索引数据结构之B-Tree与B+Tree(上篇)
扫描下方二维码或者微信搜索公众号
菜鸟飞呀飞,即可关注微信公众号,阅读更多Spring源码分析、Java并发编程和Netty源码系列文章。

树
树是一种十分常见的数据结构,根据子结点的个数,我们可以将树分为二叉树和多叉树。每个结点最多两个子结点的树称之为二叉树,比较典型的二叉树有二叉搜索树、完全二叉树、满二叉树、二叉平衡树、红黑树等。子结点的个数大于 2 的树称之为多叉树,常见的多叉树有 B 树和 B+树。
B 树和 B+树是一种多路搜索树,它由二叉搜索树演变而来,常用于数据库的索引结构中,且 B+树和 B 树具有很多相似的地方,也比较容易弄混,因此本文将两者放在一起进行学习,进行对比。
B-Tree
B-Tree 又叫做 B 树,很多人见到有 B+树(B+Tree),所以经常会把 B-Tree 和 B 树当做是两种树,实际上 B-Tree 和 B 树是同一种树(单词 B-Tree 翻译过来就是 B 树)。(这个”很多人“就包括笔者,笔者是个菜鸟,最开始把 B-Tree、B 树,B+Tree 当成是三种树,还经常把它们理解为 B 减树,B 树,B 加树,后来去网上查了查才搞清楚)。
对于树这种数据结构,有一个描述树结构的概念叫做度(也叫做阶),它描述的是一个结点中子结点的个数,例如一个二叉树,每个结点最多有 2 个子结点,因此二叉树的度(阶)为 2。对于 B-Tree 而言,同样也有阶的概念,例如一个 5 阶的 B-Tree,表示的是每个结点最多有 5 个子结点。
对于一个阶数为 m 的 B-Tree,它有如下性质:
- 每个结点最多有 m 个子结点;
- 每个非叶子结点(根结点除外)至少含有 m/2 个子结点;
- 如果根结点不是叶子结点,那么根结点至少有两个子结点;
- 对于一个非叶子结点而言,它最多能存储 m-1 个关键字(所谓的关键字,我们可以理解为就是节点上存放的数据);
- 每个节点上,所有的关键字都是有序的,从左至右,依次从小到大排列;
- 每个关键字的左子树的值均小于当前关键字,右子树的值均大于当前关键字;
- 每个节点都存有索引和数据(记住这一点非常重要,这是和后面介绍的 B+Tree 的最重要的区别之一)。
从上面的性质来看,对于 B-Tree 的根结点而言,关键字数量的范围为 1<= k <= m-1;非根结点,关键字的范围为 m/2 <= k <= m-1。知道了这些性质,下面我们分别看看 B-Tree 的插入、查找、删除过程。
1. 插入
在向一个 m 阶的 B-Tree 中插入数据时,为了保证上述 B-Tree 的性质,所以在插入关键字(插入数据)时我们需要按照如下规则插入:向当前结点中插入关键字后,判断当前结点的关键字数量是否小于等于 m-1,如果小于,则插入结束;否则需要将当前结点进行分裂,如何分裂呢?在 m/2 处拆分,形成左右两部分,即两个新的子结点,然后将 m/2 处的关键字移到父节点当中(从最中间分裂)。
对于一个 5 阶的 B-Tree(也就是说,非根结点,关键字数量的范围为 2 <= k <= 4),我们依次向树中插入如下数据:50,30,40,25,其流程如下。
首先依次插入 50、30、40、25,插入后结点状态如下;
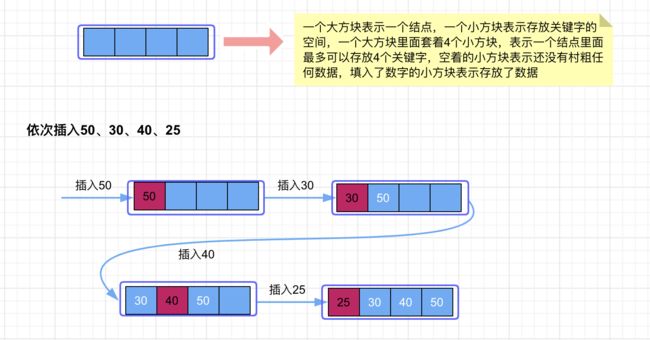
然后当我们再插入 20 时,当前结点中就存储了 5 个关键字,由于当前树是一颗 5 阶树,因此每个结点最多只能存放 4 个关键字,因此此时就需要将当前结点分裂。怎么分裂呢?就是从最中间(m/2)处将结点分成左右两部分(5/2 向上取整是 3),因此从数字 30 所在的地方进行分裂,然后将数字 30 放入到父结点当中(由于此时父结点为空,因此新建一个结点,然后将 30 放入到该结点中),然后将 30 左边的两个数 20、25 构成一个新的结点,右边的两个数 40、50 构成一个新的节点,这两个新的结点分别指向关键字 30 的左右两边。示意图如下:

