Java8 Stream API 之 IntPipeline(一) 源码解析
目录
一、PipelineHelper / AbstractPipeline
二、Sink
三、IntPipeline
1、filter / peek
2、forEach / forEachOrdered
3、ForEachOps
4、测试用例
5、IntStream range/rangeClosed
6、ForEachTask
7、ForEachOrderedTask
本篇博客继续上一篇《Java8 Stream API 之 IntStream 用法全解》探讨IntPipeline 各接口的实现细节。
一、PipelineHelper / AbstractPipeline
PipelineHelper 是一个抽象类,用于帮助流处理动作的执行,但是该类的所有方法都是抽象方法,即相当于一个接口类,AbstractPipeline继承自PipelineHelper,提供了所有抽象方法的默认实现,除了makeNodeBuilder以外,该接口包含的方法如下:
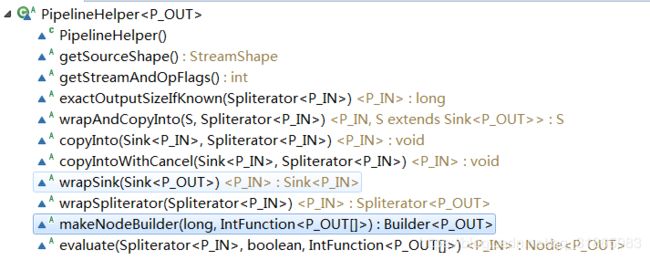
AbstractPipeline定义了不少属性和方法,相关方法的说明在后面子类的实现中再做探讨,这里重点关注其属性定义和构造方法实现,如下:
/**
* 初始的包含待处理元素的流
*/
@SuppressWarnings("rawtypes")
private final AbstractPipeline sourceStage;
/**
* 上一个流处理动作,如果当前实例是第一个流处理动作,则该属性为null
*/
@SuppressWarnings("rawtypes")
private final AbstractPipeline previousStage;
/**
* 当前流处理动作的操作标识
*/
protected final int sourceOrOpFlags;
/**
* 当前流处理动作的下一个流处理动作
*/
@SuppressWarnings("rawtypes")
private AbstractPipeline nextStage;
/**
* 非终止类型的流处理动作的个数
*/
private int depth;
/**
* 在此之前的流处理动作包括当前流处理的所有操作标识
*/
private int combinedFlags;
/**
* 当前流处理对应的Spliterator
*/
private Spliterator sourceSpliterator;
/**
* The source supplier. Only valid for the head pipeline. Before the
* pipeline is consumed if non-null then {@code sourceSpliterator} must be
* null. After the pipeline is consumed if non-null then is set to null.
*/
private Supplier> sourceSupplier;
/**
* 表示流处理是否已经开始
*/
private boolean linkedOrConsumed;
/**
* True if there are any stateful ops in the pipeline; only valid for the
* source stage.
*/
private boolean sourceAnyStateful;
private Runnable sourceCloseAction;
/**
* 是否并行流处理
*/
private boolean parallel; AbstractPipeline(Supplier> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSupplier = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
AbstractPipeline(Spliterator source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
//previousStage表示上一个流处理动作
AbstractPipeline(AbstractPipeline previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
//设置previousStage同当前Stage的关系
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
//设置当前Stage的属性
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful()) //opIsStateful由子类实现
sourceStage.sourceAnyStateful = true;
//depth属性加1
this.depth = previousStage.depth + 1;
}AbstractPipeline是抽象类,定义了多个必须由子类实现的抽象方法,如下:

其中StreamShape是一个枚举值,表示Stream API支持的流元素类型,其定义如下:

各方法的用途在后面的子类实现中会逐一讲解。
二、Sink
Sink表示多个流处理动作中的一个,比如fiter方法对应的流处理动作,该类是一个继承自Consumer的接口类,其定义如下:
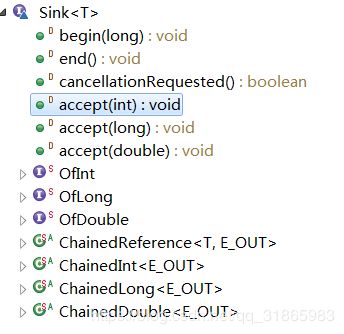
待D标记的6个方法都是空实现的default方法,要求在开始第一次调用accept方法前必须调用begin方法通知Sink 即将处理流中的元素,begin方法的参数表示即将处理的流元素的个数,如果个数未知则传-1;在流中所有的元素都处理完成后必须调用end方法通过Sink流处理已经结束了。在调用end方法后,不能再次调用accept方法,除非再次调用begin方法。如果不希望Sink继续处理,可以调用cancellationRequested方法终止流元素的处理。
Of开头的三个接口类继承自Sink,改写了对应类型的accept方法,以OfInt为例说明,如下:

其中Tripwire是java.util.stream相关类使用的打印debug日志的工具类,如果org.openjdk.java.util.stream.tripwire属性为true,则Tripwire.ENABLED为true,默认为false。
Chained开头的四个类都是Sink接口的抽象实现类,以ChainedInt为例说明,其实现如下:

这里的downstream表示下一个流处理动作对应的Sink,子类只需实现其accept方法即可。
三、IntPipeline
IntPipeline没有新增属性,我们直接看起方法的实现细节。IntPipeline实现了AbstractPipeline的大部分抽象方法,除了opIsStateful和opWrapSink外,这两个方法由子类去实现。
1、filter / peek
filter方法用于过滤流中的元素,peek通常用于打印流处理中的元素,其实现如下:
@Override
public final IntStream filter(IntPredicate predicate) {
Objects.requireNonNull(predicate); //非空校验
//返回一个新的IntStream实例
return new StatelessOp(this, StreamShape.INT_VALUE,
StreamOpFlag.NOT_SIZED) {
//传入的sink表示下一个流处理动作,被赋值给downstream
@Override
Sink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedInt(sink) {
@Override
public void begin(long size) {
//通知下一个Sink流处理开始,个数未知
//此处downstream实际就是上面的入参sink
downstream.begin(-1);
}
@Override
public void accept(int t) {
if (predicate.test(t))
//返回true以后才将t传递给下一个Sink
downstream.accept(t);
}
};
}
};
}
@Override
public final IntStream peek(IntConsumer action) {
Objects.requireNonNull(action);
return new StatelessOp(this, StreamShape.INT_VALUE,
0) {
@Override
Sink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedInt(sink) {
@Override
public void accept(int t) {
action.accept(t);
//不做任何处理,将t直接传递给下一个流处理动作
downstream.accept(t);
}
};
}
};
}
abstract static class StatelessOp extends IntPipeline {
StatelessOp(AbstractPipeline upstream,
StreamShape inputShape, //描述流元素的类型
int opFlags) {
super(upstream, opFlags);
//校验两者流元素类型一致
assert upstream.getOutputShape() == inputShape;
}
@Override
final boolean opIsStateful() {
return false; //返回false,表示无状态操作
}
}
//upstream 表示上一个流处理动作
IntPipeline(AbstractPipeline upstream, int opFlags) {
super(upstream, opFlags);
}
@Override
final StreamShape getOutputShape() {
return StreamShape.INT_VALUE;
} 2、forEach / forEachOrdered
这两个都是用来遍历流中的元素,会终止流,不返回一个新的流,其实现如下:
@Override
public void forEach(IntConsumer action) {
evaluate(ForEachOps.makeInt(action, false));
}
@Override
public void forEachOrdered(IntConsumer action) {
evaluate(ForEachOps.makeInt(action, true));
}
//父类AbstractPipeline的方法,用来执行某个关闭流的流处理动作
final R evaluate(TerminalOp terminalOp) {
//校验两者元素类型一致
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
//如果流处理已经开始则抛出异常
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true; //原来为false,置为true
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) //并行执行
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())); //串行执行
}
@Override
public final boolean isParallel() {
return sourceStage.parallel;
}
//获取sourceStage对应的sourceSpliterator
@SuppressWarnings("unchecked")
private Spliterator sourceSpliterator(int terminalFlags) {
// Get the source spliterator of the pipeline
Spliterator spliterator = null;
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}
else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
if (isParallel() && sourceStage.sourceAnyStateful) {
// Adapt the source spliterator, evaluating each stateful op
// in the pipeline up to and including this pipeline stage.
// The depth and flags of each pipeline stage are adjusted accordingly.
