基于百度API接口的python数据爬虫解析1【笔记】
目录
- 数据来源
- 数据获取
需求
通过城市出行路径数据爬取,来分析不同场景下的城市出行状况
场景:分布在城市不同位置的小伙伴想一起约饭,从14个起点开车出发,目标餐厅经过初期限定为5个,那么该选择哪个地方吃饭呢?如果能知道14个起点到每个餐厅的路线和时间就好了
数据来源
调用 百度地图开放平台 — 开发 — web服务API 接口
具体在 路线规划API—Direction API v1.0
如何调用呢?要点
- API接口URL
- 参数设置
- 密钥
- 权限设置
详细8个子接口及具体参数含义请点击
- 申请密钥(ak) ,作为访问服务的依据;
- 拼写发送http请求的url,注意需使用第一步申请的ak;
- 接收http请求返回的数据(json或xml格式),根据返回值说明解析数据。
简单示例:
http://api.map.baidu.com/direction/v1?mode=driving&origin=清华大学&destination=北京大学&origin_region=北京&destination_region=北京&output=json&ak=您的ak数据获取
在API 中输入起点和终点的参数来调用结果,利用爬虫爬取结果,主要返回的参数有路径节点的经纬度、对应时间戳
专业的爬虫是一个函数式编程,设计思路:访问网页-读取网页数据(函数1:读总路程总时间;函数2:路径节点信息),
所以先把无数个有用的功能函数先写出来,然后不停地调用就行了
API请求参数
- mode=driving
- 起/终点维/经度
- 起/终点所在区域的纬/经度
- ak
示例:
http://api.map.baidu.com/direction/v1?mode=driving&origin=39.914447,116.323027&destination=39.957935,116.349447&origin_region=%E5%8C%97%E4%BA%AC&destination_region=%E5%8C%97%E4%BA%ACoutput=json&ak=TTQPPd35xwHVNZ3Qjxs5Ah7rqBvpoGvS注意
- 经纬度可以在百度地图-拾取坐标系统中得到
- 在地址中先输入纬度,在输入经度
- URLEncoder.encode(“北京”,”UTF-8”) 会把汉字转成UTF-8编码
返回的结果在网页上看到
搞定参数,网页就会返回相应的数据啦
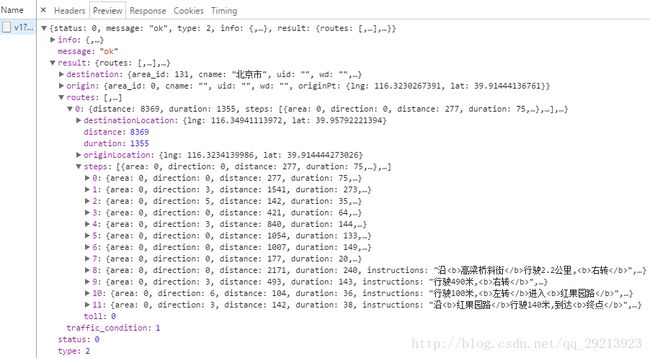
图中返回的results中的routes显示有一条路径0,路段steps显示经过的0-11,共12个路段
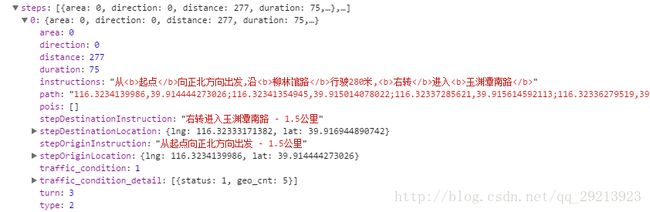
每一段路打开后可以看到path即相应的节点,标准的格式为:经度,纬度 ;经度,纬度;…
发现:一条路径多个路段,每个路段有相应的节点
需要
按顺序爬取每一条路段、节点的经纬度;
增加时间戳来判断节点通过的顺序。
按自己的逻辑写代码块
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests
url = 'http://api.map.baidu.com/direction/v1'
params = {
'mode':'driving',
'origin':'39.914447,116.323027',#中信所,纬度在前
'destination':'39.957935,116.349447',#北京交通大学
'origin_region':'北京',
'destination_region':'北京',
'output':'json',
'ak':'TTQPPd35xwHVNZ3Qjxs5Ah7rqBvpoGvS'
}
# 写入参数,字典格式
r = requests.get(url,params) #用requests包,get的方式
r_js = r.json()
# 网页请求,返回js数据,相当于省去手动输入上面的网址了
# print(type(r_js))说明json数据类型为'dict'
routes_ = r_js['result']['routes'][0]
dis_ = routes_['distance']
time_ = routes_['duration']
print('总行程距离为:'+str(dis_)+'米,总时间为:'+str(time_)+'秒')
#做到这里先试看routes的第1段steps中所有path经纬度
#steps_ = routes_['steps'][0] #变量识别
#path_ = steps['path']
#path_lst =path_.split(';') #变成列表,以;分隔,方便写出到txt文本
#printed(path_lst)
f_path = 'c:\\Users\\intel8808\\Desktop\\result.txt'
f_re = open(f_path,'w')#用到open函数
f_re.write('lng,lat\n')#标签写入
steps_ = routes_['steps']#变量识别
for step in steps_:
path_ = step['path']
point_lst =path_.split(';')
for point in point_lst:
lng = point.split(',')[0]
lat = point.split(',')[1]
f_re.writelines([str(lng),',',str(lat),'\n'])#所有列表文件以经度纬度形式写入txt
f_re.close()
print('finished!')
