人脸识别学习总结
对人脸识别算法进行了一定程度的学习,从最开始的特征脸到如今的CNN人脸检测,有了较为全面的了解。重点掌握了基于PCA的特征脸检测,LDA线性判别分析(Fisher线性判别),以及基于级联器的Haar特征,LBP特征的人脸检测算法,人脸检测的学习主要是基于OpenCV中人脸识别类FaceRecognizer的学习。目前支持的算法有:
Eigenface特征脸 createEigenFaceRecognizer()
Fisherface createFisherFaceRecognizer()
LBP局部二值直方图 createLBPHFaceRecognizer()
1、Eigenface特征脸(掌握PCA数学原理,人脸识别步骤)
特征脸EigenFace:就相当于把人脸从像素空间变换到另一个空间,在另一个空间中做相似性的计算。EigenFace选择的空间变换方法是PCA,也就是大名鼎鼎的主成分分析。EigenFace方法利用PCA得到人脸分布的主要成分,具体实现是对训练集中所有人脸图像的协方差矩阵进行特征值分解,得到对应的特征向量,这些特征向量就是“特征脸”。
1)将训练集的每一个人脸图像都拉长一列,将他们组合在一起形成一个大矩阵A。假设每个人脸图像是MxM大小,那么拉成一列后每个人脸样本的维度就是N=MxM大小了。假设有20个人脸图像,那么样本矩阵A的维度就是20xN了。
2)将所有的20个人脸求每一列的平均值,就得到了一个“平均脸”,这个“平均脸”矩阵E是一个1xN的向量,将这个向量reshape成MxM矩阵,你就可以把这个脸显示出来。
3)将20个图像都减去那个平均脸图像(即矩阵A的每一行减去向量E),得到差值图像的数据矩阵Φ,矩阵Φ的维度也是20xN。
4)计算协方差矩阵 。协方差矩阵C的维度是NxN,(注意:协方差衡量的是不同像素位置间的相关性,并不是图像与图像之间的相关性)再对其进行特征值分解。就可以得到想要的特征向量(1xN)。这些特征向量如果还原成像素排列的话,其实还蛮像人脸的,所以称之为特征脸。我们可以取前40个特征向量,作为特征脸。
5)将训练集图像和测试集的图像都投影到这些特征向量上了,再对测试集的每个图像找到训练集中的最近邻或者k近邻等处理,进行分类即可。
实现步骤:
1、读取训练样本
注意一定要读取灰度图,并且转换成CV_32FC1
2、求特征向量(特征脸)
int number_principal_compent = 10;//保留最大的主成分数(特征向量数)
//构造pca数据结构
PCA pca(database, Mat(), CV_PCA_DATA_AS_ROW, number_principal_compent);
Mat eigenvectors = pca.eigenvectors.clone();3、求出每个训练样本和测试样本在子空间中的投影系数
Mat cv=pca.project(database);//输入database(m个样本)m*n,m张图像,返回cv是一个m*number_principal_compent 的向量
Mat test = pca.project(testimage);//testimage是输入一张人脸图像:1*n,返回test是一个1*number_principal_compent 的向量,每个值代表该输入图像在每个特征脸上投影的系数。
4、计算每个训练样本和测试样本的欧式距离,取其中最小的为识别图片。
vector< double > distance
for (int i = 0;i < cv.rows;i++)
distance[i]=norm(test,cv.row(i));
auto smallest = min_element(begin(distance), end(distance));
cout << "min element is " << *smallest << " at position " << std::distance(std::begin(distance), smallest) << std::endl;
from:https://blog.csdn.net/weixiao2015/article/details/50282153
2、Fisherface
Fisherface方法是主成分分析(PCA)与Fisher线性判别分析(FLD Fisher Linear Discriminant Analysis)相结合的算法。但也可以单独使用Fisher线性判别分析。
