经典卷积神经网络结构(4)——GoogLeNet(Inception-v1/Inception-v2)网络结构详解(卷积神经网络入门,Keras代码实现)
背景简介
几乎与 VGG 网络同时,Google 在2014年9月提出了 Inception-v1 网络结构,它在两方面有打的进步:1)网络更深,有20多层;2)网络更宽,作者的出发点是,卷积核有1x1,3x3,5x5等,为什么每次卷积只能选一种大小的卷积核? W h y n o t t r y t h e m a l l ? Why\ not\ try\ them\ all? Why not try them all? 作者便在每个 Inception block 把这几种卷积核以及池化全部使用了。再加上2013年 N e t w o r k i n N e t w o r k Network\ in\ Network Network in Network 这篇文章的影响,作者使用了1x1的卷积 t r i c k trick trick 来减少计算量。这里有个 Inception-v1 也就是 GoogLeNet 的命名也很有意思,明显是在尊重大牛 LeCun 提出的 LeNet。
几个月之后,2015年2月,这个团队又提出了加速网络训练的方法 B a t c h N o r m a l i z a t i o n Batch\ Normalization Batch Normalization。这就是 I n c e p t i o n − v 2 Inception-v2 Inception−v2 相对于 I n c e p t i o n − v 1 Inception-v1 Inception−v1 的主要改变。 B a t c h N o r m a l i z a t i o n Batch\ Normalization Batch Normalization 的思想在后来的主流的神经网络模型中都用到了,因为它能够加快收敛、不需要刻意的初始化以及有类似正则项的作用等优点。
后来还有 Inception-v3,Inveption-v4,Xception等相关网络。后面会一一讲解。
原论文地址
- Inception-v1/GoogLeNet
https://arxiv.org/pdf/1409.4842.pdf - Inception-v2/Batch Normalization
https://arxiv.org/pdf/1502.03167.pdf
个人 GitHub 实现
https://github.com/uestcsongtaoli/Inception_v1_v2
我实现的是 Inception-v2,相当于是在 Inception-v1 上增加了 Btach Normalization 结构。不过这个版本在 Inception block 中未使用 Batch Normalization, 现在基本上网络经过卷积之后都加 Batch Normalization 层。
模型结构
Inception-v1
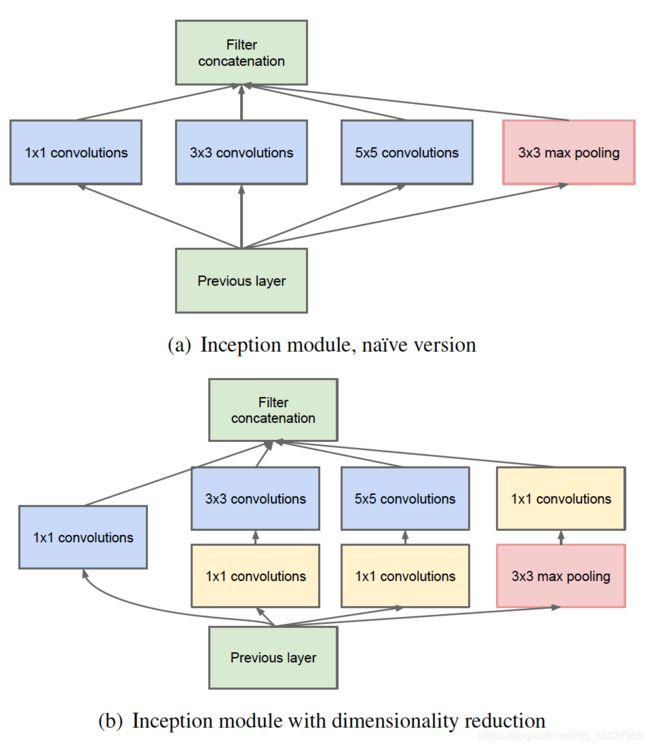
I n c e p t i o n − v 1 Inception-v1 Inception−v1 的核心思想便是,把不同的卷积核操作运用在同一层;为了减少计算量,然后都做了1x1的卷积来进行降维,也就是减少 f e a t u r e m a p feature\ map feature map 的 c h a n n e l channel channel 数。
其中 I n c e p t i o n b l o c k Inception\ block Inception block 的 K e r a s Keras Keras 代码如下,需要注意的是,池化的步长 s t r i d e s strides strides 为(1,1)。
def inception_block(x,
filters_1x1,
filters_3x3_reduce,
filters_3x3,
filters_5x5_reduce,
filters_5x5,
filters_pool_proj,
name=None):
conv_1x1 = Conv2D(filters_1x1,
kernel_size=(1, 1),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer=kernel_init,
bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filters_3x3_reduce,
