Python3学习笔记_INDEX(汇总)
目录
- 建议不要光看,要多动手敲代码。眼过千遭,不如手读一遍。
- python注释
- python运算符
- 比较:type()和 isinstance()
- 基本数据类型
- Number(数字)
- 数学函数
- 随机数函数
- 字符串
- 格式化输出
- 字符串内建函数
- 列表 list
- 增
- 删
- 改
- 查
- 其他内置函数
- 元组
- 字典
- 增
- 删
- 改
- 查
- 其他内置函数
- 集合 set
- 增
- 删
- 其他
- 条件控制
- 循环
- 函数
- 不定长参数
- 匿名函数
- 变量作用域
- 迭代器
- 生成器 generator
- 闭包
- 闭包定义
- 使用闭包的注意事项
- 闭包的作用
- 装饰器
- 带有参数的装饰器
- 类做装饰器
- wraps函数
- 装饰器使用场景
- 模块
- os模块
- hashlib模块
- 常用标准库
- functools模块
- 常用扩展库
- 包和__init__
- 输入输出
- 输入
- 输出
- 文件
- pickle模块
- 面向对象
- 魔法方法
- `__new__`方法
- `__init__`方法
- `__str__`方法
- `__del__`方法
- 其他方法
- 引用计数
- 继承
- 重写
- 类属性
- 实例属性
- 有关类方法、实例方法、静态方法的笔记参考了`蔷薇Nina `这位朋友的笔记
- 类方法
- 实例方法
- 实例方法中self的含义
- 静态方法
- 动态添加属性以及方法
- 解耦合
- 私有化
- property的使用
- `__slots__`的作用
- 元类
- `__metaclass__`属性
- 内建属性
- `__getattribute__`的坑
- `__getattr__`方法
- `__setattr__`方法
- 描述符
- 描述符定义
- 描述符种类及优先级
- 类属性>数据描述符
- 数据描述符>实例属性
- 实例属性>非数据描述符
- 描述符使用注意点
- 描述符使用
- 错误和异常
- 捕获多个异常
- 异常的嵌套
- 自定义异常
- 异常处理中抛出异常
- 调试
- 断言(assert)
- logging
- pdb调试
- pdb交互调试
- pdb程序里埋点
- 垃圾回收
- 代码块
- 代码块的缓存机制
- 小数据池
- 指定驻留
- 引用计数
- GC模块
- 内置方法
- pep8规则
- 进程
- 进程定义
- 创建进程
- linux专供版
- getpid、getppid
- multiprocessing
- Process
- Process 子类
- 进程池Pool
- multiprocessing.Pool常用函数
- 进程间的通信Queue
- Queue使用
- 进程池中的Queue
- shutil模块
- 线程
- 多线程
- 线程模块
- 查看线程数目
- threading 注意点
- 多线程共享全局变量
- 列表当实参传递到线程中
- 进程VS线程
- 线程同步
- 互斥锁
- 死锁
- 生产者消费者模式
- ThreadLocal
- 使用ThreadLocal
- 异步
- GIL(全局解释锁)
- 分布式进程
- 异步IO
- asyncio、async/await、aiohttp
- 网络编程
- TCP/IP协议(族)
- 端口
- IP地址
- 子网掩码
- socket
- udp 发送数据:
- udp绑定
- udp广播
- TCP
- tcp四次挥手
- TCP的2MSL问题
- TCP长连接和短连接
- 常见网络攻击案例
- TCP服务器
- TCP客户端
- 网络编程 应用
- 单全双工信息收发
- TFTP客户端
- 单进程 TCP服务器
- 多进程服务器
- 多线程服务器
- 单进程服务器,非阻塞模式
- select版 TCP服务器
- epoll版-TCP服务器
- 网络分析工具
- wireshark
- Packet Tracer
笔记中代码均可运行在Jupyter NoteBook下(实际上Jupyter-lab使用体验也很棒)。
建议不要光看,要多动手敲代码。眼过千遭,不如手读一遍。
相关笔记的jupiter运行代码已经上传,请在资源中自行下载。
#在download源代码的时候要适当选择较低的版本,因为语言的源码版本越低越能看出作者的意图
python注释
python的编码格式注释:#-*- coding: utf-8 -*-
linux书写环境变量注释:#!/usr/bin/env python3
'''python中的帮助函数:help(func_name)'''
# 例子
help(input)
# 例子结束
Help on method raw_input in module ipykernel.kernelbase:
raw_input(prompt='') method of ipykernel.ipkernel.IPythonKernel instance
Forward raw_input to frontends
Raises
------
StdinNotImplentedError if active frontend doesn't support stdin.
python运算符
#算数运算符
'''python中 / 表示浮点除法 // 向下取整除法'''
# 例子
print(3/4)
print("*"*8)# python符号也可进行算数运算
print(3//4)
# 例子结束
python中的比较运算符:>,<,>=,<=,==,!=,<>(不等于的这种表示方式会逐渐淘汰)
python逻辑运算符 and,or,not
'''
python赋值运算符:=, +=, -=,*=,/=,**= (算术运算符和=相结合的操作)
python 位运算符:&[按位与,同为1,否则为假],| [按位或,二者中一个即可]
^ [按位异或,相异为1],~[按位取反,1变0,0变1],
<<[左移,乘2],>>[右移,除以2]
进制转换 :转二进制:bin(),八进制:oct(),16进制:hex(),转10进制:int()
'''
#例子
a=3
print(a<<1)
b=4
print(b>>1)
# 例子结束
# python 成员运算符:in,not in
# python身份运算符:is, is not
'''is和 == 的区别:is用于判断两个变量引用是否为同一个(即id是否相同),==用于判断变量值是否相等'''
# 例子
x=y=[1, 2, 3]
z=[1, 2, 3]
print(x is y, id(x),id(y), x==y)
print(x is z, id(x), id(z), x==z)
6
2
True 140646103441800 140646103441800 True
False 140646103441800 140646103444296 True
'''
对于python中a,b = b,a的换值方法的解析
a, b = b, a操作是将a,b的地址互换
关键在于ROT_TWO的地址互换
'''
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
from dis import dis
def demo(a, b):
print(a,b)
a, b = b, a
print('new: ', a,b)
a, b = 2, 3
demo(a,b)
dis(demo)
2 3
new: 3 2
10 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 LOAD_FAST 1 (b)
6 CALL_FUNCTION 2
8 POP_TOP
11 10 LOAD_FAST 1 (b)
12 LOAD_FAST 0 (a)
14 ROT_TWO
16 STORE_FAST 0 (a)
18 STORE_FAST 1 (b)
12 20 LOAD_GLOBAL 0 (print)
22 LOAD_CONST 1 ('new: ')
24 LOAD_FAST 0 (a)
26 LOAD_FAST 1 (b)
28 CALL_FUNCTION 3
30 POP_TOP
32 LOAD_CONST 0 (None)
34 RETURN_VALUE
比较:type()和 isinstance()
'''type()和isinstance()区别
type()不认为子类是父类的一种类型,而isinstance()认为是
isinstance()也用来判断是不是可迭代对象'''
#l例子
class A:
pass
class B(A):
pass
print("isinstance(, A(),A) is ", isinstance(A(),A))
print("type(A())==A is ",type(A())==A)
print("isinstance(B(),A) is ", isinstance(B(),A))
print("type(B())==A is ",type(B())==A)
isinstance(, A(),A) is True
type(A())==A is True
isinstance(B(),A) is True
type(B())==A is False
基本数据类型
# 变量可使用del语句删除
# 例子
vara=1
print(vara)
del vara
print(vara) # 删除后打印会报错
1
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
4 print(vara)
5 del vara
----> 6 print(vara) # 删除后打印会报错
NameError: name 'vara' is not defined
'''
六个标准数据类型:
Number(数字),String(字符串),List(列表),Tuple(元组),Set(集合),Dictionary(字典)
不可变数据:Number,String,Tuple
可变数据:list,dict,set
'''
Number(数字)
int、float、bool、complex(复数)
#例子
complex(1,3)
(1+3j)
数学函数
'''ads(x)[绝对值],ceil(x)[向上取整],
cmp(x,y)[比较xy,x>y=1,xy)-(x]
exp(x)[e的x次方],fabs(x)[浮点绝对值],floor(x)[向下取整],
pow(x,y)[x的y次],round(x,y)[对x四舍五入,y表示精确度]
'''
# abs()与fabs()比较
from math import fabs
print(abs(-5))
print(fabs(-5))
# round(x,y)例子
print(round(5.6482133, 5))
5
5.0
5.64821
随机数函数
'''
choice(seq)[从序列seq中随机挑一个](在模块random中)
randrange([start,]stop[,step])
random()[随机在(0-1中生成)]
seed([x])[改变随机数生成器种子]
shuffle(lst)[随机排序一个序列]
uniform(x,y)[在(x-y中随机生成一个浮点数)]
'''
# choice()例子
import random
print("choice()例子:", random.choice(range(10)))
# randrange()使用例子
print("randrange()例子:", random.randrange(1,90,1)) # 随机数范围为1-90,步长为1
# seed()不常使用
# shuffle()例子
var_shuffle_ =[1, 2, 3, 4, 5]
random.shuffle(var_shuffle_)
print(var_shuffle_)
# uniform()例子
print("uniform例子:", random.uniform(1, 45))
choice()例子: 0
randrange()例子: 79
[3, 4, 5, 2, 1]
uniform例子: 4.053759455798719
from math import pi
print(pi)
3.141592653589793
字符串
'''
原始字符串:r/R
'''
#例子
a = r'test\n'
print('test\n')
print(a)
test
test\n
格式化输出
# 格式化输出可以用% 和"str".format()
# "str".format()中在字符串"str"中用{[var]}表示变量,[var]为可选的变量名
# 这里注意:{}中无变量名,切未指示位置的时候,无变量名的参数应在有变量名的参数的位置前面
# 在{}中表示数字时用':'(冒号),表示数字格式化
# format()还可以在"str"的{}中通过指定位置来输出
# 在format中对大括号的转义用{},例子{{}}
'''
%c[字符,或ascii码]
'''
print("这是 %s" %('用%格式化输出例子'))
# format()格式化输出例子
print("这是{name}{}".format('有无变量名混用的例子', name='format'))
print("这是{0}而不用{1}的例子,{1}{0}".format("通过位置输出", "变量名输出"))
from math import pi
print("这是数字格式化例子:输出保留两位小数的pi{:.2f}, 不设置保留位数的pi={ppi}".format(pi,ppi=pi))
print("format对{{}}的转义例子输出".format())
这是 用%格式化输出例子
这是format有无变量名混用的例子
这是通过位置输出而不用变量名输出的例子,变量名输出通过位置输出
这是数字格式化例子:输出保留两位小数的pi3.14, 不设置保留位数的pi=3.141592653589793
format对{}的转义例子输出
字符串内建函数
'''
capitalize()[首字母大写],
center(width,fillchar)[在宽度为width的输出空间中居中显示fillchar字符串],
count(str,beg=0,end=len(string))[统计str在string中出现的次数,
若beg或end指定,则返回指定范围的次数],
bytes.decode(encoding="utf-8",errors="strict")[指定解码,
用的是bytes对象的方法]
encode(encoding="utf-8",errors='strict')[指定编码方式]
查找:find,index,rfind,rindex(相同都返回下标,不同,-1,异常)
replace(原,现):替换
split(切割符) :切割
capitalize:单个首字母大写
title:全部首字母大写
endswith(str):判断结尾
startswith(str):判断开头
rjust(int),ljust(int),center(int):在int个字符中右左中对齐
strip():去掉str两边空格,\n
partition(str):以左起第一个str分割为元组
split(str):以str分割
isalpha():是否纯字母
isalnum():是否数字字母组合
isdigit():是否纯数字
str.join(a,b):以str连接a,b
'''
列表 list
'''
列表切片:list[start:end [:step(默认为1)]]
'''
# 列表生成器
[x for x in range(0,10,2)]
[0, 2, 4, 6, 8]
增
''' list.
append():追加(整体添加)
insert(位置,内容):添加
extend(list):追加list(合并list)
'''
#例子
A=[12,34,55]
B=['aa','bb']
print('this is A:',A,'\nthis is B:',B)
A.append(666)
print('this is A.append(666)',A)
B.insert(1,'this is 1')
print('this is B.insert:',B)
A.extend(B)
print('A.extend(B)',A)
this is A: [12, 34, 55]
this is B: ['aa', 'bb']
this is A.append(666) [12, 34, 55, 666]
this is B.insert: ['aa', 'this is 1', 'bb']
A.extend(B) [12, 34, 55, 666, 'aa', 'this is 1', 'bb']
删
''' list.
pop():默认最后一个
remove(str):删除str内容
clear():清空列表
del list[position]:删除列表中的某个元素
'''
#例子
A=[11,22,33,44]
print(A)
print('*'*8)
print("list.pop()操作")
#A.pop()会返回弹出值
print(A.pop())
print(A)
print('*'*8)
print("del list[position]操作")
del A[1]
print(A)
print('*'*8)
print("list.remove()操作")
A.remove(11)
print(A)
print('*'*8)
print("list.clear()操作")
A.clear()
print(A)
[11, 22, 33, 44]
********
list.pop()操作
44
[11, 22, 33]
********
del list[position]操作
[11, 33]
********
list.remove()操作
[33]
********
list.clear()操作
[]
改
'''
直接用下标进行修改
'''
#例子
A=[11,22,33]
print(A)
print('*'*8)
A[0]="changed"
print(A)
[11, 22, 33]
********
['changed', 22, 33]
查
'''
in:布尔值
list.index:下标,异常
'''
#例子
A=[11,22,33]
print(11 in A)
print(A.index(1234))
True
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
7 A=[11,22,33]
8 print(11 in A)
----> 9 print(A.index(1234))
ValueError: 1234 is not in list
其他内置函数
''' list.
count(obj) 统计obj出现次数
reverse() 反向排列
sort([key=None,reverse=False]) 排序,key表示排序依据,
reverse表示反向,默认False
copy() 复制列表
'''
'''
len(list):list长度
max(list):list中的最大值
min(list):list中的最小值
list(seq):将元组转换为list
'''
A = [1, 2, 3, 4]
B = (22, 33)
print("对A的操作:len(A): {lena}\tmax(A):{maxa}\tmin(A):{mina}\n".format(lena=len(A), maxa=max(A), mina=min(A)))
print("对B的操作:list(B):{listb}".format(listb=list(B)))
对A的操作:len(A): 4 max(A):4 min(A):1
对B的操作:list(B):[22, 33]
元组
'''
不可更改的列表,死的
扩展通过新建一个组合元组
tuple(list):将list转换为tuple
'''
字典
增
'''
dict['key']='value'
'''
删
'''
del dict["key"] 删除键名为"key"的键值对
pop(key,[default]) 删除字典给定键的键值对,返回被删除的值,key必须给出
popitem() 随机删除并返回一对键值对(一般删除的是末尾的键值对)
'''
改
'''
键值对赋值
dict.update(dict2) 把字典dict2中的键值对更新到dict中
'''
dict_a = {'name':'value'}
dict_b = {'name':'18'}
print(dict_a)
dict_a.update(dict_b)
print(dict_a)
{'name': 'value'}
{'name': '18'}
查
'''
dict.get(key)
in
'''
其他内置函数
'''
len(dict):键值对个数
dict.keys():dict的所有键
dict.values():dict的所有值
dict.
clear() 清空字典
copy() 浅复制
fromkeys() 创建新字典
ietms() 以列表返回可遍历的键值对
'''
#例子
D={'a':'111','b':222}
print(D)
print(D.items())
D.clear()
print(D)
{'a': '111', 'b': 222}
dict_items([('a', '111'), ('b', 222)])
{}
集合 set
'''
集合中没有重复值,(集合会自动去重)
list、tuple可以有重复值,不会自动去重
字典中,当键重复时,会保留最后的那个,其他的去重(不论值是否相同)
强制类型转换得到的变量恢复到原类型用eval()
'''
增
'''set.
add() 添加元素
'''
删
'''set.
pop() 随机移除
remove() 移除指定元素,当元素不存在会报错
discard() 删除指定元素, 当元素不存在不会报错
clear() 清空
'''
其他
'''set.
copy() 拷贝
difference() 返回多个集合的差集
difference_update() 移除集合中的元素,该元素在指定的集合也存在。
intersection() 返回交集
isdisjoint() 布尔判断集合间是否包含相同元素
issubset() 子集判断
union() 并集
'''
条件控制
'''
if exp:
pass
elif exp1:
pass
else:
pass
if的各种真假判断
"",None,[],{},数字0,都表示假
'''
循环
'''
while exp:
pass
while exp:
pass
else:
pass
for var in seq: # 这里seq必须是可迭代数据
pass
break
continue
'''
'''
for循环中删除元素的坑:在循环的过程中删除元素可能出现漏删的情况。
'''
# for循环例子
a = [1,2,3,4,5,6,7]
for i in a:
print(i, end=',')
if i == 2 or i == 3:
a.remove(i)
print("\na = {0}".format(a))
#这时输出分别为1,2,4,5,6,7,和a = [1,3,4,5,6,7]
#从这里的结果可以看出在循环中漏删了3
1,2,4,5,6,7,
a = [1, 3, 4, 5, 6, 7]
'''
这里可以使用“缓存”的方法
用另一个变量临时存储要删除的变量,待循环结束后在删除
'''
# for循环解决例子
a = [1,2,3,4,5,6,7]
b = []
for i in a:
print(i, end = ",")
if i == 2 or i == 3:
b.append(i)
for i in b:
a.remove(i)
print("\na = {0}".format(a))
#此时得到的a的结果就是完全删除的结果 a = [1,4,5,6,7]
1,2,3,4,5,6,7,
a = [1, 4, 5, 6, 7]
函数
在一个Python文件中,定义重名的函数不会报错,但是会使用最后的一个函数
def funcName(*args,**kwargs):
pass
不定长参数
'''
*args:长度不限,来着不拒,输出的是元组形式
**kwargs:长度不限,输入必须是key=value的形式,否则无法传入;
输出为字典形式
注意:不定长参数应放在参数列表最后,否则会吞参数
'''
#*args,**kwargs例子
def funcDemo(a,*args,**kwargs):
print(a)
print(args)
print(kwargs)
funcDemo(111,1,2,3,4,name='name',age='age')
111
(1, 2, 3, 4)
{'name': 'name', 'age': 'age'}
'''
对不定长参数传入的拆包
元组传入加*:*tuple
字典传入加**:**dict
如果不拆包直接传入,会被*args吞并,不会区分传值
'''
#拆包例子
A=(1,2,3,4)
B={'name':'name','age':'age'}
def func(*args,**kwargs):
print(args)
print(kwargs)
func(A,B)
print("*"*8)
func(*A,**B)
((1, 2, 3, 4), {'name': 'name', 'age': 'age'})
{}
********
(1, 2, 3, 4)
{'name': 'name', 'age': 'age'}
匿名函数
'''
lambda [arg1,[arg2,arg3...]]:expression
'''
# lambda简单例子
f = lambda x,y:x+y
print(f(2,3))
5
变量作用域
'''
L(Local) 局部作用域
E(Enclosing) 闭包函数外的函数中
G(Global) 全局作用域
B(Built-in) 内建作用域
变量查找顺序:LEGB
'''
# global和nonlocal
'''
局部内改全局,变量前加global
内部修改外部函数变量,变量前加nonlocal
'''
#nonlocal 例子
def outer():
num=10
print('this is raw num:',num)
def inner():
nonlocal num # 声明外部变量
num='change'
print('this is changed num:',num)
inner()
print('this is num:',num)
outer()
this is raw num: 10
this is changed num: change
this is num: change
迭代器
'''
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
可迭代对象:list,tuple,dict,set,str,生成器(generator,带yield的generator function)
# 这里也可说是Iterable
判断是否是可迭代对象:isinstance:
1
from collections.abc import Iterable
isinstance(flag, Iterable)
2
或者是使用for循环来判断
iter()函数用来将Iterable转换为Iterator
'''
# isinstance 迭代对象判断 例子
# 导入Iterable
from collections.abc import Iterable
# 判断是否可迭代
isinstance('flag', Iterable) # 会输出True
# 例子释义:isinstance是判断变量1(代码中的''flag)是否为变量2(Iterable)类的实例或是其子类的实例
# isinstance 例子
class A(object):
def __str__(self):
return 'this is class A'
class B(A):
def __str__(self):
str = 'this is class B, and is son class of A'
return str
b = B()
a = isinstance(b,B) # 判断b是否为B的实例
c = isinstance(b,A) # 判断b是否为A的实例
print(a,c) # 输出显示b是B的实例,b是A的子类的实例
print("*"*8)
# Iterable 和Iterator判断
from collections.abc import Iterator
a = isinstance('str', Iterator) # False
c = isinstance(iter('str'), Iterator) # True
print(a,c)
True True
********
False True
生成器 generator
对于要创建的数据(尤其是Iterable数据及其范类),不是一下全部创建,而是在程序运行中逐步生成。可以极大的节约内存。
'''
可以用next()获取生成器的下一个返回值
但是这里next()执行完最后一次还调用会报错
加了yield参数的函数就是一个生成器
对生成器函数不可用普通函数的调用方法,生成器函数返回的是一个对象。
此时需要用一个变量来指向这个生成器。
此时用next(x)来执行生成器时,
会在yield处停止,并返回yield后的参数,
这个返回的参数就是生成器生成的值,
在下一次调用生成器时,会在yield停止的地方接着执行。
next(x)和x.__next__()作用相同
一个生成器中可以有多个yield
协程多任务:运行一下,停一下
这里就可以用生成器的来实现多任务
'''
# yield function 例子 : next()输出fib数列
def fib():
a,b = 0,1
for i in range(10):
yield b
a,b = b,a+b
a = fib()
flag = 1
print('1-10的fib数列:')
while flag ==1:
try:
fib = next(a) # 这里next(generator)和a.__next__()是一样的
print(fib, end='\t')
except Exception as result:
print('\n1-10的最大fib数:', fib)
flag = 0
1-10的fib数列:
1 1 2 3 5 8 13 21 34 55
1-10的最大fib数: 55
# yield function 不用next(),使用循环输出生成器生成的值
# 一个生成任意数的斐波那契数列的函数
def fibs(num):
i = 0
a, b = 0, 1
while i<num:
yield b # 生成器核心
a,b = b, a+b
i +=1
# 这里以输出11的fib数列举例
for f in fibs(11):
print(f, end = '\t')
1 1 2 3 5 8 13 21 34 55 89
'''
x.send(value) # value必须有,可以是None,但是不可不写
'''
# x.send(value) 例子
def fib():
a,b = 0,1
for i in range(10):
temp = yield b
a,b = b,a+b
print(temp)
a = fib()
next(a)
# 这里print()的结果是None,因为生成器在yield处停止,
# 不会对temp赋值
k = a.send("yeyeye")
# 这里print()的结果是yeyeye,因为send()将这个值传入了temp
print('生成器返回的值',k)
print('1111111111')
yeyeye
生成器返回的值 1
1111111111
闭包
参考网址1(闭包):
https://blog.csdn.net/marty_fu/article/details/7679297
参考网址2(python编译与执行):
对于上一个参考网址中对for循环中的闭包问题解析的不同解释
https://blog.csdn.net/helloxiaozhe/article/details/78104975
闭包定义
'''
在一个函数内部定义一个函数,
并且内部的函数调用了外部函数的参数,
此时,内部函数和用到的参数就叫做闭包。
闭包 = 函数块+定义函数时的环境
'''
# 闭包定义例子
# 定义一个外部函数
def outer(out_num):
#在函数内部再定义一个函数,
# 并且这个函数用到了外边函数的变量,
# 那么将这个函数以及用到的一些变量称之为闭包
def inner(in_num):
sum = out_num + in_num
return sum
#这里返回的是闭包的结果
return inner
# 对outer函数中的out_num赋值为3
mid = outer(3)
print('mid的类型是:',type(mid))
print('mid的名字是:',mid.__name__)
print('此时的mid为:', mid)
# 这个6是对inner(in_num)中的in_num赋值
result = mid(6)
print('对内外均赋值后mid的类型是:',type(result))
print('对内外均赋值后的mid为:', result)
mid的类型是:
mid的名字是: inner
此时的mid为: .inner at 0x7ff6d804ce18>
对内外均赋值后mid的类型是:
对内外均赋值后的mid为: 9
使用闭包的注意事项
'''
闭包内对外部函数的局部变量进行修改:
1、要么在闭包内添加 nonlocal 声明此变量为外部局部变量
(nonlocal 声明只有python3中有,在python2中只能用法2)
2、要么外部变量为列表,字典,集合这种可扩展变量,
在闭包内部才可进行修改
方法2实际上还是由legb次序返回到外部函数环境中,所以两个方法殊途同归
'''
# 例子
def out():
a = 1
def inner():
# nonlocal a
a = a+1
return a
return inner
t = out()
t() # 这里报错
# 报错原因:python规则指定所有在赋值语句左面的变量都是局部变量
# 则在闭包inner()中,变量a在赋值符号"="的左面,被当做inner()的局部变量,但是未在inner找到a的定义
-------------------------------------------------------------------------
UnboundLocalError Traceback (most recent call last)
in
19
20 t = out()
---> 21 t() # 这里报错
22 # 报错原因:python规则指定所有在赋值语句左面的变量都是局部变量
23 # 则在闭包inner()中,变量a在赋值符号"="的左面,被当做inner()的局部变量,但是未在inner找到a的定义
in inner()
14 def inner():
15 # nonlocal a
---> 16 a = a+1
17 return a
18 return inner
UnboundLocalError: local variable 'a' referenced before assignment
# 解决方法1
def out():
a = 1
def inner():
nonlocal a
a = a+1
return a
return inner
t = out()
print('解决方法1:',t())
# 解决方法2
def out():
# 定义a为一个列表
a = [1]
def inner():
# 在执行时在inner()内未找到a的定义,但是在外部函数空间找到a[0]为list的定义
a[0]= a[0]+1
return a
return inner
t = out()
print('解决方法2:',t())
type(t())# 注意:此时输出的t的类型为list
解决方法1: 2
解决方法2: [2]
list
'''
闭包在循环体中的使用:
'''
# 错误示例
flist = []
for i in range(3):
print('for START')
print('FOO START')
def foo(x):
print('foo running')
print(x + i)
print('foo run over')
print('FOO END')
print('i is : ', i)
flist.append(foo)
print('for END')
for f in flist:
f(2) # 此时输出为4 4 4
# 原因是在执行for是遇到foo这一函数定义,只录入了foo(x)名,而没执行foo(x)的函数体
for START
FOO START
FOO END
i is : 0
for END
for START
FOO START
FOO END
i is : 1
for END
for START
FOO START
FOO END
i is : 2
for END
foo running
4
foo run over
foo running
4
foo run over
foo running
4
foo run over
'''对循环中使用闭包的正确用法'''
# 正确示例
flist = []
for i in range(3):
print('for START')
print('FOO START')
def foo(x, y=i):
print('foo running')
print(x + y)
print('foo run over')
print('FOO END')
print('i is : ',i)
flist.append(foo)
print('for END')
for f in flist:
f(2) # 此时输出为2 3 4
# 在程序执行时将foo(x,y=i)录入,此时foo中的y=i是随着for函数一起执行的,在append到flist中的元素为
# [foo(x,y=0),foo(x,y=1),foo(x,y=2)]
# 在执行foo函数体中的内容的时候会有i的不同次序值,而不是最终的i
for START
FOO START
FOO END
i is : 0
for END
for START
FOO START
FOO END
i is : 1
for END
for START
FOO START
FOO END
i is : 2
for END
foo running
2
foo run over
foo running
3
foo run over
foo running
4
foo run over
闭包的作用
'''
1、持久化编程,保持住当前的运行环境
'''
# 跳棋 例子
origin = [0, 0] # 坐标系统原点
legal_x = [0, 50] # x轴方向的合法坐标
legal_y = [0, 50] # y轴方向的合法坐标
def create(pos=origin):
def player(direction,step):
# 这里应该首先判断参数direction,step的合法性,
# 比如direction不能斜着走,step不能为负等
# 然后还要对新生成的x,y坐标的合法性进行判断处理,
# 这里主要是想介绍闭包,就不详细写了。
new_x = pos[0] + direction[0]*step
new_y = pos[1] + direction[1]*step
pos[0] = new_x
pos[1] = new_y
#注意!此处不能写成 pos = [new_x, new_y],原因在上文有说过
return pos
return player
player = create() # 创建棋子player,起点为原点
print (player([1,0],10)) # 向x轴正方向移动10步
print (player([0,1],20)) # 向y轴正方向移动20步
print (player([-1,0],10)) # 向x轴负方向移动10步
[10, 0]
[10, 20]
[0, 20]
'''
2、根据外部作用域的局部变量来得到不同的结果
这有点像一种类似配置功能的作用,我们可以修改外部的变量,
闭包根据这个变量展现出不同的功能
'''
# 这是一个根据关键字过滤文件内容的简单闭包demo
# make_filter 中的keep是关键字
# 外部函数make_filter作用是设置关键字
# 内部函数the_filter是根据关键字过滤文件内容并输出相关内容
def make_filter(keep):
def the_filter(file_name):
with open(file_name,'r', encoding='utf-8') as file:
lines = file.readlines()
filter_doc = [i for i in lines if keep in i]
return filter_doc
return the_filter
# 获取文件《闭包用途2使用文档.txt》有关"闭包"的关键字
filter = make_filter("闭包")
filter_result = filter("./Gnerate_files/闭包用途2使用文档.txt")
for f in filter_result:
print(f)
这是一个关于闭包用途的使用文档
但是我对原作者在循环中使用闭包的错误剖析有不同的见解,所以没有全部参考原作者的思路
装饰器
写代码的开放封闭原则
开放:对代码进行扩展开发
封闭:对代码已实现的功能,最好不要随意修改
语法糖:写一个函数,用@符号加在其他功能前,达到一个想要的结果
对装饰器有充分的理解要先掌握以下两点:
1、一切皆对象
2、闭包
装饰器的功能:
引入日志
函数执行时间统计
执行函数前预备处理
执行函数后清理功能
权限校验等场景
缓存
装饰器很好的实现了开放封闭原则
# 装饰器例子
def zsq(func):
print('zsq print START')
def prt():
print('prt print'.center(10,"*"))
func()
print('{}执行完毕'.format(func.__name__))
print('zsq print END')
return prt
@zsq
def f1():
print("这是一个f1函数".center(20,"*"))
def f2():
print('这是f2函数')
# test
f1()
print('*'*18)
# 这里的f2 = zsq(f2) 和上面的@zsq作用是一样的
f2 = zsq(f2) # 这里将f2()作为参数,传入zsq()中的func
f2() # 这里的f2已经不是原来的函数了,而是zsq()中封装的prt函数
# 执行顺序为(二者顺序相同,这里以f1为例):
# 对于执行顺序,建议用断点调试的方法进行观察
# 1、zsq 函数头
# 2、func = f1 赋值操作
# 3、 f1函数头
# 4、zsq 函数体第一行,这里是print('zsq print START')
# 5、 记录prt函数头标记
# 6、prt()函数后紧跟的一行此例中为print('zsq print END)
# 7、prt函数体中的第一行,这里是('prt print'.center(10,"*"))
# 8、func() 在例子中也就是f1()
# 9、prt中func()后紧跟的一行
# 依次执行,直到执行完最后一行
# f1 为函数名
# f1() 为调用f1函数,只写f1不会调用f1函数
# 这里值得注意的是python执行文件中,遇到函数会先标记,然后继续执行函数后的内容,
# 最后执行函数的函数体
zsq print START
zsq print END
prt print*
******这是一个f1函数******
f1执行完毕
******************
zsq print START
zsq print END
prt print*
这是f2函数
f2执行完毕
# 多个装饰器 例子
def zsq1(f1):
# 定义装饰器1
print("the zsq1 is RUNING")
def prt1():
print('装饰器1'.center(10, '*'))
return f1() # 回传传入的f1函数
print("the zsq1 is END")
return prt1 # 回传闭包内的函数名
def zsq2(f2):
print("the zsq2 is RUNING")
def prt2():
print('装饰器2'.center(10,'*'))
return f2()
print("the zsq2 is END")
return prt2
@zsq1
@zsq2 # 用zsq1()和zsq2()装饰test()
def test():
print('test'.center(10, '*'))
return 'hello world!'
