详解机器学习中的数据处理(一)——缺失值处理(附完整代码)
摘要:在机器学习中,我们的数据集往往存在各种各样的问题,如果不对数据进行预处理,模型的训练和预测就难以进行。这一系列博文将介绍一下机器学习中的数据预处理问题,以 U C I \color{#4285f4}{U}\color{#ea4335}{C}\color{#fbbc05}{I} UCI数据集为例详细介绍缺失值处理、连续特征离散化,特征归一化及离散特征的编码等问题,同时会附上处理的 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab程序代码,这篇博文先介绍下缺失值处理,其目录如下:
文章目录
- 前言
- 1. 缺失值处理
- 处理缺失值的方法
- 读取数据集文件
- 查找、替换缺失数据
- 2. 代码资源获取
- 结束语
点 击 跳 转 至 博 文 涉 及 的 全 部 文 件 下 载 页 \color{#4285f4}{点}\color{#ea4335}{击}\color{#fbbc05}{跳}\color{#4285f4}{转}\color{#34a853}{至}\color{#ea4335}{博}\color{#4285f4}{文}\color{#ea4335}{涉}\color{#fbbc05}{及}\color{#4285f4}{的}\color{#34a853}{全}\color{#ea4335}{部}\color{#fbbc05}{文}\color{#4285f4}{件}\color{#34a853}{下}\color{#ea4335}{载}\color{#fbbc05}{页} 点击跳转至博文涉及的全部文件下载页
前言
学习和研究了几年机器学习的一些算法,在这些日子的探索中我深深地体会到数据预处理的重要性。这几年机器学习大热,有的时候我们一股脑投入到算法的研究改进之中,为提升的那一点点准确率欣喜若狂,但往往那个我们时常不太在意的数据处理部分稍不注意便对算法结果影响巨大甚至可能颠覆我们原本的结论。
虽然 P y t h o n \color{#4285f4}{P}\color{#ea4335}{y}\color{#fbbc05}{t}\color{#4285f4}{h}\color{#34a853}{o}\color{#ea4335}{n} Python在数据处理和深度学习中表现出色,我本人也特别喜欢并经常使用这门编程语言,但其实机器学习的一些教学机构以及个人研究者还是有很多人使用 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab。毕竟如果只是轻量级的学习MATLAB还是很方便的,不用像Python那样来回倒腾各种包了,还有就是一介绍机器学习网上各种介绍用Python处理的,这里给大家换换口味总结下如何用MATLAB进行数据处理。
这篇博文我会以机器学习中经常使用的 U C I \color{#4285f4}{U}\color{#ea4335}{C}\color{#fbbc05}{I} UCI数据集为例进行介绍。关于 U C I \color{#4285f4}{U}\color{#ea4335}{C}\color{#fbbc05}{I} UCI数据集的介绍和整理,在我前面的两篇博文:UCI数据集详解及其数据处理(附148个数据集及处理代码)、UCI数据集整理(附论文常用数据集)都有详细介绍,有兴趣的读者可以点过去了解一下。
1. 缺失值处理
由于各种各样原因,现实中的许多数据集包含缺失数据,这样的数据是无法直接用于训练的,比如UCI数据集中的Adult数据集、Annealing数据集、Lung-Cancer数据集等都存在个别数据缺失,对此我们需要对缺失值进行处理。
处理缺失值的方法
处理缺失值的方法有很多并且没有统一的较好处理方式,对于缺失值的处理方法下图给出了较为详细的解答。最简单粗暴的方法就是把含有缺失值的样本丢弃,这样可以避免人为填充带来的噪声。但这样做可能会丢失一些很重要的信息,特别是数据量不多或者数据价值很高的数据来说,直接丢弃就太浪费了。因此我们可以旋转某种合适的策略对缺失值进行适当的填充。
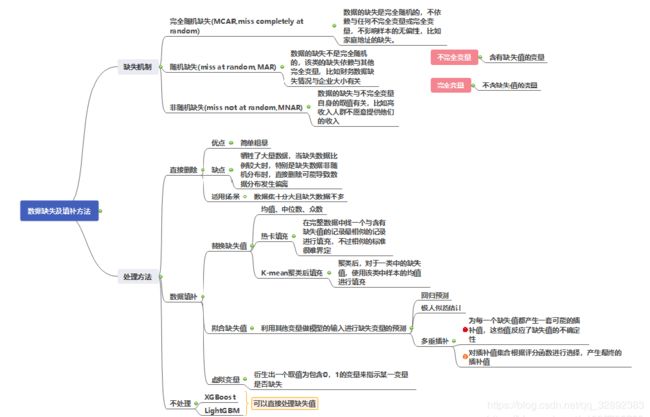
一般来说,我们可以使用平均值、中值、分位数、众数等替代。 如果想要更好的填充效果,可以考虑利用无缺失值的数据建立模型,通过模型来选择一个最适合的填充值,但如果缺失的属性对于模型可有可无,那么得出来的填充值也将不准确。我们还可以使用KNN来选择最相似的样本进行填充。除此以外,缺失信息也可以作为一种特殊的特征表达,例如人的性别,男、女、不详可能各自有着不同的含义。
读取数据集文件
