强化学习实战一
这篇强化学习实战主要依赖于Pendulum-v0项目,从以下两个方面入手:
- OpenAI Gym环境解析
- DDPG算法Pytorch代码详解
环境源码:https://github.com/openai/gym/blob/master/gym/envs/classic_control/pendulum.py
1. OpenAI Gym环境解析
入门强化学习,使用 OpenAI Gym 作为实践环境无疑是最简单的,这是一个可以用来研究和比较强化学习算法的开源工具包,包含了各种可用来训练和研究新的强化学习算法的模拟环境。但是这些环境究竟是什么呢?这一节以Pendulum-v0环境为例对Openai Gym环境做解析。
OpenAI Gym 提供了一个统一的环境接口,Agent可以通过三种基本方法(重置、执行和回馈)与环境交互:
- 重置操作(env.reset())会重置环境并返回观测值;
- 执行操作(env.step())会在环境中执行一个时间步长,并返回观测值、奖励、状态和信息;
- 回馈操作(env.render())指令会显示一个窗口提示当前环境的状态,当调用这个指令时,可以通过窗口看到算法是如何学习和执行的。会回馈环境的一个帧,比如弹出交互窗口。
先看Pendulum-v0环境源码:
import gym
from gym import spaces
from gym.utils import seeding
import numpy as np
from os import path
class PendulumEnv(gym.Env):
metadata = {
'render.modes' : ['human', 'rgb_array'],
'video.frames_per_second' : 30
}
def __init__(self, g=10.0):
self.max_speed=8
self.max_torque=2.
self.dt=.05
self.g = g
self.m = 1.
self.l = 1.
self.viewer = None
high = np.array([1., 1., self.max_speed], dtype=np.float32)
self.action_space = spaces.Box(low=-self.max_torque, high=self.max_torque, shape=(1,), dtype=np.float32)
self.observation_space = spaces.Box(low=-high, high=high, dtype=np.float32)
self.seed()
def seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return [seed]
def step(self, u):
th, thdot = self.state # th := theta
g = self.g
m = self.m
l = self.l
dt = self.dt
u = np.clip(u, -self.max_torque, self.max_torque)[0]
self.last_u = u # for rendering
costs = angle_normalize(th)**2 + .1*thdot**2 + .001*(u**2)
newthdot = thdot + (-3*g/(2*l) * np.sin(th + np.pi) + 3./(m*l**2)*u) * dt
newth = th + newthdot*dt
newthdot = np.clip(newthdot, -self.max_speed, self.max_speed) #pylint: disable=E1111
self.state = np.array([newth, newthdot])
return self._get_obs(), -costs, False, {}
def reset(self):
high = np.array([np.pi, 1])
self.state = self.np_random.uniform(low=-high, high=high)
self.last_u = None
return self._get_obs()
# observation = function(state)
def _get_obs(self):
theta, thetadot = self.state
return np.array([np.cos(theta), np.sin(theta), thetadot])
def render(self, mode='human'):
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.Viewer(500,500)
self.viewer.set_bounds(-2.2,2.2,-2.2,2.2)
rod = rendering.make_capsule(1, .2)
rod.set_color(.8, .3, .3)
self.pole_transform = rendering.Transform()
rod.add_attr(self.pole_transform)
self.viewer.add_geom(rod)
axle = rendering.make_circle(.05)
axle.set_color(0,0,0)
self.viewer.add_geom(axle)
fname = path.join(path.dirname(__file__), "assets/clockwise.png")
self.img = rendering.Image(fname, 1., 1.)
self.imgtrans = rendering.Transform()
self.img.add_attr(self.imgtrans)
self.viewer.add_onetime(self.img)
self.pole_transform.set_rotation(self.state[0] + np.pi/2)
if self.last_u:
self.imgtrans.scale = (-self.last_u/2, np.abs(self.last_u)/2)
return self.viewer.render(return_rgb_array = mode=='rgb_array')
def close(self):
if self.viewer:
self.viewer.close()
self.viewer = None
def angle_normalize(x):
return (((x+np.pi) % (2*np.pi)) - np.pi)
1.1 state、observation、action是什么?
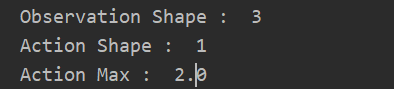
那么 State 与 Action 表示什么呢?
