推荐算法知识梳理
文章目录
- 架构介绍
- 推荐系统架构介绍
- 召回
- 简单介绍
- 非个性化召回
- 多路召回
- 模型召回
- 双塔模型
- 因子分解
- 发散点
- 用户行为序列召回
- 改进
- 用户多兴趣拆分
- 知识图谱融合召回
- 图神经网络模型召回
- 排序
- 技术发展趋势
- 模型表达能力
- 显示特征组合
- 特征抽取器的进化
- AutoML在推荐的应用
- 增强学习在推荐的应用
- 模型优化目标
- 多目标优化
- 特征扩充及信息融合
- 多模态信息融合
- 长期兴趣/短期兴趣分离
- 重排技术演进趋势
- List Wise重排序
- 参考文献
这里参考张俊林老师的文章 添加链接描述
架构介绍
推荐系统架构介绍

- 召回:缩小可选集
- 粗排:有时候因为每个用户召回环节返回的物品数量还是太多,怕排序环节速度跟不上,所以可以在召回和精排之间加入一个粗排环节,通过少量用户和物品特征,简单模型,来对召回的结果进行粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。
- 精排:使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。
- 重排:传统地看,这里往往会上各种技术及业务策略,比如去已读、去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验的。
召回
简单介绍
技术含量不太高,模型用的少,偏向策略型导向,往往灵机一动,就能想到一个策略,增加一路新的召回。总体而言,召回环节的有监督模型化以及一切Embedding化,这是两个相辅相成的总体发展趋势。而embedding的具体方法,则可以有各种选择。
非个性化召回
- 热门商品
- 历史点击率高的物料
多路召回

可以把某路召回,看成是某个排序模型的排序结果,只不过,这个排序模型,在用户侧和物品侧只用了一个特征。比如说,标签召回,其实就是用用户兴趣标签和物品标签进行排序的单特征排序结果;再比如协同召回,可以看成是只包含UID和ItemID的两个特征的排序结果
模型召回

核心思想是:将用户特征和物品特征分离,各自通过某个具体的模型,分别打出用户Embedding以及物品Embedding。
理论上来说,任何你能见到的有监督模型,都可以用来做这个召回模型,比如FM/FFM/DNN等,常说的所谓“双塔”模型,指的其实是用户侧和物品侧特征分离分别打Embedding的结构而已,并非具体的模型。
双塔模型
DNN双塔召回:Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
因子分解
fm召回
发散点
- 优点:
多路召回每路截断条数的超参个性化问题等会自然被消解掉 - 缺点:
召回内容头部问题,因为之前多路,每路召回个数靠硬性截断,可以根据需要,保证你想要召回的,总能通过某一路拉回来;而由于换成了模型召回,面向海量物料库,排在前列得分高的可能聚集在几个物料分布比较多的头部领域(解决这个问题的方法包括比如训练数据对头部领域的降采样,减少某些领域主导,以及在模型角度鼓励多样性等不同的方法) - 如果在召回阶段使用模型召回,理论上也应该同步采用和排序模型相同的优化目标,尤其是如果排序阶段采用多目标优化的情况下,召回模型也应该对应采取相同的多目标优化
- 如果整个流程中包含粗排模块,粗排也应该采用和精排相同的多目标优化,几个环节优化目标应保持一致。因为召回和粗排是精排的前置环节,否则,如果优化目标不一致,很可能会出现高质量精排目标,在前置环节就被过滤掉的可能,影响整体效果
用户行为序列召回
一般用户之所以会对物品发生行为,往往意味着这些物品是符合用户兴趣的,而不同类型的行为,可能代表了不同程度的兴趣。比如购买就是比点击更能表征用户兴趣的行为。

