Drools 规则引擎----向领域驱动进步(七)
1.Drools与项目集成
1.1 架构考虑
在设计Drools如何与应用程序组件的其余部分交互时,我们首先需要解决的问题是它们如何适应整个体系结构;我们将对如何将数据输入规则引擎有特定的要求,可以从项目中也可以从外部资源。当然,我么必须决定从规则引擎中如何将信息发布回我们的应用程序,或者如何将它公开到外部应用程序。
在前面的章节中,我们已经看到了Drools和应用程序其余部分之间的通信机制(举几个):
>我们可以使用全局变量在KIE Session之外发送和接收信息,并与不同的系统进行通信。这些全局变量可以表示任何Java组件,从简单的列表,到数据库访问器,到web服务客户端存根,它允许会话与基础设施的任何部分进行通信。
>我们可以使用入口点,对Drools接收的事实数据和事件,去识别它们不同的信息来源。在我们的应用程序中,我们可以使用不同端点的每个入口点来与我们的KIE Session进行通信。
>我们可以注册通道,将从Drools运行时推断出来的新信息发送到任何其他组件。注册侦听器样类,我们可以发送关于特定领域情况的信息。
>我们可以使用任何可插入的组件来检测工作内存中信息状态的变化,以便将关于我们的KIE Session的信息发布到任何形式的数据源。另外,还可以构建其他服务来查询这些数据源。
另外,我们需要根据我们的域逻辑的需要,决定我们的规则是否应该以离散或连续的方式运行。我们将在下一小节中讨论这个案例。
1.1.1 异步和同步设计
吉祥我们在《复杂事件处理》那一节讨论的,我们可能会遇到Drools运行时缺少输入数据可能触发规则的情况。对于这种样例,我们仍然可以将我们的应用程序设计成一组异步组件,这些组件通过公共消息总线连接,比如JMS,并且仍然需要以一种适应异步管理的方式来管理我们的规则。如果我们需要以同步的方式执行业务规则,我们可以采取一系列的操作来简化我们的规则执行到我们的应用程序,包括:
>使用 stateless Kie Sessions,如果在规则执行之间保持状态,这不是我们需要担心的事情。如果您这样做,您可以创建尽可能多的KIE Session,就像潜在的服务请求一样。
>使用全局变量来存储特定的规则执行信息。因为在插入新数据之后,我们将调用fireAllRules,我们可以获得可能修改全局变量的规则执行信息,并在响应中公开它。
如果我们需要以异步方式执行业务规则,我们需要处理一些其他的事情:
>KIE Session可以在不同的线程之间共享,因为它们中的一些可能会插入新的信息,而另一些可能会处理触发规则(即使用 fireUntilHalt)。
>如果规则执行被延迟到不同的线程,那么我们需要考虑我们的规则,以便将特殊情况通知到应用程序的其他部分,同时也是异步的。实现此目的的一种方法是将特殊的侦听器注册为全局变量,该变量负责通知其他组件关于规则检测到的特殊情况,而不是将数据列表作为全局变量来存储延迟到规则执行后的信息。这主要是因为规则执行不会停止规则触发线程。
>当多个源将信息插入到一个基会话中时,入口点就成为一个非常有用的组件,因为它可以让规则很容易地识别信息的来源。
这些考虑将影响应用程序的整个结构,而不仅仅是Drools运行时。Drools异步和同步使用中使用的常见实践的讨论的目的是为了理解我们可以适应任何我们设计应用程序来处理的情况。
一旦我们考虑了这些考虑,我们可能会开始考虑Drools运行时如何与应用程序的其余部分一起部署。
1.2 与应用程序的其余部分集成
Drools在历史上被用于覆盖许多不同的用例。因为,作为一个框架,它充当了一个行为注入组件,我们可以使用它来在我们的应用程序的任何地方注入各种逻辑。由于我们无法涵盖所有可能的集成类型,所以我们将尝试介绍这里最常见的情况,并讨论在不同应用程序中通常可以看到Drools集成的自然演进。
集成Drools的第一个常见步骤通常是将其依赖项和代码嵌入到我们自己的应用程序中,并将其作为一个库使用.
