第5章 人脸检测和识别(基于Eigenfaces算法) 个人笔记
文章目录
- 1. 前言
- 2. 静态图像中的人脸检测
- 3. 视频中的人脸及眼睛检测
- 3.1 代码
- 3.2 遇到的问题
- 3.2.1 ` roi_gray = gray[y:y + h, x:x + w]`
- 3.2.2 报错“if cv2.waitKey(1000 / 12) & 0xff == ord("q"):TypeError: integer argument expected, got float”
- 4. 人脸识别
- 4.1 生成人脸识别数据
- 4.2 加载训练数据(人脸数据及其对应ID)
- 4.2.1 代码
- 4.2.2 代码思路解析
- 4.3 基于Eigenfaces的人脸识别
- 4.3.1 代码
- 4.3.2 部分代码说明
- 5. 基于Eigenfaces的人脸识别 总程序
- 6. 总结
- 参考链接
1. 前言
主要针对 《OpenCV 3 计算机视觉 Python语言实现》 第5章 人脸检测和识别 做的个人笔记。
本章主要分为三部分:静态图像中的人脸检测 、视频中的人脸及眼睛检测 和 人脸识别 。
其中,人脸识别这一部分问题较多,现已基本解决,特此记录。
2. 静态图像中的人脸检测
源码比较简单,修改后的代码我也加了详细的注释,就不再单独对算法进行介绍了。
import cv2
# 图像路径
filename = 'vikings1.jpg'
# 定义检测函数
def detect(filename):
# 从文件中加载人脸分类器
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml')
# 读取图像并灰度化
img = cv2.imread(filename)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 图像上绘制识别到的人脸框
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 创建窗口,显示检测图像并保存
cv2.namedWindow('Vikings Detected!!')
cv2.imshow('Vikings Detected!!', img)
cv2.imwrite('vikings22.jpg', img)
cv2.waitKey(0)
detect(filename)
3. 视频中的人脸及眼睛检测
3.1 代码
源码在上一章的基础上添加了眼睛识别,代码我加了详细的注释,就不再单独对算法进行介绍了。
import cv2
# 定义检测函数
def detect():
# 从文件中加载人脸分类器
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('./cascades/haarcascade_eye.xml')
# 打开摄像头
camera = cv2.VideoCapture(0)
while (True):
# 读取摄像头当前帧并灰度化
_, frame = camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
# 图像上绘制识别到的人脸框
img = cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 复制人脸框,并在此区域进行眼睛检测
roi_gray = gray[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(roi_gray, 1.03, 5, 0, (40, 40))
# 图像上绘制识别到的眼睛框
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(img, (x + ex, y + ey), (x + ex + ew, y + ey + eh), (0, 255, 0), 2)
# 显示识别图像
cv2.imshow("camera", frame)
# 当键盘按下'q',退出
if cv2.waitKey(1000 // 12) == ord("q"):
break
# 释放摄像头并销毁窗口
camera.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
detect()
3.2 遇到的问题
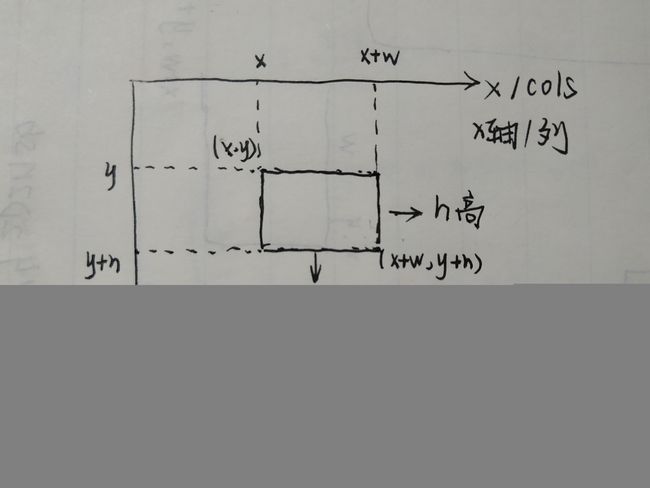
3.2.1 roi_gray = gray[y:y + h, x:x + w]
为什么矩阵复制是y在第一维而不是x?