抽象地来看的话,利用用户行为过的物品序列对用户兴趣建模,本质上就是这么个过程:输入是用户行为过的物品序列,可以只用物品ID表征,也可以融入物品的Side Information比如名称,描述,图片等,现在我们需要一个函数Fun,这个函数以这些物品为输入,需要通过一定的方法把这些进行糅合到一个embedding里,而这个糅合好的embedding,就代表了用户兴趣。无论是在召回过程,还是排序过程,都可以融入用户行为序列。在召回阶段,我们可以用用户兴趣Embedding采取向量召回,而在排序阶段,这个embedding则可以作为用户侧的特征。
核心在于:这个物品聚合函数Fun如何定义
用户行为序列中的物品,是有时间顺序的。理论上,任何能够体现时序特点或特征局部性关联的模型,都比较适合应用在这里,典型的比如CNN、RNN、Transformer等,都比较适合用来集成用户行为序列信息。而目前的很多试验结果证明,GRU(RNN的变体模型)可能是聚合用户行为序列效果最好又比较简单的模型。当然,RNN不能并行的低效率,那是另外一个问题。
排序侧表征用户特征的时候,可以只用用户行为过的物品序列,也可以混合用户其它特征,比如群体属性特征等一起来表征用户兴趣,方式比较灵活。比如DIEN,就是典型的采用混合模式的方法
改进
多用户兴趣拆分:用户往往是多兴趣的,比如可能同时对娱乐、体育、收藏感兴趣。这些不同的兴趣也能从用户行为序列的物品构成上看出来,比如行为序列中大部分是娱乐类,一部分体育类,少部分收藏类等。那么能否把用户行为序列物品中,这种不同类型的用户兴趣细分,而不是都笼统地打到一个用户兴趣Embedding里呢?用户多兴趣拆分就是解决这类更细致刻画用户兴趣的方向
用户多兴趣拆分

本质上,把用户行为序列打到多个embedding上,实际它是个类似聚类的过程,就是把不同的Item,聚类到不同的兴趣类别里去。目前常用的拆分用户兴趣embedding的方法,主要是胶囊网络和Memory Network,但是理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做
这种兴趣拆分,在召回阶段是很合适的,可以定向解决头部问题。
对于排序环节,是否有必要把用户兴趣拆分成多个,必要性不是太大。非要用的话,可以这么解释:当行为序列物品太多的时候,Atttention计算是非常耗时的操作,如果我们把这种Attention计算,放到聚类完的几个兴趣embedding维度计算,无疑能极大提升训练和预测的速度
典型工作:
- 召回:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
- 排序:Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction
知识图谱融合召回

用户-物品交互的二部图用得最多。而知识图谱这类数据是可以考虑用来增强推荐效果的,尤其是对于用户行为数据稀疏的场景,或者冷启动场景。
以上图例子说明,用户点击过电影“泰坦尼克号”,这是用户行为数据,我们知道,电影“泰坦尼克号”的主演是莱昂纳多,于是可以推荐其它由莱昂纳多主演的电影给这个用户。后面这几步操作,利用的是电影领域的知识图谱数据,通过知识图谱中的“电影1—>主演—>电影2”的图路径给出的推荐结果
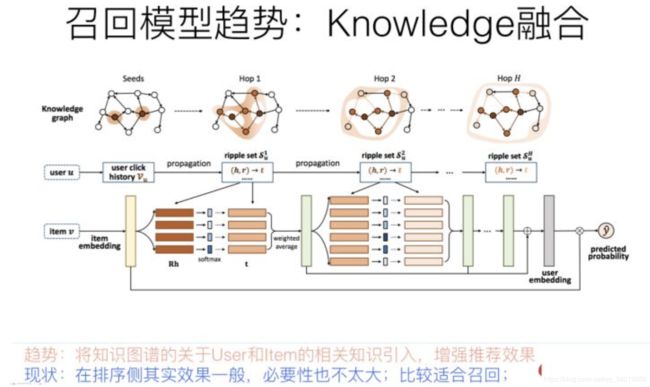
用于做推荐,一般有两大类知识图谱融合模式:知识图谱Embedding模式(KGE)及图路径模式。