1.2.1 将Drools嵌入到我们的应用程序中
这通常是将Drools与我们自己的应用程序集成的第一个场景,因为它是开始使用Drools的最快方式。我们只需要添加正确的依赖项,并在我们想要的位置直接使用api。下面的图显示了这个集成的第一个阶段:
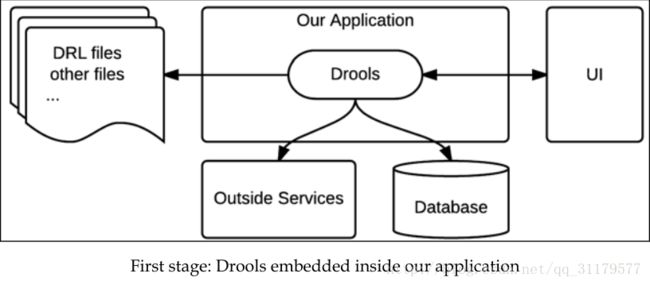
我们在本书中定义的第一个规则项目是遵循这个结构的。正如您所看到的,Drools可以与应用程序的任何层和所有层进行交互,这取决于我们期望完成的工作:
>它可以与UI交互以提供复杂的表单验证
>当规则评估确定需要时,它可以与数据源交互以加载持久的数据
>它可以与外部服务交互,可以将复杂的信息加载到规则中,也可以将消息发送到外部服务,以了解规则执行的结果。
在开发基于规则的项目的第一个阶段中,运行我们的规则所需的所有组件通常包括在我们的应用程序中,包括规则。
这意味着,如果我们想要更改其中的业务规则,我们将不得不重新部署我们的应用程序。
在这些情况下,我们通常需要做的第一件事是,以比应用程序其他部分更快的速度更新规则中的业务逻辑。这导致我们升级我们的体系结构,以便将业务规则作为一个外部依赖项移动,定义为KJAR。我们规则运行时中的组件可以动态地从外部存储库中加载这些规则,如下图所示:
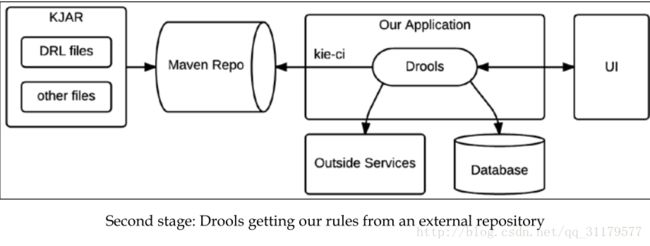
在这个结构中,我们将规则从应用程序中移开。相反,我们从一个外部的JAR里取出它们。这种变化不仅仅是一个项目的重新安排,因为在部署应用程序的时候,包含所有规则的实际JAR不会成为依赖项。相反,Drools运行时将直接从Maven存储库(本地或远程)中读取JAR,并在需要时加载规则。Drools运行时可以通过让CDI直接将与Kie相关的对象直接注入到相应的版本中,使用一个 @KReleaseId注释:
@Inject @KSession
@KReleaseId(groupId = "org.drools.devguide",
artifactId = "chapter-11-kjar",
version = "0.1-SNAPSHOT")
KieSession kSession;或者,我们可以根据代码的特定版本直接构建我们的Kie Container对象。如果这样做,我们可以使用KieScanner来让我们的运行时知道它应该监视存储库,以便将来进行更改,这样运行时就可以不用重新启动就可以更改版本了。
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.newKieContainer(
ks.newReleaseId("org.drools.devguide",
"chapter-11-kjar", "0.1-SNAPSHOT"));
KieScanner kScanner = ks.newKieScanner(kContainer);
kScanner.start(10_000);
KieSession kSession = kContainer.newKieSession();我们应该提一下,在当前这个阶段下,项目里没有其他地方添加了对于这个指定的JAR的直接依赖。依赖解析完全由运行时管理,通过kie:kie-ci这个依赖。你可以在chapter-11/chapter-11-ci 项目里参考。所有的测试在 KieCITest里。
PS:注意:在前面的代码片段中,我们使用一个特定的Maven版本ID。但是,就像在Maven中一样,我们可以使用范围来定义我们想要工作的版本的版本。此外,SNAPSHOT和LATEST的使用可以让Maven组件顾虑它们应该获得的正确版本,而不是返回单个特定的版本。
这是为我们的业务规则建立独立的开发生命周期的必要步骤。这种独立性将允许在不需要重新部署应用程序的情况下,根据需要开发、部署和管理规则。
在我们的应用程序中嵌入Drools的主要缺点是我们所需要完成的所有这些依赖项的数量。我们只使用不几个DRL文件,在我们的类路径中添加了十几种轻量级的依赖项,但是在这个阶段,我们还将在运行时直接拥有一些其他依赖项,但是这些依赖项目可能是我们不想放进类路径下的。因此,将规则作为一个外部组件,势在必行~
