葵花宝典--SparkSQL
一、概述
1、定义
- 用于处理结构化数据的spark模块,提供了结构化数据和执行计算的更多信息
- 运行时讲spark sql转换成RDD进行运算,比我们自己写的RDD效率要高,它进行了优化;并且提供了两个抽象类:DadaFrame和DataSet
2、特点
- 易整合:完美的把sql和spark进行了无缝连接
- 统一的数据访问:使用相同的方式连接不同的数据源
- 兼容HIVE:在现有的仓库运行sql和HiveSql
- 标准的数据库连接:JDBC、ODBC
3、DataFrame
一种以RDD为基础的分布式数据集,DataFrame具有schema信息,提供了类似字段的信息。

4、DataSet
是DataFrame的扩展,提供了RDD的优势,可以将DataFrame的一行数据映射成一个对象

二、Spark SQL编程
1、SparkSession
老版本中提供了SqlContext用于自己查询,和HiveContext用于连接Hive操作。SparkSession兼顾了两种,在spark-shell使用中,提供了spark对象可以操作sql。
2、DataFrame
- 创建:从spark数据源(spark.read.json等)、从RDD(rdd.toDF)、从hive table中
- sql语法:通过spark创建临时视图,使用saprk.sql执行相应的sql语句
- dsl语法:df.select("*")、df.grouoby()、如果使用运算符则使用df.select($"name" + "haello")
3、DataSet
- 通过seq序列创建,调用toDs方法
4、三者相互转换
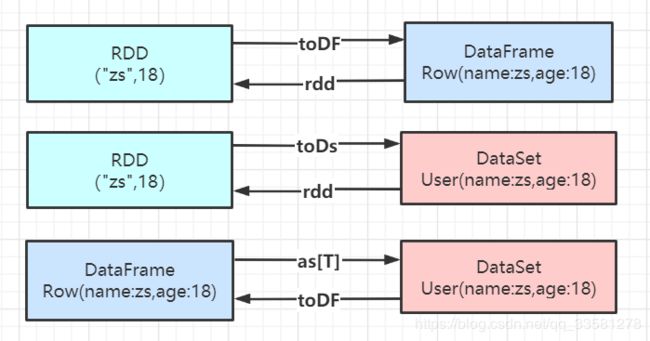
5、三者相互的共性和区别
共性:都是分布式数据集、惰性机制、拥有共同的方法、都有分区、都会根据自身情况进行缓存
区别:
- RDD:和spark mlib配合使用、不能使用spark sql
- DataFrame:每行数据为Row,不与spark mlib配合使用、支持保存为其他的文件,比如CSV
- DataSet:数据有具有映射的对象、不与spark mlib配合使用、支持保存为其他的文件,比如CSV
val conf = new SparkConf().setAppName("sparkSQL").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val df: DataFrame = spark.read.json("D:\\ideaWorkspace\\scala0105\\spark-sql\\input\\1.json")
val rdd: RDD[(String, Int)] = spark.sparkContext.makeRDD(List(("zhaoliu", 29), ("liuqi", 30)))
df.createOrReplaceTempView("user")
val sql: DataFrame = spark.sql("select * from user")
sql.show()
df.select("*").show()
val df2rdd: RDD[Row] = df.rdd
df2rdd.foreach(println)
val r2f: DataFrame = rdd.toDF()
r2f.select("*").show()
val rdd2ds: Dataset[(String, Int)] = rdd.toDS()
rdd2ds.show()
val df2ds: Dataset[User] = df.as[User]
df2ds.show()
spark.stop()
6、自定义函数(UDF、UDAF)
UDF:输入一行,输出也是一行,一对一的关系
df.createOrReplaceTempView("user_temp")
spark.udf.register("addPre",(name:String) =>{"hello " + name})
val addPreDF: DataFrame = spark.sql("select addPre(name) from user_temp")UDAF:输入多行返回一行,多对一的关系。通过继承UserDefinedAggregateFunction来实现用户自定义聚合函数。
//弱类型
val myAvg = new MyAvg
spark.udf.register("myavg",myAvg)
val ageAvg: DataFrame = spark.sql("select myavg(age) from user_temp")
class MyAvg extends UserDefinedAggregateFunction{
override def inputSchema: StructType = StructType(Array(StructField("age",LongType)))
override def bufferSchema: StructType = StructType(Array(StructField("age",LongType),StructField("count",LongType)))
override def dataType: DataType = DoubleType
override def deterministic: Boolean = true
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1L
}
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble/buffer.getLong(1)
}
//强类型
val ds: Dataset[Student] = df.as[Student]
val myAvgNew = new MyAvgNew
val col: TypedColumn[Student, Double] = myAvgNew.toColumn
ds.select(col).show()
case class Student(name:String,age:Long)
case class StudentBuffer(var allAge:Long,var allCount:Long)
class MyAvgNew extends Aggregator[Student,StudentBuffer,Double]{
override def zero: StudentBuffer = StudentBuffer(0,0)
override def reduce(b: StudentBuffer, a: Student): StudentBuffer = {
b.allAge = b.allAge + a.age
b.allCount = b.allCount + 1L
b
}
override def merge(b1: StudentBuffer, b2: StudentBuffer): StudentBuffer = {
b1.allAge = b1.allAge + b2.allAge
b1.allCount = b1.allCount + b2.allCount
b1
}
override def finish(reduction: StudentBuffer): Double = reduction.allAge.toDouble/reduction.allCount
override def bufferEncoder: Encoder[StudentBuffer] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
三、SparkSql数据的加载和保存
spark.read.load (默认parquet) 和 spark.write.save(默认parquet)修改配置项:spark.sql.sources.default
1、通用的加载和保存方式
加载:
- read:可以读取多种格式csv format jdbc json load option options orc parquet schema table text textFile
- format:spark.read.format("json").load
- option:指定一些参数,比如连接数据的需要的URL、DRIVER、USER、PASSWORD
保存:
- format:指定存储的格式,spark.write.format("json").save
- option:指定一些参数,比如连接数据的需要的URL、DRIVER、USER、PASSWORD
- mode:指定保存方式,spark.write.mode("append").format("json"),
2、mysql
val rdd: RDD[people] = spark.sparkContext.makeRDD(List(people("wusong",29),people("dawu",29)))
rdd.toDS().write.format("jdbc")
.option("url","jdbc:mysql://hadoop101:3306/test")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
.option("password","000000")
.option("dbtable","people").mode(SaveMode.Append).save()
spark.read.format("jdbc")
.option("url","jdbc:mysql://hadoop101:3306/test")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
.option("password","000000")
.option("dbtable","people").load().show()3、Hive
1、内嵌Hive:使用内嵌Hive时,为derby数据库,在本地存放,仓库也在本地
2、外部使用Hive:拷贝hive-site.xml到spark的conf目录下,确保hive可以正常使用
3、代码连接:添加hive-site.xml和依赖
开始hive支持:.enableHiveSupport()
org.apache.spark
spark-hive_2.11
2.1.1
org.apache.hive
hive-exec
1.2.1