- 知识图谱Embedding模式。首先根据TransE等对知识图谱进行Embedding化编码的工具,将节点和边转换成Embedding表征方式。然后根据用户行为过的物品,以及物品在知识图谱中的Embedding和知识图谱中其它知识embedding的距离,来扩展物品的信息含量,或者扩充用户行为数据,类似用已知的用户行为数据,在知识图谱辅助下进行外扩。知识图谱的Embedding模式在可解释性方面比较弱,因为知识之间的关联是通过Embedding计算出来的,不好解释为什么从这个知识跳到那个知识;
- 而图路径模式,则是根据物品属性之间的关联等人工定义好的所谓Meta-Path,也就是人工定义的知识图谱中知识的关联和传播模式,通过中间属性来对知识传播进行路径搭建,具体例子就是上面说的“电影1主演电影2”,这就是人事先定义好的Meta-Path,也就是人把自己的经验写成规则,来利用知识图谱里的数据。图路径模式在可解释性方面效果较好,因为是人工定义的传播路径,所以非常好理解知识传播关系,但是往往实际应用效果并不好
知识图谱是一种信息拓展的模式,对知识进行近距离的拓展,这可能会带来信息补充作用,但是如果拓展的比较远,或者拓展不当,反而可能会引入噪音。
所以,知识图谱在排序侧并不是特别好用,如果想用的话,比较适合用户行为数据非常稀疏以及用户冷启动的场景,也就是说如果用户数据太少,需要拓展,可以考虑使用它。
另外,知识图谱还有一个普适性的问题,完全通用的知识图谱在特定场景下是否好用,对此我是有疑问的,而专业性的知识图谱,还有一个如何构建以及构建成本问题;而且很多时候,所谓的知识传播,是可以通过添加属性特征来解决的,比如:电影1—>主演—>电影2这种知识传播路径,完全可以通过把主演作为电影这个实体的属性特征加入常规排序模型,来达到类似知识近距离传播的目的,所以感觉也不是很有必要在排序侧专门去做知识图谱拓展这种事情
至于如何利用知识图谱做召回,其实很直观,比如可以采取如下的无监督学习版本:例如,推荐系统里对用户感兴趣的实体比如某个或者某些明星,往往是个单独的召回路,而可以根据用户的兴趣实体,通过知识图谱的实体Embedding化表达后(或者直接在知识图谱节点上外扩),通过知识外扩或者可以根据Embedding相似性,拓展出相关实体。形成另外一路相关性弱,但是泛化能力强的Knowledge融合召回路。
典型工作:
- KGAT: Knowledge Graph Attention Network for Recommendation
- RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
图神经网络模型召回

因为图神经网络,最终获得的往往是图中节点的embedding,这个embedding,就像我们上面说的,其实融合了各种异质信息。所以它是特别适合用来做召回的,比如拿到图网络中用户的embedding和物品embedding,可以直接用来做向量召回。当然,物品和用户的embedding也可以作为特征,引入排序模型中,这都是比较自然的。有些推荐场景也可以直接根据embedding计算user to user/item to item的推荐结果,比如看了又看这种推荐场景
早期的图神经网络做推荐,因为需要全局信息,所以计算速度是个问题,往往图规模都非常小,不具备实战价值。而GraphSAGE则通过一些手段比如从临近节点进行采样等减少计算规模,加快计算速度,很多后期改进计算效率的方法都是从这个工作衍生的;而PinSage在GraphSAGE基础上(这是同一拨人做的),进一步采取大规模分布式计算,拓展了图计算的实用性,可以计算Pinterest的30亿规模节点、180亿规模边的巨型图,并产生了较好的落地效果。所以这两个工作可以重点借鉴一下
典型工作:
- GraphSAGE: Inductive Representation Learning on Large Graphs