LDA:(有监督,使用类别信息)
基本思想是计算出使Fisher准则函数达到极值的向量,并将此向量作为最佳投影方向,样本在该方向上进行投影,投影后的特征向量具有类间离散度最大,类内离散度最小特点。
假设有C个人的人脸图像,每个人可以有多张图像,所以按人来分,可以将图像分为C类,这节就是要解决如何判别这C个类的问题。判别之前需要先处理下图像,将每张图像按照逐行逐列的形式获取像素组成一个向量,设该向量为x,维数为n,x为列向量(n行1列)
我们需要增加投影向量w的个数(当然每个向量维数和数据是相同的,),设w为: 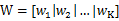
w1、w2等是n维的列向量,所以w是个n行k列的矩阵,这里的k其实可以按照需要随意选取,只要能合理表征原数据就好。x在w上的投影可以表示为: ,所以这里的y是k维的列向量。
,所以这里的y是k维的列向量。
进行人脸识别时,将人脸向量投影到LDA子空间w,得到一个低维向量 : ,其中
,其中 ![W_{lda}=[w_{1},w_{2}....w_{p}],p\leq C-1](http://img.e-com-net.com/image/info8/67ba1bd0169e4702849cdbdd279f5926.gif)
在一个人脸集合上求得k=C-1个特征向量,如何匹配某人脸和数据库内人脸是否相似呢,方法是将这个人脸在k个特征向量上做投影,得到k维的列向量或者行向量,然后和已有的投影求得欧式距离,根据阈值来判断是否匹配。
具体步骤:
1、初始LDA对象,并根据输入样本计算最佳投影向量,即LDA子空间
LDA(const Mat& src, vector labels,int num_components = 0):_num_components(num_components)
{
this->compute(src, labels); //! compute eigenvectors and eigenvalues
} 参数num_components=0采用默认,由给定数据label的类别自动判决,如果类别为C,则默认值是C-1
2、LDA::project,将样本投影到到LDA子空间
Mat LDA::project(InputArray src) {
return subspaceProject(_eigenvectors, Mat(), _dataAsRow ? src : src.getMat().t());
} 数据的处理:
1、循环读入训练图像Mat,并将Mat对象存储到vector
2、将步骤1中的数据传入到LDA的构造函数中,构造函数进行计算处理,从而获得特征矢量。
3、将训练数据利用project函数,投影到特征矢量构造的子空间,即LDA子空间,得到结果。
4、利用project函数,将测试图像投影到LDA子空间,保存返回的Mat矢量,与训练数据得到的结果进行欧式距离比较,距离最小即为识别的人脸。
总结:PCA是为了去除原始数据集中冗余的维度,让投影子空间的各个维度的方差尽可能大,也就是熵尽可能大。LDA是通过数据降维找到那些具有discriminative的维度,使得原始数据在这些维度上的投影,不同类别尽可能区分开来。
LDA+PCA
原始样本采用了200*200大小的图片,形成了40000维的特征矢量,其中包含了大量冗余信息和噪声,导致了LDA方法的不准确。因此一般先采用PCA降维:首先对原始样本图像进行PCA降维,而后再使用LDA进行分类训练;在进行测试时,也先对原始图像进行PCA降维,再利用LDA进行识别,这样可以有效消除冗余信息和噪声的干扰,压缩后的信息对脸部位置也变得不敏感。
转换矩阵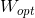 ,可以将样本投影到c-1维空间,其中c表示类别。
,可以将样本投影到c-1维空间,其中c表示类别。

投影公式为: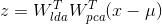
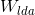 表示LDA的特征矢量构成的,
表示LDA的特征矢量构成的,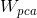 表示PCA的特征矢量构成的,u是PCA分析中所有样本的均值。z列向量的维数为类别数目-1.注意:这里x是n*1列向量,是 n*(样本数−类别数)矩阵,