1.2.2 Knowledge as a Service
一旦我们的业务规则需求开始增长,包括动态规则重新加载,越来越多的调用,以及与外部系统的交互---我们的观点是,多个应用程序需要在它们自己的运行时复制很多东西,以达到相同的行为,而这可能是通用的业务逻辑。此时的自然过渡的方式是在我们的应用程序之外创建基于knowledge的外部服务。这样就会使得管理依赖项的更新变得更简单了,下图显示了设计此类服务的常用方法:

在前面的图中,我们可以看到两个重要的方面:
>正如所期望的许多客户端应用程序可以访问Drools运行时,而无需向自己的技术栈添加复杂的复杂性,因为这种复杂性完全依赖Drools服务端。
>所有的规则都存储在Maven存储库中.如果规则是可以共享的,那么这就可以允许所有的环境都工作一套相同的业务规则下,如果规则被修改的话,所有的人都可以同时更新这些知识的相同版本。
当我们想要向Drools运行时添加一些自定义配置时,创建这种组件是最合理的---例如,访问遗留的的外部服务,或者当我们想为外部客户提供定制的响应时。我们可以使用公共集成工具,比如Spring框架或者 Apache Camel,来集成其他组件和环境。我们将在进一步的小节中了解如何配置这些元素。
然而,当我们需要在内部使用Drools运行时,(响应的特定结构可以稍后进行调整),并且配置也是标准的按照我们在kmoudle.xml所设置的,我们可以用更简单的方法。Drools提供了一个模块,叫 kie-server,它可以用来配置类似的环境,这些环境只负责运行Drools规则和进程,从外部获取kJAR,如下图所示:

我们将在进一步的小节中了解如何配置kie-server。
正如您所看到的,基于我们的体系结构、设计和面向性能的决策,有多种方法可以集成Drools。让我们讨论一些现成的集成工具,让Drools与我们的组件和应用程序进行交互。
1.3 CDI集成
没用过,不想给翻译了~~~~
1.4 Spring集成
实际的集成 参考 chapter-11/chapter-11-spring项目。
1.4.1 介绍spring框架
Soring框架,是一款使用IOC将不同的java组件绑定在一起的集成框架。通过XML配置文件或者注入注解,让我们将bean构造函数和setter绑定在一起来初始化应用程序的运行时。除了基本功能之外,Spring在市场上已经有几年的时间了,它有很多的采用和可插拔的库,可以让我们将各种功能绑定到我们的应用上,包括数据访问包,面向方面的编程功能,URL绑定和事务管理。
1.4.2 Kie Spring Config example
Drools提供了一个与Spring框架集成的模块,称为“Kie Spring”。它允许我们定义Kie模块、Bases、Sessions,并设置为组件,并将它们与Spring配置的其余部分绑定在一起。现在pom文件里加入依赖:
org.kie
kie-spring
6.3.0.Final
在此之后,我们在Spring上下文文件中定义我们的Kie组件。下面有个样例:
import releaseId-ref="kjarToUse" />
"kjarToUse"
groupId="org.drools.devguide"
artifactId="chapter-11-kjar"
version="0.1-SNAPSHOT" />
"kie-spring-sample">
"kbase1">
"ksession1"/>
在前面的示例中,我们定义了一组重要的组件:
>kie:import和kie:releaseId:有了这两个标签,我们就会宣布我们应该在一个特定的版本中动态加载的上下文,并将其加载到类路径中。
>kie:module, kie:base, 和kie:session:这些组件的使用方式与我们在kmodule。xml中定义的非常相似。它将让我们定义Kie Base的Kie Session,我们稍后可以从其他Spring管理组件引用。
>kie:batch必标签:它允许我们定义需要执行的特定命令集来初始化我们的Kie Session;使用kie:batch标签,我们可以设置全局变量,插入初始事实数据,或者任何我们需要做的事情来初始化我们的Kie session.
