最详细的Hadoop安装教程
最详细的Hadoop安装教程
前言
Hadoop 在大数据技术体系中的地位至关重要,Hadoop 是大数据技术的基础,对Hadoop基础知识的掌握的扎实程度,会决定在大数据技术道路上走多远。
这是一篇入门文章,Hadoop 的学习方法很多,网上也有很多学习路线图。本文的思路是:以安装部署 Apache Hadoop2.x 版本为主线,来介绍 Hadoop2.x 的架构组成、各模块协同工作原理、技术细节。安装不是目的,通过安装认识Hadoop才是目的。
本文分为五个部分、十三节、四十九步。
第一部分:Linux环境安装
Hadoop是运行在Linux,虽然借助工具也可以运行在Windows上,但是建议还是运行在Linux系统上,第一部分介绍Linux环境的安装、配置、Java JDK安装等。
第二部分:Hadoop本地模式安装
Hadoop 本地模式只是用于本地开发调试,或者快速安装体验 Hadoop,这部分做简单的介绍。
第三部分:Hadoop伪分布式模式安装
学习 Hadoop 一般是在伪分布式模式下进行。这种模式是在一台机器上各个进程上运行 Hadoop 的各个模块,伪分布式的意思是虽然各个模块是在各个进程上分开运行的,但是只是运行在一个操作系统上的,并不是真正的分布式。
第四部分:完全分布式安装
完全分布式模式才是生产环境采用的模式,Hadoop 运行在服务器集群上,生产环境一般都会做HA,以实现高可用。
第五部分:Hadoop HA安装
HA是指高可用,为了解决Hadoop单点故障问题,生产环境一般都做HA部署。这部分介绍了如何配置Hadoop2.x的高可用,并简单介绍了HA的工作原理。
安装过程中,会穿插简单介绍涉及到的知识。希望能对大家有所帮助。
第一部分:Linux环境安装
第一步、配置 Vmware NAT 网络
一、Vmware 网络模式介绍
参考:http://blog.csdn.net/collection4u/article/details/14127671
二、NAT模式配置
NAT是网络地址转换,是在宿主机和虚拟机之间增加一个地址转换服务,负责外部和虚拟机之间的通讯转接和IP转换。
我们部署Hadoop集群,这里选择NAT模式,各个虚拟机通过NAT使用宿主机的IP来访问外网。
我们的要求是集群中的各个虚拟机有固定的IP、可以访问外网,所以进行如下设置:
\1. Vmware 安装后,默认的 NAT 设置如下:
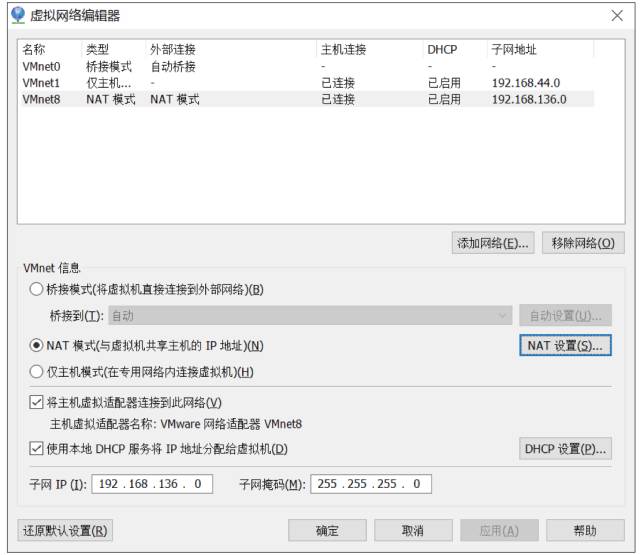
\2. 默认的设置是启动DHCP服务的,NAT会自动给虚拟机分配IP,但是我们需要将各个机器的IP固定下来,所以要取消这个默认设置。
\3. 为机器设置一个子网网段,默认是192.168.136网段,我们这里设置为100网段,将来各个虚拟机Ip就为 192.168.100.*。
\4. 点击NAT设置按钮,打开对话框,可以修改网关地址和DNS地址。这里我们为NAT指定DNS地址。
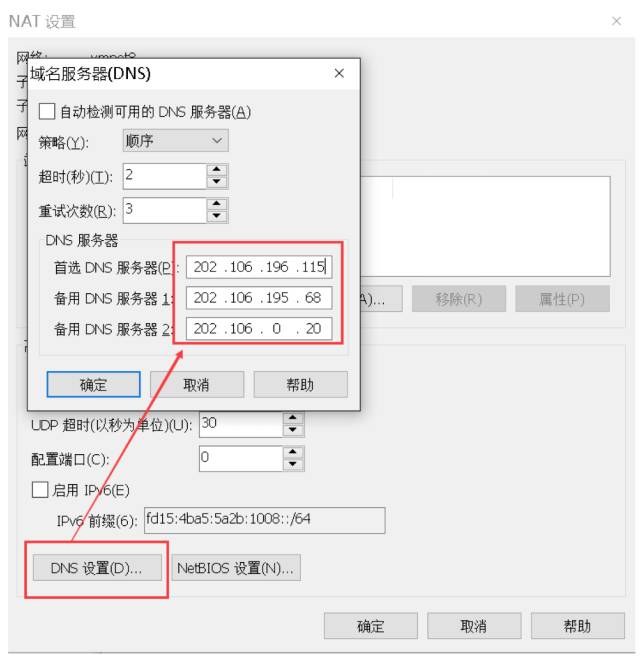
\5. 网关地址为当前网段里的.2地址,好像是固定的,我们不做修改,先记住网关地址就好了,后面会用到。
第二步、安装Linux操作系统
三、Vmware 上安装 Linux系统
\1. 文件菜单选择新建虚拟机
\2. 选择经典类型安装,下一步。
\3. 选择稍后安装操作系统,下一步。
\4. 选择 Linux 系统,版本选择 CentOS 64 位。
\5. 命名虚拟机,给虚拟机起个名字,将来显示在Vmware左侧。并选择Linux系统保存在宿主机的哪个目录下,应该一个虚拟机保存在一个目录下,不能多个虚拟机使用一个目录。
\6. 指定磁盘容量,是指定分给Linux虚拟机多大的硬盘,默认20G就可以,下一步。
\7. 点击自定义硬件,可以查看、修改虚拟机的硬件配置,这里我们不做修改。
\8. 点击完成后,就创建了一个虚拟机,但是此时的虚拟机还是一个空壳,没有操作系统,接下来安装操作系统。
\9. 点击编辑虚拟机设置,找到DVD,指定操作系统ISO文件所在位置。
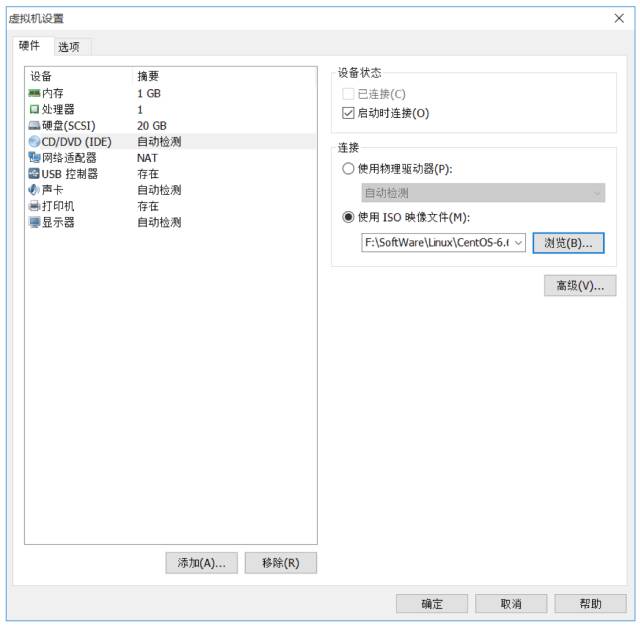
\10. 点击开启此虚拟机,选择第一个回车开始安装操作系统。
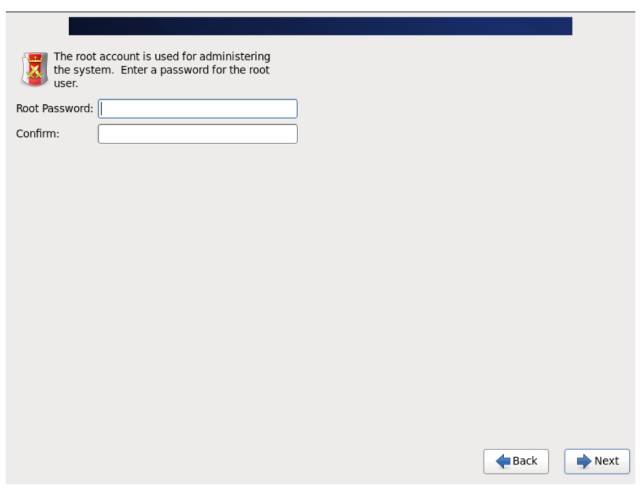
\11. 设置 root 密码。
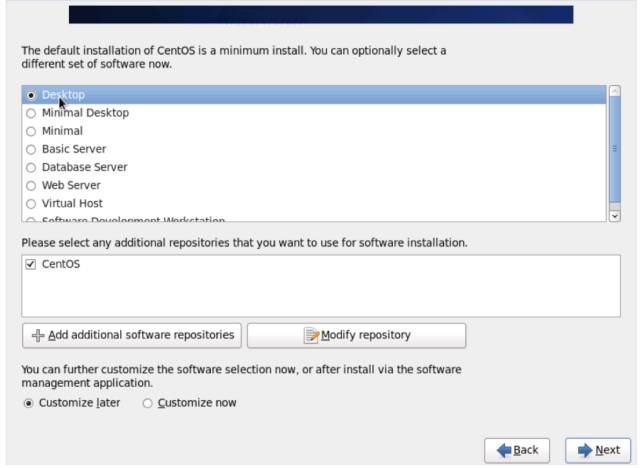
\12. 选择 Desktop,这样就会装一个 Xwindow。
\13. 先不添加普通用户,其他用默认的,就把Linux安装完毕了。
四、设置网络
因为 Vmware 的 NAT 设置中关闭了 DHCP 自动分配 IP 功能,所以 Linux 还没有 IP,需要我们设置网络各个参数。
\1. 用 root 进入 Xwindow,右击右上角的网络连接图标,选择修改连接。
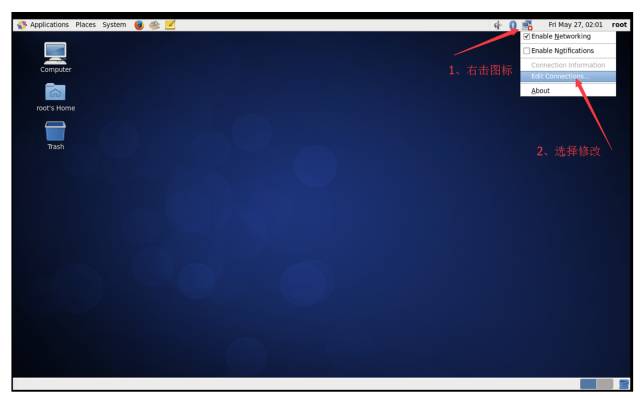
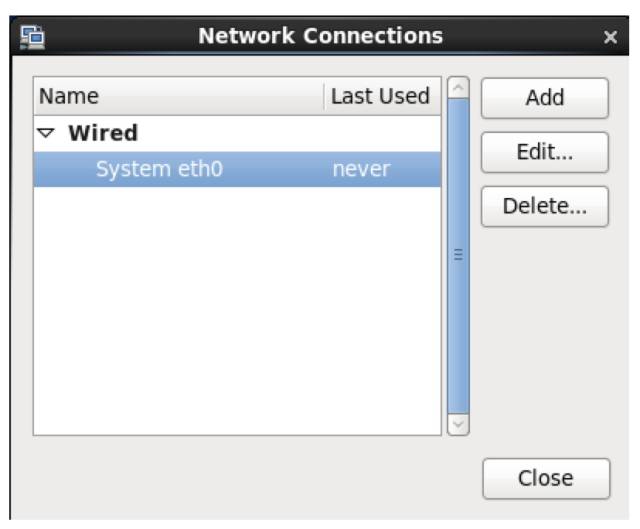
\2. 网络连接里列出了当前 Linux 里所有的网卡,这里只有一个网卡 System eth0,点击编辑。
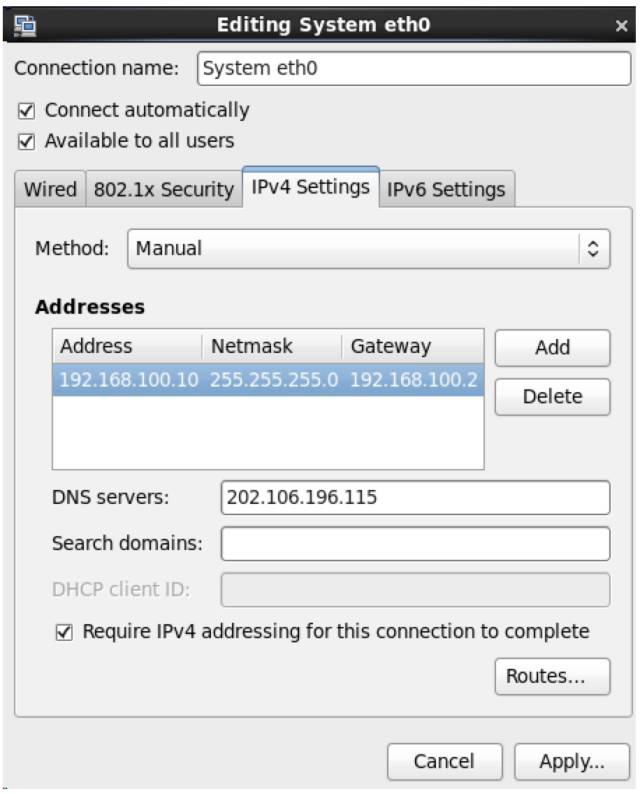
\3. 配置IP、子网掩码、网关(和NAT设置的一样)、DNS等参数,因为NAT里设置网段为100.*,所以这台机器可以设置为192.168.100.10网关和NAT一致,为192.168.100.2
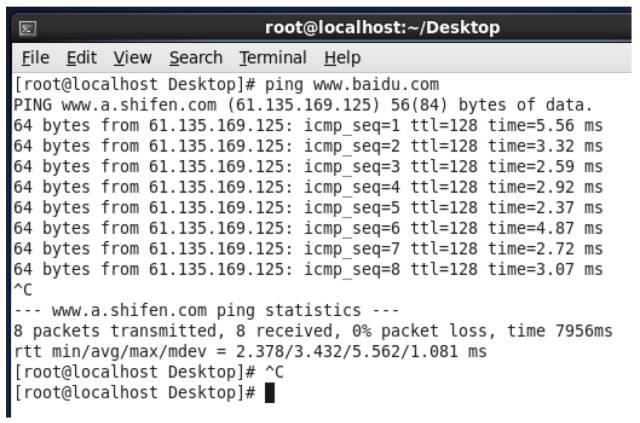
\4. 用ping来检查是否可以连接外网,如下图,已经连接成功。
五、修改 Hostname
\1. 临时修改 hostname
[root@localhost Desktop]# hostname work1
这种修改方式,系统重启后就会失效。
\2. 永久修改 hostname
想永久修改,应该修改配置文件 /etc/sysconfig/network。
命令:[root@bigdata-senior01 ~] vim /etc/sysconfig/network
打开文件后,
NETWORKING=yes #使用网络HOSTNAME=work1 #设置主机名
六、配置Host
命令:[root@bigdata-senior01 ~] vim /etc/hosts添加hosts: 192.168.100.10 work1
七、关闭防火墙
学习环境可以直接把防火墙关闭掉。
(1) 用root用户登录后,执行查看防火墙状态。
[root@bigdata-senior01 hadoop]# service iptables status
(2) 用 [root@bigdata-senior01 hadoop]# service iptables stop 关闭防火墙,这个是临时关闭防火墙。
[root@bigdata-senior01 hadoop-2.5.0]# service iptables stopiptables: Setting chains to policy ACCEPT: filter [ OK ]iptables: Flushing firewall rules: [ OK ]iptables: Unloading modules: [ OK ]
(3) 如果要永久关闭防火墙用。
[root@bigdata-senior01 hadoop]# chkconfig iptables off
关闭,这种需要重启才能生效。
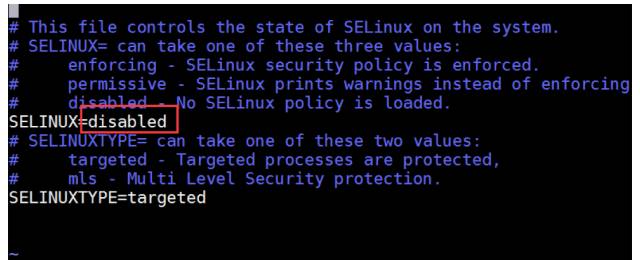
八、关闭selinux
selinux是Linux一个子安全机制,学习环境可以将它禁用。

