keras实现Segnet、FCN、U-Net系列分割网络
介绍
语义分割是计算机视觉领域中非常重要的一个领域,在无人驾驶、图像分析、图像理解领域中有很多应用。在这里就不再详细叙述语义分割算法,具体算法请参考以下链接:
Segnet:https://blog.csdn.net/zhuzemin45/article/details/79709874
U-Net:
https://blog.csdn.net/m_buddy/article/details/79399203
https://blog.csdn.net/natsuka/article/details/78565229
FCN:
https://blog.csdn.net/qq_36269513/article/details/80420363
https://www.cnblogs.com/gujianhan/p/6030639.html
主要源码讲解
train.py
import argparse
import Models , LoadBatches
parser = argparse.ArgumentParser()
parser.add_argument("--save_weights_path", type = str,default='weights/model/')#模型保存的路径
parser.add_argument("--train_images", type = str,default="data/dataset1/images_prepped_train/")#训练的图像
parser.add_argument("--train_annotations", type = str,default="data/dataset1/annotations_prepped_train/")#训练的标签文件
parser.add_argument("--n_classes", type=int,default=10)#分割的类别
parser.add_argument("--input_height", type=int , default =320 )#输入图像的height
parser.add_argument("--input_width", type=int , default =640)#输入图像的width
#这两个参数可以根据要求,自行调节
parser.add_argument('--validate',action='store_false',default=True)#是否需要验证集
parser.add_argument("--val_images", type = str , default = "data/dataset1/images_prepped_test/")#验证集的图像
parser.add_argument("--val_annotations", type = str , default = "data/dataset1/annotations_prepped_test/")#验证集的标签
parser.add_argument("--epochs", type = int, default = 10 )#epochs的数量
parser.add_argument("--batch_size", type = int, default = 2 )#batch_size数量
parser.add_argument("--val_batch_size", type = int, default = 2 )#验证集上的batch_size
parser.add_argument("--load_weights", type = str , default = "")#是否加载权重,这个设置为输入位224x224x3的VGG16权重,如果选中这个选项,输入必须是224x224的图像
parser.add_argument("--model_name", type = str , default = "vgg_segnet")#训练时选择的模型名字,后面有对应
parser.add_argument("--optimizer_name", type = str , default = "adadelta")#优化器的选择
args = parser.parse_args()
train_images_path = args.train_images
train_segs_path = args.train_annotations
train_batch_size = args.batch_size
n_classes = args.n_classes
input_height = args.input_height
input_width = args.input_width
validate = args.validate
save_weights_path = args.save_weights_path
epochs = args.epochs
load_weights = args.load_weights
optimizer_name = args.optimizer_name
model_name = args.model_name
if validate:
val_images_path = args.val_images
val_segs_path = args.val_annotations
val_batch_size = args.val_batch_size
modelFns = { 'vgg_segnet':Models.VGGSegnet.VGGSegnet , 'vgg_unet':Models.VGGUnet.VGGUnet , 'vgg_unet2':Models.VGGUnet.VGGUnet2 , 'fcn8':Models.FCN8.FCN8 , 'fcn32':Models.FCN32.FCN32 }#模型的名字
modelFN = modelFns[ model_name ]
#这里是所有的模型名字,在训练的时候可以根据要求来选择,源代码中对模型内部结构有一一对应源码
m = modelFN( n_classes , input_height=input_height, input_width=input_width)
m.compile(loss='categorical_crossentropy',
optimizer= optimizer_name ,
metrics=['accuracy'])
if len( load_weights ) > 0:
m.load_weights(load_weights)
print("Model output shape" , m.output_shape)
output_height = m.outputHeight
output_width = m.outputWidth
G = LoadBatches.imageSegmentationGenerator( train_images_path , train_segs_path , train_batch_size, n_classes , input_height , input_width , output_height , output_width )
if validate:
G2 = LoadBatches.imageSegmentationGenerator( val_images_path , val_segs_path , val_batch_size, n_classes , input_height , input_width , output_height , output_width )
if not validate:
for ep in range( epochs ):
m.fit_generator( G , 512 , epochs=1 )
m.save_weights( save_weights_path + "." + str( ep ) )
m.save( save_weights_path + str( ep )+".model" )
else:
for ep in range( epochs ):
m.fit_generator( G , 512 , validation_data=G2 , validation_steps=200 , epochs=1 )
m.save_weights( save_weights_path + "." + str( ep ) )
m.save( save_weights_path + str( ep )+".model")

