虚拟机搭建zookeeper集群和kafka集成,配置消费者和生产者java代码
自己搭建的过程记录,有任何问题希望提出建议,一定重新改过,在虚拟机环境中
首先创建三台虚拟机,我的是192.168.198.128,192.168.198.129,192.168.198.130
在这里里首先解释一些必须的命令
vim /usr/java/conf 这是打开conf的命令
如果出现以下错误
centos -bash: vim: command not found
标识vim没安装
输入rpm -qa|grep vim 命令, 如果 vim 已经正确安裝,会返回下面的三行代码:
root@server1 [~]# rpm -qa|grep vim
vim-enhanced-7.0.109-7.el5
vim-minimal-7.0.109-7.el5
vim-common-7.0.109-7.el5
如果少了其中的某一条,比如 vim-enhanced 的,就用命令 yum -y install vim-enhanced 来安裝
这里基本会全部安装
yum -y install vim-enhanced
如果上面的三条一条都沒有返回, 可以直接用 yum -y install vim* 命令
yum -y install vim*VIM
虚拟机之间经常用ping 查看是否能ping通
打开文件后按i键或者insert键后通过上下左右键操作开始进行编译
编译完后输入 :wq 保存退出
:q! 退出jdk配置
下载jdk,分别在三台虚拟机中解压,配置环境变量,我的是官网下载jdk1.8的,在自定义目录下解压,
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html这个网址,进行下载jdk,下载到自己的Windows7电脑上,再复制到虚拟机的home目录下-
cd /usr 进入usr mkdir java 创建java包 tar -zxvf jdk-8u131-linux-x64.tar.gz 解压jdk包
配置环境变量
vim /etc/profile 打开配置文件配置信息
将这些配置写在最后就行
export JAVA_HOME=/usr/java/jdk1.8.0_201 自己的jdk地址名称
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export PATH JAVA_HOME
保存退出,刷新配置启动配置,每次配置后需要启动刷新下配置文件
source /etc/profile查看配置
javac或者java -version搭建zookeeper
下载zk http://mirrors.cnnic.cn/apache/zookeeper/
上传到自定义目录下解压tar -zxvf ***zk.jar
vim /etc/profile 打开系统配置配置配置环境,刷新环境变量source /etc/profile
写入到jdk配置后就行
export ZK_HOME=/usr/zk/zookeeper-3.4.14
export PATH=$ZK_HOME/bin:$PATH
保存退出,刷新配置查看配置和java相似
zk配置
[root@localhost zookeeper-3.4.11]# cd conf 进入zk
[root@localhost zookeeper-3.4.11]# cd conf 进入zk配置
[root@localhost conf]# mv zoo_sample.cfg zoo.cfg 修改名称为zoo.cfg
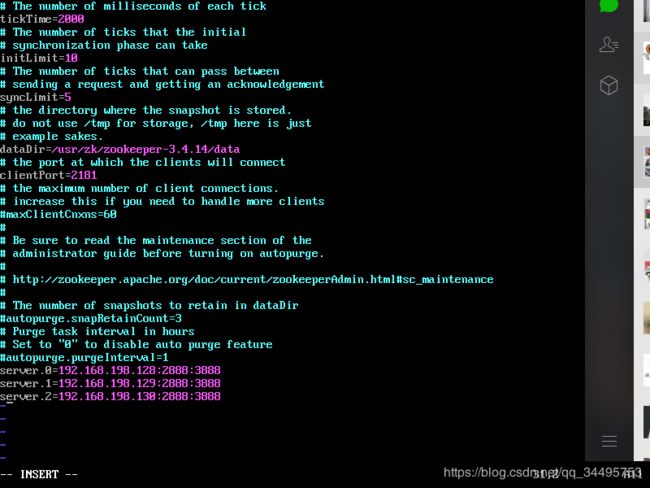
[root@localhost conf]# vim zoo.cfg 打开配置,修改dataDir=/usr/zk/zookeeper-3.4.14/data
最下面配置
server.0=192.168.192.128:2888:3888
server.1=192.168.192.129:2888:3888
server.2=192.168.192.130:2888:3888
解释
server.X=A:B:C
X-代表服务器编号
A-代表ip
B和C-代表端口,这个端口用来系统之间通信
保存退出如图
配置myid这里需要每个机器中都配置
找到Zookeeper目录,新建data文件夹,并且在data文件夹下面创建一个文件,叫myid,并且在文件里写入server.X对应的X
cd data
vim myid
#直接在myid里面写 X 即可
#比如我配置的三个server,myid里面写的X就是所对应的X
如下三台机器分别填写自己对应的server.X
server.0=192.168.192.128:2888:3888【192.168.192.128服务器上面的myid填写0】
server.1=192.168.192.129:2888:3888【192.168.192.129服务器上面的myid填写1】
server.2=192.168.192.130:2888:3888【192.168.192.130服务器上面的myid填写2】
保存退出开启防火墙虽然不知道有什么用,暂时没搞清楚
[root@localhost zookeeper-3.4.11]# firewall-cmd --zone=public --add-port=2888/tcp --permanent
success
[root@localhost zookeeper-3.4.11]# firewall-cmd --zone=public --add-port=3888/tcp --permanent
success
[root@localhost zookeeper-3.4.11]# systemctl restart firewalld启动zookeeper
zkServer.sh start 启动
zkServer.sh status 查看状态出现follower或者leder标识成功
进入zookeeper客户端
启动配置集群客户端,配置几台就需要写几台
zkCli.sh -server 192.168.198.128:2181,192.168.198.129:2181,192.168.198.129:2181
进入后简单操作命令
ls / 查看所有
ls /zookeeper 查看zk下文件
get /zookeeper 获取文件夹下面文件
quit 退出kafka配置
下载(注意下载Binary文件下的,Scala中的,我下载的是第一个)
http://kafka.apache.org/downloads解压到自定义文件下,配置环境变量
/etc/profile
export KAFKA_HOME=/home/jjf/kafka_2.12-1.0.0
export PATH=$PATH:$KAFKA_HOME/bin
保存退出,刷新配置查询环境变量
echo $PATH 其中出现kafka和配置的所有就算成功
修改kafka配置
修改kafka文件下conf中的server.properties为kafka核心配置,修改log.dirs日志存储地址
/usr/kafka/kafka_2.12-2.20/data/log,这里如果没有需要创建,可自定义
broker.id=1;//配置是0是创建不了topic,不知道为什么
是自己的所有zk地址
zookeeper.connect=192.168.198.128:2181,192.168.198.129:2181,192.168.198.130:2181
启动kafka
//启动线程并写入日志