kernel_size=(1, 1),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer=kernel_init,
bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filters_3x3,
kernel_size=(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer=kernel_init,
bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filters_5x5_reduce,
kernel_size=(1, 1),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer=kernel_init,
bias_initializer=bias_init)(x)
conv_5x5 = Conv2D(filters_5x5,
kernel_size=(5, 5),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer=kernel_init,
bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D(pool_size=(3, 3), strides=(1, 1), padding="same")(x)
pool_proj = Conv2D(filters_pool_proj,
kernel_size=(1, 1),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer=kernel_init,
bias_initializer=bias_init)(pool_proj)
output = concatenate([conv_1x1, conv_3x3, conv_5x5, pool_proj], axis=3, name=name)
return output
GoogLeNet
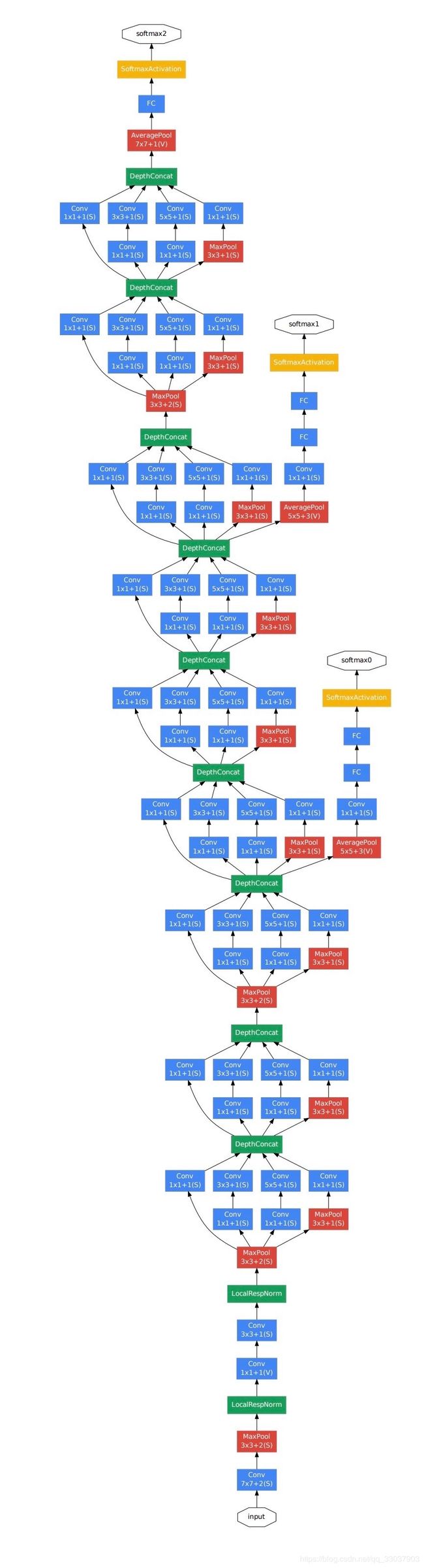
这里网络还是从 AlexNet 的基础上进行扩展的,从5个卷积层,演化成5个 Stage,第一个是主干部分 stem,接下来的4个 Stage 是有 inception block 组成的。具体代码参考我的 Github。值得一提的是,这里多增加了两个额外的损失,不过后来的图像分类网络比较少这么干。但是,这里可以让我们了解,多个损失的时候,我们如何用 Keras 去设计模型。不过我的实现方式,是复制 Keras 源码然后修改,不是很好的方法,后续会改进。
个人理解
- inception-v1 主要是从深度和宽度对网络进行了扩展,后来的网络都采用了这个思想
- inception-vc2 其实主要是提出了 Batch normalization,这也是后来的网络常见的思想。
- 不过,初步试验感觉这个网络还没有 VGG 效果好,可能是我调参的问题。
- v1-v2确实还是比不了 ResNet,相比之下,ResNet 收敛快太多了,而且平均效果还要好很多。
- 目前我的训练都是从头开始训练,后面还需要对比 fine-tuning 的效果。
更多参考资料
- A Simple Guide to the Versions of the Inception Network
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202 - Deep Learning in the Trenches: Understanding Inception Network from Scratch
https://www.analyticsvidhya.com/blog/2018/10/understanding-inception-network-from-scratch/
代码可以参考这边文章 - Review: GoogLeNet (Inception v1)— Winner of ILSVRC 2014 (Image Classification)
https://medium.com/coinmonks/paper-review-of-googlenet-inception-v1-winner-of-ilsvlc-2014-image-classification-c2b3565a64e7