数据库系统概论——关系数据库标准语言SQL
//[ ]中的内容不是必须内容,是为了实现某些功能时才添加的。
1、SQL概述
SQL (Structured Query Language):结构化查询语言,是关系数据库的标准语言。
1.1 SQL的特点
- 综合统一
- 高度非过程化
- 面向集合的操作方式
- 以同一种语法结构提供多种使用方式
- 语言简洁,易学易懂
九个核心词
| SQL功能 |
动词 |
| 数据查询 |
SELECT |
| 数据定义 |
CREATE,DROP,ALTER |
| 数据操纵 |
INSERT,UPDATE,DELETE |
| 数据控制 |
GRANT,REVOKE |
2、SQL的基本概念
SQL支持关系数据库三级模式结构:
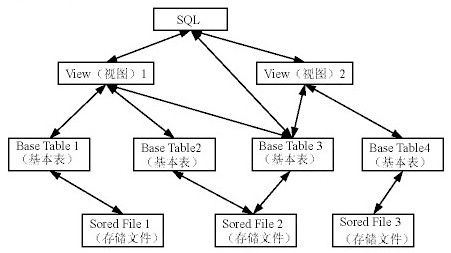
基本表
- 本身独立存在的表;
- SQL中一个关系就对应一个基本表;
- 一个(或多个)基本表对应一个存储文件;
- 一个表可以带若干索引。
视图
- 从一个或几个基本表导出的表;
- 数据库中只存放视图的定义而不存放视图对应的数据;
- 视图是一个虚表;
- 用户可以在视图上再定义视图。
3、数据定义
SQL的数据定义功能:模式定义、表定义、视图和索引的定义。
| 操作对象 |
操作方式 |
||
| 创建 |
删除 |
修改 |
|
| 模式 |
CREATE SCHEMA |
DROP SCHEMA |
|
| 表 |
CREATE TABLE |
DROP TABLE |
ALTER TABLE |
| 视图 |
CREATE VIEW |
DROP VIEW |
|
| 索引 |
CREATE INDEX |
DROP INDEX |
ALTER INDEX |
3.1模式的定义与删除
1.定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名> ;说明:
- 若没有指定模式名,那么<模式名>隐含为<用户名>。
- 在CREATE SCHEMA中可以接受CREATE TABLE,CREATE VIEW和GRANT子句。
- 执行创建模式语句必须拥有DBA(数据库管理员)权限,或者DBA授予在CREATE SCHEMA的权限。
2.删除模式
DROP SCHEMA <模式名> ; 说明:
- CASCADE(级联)删除模式的同时把该模式中所有的数据库对象全部删除。
- RESTRICT(限制)如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行。当该模式中没有任何下属的对象时才能执行。
3.2基本表的定义、删除与修改
1.定义基本表
CREATE TABLE <表名>(
<列名> <数据类型> [<列级完整性约束条件>],
……
);说明:
- 如果完整性约束条件涉及到该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级。
2.数据类型
SQL 数据类型 (w3school.com.cn)
3.修改基本表
ALTER TABLE <表名>
[ ADD[COLUMN] <新列名> <数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN ] <列名> [CASCADE |RESTRICT]]
[DROP CONSTRAINT<完整性约束名>[RESTRICT|CASCADE]
[ALTER COLUMN <列名> <数据类型>];说明:
- <表名>是要修改的基本表。
- ADD子句用于增加新列、新的列级完整性约束条件和新的表级完整性约束条件。
- DROP COLUMN子句用于删除表中的列。(如果指定了CASCADE短语,则自动删除引用该列的其他对象。如果指定了RESTRICT短语,则如果该列被其他对象引用,关系数据库管理系统将拒绝删除该列)
- DROP CONSTRAINT子句用于删除指定的完整性约束条件。
- ALTER COLUMN子句用于修改原有的列定义,包括修改列名和数据类型。
4.删除基本表
DROP TABLE <表名> [CASCADE |RESTRICT]3.3索引的建立和删除
1.建立索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名> (<列名>[次序]);
(ASC升序 DESC降序)UNIQUE表明此索引每一个索引值只对应唯一的数据。
CLUSTER表示要建立的索引是聚簇索引。聚簇索引是指索引顺序与表中记录的物理顺序一致。
2.删除索引
DROP INDEX <索引名>4、数据查询

(目标列表达式)函数(列名);表达式运算符号列名;‘字符串’;列名 想在表中显示的名字。
- (DISTINCT) 去掉表中重复的列名;
- (ORDER BY) 可以按一个或者多个属性列排列。ASC——升序;DESC——降序;作用于实表;
- (GROUP BY)按指定的一列或多列分组;作用于实表;
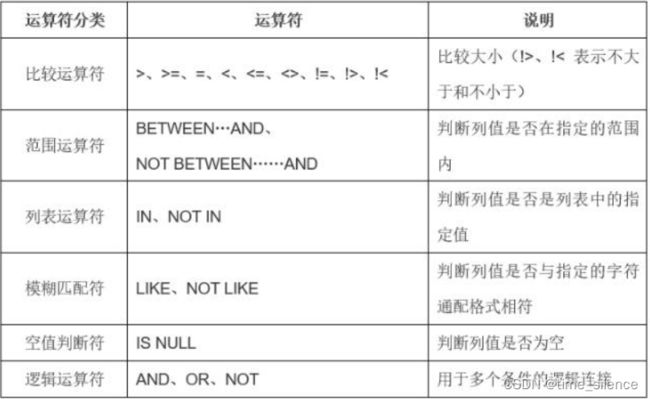
- (WHERE)常用的查询条件:
 例:
例:
SELECT Sname,Ssex FROM Student WHERE Sdept IN('IS','MA','CS');
SELECT Sname,Sno,Ssex FROM Student WHERE Sname LlKE '刘%';(%——任意字符,_——任意单个字符)
SELECT * FROM Course WHERE Cname LIKE 'DB\_%i_ _ ' EXCAPE '\';(换码字符)