光这么说可能太宽泛,这里以一个简单的数据集:Lung-Cancer为例,从官网地址下载该数据集并将文件“lung-cancer.data”保存在自定义文件夹下,用 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab打开文件部分数据截图如下图所示:
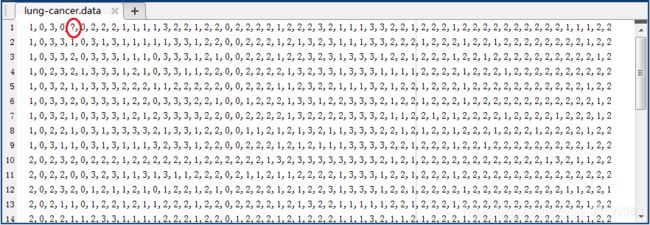
仔细观察上面的文本数据可以发现部分数据缺失,UCI数据集对于缺失数据用“?”,这是为了保持文本数据中的格式统一性。首先我们先去读取数据集中的属性和标签数据,在该目录下新建 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab文件“read_dataset.m”并在编辑器中键入如下代码:
% author:思绪无限, date:2020.2.29, website:https://wuxian.blog.csdn.net
% lung-cancer
clear;
clc;
data_name = 'lung-cancer';
fprintf('读取数据集: %s ...\n', data_name);
n_entradas= 56; % 数据集属性个数
n_clases= 3; % 类别数
n_fich= 1; % 文件个数
fich{1}= 'lung-cancer.data'; % 文件路径
n_patrons(1)= 32; % 数据量
n_max= max(n_patrons);
x = zeros(n_max, n_entradas); % 存储属性
cl= zeros(n_max, n_fich); % 存储标签
% 用于显示进度
n_patrons_total = sum(n_patrons);
n_iter=0;
for i_fich=1:n_fich
f=fopen(fich{i_fich}, 'r'); % 打开文件
if -1==f
error('打开文件出错 %s\n', fich{i_fich});
end
for i=1:n_patrons(i_fich)
% 显示进度
n_iter=n_iter+1;
fprintf('%5.1f%%\r', 100*n_iter/n_patrons_total);
temp = fscanf(f,'%i',1) - 1; % 读取数据标签(这里标签从0开始,与原标签相差1)
cl(i, i_fich) = temp;
% 读取每一列属性
for j = 1:n_entradas
fscanf(f,'%c',1); % 跳过各属性间的逗号
t = fscanf(f,'%c',1); % 读取属性数值
if t ~= '?' % 判断是否为缺失数据
fseek(f,-1,0);
x(i,j) = fscanf(f, '%i',1);
else
x(i,j) = NaN; % 缺失数据保存为空值
% x(i,j) = missing; % 缺失数据保存为空值(MATLAB R2019 可保存为missing)
end
end
end
fclose(f);
end
save('lung-cancer-raw.mat', 'x','cl') % 将读取出的数据保存
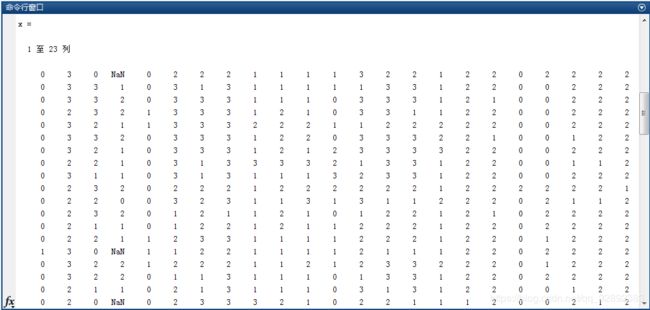
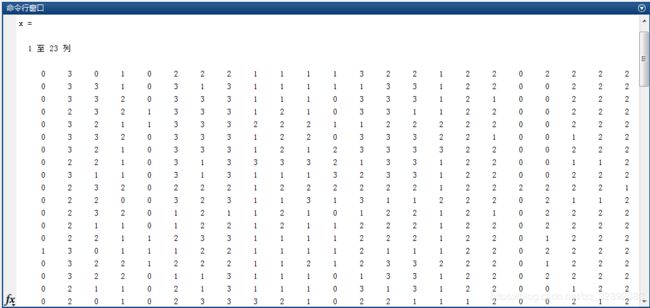
以上代码通过循环调用scanf( )函数逐个读入文本文件中的每个数据,外循环代码(第28-51行)遍历每行数据,内循环(第37-49行)遍历一行中每一个属性数据,通过移动文件指针跳过两个属性间的逗号(第38行),最终得到纯数值数据。其中代码第41-47行判断每个属性数据是否为“?”,由于Matlab中将缺失值保存为“NaN”(Matlab R2019a及以上还可保存为missing),这里加条件判断缺失数据赋值为NaN。代码最后将读取到的属性和标签数据(x, cl)保存在“lung-cancer-raw.mat”中,在命令行打印x的值部分截图如下:
查找、替换缺失数据
按照前面的介绍的方法这里使用各列属性的平均值替换缺失值,首先我们需要计算缺失数据所在属性的均值。这里可以先使用isnan( )指示缺失值位置进行查看,由于存在NaN数值,若直接使用Matlab内置函数mean( )计算将得到NaN的结果。常规思路是先找到NaN值的位置然后删去后计算均值,但其实许多 Matlab函数都可以忽略缺失值,我们不必首先显式定位、填充或删除它们。我们可以结合使用mean函数和’omitnan’选项来直接忽略和中的NaN,例如如下的代码和结果。
>> xDouble=[0 1 1 3 nan 2]
xDouble =
0 1 1 3 NaN 2
>> meanNan = mean(xDouble, 'omitnan')
meanNan =
1.4000