第三步、安装JDK
九、安装 Java JDK
\1. 查看是否已经安装了 java JDK。
[root@bigdata-senior01 Desktop]# java –version
注意:Hadoop 机器上的 JDK,最好是 Oracle 的 Java JDK,不然会有一些问题,比如可能没有 JPS 命令。
如果安装了其他版本的 JDK,卸载掉。
\2. 安装 java JDK
(1) 去下载 Oracle 版本 Java JDK:jdk-7u67-linux-x64.tar.gz
(2) 将 jdk-7u67-linux-x64.tar.gz 解压到 /opt/modules 目录下
[root@bigdata-senior01 /]# tar -zxvf jdk-7u67-linux-x64.tar.gz -C /opt/modules
(3) 添加环境变量
设置 JDK 的环境变量 JAVA_HOME。需要修改配置文件/etc/profile,追加
export JAVA_HOME="/opt/modules/jdk1.7.0_67"export PATH=$JAVA_HOME/bin:$PATH
修改完毕后,执行 source /etc/profile
(4)安装后再次执行 java –version,可以看见已经安装完成。

第二部分:Hadoop本地模式安装
第四步、Hadoop部署模式
Hadoop 部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是 NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
| 模式名称 | 各个模块占用的JVM进程数 | 各个模块运行在几个机器数上 |
|---|---|---|
| 本地模式 | 1个 | 1个 |
| 伪分布式模式 | N个 | 1个 |
| 完全分布式模式 | N个 | N个 |
| HA完全分布式 | N个 | N个 |
第五步、本地模式部署
十、本地模式介绍
本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。下载 hadoop 安装包后不用任何设置,默认的就是本地模式。
十一、解压hadoop后就是直接可以使用
\1. 创建一个存放本地模式hadoop的目录
[hadoop@bigdata-senior01 modules]$ mkdir /opt/modules/hadoopstandalone
\2. 解压 hadoop 文件

\3. 确保 JAVA_HOME 环境变量已经配置好
[hadoop@bigdata-senior01 modules]$ echo ${JAVA_HOME}/opt/modules/jdk1.7.0_67
十二、运行MapReduce程序,验证
我们这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
\1. 准备mapreduce输入文件wc.input
[hadoop@bigdata-senior01 modules]$ cat /opt/data/wc.inputhadoop mapreduce hivehbase spark stormsqoop hadoop hivespark hadoop
\2. 运行 hadoop 自带的 mapreduce Demo

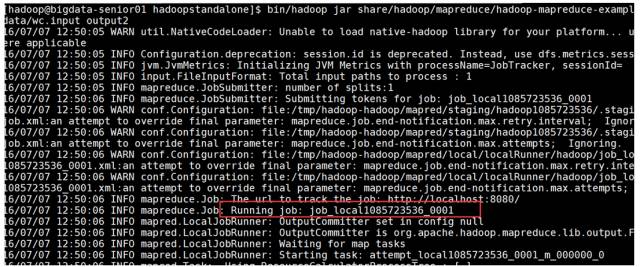
这里可以看到 job ID 中有 local 字样,说明是运行在本地模式下的。
\3. 查看输出文件
本地模式下,mapreduce 的输出是输出到本地。
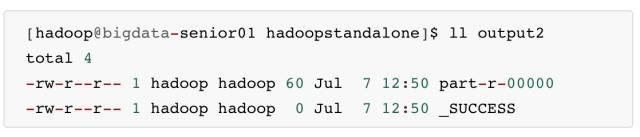
输出目录中有 _SUCCESS 文件说明 JOB 运行成功,part-r-00000 是输出结果文件。
第三部分:Hadoop 伪分布式模式安装
第六步 伪分布式 Hadoop 部署过程
十三、Hadoop 所用的用户设置
\1. 创建一个名字为 hadoop 的普通用户

\2. 给 hadoop 用户 sudo 权限

设置权限,学习环境可以将 hadoop 用户的权限设置的大一些,但是生产环境一定要注意普通用户的权限限制。

注意:如果root用户无权修改sudoers文件,先手动为root用户添加写权限。
![]()
\3. 切换到hadoop用户
[root@bigdata-senior01 ~]# su - hadoop[hadoop@bigdata-senior01 ~]$
\4. 创建存放hadoop文件的目录

\5. 将hadoop文件夹的所有者指定为hadoop用户
如果存放hadoop的目录的所有者不是hadoop,之后hadoop运行中可能会有权限问题,那么就讲所有者改为hadoop。

十四、解压Hadoop目录文件
\1. 复制 hadoop-2.5.0.tar.gz 到/opt/modules目录下。
\2. 解压 hadoop-2.5.0.tar.gz

十五、配置 Hadoop
\1. 配置 Hadoop 环境变量

追加配置:

执行:source /etc/profile 使得配置生效
验证 HADOOP_HOME 参数:

\2. 配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh 文件的 JAVA_HOME参数

\3. 配置 core-site.xml
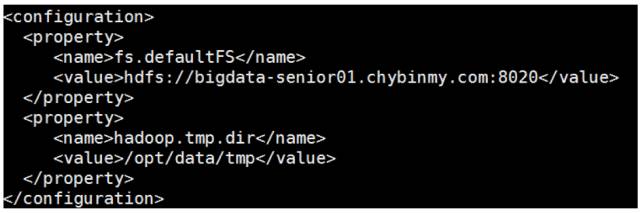
[hadoop@bigdata-senior01 ~]$ sudo vim ${HADOOP_HOME}/etc/hadoop/core-site.xml
(1) fs.defaultFS 参数配置的是HDFS的地址。