# 测试
tmp = test()
print(tmp)
# 解释:
# python程序是顺序执行的,
# 装入顺序为取近优先,最靠近被装饰函数最先被装饰,并且函数在装饰时就已经开始运行了
# 例子中zsq2最靠近被装饰函数test(),所以test()函数先装入zsq2
# zsq2又被zsq1所装饰,所以zsq2要放入zsq1中
# 执行顺序为剥洋葱,由外向内
# 先执行zsq1中的闭包,然后是zsq2中的闭包(被装饰函数test()在zsq2函数的闭包中)
#######################
# 更加形象的例子就是把多个装饰器比作俄罗斯套娃
# 将被装饰函数看做最小的套娃,装饰器依据靠近被装饰函数的距离依次变大
# 在装饰器进行装饰时,可以看做装套娃:从最小的(这里是被装饰函数)开始,依次放入比自己大的娃娃中
# 在执行装饰器时,可以看做拆套娃:从最大的开始(这里是最外层的装饰器)拿,依次向内,直到取出最小的娃娃
the zsq2 is RUNING
the zsq2 is END
the zsq1 is RUNING
the zsq1 is END
***装饰器1***
***装饰器2***
***test***
hello world!
'''
装饰器执行的时间
Python解释器执行到@处时,就已经开始装饰了
装饰器对有参数,无参数函数进行装饰:
当无参时,不必特别处理,
当有参数时,对闭包中的函数进行设置形参,
这里就可以进行有参数的函数进行装饰了.
这里需要特别注意:
在有参数时,可以用不定长参数的方式,
*args和**kwargs,在调用装饰的函数时,
需要用同样的不定长参数进行解包
装饰器对带有返回值的函数进行装饰:
在闭包的函数中设置一个return 在调用被装饰的函数时,赋值,这样就可以输出
'''
# 对含定长参函数进行装饰 例子
print('对定长参数函数装饰')
def decorator_var(func):
def decorator_var_in(a, b):
print(a,'\t',b)
func(a,b)
return decorator_var_in
@decorator_var
def foo(a, b):
print('sum = ', a+b)
foo(1,2)
print('定长装饰例子结束\n')
对定长参数函数装饰
1 2
sum = 3
定长装饰例子结束
# 对不定长参数函数装饰 例子
print('对不定长参数函数装饰')
def decorator_var(func):
def decorator_var_in(*args, **kwargs):
print(args,'\n',kwargs)
func(*args, **kwargs)
return decorator_var_in
@decorator_var
def foo(*args, **kwargs):
l = [args, kwargs]
print('set = :',l)
t = (1,2,3)
d = {'name':'sss','age':16}
foo(*t, **d)
print('不定定长装饰例子结束\n')
对不定长参数函数装饰
(1, 2, 3)
{'name': 'sss', 'age': 16}
set = : [(1, 2, 3), {'name': 'sss', 'age': 16}]
不定定长装饰例子结束
# 对带有返回值的函数进行装饰 例子
print('带有返回值的函数进行装饰')
def zsq(func):
def bb():
re = func()
return re # 这里是注意点
return bb
@zsq
def test():
print("this is a test def !".center(30,"*"))
return 666
ret = test()
# 注意这里的return
print(ret)
print('带有返回值的函数进行装饰结束')
带有返回值的函数进行装饰
*****this is a test def !*****
666
带有返回值的函数进行装饰结束
# 通用装饰器 例子
def decorator_pub(func):
def decorator_in(*args, **kwargs):
print("这是一个通用装饰器")
print("args is {}\nkwargs is {}".format(*args, **kwargs))
tmp = func(*args, **kwargs)
return tmp
#注意,在Python中,如果return 返回的是None,那么不算是错误,
# 所以,在这里一直写上return 是不算错的
return decorator_in
@decorator_pub
def test(a,b):
print("this is a test")
return a+b
ret = test('a','c')
print(ret)
这是一个通用装饰器
args is ('a', 'c')
kwargs is {}
this is a test
ac
带有参数的装饰器
装饰器带参数,在原有的装饰器的基础上,设置外部变量
这里的设置外部变量就是在原有的装饰器的基础上,在外部再加一个带参数的函数
带有参数的装饰器能起到在运行时使用不同的功能
# 带参数的装饰器 例子
def func_arg(tmp):
print("the value is {}".format(tmp))
def zsq(func):
print("zsq")
def bb():
print("bb")
func()
return bb
return zsq
@func_arg(6666) # python执行到这里时,先执行了func_arg(tmp = 6666)
def test():
print("this is test")
test()
print('\n我是分隔符\n')
def demo():
print('this is demo')
demo = func_arg('11111')(demo)
demo()
# test的形式和demo的形式等价
the value is 6666
zsq
bb
this is test
我是分隔符
the value is 11111
zsq
bb
this is demo
类做装饰器
用类做装饰器需要在类中定义一个__call__()方法
# 类做装饰器 例子
class Demo(object):
def __init__(self, func):
print("初始化{}".format(func.__name__))
self.__func = func
def __call__(self):
print("这是类装饰器")
self.__func()
@Demo
def test():
print("test".center(20,"*"))
test()
初始化test
这是类装饰器
********test********
wraps函数
用于消除装饰器在装饰函数时改变了被装饰函数的说明文档这一缺点
# 未使用warps() 例子
import functools
print('未使用warps() 例子')
def zsq(func):
"这是一个装饰器"
# @functools.wraps(func)
def a():
'这是装饰器的内部函数'
print("这里添加了一个装饰器")
func()
return a
@zsq
def test():
"这里是一个测试函数"
print("this is a test")
test()
# 输出test()的文档
print(test.__doc__)
未使用warps() 例子
这里添加了一个装饰器
this is a test
这是装饰器的内部函数
import functools
print('\n使用warps() 例子')
def zsq(func):
"这是一个装饰器"
@functools.wraps(func)
def a():
'这是装饰器的内部函数'
print("这里添加了一个装饰器")
func()
return a
@zsq
def test():
"这里是一个测试函数"
print("this is a test")
test()
print(test.__doc__)
使用warps() 例子
这里添加了一个装饰器
this is a test
这里是一个测试函数
装饰器使用场景
'''授权(Authorization)'''
# 导入wraps防止说明文档被覆盖
from functools import wraps
def requires_auth(f):
@wraps(f)
def decorated(*args, **kwargs):
auth = request.authorization
if not auth or not chech_auth(auth.username, auth.password):
authenticate()
return f(*args, **kwargs)
return decorated
'''日志(Logging)'''
# 导入wraps防止说明文档被覆盖
from functools import wraps
def logit(func):
@wraps(func)
def with_logging(*args, **kwargs):
print(func.__name__ + 'wass called')
return func(*args, **kwargs)
return with_logging
@logit
def addition_func(x):
'''Do some math.'''
return x + x
result = addition_func(4)
# output: addition_funcwass called
addition_funcwass called
'''在函数中嵌入装饰器(相当于带参数的装饰器)'''
# 记录日志并输出到日志文件
from functools import wraps
def logit(logfile='./Gnerate_files/out.log'):
def logging_decorator(func):
@wraps(func)
def wrapped_function(*args, **kwargs):
log_string = func.__name__+' was called'
print(log_string)
# 打开logfile,写入日志
with open(logfile, 'a+', encoding='utf-8') as log_file:
# 写入日志
log_file.write(log_string + '\n')
return func(*args, **kwargs)
return wrapped_function
return logging_decorator
@logit()
def myFunc1():
pass
@logit(logfile='./Gnerate_files/func2.log')
def myFunc2():
pass
# 测试
myFunc1()
# 输出myFunc1 was called
# 并且生成一个out.log文件,文件内容为上述字符串
myFunc2()
# 输出myFunc2 was called
# 并且生成一个out.log文件,文件内容为上述字符串
myFunc1 was called
myFunc2 was called
模块
'''
os.__file__
__file__:用于显示当前文件所在的绝对路径
import os
xxx-cpython-35.pyc 表示c语言编写的Python编译器3.5版本的字节码
import Name
from name import defName,defName2
from name import * 注意:这里尽量不要使用这种方法导入;
使用这种方式导入,若存在同名函数,后导入的函数会覆盖先导入的函数
import Name as sName
__name__属性
在模块被调用时不希望调用模块中的某些功能可是使用"__name__"属性来实现
例子:
if __name__ == '__main__':
print('在本体模块内被调用')
else:
print('在其他模块内被调用')
例子结束
__all__属性
在模块被导入时的所有方法名
所有在模块被调用的方法名都存在__all__[]中
__all__属性的功能还可用dir([x])来实现
dir()函数会罗列当前定义的所有名称
并不是所有模块都有"__all__"属性
程序执行时导入模块路径:
import sys
sys.path.append('/home/itcast/xxx')
# 末尾追加路径
sys.path.insert(0, '/home/itcast/xxx')
#头部添加路径(可以确保先搜索这个路径)
'''
# 程序执行时添加路径 例子
import sys
raw_list = sys.path
sys.path.append('D:\\Documents\\Jupyter_notebook')
append_list = sys.path
sys.path.insert(0, 'D:\\Documents')
insert_list = sys.path
print('raw_list = {}\n\nappend_list = {}\n\ninsert_list = {}'.format(
raw_list,append_list,insert_list
))
raw_list = ['D:\\Documents', '', 'D:\\Documents\\Jupyter_notebook', 'C:\\MyPrograms\\Anaconda3\\python37.zip', 'C:\\MyPrograms\\Anaconda3\\DLLs', 'C:\\MyPrograms\\Anaconda3\\lib', 'C:\\MyPrograms\\Anaconda3', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\win32', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\win32\\lib', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\Pythonwin', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\IPython\\extensions', 'C:\\Users\\shj\\.ipython', 'D:\\Documents\\Jupyter_notebook']
append_list = ['D:\\Documents', '', 'D:\\Documents\\Jupyter_notebook', 'C:\\MyPrograms\\Anaconda3\\python37.zip', 'C:\\MyPrograms\\Anaconda3\\DLLs', 'C:\\MyPrograms\\Anaconda3\\lib', 'C:\\MyPrograms\\Anaconda3', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\win32', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\win32\\lib', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\Pythonwin', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\IPython\\extensions', 'C:\\Users\\shj\\.ipython', 'D:\\Documents\\Jupyter_notebook']
insert_list = ['D:\\Documents', '', 'D:\\Documents\\Jupyter_notebook', 'C:\\MyPrograms\\Anaconda3\\python37.zip', 'C:\\MyPrograms\\Anaconda3\\DLLs', 'C:\\MyPrograms\\Anaconda3\\lib', 'C:\\MyPrograms\\Anaconda3', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\win32', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\win32\\lib', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\Pythonwin', 'C:\\MyPrograms\\Anaconda3\\lib\\site-packages\\IPython\\extensions', 'C:\\Users\\shj\\.ipython', 'D:\\Documents\\Jupyter_notebook']
# __all__和dir() 比较例子
print('this is a example for __all_ and dir()')
import os
A=os.__all__
B=dir(os)
print('this is __all__:',A)
print('\n***\n'*2)
print('this is dir(): ',A)
print('\n***\n'*2)
C=list(set(A).difference(set(B)))
print('this is difference of __all__ and dir()', C)
this is a example for __all_ and dir()
this is __all__: ['altsep', 'curdir', 'pardir', 'sep', 'pathsep', 'linesep', 'defpath', 'name', 'path', 'devnull', 'SEEK_SET', 'SEEK_CUR', 'SEEK_END', 'fsencode', 'fsdecode', 'get_exec_path', 'fdopen', 'popen', 'extsep', '_exit', 'DirEntry', 'F_OK', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'R_OK', 'TMP_MAX', 'W_OK', 'X_OK', 'abort', 'access', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'device_encoding', 'dup', 'dup2', 'environ', 'error', 'execv', 'execve', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'link', 'listdir', 'lseek', 'lstat', 'mkdir', 'open', 'pipe', 'putenv', 'read', 'readlink', 'remove', 'rename', 'replace', 'rmdir', 'scandir', 'set_handle_inheritable', 'set_inheritable', 'spawnv', 'spawnve', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'symlink', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'write', 'makedirs', 'removedirs', 'renames', 'walk', 'execl', 'execle', 'execlp', 'execlpe', 'execvp', 'execvpe', 'getenv', 'supports_bytes_environ', 'spawnl', 'spawnle']
***
***
this is dir(): ['altsep', 'curdir', 'pardir', 'sep', 'pathsep', 'linesep', 'defpath', 'name', 'path', 'devnull', 'SEEK_SET', 'SEEK_CUR', 'SEEK_END', 'fsencode', 'fsdecode', 'get_exec_path', 'fdopen', 'popen', 'extsep', '_exit', 'DirEntry', 'F_OK', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'R_OK', 'TMP_MAX', 'W_OK', 'X_OK', 'abort', 'access', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'device_encoding', 'dup', 'dup2', 'environ', 'error', 'execv', 'execve', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'link', 'listdir', 'lseek', 'lstat', 'mkdir', 'open', 'pipe', 'putenv', 'read', 'readlink', 'remove', 'rename', 'replace', 'rmdir', 'scandir', 'set_handle_inheritable', 'set_inheritable', 'spawnv', 'spawnve', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'symlink', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'write', 'makedirs', 'removedirs', 'renames', 'walk', 'execl', 'execle', 'execlp', 'execlpe', 'execvp', 'execvpe', 'getenv', 'supports_bytes_environ', 'spawnl', 'spawnle']
***
***
this is difference of __all__ and dir() []
#dir() 例子
dir()
['In',
'Out',
'_',
'__',
'___',
'__builtin__',
'__builtins__',
'__doc__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'_dh',
'_i',
'_i1',
'_i10',
'_i11',
'_i12',
'_i13',
'_i14',
'_i15',
'_i16',
'_i17',
'_i18',
'_i19',
'_i2',
'_i20',
'_i3',
'_i4',
'_i5',
'_i6',
'_i7',
'_i8',
'_i9',
'_ih',
'_ii',
'_iii',
'_oh',
'a',
'add',
'alist',
'astring',
'exit',
'get_ipython',
'i',
'is_odd',
'l',
'newlist',
'numlist',
'produce',
'quit',
'reduce',
'sort_list',
'sorted_str',
'sum']
os模块
'''
os.access(path,mode)
检查权限;path:路径;mode{
os.F_OK: 作为access()的mode参数,测试path是否存在。最常用
os.R_OK: 包含在access()的mode参数中 , 测试path是否可读。
os.W_OK 包含在access()的mode参数中 , 测试path是否可写。
os.X_OK 包含在access()的mode参数中 ,测试path是否可执行。
}
os.chdir(path) 改变当前工作目录
os.chmod(path,mode) 更改权限
os.chown(path, uid, gid) 更改文件所有者
os.chroot(path) 改变当前进程的根目录
os.path.realpath(__file__) 返回真实路径
os.path.split() 返回路径的目录和文件名
os.getcwd() 得到当前工作的目录
__file__ 是用来获得模块所在的路径的
更多参照下方的help
'''
import os
dir(os)
['DirEntry',
'F_OK',
'MutableMapping',
'O_APPEND',
'O_BINARY',
'O_CREAT',
'O_EXCL',
'O_NOINHERIT',
'O_RANDOM',
'O_RDONLY',
'O_RDWR',
'O_SEQUENTIAL',
'O_SHORT_LIVED',
'O_TEMPORARY',
'O_TEXT',
'O_TRUNC',
'O_WRONLY',
'P_DETACH',
'P_NOWAIT',
'P_NOWAITO',
'P_OVERLAY',
'P_WAIT',
'PathLike',
'R_OK',
'SEEK_CUR',
'SEEK_END',
'SEEK_SET',
'TMP_MAX',
'W_OK',
'X_OK',
'_Environ',
'__all__',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'_execvpe',
'_exists',
'_exit',
'_fspath',
'_get_exports_list',
'_putenv',
'_unsetenv',
'_wrap_close',
'abc',
'abort',
'access',
'altsep',
'chdir',
'chmod',
'close',
'closerange',
'cpu_count',
'curdir',
'defpath',
'device_encoding',
'devnull',
'dup',
'dup2',
'environ',
'error',
'execl',
'execle',
'execlp',
'execlpe',
'execv',
'execve',
'execvp',
'execvpe',
'extsep',
'fdopen',
'fsdecode',
'fsencode',
'fspath',
'fstat',
'fsync',
'ftruncate',
'get_exec_path',
'get_handle_inheritable',
'get_inheritable',
'get_terminal_size',
'getcwd',
'getcwdb',
'getenv',
'getlogin',
'getpid',
'getppid',
'isatty',
'kill',
'linesep',
'link',
'listdir',
'lseek',
'lstat',
'makedirs',
'mkdir',
'name',
'open',
'pardir',
'path',
'pathsep',
'pipe',
'popen',
'putenv',
'read',
'readlink',
'remove',
'removedirs',
'rename',
'renames',
'replace',
'rmdir',
'scandir',
'sep',
'set_handle_inheritable',
'set_inheritable',
'spawnl',
'spawnle',
'spawnv',
'spawnve',
'st',
'startfile',
'stat',
'stat_result',
'statvfs_result',
'strerror',
'supports_bytes_environ',
'supports_dir_fd',
'supports_effective_ids',
'supports_fd',
'supports_follow_symlinks',
'symlink',
'sys',
'system',
'terminal_size',
'times',
'times_result',
'truncate',
'umask',
'uname_result',
'unlink',
'urandom',
'utime',
'waitpid',
'walk',
'write']
hashlib模块
用于生成hash(哈希)码等操作
参考于python高级
hashlib.new(name[, data])
对数据进行加密参数:name:加密算法名,例如:‘md5’,[, data]要加密的数据
hash.digest() 返回二进制数据字符串的摘要
hash.hexdigest() 返回16进制数据字符串的摘要
hash.digest_size hash对象的字节长度
hash.block_size hash对象的内部块大小
hash.name hash对象的名称
hash.update(data) 传递类字节参数(通常是bytes)更新hash对象。
重复调用update()等同于单次的拼接调用:m.update(a); m.update(b)等同m.update(a+b)
hash.copy() 返回hash对象的克隆这里hash指的是经过加密算法加密后的摘要
hashlib.algorithms_guaranteed 所有平台的hashlib模块都支持的hash算法的名称集合。
hashlib.algorithms_available 当前运行的python解释器支持的hash算法的名称集合hashlib.algorithms_guaranteed的结果集总是hashlib.algorithms_available结果集的子集
简单的加密算法可能通过“撞库”破解,这时可以通过附加key来加强安全性
首先设定key,这个key最好是动态的,并且不能泄露,不然安全性会降低
然后设定加密算法md5 = hashlib.md5(key)这里的key指的是自定义的key值
再通过res = md5.update(data)来对data数据进行加密
最后通过res.hexdigest()输出密文
# hashlib.new()使用例子
import hashlib
tmp = "PHP是世界上最好的语言".encode("utf-8")
result = hashlib.new('sha1', tmp)
print("二进制摘要:",result.digest())
print("16进制摘要:",result.hexdigest())
print("result摘要的字节长度:",result.digest_size)
print("result摘要的内部块大小:", result.block_size)
print("result对象的内部名(也可看做加密算法名):",result.name)
二进制摘要: b'\xc1W:\xb5VF=\xed\xb7\x8f\xfa\x1c\xe5\xe2\x11\x93\xc4ND8'
16进制摘要: c1573ab556463dedb78ffa1ce5e21193c44e4438
result摘要的字节长度: 20
result摘要的内部块大小: 64
result对象的内部名: sha1
# 高级加密(附加key)
key = "您说的对".encode("utf-8")
print(key)
sha1 = hashlib.sha1(key)
pa = sha1.update(tmp)
pb = sha1.hexdigest()
print("未添加key加密后的密文:",result.hexdigest())
print("高级加密后的密文:", pb)
b'\xe6\x82\xa8\xe8\xaf\xb4\xe7\x9a\x84\xe5\xaf\xb9'
未添加key加密后的密文: c1573ab556463dedb78ffa1ce5e21193c44e4438
高级加密后的密文: af672023437b22c31233917c74b489c9c2ede424
# hash.update()例子
# 分段加密的最终密文和不分段单次加密后的密文是相同的
sha1 = hashlib.sha1() # 选定算法
sha1.update(tmp) # 加密第一段
pa_res = sha1.hexdigest()
print("分段加密第一段密文:", pa_res)
sha1.update(key) # 加密第二段
pb_res = sha1.hexdigest()
print("分段加密第二段密文:", pb_res)
sha1 = hashlib.sha1() # 复位算法,尤其重要,否则后面的总段会认为是第三分段,而不是总段
sha1.update(tmp+key) # 加密总段
pc_res = sha1.hexdigest()
print("不分段加密后的密文:", pc_res)
print("第一分段字节编码:", tmp,'\n',"第二分段字节编码",key,'\n',"总段字节编码:",tmp+key) # 打印第一段,第二段,总段的字节编码
分段加密第一段密文: c1573ab556463dedb78ffa1ce5e21193c44e4438
分段加密第二段密文: 5e9d37c4e41b5abdf8fe3f52b22c435622682c60
不分段加密后的密文: 5e9d37c4e41b5abdf8fe3f52b22c435622682c60
第一分段字节编码: b'PHP\xe6\x98\xaf\xe4\xb8\x96\xe7\x95\x8c\xe4\xb8\x8a\xe6\x9c\x80\xe5\xa5\xbd\xe7\x9a\x84\xe8\xaf\xad\xe8\xa8\x80'
第二分段字节编码 b'\xe6\x82\xa8\xe8\xaf\xb4\xe7\x9a\x84\xe5\xaf\xb9'
总段字节编码: b'PHP\xe6\x98\xaf\xe4\xb8\x96\xe7\x95\x8c\xe4\xb8\x8a\xe6\x9c\x80\xe5\xa5\xbd\xe7\x9a\x84\xe8\xaf\xad\xe8\xa8\x80\xe6\x82\xa8\xe8\xaf\xb4\xe7\x9a\x84\xe5\xaf\xb9'
常用标准库
官方网址:
https://docs.python.org/3.7/library/
builtins 内建函数默认加载
os 操作系统接口
sys python自身的运行环境
functools 常用的工具
json 编码和解码JSON对象
logging 记录日志,调试
multiprocessing 多进程
threading 多线程
copy 拷贝
time 时间
time 模块参考网址:https://finthon.com/python-time/
datetime 日期和时间
calendar 日历
hashlib 哈希加密算法
random 随机数
re 正则
socket 标准BSD Sockets API
shutil 文件和目录管理(和os模块互补)
glob 基于文件通配符搜索
'''
深拷贝、浅拷贝
这里的深浅指的是拷贝的程度
浅拷贝:只是对同一个变量的地址引用(地址的拷贝),这里的拷贝只是用引用指向
深拷贝:这里需要导入模块【import copy ;new = copy.deepcopy(old)】这里的拷贝是新建了内存的拷贝
copy模块中的copy和deepcopy的区别:copy只copy第一层,而deepcopy是完全copy
copy拷贝的特点:自动判断>>>当copy的对象是不可变类型时,浅拷贝,当是可变类型时,copy第一层
'''
functools模块
'''
这个模块中放置相对常用的一些方法
partial()(偏函数):把一个函数的某些参数设置成默认值,返回一个新的函数,
调用这个新的函数更简单
'''
# 例子
import functools
def test(*args, **kwargs):
#注意这里的可变长参数,如果设置定长参数,会出现参数多给报错
print('the args in test is:',args)
print('the kwargs in test is: ', kwargs)
q = functools.partial(test, 1,2)
q()
q(666, 2333)
the args in test is: (1, 2)
the kwargs in test is: {}
the args in test is: (1, 2, 666, 2333)
the kwargs in test is: {}
常用扩展库
'''
requests 使用urllib3,继承了urllib2的所有特性
urllib 基于http的高层库
scrapy 爬虫
beautifulsoup4 HTML/XML的解析器
celery 分布式任务调度模块
redis 缓存
Pillow(PIL) 图像处理
xlsxwriter 仅写excle功能,支持xlsx
xlwt 仅写excel功能,支持xls,2013或更早版office
xlrd 只读excle功能
elasticsearch 全文搜索引擎
pymysql MySQL链接库
mongoengine/pymongo mongodbpython接口
matplotlib 画图
numpy/scipy 科学计算
django/tornado/flask web框架
SimpleHTTPServer 简单HTTPServer,不使用Web框架
gevent 基于协程的Python网络库
fabric 系统管理
pandas 数据处理库
scikit-learn 机器学习库
'''
包和__init__
'''
在一个文件夹下有py文件,有__init__.py文件称为包
包中__init__.py文件的内容应含有__all__,以及
from . import xxxName : 这里是对from * (all)以及 import 的导包方法的使用声明
如果__init__文件为空,导包会失败
模块重新导入
向导入模块中添加新的路径:sys.path.append("yourPath")
重新导入模块
from ModelName import *
reload("old_Model") # 这里的参数是要重新导入的模块
模块的循环导入问题
a模块中导入了b模块,然而在b模块中又导入了a模块(这样就出现了一个模块导入的死递归)
解决方法:再建立一个新的模块,让这两个递归的模块成为子模块,让那个新的模块调用这两个模块
'''
输入输出
'''
给程序传参:sys
import sys
print(sys.argv) #这里sys.argv是一个列表,0表示程序名,1:表示传入的参数
'''
# sys.argv 例子
import sys
print(sys.argv)
['/home/shj/WorkStations/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py', '-f', '/run/user/1000/jupyter/kernel-fc9aa604-d8c9-4367-a568-145f624bfffd.json']
输入
'''
input() 键入字符串
'''
输出
'''
repr(): 产生一个解释器易读的表达形式。
print() 打印
'''
# repr() 例子
s = '123456'
repr(s)
"'123456'"
'''
格式化输出
print('xxx %d' %(123))
print('strings{key}'.format())# {}中可以设置变量名,在format中用key=value赋值,{}中设置数字顺序在format中可以按序号给出值
'''
#format()例子
print("this is sequence:{} {} {}".format('who','am', 'i'))
print('*'*8)
print("this is no sequence:{2} {1} {0}".format('who','am', 'i'))
this is sequence:who am i
********
this is no sequence:i am who
文件
'''
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True)
参数说明:
{
file: 必需,文件路径(相对或者绝对路径)
mode: 可选,文件打开模式
buffering: 设置缓冲区大小,默认-1:全缓冲,0:无缓冲,1:行缓冲,大于1的任意整数:任意字节大小的缓冲区
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
}
file.close() 关闭
file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件
file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型),
可以用在如os模块的read方法等一些底层操作上。
file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。
file.next() 返回文件下一行。(python3中不支持此方法)
file.read([size]) 从文件读取指定的字节数,如果未给定或为负则读取所有。
file.write(str)
file.readline([size]) 读取整行,包括 "\n" 字符。 size表示读取的行内字节数,
当size大小超过整行数据大小时,读取整行
file.readlines([sizeint]) 读取所有行并返回列表,若给定sizeint>0,
返回总和大约为sizeint字节大小的所在行,
实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。
file.seek(size,pos(0开头,1中间,2结尾)) size表示偏移量(单位为字节),
pos表示偏移位置(0开头,1中间,2结尾)
file.tell() 返回地址
file.writelines(sequence) 向文件写入一个序列字符串列表,
如果需要换行则要自己加入每行的换行符。
file.truncate([size]) 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;
截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。
OS
import os
os.rename("old","new") #重命名
os.mkdir("name") #创建dir
os.getcwd() #获取当前路径
os.chdir("newpath") #改变默认目录
os. listdir("./") #获取目录
'''
# 文件例子
import os
print(os.listdir('./Gnerate_files/'))
with open('./Gnerate_files/fileDemo.txt','w',encoding='utf-8') as f_out:
f_out.write('this is a file wirte demo.')