表示PCA的特征矢量构成的,u是PCA分析中所有样本的均值。z列向量的维数为类别数目-1.注意:这里x是n*1列向量,是 n*(样本数−类别数)矩阵,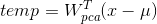 得到(样本数−类别数)*1的列向量,实际上就是压缩后的人脸图像temp,
得到(样本数−类别数)*1的列向量,实际上就是压缩后的人脸图像temp, ( ,这里的是在pca降维后的人脸图像上求得的投影向量,矩阵尺寸为(样本数−类别数)*(类别数-1)
( ,这里的是在pca降维后的人脸图像上求得的投影向量,矩阵尺寸为(样本数−类别数)*(类别数-1)
from:https://blog.csdn.net/zdyueguanyun/article/details/8595549
除了特征脸和Fisher线性判别外,人脸检测与识别有三个常用特征,分别是Haar,HOG,LBP。
Haar
Haar特征其实就是一组特征模板,模板由黑白两区域组成,每个模板代表一种Haar特征,用这些模板在图像上进行滑动,皆可以求出图像每个像素的不同种Haar特征响应,特征响应相当于模板与图像进行卷积,每个特征由白方块下的像素和减去黑方块的像素和来得到。 为了加速计算一般采用在积分图(掌握积分图计算)上进行求解。
一般是用一个滑动子窗口遍历所有图像区域,求出每个待检测子窗口中的特征个数然后求出每个特征的特征值。矩形特征的数量只与子窗口的大小有关。在24×24的检测窗口中,矩形特征的数量约为160,000个。
从这些特征中跳出最优的k个特征,每个特征就是一个弱分类器,使用adaboost算法挑选出m个(迭代m次)分类器,训练处权重,组成一个强分类器,重复adaboost训练处多个强分类器,级联起来。
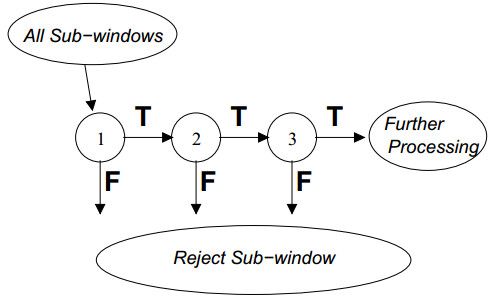
首先将所有待检测的子窗口输入到第一个分类器中,如果某个子窗口判决通过,则进入下一个分类器继续检测识别,否则该子窗口直接退出检测流程。通过这样一种级联的方式可以去除一些误识为目标的子窗口,降低误识率。例如,单个强分类器,99%的目标窗口可以通过,同时50%的非目标窗口也能通过,假设有20个强分类器级联,最终的正确检测率为0.9920=98%,而错误识别率为0.5020≈0.0001%
在一幅图像中,为了能够检测到不同位置的目标区域,需要以一定步长遍历整幅图像;而对于不同大小的目标,则需要改变检测窗口的尺寸,或者固定窗口而缩放图像。这样,最后检测到的子窗口必然存在相互重叠的情况,因此需要进一步对这些重叠的子窗口进行合并,也就是非极大值抑制(NMS,non-maximum suppression),同时剔除零散分布的错误检测窗口。
HOG方向梯度直方图
HOG特征的提取过程:
1、Gamma归一化![]() : 对图像颜色进行Gamma归一化处理,降低局部阴影及背景因素的影响.
: 对图像颜色进行Gamma归一化处理,降低局部阴影及背景因素的影响.
2、计算梯度:通过差分计算出图像在水平方向上及垂直方向上的梯度,然后得到各个像素点的梯度的幅值及方向
3、划分cell
将整个图像窗口划分成大小相同互不重叠的细胞单元cell(如8×8像素),计算出每个cell的梯度大小及方向.然后将每像素的梯度方向在0−180(无向:0-180,有向:0-360)平均分为9个bins,统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor.
4、组合成block,统计block直方图
将2×2个相邻的cell组成大小为16×16的像素块即block.依次将block大小的滑动框在整个图像窗口内,从左到右从上到下滑动,求其梯度方向直方图向量,一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
对于64*128的图像而言,每8*8的像素组成一个cell,每2*2个cell组成一个block(16×16像素),因为每个cell有9个特征,所以每个block内有4*9=36个特征,以8个像素为步长,那么,水平方向将有7个扫描窗口(block),垂直方向将有15个扫描窗口(block),这样检测窗口block的数量有((128-16)/8+1)×((64-16)/8+1)=15×7。也就是说,64*128的图片,总共有36*7*15=3780个特征。
HOG在行人检测和这里的检测中,一个是级联adaboost,另一个是SVM进行判别。
LBP