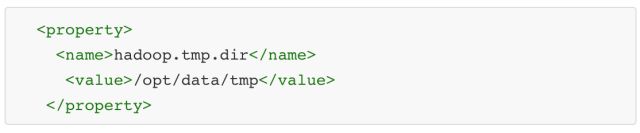
(2) hadoop.tmp.dir配置的是Hadoop临时目录,比如HDFS的NameNode数据默认都存放这个目录下,查看*-default.xml等默认配置文件,就可以看到很多依赖${hadoop.tmp.dir}的配置。
默认的hadoop.tmp.dir是/tmp/hadoop-${user.name},此时有个问题就是 NameNode 会将 HDFS 的元数据存储在这个/tmp目录下,如果操作系统重启了,系统会清空 /tmp 目录下的东西,导致NameNode元数据丢失,是个非常严重的问题,所有我们应该修改这个路径。
- 创建临时目录:

- 将临时目录的所有者修改为 hadoop

- 修改 hadoop.tmp.dir
十六、配置、格式化、启动 HDFS
\1. 配置 hdfs-site.xml
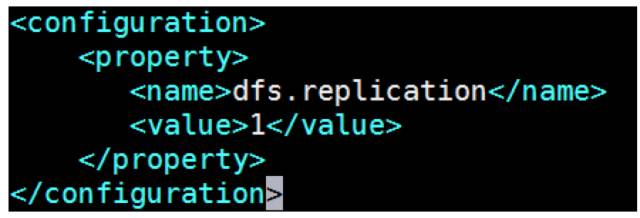
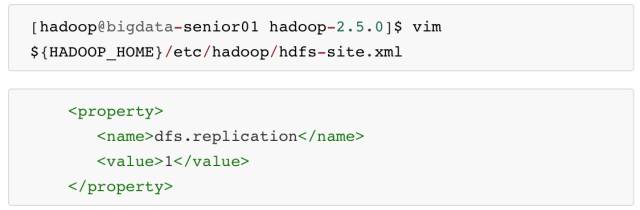
dfs.replication 配置的是 HDFS存 储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1。
\2. 格式化 HDFS
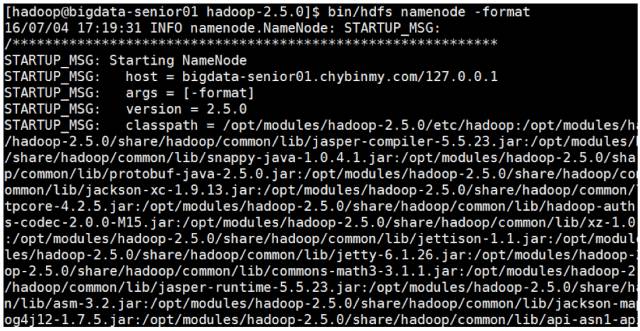

格式化是对 HDFS 这个分布式文件系统中的 DataNode 进行分块,统计所有分块后的初始元数据的存储在 NameNode 中。
格式化后,查看 core-site.xml 里 hadoop.tmp.dir(本例是 /opt/data 目录)指定的目录下是否有了 dfs 目录,如果有,说明格式化成功。
注意:
- 格式化时,这里注意 hadoop.tmp.dir 目录的权限问题,应该 hadoop 普通用户有读写权限才行,可以将 /opt/data 的所有者改为 hadoop。
[hadoop@bigdata-senior01 hadoop-2.5.0]$ sudo chown -R hadoop:hadoop /opt/data - 查看 NameNode 格式化后的目录。
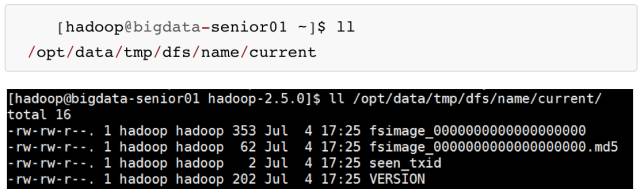
fsimage 是 NameNode 元数据在内存满了后,持久化保存到的文件。
fsimage*.md5 是校验文件,用于校验 fsimage 的完整性。
seen_txid 是 hadoop 的版本
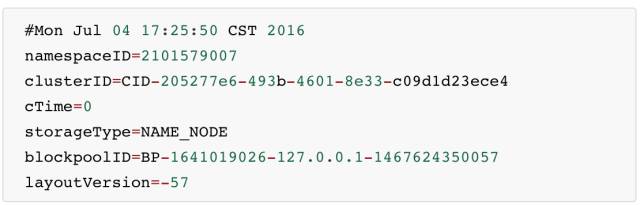
vession 文件里保存:
- namespaceID:NameNode 的唯一 ID。
- clusterID:集群 ID,NameNode 和 DataNode 的集群 ID 应该一致,表明是一个集群。
\3. 启动 NameNode

![]()
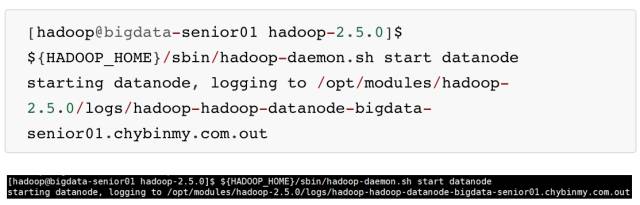
\4. 启动 DataNode
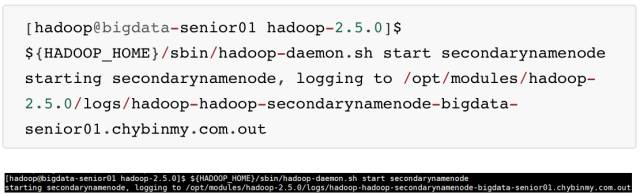
\5. 启动 SecondaryNameNode
\6. JPS 命令查看是否已经启动成功,有结果就是启动成功了。
\7. HDFS 上测试创建目录、上传、下载文件
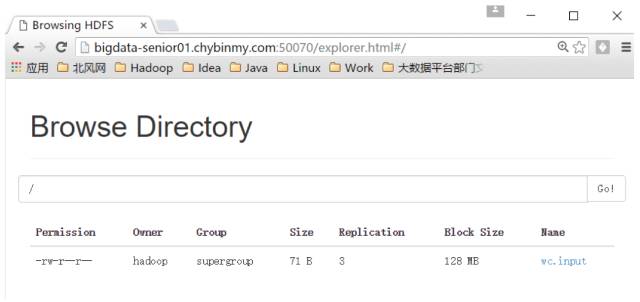
HDFS 上创建目录

上传本地文件到 HDFS 上

读取 HDFS 上的文件内容

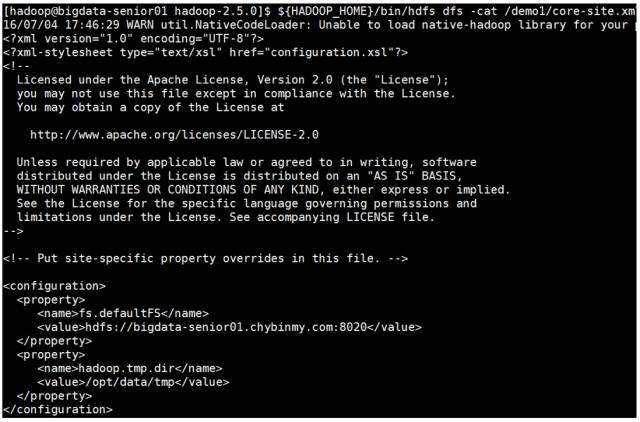
从 HDFS上 下载文件到本地
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -get /demo1/core-site.xml
十七、配置、启动YARN
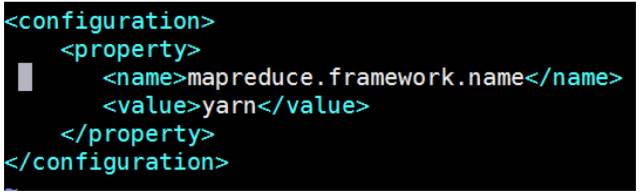
\1. 配置mapred-site.xml
默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。

添加配置如下:

指定 mapreduce 运行在 yarn 框架上。
\2. 配置 yarn-site.xml
添加配置如下:

-
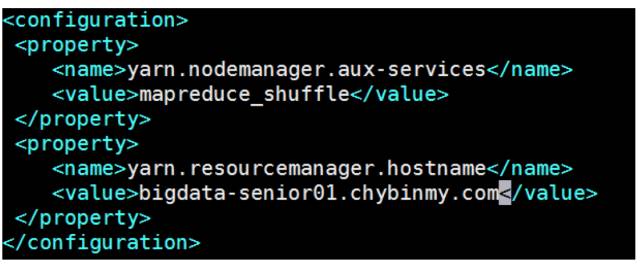
yarn.nodemanager.aux-services 配置了 yarn 的默认混洗方式,选择为 mapreduce 的默认混洗算法。
-
yarn.resourcemanager.hostname 指定了 Resourcemanager 运行在哪个节点上。
\3. 启动 Resourcemanager

![]()
\4. 启动 nodemanager

![]()
\5. 查看是否启动成功

可以看到 ResourceManager、NodeManager 已经启动成功了。

\6. YARN 的 Web 页面
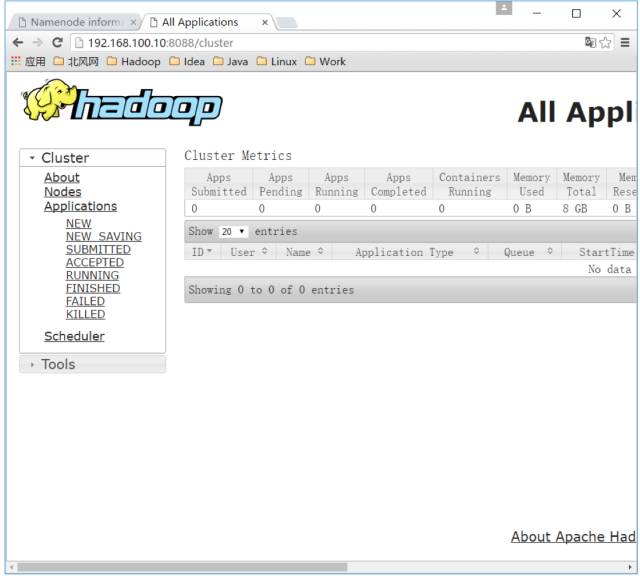
YARN 的 Web 客户端端口号是 8088,通过 http://192.168.100.10:8088/ 可以查看。
十八、运行 MapReduce Job
在 Hadoop 的 share 目录里,自带了一些 jar 包,里面带有一些 mapreduce 实例小例子,位置在 share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar,可以运行这些例子体验刚搭建好的Hadoop平台,我们这里来运行最经典的 WordCount 实例。
\1. 创建测试用的 Input 文件
创建输入目录:

创建原始文件:
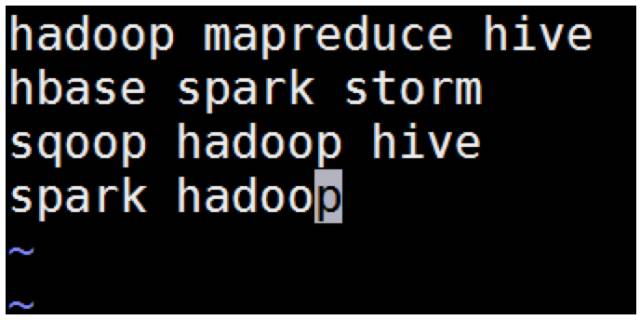
在本地 /opt/data 目录创建一个文件 wc.input,内容如下。
将 wc.input 文件上传到 HDFS 的 /wordcountdemo/input 目录中:


\2. 运行 WordCount MapReduce Job

\3. 查看输出结果目录
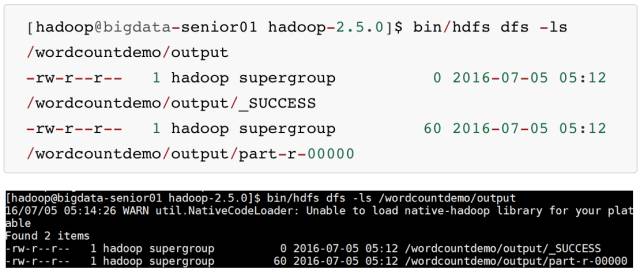
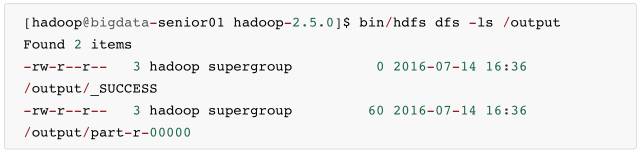
- output 目录中有两个文件,_SUCCESS 文件是空文件,有这个文件说明Job执行成功。
- part-r-00000文件是结果文件,其中-r-说明这个文件是 Reduce 阶段产生的结果,mapreduce 程序执行时,可以没有 reduce 阶段,但是肯定会有 map 阶段,如果没有 reduce 阶段这个地方有是-m-。
- 一个 reduce 会产生一个 part-r- 开头的文件。
- 查看输出文件内容。
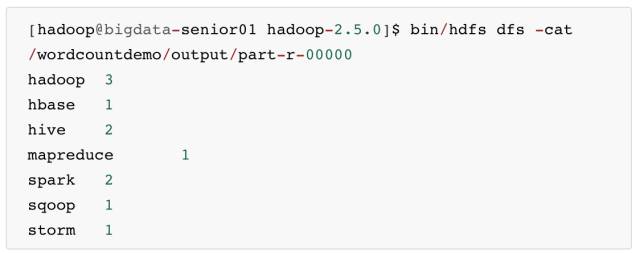
结果是按照键值排好序的。
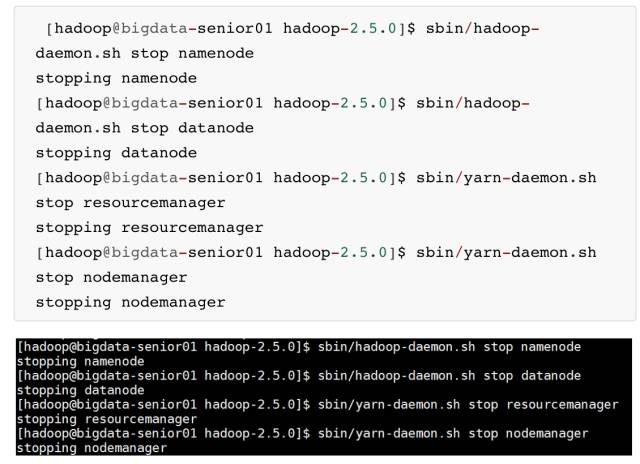
十九、停止 Hadoop
二十、 Hadoop 各个功能模块的理解
\1. HDFS模块
HDFS 负责大数据的存储,通过将大文件分块后进行分布式存储方式,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,HDFS 是个相对独立的模块,可以为 YARN 提供服务,也可以为 HBase 等其他模块提供服务。
\2. YARN 模块
YARN 是一个通用的资源协同和任务调度框架,是为了解决 Hadoop1.x 中MapReduce 里 NameNode 负载太大和其他问题而创建的一个框架。
YARN 是个通用框架,不止可以运行 MapReduce,还可以运行Spark、Storm等其他计算框架。
\3. MapReduce 模块
MapReduce 是一个计算框架,它给出了一种数据处理的方式,即通过 Map 阶段、Reduce阶段来分布式地流式处理数据。它只适用于大数据的离线处理,对实时性要求很高的应用不适用。
第七步 开启历史服务
二十一、历史服务介绍
Hadoop 开启历史服务可以在 web 页面上查看 Yarn 上执行 job 情况的详细信息。可以通过历史服务器查看已经运行完的 Mapreduce 作业记录,比如用了多少个 Map、用了多少个 Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
二十二、开启历史服务

开启后,可以通过 Web 页面查看历史服务器:
http://work1:19888/
二十三、Web 查看 job 执行历史
\1. 运行一个 mapreduce 任务

\2. job 执行中
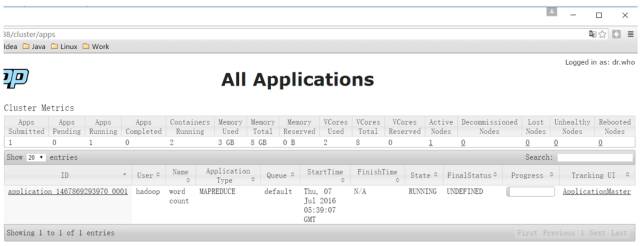
\3. 查看 job 历史
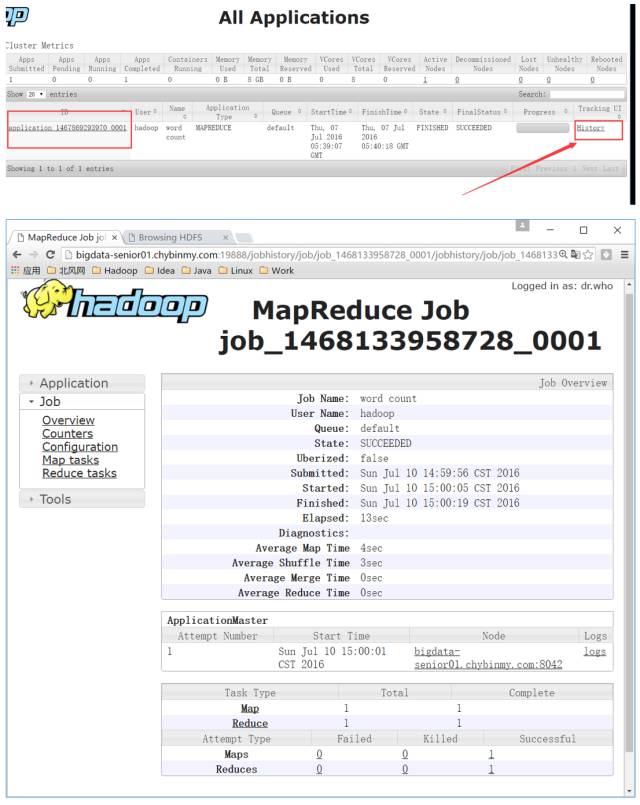
历史服务器的 Web 端口默认是19888,可以查看Web界面。
但是在上面所显示的某一个 Job 任务页面的最下面,Map 和 Reduce 个数的链接上,点击进入 Map 的详细信息页面,再查看某一个 Map 或者 Reduce 的详细日志是看不到的,是因为没有开启日志聚集服务。
二十四、开启日志聚集
\4. 日志聚集介绍
MapReduce是在各个机器上运行的,在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在HDFS上,这个过程就是日志聚集。
\5. 开启日志聚集
配置日志聚集功能:
Hadoop 默认是不启用日志聚集的。在 yarn-site.xml 文件里配置启用日志聚集。

yarn.log-aggregation-enable:是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds:设置日志保留时间,单位是秒。
将配置文件分发到其他节点:

重启 Yarn 进程:

重启 HistoryServer 进程:

\6. 测试日志聚集
运行一个 demo MapReduce,使之产生日志:

查看日志:
运行 Job 后,就可以在历史服务器 Web 页面查看各个 Map 和 Reduce 的日志了。
第四部分:完全分布式安装
第八步 完全布式环境部署 Hadoop
完全分部式是真正利用多台 Linux 主机来进行部署 Hadoop,对 Linux 机器集群进行规划,使得 Hadoop 各个模块分别部署在不同的多台机器上。
二十五、环境准备
\1. 克隆虚拟机
- Vmware 左侧选中要克隆的机器,这里对原有的 BigData01 机器进行克隆,虚拟机菜单中,选中管理菜单下的克隆命令。
- 选择“创建完整克隆”,虚拟机名称为 BigData02,选择虚拟机文件保存路径,进行克隆。
- 再次克隆一个名为 BigData03 的虚拟机。
\2. 配置网络
修改网卡名称:
在 BigData02 和 BigData03 机器上编辑网卡信息。执行 sudo vim /etc/udev/rules.d/70-persistent-net.rules 命令。因为是从 BigData01 机器克隆来的,所以会保留 BigData01 的网卡 eth0,并且再添加一个网卡 eth1。
并且 eth0 的 Mac 地址和 BigData01 的地址是一样的,Mac 地址不允许相同,所以要删除 eth0,只保留 eth1 网卡,并且要将 eth1改名为 eth0。将修改后的 eth0 的 mac 地址复制下来,修改 network-scripts 文件中的 HWADDR 属性。
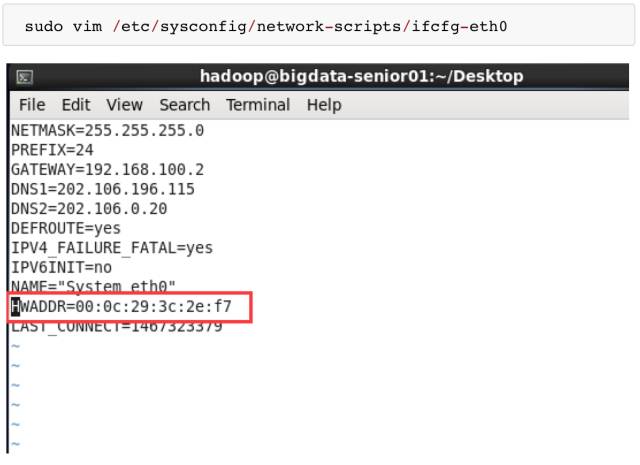
修改网络参数:
BigData02机器IP改为192.168.100.12
BigData03机器IP改为192.168.100.13
\3. 配置 Hostname
BigData02 配置 hostname 为 work2
BigData03 配置 hostname 为 work3
\4. 配置 hosts
BigData01、BigData02、BigData03 三台机器 hosts 都配置为:

\5. 配置 Windows 上的 SSH 客户端
在本地 Windows 中的 SSH 客户端上添加对 BigData02、BigData03 机器的SSH链接。
二十六、服务器功能规划
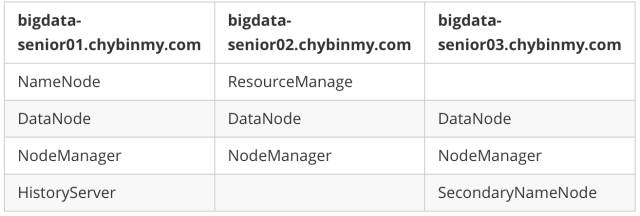
为了和之前 BigData01 机器上安装伪分布式 Hadoop 区分开来,我们将 BigData01上的 Hadoop 服务都停止掉,然后在一个新的目录 /opt/modules/app下安装另外一个Hadoop。
二十七、在第一台机器上安装新的 Hadoop
我们采用先在第一台机器上解压、配置 Hadoop,然后再分发到其他两台机器上的方式来安装集群。
\6. 解压 Hadoop 目录:

\7. 配置 Hadoop JDK 路径修改 hadoop-env.sh、mapred-env.sh、yarn-env.sh 文件中的 JDK 路径:
![]()
\8. 配置 core-site.xml
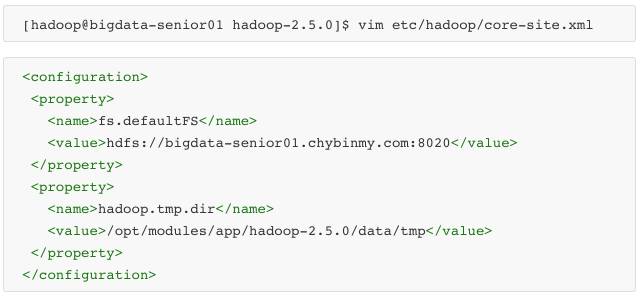
fs.defaultFS 为 NameNode 的地址。
hadoop.tmp.dir 为 hadoop 临时目录的地址,默认情况下,NameNode 和 DataNode 的数据文件都会存在这个目录下的对应子目录下。应该保证此目录是存在的,如果不存在,先创建。
\9. 配置 hdfs-site.xml
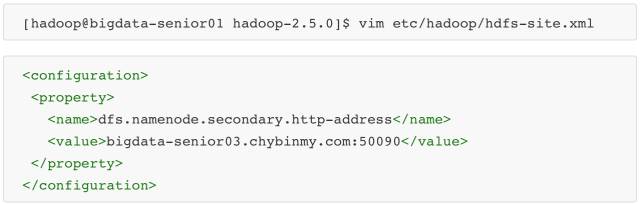
dfs.namenode.secondary.http-address 是指定 secondaryNameNode 的 http 访问地址和端口号,因为在规划中,我们将 BigData03 规划为 SecondaryNameNode 服务器。
所以这里设置为:work3:50090
\10. 配置 slaves

slaves 文件是指定 HDFS 上有哪些 DataNode 节点。
\11. 配置 yarn-site.xml

根据规划yarn.resourcemanager.hostname这个指定 resourcemanager 服务器指向work2。
yarn.log-aggregation-enable是配置是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds是配置聚集的日志在 HDFS 上最多保存多长时间。
\12. 配置 mapred-site.xml
从 mapred-site.xml.template 复制一个 mapred-site.xml 文件。
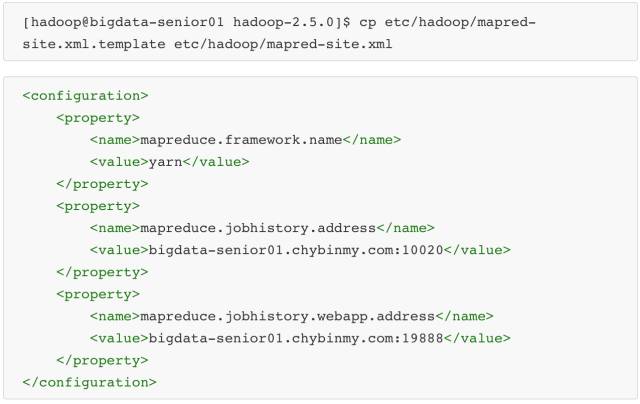
mapreduce.framework.name 设置 mapreduce 任务运行在 yarn 上。
mapreduce.jobhistory.address 是设置 mapreduce 的历史服务器安装在BigData01机器上。
mapreduce.jobhistory.webapp.address 是设置历史服务器的web页面地址和端口号。
二十八、设置 SSH 无密码登录
Hadoop 集群中的各个机器间会相互地通过 SSH 访问,每次访问都输入密码是不现实的,所以要配置各个机器间的
SSH 是无密码登录的。
\1. 在 BigData01 上生成公钥
![]()
一路回车,都设置为默认值,然后再当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa)。
\2. 分发公钥

\3. 设置 BigData02、BigData03 到其他机器的无密钥登录
同样的在 BigData02、BigData03 上生成公钥和私钥后,将公钥分发到三台机器上。
二十九、分发 Hadoop 文件
- 首先在其他两台机器上创建存放 Hadoop 的目录

\2. 通过 Scp 分发
Hadoop 根目录下的 share/doc 目录是存放的 hadoop 的文档,文件相当大,建议在分发之前将这个目录删除掉,可以节省硬盘空间并能提高分发的速度。
doc目录大小有1.6G。

三十、格式 NameNode
在 NameNode 机器上执行格式化:

注意:
如果需要重新格式化 NameNode,需要先将原来 NameNode 和 DataNode 下的文件全部删除,不然会报错,NameNode 和 DataNode 所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
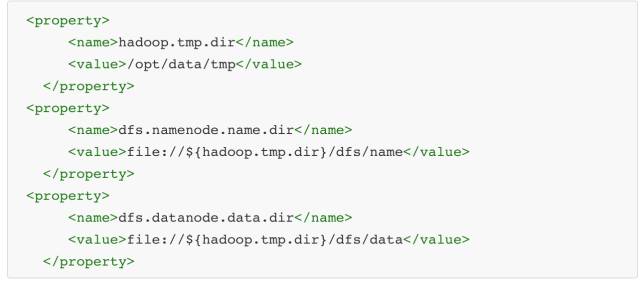
因为每次格式化,默认是创建一个集群ID,并写入 NameNode 和 DataNode 的 VERSION 文件中(VERSION 文件所在目录为 dfs/name/current 和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致 namenode 中的 VERSION 文件中是新的集群 ID,而 DataNode 中是旧的集群 ID,不一致时会报错。
另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
三十一、启动集群
- 启动 HDFS
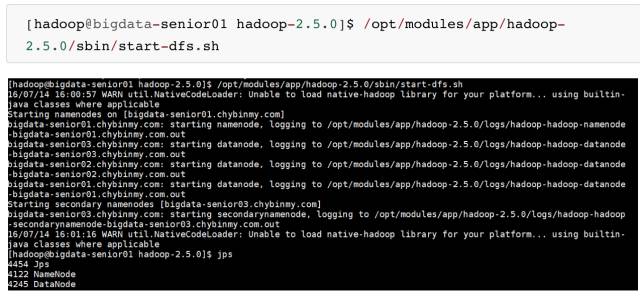
\2. 启动 YARN

在 BigData02 上启动 ResourceManager:
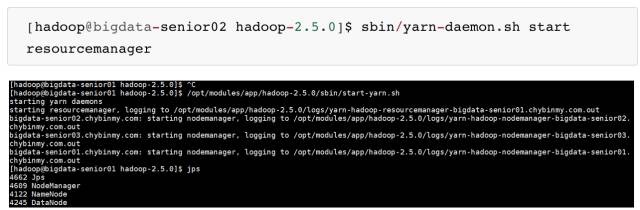
\3. 启动日志服务器
因为我们规划的是在 BigData03 服务器上运行 MapReduce 日志服务,所以要在 BigData03 上启动。
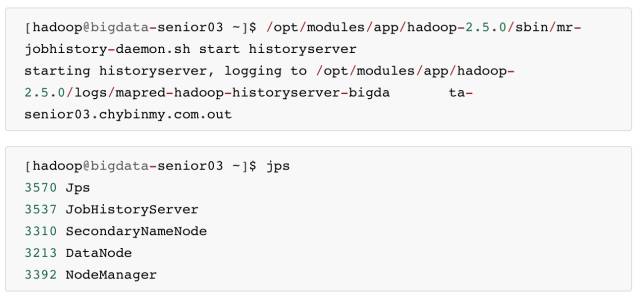
\4. 查看 HDFS Web 页面
http://work1:50070/
\5. 查看 YARN Web 页面
http://work2:8088/cluster
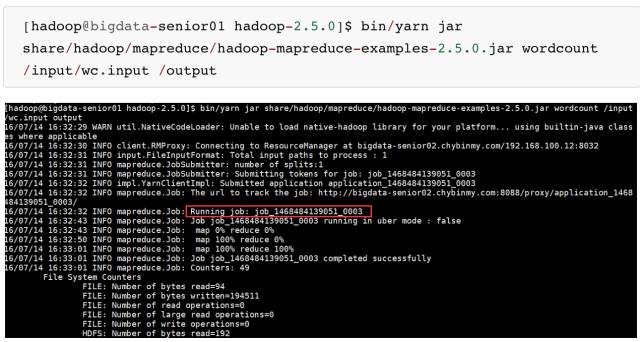
三十二、测试 Job
我们这里用 hadoop 自带的 wordcount 例子来在本地模式下测试跑mapreduce。
- 准备 mapreduce 输入文件 wc.input

\2. 在 HDFS 创建输入目录 input
![]()
\3. 将 wc.inpu t上传到 HDFS

\4. 运行 hadoop 自带的 mapreduce Demo
\5. 查看输出文件
第五部分:Hadoop HA 安装
HA 的意思是 High Availability 高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
HA 方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA 是 Hadoop 2.x 中新添加的特性,包括 NameNode HA 和 ResourceManager HA。
因为 DataNode 和 NodeManager 本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
第九步 时间服务器搭建
Hadoop 对集群中各个机器的时间同步要求比较高,要求各个机器的系统时间不能相差太多,不然会造成很多问题。
可以配置集群中各个机器和互联网的时间服务器进行时间同步,但是在实际生产环境中,集群中大部分服务器是不能连接外网的,这时候可以在内网搭建一个自己的时间服务器(NTP服务器),集群的各个机器与这个时间服务器进行时间同步。
三十三、配置NTP服务器
我们选择第三台机器(work3)为NTF服务器,其他机器和这台机器进行同步。
- 检查 ntp 服务是否已经安装

显示已经安装过了ntp程序,其中ntpdate-4.2.6p5-1.el6.centos.x86_64 是用来和某台服务器进行同步的,ntp-4.2.6p5-1.el6.centos.x86_64是用来提供时间同步服务的。
\2. 修改配置文件 ntp.conf
![]()
启用 restrice,修改网段
restrict 192.168.100.0 mask 255.255.255.0 nomodify notrap
将这行的注释去掉,并且将网段改为集群的网段,我们这里是100网段。
注释掉 server 域名配置

是时间服务器的域名,这里不需要连接互联网,所以将他们注释掉。
修改
server 127.127.1.0
fudge 127.127.1.0 stratum 10
\3. 修改配置文件 ntpd
![]()
添加一行配置:SYNC_CLOCK=yes

\4. 启动 ntp 服务
![]()
这样每次机器启动时,ntp 服务都会自动启动。
三十四、配置其他机器的同步
切换到 root 用户进行配置通过 contab 进行定时同步:

三十五、 测试同步是否有效
- 查看目前三台机器的时间
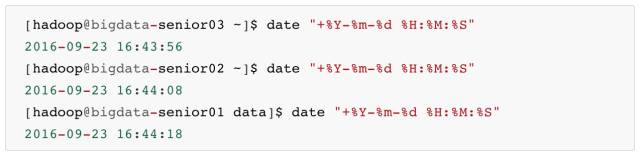
\2. 修改 bigdata-senior01上的时间
将时间改为一个以前的时间:

等10分钟,看是否可以实现自动同步,将 bigdata-senior01 上的时间修改为和 bigdata-senior03 上的一致。
\3. 查看是否自动同步时间

