-
{% for result in page %}
-
{# object取得才是sku对象 #}
{{ result.object.name }}
¥{{ result.object.price }} {{ result.object.comments }}评价
{% else %}
没有找到您要查询的商品。
{% endfor %}在电商中对于商品,有两个重要的概念:SPU和SKU
iPhone X 就是一个SPU,与商家、颜色、款式、规格、套餐等都无关。
iPhone X 全网通 黑色 256G 就是一个SKU,表示了具体的规格、颜色等信息。
SPU和SKU是怎样的对应关系?
- 一对一?
- 一对多?
============================

class ContentCategory(BaseModel):
"""广告内容类别"""
name = models.CharField(max_length=50, verbose_name='名称')
key = models.CharField(max_length=50, verbose_name='类别键名')
class Meta:
db_table = 'tb_content_category'
verbose_name = '广告内容类别'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class Content(BaseModel):
"""广告内容"""
category = models.ForeignKey(ContentCategory, on_delete=models.PROTECT, verbose_name='类别')
title = models.CharField(max_length=100, verbose_name='标题')
url = models.CharField(max_length=300, verbose_name='内容链接')
image = models.ImageField(null=True, blank=True, verbose_name='图片')
text = models.TextField(null=True, blank=True, verbose_name='内容')
sequence = models.IntegerField(verbose_name='排序')
status = models.BooleanField(default=True, verbose_name='是否展示')
class Meta:
db_table = 'tb_content'
verbose_name = '广告内容'
verbose_name_plural = verbose_name
def __str__(self):
return self.category.name + ': ' + self.title===========================

class GoodsCategory(BaseModel):
"""商品类别"""
name = models.CharField(max_length=10, verbose_name='名称')
parent = models.ForeignKey('self', related_name='subs', null=True, blank=True, on_delete=models.CASCADE, verbose_name='父类别')
class Meta:
db_table = 'tb_goods_category'
verbose_name = '商品类别'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class GoodsChannelGroup(BaseModel):
"""商品频道组"""
name = models.CharField(max_length=20, verbose_name='频道组名')
class Meta:
db_table = 'tb_channel_group'
verbose_name = '商品频道组'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class GoodsChannel(BaseModel):
"""商品频道"""
group = models.ForeignKey(GoodsChannelGroup, verbose_name='频道组名')
category = models.ForeignKey(GoodsCategory, on_delete=models.CASCADE, verbose_name='顶级商品类别')
url = models.CharField(max_length=50, verbose_name='频道页面链接')
sequence = models.IntegerField(verbose_name='组内顺序')
class Meta:
db_table = 'tb_goods_channel'
verbose_name = '商品频道'
verbose_name_plural = verbose_name
def __str__(self):
return self.category.name
class Brand(BaseModel):
"""品牌"""
name = models.CharField(max_length=20, verbose_name='名称')
logo = models.ImageField(verbose_name='Logo图片')
first_letter = models.CharField(max_length=1, verbose_name='品牌首字母')
class Meta:
db_table = 'tb_brand'
verbose_name = '品牌'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class SPU(BaseModel):
"""商品SPU"""
name = models.CharField(max_length=50, verbose_name='名称')
brand = models.ForeignKey(Brand, on_delete=models.PROTECT, verbose_name='品牌')
category1 = models.ForeignKey(GoodsCategory, on_delete=models.PROTECT, related_name='cat1_spu', verbose_name='一级类别')
category2 = models.ForeignKey(GoodsCategory, on_delete=models.PROTECT, related_name='cat2_spu', verbose_name='二级类别')
category3 = models.ForeignKey(GoodsCategory, on_delete=models.PROTECT, related_name='cat3_spu', verbose_name='三级类别')
sales = models.IntegerField(default=0, verbose_name='销量')
comments = models.IntegerField(default=0, verbose_name='评价数')
desc_detail = models.TextField(default='', verbose_name='详细介绍')
desc_pack = models.TextField(default='', verbose_name='包装信息')
desc_service = models.TextField(default='', verbose_name='售后服务')
class Meta:
db_table = 'tb_spu'
verbose_name = '商品SPU'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class SKU(BaseModel):
"""商品SKU"""
name = models.CharField(max_length=50, verbose_name='名称')
caption = models.CharField(max_length=100, verbose_name='副标题')
spu = models.ForeignKey(SPU, on_delete=models.CASCADE, verbose_name='商品')
category = models.ForeignKey(GoodsCategory, on_delete=models.PROTECT, verbose_name='从属类别')
price = models.DecimalField(max_digits=10, decimal_places=2, verbose_name='单价')
cost_price = models.DecimalField(max_digits=10, decimal_places=2, verbose_name='进价')
market_price = models.DecimalField(max_digits=10, decimal_places=2, verbose_name='市场价')
stock = models.IntegerField(default=0, verbose_name='库存')
sales = models.IntegerField(default=0, verbose_name='销量')
comments = models.IntegerField(default=0, verbose_name='评价数')
is_launched = models.BooleanField(default=True, verbose_name='是否上架销售')
default_image_url = models.CharField(max_length=200, default='', null=True, blank=True, verbose_name='默认图片')
class Meta:
db_table = 'tb_sku'
verbose_name = '商品SKU'
verbose_name_plural = verbose_name
def __str__(self):
return '%s: %s' % (self.id, self.name)
class SKUImage(BaseModel):
"""SKU图片"""
sku = models.ForeignKey(SKU, on_delete=models.CASCADE, verbose_name='sku')
image = models.ImageField(verbose_name='图片')
class Meta:
db_table = 'tb_sku_image'
verbose_name = 'SKU图片'
verbose_name_plural = verbose_name
def __str__(self):
return '%s %s' % (self.sku.name, self.id)
class SPUSpecification(BaseModel):
"""商品SPU规格"""
spu = models.ForeignKey(SPU, on_delete=models.CASCADE, related_name='specs', verbose_name='商品SPU')
name = models.CharField(max_length=20, verbose_name='规格名称')
class Meta:
db_table = 'tb_spu_specification'
verbose_name = '商品SPU规格'
verbose_name_plural = verbose_name
def __str__(self):
return '%s: %s' % (self.spu.name, self.name)
class SpecificationOption(BaseModel):
"""规格选项"""
spec = models.ForeignKey(SPUSpecification, related_name='options', on_delete=models.CASCADE, verbose_name='规格')
value = models.CharField(max_length=20, verbose_name='选项值')
class Meta:
db_table = 'tb_specification_option'
verbose_name = '规格选项'
verbose_name_plural = verbose_name
def __str__(self):
return '%s - %s' % (self.spec, self.value)
class SKUSpecification(BaseModel):
"""SKU具体规格"""
sku = models.ForeignKey(SKU, related_name='specs', on_delete=models.CASCADE, verbose_name='sku')
spec = models.ForeignKey(SPUSpecification, on_delete=models.PROTECT, verbose_name='规格名称')
option = models.ForeignKey(SpecificationOption, on_delete=models.PROTECT, verbose_name='规格值')
class Meta:
db_table = 'tb_sku_specification'
verbose_name = 'SKU规格'
verbose_name_plural = verbose_name
def __str__(self):
return '%s: %s - %s' % (self.sku, self.spec.name, self.option.value)=======================
提示:
- 数据库表有了以后,我们现在需要准备商品信息数据和商品图片数据,以便查询和展示。
- 商品信息数据:比如商品编号等都是字符串类型的,可以直接存储在MySQL数据库。
- 商品图片数据:MySQL通常存储的是图片的地址字符串信息。
- 所以图片数据需要进行其他的物理存储。