生成的模型,每个epoch会生成一个模型
visualizeDataset.py这个文件是用来可视化训练标签和图像的。
import glob
import numpy as np
import cv2
import random
import argparse
def imageSegmentationGenerator( images_path , segs_path , n_classes ):
assert images_path[-1] == '/'
assert segs_path[-1] == '/'
images = glob.glob( images_path + "*.jpg" ) + glob.glob( images_path + "*.png" ) + glob.glob( images_path + "*.jpeg" )
images.sort()
segmentations = glob.glob( segs_path + "*.jpg" ) + glob.glob( segs_path + "*.png" ) + glob.glob( segs_path + "*.jpeg" )
segmentations.sort()
colors = [ ( random.randint(0,255),random.randint(0,255),random.randint(0,255) ) for _ in range(n_classes) ]
assert len( images ) == len(segmentations)
for im_fn , seg_fn in zip(images,segmentations):
assert( im_fn.split('\\')[-1] == seg_fn.split('\\')[-1] )
img = cv2.imread( im_fn )
seg = cv2.imread( seg_fn )
print(np.unique( seg ))
seg_img = np.zeros_like( seg )
for c in range(n_classes):
seg_img[:,:,0] += ( (seg[:,:,0] == c )*( colors[c][0] )).astype('uint8')
seg_img[:,:,1] += ((seg[:,:,0] == c )*( colors[c][1] )).astype('uint8')
seg_img[:,:,2] += ((seg[:,:,0] == c )*( colors[c][2] )).astype('uint8')
cv2.imshow("img" , img )
cv2.imshow("seg_img" , seg_img )
cv2.waitKey()
parser = argparse.ArgumentParser()
parser.add_argument("--images", type = str,default="data/dataset1/images_prepped_train/" )
parser.add_argument("--annotations", type = str,default="data/dataset1/annotations_prepped_train/" )
parser.add_argument("--n_classes", type=int,default=10 )
args = parser.parse_args()
imageSegmentationGenerator(args.images , args.annotations , args.n_classes )
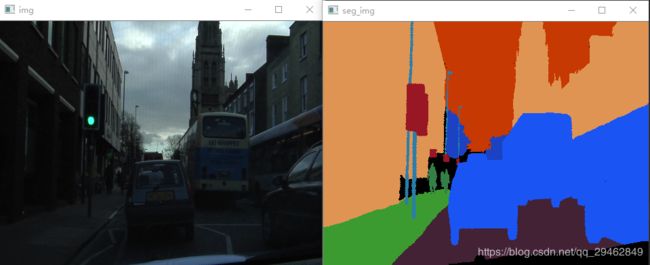
predict.py这个文件是用来测试训练好的模型。
import argparse
import Models , LoadBatches
from keras.models import load_model
import glob
import cv2
import numpy as np
import random
parser = argparse.ArgumentParser()
parser.add_argument("--save_weights_path", type = str,default='weights/model/')
parser.add_argument("--epoch_number", type = int, default = 9 )
parser.add_argument("--test_images", type = str , default = "data/dataset1/test/")
parser.add_argument("--output_path", type = str , default = "data/predictions/")
parser.add_argument("--input_height", type=int , default = 320 )#保持和训练时的图像尺寸大小相同
parser.add_argument("--input_width", type=int , default = 640 )
parser.add_argument("--model_name", type = str , default = "vgg_segnet")#模型和训练时的相同
parser.add_argument("--n_classes", type=int,default=10)
args = parser.parse_args()
n_classes = args.n_classes
model_name = args.model_name
images_path = args.test_images
input_width = args.input_width
input_height = args.input_height
epoch_number = args.epoch_number
modelFns = { 'vgg_segnet':Models.VGGSegnet.VGGSegnet , 'vgg_unet':Models.VGGUnet.VGGUnet , 'vgg_unet2':Models.VGGUnet.VGGUnet2 , 'fcn8':Models.FCN8.FCN8 , 'fcn32':Models.FCN32.FCN32 }
modelFN = modelFns[ model_name ]
m = modelFN( n_classes , input_height=input_height, input_width=input_width )
m.load_weights( args.save_weights_path + str( epoch_number )+'.model')
m.compile(loss='categorical_crossentropy',
optimizer= 'adadelta' ,
metrics=['accuracy'])
output_height = m.outputHeight
output_width = m.outputWidth
images = glob.glob( images_path + "*.jpg" ) + glob.glob( images_path + "*.png" ) + glob.glob( images_path + "*.jpeg" )
images.sort()
colors = [ ( random.randint(0,255),random.randint(0,255),random.randint(0,255) ) for _ in range(n_classes) ]
k=0
for imgName in images:
X = LoadBatches.getImageArr(imgName , args.input_width , args.input_height )
pr = m.predict( np.array([X]) )[0]
pr = pr.reshape(( output_height , output_width , n_classes ) ).argmax( axis=2 )
seg_img = np.zeros( ( output_height , output_width , 3 ) )
for c in range(n_classes):
seg_img[:,:,0] += ( (pr[:,: ] == c )*( colors[c][0] )).astype('uint8')
seg_img[:,:,1] += ((pr[:,: ] == c )*( colors[c][1] )).astype('uint8')
seg_img[:,:,2] += ((pr[:,: ] == c )*( colors[c][2] )).astype('uint8')
seg_img = cv2.resize(seg_img , (input_width , input_height ))
# print(seg_img)
cv2.imwrite("data/predictions/"+str(k)+".png" , seg_img)#保存预测出的图像
k=k+1
预测出的结果图像:

原图像

分割结果图像
由上述结果图像看的出,分割效果还不尽人意,因为在这里10类物体一共才有370幅训练图像,epoch=10,有兴趣的话,可以多搜集些训练数据,加长训练,结果会好很多。
源代码和数据
博文所用的源代码和数据在下面的链接中:
https://download.csdn.net/download/qq_29462849/10823289
关于VGG16的模型,如有需要请见:
https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_th_dim_ordering_th_kernels.h5
下载完毕后,放入到data文件夹中即可