《数据库系统概论》课程学习(23)——数据库原理及应用实验指导书
数据库原理及应用实验指导书
****大学计算机与信息技术学院
2011年6月
目 录
内容简介 1
实验一 熟悉 SQL SERVER 2005的环境及数据库的管理 11
实验二 数据表的创建与管理 19
实验三 数据表的操作 24
实验四 视图的创建与使用 29
实验五 索引的创建与使用 33
实验六 存储过程的创建与使用 36
实验七 触发器的创建与使用 42
内容简介
一、本实验课的性质、任务与教学目标
《数据库原理及应用》课程不仅要求学生掌握数据库技术的基本理论,更重要的是要培养学生的数据库技术实际应用能力,实验课的安排有利于帮助学生更好地掌握数据库技术的知识,培养学生利用数据库技术解决实际管理问题的能力。
本实验课的教学目的是使学生在正确理解数据库系统原理的基础上,熟练掌握主流数据库管理系统(SQL Server 2005)的应用技术进行数据库应用系统的设计与开发。
教学目标:通过上机操纵SQL语句,熟练掌握和深入理解SQL SERVER 2005环境下的基本使用知识。熟悉 SQL SERVER 2005的环境;熟练掌握SQL中数据库及表的定义功能;熟练掌握数据库表的操纵功能;理解视图、索引的创建和使用;了解存储过程和触发器的使用;能运用SQL SERVER 2005的完成后台数据库的设计。
二、本实验课的基本理论
该实验课是在理论思想指导下为达到某项目标而进行的实验,实验的语言是程序、实验的成功与失败必须用程序设计语句及实验得到的界面来说明。本课程的基本理论包括:SQL定义功能,熟练掌握SQL操纵功能,了解SQL数据控制功能,关系数据库的规范化理论,数据库设计的过程及方法等。
三、实验基本要求
通过本课程的学习,学生应达到下列基本要求:
1.了解数据库的基本概念,掌握数据库设计基本知识和技术。
2.熟悉SQL Server安装和配置。
3.熟练使用企业管理器、查询分析器创建、使用和管理数据库和数据库对象。
4.熟练掌握Transact-SQL语言的使用,并能进行编程。
5.掌握设计开发数据库系统后台数据库的基本过程和方法。
6.了解本课程的专业素质要求。
四、实验环境介绍
本课程选用SQL Server 2005系统作为实验环境。SQL Server是使用客户机/服务器(C/S)体系结构的关系型数据库管理系统(RDBMS)。
1.硬件需求
(1)显示器:VGA或者分辨率至少在1,024x768像素之上的显示器。
(2)点触式设备:鼠标或者兼容的点触式设备。
(3)CD 或者 DVD驱动器。
(4)处理器型号,速度及内存需求。SQL Server 2005不同的版本对处理器型号,速度及内存的需求是不同的,如下表:
| SQL Server 2005版本 |
处理器型号 |
处理器速度 |
内存(RAM) |
| SQL Server 2005企业版 SQL Server 2005开发者版 SQL Server 2005标准版 SQL Server 2005工作组版 |
Pentium III及其兼容处理器,或者更高型号。 |
至少600 MHz,推荐1GHz或更高。 |
至少512MB,推荐1GB或更大。 |
| SQL Server 2005简化版 |
Pentium III及其兼容处理器,或者更高型号。 |
至少600 MHz,推荐1GHz或更高。 |
至少192 MB,推荐512MB或更大。 |
(5)硬盘空间需求。实际的硬件需求取决于你的系统配置以及你所选择安装的SQL Server 2005服务和组件。如下表:
| 服务和组件 |
硬盘需求 |
| 数据库引擎及数据文件,复制,全文搜索等 |
150 MB |
| 分析服务及数据文件 |
35 KB |
| 报表服务和报表管理器 |
40 MB |
| 通知服务引擎组件,客户端组件以及规则组件 |
5 MB |
| 集成服务 |
9 MB |
| 客户端组件 |
12 MB |
| 管理工具 |
70 MB |
| 开发工具 |
20 MB |
| SQL Server联机图书以及移动联机图书 |
15 MB |
| 范例以及范例数据库 |
390 MB |
2.软件需求
(1)浏览器软件。在装SQL Server 2005之前,需安装Microsoft Internet Explorer 6.0 SP1或者其升级版本。因为微软控制台以及HTML帮助都需要此软件。
(2)IIS软件。在装SQL Server 2005之前,需安装IIS5.0及其后续版本,以支持SQL Server 2005的报表服务。
(3)ASP.NET 2.0。当安装报表服务时,SQL Server 2005安装程序会检查ASP.NET是否已安装到本机上。
(4)还需要安装以下软件:Microsoft Windows .NET Framework 2.0;Microsoft SQL Server Native Client;Microsoft SQL Server Setup support files。
五、SQL Server 2005安装过程
SQL Server 2005的安装过程与其它Microsoft Windows系列产品类似。用户可以根据向导提示,选择需要的选项一步一步地完成。

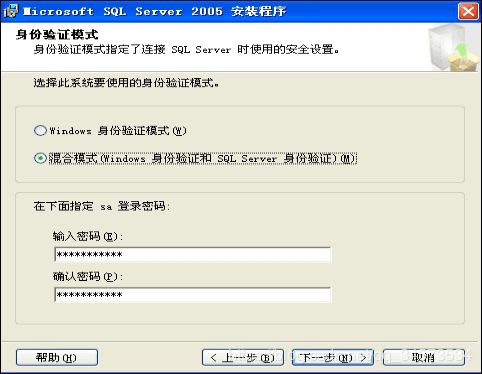
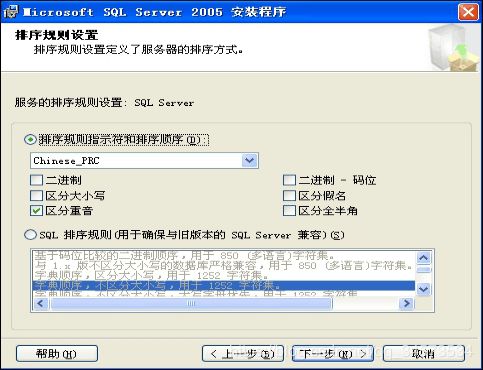
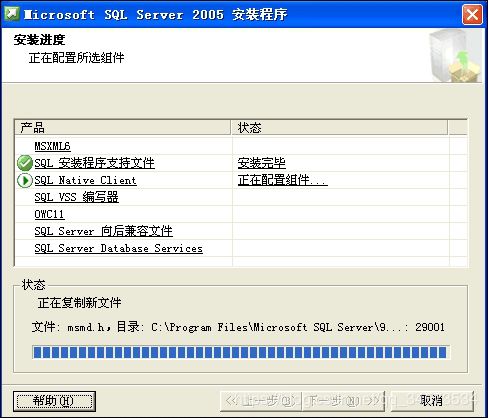
六、系统安装后的数据库
SQL Server 2005有4个系统数据库,它们分别为Master、Model、Msdb、Tempdb。
(1)Master数据库是SQL Server系统最重要的数据库,它记录了SQL Server系统的所有系统信息。这些系统信息包括所有的登录信息、系统设置信息、SQL Server的初始化信息和其他系统数据库及用户数据库的相关信息。因此,如果 master 数据库不可用,则 SQL Server 无法启动。在 SQL Server 2005 中,系统对象不再存储在 master 数据库中,而是存储在 Resource 数据库中。