图片物理存储思考:
图片物理存储方案:
=================================
c语言编写的一款开源的轻量级分布式文件系统。
Client、Tracker server和Storage server。
Client请求Tracker进行文件上传、下载,Tracker再调度Storage完成文件上传和下载。Tracker或Storage进行数据交互。FastDFS提供了upload、download、delete等接口供客户端使用。

![]()
store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。
===================================
思考:
- FastDFS的安装步骤非常的多,涉及的依赖包也很多,当新的机器需要安装FastDFS时,是否需要从头开始安装。
- 我们在学习时拿到ubuntu系统的镜像,在VM虚拟机中运行这个镜像后,为什么就可以直接进行开发,而不需要重新搭建开发环境。
- 在工作中,如何高效的保证开发人员写代码的开发环境与应用程序要部署的生产环境一致性。如果要部署一台新的机器,是否需要从头开始部署。
结论:
- 上述思考的问题,都涉及到相同的工作是否需要重复做。
- 避免相同的工作重复做是容器化技术应用之一。
容器化方案:
- Docker
- Docker的目标之一就是缩短代码从开发、测试到部署、上线运行的周期,让我们的应用程序具备可移植性、易于构建、并易于协作。
客户端-服务端(C/S)架构程序。
Docker 包括三个基本概念:
镜像(Image)
容器(Container)
仓库(Repository)
1.源码安装Docker CE
$ cd docker源码目录
$ sudo apt-key add gpg
$ sudo dpkg -i docker-ce_17.03.2~ce-0~ubuntu-xenial_amd64.deb
2.检查Docker CE是否安装正确
$ sudo docker run hello-world
出现如下信息,表示安装成功

3.启动与停止
- 安装完成Docker后,默认已经启动了docker服务。
# 启动docker
$ sudo service docker start
# 重启docker
$ sudo service docker restart
# 停止docker
$ sudo service docker stop
1.镜像列表
$ sudo docker image ls![]()
* REPOSITORY:镜像所在的仓库名称
* TAG:镜像标签
* IMAGEID:镜像ID
* CREATED:镜像的创建日期(不是获取该镜像的日期)
* SIZE:镜像大小
2.从仓库拉取镜像
# 官方镜像
$ sudo docker image pull 镜像名称 或者 sudo docker image pull library/镜像名称
$ sudo docker image pull ubuntu 或者 sudo docker image pull library/ubuntu
$ sudo docker image pull ubuntu:16.04 或者 sudo docker image pull library/ubuntu:16.04
# 个人镜像
$ sudo docker image pull 仓库名称/镜像名称
$ sudo docker image pull itcast/fastdfs
3.删除镜像
$ sudo docker image rm 镜像名或镜像ID
$ sudo docker image rm hello-world
$ sudo docker image rm fce289e99eb9
1.容器列表
# 查看正在运行的容器
$ sudo docker container ls
# 查看所有的容器
$ sudo docker container ls --all
2.创建容器
$ sudo docker run [option] 镜像名 [向启动容器中传入的命令]
常用可选参数说明:
* -i 表示以《交互模式》运行容器。
* -t 表示容器启动后会进入其命令行。加入这两个参数后,容器创建就能登录进去。即分配一个伪终端。
* --name 为创建的容器命名。
* -v 表示目录映射关系,即宿主机目录:容器中目录。注意:最好做目录映射,在宿主机上做修改,然后共享到容器上。
* -d 会创建一个守护式容器在后台运行(这样创建容器后不会自动登录容器)。
* -p 表示端口映射,即宿主机端口:容器中端口。
* --network=host 表示将主机的网络环境映射到容器中,使容器的网络与主机相同。
3.交互式容器
$ sudo docker run -it --name=ubuntu1 ubuntu /bin/bash
在容器中可以随意执行linux命令,就是一个ubuntu的环境。
当执行 exit 命令退出时,该容器随之停止。
4.守护式容器
# 开启守护式容器
$ sudo docker run -dit --name=ubuntu2 ubuntu
# 进入到容器内部交互环境
$ sudo docker exec -it 容器名或容器id 进入后执行的第一个命令
$ sudo docker exec -it ubuntu2 /bin/bash
如果对于一个需要长期运行的容器来说,我们可以创建一个守护式容器。
在容器内部执行 exit 命令退出时,该容器也随之停止。
5.停止和启动容器
# 停止容器
$ sudo docker container stop 容器名或容器id
# kill掉容器
$ sudo docker container kill 容器名或容器id
# 启动容器
$ sudo docker container start 容器名或容器id
6.删除容器
- 正在运行的容器无法直接删除。
$ sudo docker container rm 容器名或容器id
7.容器制作成镜像
- 为保证已经配置完成的环境可以重复利用,我们可以将容器制作成镜像。
# 将容器制作成镜像
$ sudo docker commit 容器名 镜像名
# 镜像打包备份
$ sudo docker save -o 保存的文件名 镜像名![]()
# 镜像解压
$ sudo docker load -i 文件路径/备份文件
==========================
1.获取FastDFS镜像
# 从仓库拉取镜像
$ sudo docker image pull delron/fastdfs
# 解压教学资料中本地镜像
$ sudo docker load -i 文件路径/fastdfs_docker.tar
2.开启tracker容器
- 我们将 tracker 运行目录映射到宿主机的
/var/fdfs/tracker目录中。
$ sudo docker run -dit --name tracker --network=host -v /var/fdfs/tracker:/var/fdfs delron/fastdfs tr
3.开启storage容器
- TRACKER_SERVER=Tracker的ip地址:22122(Tracker的ip地址不要使用127.0.0.1)
- 我们将 storage 运行目录映射到宿主机的
/var/fdfs/storage目录中。
$ sudo docker run -dti --name storage --network=host -e TRACKER_SERVER=192.168.103.158:22122 -v /var/fdf
4.查看宿主机映射路径