人脸特征还可以LBP直方图向量进行表达。在图像的每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(每个像素点的LBP值)。然后将一幅图片划分为若干的子区域,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了,LBP即可以用于人脸检测,也可用于人脸识别。更多适用于检测,识别精度可能不高。
怎样选择合适的算法做人脸检测
最近人脸检测算法的流派包括三类以及这三类之间的组合:viola-jones(后面简称vj)框架,dpm和cnn。如果是为了在服务器上搭一个性能不错但是也要兼顾一些速度的人脸检测服务,建议搞cnn和vj这两个,因为dpm实在是太慢了,如果是dpm+cnn更是慢上加慢。相比之下,单独使用cnn就可以获得很不错的性能,同时如果有gpu服务器的话,速度也尚可。vj的话,性能一般但是速度是没问题的。如果准备在移动端or嵌入式上使用(就是计算能力,内存,甚至代码和模型大小都有限制),而且还想实时的话,基本上就只能选vj了,当然特征不一定要用haar。hog,lbp,pixel-difference以及一系列手工设计的特征都可以一战。其实如果待检测的人脸没有特别大幅度的姿态变化,传统的vj就够了,新的方法主要还是在表达能力(说白了就是能检测到更多千奇百怪的人脸)上增强了很多。如果你的人脸没那么奇怪(例如:严重遮挡、旋转的特别厉害、特别不清晰等等),用vj也就够了。
1、人脸检测技术的突破:VJ人脸检测器及其发展
VJ人脸检测之所以器能够获得成功,极大地提高人脸检测速度,其中有三个关键要素:
特征的快速计算方法——积分图,有效的分类器学习方法——AdaBoost,高效的分类策略——级联结构的设计。
VJ人脸检测器采用Haar特征来描述每个窗口。
- 所谓Haar特征,其实就是在窗口的某个位置取一个矩形的小块,
- 然后将这个矩形小块划分为黑色和白色两部分,并分别对两部分所覆盖的像素点(图像上的每个点称为一个像素)的灰度值求和,
- 最后用白色部分像素点灰度值的和减去黑色部分像素点灰度值的和,得到一个Haar特征的值。
在OpenCV级联分类器检测类CascadeClassifier中,使用Adaboost的方法+LBP、HOG、HAAR进行目标检测。
Cascade器是通过将多个强分类器串联在一起,当样本满足所有分类器时,才能判别该样本是人脸,好处是:比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99^20约等于98%,错误接受率也仅为0.5^20约等于0.0001%。这样的效果就可以满足现实的需要了。
强分类器的获取通过adaboost提升算法获得,强分类器是由多个弱分类器“并列”构成,即强分类器中的弱分类器是两两相互独立的。在检测目标时,每个弱分类器独立运行并输出,然后把当前强分类器中每一个弱分类器的输出值相加,这里的弱分类器其实就是Haar特征判别,CART树,仅有一个树桩节点(单个特征)。
如果直接利AdaBoost训练,那么工作量是极其极其巨大的,因为Haar特征太多。所以必须有个筛选的过程,筛选出T个优秀的特征值(即最优弱分类器),然后把这个T个最优弱分类器传给AdaBoost进行训练。
弱分类器的选取过程: 对于每个特征 f,为该特征弱分类器选择使分类误差最小的阈值(最优阈值),此时我们的第一个最优弱分类器就诞生了,依次训练我么会得到每个特征的最优弱分类器。
然后从这些最优弱分类器中挑选最好的T个分类器,分别送入多个Adaboost中进行训练。最终得到多个Adaboost强分类器(意思是:我们把选出的T个分类器分为10组,然后对每组的分类器分别进行Adaboost训练,这样最终我们会得到10个强分类器),最后将这些强分类器进行级联。
2、DPM
。。。
3、CNN
深度学习给目标检测任务点起了一把火,这个火种就是R-CNN。R对应于“Region(区域)”,意指CNN以图像区域作为输入。在检测方法上的变革。
1、首当其冲的是抛弃了滑动窗口范式,取而代之的是一个新的生成候选窗口的环节。
从某种意义上讲,VJ 人脸检测器中多个分类器相级联,每一级分类器都在为接下来的一级分类器提名候选窗口,但是这和 R-CNN 所采用的生成候选窗口的方式有一个重要的区别:
实际上所有的窗口仍然都被检查了一遍,只是不断在排除,这是一种减法式的方案。
相比之下,R-CNN 采用的候选窗口生成方式,是根据图像的某些特征来猜测可能有哪些地方存在待检测的目标,以及这些目标有多大,这是一种从无到有的加法式的方案。