(2)model 数据库用作在 SQL Server 实例上创建的所有数据库的模板。因为每次启动 SQL Server 时都会创建 tempdb,所以 model 数据库必须始终存在于 SQL Server 系统中。当发出 CREATE DATABASE(创建数据库)语句时,将通过复制 model 数据库中的内容来创建数据库的第一部分,然后用空页填充新数据库的剩余部分。 如果修改 model 数据库,之后创建的所有数据库都将继承这些修改。例如,可以设置权限或数据库选项或者添加对象,例如,表、函数或存储过程。
(3)Msdb数据库是代理服务数据库,为其报警、任务调度和记录操作员的操作提供存储空间。
(4)Tempdb是一个临时数据库,它为所有的临时表、临时存储过程及其他临时操作提供存储空间。Tempdb数据库由整个系统的所有数据库使用,不管用户使用哪个数据库,他们所建立的所有临时表和存储过程都存储在tempdb上。SQL Server每次启动时,tempdb数据库被重新建立。当用户与SQL Server断开连接时,其临时表和存储过程自动被删除。
实验一 熟悉 SQL SERVER 2005的环境及数据库的管理
一、实验目的
- 熟悉SQL SERVER 2005企业管理器、查询分析器的基本使用方法
- 了解SQL SERVER 2005数据库的逻辑结构和物理结构及其结构特点
- 掌握在企业管理器中创建数据库
- 掌握使用T-SQL语句创建数据库
二、实验内容
(一)SQL SERVER 2005管理工具介绍
SQL Server 2005管理平台(SQL Server Management Studio)包含了SQL Server 2000企业管理器(Enterprise Manager),以及查询分析器(Query Analyzer)等方面的功能。此外,SQL Server 2005管理平台还提供了一种环境,用于管理 Analysis Services(分析服务)、Integration Services(集成服务)、Reporting Services(报表服务)和 XQuery。
(二)服务器管理
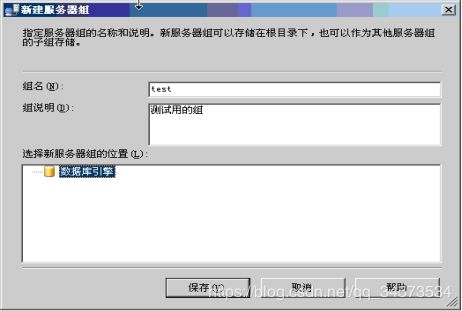
1.创建服务器组
在一个网络系统中,可能有多个SQL Server服务器,可以对这些SQL Server服务器进行分组管理。分组的原则往往是依据组织结构原则,如将公司内一个部门的几个SQL Server服务器分为一组。SQL Server分组管理由SQL Server管理平台来进行。
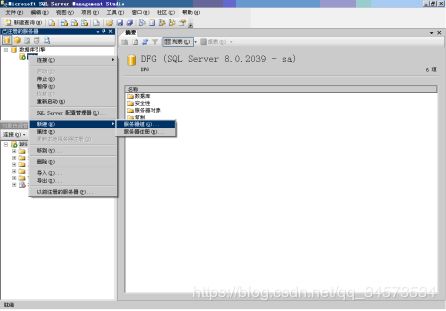
2.服务器注册与连接
在SQL Server管理平台中注册服务器可以存储服务器连接信息,以供将来连接时使用。
有三种方法可以在SQL Server管理平台中注册服务器:
(1)在安装管理平台之后首次启动它时,将自动注册 SQL Server 的本地实例;
(2)可以随时启动自动注册过程来还原本地服务器实例的注册;
(3)可以使用 SQL Server管理平台的“已注册的服务器”工具注册服务器。
在注册服务器时必须指定以下选项,如图所示:
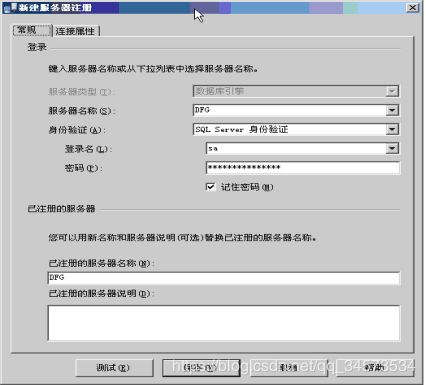
(1)服务器的类型。
(2)服务器的名称。
(3)登录到服务器时使用的身份验证的类型,以及登录名和密码(如果需要)。
(4)注册了服务器后要将该服务器加入到其中的组的名称。
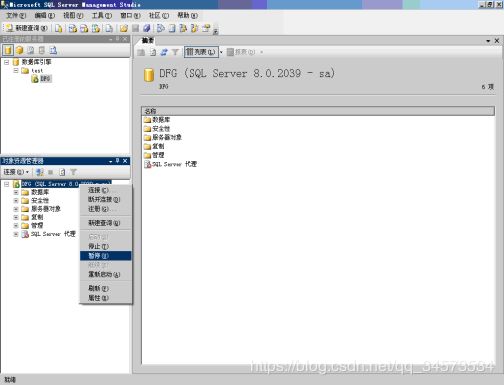
3.服务器启动、暂停和停止
在SQL Server管理平台中,在所要启动的服务器上单击右键,从弹出的快捷菜单中选择“启动”选项,即可启动服务器。
暂停和关闭服务器的方法与启动服务器的方法类似,只需在相应的快捷菜单中选择“暂停(Pause)”或“停止(Stop)”选项即可,如图所示。
(三)创建数据库
1.在企业管理器中创建数据库
(1)在企业管理器中,单击工具栏中的 ![]() 图标,或在数据库文件夹或其下属任一数据库图标上单击右键,选择新建数据库选项,就会出现数据库属性对话框。
图标,或在数据库文件夹或其下属任一数据库图标上单击右键,选择新建数据库选项,就会出现数据库属性对话框。
(2)在常规(General)页框中,要求用户输入数据库名称以及排序规则名称。
(3)点击数据文件(Data Files)页框,该页框用来输入数据库文件的逻辑名称、存储位置、初始容量大小和所属文件组名称。
(4)点击事务日志(Transaction Log)页框,该页框用来设置事务日志文件信息。
(5)单击“确定”按钮,则开始创建新的数据库。
2.使用T-SQL语句创建数据库
语法如下:
CREATE DATABASE database_name
[ON [PRIMARY] [
[LOG ON {
[FOR RESTORE]
FILENAME=‘os_file_name’
[,SIZE=size]
[,MAXSIZE={max_size|UNLIMITED}]
[,FILEGROWTH=growth_increment] ) [,…n]
各参数说明如下:
- database_name:数据库的名称,最长为128个字符。
- PRIMARY:该选项是一个关键字,指定主文件组中的文件。
- LOG ON:指明事务日志文件的明确定义。
- NAME:指定数据库的逻辑名称,这是在SQL Server系统中使用的名称,是数据库在SQL Server中的标识符。
- FILENAME:指定数据库所在文件的操作系统文件名称和路径,该操作系统文件名和NAME的逻辑名称一一对应。
- SIZE:指定数据库的初始容量大小。
- MAXSIZE:指定操作系统文件可以增长到的最大尺寸。
- FILEGROWTH:指定文件每次增加容量的大小,当指定数据为0时,表示文件不增长。
例1:使用CREATE DATABASE创建一个student数据库,所有参数均取默认值。
Create database student例2:创建一个gzgl数据库,该数据库的主文件逻辑名称为gzgl,物理文件名为gzgl_data.mdf,初始大小为10MB,最大尺寸为无限大,增长速度为10%;数据库的日志文件逻辑名称为gzgl_log,物理文件名为gzgl_log.ldf,初始大小为1MB,最大尺寸为5MB,增长速度为1MB。