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;
u != e;
u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
// Clear the short circuit flag for next pipeline stage
// This stage encapsulates short-circuiting, the next
// stage may not have any short-circuit operations, and
// if so spliterator.forEachRemaining should be used
// for traversal
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
//获取经过包装的在并行条件下执行的Spliterator实现
spliterator = p.opEvaluateParallelLazy(u, spliterator);
// Inject or clear SIZED on the source pipeline stage
// based on the stage's spliterator
thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED)
? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED
: (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED;
}
p.depth = depth++;
p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags);
}
}
if (terminalFlags != 0) {
// Apply flags from the terminal operation to last pipeline stage
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
} 其中TerminalOp是Stream API内部的一个接口类,表示一个会终止流的操作,该接口的定义如下:
interface TerminalOp {
default StreamShape inputShape() { return StreamShape.REFERENCE; }
default int getOpFlags() { return 0; }
default R evaluateParallel(PipelineHelper helper,
Spliterator spliterator) {
if (Tripwire.ENABLED)
Tripwire.trip(getClass(), "{0} triggering TerminalOp.evaluateParallel serial default");
return evaluateSequential(helper, spliterator);
}
R evaluateSequential(PipelineHelper helper,
Spliterator spliterator);
} 该类的子类如下:

其中ReduceOp下的子类都是匿名内部类,是reduce,max,min等方法的底层实现,FindOp是findFirst / findAny 方法的底层实现,ForEachOp是forEach / forEachOrdered 方法的底层实现,MatchOp是 anyMatch / allMatch / noneMatch 方法的底层实现。
3、ForEachOps
ForEachOps定义的方法和类如下:

4个静态方法都是返回对应类型的ForEachOp的实现类,以makeInt为例说明,其实现如下:

ForEachOp本身是抽象类,有4个子类,与静态方法一一对应,如下:

ForEachOp实现了TerminalOp和TerminalSink两个接口,其中TerminalSink继承自Sink和Supplier接口,其定义如下:

ForEachOp的实现如下:
static abstract class ForEachOp
implements TerminalOp, TerminalSink {
private final boolean ordered; //是否排序
protected ForEachOp(boolean ordered) {
this.ordered = ordered;
}
@Override
public int getOpFlags() {
return ordered ? 0 : StreamOpFlag.NOT_ORDERED;
}
@Override
//传入此方法的spliterator是sourceStage的sourceSpliterator实现
public Void evaluateSequential(PipelineHelper helper,
Spliterator spliterator) {
//序列化执行,此处的helper实际是上一个流处理对应的AbstractPipeline实现,此处wrapAndCopyInto也是调用
//AbstractPipeline的实现,最后的get无意义,只是用来返回Void
return helper.wrapAndCopyInto(this, spliterator).get();
}
@Override
public Void evaluateParallel(PipelineHelper helper,
Spliterator spliterator) {
if (ordered)
//多线程遍历时保证遍历顺序,invoke方法会阻塞当前线程直到任务执行完成
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
//多线程遍历时不保证顺序
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
//Supplier的接口方法
@Override
public Void get() {
return null;
}
}
//AbstractPipeline 中对PipelineHelper接口的实现,此方法的参数sink表示最后一个流处理动作
@Override
final > S wrapAndCopyInto(S sink, Spliterator spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
@Override
@SuppressWarnings("unchecked")
final Sink wrapSink(Sink sink) {
Objects.requireNonNull(sink);
//this表示最后一个流处理动作,depth表示p前面的流处理动作的个数,previousStage表示p的前一个流处理动作
//这里是沿着流处理的动作链向前遍历,返回第一个流处理动作对应的Sink
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
//opWrapSink由子类实现,会返回一个新的Sink实例,参考filter方法的实现
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink) sink;
}
//wrappedSink表示经过处理后的,包含了所有流处理动作的Sink
@Override
final void copyInto(Sink wrappedSink, Spliterator spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