Selective Search是一种典型的候选窗口生成方法,其采用了图像分割的思路:
先基于各种颜色特征将图像划分为多个小块, 然后自底向上地对不同的块进行合并, 在这个过程中,合并前后的每一个块都对应于一个候选窗口, 最后挑出最有可能包含待检测目标的窗口作为候选窗口。
2、第二点非常大的改变在特征提取上:不再采用人工设计的特征,而是用 CNN来自动学习特征。
特征提取过程就是从原始的输入图像(像素颜色值构成的矩阵)变换到特征向量的过程,之前的如 Haar 特征等是科研工作者根据自己的经验和对研究对象的认识设计出来的,换言之人工定义了一个变换,而新的做法是只限定这个变换能够用CNN来表示
好处:不仅避免了人工干预,解放了人力,而且有利于学习到更契合实际数据和目标的特征来,特征提取和分类两个环节可以相互促进,相辅相成;
坏处:自动学习出的特征往往可解释性比较差,不能让人直观地去理解为什么这样提取出特征会更好,另外就是对训练集会产生一定程度的依赖。
3、边框回归
R-CNN在检测过程中引入了一个新的环节:边框回归(“框”念第四声),检测不再仅仅是一个分类问题,它还是一个回归问题:"回归和分类的区别就在于回归模型输出的不是离散的类别标签,而是连续的实数值。"
边框回归指的是在给定窗口的基础上去预测真实检测框的位置和大小,也就是说:
有了候选窗口之后,如果其被判别成了一个人脸窗口,那就会进一步被调整以得到更加精确的位置和大小——和待检测目标贴合得更好。边框回归一方面提供了一个新的角度来定义检测任务,另一方面对于提高检测结果的精确度有比较显著的作用。
用R-CNN进行目标检测的流程是:
1. 先采用如 Selective Search等方法生成候选窗口, 2. 然后用学习好的CNN提取候选窗口对应的特征, 3. 接着训练分类器基于提取的特征对候选窗口进行分类, 4. 最后对判别为人脸的窗口采用边框回归进行修正。
虽然R-CNN带来了目标检测精度的一次巨大提升,然而由于所采用的候选窗口生成方法和深度网络都具有比较高的计算复杂度,因而检测速度非常慢。为了解决R-CNN的速度问题,紧接着出现了Fast R-CNN 和 Faster R-CNN,从名字上可以看到,它们的速度一个比一个快。
1、在 Fast R-CNN 中,直接以整张图像作为输入,先得到整张图对应的卷积特征图, 然后对于每一个候选窗口,在提取特征时直接去整张图对应的卷积特征图上取出窗口对应的区域,从而避免重复计算, 之后只需要通过所谓的RoIPooling层来将所有的区域放缩到相同大小即可。(可以提供几十甚至上百倍的加速)
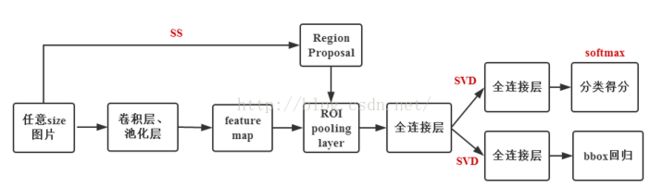
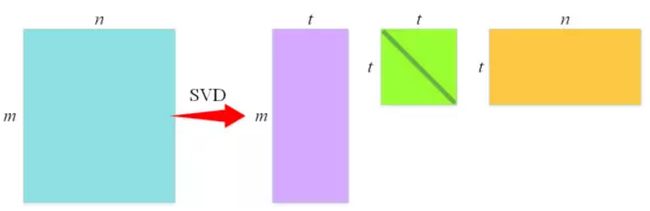
2、Fast R-CNN利用了一种名为 SVD 的矩阵分解技术,其作用是将一个大的矩阵(近似)拆解为三个小的矩阵的乘积,使得拆解之后三个矩阵的元素数目远小于原来大矩阵的元素数目,从而达到在计算矩阵乘法时降低计算量的目的,通过将 SVD应用于全连接层的权值矩阵,处理一张图片所需要的时间能够降低30%。
3、Faster R-CNN开始着眼于生成候选窗口的环节,其采用 CNN 来生成候选窗口,同时让其和分类、边框回归所使用的 CNN 共享卷积层,这样使得两个步骤中可以使用同样的卷积特征图,从而极大地减少计算量。
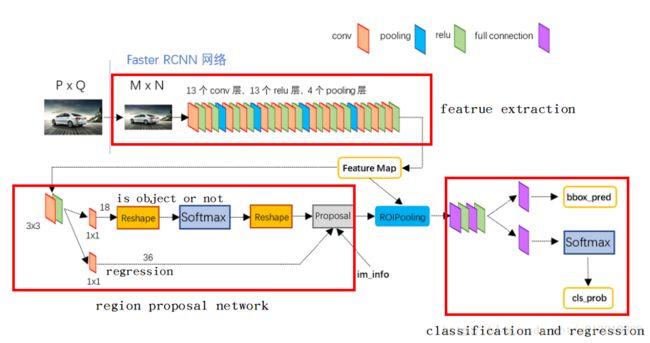
人脸识别概述:https://www.cnblogs.com/jesse123/p/5687069.html
严格定义上的人脸识别分为四个步骤:
①人脸检测:从图片中准确定位到人脸
②人脸对齐: 自动定位出面部关键特征点
③进行特征提取
④对两张人脸图像的特征向量进行对比,计算相似度。
人脸对齐任务即根据输入的人脸图像,自动定位出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点等,并提取相应的部件特征。
1、人脸关键点定位3000fps的LBF方法
2、DCNN方法https://blog.csdn.net/qq_30815237/article/details/89709352,基于它改进算法,将人脸分为内部点和轮廓点;
对人脸检测MTCNN算法做一个简要研究。该MTCNN算法出自深圳先进技术研究院,乔宇老师组,是今年2016的ECCV。