Create database gzgl
On primary
(name= gzgl _data,
filename=’e:\data\gzgl_data.mdf’,
size=10,
maxsize=unlimited,
filegrowth=10%)
log on
(name= gzgl _log,
filename=’e:\data\gzgl_log.ldf’,
size=1,
maxsize=5,
filegrowth=1)(四)删除数据库
1.利用企业管理器删除数据库
在企业管理器中,右击要删除的数据库,从弹出的快捷菜单中选择“删除”或按下“delete”键。
2.利用Drop语句删除数据库
语法格式:Drop database database_name[,…n]
说明:只有处于正常状态下的数据库,才能使用DROP语句删除。当数据库处于以下状态时不能被删
除:数据库正在使用;数据库正在恢复;数据库包含用于复制的已经出版的对象。
例3:删除已创建的数据库student
drop database student(五)修改数据库
1.利用企业管理器修改数据库
数据库创建以后,可以在企业管理器中利用数据库的属性设置,来更改数据库创建的某些设置,以及创建时无法设置的属性。在企业管理器中,右击要修改的数据库,选择“属性”选项,在弹出的数据库属性窗口中进行修改。
2.利用Drop语句修改数据库,语法如下:
Alter database databasename
{add file
|add log file
|remove file logical_file_name
|remove filegroup filegroup_name
|modify file
|modify name=new_databasename
|add filegroup filegroup_name
|modify filegroup filegroup_name
{filegroup_property|name=new_filegroup_name}}
参数说明:
add file
add log file
remove file logical_file_name:删除指定的操作系统文件。
remove filegroup filegroup_name:删除指定的文件组。
modify file
modify name=new_databasename:重命名数据库。
add filegroup filegroup_name:增加一个文件组。
modify filegroup filegroup_name:修改某个指定文件组的属性。
例4:将gzgl数据库的日志文件初始大小改为10MB
Alter database gzgl
MODIFY FILE
(NAME = gzgl_log,
SIZE = 10MB)例5:为gzgl数据库添加一个次要数据文件gzgl_data2.ndf,初始大小为5MB,最大尺寸为100MB,增长速度为5MB。
ALTER DATABASE gzgl
ADD FILE
( NAME = gagl_data2,
FILENAME = 'e:\dhb\gzgl_data2.ndf',
SIZE = 5MB,
MAXSIZE = 100MB,
FILEGROWTH = 5MB)注释:SQL Server 2005 数据库有三种类型的文件:
(1)主要数据文件:是数据库的起点,指向数据库中文件的其它部分。每个数据库都有一个主要数据文件。主要数据文件的推荐文件扩展名是 .mdf。
(2)次要数据文件:包含除主要数据文件外的所有数据文件。有些数据库可能没有次要数据文件,而有些数据库则有多个次要数据文件。次要数据文件的推荐文件扩展名是 .ndf。
(3)日志文件:包含恢复数据库所需的所有日志信息。每个数据库必须至少有一个日志文件,但可以不止一个。日志文件的推荐文件扩展名是 .ldf。
三、实验习题
分别用企业管理器和查询分析器创建“学生”数据库,要求数据库student初始大小为10MB,最大尺寸为40MB,增长速度为5%;数据库的日志文件逻辑名称为Student_log,物理文件名为Student_log.ldf,初始大小为2MB,最大尺寸为10MB,增长速度为1MB。
实验二 数据表的创建与管理
一、实验目的
- 了解SQL SERVER的基本数据类型及空值的概念
- 掌握在企业管理器中进行表的创建和管理
- 掌握使用T-SQL语句进行表的创建和管理
二、实验内容
(一)创建表
1. 利用企业管理器创建表
在企业管理器中,展开指定的服务器和数据库,打开想要创建新表的数据库,右击表对象,并从弹出的快捷菜单中选择“新建表”,出现对话框。
在对话框,定义的属性说明如下:
- 默认值:指定列的默认值。除定义为TIMESTAMP或带IDENTITY属性的列以外的任何列。删除表时,将删除默认值定义。只有常量值(如字符串)、SQL Server内部函数(如SYSTEM_USER())或NULL值可以用作默认值。
- 精度和小数位数:精度是列的总长度,包括整数部分和小数部分的长度之和,但不包括小数点;小数位数指定小数点后面的长度。
- 标识:指定列是否是标识列。一个表只能创建一个标识列。不能对标识列使用绑定默认值和DEFAULT约束。必须同时指定种子和增量,或者两者都不指定。默认值(1,1)。能够成为标识列的数据类型有int、smallint、tinyint、numeric和decimal等系统数据类型;如果其数据类型为numeric和decimal,不允许出现小数位数。
- 标识种子:指定标识列的初始值。
- 标识递增量:指定标识列的增量值。
- RowGuid:指定列是否使用全局唯一标识符。
- 公式:用于指定计算列的列值表达式。
- 排序规则:指定列的排序规则。
注意:在数据库中表名必须是唯一的,但是如果为表指定了不同的用户,就可以创建多个相同名称的表。
2.利用T-SQL语句创建表,语法如下:
CREATE TABLE
[ database_name.[ owner ] .| owner.]