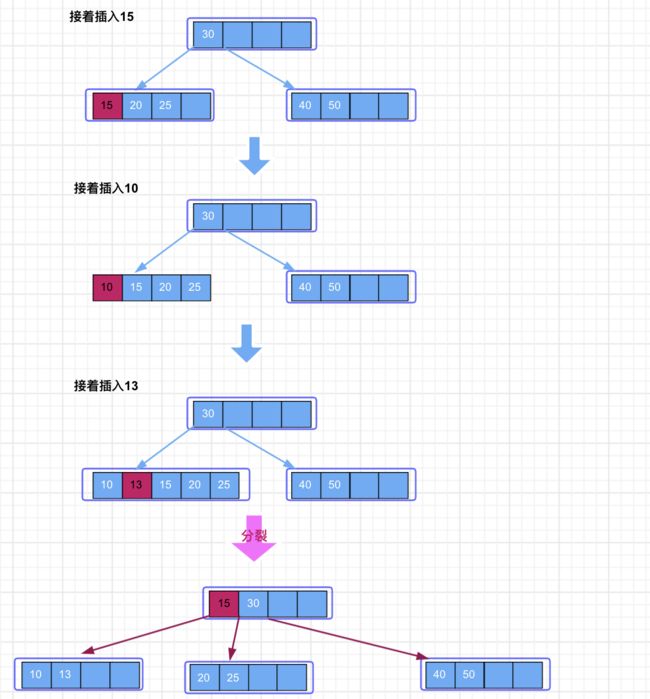
继续向树中插入数据 15、10、13。当插入到 13 时,我们发现结点中的关键字的数量又超过了 m-1,因此又需要进行结点的分裂了。此时将中间的数 15 拆分出去,放到父结点当中,剩下的左右两部分分别构成新的结点。
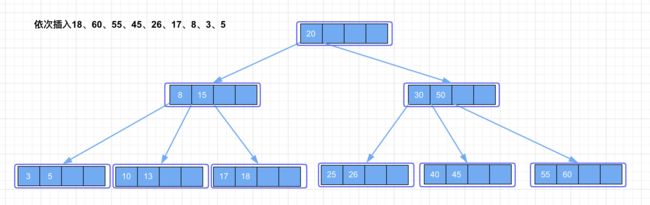
再继续向树中一次插入数据:18、60、55、45、26、17、8、3、5。最后该 B-Tree 的结构如下图所示。
文章中贴出的全是静态图,如果想体验 B-Tree 数据插入的动态过程,可以去下面这个学习网站中去手动插入数据,体验一下数据插入的动态过程。(网址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html 一个非常不错的学习数据结构与算法的网站)
2. 查找
B-Tree 的查找操作相对比较简单,和二叉查找树的查找类似。
- 先从根结点开始查找,依次遍历根结点的关键字,找到第一个不小于要查找数据的关键字;
- 判断要查找的数据是否等于当前关键字,如果等于则返回数据;
- 如果不等于,则表示要查找的数据是否小于当前关键字,因此进入当前关键字的左子树查找,查找过程和根结点的查找过程类似,重复上述步骤即可。
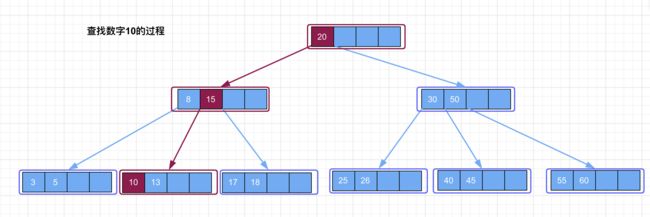
以上面 B-Tree 的数据为例,查找数字 10。首先从根结点开始查找,第一个不小于 10 的关键字是 20,由于要查找的数据10不等于关键字20,因此进入关键字 20 的左子树查找,此时指针指向关键字 8、15 所在的结点,在该结点中第一个不小于 10 的关键字是 15,所以进入关键字 15 的左子树查找,此时指针指向关键字 10、13 所在的结点,发现该结点中关键字 10 等于要查找的数据,因此返回。(如下图所示,红色表示查找过程中的路径)
