性和准时性可能会发生变化,必须更新对该工人的激励。只要有可用的任务,这个过程就会迭代。
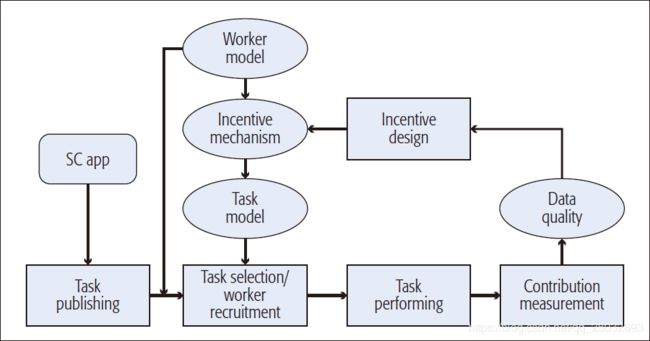
图2. 空间众包系统的一般流程
未来研究方向
现有的关于空间众包的工作已经对空间众包的各个方面进行了研究,接下来我们将着重介绍未来研究的几个方向。
- 考虑激励措施和预算. 虽然激励机制设计在典型的众包中是一个很好的研究课题,但现有的空间众包系统大多依赖于志愿工人或简单的激励机制,其中相同的奖励适用于每个参与者。然而,在现实场景中,人们在参与空间众包时往往会寻求报酬,而且贡献数据的质量因人而异,因此,用一定的报酬和预算对空间众包进行建模更接近现实。对于任务发布者来说,如何分配有限的预算来吸引更多的工人应该为志愿者研究,如何获得尽可能多的奖励是很重要的。
- 将位置隐私集成到空间众包中. 大多数现有的方法使用服务器分配任务模型,服务器收集所有潜在志愿者的位置信息,这可能会揭示工人的位置。虽然学术界对隐私权保护进行了探讨,但这一问题尚未得到充分的研究。例如,任务模型、工人模型和回答模型在不同的情况下会有所不同;因此,在保护工人位置隐私的同时,提供最有效的空间众包是一个挑战。
- 结合服务器分配和工作者选择模型. 大多数现有的任务分配模型都关注于服务器分配任务,这假设工作人员在收到任务分配后应该执行任务。然而,在现实中,由于各种原因(如旅行时间长、劳动强度大)工人可能会拒绝完成任务。因此,将服务器分配模型与工人选择模型相结合,使工人能够选择自己擅长的任务,然后与其他人竞争以获得报酬,是一种更有效的方法。
- 联合优化系统. 现有空间众包研究的优化目标主要是单一目标。然而,实际应用往往需要联合优化几个因素。例如,空间众包应用程序可能需要同时最大化任务分配和数据质量。
- 将SC与社交网络整合. 现有的空间众包工作只考虑工人的地理信息或专业知识特征。然而,在现实世界中,工人之间可能会相互影响,属于社区群体。例如,如果空间任务是拍摄一个地方的照片,那么将任务分配给标记为“摄影师”的社区群体更为合理,因此,结合空间众包任务分配的社区检测是一个有趣的探索思路。
上述问题解决了可能有针对性的技术问题。此外,在现实中,没有可用的数据集可以直接用于空间众包任务。因此,从工程的角度来看,有必要收集真实世界的数据,以帮助验证不同的研究思路和系统,而不是对合成数据进行模拟。
结论
在这篇文章中,我们调查了众包的一个新分支-空间众包-它要求工人在特定的物理位置以完成任务。我们讨论了空间众包的独特性,然后将最新研究分为不同的类别。最后,我们提出了目前文献中尚未研究的几个有希望的问题。
参考文献
[1] A. J. Quinn and B. B. Bederson, “Human Computation: A Survey and Taxonomy of a Growing Field,” Proc. Int’l. Conf. Human Factors in Computing Systems, 2011, pp. 1403–12.
[2] M. Van Exel, E. Dias, and S. Fruijtier, “The Impact of Crowdsourcing on Spatial Data Quality Indicators,” Proc. 6th GIScience Int’l. Conf. Geographic Info. Science, 2010.
[3] H. To, G. Ghinita, and C. Shahabi, “Privgeocrowd: A Toolbox for Studying Private Spatial Crowdsourcing,” Proc. 31st IEEE Int’l. Conf. Data Engineering, 2015, pp. 1404–07.
[4] R. Karam and M. Melchiori, “A Crowdsourcing-Based Framework for Improving Geo-Spatial Open Data,” Proc. IEEE Int’l. Conf. Systems, Man, and Cybernetics, 2013, pp. 468–73.
[5] M. F. Bulut, Y. S. Yilmaz, and M. Demirbas, “Crowdsourcing Location-Based Queries,” Proc. IEEE Int’l. Conf. Pervasive Computing and Communications Wksps., 2011, pp. 513–18.
[6] Z. Chen et al., “Gmission: A General Spatial Crowdsourcing Platform,” VLDB Endowment, vol. 7, no. 13, 2014, pp. 1629–32.
[7] X. Xie, H. Chen, and H. Wu, “Bargain-Based Stimulation Mechanism for Selfi sh Mobile Nodes in Participatory Sensing Network,” Proc. 6th Annual IEEE ComSoc Conf. Sensor, Mesh and Ad Hoc Commun. and Networks, 2009, pp. 1–9.
[8] L. Kazemi and C. Shahabi, “Geocrowd: Enabling Query Answering with Spatial Crowdsourcing,” Proc. 20th ACM Int’l. Conf. Advances in Geographic Information Systems, 2012, pp. 189–98.
[9] D. Deng, C. Shahabi, and U. Demiryurek, “Maximizing the Number of Worker’s Self-Selected Tasks in Spatial Crowdsourcing,” Proc. 21st ACM SIGSPATIAL Int’l. Conf. Advances in Geographic Information Systems, 2013, pp. 324–33.
[10] C. Chen et al., “Towards City-Scale Mobile Crowdsourcing: Task Recommendations Under Trajectory Uncertainties,” Proc. 24th Int’l. Joint Conf. Artifi cial Intelligence, 2015, pp. 1113–19.
[11] P. Cheng et al., “Reliable Diversity-Based Spatial Crowdsourcing by Moving Workers,” PVLDB, vol. 8, no. 10, pp. 1022–33, 2015.
[12] L. Kazemi, C. Shahabi, and L. Chen, “Geotrucrowd: Trustworthy Query Answering with Spatial Crowdsourcing,” Proc. 21st ACM SIGSPATIAL Int’l. Conf. Advances in Geographic Information Systems, 2013, pp. 314–23.
[13] H. To, C. Shahabi, and L. Kazemi, “A Server-Assigned Spatial Crowdsourcing Framework,” ACM Trans. Spatial Algorithms and Systems, vol. 1, no. 1, 2015, p. 2.
[14] D. Deng, C. Shahabi, and L. Zhu, “Task Matching and Scheduling for Multiple Workers in Spatial Crowdsourcing,” Proc. 23rd Int’l. Conf. Advances in Geographic Information Systems, 2015, pp. 21:1–21:10.
[15] I. Boutsis and V. Kalogeraki, “On Task Assignment for Real-Time Reliable Crowdsourcing,” Proc.