table_name
( { < column_definition >| column_name AS computed_column_expression|< table_constraint >} [,…n])
[ ON { filegroup | DEFAULT } ]
[ TEXTIMAGE_ON { filegroup | DEFAULT } ]
< column_definition > ::= { column_name data_type }
[ COLLATE < collation_name > ]
[ [ DEFAULT constant_expression ]
| [ IDENTITY [ ( seed , increment ) [ NOT FOR REPLICATION ] ] ] ]
[ ROWGUIDCOL]
[ < column_constraint > ] [ ...n ]
< column_constraint > ::=[ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[ WITH FILLFACTOR = fillfactor ]
[ON {filegroup | DEFAULT} ] ] }
|FOREIGN KEY [(column [,…n])]
REFERENCES ref_table [ ( ref_column [,…n]) ] [NOT FOR REPLICATION]
| CHECK [ NOT FOR REPLICATION ]
( logical_expression )}
例1:在GZGL中创建一个JBXX的数据库表
use GZGL
go
create table jbxx1
(employee_id char(6) not null,
name char(10) not null,
birthday datetime not null,
sex char(2) default‘男’)
go- 创建、删除和修改约束
1.利用企业管理器
在企业管理器中,右击要操作的数据表,从弹出的快捷菜单中选择“设计表”选项,出现设计表对话框,选择要设定为主键的字段,如果有多个字段,按住Ctrl键的同时,用鼠标单击选中的某个字段,从弹出的快捷菜单中选择“设置主键”选项;在属性对话框中的“索引/键”选项卡中设置。
2.利用T-SQL语句,语法如下:
CONSTRAINT constraint_name
PRIMARY KEY/UNIQUE
[CLUSTERED|NONCLUSTERED]
(column_name[,…n])
参数说明:
constraint_name约束名称,在数据库中应该唯一,不指定,系统会自动生成一个约束名。
[CLUSTERED|NONCLUSTERED]索引类型,聚族索引或非聚族索引,CLUSTERED为默认值。
column_name用于指定主键的列名。最多由16个列组成。
例1:在GZGL中创建一个JBXX的数据库表,字段employee_id具有唯一性
use GZGL
go
create table jbxx2
(employee_id char(6) not null primary key,
name char(10) not null,
birthday datetime not null,
sex char(2) default‘男’
constraint uk_name unique(employee_id)
constraint chk_sex check(sex in (‘男’,‘女’)))
go(三)增加、删除和修改字段
1.利用企业管理器
在企业管理器中,右击要操作的数据表,从弹出的快捷菜单中选择“设计表”选项,出现设计表对话框,在对话框可完成增加、删除和修改字段的操作。
2.利用T-SQL语句,语法如下:
ALTER TABLE table
{ [ ALTER COLUMN column_name
{ new_data_type [ ( precision [ , scale ] ) ]
[ COLLATE < collation_name > ]
[ NULL | NOT NULL ]
| {ADD | DROP } ROWGUIDCOL } ]
| ADD
{ [ < column_definition > ]
| column_name AS computed_column_expression
} [ ,...n ]
| [ WITH CHECK | WITH NOCHECK ] ADD
{ < table_constraint > } [ ,...n ]
| DROP
{ [ CONSTRAINT ] constraint_name
| COLUMN column } [ ,...n ]
| { CHECK | NOCHECK } CONSTRAINT
{ ALL | constraint_name [ ,...n ] }
| { ENABLE | DISABLE } TRIGGER
{ ALL | trigger_name [ ,...n ] }
}
例如:
alter table jbxx2 alter column name char(8)
alter table jbxx2 drop column birthday
alter table jbxx2 add memo varchar(200)
alter table jbxx1 add constraint PK_em_id primary key(employee_id)
alter table jbxx1 add constraint sex default’男’for sex(四)查看表格
1.利用企业管理器
在企业管理器中,右击要操作的数据表,从弹出的快捷菜单中选择“属性”选项,出现表属性对话框,在对话框可显示对表格的定义。
在企业管理器中,右击要操作的数据表,从弹出的快捷菜单中选择“打开表”选项,该选项有三个子项:“返回所有行”:显示所有记录;“返回首行”::显示前N条记录,N可自己输入;“查询”:查询具体某行记录。
2.利用T-SQL语句
语法:sp_help [[@objname=]name]
系统存储过程Sp_help可以提供指定数据库对象的信息,只用于当前数据库。其中[[@objname=]name]字句用于指定对象的名称,如果不指定对象名称,sp_help存储过程就会列出当前数据库中的所有对象名称、对象的所有者和对象的类型。
例1:显示当前数据库中所有对象的信息
use gzgl
go
exec sp_help例2:显示表jbxx的信息
use gzgl
go
exec sp_help jbxx1- 更改表的名称
语法:sp_rename [@objname=]‘object_name’,[@newname=] ‘new_name’
[,[@objtype=] ‘object_type’]
@objtype=] ‘object_type’指定要改名的对象的类型,其值可以为COLUMN,DATABASE,INDEX,USERDATATYPE,OBJECT。值OBJECT指代系统表中的所有对象,OBJECT值为默认值。
例1:sp_rename ‘jbxx1’,‘基本信息‘ //将jbxx1的名称改为基本信息
- 删除表
1.利用企业管理器
在企业管理器中,右击要删除的数据表,从弹出的快捷菜单中选择“删除”选项,出现“除去对象”对话框,在对话框完成操作。
2.利用T-SQL语句
DROP TABLE table_name
三、实验习题
分别用企业管理器和查询分析器在“学生”数据库中创建学生表、课程表、选课表,表中字段如下:
s(sno,sname,age,sex),c(cno,cname,teacher),sc(sno,cno,grade),类型自定。
实验三 数据表的操作
一、实验目的
- 掌握在企业管理器中对表进行插入、修改和删除数据的操作
- 掌握使用T-SQL语句对表进行插入、修改和删除数据的操作
- 掌握使用T-SQL语句对表进行插入、修改和删除数据的操作
- 重点掌握 SELECT语句的使用方法
- 掌握子查询(嵌套查询)、连接查询的使用
二、实验内容
-
- 在企业管理器中对数据库中的表进行插入、修改和删除数据
例1:在企业管理器中向数据库gzgl中的表输入数据
在企业管理器中向jbxx表插入记录,选择并用鼠标右击表jbxx →选择“返回所有行” →逐字段输入各记录值,输入完后关闭窗口。
例2:在企业管理器中将表jbxx中编号为020805的记录的部门号改为003
在企业管理器中选择表并用鼠标右击表jbxx →选择“返回所有行” →将光标定位至employee_id为020805的记录的department_id字段,改为003。
例3:在企业管理器中删除数据库gzgl表数据
在企业管理器中删除表jbxx的第3、6行操作步骤:在企业管理器中选择表并用鼠标右击表jbxx →选择“返回所有行” →选择要删除的行 →单击鼠标右键 →删除 →关闭表窗口。
-
- 使用T-SQL语句对表进行插入、修改和删除数据的操作
1. 使用INSERT语句插入数据
语法:INSERT [ INTO]
{ table_name
| view_name
}
{[( column_list )]
{ VALUES