- PinSage: Graph Convolutional Neural Networks for Web-Scale Recommender Systems
排序
技术发展趋势

模型表达能力代表了模型是否具备充分利用有效特征及特征组合的能力,其中显示特征组合、新型特征抽取器、增强学习技术应用以及AutoML自动探索模型结构是这方面明显的技术进化方向;模型优化目标则体现了我们希望推荐系统去做好什么,往往跟业务目标有关联,这里我们主要从技术角度来探讨,而多目标优化以及ListWise最优是目前最常见的技术进化方向,ListWise优化目标在排序阶段和重排阶段都可采用,我们把它放到重排部分去讲,这里主要介绍多目标优化;从特征和信息角度,如何采用更丰富的新类型特征,以及信息和特征的扩充及融合是主要技术进化方向,用户长短期兴趣分离、用户行为序列数据的使用、图神经网络以及多模态融合等是这方面的主要技术趋势。
模型表达能力
显示特征组合

纯粹的简单DNN模型本质上其实是在FM模型的特征Embedding化基础上,添加几层MLP隐层来进行隐式的特征非线性自动组合而已。所谓隐式,意思是并没有明确的网络结构对特征的二阶组合、三阶组合进行直接建模,只是通过MLP,让不同特征发生交互,至于怎么发生交互的,怎么进行特征组合的,谁也说不清楚,这是MLP结构隐式特征组合的作用,当然由于MLP的引入,也会在特征组合时候考虑进入了特征间的非线性关系。
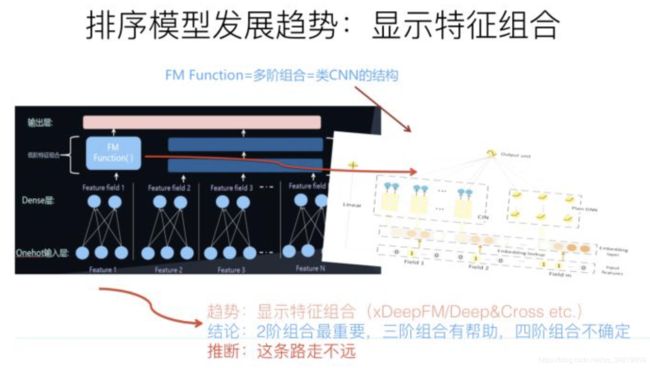
显式特征组合,就是在模型结构中,明确设计一些子网络或者子结构,对二阶特征组合、三阶特征组合,甚至更高阶的特征组合进行表征。比如说DeepFM,Deep部分就是个典型的DNN模型,这个大家基本都会用,而FM部分则是明确对特征二阶组合进行建模的子模型。这就是一个典型的显式二阶特征组合的模型。而如果进一步拓展的话,很自然想到的一个改进思路是:除了明确的把特征二阶组合做一个子结构,还可以把特征三阶特征组合,更高阶特征组合……分别做一个模型子结构。融合这些子结构一起来做预测。这就是显式特征组合的含义,其实这条线的发展脉络是异常清晰的。典型的对高阶特征组合建模的比如Deep& Cross、XDeepFM模型等,就是这么个思路。
- 局限性:在实际做事情的时候,其实显式结构把三阶特征组合引入,已经基本足够了
特征抽取器的进化
MLP结构用来捕获特征组合,是效率比较低下的,除非把隐层神经元个数急剧放大,而这又会急剧增加参数规模。与自然语言处理和图像处理比较,推荐领域的特征抽取器仍然处于非常初级的发展阶段
 目前其它AI领域里,常用的特征抽取器包括图像领域的CNN、NLP领域的RNN和Transformer。这些新型特征抽取器,在推荐领域最近两年也逐步开始尝试使用,但是宏观地看,在推荐领域,相对MLP结构并未取得明显优势,这里的原因比较复杂。CNN捕获局部特征关联是非常有效的结构,但是并不太适合做纯特征输入的推荐模型,因为推荐领域的特征之间,在输入顺序上并无必然的序列关系,基本属于人工定义随机顺序,而CNN处理这种远距离特征关系能力薄弱,所以并不是特别适合用来处理特征级的推荐模型。当然,对于行为序列数据,因为本身带有序列属性,所以CNN和RNN都是非常适合应用在行为序列结构上的,也是有一定应用历史的典型工具,但是对于没有序关系存在的特征来说,这两个模型的优势不能发挥出来,反而会放大各自的劣势,比如CNN的捕获远距离特征关系能力差的弱点,以及RNN的不可并行处理、所以速度慢的劣势等。