参考链接1.
图像坐标系不同于传统的坐标系,y轴等同于行,x轴等同于列。
3.2.2 报错“if cv2.waitKey(1000 / 12) & 0xff == ord(“q”):TypeError: integer argument expected, got float”
应改为
if cv2.waitKey(1000 // 12) & 0xff == ord("q"):
" / “就表示 浮点数除法,返回浮点结果;” // "表示整数除法。
对两个整数进行除的运算,同时结果会舍去小数部分,返回一个整数。
此语句作用:
waitKey()的参数为等待键盘触发时间,如果83ms内有按键按下且其对应ASCII码为‘q’的ASCII码,则退出。
在所有系统中,可以通过读取返回值的最后一个字节来保证只提取ASCII码。
keycode = cv2.waitKey(1)
if keycode != -1:
keycode &= 0xFF
4. 人脸识别
4.1 生成人脸识别数据
该代码在上一章的基础上略微修改,代码我加了详细的注释,就不再单独对算法进行介绍了。
import cv2
# 生成人脸数据
def generate():
# 从文件中加载人脸分类器
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml')
# 打开摄像头
camera = cv2.VideoCapture(0)
# 照片数量置0
count = 0
while (True):
# 读取摄像头当前帧并灰度化
_, frame = camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
# 图像上绘制识别到的人脸框
cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
# 调整灰度化的帧的大小,并将其存储
f = cv2.resize(gray[y:y+h, x:x+w], (200, 200))
cv2.imwrite('data/%s.pgm' % str(count), f)
print(count)
# 照片数量加1
count += 1
# 显示检测图像
cv2.imshow("camera", frame)
# 当键盘按下'q',退出
if cv2.waitKey(1000 // 12) & 0xff == ord("q"):
break
# 释放摄像头并销毁窗口
camera.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
generate()
4.2 加载训练数据(人脸数据及其对应ID)
本文并没有采用CSV文件,ID在加载人脸数据时自动生成。不同人的人脸数据位于不同的子文件夹下,加载人脸数据时,对不同的子文件夹的人脸数据赋不同的ID值,用以区分。
4.2.1 代码
参考链接2.代码是自己改的,并详细注释的。
# 加载数据并给ID赋值,每个子目录下表示不同人的数据,赋不同的ID值
def read_images(path):
# 初始化ID值
id = 0
# 定义2个列表,X存放路径下每幅图片的数组列表,y存放路径下每幅图片的ID
X = []
y = []
# 扫描路径下的路径名,文件名
for dirname, dirnames, filenames in os.walk(path):
for subdirname in dirnames:
subject_path = os.path.join(dirname, subdirname)
for filename in os.listdir(subject_path):
try:
# 连接路径
filename = os.path.join(subject_path, filename)
# 以灰度图读取该图片,并将其添加到X中
im = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)
X.append(np.asarray(im, dtype=np.uint8))
# 将该图片对应的ID添加到y中
y.append(id)
# 异常处理
except IOError as e:
print('I/O error({0}):{1}'.format(e.errno, e.strerror))
except:
print("unexpected error:", sys.exc_info()[0])
raise
# 多人训练,不同人对应不同的ID
id = id + 1
return [X, y]
4.2.2 代码思路解析
这一部分是我理解最吃力的地方,所以加上代码思路。
- 通过
os.walk得到起始路径dirname和起始路径下的文件夹dirnames - 使用for循环遍历dirnames
对于不同的子文件subdirname,通过os.path.join得到每个子文件夹的路径(代表不同的人对应的人脸数据)
读取该路径下的所有图片并灰度化
将图片添加到X中,将ID添加到y中 - 返回X,y
4.3 基于Eigenfaces的人脸识别
4.3.1 代码
参考链接2.代码是自己改的,并详细注释的。
# 人脸识别
def face_rec():
# 定义一个名字的列表,不同人的ID对应不同的名字
names = ['L1', 'L2', 'L3', 'L4']
# 加载数据并读取其对应的ID值
[X, y] = read_images(filepath)
# 此处可以观察ID值,检验程序
print(y)