print("file writed!")
print(os.listdir('./Gnerate_files/'))
with open('./Gnerate_files/fileDemo.txt','r',encoding='utf-8') as f_in:
print("file read in:")
print(f_in.read())
['.ipynb_checkpoints', 'data.pkl', 'func2.log', 'out.log', '闭包用途2使用文档.txt']
file writed!
['.ipynb_checkpoints', 'data.pkl', 'fileDemo.txt', 'func2.log', 'out.log', '闭包用途2使用文档.txt']
file read in:
this is a file wirte demo.
pickle模块
'''
pickle 模块
python的pickle模块实现了基本的数据序列和反序列化。
序列化操作:将程序中运行的对象信息保存到文件中去,永久存储。
反序列化操作:可从文件中创建上一次程序保存的对象。
基本接口:
pickle.dump(obj, file, [,protocol]) 将数据序列化(二进制)输出到文件
protocol为可选参数,默认为0,当为-1时为最高级协议版本
x = pickle.load(file) 将file文件保存的数据反序列化(还原)
str = pickle.dumps(data) 将data数据序列化为一串字符串
data_re = pickle.loads(str) 将序列化字符串str反序列化
'''
# 序列化
import pickle
# 使用pickle模块将数据对象保存到文件
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('./Gnerate_files/data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
#反序列化
import pprint, pickle, os
#使用pickle模块从文件中重构python对象
pkl_file = open('./Gnerate_files/data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()
os.listdir('./Gnerate_files/')
{'a': [1, 2.0, 3, (4+6j)], 'b': ('string', 'Unicode string'), 'c': None}
[1, 2, 3, ]
['.ipynb_checkpoints',
'data.pkl',
'fileDemo.txt',
'func2.log',
'out.log',
'闭包用途2使用文档.txt']
面向对象
'''
类:
class ClassName:
pass
对代码基本相同的类抽取基类:当不同类中的方法基本相同时,
可以抽取出一个基类,用来简化代码
属性:
实例属性可以通过在__init__方法中设置,不必刻意写出
方法:
def func(self):
pass
# 这里的self相当于java中的this,只是python中写成了self
'''
魔法方法
'''相当于java中的实例属性'''
__new__方法
通常__new__都不需要定义,在元类编程中才需要,它可以控制类的生成过程。
'''
__new__至少要有一个参数cls,代表要实例化的类,
此参数在实例化时由python解释器自动提供
__new__必须要有返回值,返回实例化出来的实例,
这点在自己实现__new__时要特别注意,
可以return父类__new__出来的实例,或者直接是object的__new__出来的实例
__new__(cls):这个方法在类被引用时会被执行
(自动的,如果不被创建,类会调用默认的__new__方法)
这里的cls此时指向的是类的名字[其实类是通过父类object.__new__(cls)来生成的]
__new__方法只负责创建,__init__方法只负责初始化
__init__的self参数就是__new__返回的实例,__init__在__new__的基础上完成初始化动作,__init__不需要返回值
注意,在创建对象时最先调用__new__方法,这时向类中添加参数会报错,
所以这时需要在__new__方法中设置虚参,只是一个样子,不需要用到
'''
# 在此比较java和c++中的构造方法,构造方法其实包含了Python中的这两个方法
'''单例模式:确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。'''
# 创建单例对象:不管创建多少只有一个对象
class A(object):
pass
d = A()
e = A()
print(id(d))
print(id(e))
#注意,这里的两个print的输出值并不相同
#这里不是单例模式
"""单例模式可以通过类变量来实现"""
# 这个单例模式只是一个例子,可以看出只能创建单例模式中的类属性,方法的创建就要添加参数
class A(object):
__num = None
def __new__(cls):
if cls. __num == None: # 这里判断是否为第一次实例化
cls.__num = object.__new__(cls) # 第一次实例化,进行实例化
return cls.__num
else :
# 不是第一次实例化:返回上面生成的cls.__num
return cls.__num
# 这里依据类属性在实例化对象中公用的原理,创建单例模式
'''在实例化a时,将A类的私有属性__num'''
a = A()
b = A()
print(id(a))
print(id(b))
#此时打印的a、b的id是相同的
#也就是表明此时是单例模式
139934035060440
139934035059712
139934035060216
139934035060216
__init__方法
用于初始化:初始化函数,将变量绑定到实例中,更新实例的__dict__字典。
其中第一个参数self就是__new__的返回值,是类的实例。__new__方法先于__init__方法执行。
# __init__方法:
class Demo:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return ('your name is {name},your age is {age}'.format(name = self.name,
age = self.age))
demo = Demo('shj', 22)
print(demo)
your name is shj,your age is 22
__str__方法
用于获取描述信息
# __str__方法:
class Demo:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return ('your name is {name},your age is {age}'.format(name = self.name,
age = self.age))
demo = Demo('shj', 22)
print(demo)
your name is shj,your age is 22
__del__方法
析构函数,释放对象时使用
在硬链接的obj完全删除时自动调用此方法,可视为善后处理
其他方法
''' 这些方法都是类(Class)专有方法
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
'''
引用计数
'''
sys模块中的getrefcount()方法
sys.getrefcount() :用于查看一个对象被引用的次数
返回的值是引用次数+1(次数=返回值-1)
'''
# 引用计数例子
from sys import getrefcount
class DD:
def __init__(self,info):
self.info = info
def __str__(self):
return 'this is {} Demo'.format(self.info)
d1 = DD('d1')
d2 = DD('d2')
print(d1)
print(d2)
print('*'*8)
count = getrefcount(DD)-1
print('the getrefcount is {}'.format(count))
this is d1 Demo
this is d2 Demo
********
the getrefcount is 6
继承
'''
class sonClass(FatherClass):
pass
世袭:子类可以继承父类(基类),也可以继承父类的父类
多继承
class sonClass(Base1, Base2, Base3):
pass
继承后对方法的查找顺序:从左至右
可用className.__mro__打印这个类可调用的类
私有方法、私有属性不能被继承
但是调用的公有方法中包含私有方法或属性,这个公有方法可以被继承
'''
# 多继承例子
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多重继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中排前地父类的方法
print('\nthe class sample can use BASE CLASS IS:\n {}'.format(sample.__mro__))
我叫 Tim,我是一个演说家,我演讲的主题是 Python
the class sample can use BASE CLASS IS:
(, , , , )
重写
'''
子类重写父类方法和java相同
调用被重写的方法:
BaseClass.funcName()
super.funcName()
'''
'''多态:定义的方法根据传递进的方法的不同而得到不同的结果'''
# 一个多态的小例子
class F1(object):
def show(self):
print ('F1.show')
class S1(F1):
def show(self):
print ('S1.show')
class S2(F1):
def show(self):
print ('S2.show')
# 由于在Java或C#中定义函数参数时,必须指定参数的类型
# 为了让Func函数既可以执行S1对象的show方法,又可以执行S2对象的show方法,所以,定义了一个S1和S2类的父类
# 而实际传入的参数是:S1对象和S2对象
'''
对java或C#
def Func(F1 obj):
"""Func函数需要接收一个F1类型或者F1子类的类型"""
print (obj.show())
'''
# python
def func(obj):
obj.show()
print("*"*8)
s1_obj = S1()
func(s1_obj) # 在Func函数中传入S1类的对象 s1_obj,执行 S1 的show方法,结果:S1.show
s2_obj = S2()
func(s2_obj) # 在Func函数中传入Ss类的对象 ss_obj,执行 Ss 的show方法,结果:S2.show
S1.show
********
S2.show
********
类属性
'''
定义在class内部,但是在方法外部的变量称为类的属性
类属性属于类,并且类属性在实例间共享
'''
实例属性
'''
和具体的某个实例对象有关,在类内部的实例属性不同实例对象共用,类外部单独创建的实例属性不共用
实例属性和类属性重名会强制覆盖类属性,但是无法通过实例属性对类属性进行更改
'''
有关类方法、实例方法、静态方法的笔记参考了蔷薇Nina这位朋友的笔记
导向链接
https://www.cnblogs.com/wcwnina/p/8644892.html
类方法
类的方法,需要在方法前添加@classmethod
注意:类方法必须有有一个cls变量做形参,这个cls表示类本身(当前类对象)
,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
@classmethod
def classFunc(cls): # 这里必须要定义一个形参,名称无所谓,惯用cls,这个变量表示类本身
pass
原则上,类方法是将类本身作为对象进行操作的方法。
假设有个方法,且这个方法在逻辑上采用类本身作为对象来调用更合理,那么这个方法就可以定义为类方法。
另外,如果需要继承,也可以定义为类方法。
# 假设我有一个学生类和一个班级类,想要实现的功能为:
# 执行班级人数增加的操作、获得班级的总人数;
# 学生类继承自班级类,每实例化一个学生,班级人数都能增加;
# 最后,我想定义一些学生,获得班级中的总人数。
# 思考:这个问题用类方法做比较合适,为什么?因为我实例化的是学生,
# 但是如果我从学生这一个实例中获得班级总人数,在逻辑上显然是不合理的。
# 同时,如果想要获得班级总人数,如果生成一个班级的实例也是没有必要的。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import hashlib
from math import pi
class ClassRoom(object):
__num = 0
@classmethod
def add_num(cls):
cls.__num += 1
@classmethod
def get_num(cls):
return cls.__num
def __new__(self):
ClassRoom.add_num()
return super().__new__(self)
class Student(ClassRoom):
def __init__(self):
self.name = ""
stu_a = Student()
stu_a.name = "lee"
stu_b = Student()
stu_b.name = "sh"
print("现在的学生人数为:", ClassRoom.get_num())
实例方法
实例方法:第一个参数必须是实例对象,该参数名一般约定为“self”,
通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类中定义的方法没有特殊标注都是实例方法
self 必须写
def intanceFunc(self): # self 表示实例本身
pass
实例方法中self的含义
'''
self代表的是实例,不是类
'''
# 例子
class Demo(object):
def get(self):
print(self.__class__) # 打印self的类
print(self) # 打印self
demo = Demo()
demo.get()
print(demo.get)
<__main__.Demo object at 0x7f17e820d390>
>
'''
实例方法中的self必须写,不写的话将变成类方法,
并且此类方法只能用类名调用,用实例名调用会报错,
因为少self参数,无法实例化
'''
# 例子
class Demo(object):
# 定义和调用都有self
def get(self):
print(self) # 打印self
print(self.__class__) # 打印self的类
demo = Demo()
print('实例方法中有self:')
demo.get()
print("*"*8)
class Test(object):
# 定义时无self,调用时有self
def get():
print(self)
# 异常处理
try:
test = Test()
test.get()
except Exception as result:
print('实例化方法中无self会抛出异常:')
print(result)
class Test_1(object):
# 定义和调用均无self
def get():
print('方法定义时无self,调用时也没有self')
print(__class__)
Test_1.get()
实例方法中有self:
<__main__.Demo object at 0x7f44eda10208>
********
实例化方法中无self会抛出异常:
get() takes 0 positional arguments but 1 was given
方法定义时无self,调用时也没有self
'''
继承时,实例为被实例化的类的实例,不是定义了实例所调用的方法的类的实例
'''
# 例子
class People(object):
def infos(self):
str = 'i am People{}'.format(self)
return str
class Man(People):
def about(self):
str = 'I am man {}'.format(self)
return str
man = Man()
print('Man的实例man调用Man的about()实例方法:\n\t', man.about())
print('Man的实例man调用Man的父类People的infos()实例方法:\n\t', man.infos())
# 比较上述两个输出结果可以看出,实例是被实例化类Man的实例,而不是定义了实例方法的People类的实例
print('\n*'*2)
people = People()
print('People的实例people调用People类的实例方法infos():\n\t', people.infos())
Man的实例man调用Man的about()实例方法:
I am man <__main__.Man object at 0x7f17e8217f98>
Man的实例man调用Man的父类People的infos()实例方法:
i am People<__main__.Man object at 0x7f17e8217f98>
*
*
People的实例people调用People类的实例方法infos():
i am People<__main__.People object at 0x7f17e8217a90>
'''
在描述符类中,self指的是描述符类的实例
'''
# 例子
class Desc:
def __get__(self, ins, cls):
print('self in Desc: %s ' % self )
print(self, ins, cls)
class Test:
x = Desc()
def prt(self):
print('self in Test: %s' % self)
t = Test()
t.prt()
'''
这里调用的是t.x,也就是说是Test类的实例t的属性x,
由于实例t中并没有定义属性x,所以找到了类属性x,
而该属性是描述符属性,为Desc类的实例而有,
所以此处并没有顶用Test的任何方法。
那么我们如果直接通过类来调用属性x也可以得到相同的结果。
[把t.x改为Test.x]
'''
t.x
self in Test: <__main__.Test object at 0x7f44eda29748>
self in Desc: <__main__.Desc object at 0x7f44eda29438>
<__main__.Desc object at 0x7f44eda29438> <__main__.Test object at 0x7f44eda29748>
静态方法
静态方法:在类中,方法前添加@staticmethod
静态方法可以不定义参数,也可以定义参数(cls、self在静态方法中没啥意义)
调用:实例对象和类对象都可以调用。
@staticmethod
def staticFunc([self]): # 静态方法的self可写可不写,静态方法相当于一个普通方法
pass
逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作。
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
"""this is a test py flie"""
# 类属性 实例属性 类方法 实例方法 静态方法 例子
class classDemo:
# 类属性
msg = 'class msg'
# 初始化
def __init__(self, info): # 这里info是实例属性
self.info = info
# 实例方法
def about(self):
return self.info
# 类方法
@classmethod
def classFunc(cls):
msg = 'class method'
return msg
# 静态方法
@staticmethod
def staticFunc():
return 'static method'
# 声明两个实例对象 classDemo中的参数传给self.info
demo1 = classDemo('demo1')
demo2 = classDemo('demo2')
# 在实例对象外部为不同实例对象创建不同的实例属性,类外部创建的实例属性不共用
demo1.flag = 'ddd'
demo2.key = 'asdemo'
print(demo1.flag) # ddd
# 这里demo2调用了非共用实例属性,会报错
try:
print(demo2.flag)
except Exception as result:
print(result) # 'classDemo' object has no attribute 'flag'
print("*" * 8)
# info是二者共有的实例属性,不会报错
print(demo1.info) # demo1
print(demo2.info) # demo2
print("*" * 8)
# 类属性可通过实例对象调用
print('use by instance:', demo1.msg) # use by instance: class msg
# 类属性还可通过类名调用
print('use by class name: ', classDemo.msg) # use by class name: class msg
print("*" * 8)
# 类属性不能通过同名实例属性更改
demo1.msg = 'demo1 msg'
print('demo1.msg={0},class.msg={1}'.format(demo1.msg, classDemo.msg))
# demo1.msg=demo1 msg,class.msg=class msg
classDemo.msg = 'changed class msg'
print('demo1.msg={0},class.msg={1}'.format(demo1.msg, classDemo.msg))
# demo1.msg=demo1 msg,class.msg=changed class msg
print("*" * 8)
# 类方法同样可以通过类名和实例对象调用
print('use by instance:', demo1.classFunc()) # use by instance: class method
print('use by class name: ', classDemo.classFunc()) # use by class name: class method
print("*" * 8)
# 静态方法同样可通过类名和实例对象调用
print('use by instance:', demo1.staticFunc()) # use by instance: static method
print('use by class name: ', classDemo.staticFunc()) # use by class name: static method
ddd
'classDemo' object has no attribute 'flag'
********
demo1
demo2
********
use by instance: class msg
use by class name: class msg
********
demo1.msg=demo1 msg,class.msg=class msg
demo1.msg=demo1 msg,class.msg=changed class msg
********
use by instance: class method
use by class name: class method
********
use by instance: static method
use by class name: static method
动态添加属性以及方法
'''
添加属性就是简单的"."操作,但是添加方法时,需要用到模块,types
instanceName.method = types.MethodType(methodName, instance)
'''
# 动态添加方法例子
class Demo(object):
def __init__(self, name):
self.name = name
# Demo类中并没有tmp方法,现在为其添加tmp方法
# 先定义方法
def tmp(self):
print("this is a test function for {}".format(self.name))
d = Demo("666")
try:
d.tmp()
except Exception as result:
print('目前未对Demo添加tmp方法,使用tmp方法会报错')
print(result) # 'Demo' object has no attribute 'tmp'
# 导入types模块
import types
# 用types.MethodType(func, instanceName) 添加了tmp方法
d.tmp = types.MethodType(tmp, d)
print('\nafter add a method') # after add a method
d.tmp() # this is a test function for 666
#这样就添加了一个方法
目前未对Demo添加tmp方法,使用tmp方法会报错
'Demo' object has no attribute 'tmp'
after add a method
this is a test function for 666
'''
types.MethodType的作用:将对象和要添加的方法绑定
这里需要特别注意:用到types.MethodType时,
只是用来添加实例对象的方法,对静态方法(staticmethod)
和类方法(classmethod)只是需要用"."操作:
className.p = p这种方式就可以直接添加
'''
# 对类添加类方法和静态方法 例子
class Demo(object):
def __init__(self, name):
self.name = name
@staticmethod
def addstaticFunc():
print("static method")
@classmethod
def addClassFunc(cls):
print("class method")
demo = Demo(666)
#添加静态方法
Demo.addstaticFunc = addstaticFunc
#添加类方法
Demo.addClassFunc = addClassFunc
#使用静态方法和类方法
Demo.addstaticFunc() # static method
print('*'*8)
demo.addClassFunc() # class method
static method
********
class method
解耦合
'''
对于两个类有交互的时候,可以通过中间件(函数或其他方式)来解决耦合
但是在开发中,尽量使用一个类型,即用类尽量都用类,用方法尽量都用方法
'''
# 工厂模式 解耦合 例子
class Factory(object):
def factFun(self):
return fac
class A(object):
def __int__(self):
self.factory = Factory()
def useB(self):
return use_b
class B(object):
def theBFun(self):
return theB
私有化
'''
name:公有
_name (单_):私有,from XX improt * 禁止导入,类和子类可以访问
__name (双_):私有,避免和子类发生冲突,在外部无法访问
__name__(双_)私有,特有的魔法方法或属性,个人最好不要创建
name_:用于区别与关键字重复
只要开头有_,基本from xx import * 就无法导入,但是只是导入模块,还是可以用的
name mangLing(名字重整)为了防止对私有属性或方法的使用(访问时可以_ClassName.__name)
'''
property的使用
'''
这里需要建立像Java中的setter和getter方法
property通过setter方法和getter方法,
将本不可在外部通过 对象.属性 的调用方式成功实现了
'''
# 例子
class Test(object):
def __init__(self):
self.__num = 0
def getNum(self):
return self.__num
def setNum(self,newNum):
self.__num = newNum
new = property(getNum, setNum)
t = Test()
print('实例未对私有属性赋值:',t.new)
t.new = 666 # 实例对私有属性赋值
print('实例对私有属性赋值后:',t.new)
print('用getter方法获取私有属性的值:',t.getNum())
实例未对私有属性赋值: 0
实例对私有属性赋值后: 666
用getter方法获取私有属性的值: 666
'''
property也可以用装饰器的方法调用
'''
# 例子
class Test(object):
def __init__(self):
self.__num = 0
@property
def num(self):
"""getter"""
return self.__num
@num.setter
def num(self, newNum):
"""setter"""
self.__num = newNum
# 这里就不用写property(getter,setter)方法了
t = Test()
t.num
print('实例未对私有属性赋值:',t.num)
t.num = 666 # 实例对私有属性赋值
print('实例对私有属性赋值后:',t.num)
实例未对私有属性赋值: 0
实例对私有属性赋值后: 666
__slots__的作用
通过在类中用__slots__来限制该类实例能添加的属性(__slots__中有的属性才可添加)
__slots__只对当前类的属性有限制作用,对子类并没有作用
极其不建议用此操作
class Demo(object):
__slots__ = ('name', 'age') # 类Demo只能添加name,age两个属性,添加其他属性会报错
# __slots__限制实例属性的例子
class Person(object):
__slots__ = ('name', 'age')
p = Person()
p.name = 'jack Ma'
p.age = 50
# 这里添加了不允许的实例属性
p.qq = 123456
---------------------------------------------------------------
AttributeError Traceback (most recent call last)
in
13
14 # 这里添加了不允许的实例属性
---> 15 p.qq = 123456
AttributeError: 'Person' object has no attribute 'qq'
元类
'''
类也是对象,所以也可以在运行时动态的创建
'''
# 动态创建类 例子 这是一个半动态的例子
def choose_classs(name):
if name == 'foo':
class Foo(object):
pass
return Foo
else:
class Lol:
pass
return Lol
myClass = choose_classs('foo')
print(myClass) # 函数返回类
print(myClass()) # 可以通过这个类创建实例
.Foo'>
<__main__.choose_classs..Foo object at 0x7f44ed9db6d8>
'''
还可以用type来创建类
type除了可以用来查看一个变量的属性,同样也可以用来创建类
type("classname", 由父类名组成的tuple(), 由属性组成的dict{})#注意:这里这种方法只是用来保证版本的兼容性,不建议用
注意:这里的type就相当于一个元类
'''
# type动态创建类
Demo = type('Demo', (object,), {'dd':'dd'})
print(Demo())
print(Demo.dd)
<__main__.Demo object at 0x7f44ee2ce710>
dd
__metaclass__属性
用于指定创建class的类
'''
__metaclass__ = FatherName(这里也可以是一坨代码)
#这里是用于定义类的生成方式这里系统默认会指定,
但是自己写过后会自动调用自己的
'''
# 自定义类的生成方式
def upper_attr(future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():
if not name.startswith("__"):
newAttr[name.upper()] = value
#调用type来创建一个类
return type(future_class_name, future_class_parents, newAttr)
# python3 用法
class Foo(object, metaclass=upper_attr):
bar = 'bip'
# 在Python2中用如下操作:
# class NewClass(object):
# __metaclass__ = DiyClass
# pass
print(hasattr(Foo, 'bar'))
print(hasattr(Foo, 'BAR'))
f = Foo()
print(f.BAR)
False
True
bip
'''自定义类生成方式完整版'''
# 完整版
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# 你很少用到__new__,除非你希望能够控制对象的创建
# 这里,创建的对象是类,我们希望能够自定义它,所以我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 还有一些高级的用法会涉及到改写__call__特殊方法,但是我们这里不用
def __new__(cls, future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():
if not name.startswith("__"):
newAttr[name.upper()] = value
# 方法1:通过'type'来做类对象的创建
# return type(future_class_name, future_class_parents, newAttr)
# 方法2:复用type.__new__方法
# 这就是基本的OOP编程,没什么魔法
# return type.__new__(cls, future_class_name, future_class_parents, newAttr)
# 方法3:使用super方法
return super(UpperAttrMetaClass, cls).__new__(cls, future_class_name, future_class_parents, newAttr)
#python2的用法
# class Foo(object):
# __metaclass__ = UpperAttrMetaClass
# bar = 'bip'
# python3的用法
class Foo(object, metaclass = UpperAttrMetaClass):
bar = 'bip'
print(hasattr(Foo, 'bar'))
# 输出: False
print(hasattr(Foo, 'BAR'))
# 输出:True
f = Foo()
print(f.BAR)
# 输出:'bip'
False
True
bip
内建属性
__init__:创建实例后,赋值时使用,在__new__后
__new__:新建实例
__class__:实例.__class__
__str__:print()如果没有,使用repr结果,美化版repr
__repr__:类实例 回车 或者print(类实例),打印的结果是程序的表达方式
__del__:删除实例
__dict__:vars(类或实例.__dict__)
__doc__:help(类或实例)
__bases__:类名.__bases__
__getattribute__:访问实例属性时,属性拦截器(类属性和实例属性),会在所有属性使用之前调用
可以看做是看门的,访问属性前先走一遍__getattribute__才可以
def __getattribute__(self, obj):
pass
# __bases__例子
class C1(object):
pass
class C2(object):
pass
class C3(object):
pass
class C4(C3):
pass
class C5(C1, C2, C4):
pass
print(C5.__bases__)
(, , )
'''
由于__getattribute__拦截对所有属性的访问(包括对__dict__的访问),在使用中要十分小心地避开无限循环的陷阱。
在__getattribute__方法中访问当前实例的属性时,唯一安全的方式是使用基类(超类) 的__getattribute__方法(使用super)。
'''
# __getattribute__ 例子1
class Demo(object):
msg = "this is Demo class"
def __init__(self, name, age):
self.name = name
self.age = age
def __getattribute__(self, attr):
print("the attr: {} is block".format(attr))
try:
return super().__getattribute__(attr)
except AttributeError as result:
print("the attr of input: {} is not exit!".format(attr))
print("the Error is: \n\t", result)
demo = Demo('sh', 24)
print("类调用类属性结果:", Demo.msg)
print("实例调用类属性结果:")
print(demo.msg)
print("实例调用存在的实例属性结果:")
print(demo.name)
print("实例调用不存在的实例属性结果:")
print(demo.what)
# 注意:当访问的属性不存在并重载(覆盖基类对某方法的默认实现)了__getattribute__方法时,
# 该方法不会主动抛出AttributeError异常。
# 例子中捕获的AttributeError异常,是由基类的__getattribute__方法实现并抛出。
类调用类属性结果: this is Demo class
实例调用类属性结果:
the attr: msg is block
this is Demo class
实例调用存在的实例属性结果:
the attr: name is block
sh
实例调用不存在的实例属性结果:
the attr: what is block
the attr of input: what is not exit!