目前其它AI领域里,常用的特征抽取器包括图像领域的CNN、NLP领域的RNN和Transformer。这些新型特征抽取器,在推荐领域最近两年也逐步开始尝试使用,但是宏观地看,在推荐领域,相对MLP结构并未取得明显优势,这里的原因比较复杂。CNN捕获局部特征关联是非常有效的结构,但是并不太适合做纯特征输入的推荐模型,因为推荐领域的特征之间,在输入顺序上并无必然的序列关系,基本属于人工定义随机顺序,而CNN处理这种远距离特征关系能力薄弱,所以并不是特别适合用来处理特征级的推荐模型。当然,对于行为序列数据,因为本身带有序列属性,所以CNN和RNN都是非常适合应用在行为序列结构上的,也是有一定应用历史的典型工具,但是对于没有序关系存在的特征来说,这两个模型的优势不能发挥出来,反而会放大各自的劣势,比如CNN的捕获远距离特征关系能力差的弱点,以及RNN的不可并行处理、所以速度慢的劣势等。
Transformer作为NLP领域最新型也是最有效的特征抽取器,从其工作机制来说,其实是非常适合用来做推荐的。为什么这么说呢?核心在于Transformer的Multi-Head Self Attention机制上。MHA结构在NLP里面,会对输入句子中任意两个单词的相关程度作出判断,而如果把这种关系套用到推荐领域,就是通过MHA来对任意特征进行特征组合,而上文说过,特征组合对于推荐是个很重要的环节,所以从这个角度来说,Transformer是特别适合来对特征组合进行建模的,一层Transformer Block代表了特征的二阶组合,更多的Transformer Block代表了更高阶的特征组合。但是,实际上如果应用Transformer来做推荐,其应用效果并没有体现出明显优势,甚至没有体现出什么优势,基本稍微好于或者类似于典型的MLP结构的效果。这意味着,可能我们需要针对推荐领域特点,对Transformer需要进行针对性的改造,而不是完全直接照搬NLP里的结构
AutoML在推荐的应用
在cv,nlp领域,目前都能通过AutoML找到比人设计的效果更好的模型结构。AutoML通过各种基础算子的任意组合,在超大的算子组合空间内,寻找性能表现最好的模型,几乎可以达到穷举遍历的效果,如果设计精良的AutoML,一定可以自己找到超过目前人类专家设计的最好的那个模型,现在AutoML的不成熟,体现在需要搜索的空间太大,比较消耗计算资源方面而已,随着技术的不断成熟,搜索成本越来越低,AutoML在很多算法方向超过人类表现只是个时间问题。



我们用ENAS作为网络搜索工具,设计了推荐领域网络结构自动探索的尝试。ENAS是个非常高效率的AutoML工具,可以做到单GPU半天搜索找到最优的网络结构,但是它定义的主要是CNN结构和RNN结构搜索。我们对ENAS进行了改造,包括算子定义,优化目标以及评价指标定义等。DNN排序模型因为模型比较单一,所以算子是比较好找的,我们定义了推荐领域的常用算子,然后在这些算子组合空间内通过ENAS自动寻找效果最优的网络结构,最终找到的一个表现最好的网络结构如下图所示:

总体而言,目前AutoML来做推荐模型,还很不成熟,找出的结构相对人工设计结构效果优势也不是太明显。这与DNN Ranking模型比较简单,算子类型太少以及模型深度做不起来也有很大关系
典型工作:
- 双线性特征组合: FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
增强学习在推荐的应用
一般而言,增强学习有几个关键要素:状态、行为以及回报。在推荐场景下,我们可以把状态St定义为用户的行为历史物品集合;推荐系统可选的行为空间则是根据用户当前状态St推荐给用户的推荐结果列表,这里可以看出,推荐场景下,用户行为空间是巨大无比的,这制约了很多无法对巨大行为空间建模的增强学习方法的应用;而回报呢,则是用户对推荐系统给出的列表内容进行互动的行为价值,比如可以定义点击了某个物品,则回报是1,购买了某个物品,回报是5….诸如此类。有了这几个要素的场景定义,就可以用典型的增强学习来对推荐进行建模。