//getExactSizeIfKnown获取待处理的元素个数,如果未知则返回-1,此处通知流处理开始
wrappedSink.begin(spliterator.getExactSizeIfKnown());
//不断循环,遍历所有的元素
spliterator.forEachRemaining(wrappedSink);
//通知流处理结束
wrappedSink.end();
}
else {
//如果增加了SHORT_CIRCUIT标识,则遍历过程中会判断cancellationRequested是否为true,如果是则终止遍历
copyIntoWithCancel(wrappedSink, spliterator);
}
}
@Override
final int getStreamAndOpFlags() {
return combinedFlags;
}
@Override
@SuppressWarnings("unchecked")
final void copyIntoWithCancel(Sink wrappedSink, Spliterator spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
//往前遍历,获取第一个流处理动作
AbstractPipeline p = AbstractPipeline.this;
while (p.depth > 0) {
p = p.previousStage;
}
wrappedSink.begin(spliterator.getExactSizeIfKnown());
p.forEachWithCancel(spliterator, wrappedSink);
wrappedSink.end();
}
//子类IntPipeline的实现方法
final void forEachWithCancel(Spliterator spliterator, Sink sink) {
Spliterator.OfInt spl = adapt(spliterator);
IntConsumer adaptedSink = adapt(sink);
//cancellationRequested默认返回false
do { } while (!sink.cancellationRequested() && spl.tryAdvance(adaptedSink));
}
private static Spliterator.OfInt adapt(Spliterator s) {
if (s instanceof Spliterator.OfInt) {
return (Spliterator.OfInt) s;
}
else {
if (Tripwire.ENABLED)
Tripwire.trip(AbstractPipeline.class,
"using IntStream.adapt(Spliterator s)");
throw new UnsupportedOperationException("IntStream.adapt(Spliterator s)");
}
}
private static IntConsumer adapt(Sink sink) {
if (sink instanceof IntConsumer) {
return (IntConsumer) sink;
}
else {
if (Tripwire.ENABLED)
Tripwire.trip(AbstractPipeline.class,
"using IntStream.adapt(Sink s)");
return sink::accept;
}
}
4、测试用例
@Test
public void test15() throws Exception {
IntStream intStream = IntStream.rangeClosed(0,10);
IntStream a=intStream.filter(x->{
return x>2;
});
System.out.println("a->"+a);
IntStream b=a.filter(x->{
return x>4;
});
System.out.println("b->"+b);
IntStream c=b.filter(x->{
return x>6;
});
System.out.println("c->"+c);
IntStream d=c.filter(x->{
return x%2==0;
});
System.out.println("d->"+d);
d.forEach(x->{
System.out.println("filter result->"+x);
});
}可以在AbstractPipeline的如下位置打断点:

在ForEachOps的如下位置打断点:

通过断点调试并结合上面的ForEachOp的源码分析可知,多个流处理动作经过wrapSink方法处理后会通过Sink的downstream属性构成一个链表,wrapSink方法返回的就是第一个流处理动作对应的Sink,数据通过Sink的accept方法处理后,如果符合要求会调用下一个Sink继续处理,如果不符合要求则终止后续Sink的处理,如此直到最后一个Sink处理。
5、IntStream range/rangeClosed
public static IntStream range(int startInclusive, int endExclusive) {
if (startInclusive >= endExclusive) {
return empty();
} else {
return StreamSupport.intStream(
new Streams.RangeIntSpliterator(startInclusive, endExclusive, false), false);
}
}
public static IntStream rangeClosed(int startInclusive, int endInclusive) {
if (startInclusive > endInclusive) {
return empty();
} else {
return StreamSupport.intStream(
new Streams.RangeIntSpliterator(startInclusive, endInclusive, true), false);
}
}
public static IntStream intStream(Spliterator.OfInt spliterator, boolean parallel) {
return new IntPipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
//Head通常作为提供原始数据流的sourceStage,所以跟流处理操作相关的opIsStateful和opWrapSink方法都是直接抛出UnsupportedOperationException异常
//原始数据流通过Spliterator来提供
static class Head extends IntPipeline {
Head(Supplier> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
Head(Spliterator source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
@Override
final boolean opIsStateful() {
throw new UnsupportedOperationException();
}
@Override