注意:如果无法重启storage容器,可以删除/var/fdfs/storage/data目录下的fdfs_storaged.pid 文件,然后重新运行storage。
1.安装FastDFS客户端扩展
- 安装准备好的
fdfs_client-py-master.zip到虚拟环境中
$ pip install fdfs_client-py-master.zip
$ pip install mutagen
$ pip isntall requests
2.准备FastDFS客户端扩展的配置文件
meiduo_mall.utils.fastdfs.client.conf

base_path=FastDFS客户端存放日志文件的目录
tracker_server=运行Tracker服务的机器ip:22122
3.FastDFS客户端实现文件存储
# 使用 shell 进入 Python交互环境
$ python manage.py shell
# 1. 导入FastDFS客户端扩展
from fdfs_client.client import Fdfs_client
# 2. 创建FastDFS客户端实例
client = Fdfs_client('meiduo_mall/utils/fastdfs/client.conf')
# 3. 调用FastDFS客户端上传文件方法
ret = client.upload_by_filename('/Users/zhangjie/Desktop/kk.jpeg')
ret = {
'Group name': 'group1',
'Remote file_id': 'group1/M00/00/00/wKhnnlxw_gmAcoWmAAEXU5wmjPs35.jpeg',
'Status': 'Upload successed.',
'Local file name': '/Users/zhangjie/Desktop/kk.jpeg',
'Uploaded size': '69.00KB',
'Storage IP': '192.168.103.158'
}
ret = {
'Group name': 'Storage组名',
'Remote file_id': '文件索引,可用于下载',
'Status': '文件上传结果反馈',
'Local file name': '上传文件全路径',
'Uploaded size': '文件大小',
'Storage IP': 'Storage地址'
}![]()
思考:如何才能找到在Storage中存储的图片?
http192.168.103.158
Nginx服务器的IP地址。8888
Nginx服务器的端口。group1/M00/00/00/wKhnnlxw_gmAcoWmAAEXU5wmjPs35.jpeg
http://192.168.103.158:8888/group1/M00/00/00/wKhnnlxw_gmAcoWmAAEXU5wmjPs35.jpeg编写测试代码:
meiduo_mall.utils.fdfs_t.html
============================
$ mysql -h127.0.0.1 -uroot -pmysql meiduo_mall < 文件路径/goods_data.sql
1.准备新的图片数据压缩包