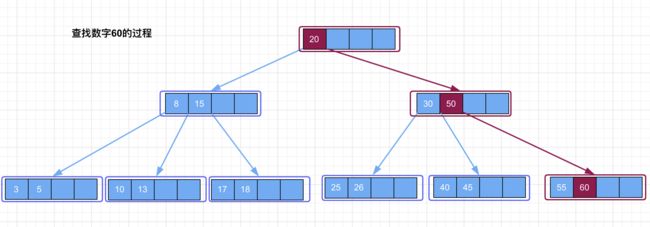
如果要数字 60,过程和上面一样,先从根结点开始,发现根结点中所有的关键字都小于 60,所以进入根结点最后一个关键字的右子树查找,即进入关键字 20 的右子树查找。同样,发现关键字 30、50 所在的结点中,所有的关键字都小于 60,因此进入当前节点最后一个关键字 50 的右子树查找,最终查找到 60,返回数据。如下图所示,红色表示查找过程中的路径)
3. 删除
B-Tree 在数据的插入过程中,为了满足 B-Tree 的性质,因此中间会出现结点的分裂过程,同样,在数据的删除过程中,有可能因为删除了某个关键字而导致不满足 B-Tree 的相关性质了,因此在删除过程中会出现结点的合并等情况,删除过程相对比较复杂,但总体来说,可以归结为以下三种场景。
- 如果是叶子结点,删除关键字后,叶子结点中关键字的数量不少于 m/2 个,那么直接删除关键字即可;
- 如果是叶子结点,删除关键字后,叶子结点中关键字的数量少于 m/2 个,这个时候就不满足 B-Tree 的性质了,因此需要向兄弟结点借关键字。如果兄弟结点中关键字个数大于 m/2,那么就可以借,先将父节点移到当前节点中,然后兄弟结点的一个关键字移到父结点中;如果兄弟结点的关键字数量个数小于等于 m/2,假设兄弟结点借出一个关键字后,那么它自己的关键字数量就少于 m/2 了,又不符合 B-Tree 的性质了,因此这个时候不能借,此时需要将要删除的关键字删除后,将父节点移到此处,然后将当前节点和兄弟结点合并。
- 如果是非叶子节点删除关键字,那么就需要先删除当前关键字,然后用右子树中最小的关键字补上当前位置,再从右子树中删除刚刚补充上去的关键字,这个删除操作就又是B-Tree的删除操作了。(右子树中最小的关键字一定是在叶子结点中,所以删除过程就是删除叶子结点中的关键字了,也就是场景 1 和场景 2 的流程了)。
下面结合具体示例,针对上面 3 个场景分别举例来说明删除操作的流程,以下面的数据为例。