( { DEFAULT | NULL | expression }
[ ,...n] )
| derived_table
}
例1:向数据库gzgl中的表输入数据
use gzgl
go
insert into jbxx
values(‘0111112’,’李子林’,’1973_5_3’,’1’,’310107196206088243’,’交通路5号’,’[email protected]’)
go单击快捷工具栏的执行图标或按F5,执行上述语句。
2. 使用UPDATE语句更新数据
语法:UPDATE
{ table_name
| view_name
}
[ FROM { < table_source > } [ ,...n ]
SET
column_name = { expression | DEFAULT | NULL }[ ,...n ]
[ WHERE search_condition > ]
例2:将表jbxx中编号为020805的记录的部门号改为003
use gzgl
go
update jbxx
set department_id=’003’
where employee_id=’020805’
go例3:将表jbxx中的年龄增加1岁。
use gzgl
go
update jbxx
set age=age+1
go例4:将表jbxx中所有记录的dang员属性改为“dang员”
use gzgl
go
update jbxx
set polity=’dang’
&&如果没有where子句,则将修改表中的每一行数据
单击快捷工具栏的执行图标或按F5,执行上述语句。
3. 使用DELETE语句删除数据
语法:DELETE
[ FROM ]
{ table_name WITH ( < table_hint_limited > [ ...n ] )
| view_name
}
[ WHERE
< search_condition >
]
例1:删除jbxx表中编号为020805的记录。
use gzgl
go
delete from jbxx
where employee_id=’020805’例2:删除数据库gzgl中jbxx表的所有数据
use gzgl
go
delete from jbxx或者使用TRUNCATE TABLE name
use gzgl
go
truncate table jbxx-
- SELECT语句的使用方法。
基本格式如下:
SELECT select_list
[ INTO new_table ]
FROM table_source
[ WHERE search_condition ]
[ GROUP BY group_by_expression ]
[ HAVING search_condition ]
[ ORDER BY order_expression [ ASC | DESC ] ]
例1:对学生成绩的查询。
/*方法一*/
select s.sname,sc.grade
from s,sc
where s.sno=sc.sno/*方法二*/
select s.sname,sc.grade
from s JOIN sc
on s.sno=sc.sno例2:查询结果只显示前n条记录*
select top 3 sno,sname,sdept
from s例3:分组查询、并改名
select sage as 学生年龄,count(*)as 学生数
from s
group by sage例4:使用CASE函数分类查询
select * ,
case cno
when 1 then round((grade*1.03),-1)
when 2 then round((grade*1.04),-1)
when 3 then round((grade*1.05),-1)
else round((grade*1.01),-1)
end as 期望成绩
from sc1.基本select语句使用
例:查询employee_id为000001职工地址和电话
use gzgl
go
select address,phone_id from jbxx where employee_id=’000001’
go2.连接查询使用
例:查询每个职工的情况及其薪水的情况
use gzgl
go
select jbxx.*,gzxx.* from jbxx,gzxx
where jbxx.employee_id=gzxx. employee_id
go3.统计函数group by、order by 子句的使用
例:查询职工的平均收入
use gzgl
go
select employee_id,avg(realcome) from gzxx
go4.子查询(嵌套)的使用
三、实验习题
-
- 为 “学生”数据库的学生表(student)、课程表(course)、选课表(sc)添加记录。
- 验证P97 例3.8以及课堂所授内容中的查询实例。
- 完成书上P128 3.2,P128 3.7,P128 3.12
实验四 视图的创建与使用
一、实验目的
- 了解视图和数据表之间的主要区别
- 掌握在企业管理器中创建视图的方法
- 掌握使用T-SQL语句创建视图的方法
- 掌握查看视图修改数据表的方法
二、实验内容
- 在企业管理器中创建视图
①打开企业管理器窗口,打开新建视图对话框。
方法一:在企业管理器左边的“树”选项卡中选择指定的SQL SERVER组,展开指定的服务器,打开要创建视图的数据库文件夹,选中指定的数据库,右击该数据库图标,从弹出的快捷菜单中依次选择“新建”|“视图”选项,打开新建视图对话框。
方法二:在数据库文件夹中,用鼠标右击下一层的“视图”选项,在弹出的快捷菜单中选择“新建视图”选项。
②在新建视图对话框中,右击窗口上部的空白部分,从弹出的快捷菜单中选择“添加表”选项,或者单击工具栏中的按钮,出现“添加表”对话框,在该框中可以选择需要添加的基本表,单击“添加”按钮,就可以添加进去;也可以某个表名来添加表。使用同样的方法可以切换到“视图”或“函数”选项卡,从中选择需要的视图或函数,并依次创建新的视图。
③这里利用Ctrl键和鼠标配合,同时选前面建立的3个表S,SC,C,并单击“添加”按钮,即可将这3个表添加到创建视图对话框中。然后通过单击字段左边的复选框选择需要的字段,这里选择s表中sno,sname,C表中cno,SC表中sno,cno,属性设置如下:
△选中“输出”复选框,可以在输出结果中显示该字段。
△在“准则”复选框中输入限制条件,可以限制输出的记录。在定义视图的查询语句中该相知条件对应WHERE子句。
④右击字段定义对话框,从弹出的快捷菜单中选择“属性”选项,出现视图属性对话框。该对话框中,“distinct值”可以选择不输出重复的记录,“加密浏览”可以实现对视图定义加密,选中“顶端”复选框可以限制视图最多输出的记录条数。
⑤要运行并输出该视图结果,可以在视图设计窗口中单击工具栏中“!”按钮,或右击窗口空白区,在弹出的快捷菜单中选择“运行”选项,则可根据设置的查询语句,在本窗口最下面的数据结果区显示出生成的视图内容。
⑥可以单击工具栏中的“保存”按钮,或者在窗口上部显示数据表的窗格内单击鼠标右键,从弹出的快捷菜单中选择“保存”选项保存视图。
- 使用T-SQL语句创建视图
语法:CREATE VIEW
[ < database_name > .] [ < owner > .]
view_name [ ( column [ ,...n ] ) ]
[ WITH < view_attribute > [ ,...n ] ]
AS
select_statement
[ WITH CHECK OPTION ]
< view_attribute > ::=
{ ENCRYPTION | SCHEMABINDING |
VIEW_METADATA }
例1:建立显示年龄大于20岁的学生学号、姓名、性别等信息的S_view1
create view S_view1
as
select sno,sname,sex from s where age>20例2:创建v_score1,要求基本表来源:S,C,SC;选择的字段为:S表中的sno、sname;C表中的cname及SC表中score;要求查询的数据为学号为20030001的学生的考试成绩。
Use s
create view v_score1
As
Select s.sno,s.sname,c.cname,sc.score
From s,c,sc
Where s.sno=sc.sno and c.cno=sc.cno and sno=“20030001”在查询分析器中执行上面的程序,会生成视图v_score1。为了查看视图中的数据,在查询分析器中输入语句:select * from v_score1。
- 使用企业管理器查看视图信息
在企业管理器左边的“树”选项卡中选择指定的SQL SERVER组,展开指定的服务器,打开要查看视图的数据库文件夹,选择数据库文件夹下的“视图”目录,在右边窗格中回列出当前数据库中的所有视图。
①若要查看视图的基本信息,右键单击要查看的视图,在弹出的快捷菜单中选择“属性”选项,打开视图属性对话框;
②若要查看视图的相关性信息,右键单击要查看的视图,在弹出的快捷菜单中依次选择“所有任务”│“显示相关性”选项,打开视图相关性对话框。