final Sink opWrapSink(int flags, Sink sink) {
throw new UnsupportedOperationException();
}
//改写了父类forEach 和 forEachOrdered的实现
@Override
public void forEach(IntConsumer action) {
if (!isParallel()) {
//非并行时,adapt方法适配成Spliterator.OfInt,直接调用forEachRemaining方法遍历所有的元素,减少中间的调用链
adapt(sourceStageSpliterator()).forEachRemaining(action);
}
else {
super.forEach(action);
}
}
@Override
public void forEachOrdered(IntConsumer action) {
if (!isParallel()) {
adapt(sourceStageSpliterator()).forEachRemaining(action);
}
else {
super.forEachOrdered(action);
}
}
}
IntPipeline(Supplier> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
public static IntStream empty() {
return StreamSupport.intStream(Spliterators.emptyIntSpliterator(), false);
}
static final class RangeIntSpliterator implements Spliterator.OfInt {
//起始值
private int from;
//终止值
private final int upTo;
//是否包含终止值,如果last是1表示包含,否则不包含
private int last;
RangeIntSpliterator(int from, int upTo, boolean closed) {
this(from, upTo, closed ? 1 : 0);
}
private RangeIntSpliterator(int from, int upTo, int last) {
this.from = from;
this.upTo = upTo;
this.last = last;
}
@Override
//外层循环调用tryAdvance
public boolean tryAdvance(IntConsumer consumer) {
Objects.requireNonNull(consumer);
final int i = from;
if (i < upTo) {
//from加1,下一次调用tryAdvance时,i就会加1
from++;
consumer.accept(i);
return true;
}
else if (last > 0) {
//大于等于upTo,如果last等于1,则处理,此时i等于upTo
//将last置为0,可避免再次处理upTo
last = 0;
consumer.accept(i);
return true;
}
return false;
}
@Override
//forEachRemaining 自己内部循环调用
public void forEachRemaining(IntConsumer consumer) {
Objects.requireNonNull(consumer);
int i = from;
final int hUpTo = upTo;
int hLast = last;
from = upTo;
last = 0;
while (i < hUpTo) {
//处理from到upTo之间的值
consumer.accept(i++);
}
if (hLast > 0) {
//如果包含终止值,则处理upTo
consumer.accept(i);
}
}
@Override
public long estimateSize() {
//计算处理的数据大小
return ((long) upTo) - from + last;
}
@Override
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED |
Spliterator.IMMUTABLE | Spliterator.NONNULL |
Spliterator.DISTINCT | Spliterator.SORTED;
}
@Override
public Comparator getComparator() {
return null;
}
@Override
//并行处理式,进行任务切割
public Spliterator.OfInt trySplit() {
long size = estimateSize();
return size <= 1
? null
//将当前任务一分为二,返回新切割出来的子任务,当前任务为剩下的另一半
: new RangeIntSpliterator(from, from = from + splitPoint(size), 0);
}
private static final int BALANCED_SPLIT_THRESHOLD = 1 << 24;
private static final int RIGHT_BALANCED_SPLIT_RATIO = 1 << 3;
private int splitPoint(long size) {
int d = (size < BALANCED_SPLIT_THRESHOLD) ? 2 : RIGHT_BALANCED_SPLIT_RATIO;
return (int) (size / d);
}
} 6、ForEachTask
ForEachTask用于forEach方法的并行遍历,该类继承自CountedCompleter,CountedCompleter的用法可以参考《Java8 RecursiveAction / RecursiveTask / CountedCompleter 源码解析》,其实现如下:
static final class ForEachTask extends CountedCompleter {
private Spliterator spliterator;
private final Sink sink;
private final PipelineHelper helper;
private long targetSize;
//evaluateParallel方法使用
ForEachTask(PipelineHelper helper,
Spliterator spliterator,
Sink sink) {
super(null);
this.sink = sink;
this.helper = helper;
this.spliterator = spliterator;
this.targetSize = 0L;
}
//下面的compute方法使用,用于创建一个子任务
ForEachTask(ForEachTask parent, Spliterator spliterator) {
super(parent);
this.spliterator = spliterator;
this.sink = parent.sink;
//不再是默认的0,等于父任务的targetSize
this.targetSize = parent.targetSize;
this.helper = parent.helper;
}
//执行时会调用compute方法完成任务的切割并等待所有子任务执行完成
public void compute() {