从 B-Tree 中删除关键字 29,由于关键字 29 所在的节点是叶子结点,当将 29 删除后,当前结点的关键字数量为 3,也就是说删除剩下的关键字数量不少于 m/2(5/2=2),满足上面提到的场景 1,那么就可以将关键字直接删除。

继续从 B-Tree 中删除关键字 55,由于关键字 55 所在的节点是叶子结点,当将 55 删除后,当前结点剩下的关键字数量为 1 了,小于 m/2,因此需要向兄弟结点借关键字。当前结点的兄弟结点中有 4 个关键字(40、45、47、49),大于 m/2,所以可以借出关键字,符合场景 2 的第一种情况。因此先将关键字 55 删除,然后将父节点中关键字 50 移动到当前结点,再将兄弟结点中的关键字 49 移动到父结点中,示意图如下。

继续从 B-Tree 中删除关键字 17,由于关键字 17 所在的节点是叶子结点,当将 17 删除后,当前结点剩下的关键字数量为 1 了,小于 m/2,因此需要向兄弟结点借关键字。当前结点的兄弟结点中有 2 个关键字(10、13),小于 m/2,所以不可以借出关键字,符合场景 2 的第二种情况。因此先将关键字 17 删除,然后将父节点中关键字 15 移动到当前结点,然后将当前结点与兄弟结点合并(关键字 10、13 所在的结点)。示意图如下。

然后我们发现,在关键字 17 删除的时候,我们从父结点(关键字 8 所在的结点)中移下来一个关键字,它的父结点只剩下一个关键字了,父结点又不符合 B-Tree 的性质了,所以我们还要继续操作。让父结点找自己的兄弟结点继续借关键字,父结点此时左边没有兄弟结点,因此找右边的兄弟结点(关键字 30 和 49 所在的结点)借关键字。结果发现右边兄弟结点的关键字个数也不大于 m/2,如果兄弟结点借出关键字后,又不符合性质了,所以这个时候又符合上面我们提到的场景 2 的第二种情况,因此需要合并结点。所以接下来的操作是:将关键字 8 的父结点移到 8 所在的结点上,然后合并关键字 8 和 30、49 所在的结点。示意图如下:
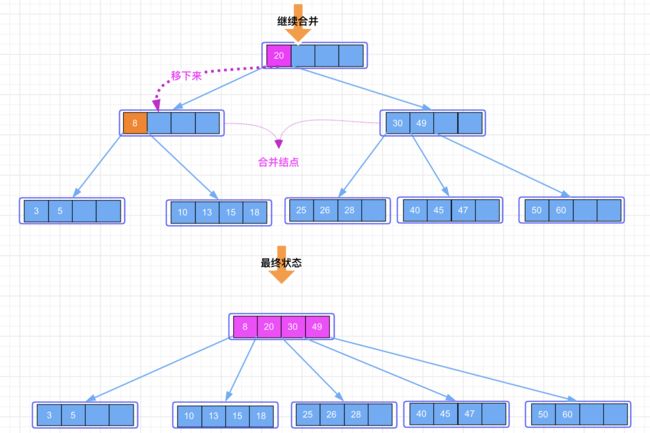
继续从 B-Tree 中删除关键字 20,此时 20 处于的结点是非叶子结点,因此满足场景 3。所以直接删除关键字 20,然后从 20 的右子树中取出最小的关键字 25 填充到 20 所在的位置,最后将 25 这个关键字从右子树的结点中删除,对于 25 这个关键字的删除流程,又可以分别对应上面叶子结点的删除场景了。示意图如下:

以上就是 B-Tree 树中关键字的删除流程,相对于插入和查找过程,删除过程更加复杂,因此最好去这个可视化网站去学习下。(PC 端打开,网址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)
在这个可视化网站中,在删除非叶子结点的关键字的时候,取的是左子树中最大的关键字填充的,而本文讲解的时候说的是取右子树中最小的关键字填充,这两者其实本质上没有任何区别,都是为了满足 B-Tree 的性质,并且保证每个结点上所有关键字是有序的。在学习数据结构和算法的过程中,没有必要死抠细节,重要的是学习思维。
总结
总结时刻。本文主要讲解了 B-Tree 相关的性质,结合示意图详细介绍了插入、查找、删除的过程。在文中的示例中,我特意没有往 B-Tree 中添加重复的数据,那么如果往 B-Tree 中插入重复的数据后又应该怎么办呢?如果出现重复的数时,我们只需要在插入的时候决定将重复的数放入到左子树中或者右子树中,这个具体放在哪边,可以自己定义。在查找数据的时候,就不能在找到一个符合要求的数据后就立马停止查找了,还需要继续往后查找,直到出现第一个不符合要求的数据才停止查找。同样,删除的时候,也需要删除所有的数据。
篇幅有限,因此B+Tree 和数据库索引相关的知识下一篇博客介绍。
相关
- redo log —— MySQL宕机时数据不丢失的原理