可以看到 bigdata-senior01 上的时间已经实现自动同步了。
第十步 Zookeeper 分布式机器部署
三十六、zookeeper 说明
Zookeeper 在Hadoop 集群中的作用。
Zookeeper是分布式管理协作框架,Zookeeper集群用来保证Hadoop集群的高可用,(高可用的含义是:集群中就算有一部分服务器宕机,也能保证正常地对外提供服务。)
Zookeeper 保证高可用的原理。
Zookeeper 集群能够保证 NamaNode 服务高可用的原理是:Hadoop 集群中有两个 NameNode 服务,两个NaameNode都定时地给 Zookeeper 发送心跳,告诉 Zookeeper 我还活着,可以提供服务,单某一个时间只有一个是 Action 状态,另外一个是 Standby 状态,一旦 Zookeeper 检测不到 Action NameNode 发送来的心跳后,就切换到 Standby 状态的 NameNode 上,将它设置为 Action 状态,所以集群中总有一个可用的 NameNode,达到了 NameNode 的高可用目的。
Zookeeper 的选举机制。
Zookeeper 集群也能保证自身的高可用,保证自身高可用的原理是,Zookeeper 集群中的各个机器分为 Leader 和 Follower 两个角色,写入数据时,要先写入Leader,Leader 同意写入后,再通知 Follower 写入。客户端读取数时,因为数据都是一样的,可以从任意一台机器上读取数据。
这里 Leader 角色就存在单点故障的隐患,高可用就是解决单点故障隐患的。
Zookeeper 从机制上解决了 Leader 的单点故障问题,Leader 是哪一台机器是不固定的,Leader 是选举出来的。
选举流程是,集群中任何一台机器发现集群中没有 Leader 时,就推荐自己为 Leader,其他机器来同意,当超过一半数的机器同意它为 Leader 时,选举结束,所以 Zookeeper 集群中的机器数据必须是奇数。
这样就算当 Leader 机器宕机后,会很快选举出新的 Leader,保证了 Zookeeper 集群本身的高可用。
写入高可用。
集群中的写入操作都是先通知 Leader,Leader 再通知 Follower 写入,实际上当超过一半的机器写入成功后,就认为写入成功了,所以就算有些机器宕机,写入也是成功的。
读取高可用。
zookeeperk 客户端读取数据时,可以读取集群中的任何一个机器。所以部分机器的宕机并不影响读取。
zookeeper 服务器必须是奇数台,因为 zookeeper 有选举制度,角色有:领导者、跟随者、观察者,选举的目的是保证集群中数据的一致性。
三十七、安装 zookeeper
我们这里在 BigData01、BigData02、BigData03 三台机器上安装 zookeeper 集群。
\1. 解压安装包
在 BigData01上安装解压 zookeeper 安装包。

\2. 修改配置
拷贝 conf 下的 zoo_sample.cfg 副本,改名为 zoo.cfg。zoo.cfg 是 zookeeper 的配置文件:

dataDir 属性设置 zookeeper 的数据文件存放的目录:
dataDir=/opt/modules/zookeeper-3.4.8/data/zData
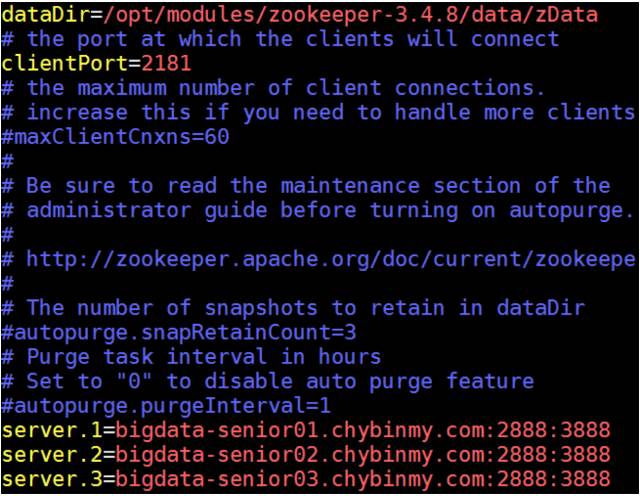
指定 zookeeper 集群中各个机器的信息:

server 后面的数字范围是1到255,所以一个 zookeeper 集群最多可以有255个机器。
\3. 创建 myid 文件
在 dataDir 所指定的目录下创一个名为 myid 的文件,文件内容为 server 点后面的数字。

\4. 分发到其他机器

\5. 修改其他机器上的myid文件

\6. 启动 zookeeper
需要在各个机器上分别启动 zookeeper。

三十八、zookeeper 命令
进入zookeeper Shell
在zookeeper根目录下执行 bin/zkCli.sh进入zk shell模式。
zookeeper很像一个小型的文件系统,/是根目录,下面的所有节点都叫zNode。
进入 zk shell 后输入任意字符,可以列出所有的 zookeeper 命令
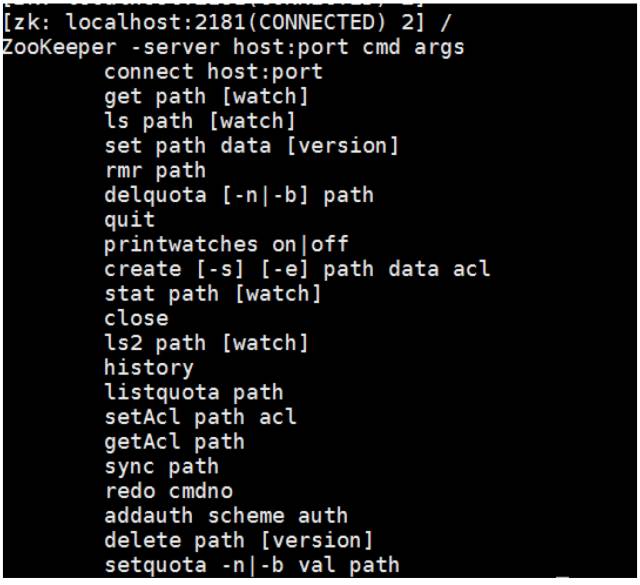
查询 zNode 上的数据:get /zookeeper
创建一个 zNode : create /znode1 “demodata “
列出所有子 zNode:ls /

删除 znode : rmr /znode1
退出 shell 模式:quit
第十一步 Hadoop 2.x HDFS HA 部署
三十九、HDFS HA原理
单 NameNode 的缺陷存在单点故障的问题,如果 NameNode 不可用,则会导致整个 HDFS 文件系统不可用。
所以需要设计高可用的 HDFS(Hadoop HA)来解决 NameNode 单点故障的问题。解决的方法是在 HDFS 集群中设置多个 NameNode 节点。
但是一旦引入多个 NameNode,就有一些问题需要解决。
- HDFS HA 需要保证的四个问题:
-
- 保证 NameNode 内存中元数据数据一致,并保证编辑日志文件的安全性。
- 多个 NameNode 如何协作
- 客户端如何能正确地访问到可用的那个 NameNode。
- 怎么保证任意时刻只能有一个 NameNode 处于对外服务状态。
- 解决方法
-
- 对于保证 NameNode 元数据的一致性和编辑日志的安全性,采用 Zookeeper 来存储编辑日志文件。
- 两个 NameNode 一个是 Active 状态的,一个是 Standby 状态的,一个时间点只能有一个 Active 状态的
NameNode 提供服务,两个 NameNode 上存储的元数据是实时同步的,当 Active 的 NameNode 出现问题时,通过 Zookeeper 实时切换到 Standby 的 NameNode 上,并将 Standby 改为 Active 状态。 - 客户端通过连接一个 Zookeeper 的代理来确定当时哪个 NameNode 处于服务状态。
四十、HDFS HA 架构图
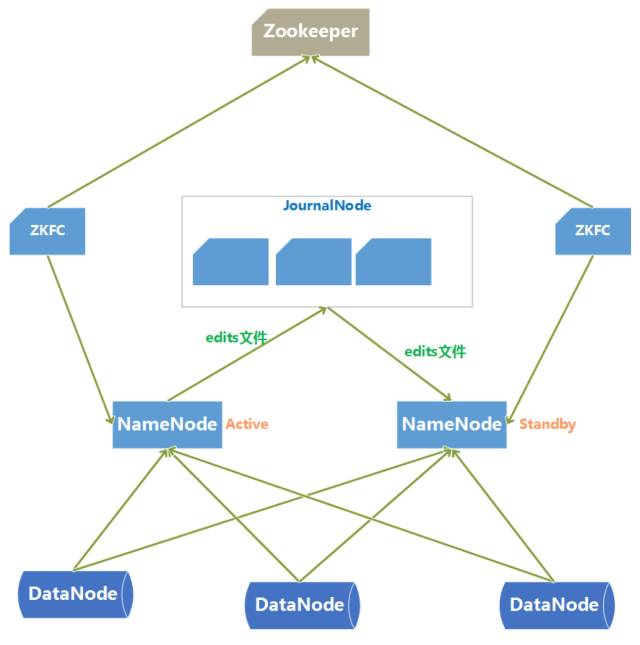
-
HDFS HA 架构中有两台 NameNode 节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
-
元数据文件有两个文件:fsimage 和 edits,备份元数据就是备份这两个文件。JournalNode 用来实时从 Active NameNode 上拷贝 edits 文件,JournalNode 有三台也是为了实现高可用。
-
Standby NameNode 不对外提供元数据的访问,它从 Active NameNode 上拷贝 fsimage 文件,从 JournalNode 上拷贝 edits 文件,然后负责合并 fsimage 和 edits 文件,相当于 SecondaryNameNode 的作用。
最终目的是保证 Standby NameNode 上的元数据信息和 Active NameNode 上的元数据信息一致,以实现热备份。
-
Zookeeper 来保证在 Active NameNode 失效时及时将 Standby NameNode 修改为 Active 状态。
-
ZKFC(失效检测控制)是 Hadoop 里的一个 Zookeeper 客户端,在每一个 NameNode 节点上都启动一个 ZKFC 进程,来监控 NameNode 的状态,并把 NameNode 的状态信息汇报给 Zookeeper 集群,其实就是在 Zookeeper 上创建了一个 Znode 节点,节点里保存了 NameNode 状态信息。
当 NameNode 失效后,ZKFC 检测到报告给 Zookeeper,Zookeeper把对应的 Znode 删除掉,Standby ZKFC 发现没有 Active 状态的 NameNode 时,就会用 shell 命令将自己监控的 NameNode 改为 Active 状态,并修改 Znode 上的数据。
Znode 是个临时的节点,临时节点特征是客户端的连接断了后就会把 znode 删除,所以当 ZKFC 失效时,也会导致切换 NameNode。 -
DataNode 会将心跳信息和 Block 汇报信息同时发给两台 NameNode, DataNode 只接受 Active NameNode 发来的文件读写操作指令。
四十一、搭建HDFS HA 环境
\1. 服务器角色规划
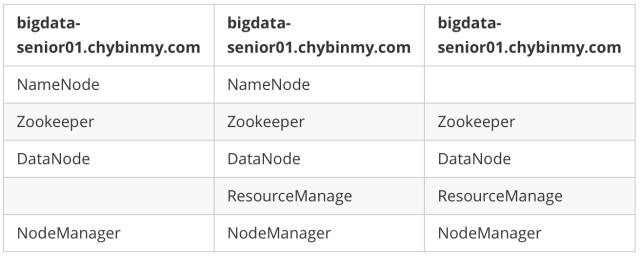
在 bigdata01、bigdata02、bigdata03 三台机器上分别创建目录 /opt/modules/hadoopha/ 用来存放 Hadoop HA 环境。
\2. 创建 HDFS HA 版本 Hadoop 程序目录
![]()
\3. 新解压 Hadoop 2.5.0