Spliterator rightSplit = spliterator, leftSplit;
//sizeEstimate表示待处理的元素总数
long sizeEstimate = rightSplit.estimateSize(), sizeThreshold;
if ((sizeThreshold = targetSize) == 0L) //初始的父任务targetSize为0,子任务的targetSize不为0
//计算子任务的数量,按照一个处理器处理4个任务
targetSize = sizeThreshold = AbstractTask.suggestTargetSize(sizeEstimate);
boolean isShortCircuit = StreamOpFlag.SHORT_CIRCUIT.isKnown(helper.getStreamAndOpFlags());
boolean forkRight = false;
Sink taskSink = sink;
ForEachTask task = this;
while (!isShortCircuit || !taskSink.cancellationRequested()) {
if (sizeEstimate <= sizeThreshold || //targetSize默认0,所以sizeEstimate应该大于等于sizeThreshold
//trySplit方法会将原来的任务一分为二,leftSplit为新切割出来的子任务,rightSplit为剩余的子任务
(leftSplit = rightSplit.trySplit()) == null) {
//如果无法继续切割子任务了,则执行剩下的子任务rightSplit
task.helper.copyInto(taskSink, rightSplit);
break;
}
ForEachTask leftTask = new ForEachTask<>(task, leftSplit);
//增加子任务计数
task.addToPendingCount(1);
ForEachTask taskToFork;
if (forkRight) {
//第二次while循环时就会进入此分支
forkRight = false;
//更新rightSplit,下一次切分基于leftSplit
rightSplit = leftSplit;
//将原rightSplit对应的task提交到线程池中
taskToFork = task;
//更新task引用
task = leftTask;
}
else {
//置为true,第一次while循环进入此分支,下一次while循环就命中上面的if分支
forkRight = true;
taskToFork = leftTask;
}
//将taskToFork提交到线程池中等待被执行
taskToFork.fork();
//更新sizeEstimate
sizeEstimate = rightSplit.estimateSize();
}//while循环结束
task.spliterator = null;
//表示一个子任务执行完成,如果所有子任务都执行完成,则将任务状态标记为已完成
task.propagateCompletion();
}
}
public static long suggestTargetSize(long sizeEstimate) {
long est = sizeEstimate / LEAF_TARGET;
return est > 0L ? est : 1L;
}
static final int LEAF_TARGET = ForkJoinPool.getCommonPoolParallelism() << 2; 7、ForEachOrderedTask
ForEachOrderedTask用于实现forEachOrdered方法的并行执行,保证多线程遍历时各线程的处理顺序与元素顺序保持一致,该类同样继承自CountedCompleter,其实现如下:
static final class ForEachOrderedTask extends CountedCompleter {
/*
* Our goal is to ensure that the elements associated with a task are
* processed according to an in-order traversal of the computation tree.
* We use completion counts for representing these dependencies, so that
* a task does not complete until all the tasks preceding it in this
* order complete. We use the "completion map" to associate the next
* task in this order for any left child. We increase the pending count
* of any node on the right side of such a mapping by one to indicate
* its dependency, and when a node on the left side of such a mapping
* completes, it decrements the pending count of its corresponding right
* side. As the computation tree is expanded by splitting, we must
* atomically update the mappings to maintain the invariant that the
* completion map maps left children to the next node in the in-order
* traversal.
*
* Take, for example, the following computation tree of tasks:
*
* a
* / \
* b c
* / \ / \
* d e f g
* a是最初的任务,将其切割成b,c两个子任务,b有进一步切割成d,e两个子任务,c切割成f,g两个子任务
* The complete map will contain (not necessarily all at the same time)
* the following associations:
*
* d -> e
* b -> f
* f -> g
* g执行完成,意味着原始的a执行完成,整个处理过程相当于还是单线程的
* Tasks e, f, g will have their pending counts increased by 1.
*
* The following relationships hold:
*
* - completion of d "happens-before" e;
* - completion of d and e "happens-before b;
* - completion of b "happens-before" f; and
* - completion of f "happens-before" g
*
* Thus overall the "happens-before" relationship holds for the
* reporting of elements, covered by tasks d, e, f and g, as specified
* by the forEachOrdered operation.