③若要查看视图的输出数据,可以在企业管理器中,右键单击要查看的视图,在弹出的快捷菜单中依次选择“打开视图”│“返回所有行”,在企业管理器中就会显示该视图的输出数据。
- 使用T-SQL语句查看视图信息
a. sp_help 数据库对象名称
报告有关数据库对象(sysobjects 表中列出的任何对象)、用户定义数据类型或 Microsoft® SQL Server™ 所提供的数据类型的信息
b. sp_helptext 视图(触发器、存储过程)
显示规则、默认值、未加密的存储过程、用户定义函数、触发器或视图的文本。
c. sp_depends 数据库对象名称
显示有关数据库对象相关性的信息(例如,依赖表或视图的视图和过程,以及视图或过程所依赖的表和视图)
- 使用企业管理器删除视图
在企业管理器打开要查看视图的数据库文件夹,选择数据库文件夹下的“视图”目录,,右键单击要删除的视图,在快捷菜单中选择“删除”命令,打开“出去对象”对话框
- 使用T-SQL语句删除视图
DROP VIEW {view_name} [,…n]
删除视图时,将从sysobjects、syscolumns、syscomments、sysdepends和sysprotects系统表中删除视图的定义及其他有关视图的信息。还将删除视图的所有权限。已删除的表上的任何视图必须通过使用DROP VIEW显示删除
- 使用视图
使用视图插入表数据
例:通过视图v_s向学生表插入一行数据
Insert into v_s
Values (‘20050009’,’李华’,19,‘男’)
使用视图修改表数据
例:update v_s
Set sex=’女’
Where sno=’20040001’
使用视图删除表数据
例:delete v_s
Where sno=’20040001’
三、实验习题:
完成书上P130 3.15
实验五 索引的创建与使用
一、实验目的
- 了解索引的概念、优点及分类
- 掌握在企业管理器中创建、修改和删除索引的操作
- 掌握使用T-SQL语句创建、修改和删除索引的操作
二、实验内容
(一)索引的概念:
数据库中的索引是一个列表,在这个列表中包含了某个表中一列或者若干列值的集合,以及这些值的记录在数据表中的存储位置的物理地址。
索引的优点:
①可以大大加快数据检索速度。
②通过创建唯一索引,可以保证数据记录的唯一性。
③使用ORDER BY和GROUP BY子句进行检索数据时,可以显著减少查询中分组和排序的时间。
④使用索引可以在检索数据的过程中使用优化隐藏器,提高系统性能。
⑤可以加速表与表之间的连接,这一点在实现数据的参照完整性方面有特别的意义。
索引的分类:
1.聚集索引和非聚集索引
2.复合索引
3.唯一索引
(二)在企业管理器中创建索引
在企业管理器中,展开指定的服务器和数据库,右击要创建索引的表,从弹出的快捷菜单中依次选择“所有任务|管理索引”选项。在出现的管理索引对话框中,可以选择要处理的数据库和表,然后单击“新建”按钮,出现“新建索引”对话框。在“索引名称”文本框中输入新建索引的名称,在下面的复选框中选择用于创建索引的字段。可以设定索引的属性,例如是否聚集、是否唯一,还可以建立复合索引,指定填充度属性,在选中字段后,可设置“排序次序”属性。最后单击“确定”按钮,即可生成新的索引。
(三)使用T-SQL语句创建索引
语法:CREATE [UNIQUE] [CLUSTERED│NONCLUSTERED]INDEX index_name ON {table│view} (column [ASC│DESC] [,…n])
例1:为表jbxx创建一个非聚集索引,索引字段为employee_name,索引名为i_employeename
create index i_employeename on jbxx(employee_name)例2:新建一个表,名称为temp,为此表创建一个惟一聚集索引,索引字段为temp_number,索引名为i_temp_number。
use student
Create table t_temp
(temp_number int,
temp_name char(10),
temp_age int)
create unique clustered index i_temp_number
on t_temp(temp_number)例3:为表s创建一个复合索引,使用sex和birthday字段。
Use student
Create index i_s on s(sex,birthday)(四)使用企业管理器查看、修改和删除索引的操作
在企业管理器中,展开指定的服务器和数据库,右击要创建索引的表,从弹出的快捷菜单中依次选择“所有任务|管理索引”选项,在出现的管理索引对话框中,选择要查看或修改的索引,单击“编辑”按钮,出现“编辑现有索引”对话框。在该对话框中,可以修改索引的大部分设置,还可以直接修改其SQL脚本,只需单击“编辑SQL”按钮,即可出现“编辑Transact_SQl脚本”对话框,在此可以编辑、分析、执行索引的Transact_SQl脚本。
要在企业管理器中修改索引的名称,需要在表的“属性”对话框中进行。在企业管理器中,右击要修改名称的表,从弹出的快捷菜单中选择“设计表”选项,在打开的设计表的窗口中,打开表的“属性”对话框,选择“索引/键”选项卡,在此对话框中,先选定要修改索引名称的索引,然后直接在“索引名”文本框中输入心得索引名称替换原来的索引名称。
要删除索引,可以在“管理索引”对话框中或表的“属性”对话框中,选择要删除的索引,单击“删除”按钮,即可删除索引。
(五)使用T_SQL查看、修改和删除索引的操作
使用系统存储过程查看索引信息,语法如下:
sp_helpindex [@objname=] ‘name’
例1:查看jbxx表的索引信息
sp_helpindex jbxx使用系统存储过程修改索引名称,语法如下:
sp_rename[@objname=] ‘object_name’,[@newname=] ‘new_name’
[,[@objtype=] ‘object_type’]
例2:将s表中的索引i_s的名称改为i_s_sexandbirth
use student
sp_rename ‘s.i_s’,’i_s_ sexandbirth’,’index’删除索引句法:
drop index ‘table.index│view.index’[,…n]
例3:删除表s中的索引i_s_sexandbirth
drop index s. i_s_sexandbirth三、实验习题
为建立的student数据库中的各个表建立索引。
实验六 存储过程的创建与使用
一、实验目的
- 了解存储过程的概念
- 了解使用存储过程的特点及用途
- 掌握创建存储过程的方法
- 掌握执行存储过程的方法
- 了解查看、修改和删除存储过程的方法
二、实验内容
(一)存储过程的概念
SQL Server的存储过程类似于编程语言中的过程。在使用Transact-SQL语言编程的过程中,我们可以将某些需要多次调用的实现某个特定任务的代码段编写成一个过程,将其保存在数据库中,并由SQL Server服务器通过过程名来调用它们,这些过程就叫做存储过程。
存储过程在创建时就被编译和优化,调用一次以后,相关信息就保存在内存中,下次调用时可以直接执行。
(二)存储过程的优点及分类
存储过程的优点 :
- 实现了模块化编程。
- 存储过程具有对数据库立即访问的功能。
- 使用存储过程可以加快程序的运行速度。
- 使用存储过程可以减少网络流量。
- 使用存储过程可以提高数据库的安全性。
存储过程的分类
- 系统存储过程 :系统自动创建,主要存储在master数据库中,一般以sp_为前缀。
- 用户自定义存储过程 :由用户创建并能完成某一特定功能的存储过程。
(三)建立存储过程的方法
使用企业管理器创建存储过程:
在SQL Server企业管理器中,选择指定的服务器和数据库,右击要创建存储过程的数据库,在弹出的快捷菜单中依次选择“新建|存储过程…”选项。在弹出的“新建存储过程”对话框中的文本框中输入创建存储过程的T-SQL语句。
例1:创建一个名为StuInfo的存储过程,完成的功能是在s表中查询200501班的学生的学号、姓名、性别、出生日期的内容。输入代码如下:
CREATE PROCEDURE StuInfo
AS
SELECT SNO AS 学号,
SNAME AS 姓名,
SSEX AS 性别,
SAGE AS 年龄
FROM S
WHERE LEFT(SNO,6)=’200501’输入完毕单击“检查语法”按钮,进行语法检查,检查成功,系统弹出提示信息框,单击“确定”,保存该存储过程,并关闭该对话框。
使用 T-SQL创建存储过程
使用Transact-SQL语句中的CREATE PROCEDURE命令创建存储过程。语法如下:
CREATE PROC[EDURE] procedure-name[;number]
[{@parameter data_type}
[varying][=default][outpur]
][,…n]
WITH
{RECOMPILE│ENCRYPTION│RECOMPILE,ENCRYPTION}]
[FOR REPLICATION]
AS sql_statement […n]
说明:
- procedure-name:存储过程的名称,必须唯一且符合标识符命名规则。