\4. 配置 Hadoop JDK 路径

\5. 配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>ns1value>
property>
<property>
<name>dfs.ha.namenodes.ns1name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1name>
<value>work1:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2name>
<value>work2:8020value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn1name>
<value>work1:50070value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn2name>
<value>work2:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://work1:8485;work2:8485;work3:8485/ns1value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/modules/hadoopha/hadoop-2.5.0/tmp/data/dfs/jnvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.ns1name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
configuration>
\6. 配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://ns1value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/modules/hadoopha/hadoop-2.5.0/data/tmpvalue>
property>
configuration>
hadoop.tmp.dir设置 hadoop 临时目录地址,默认时,NameNode 和 DataNode 的数据存在这个路径下。
\7. 配置 slaves 文件

\8. 分发到其他节点
分发之前先将 share/doc 目录删除,这个目录中是帮助文件,并且很大,可以删除。

\9. 启动HDFS HA集群
三台机器分别启动Journalnode。

jps 命令查看是否启动。
\10. 启动Zookeeper
在三台节点上启动Zookeeper:

\11. 格式化 NameNode
在第一台上进行 NameNode 格式化:
![]()
在第二台 NameNode 上:

\12. 启动 NameNode
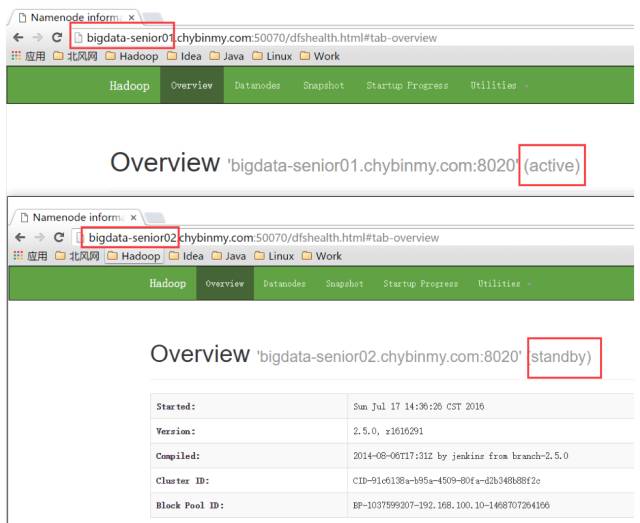
在第一台、第二台上启动 NameNode:

查看 HDFS Web 页面,此时两个 NameNode 都是 standby 状态。
切换第一台为 active 状态:

可以添加上 forcemanual 参数,强制将一个 NameNode 转换为 active 状态。

此时从 web 页面就看到第一台已经是 active 状态了。
\13. 配置故障自动转移
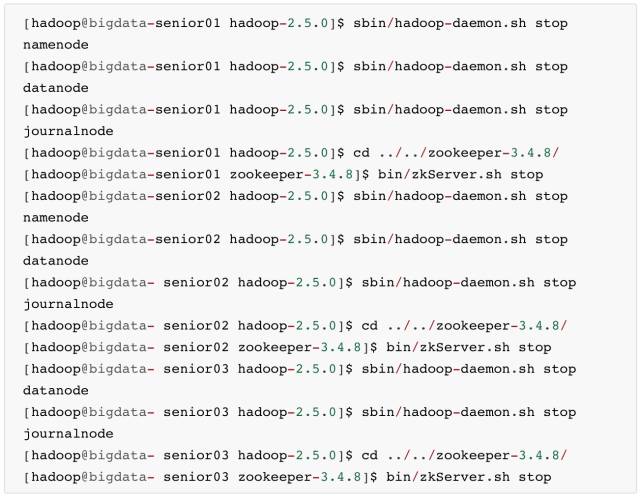
利用 zookeeper 集群实现故障自动转移,在配置故障自动转移之前,要先关闭集群,不能在 HDFS运行期间进行配置。
关闭 NameNode、DataNode、JournalNode、zookeeper
修改 hdfs-site.xml

修改 core-site.xml
将 hdfs-site.xml 和 core-site.xml 分发到其他机器
启动 zookeeper
三台机器启动 zookeeper

创建一个 zNode


在 Zookeeper 上创建一个存储 namenode 相关的节点。
\14. 启动 HDFS、JournalNode、zkfc
启动 NameNode、DataNode、JournalNode、zkfc
![]()
zkfc只针对 NameNode 监听。
四十二、测试 HDFS HA
\1. 测试故障自动转移和数据是否共享
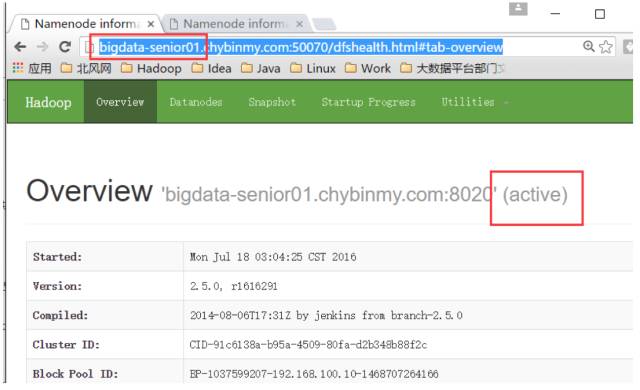
在 nn1 上上传文件
目前 bigdata-senior01节点上的 NameNode 是 Active 状态的。
![]()
将 nn1 上的 NodeNode 进程杀掉
[hadoop@bigdata-senior01 hadoop-2.5.0]$ kill -9 3364
nn1 上的 namenode 已经无法访问了。
查看 nn2 是否是 Active 状态
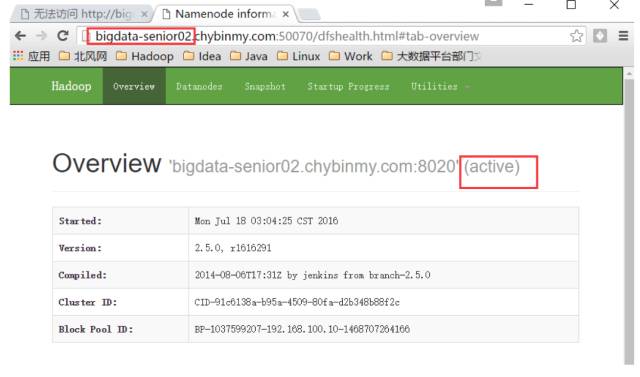
在nn2上查看是否看见文件
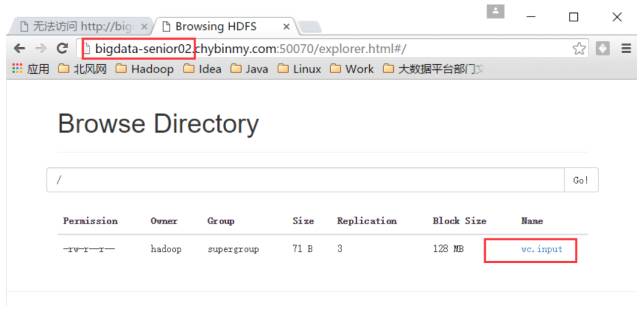
经以上验证,已经实现了 nn1 和 nn2 之间的文件同步和故障自动转移。
第十二步 Hadoop 2.x YARN HA 部署
四十三、YARN HA原理
Hadoop2.4 版本之前,ResourceManager 也存在单点故障的问题,也需要实现HA来保证 ResourceManger 的高可也用性。
ResouceManager 从记录着当前集群的资源分配情况和 JOB 的运行状态,YRAN HA 利用 Zookeeper 等共享存储介质来存储这些信息来达到高可用。另外利用 Zookeeper 来实现 ResourceManager 自动故障转移。
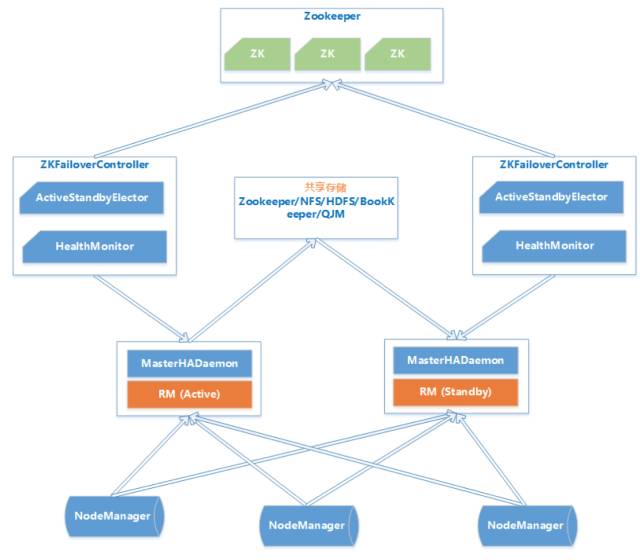
- MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
- 共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
- ZKFailoverController:基于 Zookeeper 实现的切换控制器,由 ActiveStandbyElector 和 HealthMonitor 组成,ActiveStandbyElector 负责与 Zookeeper 交互,判断所管理的 Master 是进入 Active 还是 Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
- Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个 Active的ResourceManager。
四十四、搭建 YARN HA 环境
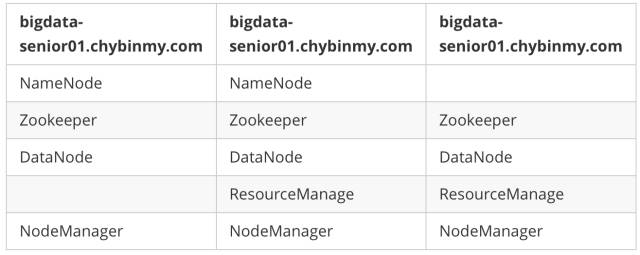
\1. 服务器角色规划
\2. 修改配置文件yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>106800value>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yarn-clustervalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm12,rm13value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm12name>
<value>bigdata-senior02.chybinmy.comvalue>
property>
<property>
<name>yarn.resourcemanager.hostname.rm13name>
<value>bigdata-senior03.chybinmy.comvalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>bigdata-senior01.chybinmy.com:2181,bigdata-senior02.chybinmy.com:2181,bigdata-senior03.chybinmy.com:2181value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
configuration>
\3. 分发到其他机器

\4. 启动
在 bigdata-senior01 上启动 yarn:
![]()
在 bigdata-senior02、bigdata-senior03 上启动 resourcemanager:

启动后各个节点的进程。
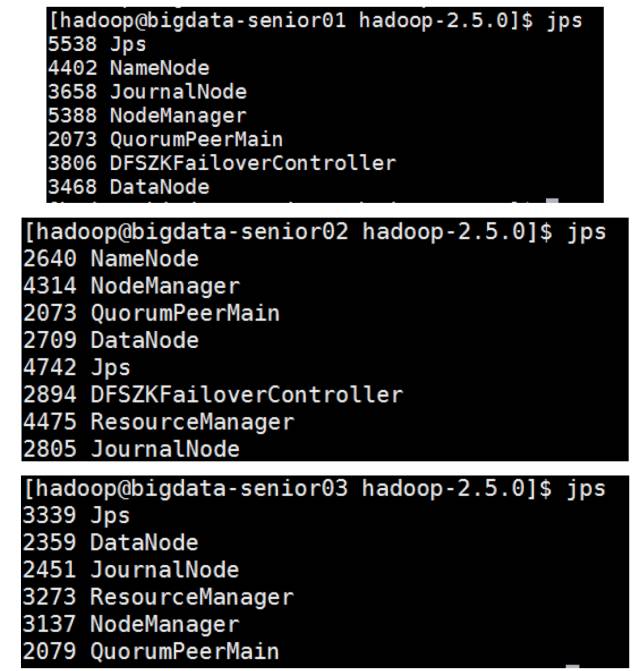
Web 客户端访问 bigdata02 机器上的 resourcemanager 正常,它是 active 状态的。
http://work2:8088/cluster
访问另外一个 resourcemanager,因为他是 standby,会自动跳转到 active 的resourcemanager。
http://work3:8088/cluster
四十五、测试 YARN HA
\5. 运行一个mapreduce job