对于缺失数据的填充 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab有专门的填充函数fillmissing函数,使用方法如下引用,更多功能可以访问fillmissing官方文档。这里我们使用F = fillmissing(A,‘constant’,v)为缺失值填充常量,常量v的值为上面计算得到的均值。需要注意的是,Lung-Cancer数据集的每列属性均为0-3的整数,为保持数据类型的统一性,这里先对计算得到的均值向下取值然后替换缺失值。
fillmissing
填充缺失值
语法
F = fillmissing(A,‘constant’,v)
F = fillmissing(A,method)
F = fillmissing(A,movmethod,window)
说明
F = fillmissing(A,‘constant’,v) 使用常量值 v 填充缺失的数组或表条目。
F = fillmissing(A,method) 使用 method 指定的方法填充缺失的条目。
F = fillmissing(A,movmethod,window) 使用窗口长度为 window 的移动窗口均值或中位数填充缺失条目。
——MATLAB官方文档
根据上面的分析编写程序使用均值填充缺失值,在该目录下新建 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab文件“replace_missing.m”并在编辑器中键入如下代码:
% 读取原始数据,采用均值填充
clear;
clc
load('lung-cancer-raw.mat','x','cl'); % 导入数据
nanData = x;
TF = isnan(nanData); % 缺失数据位置
meanData = mean(nanData, 'omitnan'); % 计算每列上数据的均值(忽略NaN)
intMean = floor(meanData); % 由于lung-cancer数据的属性均为0-3的整数,这里对向下取值
x = fillmissing(nanData,'constant',intMean); % 填充缺失数据为均值
% x = fillmissing(nanData,'constant',0); % 也可填充缺失数据为0
save('lung-cancer-fill.mat', 'x', 'cl'); % 保存填充后的数据
以上代码最终将填充后的结果保存在文件“lung-cancer-fill.mat”中,再次输出x的值可以看到NaN的位置数据已替换为该列属性的均值,在命令行打印x的值部分截图如下。如此缺失值填充完成,当然处理方式并无最佳的统一方法,比较简单的方式还可以直接补0,如上代码第13行。
处理完成后工作区的情况如下图:

2. 代码资源获取
这里对博文中涉及的数据及代码文件做一个整理,本文涉及的代码文件如下图所示。所有代码均在 M a t l a b \color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b} Matlab R 2 0 1 6 b \color{#4285f4}{R}\color{#ea4335}{2}\color{#fbbc05}{0}\color{#4285f4}{1}\color{#34a853}{6}\color{#ea4335}{b} R2016b中调试通过,点击即可运行。
后续博文会继续分享数据处理系列的代码,敬请关注博主的机器学习数据处理分类专栏。
【资源获取】
若您想获得博文中介绍的填充缺失数据涉及的完整程序文件(包含数据集的原始文件、整理数据集程序代码文件及整理好的文件),可扫描以下二维码并关注公众号“AI技术研究与分享”,并且在后台回复“DP20200301”(建议复制红色字体)获取,后续系列的代码也会陆续分享打包在里面。

该公众号持续分享大量人工智能资源,欢迎关注!
【更多下载】
更多的UCI数据及处理方式可在博主面包多网页下载获取,里面有大量的UCI数据集整理和数据处理代码,点击以下链接可以下载:
下载地址:博主的面包多网站下载页
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
【参考文献】
[1] https://ww2.mathworks.cn/help/matlab/data_analysis/missing-data-in-matlab.html
[2] https://ww2.mathworks.cn/help/matlab/ref/fillmissing.html
[3] https://ww2.mathworks.cn/help/matlab/matlab_prog/clean-messy-and-missing-data-in-tables.html