2.删除 Storage 中旧的data目录

3.拷贝新的图片数据压缩包到 Storage,并解压
# 解压命令
sudo tar -zxvf data.tar.gz
4.查看新的
data目录

======================
首页数据由 商品频道分类 和 广告 组成


{
"1":{
"channels":[
{"id":1, "name":"手机", "url":"http://shouji.jd.com/"},
{"id":2, "name":"相机", "url":"http://www.itcast.cn/"}
],
"sub_cats":[
{
"id":38,
"name":"手机通讯",
"sub_cats":[
{"id":115, "name":"手机"},
{"id":116, "name":"游戏手机"}
]
},
{
"id":39,
"name":"手机配件",
"sub_cats":[
{"id":119, "name":"手机壳"},
{"id":120, "name":"贴膜"}
]
}
]
},
"2":{
"channels":[],
"sub_cats":[]
}
}
class IndexView(View):
"""首页广告"""
def get(self, request):
"""提供首页广告界面"""
# 查询商品频道和分类
categories = OrderedDict()
channels = GoodsChannel.objects.order_by('group_id', 'sequence')
for channel in channels:
group_id = channel.group_id # 当前组
if group_id not in categories:
categories[group_id] = {'channels': [], 'sub_cats': []}
cat1 = channel.category # 当前频道的类别
# 追加当前频道
categories[group_id]['channels'].append({
'id': cat1.id,
'name': cat1.name,
'url': channel.url
})
# 构建当前类别的子类别
for cat2 in cat1.subs.all():
cat2.sub_cats = []
for cat3 in cat2.subs.all():
cat2.sub_cats.append(cat3)
categories[group_id]['sub_cats'].append(cat2)
# 渲染模板的上下文
context = {
'categories': categories,
}
return render(request, 'index.html', context)
index.html
1.封装首页商品频道分类到
contents.utils.py文件
def get_categories():
"""
提供商品频道和分类
:return 菜单字典
"""
# 查询商品频道和分类
categories = OrderedDict()
channels = GoodsChannel.objects.order_by('group_id', 'sequence')
for channel in channels:
group_id = channel.group_id # 当前组
if group_id not in categories:
categories[group_id] = {'channels': [], 'sub_cats': []}
cat1 = channel.category # 当前频道的类别
# 追加当前频道
categories[group_id]['channels'].append({
'id': cat1.id,
'name': cat1.name,
'url': channel.url
})
# 构建当前类别的子类别
for cat2 in cat1.subs.all():
cat2.sub_cats = []
for cat3 in cat2.subs.all():
cat2.sub_cats.append(cat3)
categories[group_id]['sub_cats'].append(cat2)
return categories
2.
contents.view.py中使用contents.utils.py文件
class IndexView(View):
"""首页广告"""
def get(self, request):
"""提供首页广告界面"""
# 查询商品频道和分类
categories = get_categories()
# 广告数据
contents = {}
content_categories = ContentCategory.objects.all()
for cat in content_categories:
contents[cat.key] = cat.content_set.filter(status=True).order_by('sequence')
# 渲染模板的上下文
context = {
'categories': categories,
'contents': contents,
}
return render(request, 'index.html', context)=================================


结论:
- 首页商品广告数据由广告分类和广告内容组成。
- 广告分类带有标识符
key,可以利用它确定广告展示的位置。- 确定广告展示的位置后,再查询和渲染出该位置的广告内容。
- 广告的内容还有内部的排序字段,决定了广告内容的展示顺序。
class IndexView(View):
"""首页广告"""
def get(self, request):
"""提供首页广告界面"""
# 查询商品频道和分类
......
# 广告数据
contents = {}
content_categories = ContentCategory.objects.all()
for cat in content_categories:
contents[cat.key] = cat.content_set.filter(status=True).order_by('sequence')
# 渲染模板的上下文
context = {
'categories': categories,
'contents': contents,
}
return render(request, 'index.html', context)
1.轮播图广告
{% for content in contents.index_lbt %}

2.快讯和页头广告
快讯
更多 >
{% for content in contents.index_kx %}
- {{ content.title }}
{% endfor %}
{% for content in contents.index_ytgg %}
{% endfor %}
3.楼层广告(一楼)
 {% for content in contents.index_1f_pd %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_1f_bq %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_1f_pd %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_1f_bq %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_1f_ssxp %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
{% for content in contents.index_1f_cxdj %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
{% for content in contents.index_1f_sjpj %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
4.楼层广告(二楼)
 {% for content in contents.index_2f_pd %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_2f_bq %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_2f_pd %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_2f_bq %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_2f_cxdj %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
{% for content in contents.index_2f_jjhg %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
5.楼层广告(三楼)
 {% for content in contents.index_3f_pd %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_3f_bq %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_3f_pd %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_3f_bq %}
{{ content.title }}
{% endfor %}
{% for content in contents.index_3f_shyp %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
{% for content in contents.index_3f_cfyp %}
-
{{ content.title }}
{{ content.text }}
{% endfor %}
==============================
思考:
- 下图首页页面中图片无法显示的原因。


结论:
- 通过FastDFS上传文件后返回的
'Remote file_id'字段是文件索引。- 文件索引会被我们存储到MySQL数据库。所以将来读取出来的也是文件索引,导致界面无法下载到图片。
解决:
- 重写Django文件存储类的url()方法。
- 在重写时拼接完整的图片下载地址(协议、IP、端口、文件索引)

结论:
- 文件存储类
url()方法的作用:返回name所代表的文件内容的URL。- 文件存储类
url()方法的触发:content.image.url
- 虽然表面上调用的是
ImageField的url方法。但是内部会去调用文件存储类的url()方法。- 文件存储类
url()方法的使用:
- 我们可以通过自定义Django文件存储类达到重写
url()方法的目的。- 自定义Django文件存储类必须提供
url()方法。- 返回name所指的文件对应的绝对URL。
自定义文件存储类的官方文档
class FastDFSStorage(Storage):
"""自定义文件存储系统"""
def _open(self, name, mode='rb'):
"""
用于打开文件
:param name: 要打开的文件的名字
:param mode: 打开文件方式
:return: None
"""
# 打开文件时使用的,此时不需要,而文档告诉说明必须实现,所以pass
pass
def _save(self, name, content):
"""
用于保存文件
:param name: 要保存的文件名字
:param content: 要保存的文件的内容
:return: None
"""
# 保存文件时使用的,此时不需要,而文档告诉说明必须实现,所以pass
pass
1.重写
url()方法
class FastDFSStorage(Storage):
"""自定义文件存储系统,修改存储的方案"""
def __init__(self, fdfs_base_url=None):
"""
构造方法,可以不带参数,也可以携带参数
:param base_url: Storage的IP
"""
self.fdfs_base_url = fdfs_base_url or settings.FDFS_BASE_URL
def _open(self, name, mode='rb'):
......
def _save(self, name, content):
......
def url(self, name):
"""
返回name所指文件的绝对URL
:param name: 要读取文件的引用:group1/M00/00/00/wKhnnlxw_gmAcoWmAAEXU5wmjPs35.jpeg
:return: http://192.168.103.158:8888/group1/M00/00/00/wKhnnlxw_gmAcoWmAAEXU5wmjPs35.jpeg
"""
# return 'http://192.168.103.158:8888/' + name
# return 'http://image.meiduo.site:8888/' + name
return self.fdfs_base_url + name
2.相关配置参数
# 指定自定义的Django文件存储类
DEFAULT_FILE_STORAGE = 'meiduo_mall.utils.fastdfs.fdfs_storage.FastDFSStorage'
# FastDFS相关参数
# FDFS_BASE_URL = 'http://192.168.103.158:8888/'
FDFS_BASE_URL = 'http://image.meiduo.site:8888/'
3.添加访问图片的域名
- 在
/etc/hosts中添加访问Storage的域名
$ Storage的IP 域名
$ 192.168.103.158 image.meiduo.site
4.文件存储类
url()方法的使用
- 以图片轮播图为例:
content.image.url
{% for content in contents.index_lbt %}