the Error is:
'Demo' object has no attribute 'what'
None
# __getattribute__ 例子2
class Demo(object):
def __init__(self, tmp1):
self.tmp1 = tmp1
self.tmp2 = "shj"
def __getattribute__(self, obj):
print("this obj is {}".format(obj).center(20, "*"))
if obj == "":
print("the input is {}".format(self.obj))
else:
tmp = object.__getattribute__(self, obj)
print("this is not if %s" %tmp)
return tmp
def test(self):
print("this is the function named test")
s = Demo("666")
print('test START')
print(s.tmp1)
print('000'*8)
print(s.tmp2)
s.test()
# 注意这里:这里调用的test方法是显示的一个绑定
# this is not if >
#这里说明,类中的方法同样作为一个属性
# this is the function named test
#通过这两个注意可以看到,类中的方法其实是不存在的,
# 而是通过创建一个属性,通过对属性绑定方法来达到创建方法的操作
__getattribute__的坑
class Demo(object):
def __getattribute__(self, obj):
print("这是一个关于attribute属性的坑")
if obj.startswith("a"):
return "666"
else:
return self.test
def test(self):
print("this is the function test")
d = Demo()
print(d.a)
# print(d.b)
#会让程序死掉
#原因是:当d.b执行时,会调用PDemo类中定义的__getattribute__方法,但是在这个方法的执行过程中
#if条件不满足,所以 程序执行else里面的代码,即return self.test 问题就在这,因为return 需要把
#self.test的值返回,那么首先要获取self.test的值,因为self此时就是d这个对象,所以self.test就是
#d.test 此时要获取d这个对象的test属性,那么就会跳转到__getattribute__方法去执行,即此时产
#生了递归调用,由于这个递归过程中 没有判断什么时候退出,所以这个程序会永无休止的运行下去,又因为
#每次调用函数,就需要保存一些数据,那么随着调用的次数越来越多,最终内存吃光,所以程序 崩溃
#
# 注意:以后不要在__getattribute__方法中调用self.xxxx
这是一个关于attribute属性的坑
666
__getattr__方法
执行需要满足两个必须条件:一是访问对象属性;二是触发AttributeError异常。
# __getattr__方法执行例子
class Demo(object):
msg = "this is Demo class"
def __init__(self, name, age):
self.name = name
self.age = age
def __getattribute__(self, attr):
print("the attr: {} is block".format(attr))
if attr not in Demo.__dict__:
raise AttributeError
def __getattr__(self, attr):
print("the method __getattr_ is runing")
demo = Demo('sh', 24)
demo.what
the attr: what is block
the method __getattr_ is runing
# 重载了__getattribute__方法,却没有主动抛出AttributeError异常的机制,
# 或者抛出一个其它类型的异常,__getattr__方法都不会执行。
class Demo(object):
msg = "this is Demo class"
def __init__(self, name, age):
self.name = name
self.age = age
def __getattribute__(self, attr):
print("the attr: {} is block".format(attr))
# if attr not in Demo.__dict__:
# raise AttributeError
def __getattr__(self, attr):
print("the method __getattr_ is runing")
demo = Demo('sh', 24)
demo.what
the attr: what is block
__setattr__方法
试图给属性赋值时自动调用该方法
当__setattr__(self, name, value)方法和__getattribute__(self, attr)方法同在时,每次赋值都会调用这两个方法,
因为__setattr__(self, name, value)方法出现赋值操作时必调用,包括在__init__(self)方法中的赋值操作
__getattribute__(self, attr)方法在出现访问属性操作时必调用
# __setattr_例子
class Demo(object):
msg = "this is Demo class"
def __init__(self, name, age):
self.name = name
self.age = age
def __getattribute__(self, attr):
print("the attr: {} is block".format(attr))
return super().__getattribute__(attr)
# if attr not in Demo.__dict__:
# raise AttributeError
def __getattr__(self, attr):
print("the method __getattr_ is runing")
def __setattr__(self, name, value):
print("the method __setattr__ is running")
self.__dict__[name] = value
demo = Demo('sh', 24)
demo.name = "haha"
# 这里出现多次重复输出是因为在__init__()方法初始化时赋值两次,调用__setattr__()两次
# 在自己赋值时:赋值一次,调用__setattr__()方法一次
# 而__getattribute__()方法和__setattr__()方法同在,访问属性和赋值均会依次调用
# 所以,会出现重复输出的结果
the method __setattr__ is running
the attr: __dict__ is block
the method __setattr__ is running
the attr: __dict__ is block
the method __setattr__ is running
the attr: __dict__ is block
# 在__setattr__方法中,不能使用self.attr = value的方法直接给属性赋值(会导致无限循环),
# 而通常的做法是使用self.__dict__[attr] = value的赋值方法
class Demo(object):
msg = "this is Demo class"
def __init__(self, name, age):
self.name = name
self.age = age
def __setattr__(self, name, value):
print("the method __setattr__ is running")
# self.name = value # 使用此方法赋值会出现无限循环的bug
'''以下代码运行会有死循环bug,故不运行'''
# demo = Demo('sh', 24)
# demo.name = "haha"
the method __setattr__ is running
the method __setattr__ is running
the method __setattr__ is running
the method __setattr__ is running
the method __setattr__ is running
the method __setattr__ is running
the method __setattr__ is running
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
in
12
13
---> 14 demo = Demo('sh', 24)
15 try:
16 start_time = time()
in __init__(self, name, age)
4
5 def __init__(self, name, age):
----> 6 self.name = name
7 self.age = age
8
in __setattr__(self, name, value)
9 def __setattr__(self, name, value):
10 print("the method __setattr__ is running")
---> 11 self.name = value # 使用此方法赋值会出现无限循环的bug
12
13
... last 1 frames repeated, from the frame below ...
in __setattr__(self, name, value)
9 def __setattr__(self, name, value):
10 print("the method __setattr__ is running")
---> 11 self.name = value # 使用此方法赋值会出现无限循环的bug
12
13
RecursionError: maximum recursion depth exceeded while calling a Python object
描述符
参考网址:
https://www.cnblogs.com/Lynnblog/p/9033455.html
链接已失效:网页404
https://blog.csdn.net/zhaoyun_zzz/article/details/82179481
描述符定义
'''
把实现了__get__()、__set__()和__delete__()中的其中任意一种方法的类称之为描述符,
描述符的本质是新式类,并且被代理的类(即应用描述符的类)也是新式类。
描述符的作用是用来代理一个类的属性,
需要注意的是描述符不能定义在类的构造函数中,只能定义为类的属性,它只属于类的,不属于实例。
'''
描述符种类及优先级
种类:
描述符分为数据描述符和非数据描述符。
数据描述符:至少实现了__get__()和__set__()方法
非数据描述符:没有实现__set__()
分类的原因是在访问属性时的搜索顺序上:
获取一个属性的时候:
优先级:
搜索链(或者优先链)的顺序:数据描述符>实体属性(存储在实体的dict中)>非数据描述符
解释:
- 首先,看这个属性是不是一个数据描述符,
如果是,就直接执行描述符的__get__(),并返回值。 - 其次,如果这个属性不是数据描述符,那就按常规去从
__dict__里面取属性,
如果__dict__里面还没有,但这是一个非数据描述符,
则执行非数据描述符的__get__()方法,并返回。 - 最后,找不到的属性触发
__getattr__()执行
而设置一个属性的值时,访问的顺序又有所不同
优先级:
类属性 > 数据描述符 > 实例属性 > 非数据描述符 > 找不到的属性触发__getattr__()
三种方法的调用及参数解释:
__get__(self, instance, owner):调用一个属性时,触发
__set__(self, instance, value):为一个属性赋值时,触发
__delete__(self, instance):采用del删除属性时,触发
参数解释:self: 是定义描述符的对象,不是使用描述符类的对象
instance: 这才是使用描述符类的对象
owner: 是instance的类(定义使用描述符的实例的类)
value: 是instance的值(使用描述符的实例的值)
# 对参数解释的例子
class Desc(object):
def __get__(self, instance, owner):
print("__get__...")
print("self : \t", self) # self : <__main__.Desc object at 0x7f957c069470>
print("instance : \t", instance) # instance : <__main__.TestDesc object at 0x7f957c069400>
print("owner : \t", owner) # owner : __set__...
self : <__main__.Desc object at 0x7fca10f46dd8>
instance : <__main__.TestDesc object at 0x7fca10f46e48>
value : 34
========================================
类属性>数据描述符
class Descriptors(object):
'''数据描述符'''
def __get__(self, instance, owner):
print('执行Descriptors的__get__()')
def __set__(self, instance, value):
print('执行Descriptors的__set__()')
def __delete__(self, instance):
print('执行Descriptors的__delete__()')
class DoDesc(object):
# 使用描述符
useDesc = Descriptors()
# test
DoDesc.useDesc # 执行描述符的get内置属性
print(DoDesc.__dict__) # 此时name显示的是描述符的对象
DoDesc.useDesc = 'TEST' # 未执行set内置属性
print(DoDesc.useDesc) # TEST
del DoDesc.useDesc # 未执行delete内置属性
# print(DoDesc.useDesc) # 报错,因为属性被删除了,无法找到
执行Descriptors的__get__()
{'__module__': '__main__', 'useDesc': <__main__.Descriptors object at 0x7f957c0424a8>, '__dict__': , '__weakref__': , '__doc__': None}
TEST
数据描述符>实例属性
数据描述符的优先级大于实例属性的优先级,
此时实例属性name被数据描述符所覆盖,
而price没有描述符代理,所以它仍然是实例属性。
class Descriptors:
"""
数据描述符
"""
def __get__(self, instance, owner):
print("执行Descriptors的get")
def __set__(self, instance, value):
print("执行Descriptors的set")
def __delete__(self, instance):
print("执行Descriptors的delete")
class Light:
#使用描述符
name = Descriptors()
def __init__(self, name, price):
self.name = name
self.price = price
#使用类的实例对象来测试
light = Light("电灯泡",60) #执行描述符的set内置属性
light.name #执行描述符的get内置属性
print(light.__dict__) #查看实例的字典,不存在name
print(Light.__dict__) #查看类的字典,存在name(为描述符的对象)
del light.name #执行描述符的delete内置属性
执行Descriptors的set
执行Descriptors的get
{'price': 60}
{'__module__': '__main__', 'name': <__main__.Descriptors object at 0x7f957c05a0b8>, '__init__': , '__dict__': , '__weakref__': , '__doc__': None}
执行Descriptors的delete
实例属性>非数据描述符
实例属性中使用了非数据描述符,就不能对其进行复制操作。
可见非数据描述符应该应用于不需要设置值的属性或者函数中。
class Descriptors:
"""
非数据描述符
"""
def __get__(self, instance, owner):
print("执行Descriptors的set")
def __delete__(self, instance):
print("执行Descriptors的delete")
class Light:
#使用描述符
name = Descriptors()
def __init__(self, name, price):
self.name = name
self.price = price
#测试
light = Light("电灯泡",60) #报错,描述符中没有__set__()方法
---------------------------------------------------------------
AttributeError Traceback (most recent call last)
in
18
19 #测试
---> 20 light = Light("电灯泡",60) #报错,描述符中没有__set__()方法
in __init__(self, name, price)
14
15 def __init__(self, name, price):
---> 16 self.name = name
17 self.price = price
18
AttributeError: __set__
'''
在该类中并没有set方法,所以该类是一个非数据描述符,
Python中一切皆对象,函数也是一个对象,
既然是对象那也可以是类实例化所得到的结果。
函数在类中本身也是一种属性(函数属性),
描述符在应用的时候也是被实例化为一个属性。
'''
class Descriptors:
"""
非数据描述符
"""
def func(self):
print("世界的变化真快!近日00后都已经开始在街头打小三了")
d = Descriptors()
d.func()
print(hasattr(Descriptors.func,"__set__")) #False
print(hasattr(Descriptors.func,"__get__")) #True
print(hasattr(Descriptors.func,"__delete__")) #False
d.func = "函数也是属性,也可以赋值,没毛病"
print('print: ',d.func)
del d.func
d.func
世界的变化真快!近日00后都已经开始在街头打小三了
False
True
False
print: 函数也是属性,也可以赋值,没毛病
>
描述符使用注意点
'''
描述符必须定义在类层次上,否则Python无法自动调用设置的__get__()和__set__()
访问类层次上的描述符可以自动调用__get__(),但是访问实例层次上的描述符只会返回描述符本身
描述符在所有的实例间共享数据(描述符是类属性的一种)
'''
# 使用注意点 例子
class Desc(object):
def __init__(self, name):
self.name = name
def __get__(self, instance, owner):
print("__get__...")
print('name = ', self.name)
print('=' * 40, "\n")
class TestDesc(object):
x = Desc('x')
def __init__(self):
self.y = Desc('y')
# 以下为测试代码
t = TestDesc()
t.x # 相当于默认值
print(t.__dict__)
print(t.y) # 在__init__中对描述符有了新的赋值
__get__...
name = x
========================================
{'y': <__main__.Desc object at 0x7f957c024860>}
<__main__.Desc object at 0x7f957c024860>
描述符使用
常使用的@classmethod、@staticmethd、@property、甚至是__slots__等属性都是通过描述符来实现的。
# 1. 模拟 @classmethod
class Imitate_classmethod(object):
'''使用描述符模拟@classmethod'''
def __init__(self, func):
self.func = func
def __get__(self, instance, owner):
# 对传入的函数加工,并返回加工后的函数
def maching_func(*args, **kwargs):
print('函数加工后,返回实例的类')
return self.func(owner, *args, **kwargs)
return maching_func
class Test(object):
msg = '这是一个对描述符模拟classmethod的测试'
# 这里是一个类装饰器
@Imitate_classmethod
def about(cls):
print('print: ', cls.msg)
@Imitate_classmethod
def about_var(cls, value):
print('pirnt: {}, 传入的值为:{}'.format(cls.msg, value))
# test
t = Test()
Test.about()
Test.about_var(666)
print('\n下面是Test实例的输出:\n')
t.about()
t.about_var(777)
函数加工后,返回实例的类
print: 这是一个对描述符模拟classmethod的测试
函数加工后,返回实例的类
pirnt: 这是一个对描述符模拟classmethod的测试, 传入的值为:666
下面是Test实例的输出:
函数加工后,返回实例的类
print: 这是一个对描述符模拟classmethod的测试
函数加工后,返回实例的类
pirnt: 这是一个对描述符模拟classmethod的测试, 传入的值为:777
'''
2. 模拟 @staticmethod
staticmethod方法与classmethod方法的区别在于:
classmethod方法在使用需要传进一个类的引用作为参数。
而staticmethod则不用。
'''
# 例子
class Imitate_staticmethod:
'''
使用描述符模拟@staticmethod
'''
def __init__(self, func):
self.func = func
def __get__(self, instance, owner):
#对传进函数进行加工,最后返回该函数
def machining_func(*args, **kwargs):
print("函数加工处理后,返回实例的类")
return self.func(*args, **kwargs)
return machining_func
class Test:
@Imitate_staticmethod
def static_func(*args):
print("您输入的是:",*args)
#测试
Test.static_func("柠檬","香蕉")
test = Test()
test.static_func(110, 112)
函数加工处理后,返回实例的类
您输入的是: 柠檬 香蕉
函数加工处理后,返回实例的类
您输入的是: 110 112
'''
3. 模拟 @property
在下面的代码中,
将描述符的回调结果存入对象字典中的好处是以后再执行函数时就不会每一次都触发描述的运行,从而提高程序的效率。
这样,我们有再执行同样的函数时,解释器会先检索对象的字典,
如果字典存在上次执行结果的值,那就不用触发描述符的运行了。
在这个实验中必须强调的一点是描述符的优先级,
我们想让程序的描述符不能覆盖实例属性就必须使用非数据描述符。所以因需求不同,描述符的优先级也不同。
'''
# 例子
class Imitate_property:
'''使用描述符模拟property'''
def __init__(self, func):
self.func = func
def __get__(self, instance, owner):
if instance is None:
return self
#回调传入的函数,将运行结果保存在变量res中
res = self.func(instance)
#为函数名func.__name__设置一个值res后存入对象的字典中
setattr(instance, self.func.__name__, res)
return res
class Test:
def __init__(self, value):
self.value = value
@Imitate_property
def function(self):
return self.value**2
test = Test(2)
print(test.function) #输出:4
print(test.__dict__) #输出:{'value': 2, 'function': 4}
print(test.function) #输出:4
print(test.function) #输出:4
print(test.__dict__) #输出:{'value': 2, 'function': 4}
4
{'value': 2, 'function': 4}
4
4
{'value': 2, 'function': 4}
错误和异常
'''
try: # 在try中的异常后的代码不会执行,程序会跳转到except中对异常进行处理
pass # 需要捕获异常的代码块
except ExceptName as result: # 捕获异常ExceptName并将异常重命名为result
pass # 对捕获异常的处理代码块
[
except Exp1 as result1: # except 捕获语句可以有多条,不冲突即可
pass
...
]
Exception :是异常总和,所有异常都可被此异常捕获
当捕获的异常和设定的异常名称不对应时,会进行系统异常处理。
try: # 开启捕获
pass
except Exp: # 捕获到异常时执行
pass
else: # 没有捕获到异常时执行
pass
finally: # 收尾工作,不论是否捕获到异常都会执行
pass
'''
捕获多个异常
'''
将异常名放入元组中存储
try:
pass
except (err1, err2 [,err...]):
pass
'''
# 异常 多个异常 例子
try:
1/0
open("sss0")
except NameError:
print("try中出现NameError的异常")
except Exception as result:
print("这里出现一个笼统的异常,{}".format(result))
else:
print("try中没有异常时打印")
finally:
print("不管try中是否有异常,都会执行finally")
print("异常测试结束")
# 例子结束
这里出现一个笼统的异常,division by zero
不管try中是否有异常,都会执行finally
异常测试结束
异常的嵌套
'''
内部try未捕获到异常,向外部逐层传递
try:
try:
pass
except Exp1:
pass
pass
except Exp2:
pass
'''
自定义异常
'''raise'''
# 用户自定义异常例子
class UserError(Exception):
def __init__(self):
print("这里是用户自定义的异常")
try:
raise UserError
except UserError:
print("抛出自定义异常")
else:
print("没有异常")
# 例子结束
这里是用户自定义的异常
抛出自定义异常
异常处理中抛出异常
'''
try:
Error
except exception as result:
if (pass):
pass # 开启捕获异常
print(result)
else:
pass # 重写抛出异常,此时的异常不会被捕获,交由系统处理
raise
'''
调试
最简单
断言(assert)
在程序中可以用print的地方就可以用断言(assert)
assert expression, throwException
表达式expression应该为True,否则,抛出AssertionError:throwException
python -O fileName.py 关闭断言
# assert 例子
def judger(name):
# name!='username'为True,继续运行,False抛出your name is error!异常
assert name != 'username','your name is error!'
print('123456')
def main():
judger('username')
if __name__=='__main__':
main()
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
in ()
9
10 if __name__=='__main__':
---> 11 main()
12
in main()
6
7 def main():
----> 8 judger('username')
9
10 if __name__=='__main__':
in judger(name)
2 def judger(name):
3 # name!='username'为True,继续运行,False抛出your name is error!异常
----> 4 assert name != 'username','your name is error!'