# 创建一个基于Eigenfaces的人脸识别的实例
model = cv2.face.EigenFaceRecognizer_create()
# 训练数据
model.train(np.asarray(X), np.asarray(y))
# 从文件中加载分类器
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml')
# 打开摄像头
camera = cv2.VideoCapture(0)
while(True):
# 读取摄像头当前帧
read, img = camera.read()
# 对当前帧进行人脸检测
faces = face_cascade.detectMultiScale(img, 1.3, 5)
for (x, y, w, h) in faces:
# 在当前帧绘制检测到的脸框
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 将当前帧灰度化并复制检测到的ROI
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
roi = gray[x: x + w, y: y + h]
try:
# 使用最邻近插值修改ROI大小
roi = cv2.resize(roi, (200, 200), interpolation=cv2.INTER_LINEAR)
# 预测,得到预测的ID及置信度
params = model.predict(roi)
# 打印预测的ID及置信度
print("Label: %s, Confidence: %.2f" % (params[0], params[1]))
# 绘制预测的ID及置信度
cv2.putText(img, names[params[0]], (x, y - 20),cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 2)
cv2.putText(img, str(np.around(params[1], decimals=2)), (x + 60, y - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 1)
except:
continue
# 显示识别图像
cv2.imshow("camera", img)
# 当键盘按下'q',退出
if cv2.waitKey(1000 // 12) & 0xff == ord("q"):
break
# 释放摄像头并销毁窗口
camera.release()
cv2.destroyAllWindows()
4.3.2 部分代码说明
- 名字列表names
这能根据对应的ID值,显示识别人的真实名字。例如,在本程序中如果ID=0,则通过cv2.putText会显示‘L1’. - 训练算法修改
本文应用的基于Eigenfaces的人脸识别,可以修改model的值来改变人脸识别的算法。
基于Fisherfaces的人脸识别和基于LBPH的人脸识别的model分别为:
model = cv2.face.FisherFaceRecognizer_create()
model = cv2.face.LBPHFaceRecognizer_create()
- predict()函数
predict()返回含有两个元素的数组:第一个是所识别个体的ID,第二个是置信度评分。
5. 基于Eigenfaces的人脸识别 总程序
import os
import sys
import cv2
import numpy as np
# 训练数据的路径
filepath = 'data_Li\\'
# 加载数据并给ID赋值,每个子目录下表示不同人的数据,赋不同的ID值
def read_images(path):
--snip--
# 人脸识别
def face_rec():
--snip--
# 加载数据并读取其对应的ID值
[X, y] = read_images(filepath)
--snip--
if __name__ == "__main__":
face_rec()
6. 总结
本文主要针对 《OpenCV 3 计算机视觉 Python语言实现》 第5章 人脸检测和识别 的内容,做了一份笔记。
不得不吐槽一下这么书的代码,有点乱,残缺不全,不知道是不是翻译的问题。
当然,你强到改源码顺风顺水,也就不用在乎这些小麻烦了~
期间,最大的问题就是ID赋值那一块,差点把c与生成人脸数据时的count混淆。当时还纳闷CSV文件,在我看来,实际上书上的源码并没有使用,只是单纯的赋值。
第一次做人脸识别,觉得很神奇。从自己通过摄像头生成自己人脸的训练数据,到啃懂ID,最后在窗口中识别自己,很是开心。
其实,我不懂PCA,也不懂Fisher,只是数学建模的时候数院队友用过。这些写好的训练器,才是真的强。
我也不知道这三大训练器的内部原理。在我看来,训练器的书写,才是整个过程最重要的部分。
不知道未来的自己能不能写出合格的训练器,但对机器学习的未来充满信心。
个人水平有限,也没有搞懂各个训练器的内部原理。有问题欢迎各位大神批评指正!
参考链接
- 不再纠结OpenCV图像中的x,y;width,height;cols,rows
https://blog.csdn.net/u014177533/article/details/75677287#commentBox - OpenCV3计算机视觉Python语言实现人脸识别笔记
https://blog.csdn.net/rencia/article/details/79779365