\6. 在 job 运行过程中,将 Active 状态的 resourcemanager 进程杀掉。
![]()
\7. 观察另外一个 resourcemanager 是否可以自动接替。
bigdata02 的 resourcemanage Web 客户端已经不能访问,bigdata03 的 resourcemanage 已经自动变为active状态。
\8. 观察 job 是否可以顺利完成。
而 mapreduce job 也能顺利完成,没有因为 resourcemanager 的意外故障而影响运行。
经过以上测试,已经验证 YARN HA 已经搭建成功。
第十三步 HDFS Federation 架构部署
四十六、HDFS Federation 的使用原因
\1. 单个 NameNode 节点的局限性
命名空间的限制。
NameNode 上存储着整个 HDFS 上的文件的元数据,NameNode 是部署在一台机器上的,因为单个机器硬件的限制,必然会限制 NameNode 所能管理的文件个数,制约了数据量的增长。
数据隔离问题。
整个 HDFS 上的文件都由一个 NameNode 管理,所以一个程序很有可能会影响到整个 HDFS 上的程序,并且权限控制比较复杂。
性能瓶颈。
单个NameNode 时 HDFS文件系统的吞吐量受限于单个 NameNode 的吞吐量。因为 NameNode 是个 JVM 进程,JVM 进程所占用的内存很大时,性能会下降很多。
\2. HDFS Federation介绍
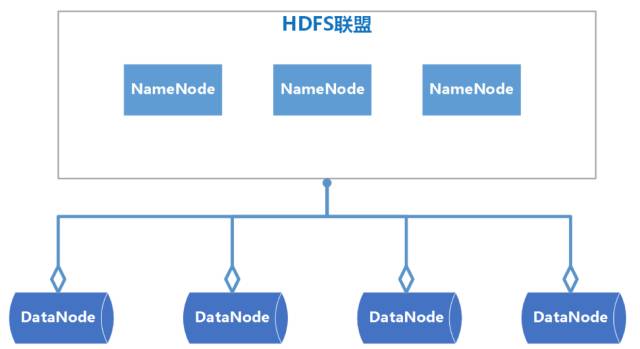
HDFS Federation 是可以在 Hadoop 集群中设置多个 NameNode,不同于 HA 中多个 NameNode 是完全一样的,是多个备份,Federation 中的多个 NameNode 是不同的,可以理解为将一个 NameNode 切分为了多个 NameNode,每一个 NameNode 只负责管理一部分数据。
HDFS Federation 中的多个 NameNode 共用 DataNode。
四十七、HDFS Federation 的架构图
四十八、HDFS Federation搭建
\1. 服务器角色规划
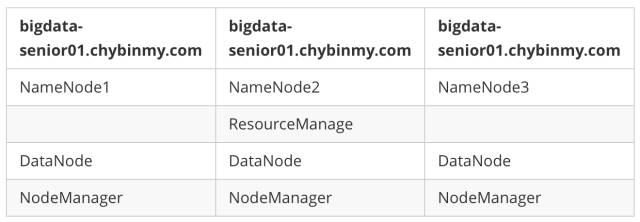
\2. 创建HDFS Federation 版本Hadoop程序目录
在bigdata01上创建目录/opt/modules/hadoopfederation /用来存放Hadoop Federation环境。
![]()
\3. 新解压 Hadoop 2.5.0

\4. 配置 Hadoop JDK 路径
修改 hadoop-env.sh、mapred-env.sh、yarn-env.sh 文件中的 JDK 路径。
export JAVA_HOME=”/opt/modules/jdk1.7.0_67”
\5. 配置hdfs-site.xml
<configuration><property><!—配置三台NameNode --> <name>dfs.nameservicesname> <value>ns1,ns2,ns3value> property> <property><!—第一台NameNode的机器名和rpc端口,指定了NameNode和DataNode通讯用的端口号 --> <name>dfs.namenode.rpc-address.ns1name> <value>bigdata-senior01.chybinmy.com:8020value> property> <property><!—第一台NameNode的机器名和rpc端口,备用端口号 --> <name>dfs.namenode.serviceerpc-address.ns1name> <value>bigdata-senior01.chybinmy.com:8022value> property> <property><!—第一台NameNode的http页面地址和端口号 --> <name>dfs.namenode.http-address.ns1name> <value>bigdata-senior01.chybinmy.com:50070value> property><property><!—第一台NameNode的https页面地址和端口号 --> <name>dfs.namenode.https-address.ns1name> <value>bigdata-senior01.chybinmy.com:50470value> property> <property> <name>dfs.namenode.rpc-address.ns2name> <value>bigdata-senior02.chybinmy.com:8020value> property> <property> <name>dfs.namenode.serviceerpc-address.ns2name> <value>bigdata-senior02.chybinmy.com:8022value> property> <property> <name>dfs.namenode.http-address.ns2name> <value>bigdata-senior02.chybinmy.com:50070value> property> <property> <name>dfs.namenode.https-address.ns2name> <value>bigdata-senior02.chybinmy.com:50470value> property> <property> <name>dfs.namenode.rpc-address.ns3name> <value>bigdata-senior03.chybinmy.com:8020value> property> <property> <name>dfs.namenode.serviceerpc-address.ns3name> <value>bigdata-senior03.chybinmy.com:8022value> property> <property> <name>dfs.namenode.http-address.ns3name> <value>bigdata-senior03.chybinmy.com:50070value> property> <property> <name>dfs.namenode.https-address.ns3name> <value>bigdata-senior03.chybinmy.com:50470value> property>configuration>
\6. 配置 core-site.xml
<configuration><property> <name>hadoop.tmp.dirname> <value>/opt/modules/hadoopha/hadoop-2.5.0/data/tmpvalue>property>configuration>
hadoop.tmp.dir 设置 hadoop 临时目录地址,默认时,NameNode 和 DataNode 的数据存在这个路径下。
\7. 配置 slaves 文件

\8. 配置 yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname work2 yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 106800 \9. 分发到其他节点
分发之前先将 share/doc 目录删除,这个目录中是帮助文件,并且很大,可以删除。

\10. 格式化 NameNode
在第一台上进行 NameNode 格式化。

这里一定要指定一个集群 ID,使得多个 NameNode 的集群 ID 是一样的,因为这三个 NameNode 在同一个集群中,这里集群 ID 为 hadoop-federation-clusterId。
在第二台 NameNode 上。

在第三台 NameNode 上。

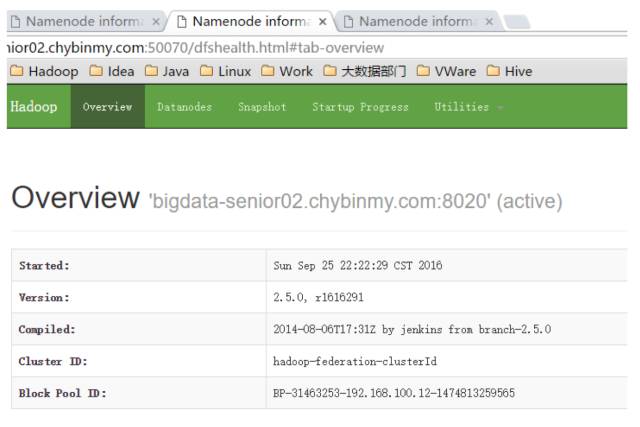
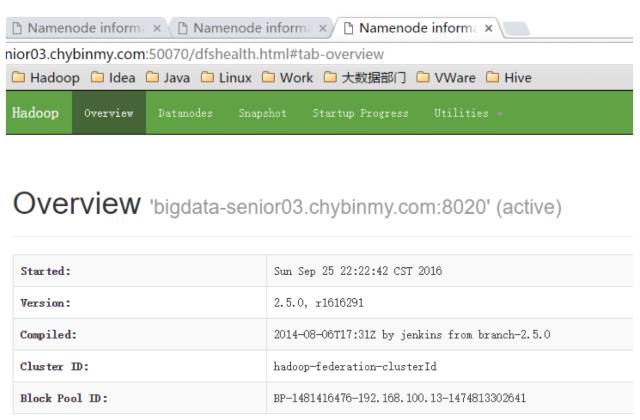
\11. 启动 NameNode
在第一台、第二台、第三台机器上启动 NameNode:

启动后,用 jps 命令查看是否已经启动成功。
查看 HDFS Web 页面,此时三个 NameNode 都是 standby 状态。
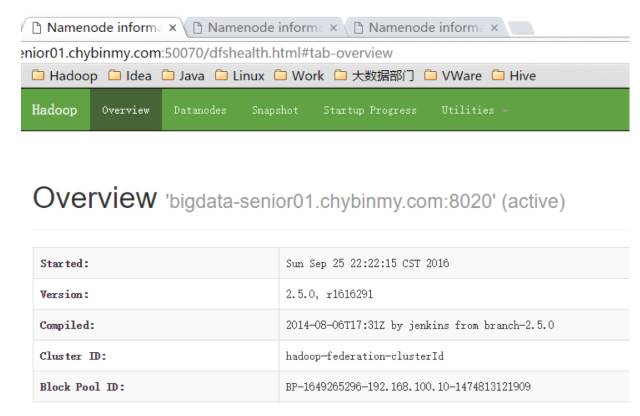
\12. 启动 DataNode
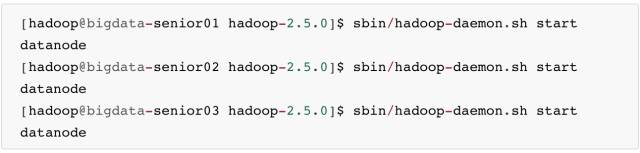
启动后,用 jps 命令确认 DataNode 进程已经启动成功。
四十九、测试HDFS Federation
\1. 修改 core-site.xml
在bigdata-senior01机器上,修改core-site.xml文件,指定连接的NameNode是第一台NameNode。
[hadoop@bigdata-senior01 hadoop-2.5.0]$ vim etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://work1:8020value> property><property> <name>hadoop.tmp.dirname> <value>/opt/modules/hadoopfederation/hadoop-2.5.0/data/tmpvalue>property>configuration>
\2. 在 bigdate-senior01 上传一个文件到 HDFS

\3. 查看 HDFS 文件
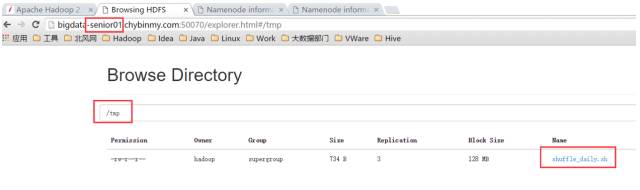
可以看到,刚才的文件只上传到了 bigdate-senior01 机器上的 NameNode 上了,并没有上传到其他的 NameNode 上去。
这样,在 HDFS 的客户端,可以指定要上传到哪个 NameNode 上,从而来达到了划分 NameNode 的目的。
后记
这篇文章的操作步骤并不是工作中标准的操作流程,如果在成百上千的机器全部这样安装会被累死,希望读者可以通过文章中一步步地安装,从而初步了解到 Hadoop 的组成部分,协助过程等,这对于 Hadoop 的深入使用有很大的帮助。
文章转载自:GitChat技术杂谈