5 print('123456')
6
AssertionError: your name is error!
logging
这篇文章对常用模块总结的很好,有所参照。导向链接
地址:https://www.cnblogs.com/wf-linux/archive/2018/08/01/9400354.html
logging 不会抛出异常,可以把调试信息输出到文件
logging 还可以指定记录信息级别(debug, info, warning, error)
指定level = INFO时,logging.debug就失效,其他级别设定同理。
logging可以通过简单的配置,一条语句同时输出到不同地方,比如:console和文件。
import logging
logging.basicConfig(level=[INFO,DEBUG,WARNING,ERROR,CRITICAL],
filename="your_log_file_name",
filemode='r,w,a',
format='your_log_format')
参数解释:
level:日志记录级别
filename:日志文件
filemode:日志文件的打开模式
format:日志记录格式参数:作用
%(levelno)s:打印日志级别的数值
%(levelname)s:打印日志级别的名称
%(pathname)s:打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s:打印当前执行程序名
%(funcName)s:打印日志的当前函数
%(lineno)d:打印日志的当前行号
%(asctime)s:打印日志的时间
%(thread)d:打印线程ID
%(threadName)s:打印线程名称
%(process)d:打印进程ID
%(message)s:打印日志信息
# logging 简单例子
import logging
file_name='./Gnerate_files/logging_test.log'
logging.basicConfig(
level=logging.INFO,
filename=file_name,
filemode='w+', # 这里针对本例子使用w,但是日志记录时不建议使用w
format='%(lineno)s\t%(asctime)s: %(name)s: %(levelname)s: %(message)s')
logger = logging.getLogger(name=__name__)
logger.info("Start print log INFO")
logger.debug("Start print log DEBUG")
logger.warning("Start print log WARNING")
logger.info("the print log INFO is end")
print("日志文件内容:")
with open(file_name, 'r', encoding='utf-8', buffering=1024) as file:
lines = file.readlines()
for line in lines:
print(line)
日志文件内容:
14 2020-02-07 13:18:03,459: __main__: INFO: Start print log INFO
16 2020-02-07 13:18:03,460: __main__: WARNING: Start print log WARNING
17 2020-02-07 13:18:03,460: __main__: INFO: the print log INFO is end
'''logger中添加StreamHandler,可以将日志输出到屏幕上'''
# 将日志同时输出到屏幕和日志文件例子
import logging
file_name = './Gnerate_files/logging_test_f_c.log'
loggerc = logging.getLogger(__name__)
loggerc.setLevel(level=logging.INFO)
handler = logging.FileHandler(file_name, mode='w+', encoding='utf-8')
handler.setLevel(logging.INFO)
formatter = logging.Formatter(
'%(asctime)s: %(name)s %(levelname)s %(message)s')
handler.setFormatter(formatter)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
loggerc.addHandler(handler)
loggerc.addHandler(console)
loggerc.info("Start print log INFO")
loggerc.debug("Start print log DEBUG")
loggerc.warning("Start print log WARNING")
loggerc.info("the print log INFO is end")
print("日志文件内容:")
with open(file_name, 'r', encoding='utf-8', buffering=1024) as file:
lines = file.readlines()
for line in lines:
print(line)
Start print log INFO
Start print log WARNING
the print log INFO is end
日志文件内容:
2020-02-07 13:18:10,353: __main__ INFO Start print log INFO
2020-02-07 13:18:10,355: __main__ WARNING Start print log WARNING
2020-02-07 13:18:10,356: __main__ INFO the print log INFO is end
pdb调试
pdb 调试有个明显的缺陷就是对于多线程,远程调试等支持得不够好,
同时没有较为直观的界面显示,不太适合大型的 python 项目。
pdb操作指令
| 命令 | 简写 | 功能 | 注解 |
|---|---|---|---|
| break | b | 设置断点 | 无 |
| continue | c | 继续执行程序 | 无 |
| list | l | 查看当前行的代码 | 无 |
| step | s | 进入函数 | 无 |
| return | r | 执行代码直到从当前函数返回 | 无 |
| quit | q | 终止并退出 | 无 |
| next | n | 执行下一行 | 无 |
| p | 打印变量的值 | 无 | |
| help | h | 帮助 | 无 |
| args | a | 查看传入参数 | 无 |
| 回车 | 重复上一条命令 | 无 | |
| break | b | 显示所有断点 | 无 |
| break lineno | b lineno | 在指定行设置断点 | 无 |
| break file:lineno | b file:lineno | 在指定文件的行设置断点 | 无 |
| clear num | 删除指定断点 | 这里的num不是添加断点的行号,而是断点的序号 | |
| bt | 查看函数调用栈帧 | 无 |
pdb交互调试
import pdb
pdb.run(funcName(attribute)) # 这里需要在pdb中先按s,然后才可以l,不然不会显示代码
pdb程序里埋点
import pdb
pdb.set_trace() # 当程序遇到这句话时才进入调试
垃圾回收
参考网址:https://www.cnblogs.com/jin-xin/articles/9439483.html
概括:
同一代码块下:缓存机制
不同代码块:小数据池
代码块
一个模块、一个函数、一个类、一个文件都是一个代码块。
在交互式命令行下,一个命令就是一个代码块。
代码块的缓存机制
Python在执行同一个代码块的初始化对象的命令时,
会检查是否其值是否已经存在,如果存在,会将其重用。
换句话说:
执行同一个代码块时,遇到初始化对象的命令时,
他会将初始化的这个变量与值存储在一个字典中,
在遇到新的变量时,会先在字典中查询记录,
如果有同样的记录那么它会重复使用这个字典中的之前的这个值。
满足缓存机制则他们在内存中只存在一个,即:id相同。
代码块的缓存机制的适用范围: int(float),str,bool。
int(float):任何数字在同一代码块下都会复用。
bool:True和False在字典中会以1,0方式存在,并且复用。
str:几乎所有的字符串都会符合缓存机制
1,非乘法得到的字符串都满足代码块的缓存机制
2,乘法得到的字符串分两种情况:
2.1 乘数为1时,任何字符串满足代码块的缓存机制:
2.2 乘数>=2时:仅含大小写字母,数字,下划线,
总长度<=20,满足代码块的缓存机制
优点:
能够提高一些字符串,整数处理人物在时间和空间上的性能;
需要值相同的字符串,整数的时候,直接从‘字典’中取出复用,避免频繁创建和销毁,提升效率,节约内存。
'''jupyter这里运行存在问题,以注释为主'''
# 字符串缓存机制 例子
# 非乘法得到的字符串
def unMult():
s1 = 'string'
s2 = 'string'
print('非乘法得到的字符串')
print('*'*30)
print('s1和s2地址比较:',id(s1) == id(s2)) # True
print('*'*30)
# 乘数为1得到的字符串
def multOne():
s3 = 'asdf!@#$%^*'*1
s4 = 'asdf!@#$%^*'*1
print('乘数为1得到的字符串')
print('*'*30)
print('s3和s4地址比较:',id(s3) == id(s4)) # True
print('*'*30)
# 乘数>=2时
def multMore():
s3 = 'adf!'*4 # 包含其他字符,总长<20
s4 = 'adf!'*4
s5 = 'qwertyuiop[]asdfghjk!@#$%^&'*4
# 包含其他字符,总长>20
s6 = 'qwertyuiop[]asdfghjk!@#$%^&'*4
s7 = 'asdf_asdf'*3 # # 不包含其他字符,总长<20
s8 = 'asdf_asdf'*3
print('乘数为>=2,总长度<=20,包含其他字符得到的字符串')
print('*'*30)
print('s3和s4地址比较:',id(s3) == id(s4)) # False
print('*'*30)
print('乘数为>=2,总长度>20,包含其他字符得到的字符串')
print('*'*30)
print('s5和s6地址比较:',id(s5) == id(s6)) # False
print('*'*30)
print('乘数为>=2,总长度<=20,不包含其他字符得到的字符串')
print('*'*30)
print('s7和s8地址比较:',id(s7) == id(s8)) # True
print('*'*30)
# test
unMult()
multOne()
multMore()
非乘法得到的字符串
******************************
s1和s2地址比较: True
s1和s2来源比较: True
******************************
乘数为1得到的字符串
******************************
s3和s4地址比较: True
s3和s4来源比较: True
******************************
乘数为>=2,总长度<=20,包含其他字符得到的字符串
******************************
s3和s4地址比较: True
s3和s4来源比较: True
******************************
乘数为>=2,总长度>20,包含其他字符得到的字符串
******************************
s5和s6地址比较: True
s5和s6来源比较: True
******************************
乘数为>=2,总长度<=20,不包含其他字符得到的字符串
******************************
s7和s8地址比较: True
s7和s8来源比较: True
******************************
小数据池
大前提:
小数据池也是只针对 int(float),str,bool。
小数据池是针对不同代码块之间的缓存机制!!!
Python自动将-5~256的整数进行了缓存,
当你将这些整数赋值给变量时,并不会重新创建对象,
而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中创建一份。
'''小数据池例子'''
# 整数
a = 100
b = 100
c = 123456
d = 123456
print('id(a) == id(b): ',id(a) == id(b))
print('id(c) == id(d): ',id(c) == id(d))
id(a) == id(b): True
id(c) == id(d): False
指定驻留
# 指定驻留 例子
from sys import intern
a = 'asd*&'*3
b = 'asd*&'*3
print('未指定驻留:a is b:', a is b)
print(id(a))
print(id(b))
c = intern('asd*&'*3)
d = intern('asd*&'*3)
print('指定驻留:c is d:', c is d)
print(id(c))
print(id(d))
未指定驻留:a is b: False
139839647396976
139839643255088
不未指定驻留:c is d: True
139839642805680
139839642805680
引用计数
Python中以引用计数为主:
引用计数优点:简单,实时性
引用计数缺点:维护时占用内存,循环引用,造成内存泄漏
引用计数减一不止del,还可以透过赋值None
隔代回收
Ruby中的垃圾回收是标记清除,对内存的申请是一次申请多个,
当内存不够用时再清理,而Python中的内存申请是用一个申请一个。
隔代回收为辅:
零代链表中检测到相互循环引用的减一,得到是否是垃圾(引用计数为0),需要回收,否则不会减一
GC模块
'''
gc.get_count():获取当前自动执行垃圾回收的计数器
返回一个元组(x,y,z)
参数解释:
[
x 表示内存占用,
y 表示零代清理次数,
z 同理表示1代清理次数
]
gc.get_threshold() 获取的gc模块中自动执行垃圾回收的频率
返回(x,y,z)
参数解释:
[
x表示清理上限,
y表示每清理零代链表10次,
清理一次 1 代链表。
z同理是1,2代 这里的x,y,z默认值为(700,10,10)
]
查看一个对象的引用计数:
sys.getrefcount()
gc.disable() 关闭Python的gc
gc.enable() 开启gc
gc.isenabled() 判断是否是开启gc的
gc.collect([generation])显式进行垃圾回收(手动回收)
可以输入参数:
[
0代表只检查第一代的对象,
1代表检查一,二代的对象,
2代表检查一,二,三代的对象,
如果不传参数,执行一个full collection,也就是等于传2。
]
注意:
尽量不要手动重写对象的__del__方法,
因为重写后会使删除时不会自动调用gc来删除,
此时需要调用父类的__del__()来删除
'''
# gc 引用计数 示例
import gc, sys
a = 1
get_a_c = sys.getrefcount(a)
b = a
get_b_c = sys.getrefcount(a)
gc_c = gc.get_count()
gc_t = gc.get_threshold()
gc.disable()
gc.enable()
gc_is = gc.isenabled()
gc_cl = gc.collect(2)
print(get_a_c, get_b_c, gc_c, gc_t, gc_is, gc_cl)
2275 2275 (603, 5, 0) (700, 10, 10) True 921
内置方法
参考网址:http://www.runoob.com/python3/python3-built-in-functions.html
'''
range(start, stop, step)
Python2中直接生成,Python3中生成器的生成方式
xrange():
Python2中:功能和range()一样,但是是生成器形式的,需要next()调用
map(function, sequence[, sequence]) 返回list
参数解释:
[
function 一个函数
sequence 一个或多个序列, 取决于function需要几个参数
这里参数序列中的每一个元素分别调用function,
返回包含每次function的函数返回值的list
]
'''
# map功能演示
a = map(lambda x:x+x, [y for y in range(1,5,1)])
'''对list [1,2,3,4]中的每一个元素进行自身叠加操作'''
print(a)
for i in a :
print(i) # 输出叠加结果
'''
filter(function, iterable) 用于过滤序列
参数解释:
[
function 判断函数,返回True或False,
iterable 可迭代对象
]
'''
# filter 过滤奇数(不可被2整除)
def is_odd(num):
'''判断函数,返回值为bool类型'''
return num % 2 == 1
l = [1,2,3,4,5,6,7,8,9,10]
newlist = filter(is_odd, l)
print('过滤结果:newlist: ', newlist)
print('得到奇数列表:', list(newlist))
过滤结果:newlist:
得到奇数: [1, 3, 5, 7, 9]
'''
reduce(function, iterable[, initial]) 对可迭代对象进行连续累积操作,
可以加减乘除等
参数解释:
[
function(x,y) 处理函数,有两个参数
iterable 可迭代对象
initial 可选参数,初始参数
]
function 同样可是是lambda函数
在Python3中,reduce合并到functools里
'''
# Python3 reduce()使用 例子:计算iterable的累加
from functools import reduce # 导入reduce
def add(x, y):
'''定义处理函数:加操作'''
return x + y
numlist = [1,2,3,4,5,6] # 可迭代对象,要处理的对象
sum = reduce(add, numlist) # 对numlist实现累加操作
print(numlist,'累加结果:',sum)
# lambda函数实现累乘
produce = reduce(lambda x,y: x*y, numlist) # 结果为720
print(numlist,'累乘结果:',produce)
[1, 2, 3, 4, 5, 6] 累加结果: 21
[1, 2, 3, 4, 5, 6] 累乘结果: 720
'''
sorted(iterable, key=None, reverse=False) 对可迭代对象进行排序(升序[A-Z])
参数解释:
[
iterable 可迭代对象
key 主要用来比表的元素,具体可取自可迭代对象中,
指定可迭代对象的一个元素
reverse 排序规则,reverse=True,降序[Z-A],reverse=False,升序[A-Z](默认)
]
sort() 应用在list中
sorted() 应用在所有可迭代对象
'''
# sort() sorted() 例子
alist = [1,2,45,3,12,6,33,44]
astring = 'asdfqwer1'
alist.sort()
sorted_str = sorted(astring)
print('sort(): ',alist,'\nsorted(): ', sorted_str)
sort(): [1, 2, 3, 6, 12, 33, 44, 45]
sorted(): ['1', 'a', 'd', 'e', 'f', 'q', 'r', 's', 'w']
pep8规则
pep8官网规范地址
https://www.python.org/dev/peps/pep-0008/
每级缩进 4个空格
函数中的形参过长,换行时建议对齐
类间隔两个空行
方法间隔一个空行
导入在单独行
import os
import sys
导库:标准库,第三方,本地(个人)
禁止使用通配符导入
类名,驼峰命名,模块,全程小写,可以用下划线
逗号,冒号,分号之前避免空格
赋值等操作符前后不能因为对齐而添加多个空格
二元运算符两边放置一个空格
关键字参数和默认值参数的前后不要加空格
索引操作中的冒号当作操作符处理前后要有同样的空格(一个空格或者没有空格)
函数调用的左括号之前不能有空格
最大行宽
限制所有行的最大行宽为79字符。
文本长块,比如文档字符串或注释,行长度应限制为72个字符。
进程
进程定义
参考网址:https://www.cnblogs.com/gengyi/p/8564052.html
‘'''
进程:
进程是程序的一次动态执行过程,它对应了从代码加载、
执行到执行完毕的一个完整过程。
进程是系统进行资源分配和调度的一个独立单位。
进程是由代码(堆栈段)、数据(数据段)、内核状态和一组寄存器组成。
在多任务操作系统中,通过运行多个进程来并发地执行多个任务。
由于每个线程都是一个能独立执行自身指令的不同控制流,
因此一个包含多个线程的进程也能够实现进程内多任务的并发执行。
进程是一个内核级的实体,进程结构的所有成分都在内核空间中,
一个用户程序不能直接访问这些数据。
进程的状态:
创建、准备、运行、阻塞、结束。
进程间的通信方式:
(1)管道(pipe)及有名管道(named pipe):
管道可用于具有亲缘关系的父子进程间的通信,有名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
(2)信号(signal):
信号是在软件层次上对中断机制的一种模拟,它是比较复杂的通信方式,
用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上可以说是一致的。
(3)消息队列(message queue):
消息队列是消息的链接表,它克服了上两种通信方式中信号量有限的缺点,
具有写权限的进程可以按照一定得规则向消息队列中添加新信息;对消息队列有读权限的进程则可以从消息队列中读取信息。
(4)共享内存(shared memory):
可以说这是最有用的进程间通信方式。
它使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据得更新。
这种方式需要依靠某种同步操作,如互斥锁和信号量等。
(5)信号量(semaphore):
主要作为进程之间及同一种进程的不同线程之间得同步和互斥手段。
(6)套接字(socket):
这是一种更为一般得进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
Python中进程创建:
os.fork()
subprocess
processing
multiprocessing
'''
创建进程
linux专供版
这里的fork()只是用于Linux(unix)仅作为了解
不要在jupyter notebook中进行大量或多次fork执行,会大量占用cpu,导致卡顿
fork 侧重于父子进程都有任务,适合于少量的子进程创建
父进程、子进程执行顺序没有规律,完全取决于操作系统的调度算法
import os
pid = os.fork()
fork()是唯一调用一次返回两次的函数,因为操作系统将父进程复制一份形成新的进程(子进程),然后分别在父进程和子进程内返回。
父进程和子进程都会从fork()函数中得到一个返回值,子进程永远返回0,而父进程返回子进程的ID。
一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
通过os.getpid()获取当前进程的pid通过os.getppid()获取当前进程父进程的pid
这里可以把fork理解为鸣人影分身的deepcopy模式,完全克隆出一个自己,对分分支后的任务进行执行
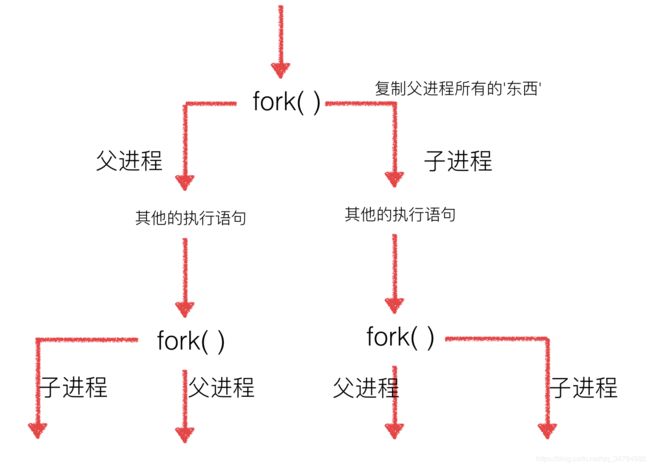
# fork() 例子
import os # fork()在os模块下
def prt():
print('我在fork前')
prt()
def use_fork():
pid = os.fork() # 进程在这里fork,产生一个新的进程,返回新进程的pid
if pid<0:
print('fork调用失败')
elif pid == 0: # 子进程
print('我是子进程<{}>,我的父进程为:<{}>'.format(os.getpid(), os.getppid()))
# 打印子进程pid,父进程pid
else: # 父进程
print('我是父进程<{}>,我的子进程为<{}>'.format(os.getpid(), pid))
# 打印父进程pid,子进程pid
print('父子进程都可以执行这行') # 分支执行结束,回归执行程序主干
use_fork()
我在fork前
我是父进程<4134>,我的子进程为<5573>
父子进程都可以执行这行
我在fork前
我是子进程<5573>,我的父进程为:<4134>
父子进程都可以执行这行
'''多进程中,每个进程中所有数据(包括全局变量)都各有拥有一份,互不影响'''
# fork() 内修改全局变量 例子
import os # fork()在os模块下
num = 12
print('未fork的全局变量:', num)
pid = os.fork() # 进程在这里fork,产生一个新的进程,返回新进程的pid
if pid<0:
print('fork调用失败')
elif pid == 0: # 子进程
print('我是子进程<{}>,我的父进程为:<{}>'.format(os.getpid(), os.getppid()))
num += 3
print('子进程修改num为num+=3:{}'.format(num))
else: # 父进程
print('我是父进程<{}>,我的子进程为<{}>'.format(os.getpid(), pid))
num += 5
print('父进程修改num为 num+=5:{}'.format(num))
print('num:',num) # 分支执行结束,回归执行程序主干
未fork的全局变量: 12
我是父进程<6203>,我的子进程为<6301>
父进程修改num为:17
num: 17
我是子进程<6301>,我的父进程为:<6203>
子进程修改num为:15
num: 15
'''多个fork()同时出现'''
# 多个fork()同时出现
import os, time
ret = os.fork()
if ret ==0:
print("1".center(10, "*"))
else:
print("2".center(10,"*"))
ret = os.fork()
if ret == 0:
print("11".center(10,"-"))
else:
print(print("22".center(10,"+")))
# 父进程、子进程执行顺序没有规律,完全取决于操作系统的调度算法
# 注意:这里的结果中,包含了两个11,22
# 这里和前边说的在fork()处分开后,代码都会分别执行,
# 也就是后边的fork()是在单个进程中的再一次分进程了
****1*****
****2*****
++++22++++
None
++++22++++
----11----
----11----
None
ERROR! Session/line number was not unique in database. History logging moved to new session 194
ERROR! Session/line number was not unique in database. History logging moved to new session 195
getpid、getppid
getpid()获得当前进程的pid
getppid()获得当前进程的父进程
在新建进程之后子进程和父进程执行的基本一样(这里只是不执行父进程专有的代码,其他的代码子进程同样会执行)
全局变量在多个进程中不共享
# getpid getppid 例子
import os, time
g_num = 666
tmp = os.fork()
if tmp == 0:
print("*"*20)
print(g_num)
g_num +=111
time.sleep(2)
print("this is son pid = {0}, ppid = {1}, g_num_id = {2}, g_num = {3}".format(os.getpid(), os.getppid(), id(g_num), g_num))
else:
print("*"*20)
print(g_num)
print("this is father pid = {0}, ppid = {1}, g_num_id = {2}, g_num = {3}".format(os.getpid(), os.getppid(), id(g_num), g_num))
********************
666
this is father pid = 6203, ppid = 6087, g_num_id = 140675625067056, g_num = 666
********************
666
this is son pid = 6941, ppid = 6203, g_num_id = 140675685461968, g_num = 777
multiprocessing
multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象
代码if __name__=='__main__':在Process使用中必须有
'''Process 创建子进程'''
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('子进程运行中,name= %s ,pid=%d...' % (name, os.getpid()))
if __name__=='__main__': # 判断是否在当前模块下
print('父进程 %d.' % os.getpid())
p = Process(target=run_proc, args=('test',)) # 创建子进程
print('子进程将要执行')
p.start()
p.join()
print('子进程已结束')
父进程 6203.
子进程将要执行
子进程运行中,name= test ,pid=7030...