kafka-server-start.sh /usr/local/kafka_2.11-0.9.0.1/config/server.properties > /usr/local/kafka_2.11-0.9.0.1/logs/logs/test.log &
test.log自定义文件名称
& 后台运行查看Topic
kafka-topics.sh -list -zookeeper 192.168.198.128:2181,192.168.198.129:2181,192.168.198.130:2181创建Topic
kafka-topics --create --topic test1 --zookeeper 192.168.198.128:2181,192.168.198.129:2181,192.168.198.130:2181 --config max.message.bytes=12800000 --config flush.messages=1 --partitions 5 --replication-factor 1删除Topic
./kafka-topics --delete --topic test0 --zookeeper 192.168.10.10:2181,192.168.10.25:2181,192.168.10.37:2181测试kafka
我在本地测试需要修改一些配置
本地测试发现连接超时
配置kafka sercer.propertise文件
listeners=PLAINTEST://192.168.198.128:9092
并关闭防火墙,虚拟机CentOS 7命令
CentOS 7
[root@jed bin]# systemctl stop firewalld.service # 关闭防火墙
[root@jed bin]# systemctl disable firewalld.service # 禁止开机启动测试java代码生产者
package com.example.kafka.Producer;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* kafka生产者
**/
public class ProducerKafka {
private final KafkaProducer producer;
public final static String TOPIC = "testTopic";
private ProducerKafka() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.198.128:9092");//xxx服务器ip
props.put("acks", "all");//所有follower都响应了才认为消息提交成功,即"committed"
props.put("retries", 0);//retries = MAX 无限重试,直到你意识到出现了问题:)
props.put("batch.size", 16384);//producer将试图批处理消息记录,以减少请求次数.默认的批量处理消息字节数
//batch.size当批量的数据大小达到设定值后,就会立即发送,不顾下面的linger.ms
props.put("linger.ms", 1);//延迟1ms发送,这项设置将通过增加小的延迟来完成--即,不是立即发送一条记录,producer将会等待给定的延迟时间以允许其他消息记录发送,这些消息记录可以批量处理
props.put("buffer.memory", 33554432);//producer可以用来缓存数据的内存大小。
props.put("key.serializer",
"org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer(props);
}
public void produce() {
int messageNo = 1;
final int COUNT = 5;
while(messageNo < COUNT) {
String key = String.valueOf(messageNo);
// String data = String.format("hello KafkaProducer message %s from hubo 06291018 ", key);
String data = "测试kafka创建这,消费信息···················"+key;
try {
producer.send(new ProducerRecord(TOPIC, data));
} catch (Exception e) {
e.printStackTrace();
}
messageNo++;
}
producer.close();
}
public static void main(String[] args) {
new ProducerKafka().produce();
}
}
测试代码消费者
package com.example.kafka.Consumer;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
/**
* kafka消费者
**/
public class ConsumerKafka extends Thread {
public static void main(String[] args){
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.198.128:9092");//xxx是服务器集群的ip
properties.put("group.id", "jd-group");//组名 不同组名可以重复消费。例如你先使用了组名A消费了kafka的1000条数据,
// 但是你还想再次进行消费这1000条数据,
// 并且不想重新去产生,那么这里你只需要更改组名就可以重复消费了
properties.put("enable.auto.commit", "true");//是否自动提交,默认为true。
properties.put("auto.commit.interval.ms", "1000");//从poll(拉)的回话处理时长
properties.put("auto.offset.reset", "latest");//:消费规则,默认earliest 。
//earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 。
//latest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 。
//none: topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
properties.put("session.timeout.ms", "30000");//超时时间。
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("testTopic"));
while (true) {
ConsumerRecords records = kafkaConsumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println("-----------------");
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
}
}
}
启动生产者和消费者在控制台输出生产者的消息,至此配置结束,非常基础的配置,有不足之处还望谅解,有改进之处还望赐教。小弟感激不尽!