============================

1.商品频道分类
contents.utils.py文件中,直接调用即可。2.面包屑导航
3.排序和分页
4.热销排行
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | GET |
| 请求地址 | /list/(?P |
# 按照商品创建时间排序
http://www.meiduo.site:8000/list/115/1/?sort=default
# 按照商品价格由低到高排序
http://www.meiduo.site:8000/list/115/1/?sort=price
# 按照商品销量由高到低排序
http://www.meiduo.site:8000/list/115/1/?sort=hot
2.请求参数:路径参数 和 查询参数
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| category_id | string | 是 | 商品分类ID,第三级分类 |
| page_num | string | 是 | 当前页码 |
| sort | string | 否 | 排序方式 |
3.响应结果:HTML
list.html
4.接口定义
class ListView(View):
"""商品列表页"""
def get(self, request, category_id, page_num):
"""提供商品列表页"""
return render(request, 'list.html')=========================
重要提示:路径参数category_id是商品第三级分类
提示: 对包屑导航数据的查询进行封装,方便后续直接使用。
goods.utils.py
def get_breadcrumb(category):
"""
获取面包屑导航
:param category: 商品类别
:return: 面包屑导航字典
"""
breadcrumb = dict(
cat1='',
cat2='',
cat3=''
)
if category.parent is None:
# 当前类别为一级类别
breadcrumb['cat1'] = category
elif category.subs.count() == 0:
# 当前类别为三级
breadcrumb['cat3'] = category
cat2 = category.parent
breadcrumb['cat2'] = cat2
breadcrumb['cat1'] = cat2.parent
else:
# 当前类别为二级
breadcrumb['cat2'] = category
breadcrumb['cat1'] = category.parent
return breadcrumb
class ListView(View):
"""商品列表页"""
def get(self, request, category_id, page_num):
"""提供商品列表页"""
# 判断category_id是否正确
try:
category = models.GoodsCategory.objects.get(id=category_id)
except models.GoodsCategory.DoesNotExist:
return http.HttpResponseNotFound('GoodsCategory does not exist')
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(category)
# 渲染页面
context = {
'categories':categories,
'breadcrumb':breadcrumb
}
return render(request, 'list.html', context)
=========================
# 按照商品创建时间排序
http://www.meiduo.site:8000/list/115/1/?sort=default
# 按照商品价格由低到高排序
http://www.meiduo.site:8000/list/115/1/?sort=price
# 按照商品销量由高到低排序
http://www.meiduo.site:8000/list/115/1/?sort=hot
class ListView(View):
"""商品列表页"""
def get(self, request, category_id, page_num):
"""提供商品列表页"""
# 判断category_id是否正确
try:
category = models.GoodsCategory.objects.get(id=category_id)
except models.GoodsCategory.DoesNotExist:
return http.HttpResponseNotFound('GoodsCategory does not exist')
# 接收sort参数:如果用户不传,就是默认的排序规则
sort = request.GET.get('sort', 'default')
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(category)
# 按照排序规则查询该分类商品SKU信息
if sort == 'price':
# 按照价格由低到高
sort_field = 'price'
elif sort == 'hot':
# 按照销量由高到低
sort_field = '-sales'
else:
# 'price'和'sales'以外的所有排序方式都归为'default'
sort = 'default'
sort_field = 'create_time'
skus = models.SKU.objects.filter(category=category, is_launched=True).order_by(sort_field)
# 创建分页器:每页N条记录
paginator = Paginator(skus, constants.GOODS_LIST_LIMIT)
# 获取每页商品数据
try:
page_skus = paginator.page(page_num)
except EmptyPage:
# 如果page_num不正确,默认给用户404
return http.HttpResponseNotFound('empty page')
# 获取列表页总页数
total_page = paginator.num_pages
# 渲染页面
context = {
'categories': categories, # 频道分类
'breadcrumb': breadcrumb, # 面包屑导航
'sort': sort, # 排序字段
'category': category, # 第三级分类
'page_skus': page_skus, # 分页后数据
'total_page': total_page, # 总页数
'page_num': page_num, # 当前页码
}
return render(request, 'list.html', context)
1.渲染分页和排序数据
{% for sku in page_skus %}
-