我们可以使用chapter-11-spring 这个项目下的KieSpringTest测试类来做测试。如果你想知道所有的标签额信息,可以参考网站: http://docs.jboss.org/drools/release/latest/drools-docs/html/ch13.html
1.5 不写了
1.6 Kie Execution Server
我们已经讨论了在一个孤立的环境中使用特定的Drools服务来运行我们的规则的可能性。Kie Execution Server (我们简称Kie Server)是一个这种服务的开箱机用的实现。它是模块化的,独立的服务器组件,可用于执行规则和过程,配置为WAR文件。目前支持java6以上。
Kie Server的主要目的是为Kie components提供一个运行时环境,并尽可能地使用尽可能少的资源,以便在云环境中轻松部署。Kie Server的每个实例可以创建和使用许多的Kie Containers,它的功能可以通过使用一种叫做“ Kie Server Extensions”的东西来扩展。
当然,KieServer也允许我们提供Kie Server Controllers,这些端点将暴露Kie Server的功能。从某种意义上说,它们将是我们的Kie Server的前端机。
让我们看一下如何在我们的Kie Server实例中配置这些组件。
1.6.1 配置Kie server
Kie Server提供两个默认的Kie Server扩展:一个是为Drools,另一个为JBPM。Kie Server加载它们的方式是通过ServiceLoader标准:在应用程序类路径的META-INF/services文件夹中包含一组文件,其中包含预期接口的不同实现的信息。
在我们的例子里,语气的接口是 KieServerExtension,所以我们需要一个META-INF/services/org.kie.services.api.KieServerExtension 文件,其唯一的内容将是该接口实现类的名称。
在我们的样例中,我们在chapter-11/chapter-11-kie-server文件夹下的项目中有这样一个配置的例子。这个项目通过确保其内部的所有Kie Base都有通过JMX发布的统计信息,从而为Kie Server增加了一个额外的特性。我们有一个叫做 CustomKieServerExtension的java类,它定义了一系列的方法:
>init/destory:这些方法让我们定义如何启动/停止与在我们的Kie Server中提供特定服务相关的相关服务器组件。在我们的示例中,我们只是确保通过询问MBean服务器启用了JMX。
>createContainer/disposeContainer:对于我们的Kie Server中使用的每一个Kie Container来说,我们可以定义这些方法来为他们做特殊的处理。由于我们的功能主要针对的是Kie components,这是我们专门针对创建的Kie components的特殊服务的正确的连接点。在我们的例子中,我们使用 DroolsManagementAgent单例类的特殊的方法注册JMX bean。
DroolsManagementAgent.getInstance().
registerKnowledgeBase(kbase);>getAppComponents:这些方法将被其他扩展(标识是名词,就是其他的extension,类是可继承的嘛)用于获取关于我们在扩展中(若有的话)启动的公开服务的信息.