子进程已结束
'''
对例子的说明:
创建子进程时,只需要传入一个执行函数和函数的参数,
创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
'''
Process
Process 语法:
Process([group[, target[, name[, args[, kwargs]]]]])
参数解释:
group: 线程组,目前还没有实现,库引用中提示必须是None;
target: 要执行的方法; 进程实例所调用对象
name: 进程名; 当前进程的别名
args/kwargs: 要传入方法的参数(参数元组/参数字典)。
Process类常用方法:
is_alive() 判断进程实例是否还在执行
join([timeout]) 是否等待进程实例执行结束,timeout为等待超时时间(秒级)
需要注意:p.join只对start方式开启的进程有效,对run方式开启的进程无效。
start() 启动进程实例,并调用该子进程中的p.run()
run() 进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
terminate() 不管任务是否完成,立即终止
不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。
如果p还保存了一个锁那么也将不会被释放,进而导致死锁
Process 属性:
daemon:守护进程标识,:默认值为False,如果设为True,代表p为后台运行的守护进程,
当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程。
必须在p.start()之前设置
exitcode:进程的退出状态码(进程运行时为None,-N表示被信号N结束)
name:进程名
pid:进程号
authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。
这个键的用途是为涉及网络连接的底层进程间通信提供安全性,
这类连接只有在具有相同的身份验证键时才能成功(了解即可)
# 例子
from multiprocessing import Process
import os
from time import sleep
# 子进程执行代码
def run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,i = {}, name = {}, age = {}, pid = {}'.format(
i, name, age, os.getpid()
))
print(kwargs)
sleep(0.5) # 挂起0.5s
if __name__=='__main__':
print('父进程:',os.getpid())
p = Process(target=run_proc, args=('test',22), kwargs={'num':123456})
print('子进程将执行')
p.start()
sleep(1) # 挂起1s
p.terminate()
p.join()
print('子进程结束')
父进程: 6203
子进程将执行
子进程运行中,i = 0, name = test, age = 22, pid = 7697
{'num': 123456}
子进程运行中,i = 1, name = test, age = 22, pid = 7697
{'num': 123456}
子进程结束
# process 例子2
from multiprocessing import Process
import time
import os
#两个子进程将会调用的两个方法
def worker_1(interval):
print('worker_1, 父进程<{}>,当前进程<{}>'.format(os.getppid(), os.getpid()))
t_start = time.time()
time.sleep(interval) # 挂起interval秒
t_end = time.time()
print('worker_1执行时间为{}'.format(t_end-t_start))
def worker_2(interval):
print('worker_2, 父进程<{}>,当前进程<{}>'.format(os.getppid(), os.getpid()))
t_start = time.time()
time.sleep(interval) # 挂起interval秒
t_end = time.time()
print('worker_2执行时间为{}'.format(t_end-t_start))
# 输出当前程序的id
print('进程pid:', os.getpid()) # 进程pid: 6203
# 创建两个进程对象,target指向进程对象要执行的方法,
# args后的元组是要传递给work_1()中的interval参数
# 若不指定name参数,默认的进程对象名称为Process-N,N为一个递增的整数
p1=Process(target=worker_1,args=(3,))
p2=Process(target=worker_2,name='Dog',args=(1,))
# 使用<进程对象.start()>来创建并执行一个子进程
# 创建的两个进程在start后分别执行worker_1和worker_2中的代码
p1.start()
p2.start()
# 同时父进程仍然向下执行,若p2进程还在执行,将返回Ture
print('p2.isalive=',p2.is_alive())
# 输出p1和p2进程的别名和pid
print('p1.name={}\tp1.pid={}'.format(p1.name, p1.pid)) # p1.name=Process-12 p1.pid=8048
print('p2.name={}\tp2.pid={}'.format(p2.name, p2.pid)) # p2.name=Dog p2.pid=8049
# join() timeout不设置,表示父进程要在这个位置等待p1
# 进程执行完成后再执行下面的语句
p1.join(1) # 设置超时时间为1s
print('set timeout=1, p1.is_alive=',p1.is_alive()) # 这里应该打印True
# 一般用于进程间的数据同步,若不写这一句,下面的is_alive判断将为True,
# 在shell(cmd)中调用此程序可以完整的看到这个过程
p1.join() # 设置等待子进程执行完毕再执行父进程的后续语句
print('p1.is_alive=',p1.is_alive())
# 等待子进程执行完毕,此处打印可能有输出延迟
进程pid: 6203
worker_1, 父进程<6203>,当前进程<8048>
worker_2, 父进程<6203>,当前进程<8049>
p2.isalive= True
p1.name=Process-12 p1.pid=8048
p2.name=Dog p2.pid=8049
worker_2执行时间为1.0010364055633545
set timeout=1, p1.is_alive= True
worker_1执行时间为3.002727746963501
p1.is_alive= False
Process 子类
创建新的进程还能够使用类的方式:
可以自定义一个类,继承Process类,
每次实例化这个类的时候,就等同于实例化一个进程对象
用Process子类来进行进程的控制可以达到简化的效果
# Process 子类 例子
from multiprocessing import Process
import time
import os
# 继承Process类
class ProcessSon(Process):
# Process类本身有__init__方法,重写Process的__init__方法,会有一个问题
# 并没有完全初始化一个Process类,所以不能使用这个类继承的一些属性和方法
# 最好的方法是将继承类本身传递给Process.__init__方法,完成对自类的初始化
def __init__(self, interval):
Process.__init__(self)
self.interval = interval
# 重写Process 的run()方法
def run(self):
print('子进程{}开始执行,父进程为{}'.format(os.getpid(), os.getppid()))
t_start = time.time()
time.sleep(self.interval)
t_stop = time.time()
print('进程{}执行结束,用时{}'.format(os.getpid(), t_stop-t_start))
if __name__=='__main__': # Process 标配
t_start = time.time()
print('当前进程为:{}'.format(os.getpid()))
p1=ProcessSon(3) # 用子类创建一个新的进程对象
# 对一个不包含target属性的Process类执行start()方法,会执行此类的run()方法,
# 这里执行的是p1.run()[也就是ProcessSon.run()]
p1.start()
p1.join()
t_stop = time.time()
print('进程{}执行结束,用时{}\nover'.format(os.getpid(), t_stop-t_start))
当前进程为:2769
子进程25847开始执行,父进程为2769
进程25847执行结束,用时3.0029664039611816
进程2769执行结束,用时3.0183212757110596
over
进程池Pool
需要创建的子进程数量不多时,可以直接用multiprocessing.Process动态生成多个进程,但是对于数目过大时,手动创建工作量太大,可以用multiprocessing模块中的Pool方法
初始化Pool时可指定最大进程数,当有新的请求提交到Pool时,在Pool未满下,会创建新进程来执行请求,但若Pool已满,则请求会等待,直到进程池有空位才会创建新的进程来执行请求
Pool进程池并不是进程数越大越好
multiprocessing.Pool常用函数
apply_async(func[, args[,kwds]]) 异步调用
使用非阻塞方式调用func(并行执行,阻塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键子参数列表;
apply(func[, args[, kwds]]) 同步调用
使用阻塞的方式调用func
close()
关闭Pool,使其不再接受新的任务
terminate()
强制终止任务,不管是否完成
join([timeout])
主进程阻塞,等待子进程的退出,必须在close()或terminate()后使用
timeout为超时时间,秒级(pool.join(1) 设定超时时间为1s)
# Pool 例子(apply_async() 异步)
#!/usr/bin/env python3
#-*- coding: utf-8 -*-
from multiprocessing import Pool;
import os
import time
import random
run_start = time.time()
def worker(msg):
t_start = time.time()
print('{}开始执行,进程号为:{}'.format(msg, os.getpid()))
# random.random()随机生成0-1之间的浮点数
sleep_num = random.random()*2
time.sleep(sleep_num)
t_stop = time.time()
use_time = t_stop-t_start
print('{}执行完毕,用时{}'.format(msg, use_time))
print('start'.center(30, '*'))
po = Pool(3) # 定义一个进程池,设置最大进程数为3
for i in range(10):
# Pool.apply_async(要调用的目标,(传递给目标的参数元组,))
# 每次循环将会用空闲出的子进程去调用目标
po.apply_async(worker, (i, )) # 运行worker函数,并且worker传递参数为i
po.close() # 关闭进程池,关闭后po不再接受新的请求
# 进程阻塞,如果不添加此句,会出现主进程执行结束后直接关闭,
# 子进程无法执行
po.join() # 等待po中所有子进程执行完成,必须放在close语句后
print('end'.center(30, '*'))
run_stop = time.time()
run_time = run_stop-run_start
print('总用时:',run_time)
************start*************
1开始执行,进程号为:8905
2开始执行,进程号为:8906
0开始执行,进程号为:8904
1执行完毕,用时1.102046012878418
3开始执行,进程号为:8905
0执行完毕,用时1.7687046527862549
4开始执行,进程号为:8904
2执行完毕,用时1.7871208190917969
5开始执行,进程号为:8906
4执行完毕,用时0.04486870765686035
6开始执行,进程号为:8904
3执行完毕,用时1.059372901916504
7开始执行,进程号为:8905
5执行完毕,用时0.5280158519744873
8开始执行,进程号为:8906
6执行完毕,用时0.6856362819671631
9开始执行,进程号为:8904
8执行完毕,用时0.30577731132507324
9执行完毕,用时0.3760497570037842
7执行完毕,用时1.3986475467681885
*************end**************
总用时: 3.6309187412261963
'''apply阻塞式'''
# Pool 例子
#!/usr/bin/env python3
#-*- coding: utf-8 -*-
from multiprocessing import Pool;
import os
import time
import random
run_start = time.time()
def worker(msg):
t_start = time.time()
print('{}开始执行,进程号为:{}'.format(msg, os.getpid()))
# random.random()随机生成0-1之间的浮点数
sleep_num = random.random()*2
time.sleep(sleep_num)
t_stop = time.time()
use_time = t_stop-t_start
print('{}执行完毕,用时{}'.format(msg, use_time))
print('start'.center(30, '*'))
po = Pool(3) # 定义一个进程池,设置最大进程数为3
for i in range(10):
# Pool.apply(要调用的目标,(传递给目标的参数元组,))
# 每次循环将会用空闲出的子进程去调用目标
po.apply(worker, (i, )) # 运行worker函数,并且worker传递参数为i
po.close() # 关闭进程池,关闭后po不在接受新的请求
# 进程阻塞,如果不添加此句,会出现主进程执行结束后直接关闭,
# 子进程无法执行
po.join() # 等待po中所有子进程执行完成,必须放在close语句后
print('end'.center(30, '*'))
run_stop = time.time()
run_time = run_stop-run_start
print('总用时:',run_time)
************start*************
0开始执行,进程号为:9181
0执行完毕,用时0.21720004081726074
1开始执行,进程号为:9182
1执行完毕,用时1.266624927520752
2开始执行,进程号为:9183
2执行完毕,用时0.8020675182342529
3开始执行,进程号为:9181
3执行完毕,用时1.9233331680297852
4开始执行,进程号为:9182
4执行完毕,用时0.48862147331237793
5开始执行,进程号为:9183
5执行完毕,用时0.8913943767547607
6开始执行,进程号为:9181
6执行完毕,用时0.03457212448120117
7开始执行,进程号为:9182
7执行完毕,用时0.5286092758178711
8开始执行,进程号为:9183
8执行完毕,用时0.452136754989624
9开始执行,进程号为:9181
9执行完毕,用时1.9772589206695557
*************end**************
总用时: 8.642189741134644
进程间的通信Queue
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,
Queue本身是一个消息列队程序
# Queue 例子
from multiprocessing import Queue
q = Queue(3) # 初始化一个Queue对象,最多接收三条put消息
q.put('msg1')
q.put('msg2')
print(q.full()) # False
q.put('msg3')
print(q.full()) # True
# 消息队列已满,抛出异常,
# 第一个try会等待2s后再抛出,
# 第二个try会立刻抛出异常
try:
q.put('msg4',True, 2)
except:
print('消息队列已满,现有消息数量:{}'.format(q.qsize()))
try:
q.put_nowait('msg4')
except:
print('消息队列已满,现有消息数量:{}'.format(q.qsize()))
# 推荐
# 先判断消息队列是否已满,再写入
if not q.full():
q.put_nowait('msg4')
# 读取消息时,先判断消息队列是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
False
True
消息队列已满,现有消息数量:3
消息队列已满,现有消息数量:3
msg1
msg2
msg3
Queue使用
初始化Queue()对象时(如:q = Queue()),若Queue中未指定值,或为负值,表示可接受消息数列无上限(直到内存存满)
Queue.qsize()
返回当前队列包含的消息数量
Queue.empty()
消息队列判空,队列为空返回True,队列已满返回False
Queue.full()
消息队列判满,已满,返回True,否则返回False
Queue.get([block[, timeout]])
获取队列的一条消息,然后将其从队列中移除,block默认值为True;
block参数设置:
1. 如果block使用默认值,且没有设置timeout(单位秒),消息队列如果已经没有空间写入,此时程序将被阻塞(停在写入状态),直到从消息队列腾出空间为止,若设置了timeout,则会等待timeout秒,若还没读取到任何消息,抛出”Queue.Empty“异常;
2. 若block值为False,消息队列为空,会立刻抛出”Queue.Empty“异常
Queue.get_nowait()
相当于`Queue.get(False)`
Queue.put(item[, block[, timeout]])
参数解释:
[
item:将要写入消息队列的消息
block:阻塞设置
block使用默认值(True),且未设置timeout(单位秒),消息队列已满,此时程序将被阻塞,直到消息队列有空间为止,若设置了timeout,等待超时后会抛出”Queue.full“异常
block=False,消息队列已满,会立刻抛出”Queue.Full”异常
timeout:超时时间
]
Queue.put_nowait(item)
相当于Queue.put(item,False)
# Queue 实例
# 这里注意:py文件名一定不能和Python中的保留名相同,不然会报错
from multiprocessing import Process, Queue
import os,time, random
# 写数据进程执行
def write(q):
for value in ['A', 'B', 'C']:
print('put {} to queue'.format(value))
q.put(value)
time.sleep(random.random())
# 读数据操作
def read(q):
while True:
if not q.empty():
value = q.get(True)
print('get {} from queue'.format(value))
time.sleep(random.random())
else:
break
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程
q = Queue()
pw = Process(target=write, args=(q, ))
pr = Process(target=read, args=(q, ))
# 启动子进程pw,写入消息
pw.start()
# 等待子进程pw结束(加入进程阻塞)
pw.join()
# 启动读消息子进程pr
pr.start()
pr.join(5) # 针对read(q)的while设置,防止等待过长
# 设置超时时间
pw.terminate()
print('\n所有数据读写完成!')
put A to queue
put B to queue
put C to queue
get A from queue
get B from queue
get C from queue
所有数据读写完成!
进程池中的Queue
Pool中使用Queue:
使用的是multiprocessing.Manager()中的Queue(),不是multiprocessing.Queue() 否则会报错“RuntimeError: Queue objects should only be shared between processes through inheritance.”
# Pool中使用Queue通信
# pool中使用的是multiprocessing.Manager的Queue
from multiprocessing import Manager, Pool
import os, time, random
def reader(q):
print('reader <{}> run, father is <{}>'.format(os.getpid(), os.getppid()))
for i in range(q.qsize()):
print('reader get msg from Queue', q.get(True))
def writer(q):
print('writer <{}> run, father is <{}>'.format(os.getpid(), os.getppid()))
for i in range(5):
q.put(i)
if __name__=='__main__':
print('pid:{} start'.format(os.getpid()))
q = Manager().Queue() # 消息队列初始化使用的是Manager().Queue()
po = Pool()
# 阻塞模式创建进程,在writer()完全执行完后再执行reader(),
# 免去reader()中的死循环
po.apply(writer, (q, ))
po.apply(reader, (q, ))
po.close() # 关闭Pool
po.join() # 进程阻塞
print('pid:{} end'.format(os.getpid()))
pid:2126 start
writer <3475> run, father is <2126>
reader <3477> run, father is <2126>
reader get msg from Queue 0
reader get msg from Queue 1
reader get msg from Queue 2
reader get msg from Queue 3
reader get msg from Queue 4
pid:2126 end
# 多进程拷贝文件
#-*- coding:utf-8 -*-
from multiprocessing import Pool, Manager
import os, shutil # 刚好和os模块互补
def cp_file(name, oldFolderName, newFolderName, queue):
'''将旧文件夹中的文件拷贝到新文件夹'''
with open(os.path.join(oldFolderName,name), 'r+', encoding='utf-8') as fr:
content = fr.read()
with open(os.path.join(newFolderName, name), 'w', encoding='utf-8') as fw:
fw.write(content)
queue.put(name)
def main():
# 获取文件要copy的文件夹的名字
oldFolderName = input('input Folder Name:')
# 新建一个文件夹
newFolderName = oldFolderName+'-复件'
# 判断文件夹是否存在
if os.path.exists(newFolderName):
# 存在就删除后再新建
shutil.rmtree(newFolderName)
os.mkdir(newFolderName)
# 获取需要copy的文件夹中的所有文件名
fileNames = os.listdir(oldFolderName)
# 使用多进程方式copy文件
pool = Pool(6)
queue = Manager().Queue()
for name in fileNames:
pool.apply_async(cp_file, args=(name, oldFolderName, newFolderName, queue))
num = 0
all_num = len(fileNames)
while num<all_num:
queue.get()
num +=1
copyRate = num/all_num
print('\rcopy的进度是{:.2f}%'.format((copyRate*100)), end='')
if __name__=='__main__':
main()
# 僵尸进程:父进程死了,但是子进程没死,也叫孤儿进程
input Folder Name:multiprocessing_test
copy的进度是100.00%
shutil模块
参考于jb51
网址:https://www.jb51.net/article/145522.htm
copyfileobj(fsrc, fdst, length=16*1024): 将fsrc文件内容复制至fdst文件,length为fsrc每次读取的长度,用做缓冲区大小
fsrc: 源文件
fdst: 复制至fdst文件
length: 缓冲区大小,即fsrc每次读取的长度
import shutil
f1 = open("file.txt","r")
f2 = open("file_copy.txt","a+")
shutil.copyfileobj(f1,f2,length=1024)
copyfile(src, dst): 将src文件内容复制至dst文件
src: 源文件路径
dst: 复制至dst文件,若dst文件不存在,将会生成一个dst文件;若存在将会被覆盖
follow_symlinks:设置为True时,若src为软连接,则当成文件复制;如果设置为False,复制软连接。默认为True。Python3新增参数
import shutil
shutil.copyfile("file.txt","file_copy.txt")
copymode(src, dst): 将src文件权限复制至dst文件。文件内容,所有者和组不受影响
src: 源文件路径
dst: 将权限复制至dst文件,dst路径必须是真实的路径,并且文件必须存在,否则将会报文件找不到错误
follow_symlinks:设置为False时,src, dst皆为软连接,可以复制软连接权限,如果设置为True,则当成普通文件复制权限。默认为True。Python3新增参数
import shutil
shutil.copymode("file.txt","file_copy.txt")
copystat(src, dst): 将权限,上次访问时间,上次修改时间以及src的标志复制到dst。文件内容,所有者和组不受影响
src: 源文件路径
dst: 将权限复制至dst文件,dst路径必须是真实的路径,并且文件必须存在,否则将会报文件找不到错误
follow_symlinks:设置为False时,src, dst皆为软连接,可以复制软连接权限、上次访问时间,上次修改时间以及src的标志,如果设置为True,则当成普通文件复制权限。默认为True。Python3新增参数
import shutil
shutil.copystat("file.txt","file_copy.txt")
copy(src, dst): 将文件src复制至dst。dst可以是个目录,会在该目录下创建与src同名的文件,若该目录下存在同名文件,将会报错提示已经存在同名文件。权限会被一并复制。本质是先后调用了copyfile与copymode而已
src:源文件路径
dst:复制至dst文件夹或文件
follow_symlinks:设置为False时,src, dst皆为软连接,可以复制软连接权限,如果设置为True,则当成普通文件复制权限。默认为True。Python3新增参数
improt shutil,os
shutil.copy("file.txt","file_copy.txt")
# 或者
shutil.copy("file.txt",os.path.join(os.getcwd(),"copy"))
copy2(src, dst): 将文件src复制至dst。dst可以是个目录,会在该目录下创建与src同名的文件,若该目录下存在同名文件,将会报错提示已经存在同名文件。权限、上次访问时间、上次修改时间和src的标志会一并复制至dst。本质是先后调用了copyfile与copystat方法而已
src:源文件路径
dst:复制至dst文件夹或文件
follow_symlinks:设置为False时,src, dst皆为软连接,可以复制软连接权限、上次访问时间,上次修改时间以及src的标志,如果设置为True,则当成普通文件复制权限。默认为True。Python3新增参数
improt shutil,os
shutil.copy2("file.txt","file_copy.txt")
# 或者
shutil.copy2("file.txt",os.path.join(os.getcwd(),"copy"))
ignore_patterns(*patterns): 忽略模式,用于配合copytree()方法,传递文件将会被忽略,不会被拷贝
patterns:文件名称,元组
copytree(src, dst, symlinks=False, ignore=None): 拷贝文档树,将src文件夹里的所有内容拷贝至dst文件夹
src:源文件夹
dst:复制至dst文件夹,该文件夹会自动创建,需保证此文件夹不存在,否则将报错
symlinks:是否复制软连接,True复制软连接,False不复制,软连接会被当成文件复制过来,默认False
ignore:忽略模式,可传入ignore_patterns()
copy_function:拷贝文件的方式,可以传入一个可执行的处理函数,默认为copy2,Python3新增参数
ignore_dangling_symlinks:sysmlinks设置为False时,拷贝指向文件已删除的软连接时,将会报错,如果想消除这个异常,可以设置此值为True。默认为False,Python3新增参数
import shutil,os
folder1 = os.path.join(os.getcwd(),"aaa")
# bbb与ccc文件夹都可以不存在,会自动创建
folder2 = os.path.join(os.getcwd(),"bbb","ccc")
# 将"abc.txt","bcd.txt"忽略,不复制
shutil.copytree(folder1,folder2,ignore=shutil.ignore_patterns("abc.txt","bcd.txt")
rmtree(path, ignore_errors=False, onerror=None): 移除文档树,将文件夹目录删除
ignore_errors:是否忽略错误,默认False
onerror:定义错误处理函数,需传递一个可执行的处理函数,该处理函数接收三个参数:函数、路径和excinfo
import shutil,os
folder1 = os.path.join(os.getcwd(),"aaa")
shutil.rmtree(folder1)
move(src, dst): 将src移动至dst目录下。若dst目录不存在,则效果等同于src改名为dst。若dst目录存在,将会把src文件夹的所有内容移动至该目录下面
src:源文件夹或文件
dst:移动至dst文件夹,或将文件改名为dst文件。如果src为文件夹,而dst为文件将会报错
copy_function:拷贝文件的方式,可以传入一个可执行的处理函数。默认为copy2,Python3新增参数
import shutil,os
# 示例一,将src文件夹移动至dst文件夹下面,如果bbb文件夹不存在,则变成了重命名操作
folder1 = os.path.join(os.getcwd(),"aaa")
folder2 = os.path.join(os.getcwd(),"bbb")
shutil.move(folder1, folder2)
# 示例二,将src文件移动至dst文件夹下面,如果bbb文件夹不存在,则变成了重命名操作
file1 = os.path.join(os.getcwd(),"aaa.txt")
folder2 = os.path.join(os.getcwd(),"bbb")
shutil.move(file1, folder2)
# 示例三,将src文件重命名为dst文件(dst文件存在,将会覆盖)
file1 = os.path.join(os.getcwd(),"aaa.txt")
file2 = os.path.join(os.getcwd(),"bbb.txt")
shutil.move(file1, file2)
disk_usage(path): 获取当前目录所在硬盘使用情况。Python3新增方法
path:文件夹或文件路径。windows中必须是文件夹路径,在linux中可以是文件路径和文件夹路径
import shutil.os
path = os.path.join(os.getcwd(),"aaa")
info = shutil.disk_usage(path)
print(info) # usage(total=95089164288, used=7953104896, free=87136059392)
chown(path, user=None, group=None): 修改路径指向的文件或文件夹的所有者或分组。Python3新增方法
path:路径
user:所有者,传递user的值必须是真实的,否则将报错no such user
group:分组,传递group的值必须是真实的,否则将报错no such group
import shutil,os
path = os.path.join(os.getcwd(),"file.txt")
shutil.chown(path,user="root",group="root")
which(cmd, mode=os.F_OK | os.X_OK, path=None): 获取给定的cmd命令的可执行文件的路径。Python3新增方法
import shutil
info = shutil.which("python3")
print(info) # /usr/bin/python3
归档操作
shutil还提供了创建和读取压缩和存档文件的高级使用程序。内部实现主要依靠的是zipfile和tarfile模块
make_archive(base_name, format, root_dir, …): 生成压缩文件
base_name:压缩文件的文件名,不允许有扩展名,因为会根据压缩格式生成相应的扩展名
format:压缩格式
root_dir:将制定文件夹进行压缩
import shutil,os
base_name = os.path.join(os.getcwd(),"aaa")
format = "zip"
root_dir = os.path.join(os.getcwd(),"aaa")
# 将会root_dir文件夹下的内容进行压缩,生成一个aaa.zip文件
shutil.make_archive(base_name, format, root_dir)
get_archive_formats(): 获取支持的压缩文件格式。目前支持的有:tar、zip、gztar、bztar。在Python3还多支持一种格式xztar
unpack_archive(filename, extract_dir=None, format=None): 解压操作。Python3新增方法
filename:文件路径
extract_dir:解压至的文件夹路径。文件夹可以不存在,会自动生成
format:解压格式,默认为None,会根据扩展名自动选择解压格式
import shutil,os
zip_path = os.path.join(os.getcwd(),"aaa.zip")
extract_dir = os.path.join(os.getcwd(),"aaa")
shutil.unpack_archive(zip_path, extract_dir)
get_unpack_formats(): 获取支持的解压文件格式。目前支持的有:tar、zip、gztar、bztar和xztar。Python3新增方法
线程
线程是应用程序中工作的最小单元。
线程可以被抢占(中断)
在其他线程正在运行时,线程可以暂时搁置(睡眠),这是线程的退让。
线程的执行顺序由操作系统的调度算法决定
线程调度
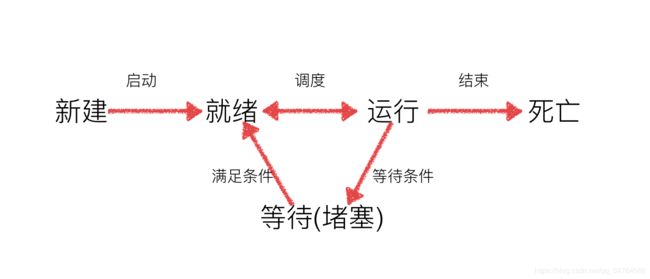 线程可以分为:
线程可以分为:
内核线程:由操作系统内核创建和撤销。
用户线程:不需要内核支持而在用户程序中实现的线程。
Python使用线程:
函数:_thread模块 `_thread.start_new_thread(function, args[, kwargs])`
不建议使用,推荐使用threading
类:Thread类
# 未使用模块的单线程 例子
import time
def about():
print('我是单线程,我就是个弟弟')
time.sleep(0.5)
if __name__=='__main__':
for i in range(5):
about()
我是单线程,我就是个弟弟
我是单线程,我就是个弟弟
我是单线程,我就是个弟弟
我是单线程,我就是个弟弟
我是单线程,我就是个弟弟
'''
调用thread模块的函数式单线程
import _thread
_thread.start_new_thread(fucntion, args[, kwargs])
参数说明:
[
funciton 线程调用函数,
args 传入被调用线程函数的参数,必须为tuple类型“(1,)”
kwargs 可选参数,dict类型(关键字参数)
]
'''
# thread 线程例子
import _thread
import time
# 定义调用函数
def print_time(threadName, delay):
count = 0
while count<3:
time.sleep(delay)
count +=1
print('线程:{}, 时间:{}'.format(threadName, time.ctime(time.time())))
# 创建两个线程
try:
_thread.start_new_thread(print_time, ('Thread-1', 1))
_thread.start_new_thread(print_time, ('Thread-2', 3))
except Exception:
print("Error:can't start thread" )
线程:Thread-1, 时间:Fri Jan 11 16:31:51 2019
线程:Thread-1, 时间:Fri Jan 11 16:31:52 2019
线程:Thread-2, 时间:Fri Jan 11 16:31:53 2019
线程:Thread-1, 时间:Fri Jan 11 16:31:53 2019
线程:Thread-2, 时间:Fri Jan 11 16:31:56 2019
线程:Thread-2, 时间:Fri Jan 11 16:31:59 2019
多线程
多线程类似于同时执行多个不同程序,多线程优点:
(1)易于调度。
(2)提高并发性。通过线程可方便有效地实现并发性。进程可创建多个线程来执行同一程序的不同部分。
(3)开销少。创建线程比创建进程要快,所需开销很少
线程模块
Python3中通过两个标准库_thread(python2中为thread)和threading提供对线程的支持。
_thread 提供低级别的、原始的线程以及一个简单的锁。
threading 提供包括_thread提供的方法以及其他方法:
threading.currentThread() 返回当前的线程变量
threading.enumerate ()返回一个包含正在运行的线程的list,正在运行指线程启动后、结束前,不包括启动前和终止后的线程
threading.activeCount() 返回正在运行的线程数量,
和len(threading.enumerate())作用相同
线程模块同样提供Thread类处理线程,Thread提供的方法:
run() 用以表示线程活动的方法
start() 启动线程
join(timeout) 阻塞调用,直到join()被中止、正常退出、抛出异常或是超时
isAlive() 判断线程是否活动 这里isAlive()=is_alive()
getName() 获取线程名
setName() 设置线程名
# threading 多线程 例子
import threading
import time
def about():
print('我是多线程,我就是快')
time.sleep(0.5)
if __name__=='__main__':
for i in range(5):
# 创建新的线程
t = threading.Thread(target=about) # 这里about不要加()
t.start() # 启动线程
# 快的不要不要的
我是多线程,我就是快
我是多线程,我就是快
我是多线程,我就是快
我是多线程,我就是快
我是多线程,我就是快
# 主线程会等待所有子线程结束后才结束
import threading
from time import sleep, ctime
def sing():
for i in range(3):
print('singing', i)
sleep(1)
def dance():
for i in range(3):
print('dancing', i)
sleep(1)
if __name__=='__main__':
print('start'.center(30, '*'))
# 创建线程
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
# 启动线程
t1.start()
t2.start()
sleep(6) # 不写此行,会出现歌舞未完晚会先完的笑话
print('end'.center(30, '*'))
************start*************
singing 0
dancing 0
singing 1
dancing 1
singing 2
dancing 2
*************end**************
查看线程数目
# 查看线程数目例子
#!/usr/bin/python3
# -*- coding:utf-8 -*-
import threading
from time import sleep, ctime
def sing():
for i in range(3):
print('singing', i)
sleep(1)
def dance():
for i in range(3):
print('dancing', i)
sleep(1)
if __name__=='__main__':
print('start'.center(30, '*'), ctime())
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=sing)
t1.start()
t2.start()
if threading.activeCount()>1:
print('当前线程数为:', threading.activeCount())
sleep(0.5)
print('end'.center(30, '*'), ctime())
'''这里jupyter notebook运行此处代码会出现死循环,但是在linux下无此问题,
所以这里不运行代码,用Linux截图显示'''
************start************* Sat Feb 15 14:09:55 2020
singing 0
singing 0
当前线程数为: 7
*************end************** Sat Feb 15 14:09:56 2020
singing 1
singing 1
singing 2
singing 2

threading 注意点
'''
线程执行代码的封装:
在使用threading模块时,定义一个新的子类,继承threading.Thread,
然后重写run方法
'''
# 线程执行代码的封装 例子
import threading
import time
class MyThread(threading.Thread): # 继承threading.Thread
def run(self): # 重写run()
for i in range(3):
time.sleep(1)
msg = '当前线程为:'+self.name+'@'+str(i)
print(msg)
if __name__=='__main__':
mt = MyThread()
mt.start()
当前线程为:Thread-7@0
当前线程为:Thread-7@1
当前线程为:Thread-7@2
'''
例子说明:
python的threading.Thread类有一个run()方法,用于定义线程的功能函数,
可在自己的线程类中覆盖该方法,在创建自己的线程实例后,
python会调用用户自定义的run()
'''
多线程共享全局变量
在一个进程内的所有线程共享全局变量,能够在不适用其他方式的前提下完成多线程之间的数据共享(这点要比多进程要好)
缺点就是,线程是对全局变量随意修改可能造成多线程之间对全局变量的混乱(即线程非安全)
# 多线程共享全局变量 例子
from threading import Thread
import time
g_num = 50
def work1():
global g_num
for i in range(5):
g_num +=2
print('\nin work1, g_num = {}'.format(g_num))
def work2():
global g_num
for i in range(3):
g_num += 3
print('\nin work2, g_num = {}'.format(g_num))
if __name__=='__main__':
t1 = Thread(target=work1)
t2 = Thread(target=work2)
t1.start()
t2.start()
# 这里会出现全局变量混乱现象
in work1, g_num = 52
in work1, g_num = 54
in work1, g_num = 56
in work1, g_num = 58
in work1, g_num = 60
in work2, g_num = 63
in work2, g_num = 66
in work2, g_num = 69

列表当实参传递到线程中
# 例子
from threading import Thread
import time
def work1(nums):
nums.append(44)
print('in work1'.center(30, "*"), nums)
def work2(nums):
# 延时,保证t1线程执行完毕
time.sleep(1)
print('in work2'.center(30, "*"), nums)
g_nums = [11, 22, 33]
t1 = Thread(target=work1, args=(g_nums, ))
t1.start()
t2 = Thread(target=work2, args=(g_nums, ))
t2.start()
***********in work1*********** [11, 22, 33, 44]
***********in work2*********** [11, 22, 33, 44]
进程VS线程
进程:进程是系统进行资源分配和调度的一个独立单位.