{{ sku.name }}
{% endfor %}
2.列表页分页器
![]()
准备分页器标签
......
# 导入样式时放在最前面导入
准备分页器交互
根据路径参数
category_id查询出该类型商品销量前二的商品。使用Ajax实现局部刷新的效果。
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | GET |
| 请求地址 | /hot/(?P |
2.请求参数:路径参数
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| category_id | string | 是 | 商品分类ID,第三级分类 |
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
| hot_skus[ ] | 热销SKU列表 |
| id | SKU编号 |
| default_image_url | 商品默认图片 |
| name | 商品名称 |
| price | 商品价格 |
{
"code":"0",
"errmsg":"OK",
"hot_skus":[
{
"id":6,
"default_image_url":"http://image.meiduo.site:8888/group1/M00/00/02/CtM3BVrRbI2ARekNAAFZsBqChgk3141998",
"name":"Apple iPhone 8 Plus (A1864) 256GB 深空灰色 移动联通电信4G手机",
"price":"7988.00"
},
{
"id":14,
"default_image_url":"http://image.meiduo.site:8888/group1/M00/00/02/CtM3BVrRdMSAaDUtAAVslh9vkK04466364",
"name":"华为 HUAWEI P10 Plus 6GB+128GB 玫瑰金 移动联通电信4G手机 双卡双待",
"price":"3788.00"
}
]
}
4.接口定义和实现
class HotGoodsView(View):
"""商品热销排行"""
def get(self, request, category_id):
"""提供商品热销排行JSON数据"""
# 根据销量倒序
skus = models.SKU.objects.filter(category_id=category_id, is_launched=True).order_by('-sales')[:2]
# 序列化
hot_skus = []
for sku in skus:
hot_skus.append({
'id':sku.id,
'default_image_url':sku.default_image.url,
'name':sku.name,
'price':sku.price
})
return http.JsonResponse({'code':RETCODE.OK, 'errmsg':'OK', 'hot_skus':hot_skus})
1.模板数据
category_id传递到Vue.js
data: {
category_id: category_id,
},
2.Ajax请求商品热销排行JSON数据
get_hot_skus(){
if (this.category_id) {
let url = '/hot/'+ this.category_id +'/';
axios.get(url, {
responseType: 'json'
})
.then(response => {
this.hot_skus = response.data.hot_skus;
for(let i=0; i {
console.log(error.response);
})
}
},
3.渲染商品热销排行界面
热销排行
-
![]()
[[ sku.name ]]
¥[[ sku.price ]]
===========================
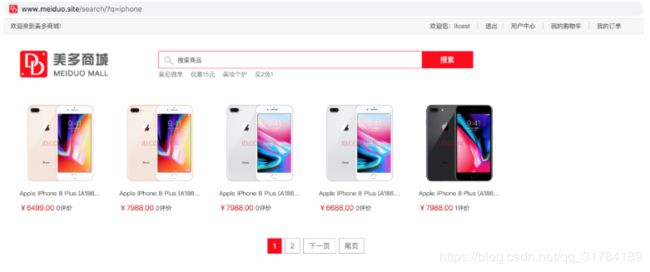
商品搜索需求
商品搜索实现
like关键字实现。全文检索方案
搜索引擎原理

结论:
- 搜索引擎建立索引结构数据,类似新华字典的索引检索页,全文检索时,关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
实现全文检索的搜索引擎,首选的是
Elasticsearch。
分词说明
我是中国人
我、是、中、国、人、中国等等都可以是这句话的关键字。elasticsearch-analysis-ik来实现中文分词处理。1.获取Elasticsearch-ik镜像
# 从仓库拉取镜像
$ sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0
# 解压教学资料中本地镜像
$ sudo docker load -i elasticsearch-ik-2.4.6_docker.tar
2.配置Elasticsearch-ik
elasticsearc-2.4.6目录拷贝到home目录下。/home/python/elasticsearc-2.4.6/config/elasticsearch.yml第54行。![]()
3.使用Docker运行Elasticsearch-ik
$ sudo docker run -dti --name=elasticsearch --network=host -v /home/python/elasticsearch-2.4.6/config:
提示:
- Elasticsearch 的底层是开源库 Lucene。但是没法直接使用 Lucene,必须自己写代码去调用它的接口。
思考:
- 我们如何对接 Elasticsearch服务端?
解决方案:
- Haystack
1.Haystack介绍
Elasticsearch、Whoosh、Solr等等)。2.Haystack安装
$ pip install django-haystack
$ pip install elasticsearch==2.4.1
3.Haystack注册应用和路由
INSTALLED_APPS = [
'haystack', # 全文检索
]
url(r'^search/', include('haystack.urls')),
4.Haystack配置
- 在配置文件中配置Haystack为搜索引擎后端
# Haystack
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://192.168.103.158:9200/', # Elasticsearch服务器ip地址,端口号固定为9200
'INDEX_NAME': 'meiduo_mall', # Elasticsearch建立的索引库的名称
},
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
重要提示:
- HAYSTACK_SIGNAL_PROCESSOR 配置项保证了在Django运行起来后,有新的数据产生时,Haystack仍然可以让Elasticsearch实时生成新数据的索引
1.创建索引类
goods应用中新建search_indexes.py文件,用于存放索引类。from haystack import indexes
from .models import SKU
class SKUIndex(indexes.SearchIndex, indexes.Indexable):
"""SKU索引数据模型类"""
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
"""返回建立索引的模型类"""
return SKU
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
return self.get_model().objects.filter(is_launched=True)
SKUIndex建立的字段,都可以借助Haystack由Elasticsearch搜索引擎查询。text字段我们声明为document=True,表名该字段是主要进行关键字查询的字段。text字段的索引值可以由多个数据库模型类字段组成,具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。2.创建
text字段索引值模板文件
templates目录中创建text字段使用的模板文件templates/search/indexes/goods/sku_text.txt文件中定义{{ object.id }}
{{ object.name }}
{{ object.caption }}
id、name、caption作为text字段的索引值来进行关键字索引查询。3.手动生成初始索引
$ python manage.py rebuild_index

1.准备测试表单
GET/search/q
2.全文检索测试结果

结论:
templates/search/目录中缺少一个search.html文件search.html文件作用就是接收和渲染全文检索的结果。===============================

Haystack返回的数据包括:
query:搜索关键字paginator:分页paginator对象page:当前页的page对象(遍历page中的对象,可以得到result对象)result.objects: 当前遍历出来的SKU对象。
{% for result in page %}
-
{# object取得才是sku对象 #}

{{ result.object.name }}
¥{{ result.object.price }}
{{ result.object.comments }}评价
{% else %}
没有找到您要查询的商品。
{% endfor %}

1.设置每页返回数据条数
HAYSTACK_SEARCH_RESULTS_PER_PAGE可以控制每页显示数量HAYSTACK_SEARCH_RESULTS_PER_PAGE = 52.准备搜索页分页器
......