- state是Pendulum的角度和角速度,记为theta与thetadot(角速度有大小限制,self.max_speed=8)。
- observation是state的函数,这里是 [np.cos(theta), np.sin(theta), thetadot] 三个值,即observation的shape是3。
抄袭一句话:上面这二者的定义很符合我们在强化学习中学到的知识,state是最原始的环境内部的表示,observation则是state的函数。比如说,我们所看见的东西并不一定就是它们在世界中的真实状态,而是经过我们的大脑加工过的信息。 - action是控制力矩,只有一个维度,且有最大值和最小值的限制(self.max_torque=2)。
注:力矩表示力对物体作用时所产生的转动效应的物理量。力和力臂的乘积为力矩。力矩是矢量(负号表示方向)。力对某一点的力矩的大小为该点到力的作用线所引垂线的长度(即力臂)乘以力的大小,其方向则垂直于垂线和力所构成的平面用右手螺旋法则来确定。力矩能使物体获得角加速度,并可使物体的动量矩发生改变,对同一物体来说力矩愈大,转动状态就愈容易改变。
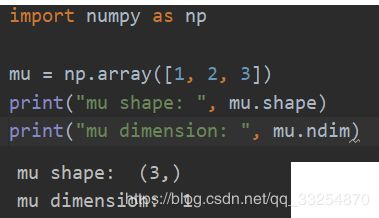
注:shape与dimension是不一样的,这里的dimension是1,但是shape是(3,)。
1.2 奖励怎么计算?
代价表示为:
costs = angle_normalize(th)**2 + .1*thdot**2 + .001*(u**2)
最后step()函数返回的是:
# 即reward = -costs
return self._get_obs(), -costs, False, {}
costs包含三项:
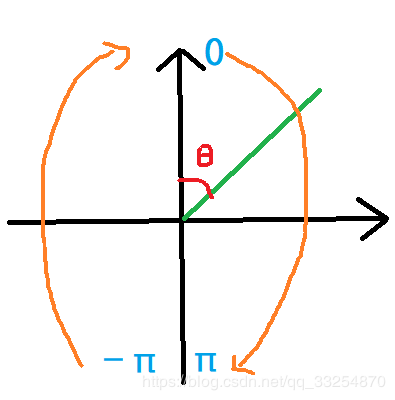
- angle_normalize(th)**2,这是对于当前倒立摆与目标位置的角度差(-pi,pi)的惩罚;
- 0.1*thdot**2,表示对于角速度的惩罚,毕竟如果我们在到达目标位置(竖直)之后,如果还有较大的速度的话,就越过去了;
- 0.001*(u**2),表示对于输入力矩的惩罚,我们所使用的力矩越大,惩罚越大,毕竟力矩×角速度=功率,还是小点的好。
2. DDPG算法实战
论文:https://arxiv.org/abs/1509.02971
DDPG源码:https://github.com/vy007vikas/PyTorch-ActorCriticRL
视频详解(直播录的,很垃圾,下次更新…)
DDPG吸收了DQN的精华,所以 Actor 与 Critic 分别有两个神经网络去进行优化(一共四个)。如果你看过这篇博客的DDPG部分,你应该对DDPG的参数更新有了了解。

核心步骤:
- Target Actor(动作现实网络)根据下一状态选择动作,然后Target Critic(状态现实网络)再根据下一状态及对应的动作进行计算q现实,最后根据q估计与q现实误差作loss去优化Critic(状态估计网络)。
- Actor(动作估计网络)根据当前状态选择动作,然后 Critic 根据预测的动作与当前时刻状态计算值函数,最后利用值函数作为loss来优化Actor(Policy Gradients算法思想:梯度下降)。
核心代码:
def optimize(self):
"""
Samples a random batch from replay memory and performs optimization
:return:
"""
s1, a1, r1, s2 = self.ram.sample(BATCH_SIZE)
s1 = Variable(torch.from_numpy(s1))
a1 = Variable(torch.from_numpy(a1))
r1 = Variable(torch.from_numpy(r1))
s2 = Variable(torch.from_numpy(s2))
# ---------------------- optimize critic ----------------------
# Use target actor exploitation policy here for loss evaluation
a2 = self.target_actor.forward(s2).detach()
next_val = torch.squeeze(self.target_critic.forward(s2, a2).detach())
# y_exp = r + gamma*Q'(s2, pi'(s2))
y_expected = r1 + GAMMA*next_val
# y_pred = Q(s1, a1)
y_predicted = torch.squeeze(self.critic.forward(s1, a1))
# compute critic loss, and update the critic
loss_critic = F.smooth_l1_loss(y_predicted, y_expected)
self.critic_optimizer.zero_grad()
loss_critic.backward()
self.critic_optimizer.step()
# ---------------------- optimize actor ----------------------
pred_a1 = self.actor.forward(s1)
loss_actor = -1*torch.sum(self.critic.forward(s1, pred_a1))
self.actor_optimizer.zero_grad()
loss_actor.backward()
self.actor_optimizer.step()
utils.soft_update(self.target_actor, self.actor, TAU)
utils.soft_update(self.target_critic, self.critic, TAU)
注:强化学习项目中一般会涉及一个问题(Ornstein-Uhlenbeck噪声),这个问题请参见Ornstein-Uhlenbeck过程。