线程:线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
进程可以理解为一台电脑上可以同时运行多个QQ
线程可以理解为一个QQ可以开多个聊天窗口
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)处理机分给线程,即真正在处理机上运行的是线程
(4)线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。线程是指进程内的一个执行单元,也是进程内的可调度实体.
进程与线程的区别:
(1)调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源.
(4)系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
各自优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
线程同步
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。
# 线程不安全 例子
from threading import Thread
import time
g_num = 0
g_number = 0
def test1():
global g_num
for i in range(1000000):
g_num +=1
print('in test1, g_num = {}'.format(g_num))
def test2():
global g_num
for i in range(1000000):
g_num +=1
print('***in test2, g_num = {}'.format(g_num))
def test3():
global g_number
for i in range(1000000):
g_number +=1
print('***in test3, g_number = {}'.format(g_number))
def test4():
global g_number
for i in range(1000000):
g_number +=1
print('***in test4, g_number = {}'.format(g_number))
# 未对线程运行进行调节
t1 = Thread(target=test1)
t1.start()
t2 = Thread(target=test2)
t2.start()
print('g_num = {}'.format(g_num))
time.sleep(5) # 保证线程t1、t2执行完毕
# 对线程运行进行调节
t3 = Thread(target=test3)
t3.start()
time.sleep(5) # 睡眠5s,保证线程t3可以完全执行完毕
t4 = Thread(target=test4)
t4.start()
t4.join()# 线程阻塞
print('g_number = {}'.format(g_number))
g_num = 362029
in test1, g_num = 1057030
***in test2, g_num = 1584212
***in test3, g_number = 1000000
***in test4, g_number = 2000000
g_number = 2000000
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定。
添加锁的原则是:在保证程序正确的前提下,尽可能的少锁住代码。(这样锁死的时间就越少)
threading模块中的Lock类,可以方便的处理锁定:
创建锁:
mutex = threading.Lock()
锁定:
mutex.acquire([blocking])
blocking参数解释:
若设定blocking为True,则当前线程堵塞,直到获得这个锁为止(默认为True)
若blocking设置为False,则当前线程不会堵塞
释放:
mutex.release()
# 用互斥锁实现上例的线程同步 例子
from threading import Thread, Lock
from time import sleep
g_num = 0
def test1():
global g_num
mutexFlag = mutex.acquire(True)
# True表示阻塞,即若这个锁在要上锁之前已经被上锁,那么此线程会一直等待到解锁
# False表示非阻塞,即不管本次上锁能否成功,都不会卡在这里,会继续执行下面的代码
if mutexFlag:
for i in range(100000):
g_num +=1
mutex.release()
print('in test1, g_num={}'.format(g_num))
def test2():
global g_num
mutexFlag = mutex.acquire(True)
# True表示阻塞,即若这个锁在要上锁之前已经被上锁,那么此线程会一直等待到解锁
# False表示非阻塞,即不管本次上锁能否成功,都不会卡在这里,会继续执行下面的代码
if mutexFlag:
for i in range(100000):
g_num +=1
mutex.release()
print('**in test2, g_num={}'.format(g_num))
if __name__ == "__main__":
# 创建一个互斥锁,这个锁默认是未上锁状态
mutex = Lock()
t1 = Thread(target=test1)
t1.start()
t2 = Thread(target=test2)
t2.start()
sleep(3)
print('for total g_num = {}'.format(g_num))
in test1, g_num=100000
**in test2, g_num=200000
for total g_num = 200000
'''
上锁解锁过程
当一个线程调用Lock的acquire()获得锁时,锁就进入“locked’状态
每次只有一个线程可以获得锁,如果此时另一个线程试图获得此锁,
尝试获取锁线程会变为”blocked“状态,称为”阻塞“
直到拥有锁的线程调用锁的release()方法释放锁,锁进入”unlocked“状态
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,
并使得该线程进入运行(running)状态。
'''
'''
锁的好处:
确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,
效率就大大地下降了
由于可以存在多个锁,不同的线程持有不同的锁,
并试图获取对方持有的锁时,可能会造成死锁
'''
'''
对多线程-非共享数据(非全局变量):
在多线程开发中,全局变量是多个线程都共享的数据,
而局部变量等是各自线程的,是非共享的
'''
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
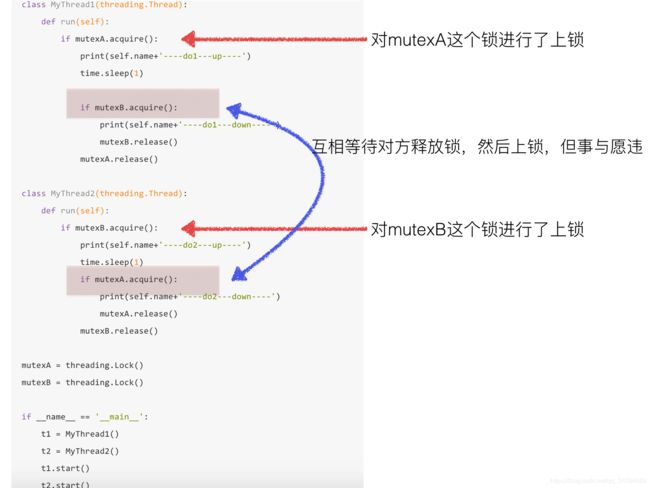
避免死锁
程序设计时要尽量避免(银行家算法)
添加超时时间等
银行家算法
一个银行家拥有一定数量的资金,有若干个客户要贷款。每个客户须在一开始就声明他所需贷款的总额。若该客户贷款总额不超过银行家的资金总数,银行家可以接收客户的要求。客户贷款是以每次一个资金单位(如1万RMB等)的方式进行的,客户在借满所需的全部单位款额之前可能会等待,但银行家须保证这种等待是有限的,可完成的。
例如:有三个客户C1,C2,C3,向银行家借款,该银行家的资金总额为10个资金单位,其中C1客户要借9各资金单位,C2客户要借3个资金单位,C3客户要借8个资金单位,总计20个资金单位。某一时刻的状态如图所示。
对于a图的状态,按照安全序列的要求,我们选的第一个客户应满足该客户所需的贷款小于等于银行家当前所剩余的钱款,可以看出只有C2客户能被满足:C2客户需1个资金单位,小银行家手中的2个资金单位,于是银行家把1个资金单位借给C2客户,使之完成工作并归还所借的3个资金单位的钱,进入b图。同理,银行家把4个资金单位借给C3客户,使其完成工作,在c图中,只剩一个客户C1,它需7个资金单位,这时银行家有8个资金单位,所以C1也能顺利借到钱并完成工作。最后(见图d)银行家收回全部10个资金单位,保证不赔本。那麽客户序列{C1,C2,C3}就是个安全序列,按照这个序列贷款,银行家才是安全的。否则的话,若在图b状态时,银行家把手中的4个资金单位借给了C1,则出现不安全状态:这时C1,C3均不能完成工作,而银行家手中又没有钱了,系统陷入僵持局面,银行家也不能收回投资。

综上所述,银行家算法是从当前状态出发,逐个按安全序列检查各客户谁能完成其工作,然后假定其完成工作且归还全部贷款,再进而检查下一个能完成工作的客户,…。如果所有客户都能完成工作,则找到一个安全序列,银行家才是安全的。
'''同步应用'''
# 使用互斥锁完成多个任务,有序的进行工作
import queue
from threading import Lock, Thread
flag = True # 循环标记
i = 0 # 运行次数
def task1(q, lock, another):
'''同步函数1'''
global flag
global i
while flag:
if q.full() != True:
if lock.acquire():
i += 1
try: # 队列满后退出循环
q.put(1, timeout=0.1)
except Exception:
break
print("this is task1 at NO.{}".format(i))
another.release()
else:
flag = False
def task2(q, lock, another):
'''同步函数2'''
global flag
global i
while flag:
if q.full() != True:
if lock.acquire():
i += 1
try:
q.put(1, timeout=0.1)
except Exception:
break
print("this is task2 at NO.{}".format(i))
another.release()
else:
flag = False
if __name__ == "__main__":
q = queue.Queue(4) # 创建一个大小为4的消息队列
# 创建两把锁
lock1 = Lock()
lock2 = Lock()
lock2.acquire()
# 初始化线程t1和t2
t1 = Thread(
target=task1, args=(
q,
lock1,
lock2,
))
t2 = Thread(
target=task2, args=(
q,
lock2,
lock1,
))
# 启动线程并对线程设置阻塞时间
t1.start()
t2.start()
t1.join(1)
t2.join(1)
this is task1 at NO.1
this is task2 at NO.2
this is task1 at NO.3
this is task2 at NO.4
生产者消费者模式
队列
先进先出
栈
后进先出
线程优先级队列( Queue):
Python 的 Queue 模块中提供了同步的、线程安全的队列类,
包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue
这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么就做完),
能够在多线程中直接使用。可以使用队列来实现线程间的同步。
import queue
q = queue.Queue()
这里的Queue和进程里Queue的方法和属性功能相同,不再赘述
Queue.task_done()
在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
# 用FIFO队列实现生成者消费者问题 例子:
from time import time, sleep
from queue import Queue
from threading import Thread
q = Queue(maxsize=10) # 声明队列
def producter(pro_name):
'''生产者'''
number = 0 # 产品批次
# 队列不满时,生产产品
while number < 20:
number += 1
try: # 处理队满异常,队满则中止生产,不满再打印生产信息
q.put(number, timeout=0.1) # 放入产品
except Exception:
break
else:
print("<{}>生产了第<{}>个产品".format(pro_name, number))
def consumer(con_name):
'''消费者'''
# 当队列非空时消费产品
while not (q.empty()):
try: # 处理空队列异常,队空再停止消费,不空则打印消费信息
seq = q.get(timeout=0.1)
except Exception:
break
else:
print("<{}>消费了第<{}>个产品".format(con_name, seq))
if __name__ == "__main__":
p1 = Thread(target=producter, args=("老王", )) # 老王生产
c1 = Thread(target=consumer, args=("张三", )) # 张三消费
c2 = Thread(target=consumer, args=("李四", )) # 李四消费
p1.start()
# 当producter中的while 条件为 not(q.full())时,需要添加如下:
# sleep(1) # 暂停1秒,防止生产队列因多线程消费而混乱
c1.start()
c2.start()
p1.join(2)
c1.join(3)
c2.join(3)
if q.empty():
sleep(1)
print("产出的产品全部消费完了!")
<老王>生产了第<1>个产品
<老王>生产了第<2>个产品
<老王>生产了第<3>个产品
<老王>生产了第<4>个产品
<老王>生产了第<5>个产品
<老王>生产了第<6>个产品
<老王>生产了第<7>个产品
<老王>生产了第<8>个产品
<老王>生产了第<9>个产品
<老王>生产了第<10>个产品
<张三>消费了第<1>个产品
<张三>消费了第<2>个产品
<老王>生产了第<11>个产品
<老王>生产了第<12>个产品
<李四>消费了第<3>个产品<张三>消费了第<4>个产品<老王>生产了第<13>个产品
<老王>生产了第<14>个产品
<李四>消费了第<5>个产品
<李四>消费了第<6>个产品
<李四>消费了第<7>个产品
<李四>消费了第<8>个产品
<李四>消费了第<9>个产品
<李四>消费了第<10>个产品
<李四>消费了第<11>个产品
<李四>消费了第<12>个产品
<李四>消费了第<13>个产品
<李四>消费了第<14>个产品
<老王>生产了第<15>个产品
<老王>生产了第<16>个产品
<老王>生产了第<17>个产品
<老王>生产了第<18>个产品
<老王>生产了第<19>个产品
<老王>生产了第<20>个产品
<李四>消费了第<15>个产品
<李四>消费了第<16>个产品
<李四>消费了第<17>个产品
<李四>消费了第<18>个产品
<李四>消费了第<19>个产品
<李四>消费了第<20>个产品
产出的产品全部消费完了!
ThreadLocal
多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
'''
使用函数传参的方法
每层都要传入参数,啰嗦的很
'''
def process_student(name):
std = Student(name)
# std是局部变量,但是每个函数都要用它,因此必须传进去:
do_task_1(std)
do_task_2(std)
def do_task_1(std):
do_subtask_1(std)
do_subtask_2(std)
def do_task_2(std):
do_subtask_2(std)
do_subtask_2(std)
'''
使用全局字典的方法
这种方式理论上是可行的,
它最大的优点是消除了std对象在每层函数中的传递问题,
但是,每个函数获取std的代码有点low。
'''
global_dict = {}
def std_thread(name):
std = Student(name)
# 把std放到全局变量global_dict中:
global_dict[threading.current_thread()] = std
do_task_1()
do_task_2()
def do_task_1():
# 不传入std,而是根据当前线程查找:
std = global_dict[threading.current_thread()]
...
def do_task_2():
# 任何函数都可以查找出当前线程的std变量:
std = global_dict[threading.current_thread()]
...
使用ThreadLocal
threadlocal是用于解决多线程之间的共享数据的参数紊乱问题
import threading
# 用threading.local() 生成全局变量
global_var = threading.local()
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题
# ThreadLocal 例子
from threading import local
global_var = local() # 创建全局ThreadLocal对象
def thread_student():
'''学生线程'''
student = global_var.student # 学生
print("Hello, Student: %s" % (student))
def process_thread(name):
'''绑定ThreadLocal对象'''
global_var.student = name
thread_student()
if __name__ == "__main__":
t1 = Thread(target=process_thread, args=("张三", ))
t2 = Thread(target=process_thread, args=("老王", ))
t1.start()
t2.start()
t1.join(1)
t2.join(1)
# 全局变量local_school就是一个ThreadLocal对象,
# 每个Thread对它都可以读写student属性,但互不影响。
# 你可以把local_school看成全局变量,
# 但每个属性如local_school.student都是线程的局部变量,
# 可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
# 可以理解为全局变量local_school是一个dict,
# 不但可以用local_school.student,还可以绑定其他变量,
# 如local_school.teacher等等。
Hello, Student: 张三
Hello, Student: 老王
异步
老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)
老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀嘀的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)
老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。
所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。
同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。
立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
# 异步例子
from multiprocessing import Pool
import time
import os
def test_1():
print('进程池中的进程:pid = {}, ppid = {}'.format(os.getpid(), os.getppid()))
for i in range(3):
print('{}'.format(i).center(10, '*'))
time.sleep(0.5)
return 'function test_1'
def test_2(args):
print('callback func pid = {}'.format(os.getpid()))
print('callback func args = {}'.format(args))
pool = Pool(3)
pool.apply_async(func=test_1, callback=test_2)
time.sleep(3)
print('主进程:pid = {}'.format(os.getpid()))
进程池中的进程:pid = 8988, ppid = 2110
****0*****
****1*****
****2*****
callback func pid = 2110
callback func args = function test_1
主进程:pid = 2110
GIL(全局解释锁)
这里特别注意:在python中多进程比多线程的效率要高
#加载动态库
from ctypes import *
lib = cdll.LoadLibrary("loadName") #这里是用于导入库
分布式进程
参考网址
https://www.liaoxuefeng.com/wiki/1016959663602400/1017631559645600
在
Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
原有的Queue可以继续使用,但是,通过managers模块把Queue通过网络暴露出去,就可以让其他机器的进程访问Queue了。
# task_master.py
import random, time, queue
from multiprocessing.managers import BaseManager
# 发送任务的队列:
task_queue = queue.Queue()
# 接收结果的队列:
result_queue = queue.Queue()
# 从BaseManager继承的QueueManager:
class QueueManager(BaseManager):
pass
# 把两个Queue都注册到网络上, callable参数关联了Queue对象:
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# 绑定端口5000, 设置验证码'abc':
manager = QueueManager(address=('', 5000), authkey=b'abc')
# 启动Queue:
manager.start()
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从result队列读取结果:
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' % r)
# 关闭:
manager.shutdown()
print('master exit.')
# 当我们在一台机器上写多进程程序时,创建的Queue可以直接拿来用,
# 但是,在分布式多进程环境下,
# 添加任务到Queue不可以直接对原始的task_queue进行操作,
# 那样就绕过了QueueManager的封装,
# 必须通过manager.get_task_queue()获得的Queue接口添加。
# 在另一台机器上启动任务进程(本机上启动也可以):
# task_worker.py
import time, sys, queue
from multiprocessing.managers import BaseManager
# 创建类似的QueueManager:
class QueueManager(BaseManager):
pass
# 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字:
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
# 连接到服务器,也就是运行task_master.py的机器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与task_master.py设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey=b'abc')
# 从网络连接:
m.connect()
# 获取Queue的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 从task队列取任务,并把结果写入result队列:
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
# 处理结束:
print('worker exit.')
异步IO
为解决CPU高速执行能力和IO设备的龟速严重不匹配,提供了多线程和多进程方法,但是还有一种解决方法:异步IO。(当代码需要执行一个耗时的IO操作时,它只发出IO指令,并不等待IO结果,然后就去执行其他代码了。一段时间后,当IO返回结果时,再通知CPU进行处理。)
异步IO模型需要一个消息循环,在消息循环中,主线程不断地重复“读取消息-处理消息”这一过程:
loop = get_event_loop()
while True:
event = loop.get_event()
process_event(event)
##### 协程
**协程**,又称微线程,纤程。英文名Coroutine。
协程其实可以认为是比线程更小的执行单元。 为啥说他是一个执行单元,因为他自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
**协程和线程差异**
线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。 所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
**协程问题**
系统并不感知,所以操作系统不会帮你做切换。 那么谁来帮你做切换?让需要执行的协程更多的获得CPU时间才是问题的关键。
>**例子**
>>目前的协程框架一般都是设计成 1:N 模式。所谓 1:N 就是一个线程作为一个容器里面放置多个协程。 那么谁来适时的切换这些协程?答案是由协程自己主动让出CPU,也就是每个协程池里面有一个调度器, 这个调度器是被动调度的。意思就是他不会主动调度。而且当一个协程发现自己执行不下去了(比如异步等待网络的数据回来,但是当前还没有数据到), 这个时候就可以由这个协程通知调度器,这个时候执行到调度器的代码,调度器根据事先设计好的调度算法找到当前最需要CPU的协程。 切换这个协程的CPU上下文把CPU的运行权交个这个协程,直到这个协程出现执行不下去需要等待的情况,或者它调用主动让出CPU的API之类,触发下一次调度。
>>>**这个实现有一个问题:**假设这个线程中有一个协程是CPU密集型的他没有IO操作, 也就是自己不会主动触发调度器调度的过程,那么就会出现其他协程得不到执行的情况, 所以这种情况下需要程序员自己避免。
```python
# 协程简单例子
from time import sleep
def A():
a = 1
while a<4:
print('A a = {}'.format(a))
yield a
a += 1
sleep(0.3)
def B(c):
while True:
try:
print('B'.center(20, '*'))
next(c)
sleep(0.3)
except StopIteration:
break
if __name__ == '__main__':
a = A()
B(a)
*********B**********
A a = 1
*********B**********
A a = 2
*********B**********
A a = 3
*********B**********
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# greenlet 版协程
from greenlet import greenlet
from time import sleep
max = 5
def A():
a = 1
while a < max:
print('A a = {}'.format(a).center(20, '*'))
gr2.switch() # 切换至B()
a += 1
sleep(0.3)
def B():
b = 1
while b < max:
print("b in B is: %d" % b)
gr1.switch()
b += 1
sleep(0.3)
gr1 = greenlet(A)
gr2 = greenlet(B)
# 协程切换要注意:切换出协程后要记得切回,以便使携程运行完,防止出现孤儿
gr1.switch()
print("gr1.dead = {}, gr2.dead = {}".format(gr1.dead, gr2.dead))
gr2.switch() # 若不切回B会出现B协程一直存活的现象
print("gr1.dead = {}, gr2.dead = {}".format(gr1.dead, gr2.dead))
******A a = 1*******
b in B is: 1
******A a = 2*******
b in B is: 2
******A a = 3*******
b in B is: 3
******A a = 4*******
b in B is: 4
gr1.dead = True, gr2.dead = False
gr1.dead = True, gr2.dead = True
'''grevent:当遇到IO时,自动切换'''
# 使用例子
# -*- coding: utf-8 -*-
import gevent
def test(n):
for i in range(n):
print('this is "{}" at NO.{}'.format(gevent.getcurrent(), i))
g1 = gevent.spawn(test, 3)
g2 = gevent.spawn(test, 3)
g1.join()
g2.join()
this is "" at NO.0
this is "" at NO.1
this is "" at NO.2
this is "" at NO.0
this is "" at NO.1
this is "" at NO.2
# gevent 切换执行
# -*- coding: utf-8 -*-
import gevent
def test(n):
for i in range(n):
print('this is "{}" at NO.{}'.format(gevent.getcurrent(), i))
gevent.sleep(0.3)
g1 = gevent.spawn(test, 3)
g2 = gevent.spawn(test, 3)
g1.join()
g2.join()
this is "" at NO.0
this is "" at NO.0
this is "" at NO.1
this is "" at NO.1
this is "" at NO.2
this is "" at NO.2
asyncio、async/await、aiohttp
参考自廖雪峰的Python教程,不在此赘述,下文给出参考网址
asyncio
async/await
aiohttp
网络编程
使用网络能够把多方链接在一起,然后可以进行数据传递
所谓的网络编程就是,让在不同的电脑上的软件能够进行数据传递,即进程之间的通信
Python Internet 模块
| 协议 | 功能用处 | 端口号 | Python模块 |
|---|---|---|---|
| HTTP | 网页访问 | 80 | httplib, urllib, xmlrpclib |
| NNTP | 阅读和张贴新闻文章,俗称为"帖子" | 119 | nntplib |
| FTP | 文件传输 | 20 | fitlib, urllib |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 接收邮件 | 110 | poplib |
| IMAP4 | 获取邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 信息查找 | 70 | gopherlib,urllib |
TCP/IP协议(族)
应用层:应用层,表示层,会话层
传输层:传输层
网络层:网络层
链路层:数据链路层,物理层

对上图的说明:
网际层也称为:网络层;网络接口层也称为:链路层
端口
端口:可以认为是设备与外界通讯交流的出口。
端口号是唯一的
端口范围:0~65535
端口分类:
**公认端口(WellKnownPorts):**从0到1023,它们紧密绑定(binding)于一些服务。
**注册端口(RegisteredPorts):**从1024到49151。它们松散地绑定于一些服务。也就是说有许多服务绑定于这些端口,这些端口同样用于许多其它目的。例如:许多系统处理动态端口从1024左右开始。
**动态和/或私有端口(Dynamicand/orPrivatePorts):**从49152到65535。理论上,不应为服务分配这些端口。实际上,机器通常从1024起分配动态端口。但也有例外:SUN的RPC端口从32768开始。
查看端口:
1、netstat -an指令查看
2、第三方扫描软件
IP地址
ip地址:用来在网络中标记一台电脑的一串数字,比如192.168.1.1;在本地局域网上是惟一的。
ip地址分类:
A类IP地址
一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”,地址范围1.0.0.1-126.255.255.254二进制表示为:00000001 00000000 00000000 00000001 - 01111110 11111111 11111111 11111110
可用的A类网络有126个,每个网络能容纳1677214个主机
B类IP地址
一个B类IP地址由2个字节的网络地址和2个字节的主机地址组成,网络地址的最高位必须是“10”,地址范围128.1.0.1-191.255.255.254
二进制表示为:10000000 00000001 00000000 00000001 - 10111111 11111111 11111111 11111110
可用的B类网络有16384个,每个网络能容纳65534主机
C类IP地址
一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”
范围192.0.1.1-223.255.255.254
二进制表示为: 11000000 00000000 00000001 00000001 - 11011111 11111111 11111110 11111110
C类网络可达2097152个,每个网络能容纳254个主机
D类地址用于多点广播
D类IP地址第一个字节以“1110”开始,它是一个专门保留的地址。
它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中
多点广播地址用来一次寻址一组计算机
地址范围224.0.0.1-239.255.255.254
- E类IP地址*
以“1111”开始,为将来使用保留
E类地址保留,仅作实验和开发用
- 私有ip*
在这么多网络IP中,国际规定有一部分IP地址是用于我们的局域网使用,也就
是属于私网IP,不在公网中使用的,它们的范围是:10.0.0.0~10.255.255.255
172.16.0.0~172.31.255.255
192.168.0.0~192.168.255.255
注意
IP地址127.0.0.1~127.255.255.255用于回路测试,
如:127.0.0.1可以代表本机IP地址,用[http://127.0.0.1]
就可以测试本机中配置的Web服务器。
子网掩码
子网掩码(subnet mask)又叫网络掩码、地址掩码、子网络遮罩,
它是一种用来指明一个IP地址的哪些位标识的是主机所在的子网,
以及哪些位标识的是主机的位掩码。
子网掩码不能单独存在,它必须结合IP地址一起使用。
子网掩码只有一个作用:就是将某个IP地址划分成网络地址和主机地址两部分。
与IP地址相同,子网掩码的长度也是32位,
左边是网络位,用二进制数字“1”表示;
右边是主机位,用二进制数字“0”表示。
假设IP地址为“192.168.1.1”子网掩码为“255.255.255.0”。
其中,“1”有24个,代表与此相对应的IP地址左边24位是网络号;
“0”有8个,代表与此相对应的IP地址右边8位是主机号。
这样,子网掩码就确定了一个IP地址的32位二进制数字中哪些是网络号、哪些是主机号。
这对于采用TCP/IP协议的网络来说非常重要,只有通过子网掩码,才能表明一台主机所在的子网与其他子网的关系,使网络正常工作。
子网掩码是“255.255.255.0”的网络:
最后面一个数字可以在0~255范围内任意变化,因此可以提供256个IP地址。
但是实际可用的IP地址数量是256-2,即254个,因为主机号不能全是“0”或全是“1”。
主机号全为0,表示网络号
主机号全为1,表示网络广播
注意:
如果将子网掩码设置过大,也就是说子网范围扩大,根据子网寻径规则,很可能发往和本地主机不在同一子网内的目标主机的数据,会因为错误的判断而认为目标主机是在同一子网内,导致数据包将在本子网内循环,直到超时并抛弃,使数据不能正确到达目标主机,导致网络传输错误;如果将子网掩码设置得过小,那么就会将本来属于同一子网内的机器之间的通信当做是跨子网传输,数据包都交给缺省网关处理,这样势必增加缺省网关的负担,造成网络效率下降。因此,子网掩码应该根据网络的规模进行设置。如果一个网络的规模不超过254台电脑,采用“255.255.255.0”作为子网掩码就可以了,现在大多数局域网都不会超过这个数字,因此“255.255.255.0”是最常用的IP地址子网掩码;假如在一所大学具有1500多台电脑,这种规模的局域网可以使用“255.255.0.0”。
socket
本地(一台机器上)的进程间通信(IPC)有很多种方式,例如
队列
同步(互斥锁、条件变量等)
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket(简称:套接字)。
Python提供了两个级别访问的网络服务:
低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
Python创建socket:
import socket
socket.socket(family[, type[, protocol]])
参数解释:
family:套接字家族可以使AF_UNIX或者AF_INET
type:套接字类型可以根据是面向连接的还是非连接分为SOCK_STREAM或SOCK_DGRAM
protocol:一般不填默认为0.