==============

1.商品频道分类
contents.utils.py文件中,直接调用方法即可。2.面包屑导航
goods.utils.py文件中,直接调用方法即可。3.热销排行
4.商品SKU信息(详情信息)
sku_id可以找到SKU信息,然后渲染模板即可。5.SKU规格信息
SKU可以找到SPU规格和SKU规格信息。6.商品详情介绍、规格与包装、售后服务
SKU可以找到SPU信息,SPU中可以查询出商品详情介绍、规格与包装、售后服务。7.商品评价
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | GET |
| 请求地址 | /detail/(?P |
2.请求参数:路径参数
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| sku_id | string | 是 | 商品SKU编号 |
3.响应结果:HTML
detail.html
4.接口定义
class DetailView(View):
"""商品详情页"""
def get(self, request, sku_id):
"""提供商品详情页"""
return render(request, 'detail.html')
渲染商品频道分类、面包屑导航、商品热销排行
- 将原先在商品列表页实现的代码拷贝到商品详情页即可。
- 添加
detail.js
class DetailView(View):
"""商品详情页"""
def get(self, request, sku_id):
"""提供商品详情页"""
# 获取当前sku的信息
try:
sku = models.SKU.objects.get(id=sku_id)
except models.SKU.DoesNotExist:
return render(request, '404.html')
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 渲染页面
context = {
'categories':categories,
'breadcrumb':breadcrumb,
'sku':sku,
}
return render(request, 'detail.html', context)
提示:为了让前端在获取商品热销排行数据时,能够拿到商品分类ID,我们将商品分类ID从模板传入到Vue.js
data: {
category_id: category_id,
},# 渲染页面
context = {
'categories':categories,
'breadcrumb':breadcrumb,
'sku':sku,
}
return render(request, 'detail.html', context)
提示:为了实现用户选择商品数量的局部刷新效果,我们将商品单价从模板传入到Vue.js
data: {
sku_price: sku_price,
},
1.查询SKU规格信息
class DetailView(View):
"""商品详情页"""
def get(self, request, sku_id):
"""提供商品详情页"""
# 获取当前sku的信息
try:
sku = models.SKU.objects.get(id=sku_id)
except models.SKU.DoesNotExist:
return render(request, '404.html')
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 构建当前商品的规格键
sku_specs = sku.specs.order_by('spec_id')
sku_key = []
for spec in sku_specs:
sku_key.append(spec.option.id)
# 获取当前商品的所有SKU
skus = sku.spu.sku_set.all()
# 构建不同规格参数(选项)的sku字典
spec_sku_map = {}
for s in skus:
# 获取sku的规格参数
s_specs = s.specs.order_by('spec_id')
# 用于形成规格参数-sku字典的键
key = []
for spec in s_specs:
key.append(spec.option.id)
# 向规格参数-sku字典添加记录
spec_sku_map[tuple(key)] = s.id
# 获取当前商品的规格信息
goods_specs = sku.spu.specs.order_by('id')
# 若当前sku的规格信息不完整,则不再继续
if len(sku_key) < len(goods_specs):
return
for index, spec in enumerate(goods_specs):
# 复制当前sku的规格键
key = sku_key[:]
# 该规格的选项
spec_options = spec.options.all()
for option in spec_options:
# 在规格参数sku字典中查找符合当前规格的sku
key[index] = option.id
option.sku_id = spec_sku_map.get(tuple(key))
spec.spec_options = spec_options
# 渲染页面
context = {
'categories':categories,
'breadcrumb':breadcrumb,
'sku':sku,
'specs': goods_specs,
}
return render(request, 'detail.html', context)
2.渲染SKU规格信息
{% for spec in specs %}
{% for option in spec.spec_options %}
{% if option.sku_id == sku.id %}
{{ option.value }}
{% elif option.sku_id %}
{{ option.value }}
{% else %}
{{ option.value }}
{% endif %}
{% endfor %}
{% endfor %}
商品详情、包装和售后信息被归类到商品SPU中,
sku.spu关联查询就可以找到该SKU的SPU信息。
- 商品详情
- 规格与包装
- 售后服务
- 商品评价(18)
- 商品详情:
- {{ sku.spu.desc_detail|safe }}
- 规格与包装:
- {{ sku.spu.desc_pack|safe }}
- 售后服务:
- {{ sku.spu.desc_service|safe }}
{#...商品评价...#}
===========================
提示:
- 统计分类商品访问量 是统计一天内该类别的商品被访问的次数。
- 需要统计的数据,包括商品分类,访问次数,访问时间。
- 一天内,一种类别,统计一条记录。