一旦这些被部署在应用服务器上,我们需要在前面提到的服务器中创建一个带着 kie-server角色的用户,我们将能够通过 http://SERVER/CONTEXT/services/rest/server/这个URL途径访问我们的部署。下面是一个预期响应的例子:
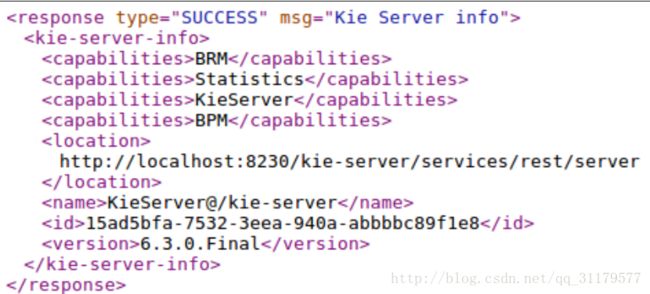
在功能内部,我们可以看到 Statistics(统计信息)是公开的功能之一。这是我们创建的一个扩展。任何功能都可以以这种方式公开。任何功能都可以以这种方式公开,就像对我们的其他 Kie Server扩展的特殊协议展示(也就是说,通过Apache Mina-https://mina.apache.org或RabbitMQ-https://www.rabbitmq.com-通信协议)
PS:当我们在测试中启动我们的样例,它会创建一个Wildfly App Server(http://wildfly.org)的实例,并在里面部署我们的定制的Kie Serrver.为了使它正常工作,我们还在该服务器中创建了一些配置文件。您可以在kie-server-tests项目的POM文件中查看项目的组装步骤 。如果您希望为其他应用程序或Web服务器配置它,这里有一个关于如何为其他环境配置它的详细列表: https://docs.jboss.org/drools/release/6.3.0.Final/drools-docs/html/ch22.html#d0e21933.
1.6.1.1 默认暴露的Kie Serve端点
至于来自Kie Server的API展示,它有两种主要的味道:REST和JMS。这两个端点使用相同的命令来creating(创建)/disposing(处理)容器,并对Kie Sessions进行操作。如果我们使用一个叫做KieServiceClient的客户端实用程序,那么这两个端点的使用方式几乎相同,这个客户端是org.kie.remote:kie-remote-client Maven依赖包提供的。然而,在内部,他们的工作方式却截然不同。
REST通过REST API公开了Kie Containers的功能。它提供了一种与任何类型的系统交互的非常有用的方式,因为任何商业使用的语言现在都带有api来调用REST api。这是与用其他语言编写的应用程序交互的最佳选择,也是对API最初使用的最佳选择。通过Kie Server公开的REST API的完整描述可以在这里找到: https://docs.jboss.org/drools/release/6.3.0.Final/drools-docs/html/ch22.html#d0e22326
JMS通过三个特定的JMS队列公开了Kie Containers的功能,分别为 Kie.SERVER.REQUEST(处理传入的命令请求),KIE.SERVER.RESPONSE(发送回一个响应),和 Kie.SERVER.EXECUTOR(异步调用,主要由BPM组件使用)。因为JMS天生就是异步的,它在创建分布式环境时,这是最好的选择。任何时候可用的每个基Kie Server都可以竞争从这些队列中获取消息,因此,随着请求的增长,可以很自然地管理高可用性和性能。
在使用这些api的代码包中有两个示例,都可以在 chapter-11/chapter-11-kie-server/kie-server-test文件夹下找到,分别是RESTClientExampleTest和JMSClientExampleTest。它们非常相似,除了如何初始化KieServicesClient类:
KieServicesConfiguration config =
KieServicesFactory.newRestConfiguration(
"http://localhost:8080/kie-server/services/rest/server",
"testuser", "test", 60000);
KieServicesClient client = KieServicesFactory.
