hive(01)、基于hadoop集群的数据仓库Hive搭建实践
在前面hadoop的一系列文中,我们对hadoop有了初步的认识和使用,以及可以搭建完整的集群和开发简单的MapReduce项目,下面我们开始学习基于Hadoop的数据仓库Apache Hive,将结构化的数据文件映射为一张数据库表,将sql语句转换为MapReduce任务进行运行的实践,hadoop系列深入学习的文章还会继续。
分享之前我还是要推荐下我自己创建的大数据学习资料分享群 232840209,不管你是小白还是大牛,小编我都挺欢迎,今天的源码已经上传到群文件,不定期分享干货,包括我自己整理的一份最新的适合2017年学习的前端资料和零基础入门教程,欢迎初学和进阶中的小伙伴
一、Apache Hive简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
二、Apache Hive场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下:
1.支持索引,加快数据查询。
2.不同的存储类型,例如,纯文本文件、HBase 中的文件。
3.将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
4.可以直接使用存储在Hadoop 文件系统中的数据。
5.内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内
置函数无法实现的操作。
6.类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
三、环境准备
1.hadoop集群环境
2.mysql数据库服务
3.mysql数据库驱动
下载地址:https://dev.mysql.com/downloads/connector/j/
4.Apache Hive安装包
官网地址:https://hive.apache.org/
下载地址:http://www.apache.org/dyn/closer.cgi/hive/

环境说明:
和hadoop的主节点公用机器:
192.168.1.10 Master主节点
192.168.1.50 Mysql数据库服务
四、安装准备
1.使用FTP上传Hive程序包到机器上

2.解压上传的hive程序包

3.删除程序包修改目录名称
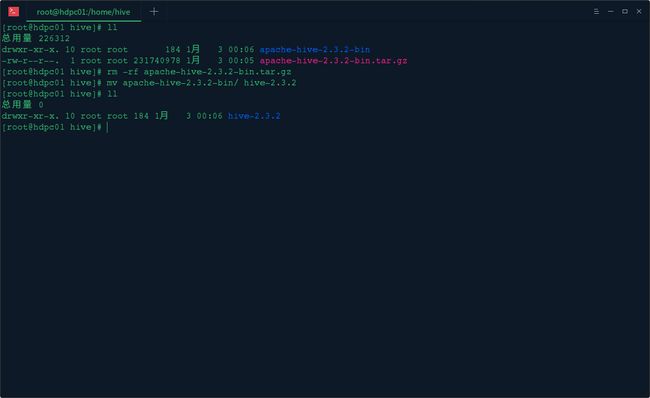
五、安装过程
1.环境变量配置
执行vi /etc/profile输入以下hive的环境变量
export HIVE_HOME=/home/hive/hive-2.3.2
export PATH=$HIVE_HOME/bin:$PATH
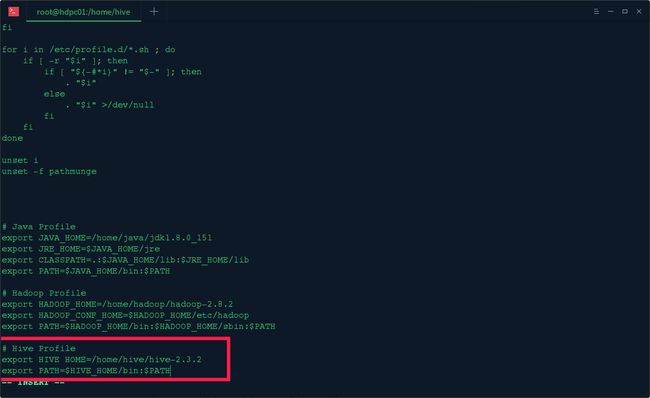
执行source /etc/profile使其立即生效
2.修改hive脚本文件
修改 hive-env.sh脚本文件
首先cp hive-env.sh.template hive-env.sh