模型类定义在
goods.models.py中,然后完成迁移建表。
class GoodsVisitCount(BaseModel):
"""统计分类商品访问量模型类"""
category = models.ForeignKey(GoodsCategory, on_delete=models.CASCADE, verbose_name='商品分类')
count = models.IntegerField(verbose_name='访问量', default=0)
date = models.DateField(auto_now_add=True, verbose_name='统计日期')
class Meta:
db_table = 'tb_goods_visit'
verbose_name = '统计分类商品访问量'
verbose_name_plural = verbose_name
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | POST |
| 请求地址 | /detail/visit/(?P |
2.请求参数:路径参数
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| category_id | string | 是 | 商品分类ID,第三级分类 |
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
4.后端接口定义和实现,
- 如果访问记录存在,说明今天不是第一次访问,不新建记录,访问量直接累加。
- 如果访问记录不存在,说明今天是第一次访问,新建记录并保存访问量。
class DetailVisitView(View):
"""详情页分类商品访问量"""
def post(self, request, category_id):
"""记录分类商品访问量"""
try:
category = models.GoodsCategory.objects.get(id=category_id)
except models.GoodsCategory.DoesNotExist:
return http.HttpResponseForbidden('缺少必传参数')
# 获取今天的日期
t = timezone.localtime()
today_str = '%d-%02d-%02d' % (t.year, t.month, t.day)
today_date = datetime.datetime.strptime(today_str, '%Y-%m-%d')
try:
# 查询今天该类别的商品的访问量
counts_data = category.goodsvisitcount_set.get(date=today_date)
except models.GoodsVisitCount.DoesNotExist:
# 如果该类别的商品在今天没有过访问记录,就新建一个访问记录
counts_data = models.GoodsVisitCount()
try:
counts_data.category = category
counts_data.count += 1
counts_data.save()
except Exception as e:
logger.error(e)
return http.HttpResponseServerError('服务器异常')
return http.JsonResponse({'code': RETCODE.OK, 'errmsg': 'OK'})=============================
- 当登录用户在浏览商品的详情页时,我们就可以把详情页这件商品信息存储起来,作为该登录用户的浏览记录。
- 用户未登录,我们不记录其商品浏览记录。

- 虽然浏览记录界面上要展示商品的一些SKU信息,但是我们在存储时没有必要存很多SKU信息。
- 我们选择存储SKU信息的唯一编号(sku_id)来表示该件商品的浏览记录。
- 存储数据:
sku_id
- 用户浏览记录是临时数据,且经常变化,数据量不大,所以我们选择内存型数据库进行存储。
- 存储位置:
Redis数据库 3号库
CACHES = {
"history": { # 用户浏览记录
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/3",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
},
}
- 由于用户浏览记录跟用户浏览商品详情的顺序有关,所以我们选择使用Redis中的
list类型存储 sku_id- 每个用户维护一条浏览记录,且浏览记录都是独立存储的,不能共用。所以我们需要对用户的浏览记录进行唯一标识。
- 我们可以使用登录用户的ID来唯一标识该用户的浏览记录。
- 存储类型:
'history_user_id' : [sku_id_1, sku_id_2, ...]
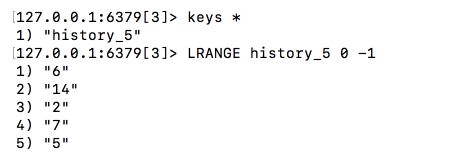
- SKU信息不能重复。
- 最近一次浏览的商品SKU信息排在最前面,以此类推。
- 每个用户的浏览记录最多存储五个商品SKU信息。
- 存储逻辑:先去重,再存储,最后截取。
============================
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | POST |
| 请求地址 | /browse_histories/ |
2.请求参数:JSON
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| sku_id | string | 是 | 商品SKU编号 |
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
4.后端接口定义和实现
class UserBrowseHistory(LoginRequiredJSONMixin, View):
"""用户浏览记录"""
def post(self, request):
"""保存用户浏览记录"""
# 接收参数
json_dict = json.loads(request.body.decode())
sku_id = json_dict.get('sku_id')
# 校验参数
try:
models.SKU.objects.get(id=sku_id)
except models.SKU.DoesNotExist:
return http.HttpResponseForbidden('sku不存在')
# 保存用户浏览数据
redis_conn = get_redis_connection('history')
pl = redis_conn.pipeline()
user_id = request.user.id
# 先去重
pl.lrem('history_%s' % user_id, 0, sku_id)
# 再存储
pl.lpush('history_%s' % user_id, sku_id)
# 最后截取
pl.ltrim('history_%s' % user_id, 0, 4)
# 执行管道
pl.execute()
# 响应结果
return http.JsonResponse({'code': RETCODE.OK, 'errmsg': 'OK'})
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | GET |
| 请求地址 | /browse_histories/ |
2.请求参数:
无
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
| skus[ ] | 商品SKU列表数据 |
| id | 商品SKU编号 |
| name | 商品SKU名称 |
| default_image_url | 商品SKU默认图片 |
| price | 商品SKU单价 |
{
"code":"0",
"errmsg":"OK",
"skus":[
{
"id":6,
"name":"Apple iPhone 8 Plus (A1864) 256GB 深空灰色 移动联通电信4G手机",
"default_image_url":"http://image.meiduo.site:8888/group1/M00/00/02/CtM3BVrRbI2ARekNAAFZsBqChgk3141998",
"price":"7988.00"
},
......
]
}
4.后端接口定义和实现
class UserBrowseHistory(LoginRequiredJSONMixin, View):
"""用户浏览记录"""
def get(self, request):
"""获取用户浏览记录"""
# 获取Redis存储的sku_id列表信息
redis_conn = get_redis_connection('history')
sku_ids = redis_conn.lrange('history_%s' % request.user.id, 0, -1)
# 根据sku_ids列表数据,查询出商品sku信息
skus = []
for sku_id in sku_ids:
sku = models.SKU.objects.get(id=sku_id)
skus.append({
'id': sku.id,
'name': sku.name,
'default_image_url': sku.default_image.url,
'price': sku.price
})
return http.JsonResponse({'code': RETCODE.OK, 'errmsg': 'OK', 'skus': skus})
Vue渲染用户浏览记录