newKieServicesClient(config);在前面的代码中,我们看到了一个Kie Server Client的初始化块,它在localhost:8080上使用REST作为一个运行在该服务器上的 Kie Server的端点配置。
除了通过代码执行这些部署管理之外,Kie项目还提供了一组可用的工作台工具,这些工具允许我们在不需要编写任何代码的情况下在任何的Kie Server上创建、构建和部署规则定义。这些工具被称为工作台,我们将在下一节中看到它们是如何工作的。
1.7 Kie工作台
还有一个我们之前简单提到过的组成部分,它就是Kie Workbench.Kie工作台是一个web环境,在这里我们可以创建和测试各种类型的Kie资产,比如规则,流程,和数据模型。它是一个非常有用的工具,它将业务人员包括在开发周期中几乎没有技术知识的人员,因为它为规则编写提供了一个用户友好的环境。让我们来到chapter-11-workbench-tests , 编译他,并从 target/wildfly.8.1.0.Final/bin/ 运行独立脚本。用于启动环境。它开始后,您的机器上去访问http://localhost:8080/kie-wb在,使用“testuser”用户名登录和“test”密码到以下页面:
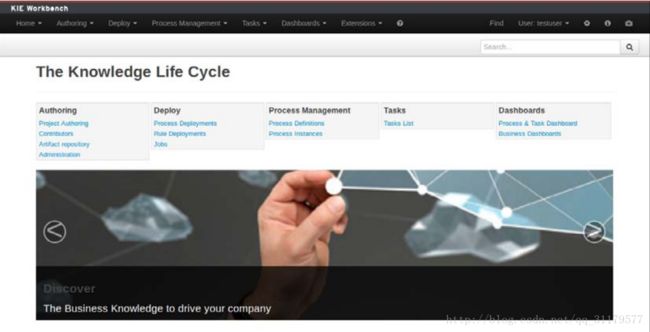
PS注意:这需要几分钟的时间,所以如果你从URL中获得404页面,只需要多花几分钟就可以加载。
一旦加载,如果我们前往如下图所示的Authoring | Project Authoring选项, 我们将能够看到涉及到编辑Kie资产的选项。

从打开的角度来看,我们将有很多可用的屏幕,我们将能够使用New Item选项创建规则、流程、数据模型和更多的元素。我们还可以创建新的项目来对这些资产进行分组,它们将在内部管理,就像Maven项目在Git存储库中进行版本管理一样。我们有一些预定义的项目可以开始玩。
我们将要打开mortgages项目编辑器。这么做,我们将会点击uf-playground选项
为此,我们将点击demo organizational unit(演示组织单元)旁边的uf-playground选项,然后在列表中选择mortgages选项。一旦打开了,点击出现在列表框的一个叫做Open Project Editor的按钮。然后在打开的编辑器内我们可以看到右边,我我们将在顶部看到一组选项。单击Build选项将显示Build & Deploy选项,然后点击它将会在内部Maven存储库中部署项目:
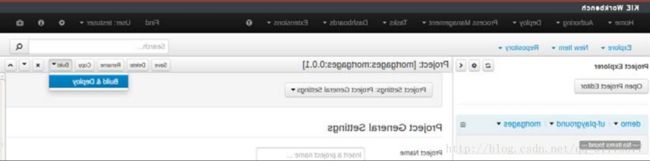
PS:上面的图很诡异,书上是这样的
我们将使用这个已部署的项目来测试一个Kie Execution Server。在工作台中我们使用了大量的工具,但是不幸的是,我们不能在本书中解释它们。有一组非常好的培训课程,用于使用在线上可用的工作台特性,由Eric D. Schabell创建。访问地址是 http://bpmworkshop-onthe.rhcloud.com/brms6_1/lab01.html
我们将集中讨论绑定到我们刚刚讨论的Kie Server的Kie Workspace的特定的组件。一旦我们构建并部署了一个项目,它将在由工作台公开的Maven存储库中可用(对于mortgages项目,你可以在 http://localhost:8080/kie-wb/maven2/mortgages/mortgages/0.0.1/mortgages-0.0.1.jar里找到它)。这个JAR将提供与Kie Workbench使用的相同的凭证。从那里,我们可以通过UI执行部署到任何可用的 Kie Execution Server。要想这么做,那么必须去菜单的顶部的Deploy | Rule Deployments选项,然后点击Register 按钮。
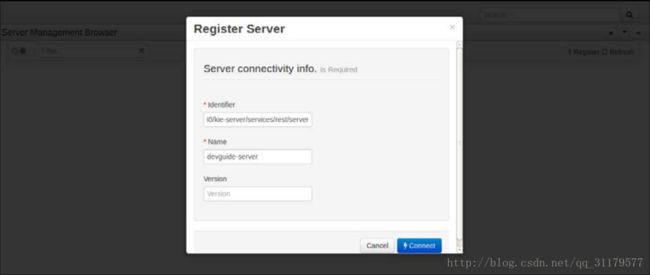
我们已经在相同的环境中部署了一个Kie Execution Server,使用我们在前一节中创建的定制WAR。为了能够部署到它,我们必须用适当的数据注册它。Identifier属性必须有Kie Server的基本REST端点。为了我们的环境,他将会是 http://localhost:8080/kie-server/services/rest/server。而对于Name属性,我们将只会写一些标识文本,比如devguide-server。