SELECT Sno,Grade FROM SC WHERE Cno='3' ORDER BY Grade DESC;
SELECT Cno,Count(Sno) FROM SC GROUP BY Cno;4.1聚集函数
| 聚集函数 |
作用 |
| count(id) |
统计表中id个数 |
| count(distinct id) |
统计表中id个数(去重) |
| max(id) |
统计id最大值 |
| min(id) |
统计id最小值 |
| sum(id) |
统计id之和 |
| avq(id) |
统计id平均值 |
例:
SELECRT COUNT(*) FROM Student; PS:WHERE子句中是不能用聚集函数作为条件表达式的。聚函数只能用于SELECT子句和GROUP BY中的HAVING子句。
4.2连接查询
1.等值与非等值连接查询
连接查询的WHERE子句中用来连接两个表的条件称为连接谓词;‘=’——等值连接,其他运算符号称为非等值连接。
- 在等值连接中把目标列中重复的属性列去掉则为自然连接。
- 一个表与自己进行连接称为自身连接。(需起别名)
SELECT FIRST.Cno,SECOND.Cpno FROM Course FIRST,Course SECOND WHERE FIRST.Cpno = SECOND.Cno; - 左外连接:列出左边关系中所有的元组。LEFT OUT JOIN SC ON
- 右外连接:列出右边关系中所有的元组。RIGHT OUT JOIN SC ON
4.3嵌套查询
一个SELECT-FROM-WHERE语句称为一个查询块。
嵌套查询定义:是指将一个查询块嵌套另一个查询块的子句或HAVING短语条件中的查询。
- 外层查询(父查询)、内层查询(子查询);
- 子查询中不能使用ORDER BY 子句。
- 带有IN谓词的子查询(在嵌套查询中,子查询的结果往往是个集合,用IN谓词表示父查询的条件在子查询结果的集合中);
- 带有比较运算符的子查询(当能确切知道内层查询返回单值时,可用比较运算符);
- 带有ANY(SOME)或ALL谓词的子查询;
- 带有EXISTS(NOT EXISTS)谓词的子查询(存在量词∃)“true” "false"(由EXISTS引出的子查询目标列表都用*);
- 用EXISTS/NOT EXISTS实现全称量词;
- 用EXISTS/NOT EXISTS实现逻辑蕴涵。
4.4集合查询
集合操作的种类:并操作、交操作、差操作.
1.并操作UNION
2.交操作INTERSECT
3.差操作EXCEPT
4.5基于派生表的查询
子查询出现在FROM子句中,子查询可以生成临时派生表成为主查询的查询对象。
SELECT Sno, Cno
FROM SC (SELECT Sno,Avg(Grade) FROM SC GROUP BY Sno)
AS Avg_sc (avg_sno,avg_grade) -- 派生表
WHERE SC.Sno=Avg_sc.avg_sno AND SC.Grade >=Avg_sc.avg_grade;
5、数据更新
5.1插入数据
1.插入元组
INSERT INTO <表名> [(<属性列1>[……])] VALUES (<常量1>[,<常量2>]……);- INTO子句:属性列的顺序可与表中的顺序不一致,没有指定属性列的默认插入全部。
- VALUES子句:提供的值必须与INTO子句匹配,值与属性列的个数和值的类型要一致。、
2.插入子查询结果
5.2修改数据
UPDATE <表名> SET<列名>==<表达式>[,<列名> = <表达式>]…… [WHERE <条件>];- SET子句:指定修改方式,修改的时间,修改后的取值。
- WHERE子句:指定要修改的元组。
5.3删除数据
DELETE FROM<表名> [WHERE<条件>];若无WHERE,删除所有元组。
空值的处理
6、视图
1.视图的特点:
- (1)视图是虚表,是从一个或几个基本表(或视图)导出的。
- (2)只存放视图的定义,不存放视图对应的数据。
- (3)表中的数据发生变化,视图中查询出的数据也随之改变。
SQL VIEW(视图)
6.1定义视图
1.建立视图
(1)语句格式
CREATE VIEW<视图名>[ (<列名>[,<列名>]…)] AS <子查询>[WITH CHECK OPTION];- 组成视图的属性列名:全部省略或全部指定。
- RDBMS执行CREATE VIEW语句时只是把视图定义存入数据字典,并不执行其中的SELECT语句。
- 受限更新(WITH CHECK OPTION ——只更新视图中的数据)
- AS后可跟任意SELECT语句
(2)带表达式的视图——子查询中带有表达式;
(3)分组视图——子查询中带有GROUP BY;
(4)行列子集视图——从单个基本表导出,保留了主码,仅去除基本表中某些行。
2.删除视图
DROP VIEW,<视图名>[CASCADE];- 如果该视图上还导出了其他视图,使用CASCADE级联删除语句,把该视图和由它导出的所有视图一起删除。
- 删除基表时,由该基表导出的所有视图定义都必须显式地使用 DROP VIEW语句删除。
6.2查询视图
1.RDBMS实现视图查询的方法——视图消解法
- 进行有效性检查。
- 转换成等价的对基本表的查询。
- 执行修正后的查询。
(GROUP BY 可能使视图消解法出现错误)
6.3更新视图
说明:因为视图不适宜存储数据,因此对视图的更新操作将通过视图消解,转为对实际表的更新操作。为防止在更新视图时出错,定义视图时要加上WITH CHECK OPTION子句。有些视图不可更新。
end~