规范化函数式爬虫代码块
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 6 18:49:55 2017
@author: Hjx
"""
import requests
import time
def file_read(path):
"""
创建函数读取坐标点txt文件
输出一个经纬度列表
path: 文件路径
"""
f = open(path, 'r')
text = []
for i in f.readlines():
i_ = i[:-2]
lng = i_.split(',')[0]
lat = i_.split(',')[1]
text.append(lat + ',' + lng)
# print(text)
return text
def get_params(s,e,c,k):
'''
创建网页参数获取函数
输出参字典列表
s: 起点经纬度字典列表
e: 终点经纬度字典列表
c: 城市名称
k: 密钥
'''
p = []
s_num = 0
e_num = 0
for i in s:
s_num += 1
for j in e:
e_num +=1
params = {
'mode': 'driving',
'origin': i,
'destination': j,
'origin_region': c,
'destination_region': c,
'output': 'json',
'ak': k
}
p.append([params,s_num,e_num])
return(p)
def get_url(u, p):
"""
创建网页信息请求函数
输出网页返回信息
u: 网址url
p: 参数
"""
r = requests.get(u, p)
# print(r.url)
return r.json()
def get_data1(js):
"""
创建路径距离/时间获取函数
输出一个字典,结果包括该条路径的总距离、总时间以及路段数量
"""
result_ = js['result']
routes_ = result_['routes'][0]
distance_ = routes_['distance']
duration_ = routes_['duration']
num = len(routes_['steps'])
data_dic = dict([['dis', distance_], ['time', duration_], ['num', num]])
# print(data_dic)
return data_dic
def get_data2(js, n):
"""
创建路径节点获取函数
输出为一个字典列表,包括每一个节点的经度纬度
"""
result_ = js['result']
routes_ = result_['routes'][0]
steps_ = routes_['steps']
step = steps_[n]
duration = step['duration']
path_points = step['path'].split(';')
point_lst = []
for point in path_points[::5]:
lng = point.split(',')[0]
lat = point.split(',')[1]
point_geo = dict([['lng', lng], ['lat', lat],['duration',duration]])
point_lst.append(point_geo)
# print(point_lst)
return (point_lst)
def main():
# 密钥,需要自己填写!
keys = ''
# 网址,不包括参数
url = 'http://api.map.baidu.com/direction/v1'
# 文件路径,需要自己填写!
path = ''
# 爬取数据所在城市
city = ''
# 调用函数,分别输出起点、终点的经纬度
start_point = file_read(path + 'start.txt')
end_point = file_read(path + 'end.txt')
# 创建结果txt文件,并填写标签
f_result = open(path + 'result.txt', 'w')
f_result.seek(0)
f_result.write('路径编号,起点编号,终点编号,节点经度,节点纬度,时间戳\n')
# 设置爬取开始时间
start_time = time.time()
# 起点编号记录
pathID = 0
# 获取所有起点、终点的参数
p = get_params(start_point,end_point,city,keys)
# print(p)
for p,sn,en in p:
pathID += 1
r_js = get_url(url,p)
data1 = get_data1(r_js)
path_num = data1['num']
point_time = start_time
for m in range(path_num):
points = get_data2(r_js, m)
point_num = len(points)
# 计算出以i为起点,j为终点的路径中,每个节点之间的平均时间
for point in points:
time_per = point['duration'] / point_num
point_time = point_time + time_per
# 算出每个节点的时间点
point_time2 = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(point_time))
# 写入数据
f_result.writelines([
str(pathID),',',
str(sn),',',
str(en),',',
str(point['lng']),',',
str(point['lat']),',',
point_time2,'\n'
])
f_result.close()
if __name__ == '__main__':
main()
print('finished!')