一旦Kie Server被创建在Kie工作台的Rule Deployments视图中,我们可以选择它并单击devguide-server行右边可见的加号。通过单击该按钮,我们可以看到带有表单的窗口,用于在给定的Kie Server中部署特定的容器。我们将使用它来部署mortgages项目,如下面的截图所示:

在部署容器之后,我们可以通过单击创建容器右侧的小箭头来查看它的详细信息(它会出现在我们点击的加号按钮下面).我们还可以通过单击创建容器左侧的单选按钮来选择它,并单击规则部署屏幕左上角的Start按钮。在部署并启动容器之后,它可以开始使用给定项目中定义的规则和流程来解决请求。
使用这些工具可以让非技术人员编写、部署和执行规则,而不需要在传统的IDE设置中编写一行代码,一切都可以通过工具完成。这也使得将业务专家引入规则的领域变得简单,也使得领域专家可以在基于drools的项目的开发过程与开发人员合作起来。
1.8 Drools and beyond: extending our functionality
我们已经在这一章中看到过,在整本书中,有很多不同的方法使用Drools。无论我们将其用作嵌入式库、服务还是封闭的产品,其主要目标是使我们的应用程序能够以一种可管理的方式增长。我们必须考虑我们的设计,内部和周围的商业规则,以达到这个目标。我们将尝试介绍一些技巧,这些技巧在过去促进了业务规则支持的应用程序的发展。
我们在Drools组件上看到的功能的第一个扩展是全局变量。如果我们将它们定义为接口或抽象类,那么我们可以通过使用不同的类来定义它们(换言之,测试用例,本地与QA,或者生产环境,等等)。它们是一种非常简单的提供可扩展性的方法,因为它们具有可插入性。
全局变量还提供了一个非常有用的特性,有时会被过度使用;因为我们可以对我们设置的全局变量进行引用,并且我们可以将信息从规则执行中存储到它中,我们最终会在全局变量中存储大量信息这是我们的规则后果----例如,一个规则的日志被触发:
global List rulesExecuted;
rule "example of bad action"
when
//our conditions
Then
//our actions
rulesExecuted.add("example of bad action");
end
KieSession ksession = ...;
List rulesExecuted = new ArrayList();
ksession.setGlobal("rulesExecuted", rulesExecuted);
...
ksession.fireAllRules();
System.out.println(rulesExecuted.size());在前面的例子中,我们可以看到一个公共点,我们开始滥用全局变量。全局变量,如果用于记录关于我们的规则执行的信息,应该用于存储特定的业务相关信息。如果我们只是想要存储哪些规则被触发,或者我们的Drools执行的任何操作,我们最好使用事件监听器。当我们想要审计我们的执行时,事件监听器是最好的选择,而不是获取关于我们的域的特定信息。在设计运行时,我们需要保持不同的思想。
与规则相关的应用程序设计的另一个重要方面是使我们的运行时代码尽可能不确定哪些特定的规则被触发。如果将执行与特定规则的执行结合起来,将很难扩展您的应用程序.在设计我们的规则时也是如此。就像我们之前说过的,规则应该是相互独立的,并且扩展到运行它们的应用程序;在执行我们的规则时,我们应该关心的是他们做出的最终决定.否则,我们的规则中的任何更改或附加组件都将需要被影响到我们的运行时。
这适用于为我们的规则创建测试。我们应该尽量避免验证特定的规则已经被触发,并验证规则执行的结果是否已经被遵守。例如,当测试我们的在线商店案例的执行时,我们应该努力测试是否遵循了规则的最终结果(比如item已经被分类,discount已经被应用,等等),而不仅仅是一个特定的规则是否已经被测试过。更简单地说,我们应该让规则引擎去做这些工作。
至此,Drools翻译完成,希望大家指正翻译的不足。
我相信Drools作为一个规则引擎,对于项目的基础是很重要的。这也是领域驱动DDD所提倡的方式,希望每一位热爱学习的人,都可以灵活运用,并设计出高可用,可拓展的项目,Fighting~~~