利用增强学习来做推荐系统,有几个显而易见的好处,比如:
- 比较容易对“利用-探索”(Exploitation/Exploration)建模。所谓利用,就是推荐给用户当前收益最大的物品,一般推荐模型都是优化这个目标;所谓探索,就是随机推给用户一些物品,以此来探测用户潜在感兴趣的东西。如果要进行探索,往往会牺牲推荐系统的当前总体收益,毕竟探索效率比较低,相当的通过探索渠道推给用户的物品,用户其实并不感兴趣,浪费了推荐位。但是,利用-探索的均衡,是比较容易通过调节增强学习的回报(Reward)来体现这个事情的,比较自然;
- 比较容易体现用户兴趣的动态变化。我们知道,用户兴趣有长期稳定的,也有不断变化的。而增强学习比较容易通过用户行为和反馈的物品对应的回报的重要性,而动态对推荐结果产生变化,所以是比较容易融入体现用户兴趣变化这个特点的。
- 有利于推荐系统长期收益建模。这点是增强学习做推荐最有优势的一个点。我们优化推荐系统,往往会有一些短期的目标比如增加点击率等,但是长期目标比如用户体验或者用户活跃留存等指标,一般不太好直接优化,而增强学习模型比较容易对长期收益目标来进行建模。
从实际落地角度来看,推荐系统里要尝试增强学习方法,如果你有这个冲动,最好还是抑制一下。主要原因是,貌似增强学习是技术落地投入产出比非常低的技术点。首先投入高,要想把增强学习做work,意味着有很多大坑在等着你去踩,数据怎么做、模型怎么写、回报怎么拍,长期收益怎么定义、建模并拆解成回报…….超大规模实际场景的用户和物品,增强学习这么复杂的模型,系统怎么才能真的落地并撑住流量……很多坑在里面;其次,貌似目前看到的文献看,貌似很少见到真的把增强学习大规模推到真实线上系统,并产生很好的收益的系统。Youtube在最近一年做了不少尝试,虽说把系统推上线了,但是收益怎样不好说。而且,从另外一个角度看,做增强学习里面还是有不少Trick在,那些收益到底是系统带来的,还是Trick带来的,真还不太好说。所以,综合而言,目前看在增强学习做推荐投入,貌似还是一笔不太合算的买卖。
模型优化目标
多目标优化
推荐系统的多目标优化(点击,互动,时长等多个目标同时优化)严格来说不仅仅是趋势,而是目前很多公司的研发现状。对于推荐系统来说,不同的优化目标可能存在互相拉后腿的现象,比如互动和时长,往往拉起一个指标另外一个就会明显往下掉,而多目标旨在平衡不同目标的相互影响,尽量能够做到所有指标同步上涨,即使很难做到,也尽量做到在某个优化目标上涨的情况下,不拉低或者将尽量少拉低其它指标。

从技术角度讲,多目标优化最关键的有两个问题。第一个问题是多个优化目标的模型结构问题;第二个问题是不同优化目标的重要性如何界定的问题。
既然存在多个优化目标,最简单直接的方式,也是目前最常用的方式是:每个优化目标独立优化,比如点击目标训练一个模型,互动目标训练一个模型,时长目标训练一个模型,各自优化,然后每个目标独立给实例预测打分,给每个目标设定权重值,各个目标打分加权求和线性融合,或者引入权重指数及根据目标关系引入非线性融合。这是目前最常见的落地方案。因为目标之间独立优化,模型是通过分数融合来实现多目标的,所以可以把这种多目标方式称作“Share-Nothing”结构。这个结构实现和优化方式很简单。