*/
private final PipelineHelper helper;
private Spliterator spliterator;
private final long targetSize;
private final ConcurrentHashMap, ForEachOrderedTask> completionMap;
private final Sink action;
private final ForEachOrderedTask leftPredecessor;
private Node node;
//evaluateParallel方法使用
protected ForEachOrderedTask(PipelineHelper helper,
Spliterator spliterator,
Sink action) {
super(null);
this.helper = helper;
this.spliterator = spliterator;
this.targetSize = AbstractTask.suggestTargetSize(spliterator.estimateSize());
// Size map to avoid concurrent re-sizes
this.completionMap = new ConcurrentHashMap<>(Math.max(16, AbstractTask.LEAF_TARGET << 1));
this.action = action;
this.leftPredecessor = null;
}
//doCompute方法使用
ForEachOrderedTask(ForEachOrderedTask parent,
Spliterator spliterator,
ForEachOrderedTask leftPredecessor) {
super(parent);
this.helper = parent.helper;
this.spliterator = spliterator;
this.targetSize = parent.targetSize;
this.completionMap = parent.completionMap;
this.action = parent.action;
this.leftPredecessor = leftPredecessor;
}
@Override
public final void compute() {
doCompute(this);
}
private static void doCompute(ForEachOrderedTask task) {
Spliterator rightSplit = task.spliterator, leftSplit;
long sizeThreshold = task.targetSize;
boolean forkRight = false;
while (rightSplit.estimateSize() > sizeThreshold &&
(leftSplit = rightSplit.trySplit()) != null) {
//如果可以切分出新的子任务
ForEachOrderedTask leftChild =
new ForEachOrderedTask<>(task, leftSplit, task.leftPredecessor);
ForEachOrderedTask rightChild =
new ForEachOrderedTask<>(task, rightSplit, leftChild);
//左右节点对应子任务在父任务之前完成
task.addToPendingCount(1);
//左节点的子任务在右节点之前完成
rightChild.addToPendingCount(1);
task.completionMap.put(leftChild, rightChild);
//祖先任务的leftPredecessor为null,rightChild的leftPredecessor不为null
if (task.leftPredecessor != null) {
/*
* Completion of left-predecessor, or left subtree,
* "happens-before" completion of left-most leaf node of
* right subtree.
* The left child's pending count needs to be updated before
* it is associated in the completion map, otherwise the
* left child can complete prematurely and violate the
* "happens-before" constraint.
*/
leftChild.addToPendingCount(1);
// Update association of left-predecessor to left-most
// leaf node of right subtree
if (task.completionMap.replace(task.leftPredecessor, task, leftChild)) {
// If replaced, adjust the pending count of the parent
// to complete when its children complete
task.addToPendingCount(-1);
} else {
// Left-predecessor has already completed, parent's
// pending count is adjusted by left-predecessor;
// left child is ready to complete
leftChild.addToPendingCount(-1);
}
}
ForEachOrderedTask taskToFork;
if (forkRight) {
forkRight = false;
rightSplit = leftSplit;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
//提交任务到线程池中
taskToFork.fork();
} //while循环结束
//子任务切分完成,task就是其中的某一个子任务
/*
* Task's pending count is either 0 or 1. If 1 then the completion
* map will contain a value that is task, and two calls to
* tryComplete are required for completion, one below and one
* triggered by the completion of task's left-predecessor in
* onCompletion. Therefore there is no data race within the if
* block.
*/
if (task.getPendingCount() > 0) {
// Cannot complete just yet so buffer elements into a Node
// for use when completion occurs
@SuppressWarnings("unchecked")
IntFunction generator = size -> (T[]) new Object[size];
Node.Builder nb = task.helper.makeNodeBuilder(
task.helper.exactOutputSizeIfKnown(rightSplit),
generator);
task.node = task.helper.wrapAndCopyInto(nb, rightSplit).build();
task.spliterator = null;
}
//表示一个子任务执行完成,如果所有子任务都执行完成,则将任务状态标记为已完成
//当某个父任务的所有子任务执行完成会回调onCompletion,在onCompletion中完成实际的父任务遍历逻辑
//从而实现happens-before
task.tryComplete();
}
@Override
public void onCompletion(CountedCompleter caller) {
if (node != null) {
//遍历node的元素,执行action
node.forEach(action);
node = null;
}
else if (spliterator != null) {
//遍历spliterator中的元素,执行action
helper.wrapAndCopyInto(action, spliterator);
spliterator = null;
}
// The completion of this task *and* the dumping of elements
// "happens-before" completion of the associated left-most leaf task
// of right subtree (if any, which can be this task's right sibling)
//
ForEachOrderedTask leftDescendant = completionMap.remove(this);
if (leftDescendant != null)
//将leftDescendant标记为已完成
leftDescendant.tryComplete();
}
}
@Override
//IntPipeline的实现
final Node.Builder makeNodeBuilder(long exactSizeIfKnown,
IntFunction generator) {
return Nodes.intBuilder(exactSizeIfKnown);
}
其实现多线程顺序遍历的核心在于通过addToPendingCount和重写onCompletion方法实现了各子任务执行的先后顺序,即多个子任务从逻辑上还是串行执行的,并非真正的并行执行。