- @parameter:过程中的参数,在CREATE PROCEDURE语句中可以申明一个或多个参数。
- data_type:用于指定参数的数据类型。
- AS:用于指定该存储过程要执行的操作。
例2:创建存储过程StuScoreInfo,完成的功能是在表s,c和sc中查询以下字段:班级、学号、姓名、性别、课程名称、考试分数。
程序清单:
打开student数据库
use student
--查询是否已存在此存储过程,如果存在,就删除它
if exists (select name from sysobjects
where name =’StuScoreInfo’ and type= ‘P’)
drop procedure StuScoreInfo
go
--创建存储过程
creat proceure StuScoreInfo
as
select 班级=substring(s.sno,1,len(s.sno)-2),
s.sno as 学号,
sname as 姓名,
sex as 性别,
c.cname as 课程名称,
sc.score as 考试分数
from s,c,sc
where s.sno=sc.sno and c.cno=sc.cno例3:创建一个带有参数的存储过程stu_info,该存储过程根据传入的学生编号,在t_student中查询此学生的信息。
程序清单:
--删除已存在的存储过程
use student
if exists (select name from sysobjects
where name = ‘stu_info’ and type =’P’)
drop procedure stu_info
go
--创建存储过程
use student
go
create procedure stu_info
@sno varchar(8)
as
select 班级=substring(s.sno,1,len(s.sno)-2),
s.sno as 学号,
sname as 姓名,
sex as 性别,
birthday as 出生日期
polity as zhengzhi面貌
from s
where sno=@sno(四)执行存储过程的方法
存储过程创建成功后,保存在数据库中。在SQL Server中可以使用EXECUTE命令来直接执行存储过程。语法如下:
[[EXEC[UTE]]
{
[@RETURN_STATUS=]
{procedure_name[;number]│@procedure_name_var}
[[@parameter=]{value│@variable[OUTPUT]│[DEFAULT]}
[,…n]
[WITH RECOMPILE]
说明:
- EXECUTE:执行存储过程的命令关键字,若此语句是批处理中的第一条语句,可以省略此关键字。
- @RETURN_STATUS:是一个可选的整型变量,保存存储过程的返回状态。这个变量在使用前,必须在批处理、存储过程或函数中申明过。
- procedure_name:指定执行的存储过程名称。
- @procedure_name_var:局部定义变量名,代表存储过程名称。
- @parameter:在创建存储过程时定义的过程参数。调用时向存储过程所传递的参数值由value参数或@varible变量提供,或者使用DEFAULT关键字指定使用该参数的默认值,OUTPUT参数说明指定参数为返回参数。
例1:执行前面例1中创建的StuInfo存储过程。
Use student
Exec StuInfo /*或者直接写存储过程的名称StuInfo*/注意:如果省略Exec关键字,则存储过程必须是批处理中的第一条语句,否则会出错。
例2:执行前面例2中创建的StuScoreInfo存储过程。
Use student
Exec StuScoreInfo例3:执行前面例3中创建的Stu_Info存储过程,该存储过程有一个输入参数“学号”,在执行时要传入一个学号值。
Use student
Exec Stu_Info ‘20050001’或:
Use student
Exec Stu_Info @sno=‘20050001’(五)查看存储过程
-
- 使用企业管理器查看用户创建的存储过程:
在企业管理器中,选择指定的服务器和数据库,单击“存储过程”文件夹,在右边的页框中右击要查看的存储过程,在弹出的快捷菜单中选择“属性”选项,弹出“存储过程属性”
对话框,在此对话框中可看到存储过程的源代码。
-
- 使用系统存储过程查看用户创建的存储过程:
sp_help [[@objname=]name]
用于显示存储过程的参数及其数据类型。
sp_helptext [[@objname=]name]
用于显示存储过程的代码。
sp_depends [@objname=]’object’
用于显示和存储过程相关的数据库对象。
(六)修改存储过程
1.使用企业管理器修改存储过程
在企业管理器中,选择指定的服务器和数据库,单击“存储过程”文件夹,在右边的页框中右击要查看的存储过程,在弹出的快捷菜单中选择“属性”选项,弹出“存储过程属性”
对话框,在此对话框中可直接修改存储过程的代码。
2.使用T_SQl修改存储过程
ALTER PROC[EDURE] procedure-name[;number]
[{@parameter data_type}
[varying][=default][outpur]][,…n]
WITH
{RECOMPILE│ENCRYPTION│RECOMPILE,ENCRYPTION}]
[FOR REPLICATION]
AS sql_statement […n]
例1:修改前面创建的stu_info存储过程,使之完成以下功能:根据传入的学号,在表s,c,sc中查询此学生的班级、姓名、性别、考试课程名称和考试分数。
Use student
Alter procedure stu_info
@sno varchar(10)
as
select班级=substring(s.sno,1,len(s.sno)-2),
sname as 姓名,
sex as 性别,
c.cname as 课程名称,
score as 考试成绩
from s,c,sc
where s.sno=@sno and s.sno=sc.sno and c.cno=sc.cno
exec stu_info ‘20050101’(七)重命名存储过程
1.使用企业管理器修改存储过程
在企业管理器中,右击要操作的存储过程,在弹出的快捷菜单中选择“重命名”选项。
2.使用T_SQl修改存储过程
sp_rename 原存储过程名称,新存储过程名称
(八)删除存储过程
1.使用企业管理器修改存储过程
在企业管理器中,右击要操作的存储过程,在弹出的快捷菜单中选择“删除”选项。
2.使用T_SQl修改存储过程
drop procedure {procedure} [,…n]
三、实验习题
1.创建一个无参存储过程,返回200502班的学生信息。
2.创建一个带参数的存储过程,输入参数为课程名称,查询有哪些班级的哪些学生参加了这门课程的考试及学生的考试成绩。
实验七 触发器的创建与使用
一、实验目的
- 了解触发器和一般存储过程的主要区别
- 了解使用触发器的优点
- 掌握创建触发器的方法
- 掌握查看触发器信息的方法
- 了解删除触发器的方法
二、实验内容
- 触发器的概念
触发器是一种特殊类型的存储过程,它不同于前面介绍过的一般的存储过程。一般的存储过程通过存储过程名称被直接调用,而触发器主要是通过事件进行触发而被执行触发器是一个功能强大的工具,它与表格紧密相连,在表中数据发生变化时自动强制执行。触发器可以用于SQL Server约束、默认值和规则的完整性检查,还可以完成难以用普通约束实现的复杂功能。
- 触发器的优点
①触发器是自动的执行的。当对表中的数据做了任何修改之后立即被激活。
②触发器可以通过数据库中的相关表进行层叠更改。
③触发器可以强制限制。
- 触发器的类型
①AFTER触发器:这种类型的触发器将在数据变动完成后才被触发,AFTER触发器只能在表上定义。在同一个数据表中可以创建多个AFTER触发器。
②INSTEAD OF触发器:SQL Server 2005新增功能。这种类型的触发器将在数据变动以前被触发,并取代变动数据的操作,而去执行触发器定义的操作。INSTEAD OF触发器可以在表或视图上定义。在表或视图上,每个INSERT、UPDATE和DELETE语句最多可以定义一个INSTEAD OF触发器。
- 触发器的创建
1.使用企业管理器创建:
在企业管理器中,展开指定的服务器和数据库,右击某个表,从弹出的快捷菜单中依次选择“所有任务|管理触发器”选项,会出现触发器属性对话框。在该对话框的“名称”文本框中选择“新建”,然后在文本框中输入创建触发器的文本。
当创建一个触发器时必须指定以下几项内容:
- 触发器的名称
- 在其定义触发器的表
- 触发器将何时激发
- 执行触发操作的编程语句
例如:创建一个INSERT触发器,当在表s中插入一条新记录时,触发该触发器,并给出“你插入了一条新记录!”的提示信息。在文本框中输入以下文本:
CREATE TRIGGER Stu_Insert on [dbo].[s]
FOR INSERT
AS
DECLARE @msg char(30)
SET @msg=”你插入了一条新记录!”