与Share-Nothing结构相比,其实我们是可以让不同优化目标共享一部分参数的,一旦引入不同目标或者任务的参数共享,我们就踏入了Transfer Learning的领地了。那么为什么要共享参数呢?一方面出于计算效率考虑,不同目标共享结构能够提升计算效率;另外一点,假设我们有两类任务或者目标,其中一个目标的训练数据很充分,而另外一个目标的训练数据比较少;如果独立优化,训练数据少的目标可能很难获得很好的效果;如果两个任务相关性比较高的话,其实我们可以通过共享参数,达到把大训练数据任务的知识迁移给训练数据比较少的任务的目的,这样可以极大提升训练数据量比较少的任务的效果。Share-Bottom结构是个非常典型的共享参数的多目标优化结构,核心思想是在比如网络的底层参数,所有任务共享参数,而上层网络,不同任务各自维护自己独有的一部分参数,这样就能达成通过共享参数实现知识迁移的目的。但是,Share-Bottom结构有他的缺点:如果两个任务不那么相关的话,因为强制共享参数,所以可能任务之间相互干扰,会拉低不同目标的效果。MMOE针对Share-Bottom结构的局限进行了改进,核心思想也很简单,就是把底层全部共享的参数切分成小的子网络,不同任务根据自己的特点,学习配置不同权重的小网络来进行参数共享。这样做的话,即使是两个任务不太相关,可以通过不同的配置来达到模型解耦的目的,而如果模型相关性强,可以共享更多的子网络。明显这样的组合方式更灵活,所以对于MMOE来说,无论是相关还是不相关的任务,它都可以达到我们想要的效果。
假设我们选定了模型结构,仍然存在一个很关键的问题:不同优化目标权重如何设定?当然,我们可以根据业务要求,强制制定一些权重,比如视频网站可能更重视时长或者完播率等指标,那就把这个目标权重设置大一些。但是,我们讲过,有些任务之间的指标优化是负相关的,提升某个目标的权重,有可能造成另外一些指标的下跌。所以,如何设定不同目标权重,能够尽量减少相互之间的负面影响,就非常重要。这块貌似目前并没有特别简单实用的方案,很多实际做法做起来还是根据经验拍一些权重参数上线AB测试,费时费力。而如何用模型自动寻找最优权重参数组合就是一个非常有价值的方向,目前最常用的方式是采用帕累托最优的方案来进行权重组合寻优,这是从经济学引入的技术方案,未来还有很大的发展空间。
特征扩充及信息融合
多模态信息融合
所谓模态,指的是不同类型的或者模态形式的信息存在形式,比如文本、图片、视频、音频、互动行为、社交关系等,都是信息不同的存在模态形式。
多模态融合,从技术手段来说,本质上是把不同模态类型的信息,通过比如Embedding编码,映射到统一的语义空间内,使得不同模态的信息,表达相同语义的信息完全可类比。比如说自然语言说的单词“苹果”,和一张苹果的图片,应该通过一定的技术手段,对两者进行信息编码,比如打出的embedding,相似度是很高的,这意味着不同模态的知识映射到了相同的语义空间了。这样,你可以通过文本的苹果,比如搜索包含苹果的照片。
如果在推荐里融入多模态,从算法层面看,并不难,它的难点其实在它处;本质上,多模态做推荐,如果说难点的话,难在工程效率。因为目前很多模态的信息抽取器,比如图片的特征抽取,用深层ResNet或者ReceptionNet,效果都很好,但是因为网络层深太深,抽取图片特征的速度问题就是多模态落地面临的主要问题。所以,本质上,在推荐领域应用多模态,看上去其实是个工程效率问题,而非复杂的算法问题。而且,如果融合多模态的话,离开DNN模型,基本是不现实的。在这点上,可以比较充分体现DNN模型相对传统模型的绝对技术优势。
长期兴趣/短期兴趣分离
对于推荐系统而言,准确描述用户兴趣是非常重要的。目前常用的描述用户兴趣的方式主要有两类。一类是以用户侧特征的角度来表征用户兴趣,也是最常见的;另外一类是以用户发生过行为的物品序列作为用户兴趣的表征。

用户短期兴趣:往往使用用户点击(或购买,互动等其它行为类型)过的物品序列来表征,尤其对于比较活跃的用户,用点击序列更能体现短期的含义,因为出于工程效率的考虑,如果用户行为序列太长,往往不会都拿来使用,而是使用最近的K个行为序列中的物品,来表征用户兴趣,而这明显更含有短期的含义;因为点击序列具备序列性和时间属性,所以对于这类数据,用那些能够刻画序列特性或者物品局部相关性的模型比较合适,比如RNN/CNN和Transformer都比较适合用来对用户短期兴趣建模。