然后编辑 vi hive-env.sh脚本
HADOOP_HOME=/home/hadoop/hadoop-2.8.2

修改hive-site.xml 配置文件
首先cp hive-default.xml.template hive-site.xml
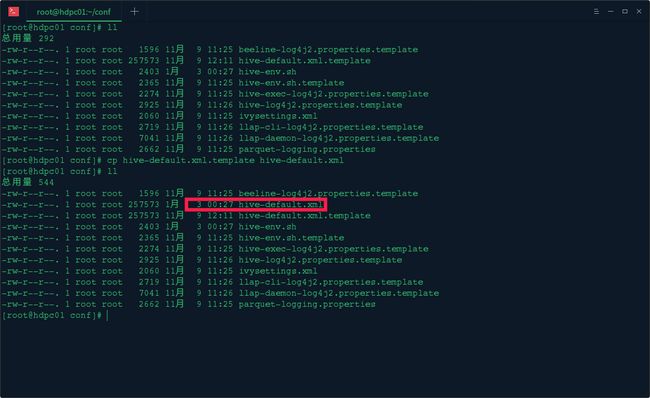
然后编辑vi hive-site.xml 配置文件,配置mysql元数据库信息
characterEncoding=utf8&useSSL=true
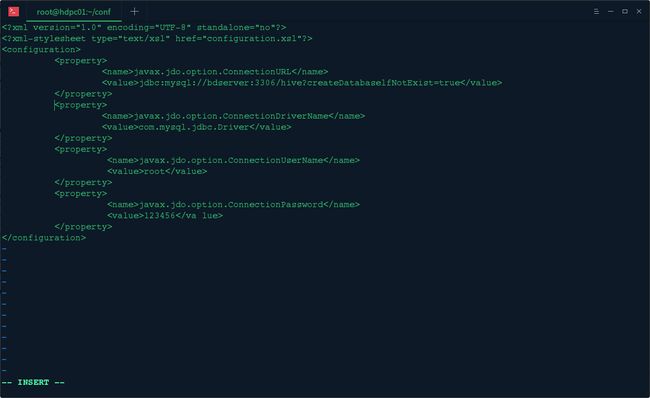
由于hive是默认将元数据保存在本地内嵌的 Derby 数据库中,但是这种做法缺点也很明显,Derby不
支持多会话连接,因此本文将选择mysql作为元数据存储,以上就是配置Hive使用mysq作为元数据的
配置,mysql数据库服务本文已经搭建完成,可参考《Linux开发环境搭建之MySQL安装配置 》
3. 配置日志地址hive-log4j.properties文件
cp hive-log4j.properties.template hive-log4j.properties

然后vi hive-log4j.properties
将hive.log日志的位置改为hive下的tmp目录下:
property.hive.log.dir = /home/hive/hive-2.3.2/logs/${sys:user.name}


3.上传数据库驱动
将下载的mysql数据库驱动上传到hive的lib目录下面

4.在主节点hosts文件中配置元数据主机地址
192.168.1.50 hdpc05

六、验证服务
1.启动hadoop集群
在主节点上启动hadoop集群start-all.sh

2.启动元数据存储服务mysql服务
远程连接我们的mysql主机,然后启动MYSQL服务(如果设置了自启动,则此步骤可以忽略)

启动hive服务端程序hive --service metastore
查看metastore服务是否启动nohup hive --service metastore > metastore.log 2>&1 &

查看hive服务是否启动nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
3.启动hive服务
使用jps -ml查看启动的服务进程:

4.验证hive服务
在主节点执行hive命令,然后在终端执行show databases;

七、问题反馈
1.使用hive服务时报如下错误:
Thu Jan 04 00:18:55 EST 2018 WARN: Establishing SSL connection without server's identity
verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements
SSL connection must be established by default if explicit option isn't set. For compliance with
existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need
either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore
for server certificate verification.

是因为MySQL 5.5.45+, 5.6.26+ and 5.7.6+版本上都要求使用ssl去连接,因此我们需要在连接时使用
useSSL=true
2.启动hive报如下错误:
Exception in thread "main" java.lang.RuntimeException: org.xml.sax.SAXParseException; systemId:
file:/home/hive/hive-2.3.2/conf/hive-site.xml; lineNumber: 6; columnNumber: 93; The reference to
entity "useSSL" must end with the ';' delimiter.

因为在xml文件中 &符号 需要转义 这个根据转义规则更改&为&于是便解决了
3.使用hive连接元数据库报如下错误:
FAILED:SemanticExceptionorg.apache.hadoop.hive.ql.metadata.HiveException:
java.lang.RuntimeException: Unable to instantiate
org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient

问题找到了,原来Hive2需要hive元数据库初始化,我们在终端执行:
schematool -dbType mysql -initSchema

八、总结
本文主要是对hive数据仓库集群的搭建实践,在过程中遇到很多问题,在上名的问题中也都列了出
来,还有问题的解决办法,hive的Metastore服务配置一般有三种方式,后面我们会有专门的一片文章来说
明这三种方式,本文中使用的是第三种方式,这种方式也是生产环境中的使用方式。