print @msg单击“检查语法”按钮,可以检查语法是否正确。然后单击“应用”按钮,在名称下拉列表中出现新创建的Stu_Insert触发器的名称,单击“确定”按钮,即可关闭该对话框,成功创建触发器。
创建该触发器后,查看向t_student表中插入数据时此触发器所完成的功能。在查询分析器中输入以下SQL语句:
use student
go
insert into t_student
(sno,sname,sex)
values(‘20030125’,’王帆’,‘男’)执行后结果如下:
你插入了一条新记录!
(所影响的行数为1行)
2.使用T-SQL创建:_SQL创建
使用Transact-SQL语言中的CREATE TRIGGER命令可以创建触发器,其中需要指定定义触发器的基表、触发器执行的事件和触发器的所有指令。创建触发器类似创建存储过程,语法形式如下:
CREATE TRIGGER trigger-name
ON{table│view}
[WITH ENCRYPTION]
{
{{FOR│AFTER│INSTEAD OF}{[DELETE][,][INSERT][,][UPDATE]}
[WITH APPEND]
[NOT FOR REPLICATION]
AS
[{IF UPDATE(column)
[{AND│OR}UPDATE(column)]
[…N
│IF(COLUMNS_UPDATED(){bitwise_operator}updated_bitmask)
{comparison_operator}column_bitmask[..n]
}]
sql_statement […n]
}
}
说明:
- trigger -name:触发器的名称,必须唯一且符合标识符命名规则。
- AFTER:用于规定此触发器只有在触发SQL语句中指定的所有操作都已成功执行后才激发。若仅指定FOR关键字,则AFTER是默认设置。注意该类型触发器仅能在表上创建,而不能在视图上定义该触发器。
- INSTEAD OF:用于规定执行的是触发器而不是执行触发SQL语句,从而用触发器替代触发语句的操作。每个INSERT、UPDATE、DELETE语句最多可以定义一个INSTEAD OF触发器。INSTEAD OF触发器不能在WITH CHECK OPTION 的可更新视图上定义。
- {[DELETE][,][INSERT][,][UPDATE]}:用于指定在表或视图上执行哪些数据修改语句时将激活触发器的关键字。必须至少指定一个选项。
例1:创建一个AFTER触发器,要求实现以下功能:在sc表上创建一个插入、更新类型的触发器scoreCheck,当在grade字段中插入或修改考试分数后,触发该触发器,检查分数是否在0~100之间。
Use student
if exists (select name from sysobjects where name = ‘scoreCheck’ and type =’TR’)
drop trigger scoreCheck
/*创建触发器*/
creat trigger scoreCheck
on sc
for insert,update
as
if update(score)
print ‘AFTER触发器开始执行……’
begin
declare @ScoreValue real
select @ScoreValue=(select score from inserted)
if @ScoreValue>100 or @ScoreValue<0
print ‘输入的分数有误,请确认输入的考试分数!’
end创建了scoreCheck触发器之后,在查询分析器中输入以下SQL语句:
use student
print ‘在sc中插入记录时触发器执行结果:’ /*在屏幕上显示引号中内容*/
print ‘’ /*在屏幕上显示一空行*/
insert into sc
values(‘20030156’,’01’,-40) /*在屏幕上显示输入错误信息*/
update sc
set score=123
where sno=’20030101’and cno=’1’ /*在屏幕上显示输入错误信息*/例2:创建一个INSTEAD OF触发器,要求实现以下功能:在c表上创建一个删除类型的触发器NotAllowDelete,当在c表中删除记录时,触发该触发器,显示不允许删除表中数据的提示信息。
Use student
if exists (select name from sysobjects
where name = ‘NotAllowDelete’ and type =’TR’)
drop trigger NotAllowDelete
/*创建触发器*/
creat triggerNotAllowDelete
on c
instead of delete
as
print ‘INSTEAD OF触发器开始执行……’
print ‘本表中的数据不允许被删除!不能执行删除操作!’创建了NotAllowDelete触发器后,在查询分析器中输入以下SQL语句:
use student
delete from c where cno=20030101’
/*屏幕上显示NSTEAD OF触发器开始执行……*/- 触发器的查看
1.企业管理器查看用户创建的存储过程
在企业管理器中,展开指定的服务器和数据库,选择指定的数据库和表,并右击要查看的表,从弹出的快捷菜单中选择“所有任务”│“管理触发器”选项,在“触发器属性”对话框中,从名称下拉列表框中选择要查看的触发器名称,在下面的文本框中就会显示该触发器的定义语句。
2.用系统存储过程查看用户创建的存储过程:
sp_help ‘触发器名称’
用于查看触发器的一般信息
sp_helptext ‘触发器名称’
用于查看触发器的正文信息
sp_depends ‘触发器名称’
用于查看指定触发器所引用的表或指定的表涉及到的所有触发器。
- 触发器的删除
1.删除触发器使用企业管理器删除存储过程
在企业管理器中,右击要删除的触发器,从弹出的快捷菜单中选择“所有任务”│“管理触发器”选项,在“触发器属性”对话框中,从名称下拉列表框中选择要删除的触发器,然后单击“删除”按钮,即可删除该触发器。
2.使用T_SQl删除
drop TRIGGER {触发器名} [,…n]
三、实验习题:
创建一个INSTEAD OF触发器,要求实现以下功能:在sc表上创建一个删除类型的触发器NotAllowDelete,当在sc表中删除记录时,触发该触发器,显示不允许删除表中数据的提示信息。