用户长期兴趣:目前在对长短期兴趣分离的工作中,关于如何刻画用户长期兴趣,往往还是用非常简单的方法,就是用UID特征来表征用户的长期兴趣,通过训练过程对UID进行Embedding编码,以此学习到的UID Embedding作为用户长期兴趣表征
重排技术演进趋势
在重排环节,常规的做法,这里是个策略出没之地,就是集中了各种业务和技术策略。比如为了更好的推荐体验,这里会加入去除重复、结果打散增加推荐结果的多样性、强插某种类型的推荐结果等等不同类型的策略。
按理说,这块没什么可讲的。但是,如果从技术发展趋势角度看,重排阶段上模型,来代替各种花样的业务策略,是个总体的大趋势。
List Wise重排序
关于List Wise排序,可以从两个角度来说,一个是优化目标或损失函数;一个是推荐模块的模型结构。
推荐系统里Learning to Rank做排序,我们知道常见的有三种优化目标:Point Wise、Pair Wise和List Wise。所以我们首先应该明确的一点是:List Wise它不是指的具体的某个或者某类模型,而是指的模型的优化目标或者损失函数定义方式,理论上各种不用的模型都可以使用List Wise损失来进行模型训练。最简单的损失函数定义是Point Wise,就是输入用户特征和单个物品特征,对这个物品进行打分,物品之间的排序,就是谁应该在谁前面,不用考虑。明显这种方式无论是训练还是在线推理,都非常简单直接效率高,但是它的缺点是没有考虑物品直接的关联,而这在排序中其实是有用的。Pair Wise损失在训练模型时,直接用两个物品的顺序关系来训练模型,就是说优化目标是物品A排序要高于物品B,类似这种优化目标。其实Pair Wise的Loss在推荐领域已经被非常广泛得使用,比如BPR损失,就是典型且非常有效的Pair Wise的Loss Function,经常被使用,尤其在隐式反馈中,是非常有效的优化目标。List Wise的Loss更关注整个列表中物品顺序关系,会从列表整体中物品顺序的角度考虑,来优化模型。在推荐中,List Wise损失函数因为训练数据的制作难,训练速度慢,在线推理速度慢等多种原因,尽管用的还比较少,但是因为更注重排序结果整体的最优性,所以也是目前很多推荐系统正在做的事情。
从模型结构上来看。因为重排序模块往往是放在精排模块之后,而精排已经对推荐物品做了比较准确的打分,所以往往重排模块的输入是精排模块的Top得分输出结果,也就是说,是有序的。而精排模块的打分或者排序对于重排模块来说,是非常重要的参考信息。于是,这个排序模块的输出顺序就比较重要,而能够考虑到输入的序列性的模型,自然就是重排模型的首选。我们知道,最常见的考虑时序性的模型是RNN和Transformer,所以经常把这两类模型用在重排模块,这是很自然的事情。一般的做法是:排序Top结果的物品有序,作为RNN或者Transformer的输入,RNN或者Transformer明显可以考虑在特征级别,融合当前物品上下文,也就是排序列表中其它物品的特征,来从列表整体评估效果。RNN或者Transformer每个输入对应位置经过特征融合,再次输出预测得分,按照新预测的得分重新对物品排序,就完成了融合上下文信息,进行重新排序的目的。
典型工作:
- Personalized Re-ranking for Recommendation
- Learning a Deep Listwise Context Model for Ranking Refinement
参考文献
https://zhuanlan.zhihu.com/p/100019681