Socket 对象(内建)方法
服务器端套接字
s.bind()
绑定地址(host, port)到socket, 在AF_INET下,以元组(host, port的形式表示地址。)
s.listen()
开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。
s.accept()
被动接受TCP客户端连接,(阻塞式)等待连接的到来
返回为(socket object, address info)
其中socket object用于处理连接期间的通信,
包括服务器接收自客户端的信息,和服务器向客户端发送的信息。
区别于服务器套接字(server_socket)和客户端套接字(client_socket),
可以记为通信套接字(communication_socket)
而address info是客户端的ip地址及端口(ip:port)
客户端套接字
s.connect()
主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
s.connect_ex()
connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv()
接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。
s.send()
发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。
s.sendall()
完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
s.recvfrom(size)
接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
s.sendto(msg, addr)
发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。
s.close()
关闭套接字
s.getpeername()
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
s.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
s.setsockopt(level, optname, value)
设置给定套接字选项的值。
s.getsocketopt(level, optname, buflen)
返回套接字选项的值。
s.settimeout(timeout)
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect())
s.gettimeout()
返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。
s.gileno()
返回套接字的文件描述符。
s.setbolcking(flag)
如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常
s.makefile()
创建一个与该套接字相关连的文件
# 创建socket 例子
import socket
# 创建一个tcp socket
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print('tcp socket created!')
# 创建一个udp socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
print('udp socket created!')
tcp socket created!
udp socket created!
# socket 简单服务器
# 导入socket, sys 模块
import socket
import sys
from time import time
# 创建socket对象
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 指定绑定地址
host = ""
# 是指端口
port = 6666
# 绑定端口号
server_socket.bind((host, port))
# 设置最大连接数,超过后阻塞
server_socket.listen(5)
# 使用start_time、stop_time、run_time来控制循环运行
start_time = time() # 开始监听时间
run_time = 0 # 运行时间
while run_time < 10: # 运行时长:10s
# 建立客户端连接
client_socket, addr = server_socket.accept()
print("client add is {}".format(addr))
msg = "Hello this is server_socket send message!".encode("utf-8")
client_socket.send(msg)
client_socket.close()
stop_time = time() # 停止时间
run_time = stop_time - start_time # 总运行时间
print("Server exit.")
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
in
21 while run_time < 10: # 运行时长:10s
22 # 建立客户端连接
---> 23 client_socket, addr = server_socket.accept()
24
25 print("client add is {}".format(addr))
~/WorkStations/anaconda3/lib/python3.7/socket.py in accept(self)
210 For IP sockets, the address info is a pair (hostaddr, port).
211 """
--> 212 fd, addr = self._accept()
213 sock = socket(self.family, self.type, self.proto, fileno=fd)
214 # Issue #7995: if no default timeout is set and the listening
KeyboardInterrupt:
# socket 客户端例子
# 导入socket, sys 模块
import socket
import sys
# 创建socket对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 指定服务器地址
host = "127.0.0.1"
# 是指端口
port = 6666
# 连接服务,指定主机和端口
s.connect((host, port))
# 接收小于2048字节的数据
msg = s.recv(2048)
s.close()
print(msg.decode('utf-8'))
socket 服务器 客户端 通信 结果图
 #### UDP
#### UDP
UDP — 用户数据报协议,是一个无连接的简单的面向数据报的运输层协议。
udp是TCP/IP协议族中的一种协议能够完成不同机器上的程序间的数据通信
udp只是把应用层传给ip层的数据报发出去,不能保证到达;udp在传输数据报前不用在客户和服务器之间建立连接,没有超时重发等机制,传输速度快。
UDP是一种面向无连接的协议,每个数据报都是一个独立的信息,包括完整的源地址或目的地址,它在网络上以任何可能的路径传往目的地,因此能否到达目的地,到达目的地的时间以及内容的正确性都是不能被保证的。
UDP特点:
面向无连接的通讯协议,UDP数据包括目的端口号和源端口号信息,由于通讯不需要连接,所以可以实现广播发送。
UDP传输数据有大小限制:每个被传输的数据报必须限定在64KB内。
udp不可靠,发送方所发送的数据报并不一定以相同的次序到达接收方。
UDP一般用于多点通信和实时的数据业务:
语音广播
视频
QQ
TFTP(简单文件传送)
SNMP(简单网络管理协议)
RIP(路由信息协议,如报告股票市场,航空信息)
DNS(域名解释)
UDP操作简单,而且仅需要较少的监护,因此通常用于局域网高可靠性的分散系统中client/server应用程序。
udp端口号动态变化解释:
每次重新运行网络程序,对于未绑定端口号的程序,系统默认随机分配一个端口号来唯一标识这个程序。如果需要向此程序发送信息,只需要向这个端口标识的程序发送即可。
UDP网络通信过程
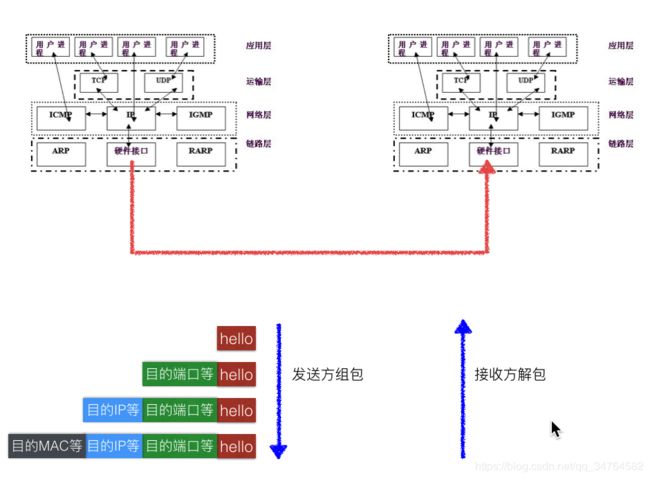
udp服务器、客户端
udp的服务器和客户端的区分:往往是通过请求服务和提供服务来进行区分
请求服务的一方称为:客户端
提供服务的一方称为:服务器
udp 发送数据:
创建一个udp客户端程序步骤:
1、创建客户端套接字
2、发送/接收数据
3、关闭套接字
UDP创建流程图
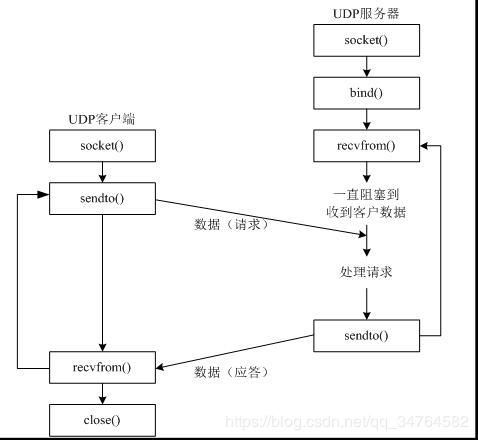
# 创建udp 客户端 例子udp
# -*- coding: utf-8 -*-
import socket
# 创建客户端socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 服务器地址
server_addr = ("192.168.1.1", 2333)
# 客户端向服务器发送的信息
# 记得编码【encode()】
client_data = "hello".encode("utf-8")
# 向服务器发送client_data数据
client_socket.sendto(client_data, server_addr)
# 接收服务器发送的信息(数据,地址)
msg, addr = client_socket.recvfrom(1024)
# 打印接收自服务器的信息msg, 服务器地址:addr
print("server message is:\n\t{}\nserver address is:{}\n\t".format(
msg.decode("utf-8"), addr))
# 关闭连接
client_socket.close()
# udp 服务器
# -*- coding: utf-8 -*-
import socket
# 创建服务器socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 设置绑定地址
listen_addr = ("", 2333)
# 绑定地址
server_socket.bind(listen_addr)
# 接收客户端信息msg,客户端地址addr
msg, addr = server_socket.recvfrom(1024)
# 打印客户发送的数据
print("receive message from client:\n\t{}".format(msg.decode("utf-8")))
# 服务器向客户端发送的数据
server_data = "this is server_data".encode("utf-8")
# 向客户端addr,发送数据server_data
server_socket.sendto(server_data, addr)
# 关闭连接
server_socket.close()
udp绑定
一个udp网络程序,可以不绑定,此时操作系统会随机进行分配一个端口,
如果重新运行次程序端口可能会发生变化
一个udp网络程序,也可以绑定信息(ip地址,端口号),如果绑定成功,
那么操作系统用这个端口号来进行区别收到的网络数据是否是此进程的
# udp 接收方 端口绑定 例子
# -*-coding: utf-8 -*-
import socket
# 1、创建socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2、绑定本地的相关信息,若一个网络程序不绑定,则系统会随机分配端口号
bind_addr = ('',6666)# ip地址和端口号,ip一般不用写,表示本机的任何一个ip
udp_socket.bind(bind_addr)
# 3、等待接收数据
recv_data = udp_socket.recvfrom(1024)# 1204为本次接收的最大字节数
# 4、显示接收数据
# 若接收到的是bite格式,则用decode('decode-type')解码,str类型不必decode
print(recv_data.decode('utf-8'))
# 5、关闭socket
udp_socket.close()
# 因为例子是接收方的端口绑定,所以单独运行是没有显示的,故不运行
# udp echo 服务器 示例
# echo服务器:将收到的信息原封不动的返回
import socket
# 1、创建socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2、绑定本地相关信息
bind_addr = ('', 6666)# ip地址和端口号,ip一般不用写,表示本机的任何一个ip
udp_socket.bind(bind_addr)
# 统计次数
num = 0
while True:
# 3、等待接收对方发送的数据
recv_data = udp_socket.recvfrom(2048)# 最大接收字节数2048
# 4、回传接收到的信息
udp_socket.sendto(recv_data[0], recv_data[1])
# 5、统计信息
num +=1
print('已完成{}次数据收发'.format(num))
# 5、关闭socket
udp_socket.close()
udp广播
# udp 广播例子
# -*- coding: utf-8 -*-
import socket, sys
from time import time
dest = ('' , 6666)
# 创建socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 对socket进行修改,以发送广播
s.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1)
# 以广播的形式发送数据到网络的所有电脑中
s.sendto('hello, world!'.encode("utf-8"), dest)
print('等待回复,Ctrl+c退出')
start_time = time()
run_time = 0
while run_time < 10:
(buf, address) = s.recvfrom(2048)
print("received from {}:{}".format(address, buf))
stop_time = time()
run_time = stop_time - start_time
等待回复,Ctrl+c退出
TCP
tcp通信模型中,在通信开始之前,一定要先建立相关的链接,才能发送数据,类似于生活中"打电话"
TCP三次握手和四次挥手部分参考自下面的网址:
参考网址 作者:小书go
背景描述:
网络层,可以实现两个主机之间的通信。但是这并不具体,因为,真正进行通信的实体是在主机中的进程,是一个主机中的一个进程与另外一个主机中的一个进程在交换数据。IP协议虽然能把数据报文送到目的主机,但是并没有交付给主机的具体应用进程。而端到端的通信才应该是应用进程之间的通信。
UDP,在传送数据前不需要先建立连接,远地的主机在收到UDP报文后也不需要给出任何确认。虽然UDP不提供可靠交付,但是正是因为这样,省去和很多的开销,使得它的速度比较快,比如一些对实时性要求较高的服务,就常常使用的是UDP。对应的应用层的协议主要有 DNS,TFTP,DHCP,SNMP,NFS 等。
TCP,提供面向连接的服务,在传送数据之前必须先建立连接,数据传送完成后要释放连接。因此TCP是一种可靠的的运输服务,但是正因为这样,不可避免的增加了许多的开销,比如确认,流量控制等。对应的应用层的协议主要有 SMTP,TELNET,HTTP,FTP 等。
TCP报文首部
-
源端口和目的端口,各占2个字节,分别写入源端口和目的端口;
-
序号,占4个字节,TCP连接中传送的字节流中的每个字节都按顺序编号。例如,一段报文的序号字段值是 301 ,而携带的数据共有100字段,显然下一个报文段(如果还有的话)的数据序号应该从401开始;
-
确认号,占4个字节,是期望收到对方下一个报文的第一个数据字节的序号。例如,B收到了A发送过来的报文,其序列号字段是501,而数据长度是200字节,这表明B正确的收到了A发送的到序号700为止的数据。因此,B期望收到A的下一个数据序号是701,于是B在发送给A的确认报文段中把确认号置为701;
-
数据偏移,占4位,它指出TCP报文的数据距离TCP报文段的起始处有多远;
-
保留,占6位,保留今后使用,但目前应该都位0;
-
紧急URG,当URG=1,表明紧急指针字段有效。告诉系统此报文段中有紧急数据;
-
确认ACK,仅当ACK=1时,确认号字段才有效。TCP规定,在连接建立后所有报文的传输都必须把ACK置1;
-
推送PSH,当两个应用进程进行交互式通信时,有时在一端的应用进程希望在键入一个命令后立即就能收到对方的响应,这时候就将PSH=1;
-
复位RST,当RST=1,表明TCP连接中出现严重差错,必须释放连接,然后再重新建立连接;
-
同步SYN,在连接建立时用来同步序号。当SYN=1,ACK=0,表明是连接请求报文,若同意连接,则响应报文中应该使SYN=1,ACK=1;
-
终止FIN,用来释放连接。当FIN=1,表明此报文的发送方的数据已经发送完毕,并且要求释放;
-
窗口,占2字节,指的是通知接收方,发送本报文你需要有多大的空间来接受;
-
检验和,占2字节,校验首部和数据这两部分;
-
紧急指针,占2字节,指出本报文段中的紧急数据的字节数;
-
选项,长度可变,定义一些其他的可选的参数。
TCP通信过程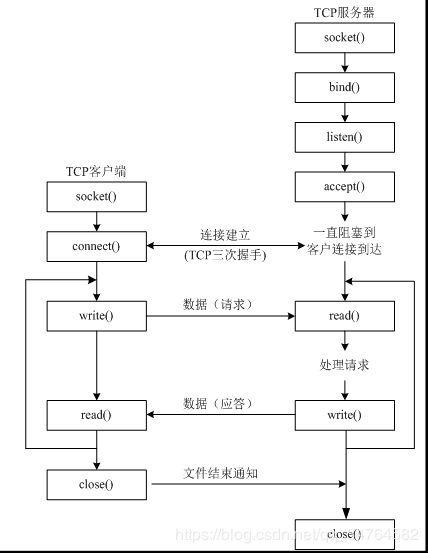 ##### TCP三次握手
##### TCP三次握手

syn>>>> syn+ack<<<<<<<<<<<< ack>>>>>>>>>>>>>>>
*tcp传输前会发送ack包确认,但是udp不会进行确认,所以有tcp比udp稳定
client close()方法,会通知到server,server会回复通知信息,然后client回复,挥手完*
 >图片作者:小书go
>图片作者:小书go
感觉作者关于TCP的三次握手与四次挥手写的比我好,请移步作者博客
作者博客地址:导向链接
https://blog.csdn.net/qzcsu/article/details/72861891
最开始的时候客户端和服务器都是处于CLOSED状态。主动打开连接的为客户端,被动打开连接的是服务器。
-
TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态;
-
TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
-
TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
-
TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
为什么TCP客户端最后还要发送一次确认
一句话,主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
tcp四次挥手

 >图片作者:小书go
>图片作者:小书go
感觉作者关于TCP的三次握手与四次挥手写的比我好,请移步作者博客
作者博客地址:导向链接
https://blog.csdn.net/qzcsu/article/details/72861891
数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于ESTABLISHED状态,然后客户端主动关闭,服务器被动关闭。
-
客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
-
服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
-
客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
-
服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
-
客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
-
服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
tcp十种状态
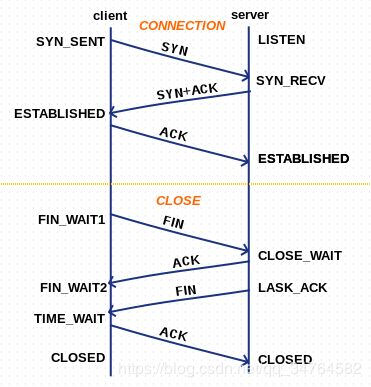
当一端收到一个FIN,内核让read返回0来通知应用层另一端已经终止了向本端的数据传送
发送FIN通常是应用层对socket进行关闭的结果
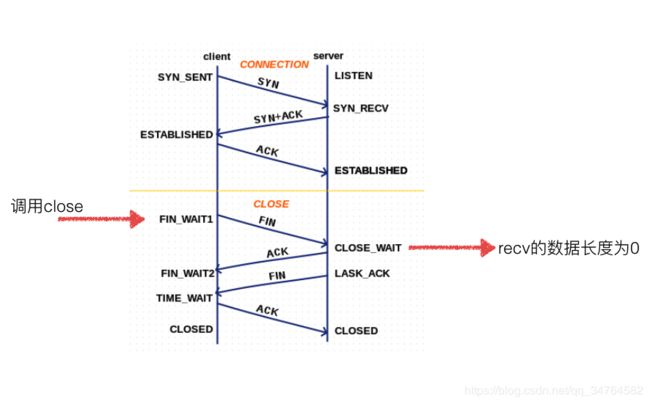
TCP的2MSL问题

MSL(Maximum Segment Lifetime),TCP允许不同的实现可以设置不同的MSL值。
第一,保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
为什么建立连接是三次握手,关闭连接确是四次挥手呢?
建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
而关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75分钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
TCP长连接和短连接
TCP在真正的读写操作之前,server与client之间必须建立一个连接,
当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,
连接的建立通过三次握手,释放则需要四次握手,
所以说每个连接的建立都是需要资源消耗和时间消耗的。
TCP短连接
模拟一种TCP短连接的情况:
-
client 向 server 发起连接请求
-
server 接到请求,双方建立连接
-
client 向 server 发送消息
-
server 回应 client
-
一次读写完成,此时双方任何一个都可以发起 close 操作
在第 步骤5中,一般都是 client 先发起 close 操作。当然也不排除有特殊的情况。
从上面的描述看,短连接一般只会在 client/server 间传递一次读写操作!
TCP长连接
模拟一种TCP长连接的情况:
-
client 向 server 发起连接请求
-
server 接到请求,双方建立连接
-
client 向 server 发送消息
-
server 回应 client
-
一次读写完成,连接不关闭
-
后续读写操作…
-
长时间操作之后client发起关闭请求
TCP长/短连接操作过程
短连接:
建立连接——数据传输——关闭连接…建立连接——数据传输——关闭连接
长连接:
建立连接——数据传输…(保持连接)…数据传输——关闭连接
长短连接各自优缺点:
长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。
对于频繁请求资源的客户来说,较适用长连接。

client与server之间的连接如果一直不关闭的话,会存在一个问题,
随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,
如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;
如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,
这样可以完全避免某个蛋疼的客户端连累后端服务。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。
但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
TCP长/短连接的应用场景:
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,
常见网络攻击案例
tcp半链接攻击
tcp半链接攻击也称为:SYN Flood (SYN洪水)
是种典型的DoS (Denial of Service,拒绝服务) 攻击
效果就是服务器TCP连接资源耗尽,停止响应正常的TCP连接请求
dns攻击
dns服务器被劫持
域名服务器对其区域内的用户解析请求负责,但是并没有一个机制去监督它有没有真地负责。
将用户引向一个错误的目标地址。这就叫作 DNS 劫持,主要用来阻止用户访问某些特定的网站,或者是将用户引导到广告页面。
dns欺骗
DNS 欺骗简单来说就是用一个假的 DNS 应答来欺骗用户计算机,让其相信这个假的地址,并且抛弃真正的 DNS 应答。
arp攻击

TCP服务器
创建TCP服务器过程:
1、创建socket
2、bind绑定ip和port
3、listen使套接字变为可以被动链接
4accept等待客户端的链接
5、recv/send接收发送数据
TCP服务器创建流程:socket(), bind(), listen(), accept(), read(), write(), close()
# tcp服务器 示例代码
# -*- coding: utf -8 -*-
import socket
# 创建socket
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定本地信息
address = ("", 6666)
tcp_server_socket.bind(address)
# 使用socket创建的套接字默认的属性是主动的,使用listen变为被动
# 变为被动后,就可以接收别人的链接了
tcp_server_socket.listen(5)
# 有行的客户端链接服务器,就为这个客户端生成一个新的套接字
# new_socket用来为这个客户端服务
# tcp_server_socket可以省下等待其他新的客户端链接
new_socket, client_addr = tcp_server_socket.accept()
# 接收对方发送的数据,最大为1024字节
recv_data = new_socket.recv(1024)
print('接收到的数据为:{}'.format(recv_data))
# 发送数据到客户端
new_socket.send('send from server!')
# 关闭为此客户端创建的socket
# 关闭后就不再服务,要想继续服务只能重连
new_socket.close()
# 关闭监听socket,此socket关闭表示不再接收客户端链接
tcp_server_socket.close()
TCP客户端
# tcp 客户端 示例代码
# -*- coding: utf-8 -*-
import socket
# 创建socket
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 链接服务器
server_addr = ('192.168.1.1', 6666)
tcp_client_socket.connect(server_addr)
# 提示输入数据
send_data = input('请输入要发送的数据:')
# 接收服务器发送来的数据,最大接收1024字节
recv_data = tcp_client_socket.recv(1024)
print('接收到的数据:{}'.format(recv_data))
# 关闭socket
tcp_client_socket.close()
'''tcp 模拟qq'''
# 客户端代码
# -*- coding: utf-8 -*-
import socket
# 创建secket
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接服务器
server_addr = ('192.168.1.1', 6666)
tcp_client_socket.connect(server_addr)
while True:
# 提示用户输入数据
send_data = input('send: ')
if len(send_data)>0:
tcp_client_socket.send(send_data)
else:
break
# 接收对方发来的数据,最大接收1024字节
recv_data = tcp_client_socket.recv(1024)
print('received:', recv_data)
# 关闭套接字
tcp_client_socket.close()
# 服务器 实例代码
#-*- coding: utf-8 -*-
import socket
# create socket
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定本地信息
address = ('', 6666)
tcp_server_socket.bind(address)
#用listen变socket为被动
tcp_server_socket.listen(5)
while True:
# new socket
new_socket, client_addr = tcp_server_socket.accept()
while True:
# 接收数据,最大接收1024字节
recv_data = new_socket.recv(1024)
# 接收到的数据长度为0,表示客户端关闭链接
if len(recv_data)>0:
print('recv: ', recvData)
else:
break
# 发送数据到客户端
send_data = input('send: ')
new_socket.send(send_data)
# 关闭此客户端的套接字,不再为此客户端服务
new_socket.close()
# 关闭监听socket
tcp_server_socket.close()
网络编程 应用
单全双工信息收发
单工:只能接收,半双工:同一时刻只能接收或是发送,全双工:可接可发
socket(套接字)是全双工的
编码:encode(“utf-8”)
解码:decode(“utf-8”)
# 简单全双工信息收发 例子
#-*-coding: utf-8 -*-
from threading import Thread
import socket
# 接收数据,打印
def recv_data():
while True:
recv_msg = udp_socket.recvfrom(4096)
print('收到>:{}:()'.str(recv_msg[1], recv_msg[0]))
# 发送数据
def send_data():
while True:
send_data = input('发送\r<:')
print('>:')
udp_socket.sendto(send_data.encode('utf-8'), (which_ip, which_port))
# socket, ip, port
udp_socket = None
which_ip = ''
which_port = 0
def main():
global udp_socket
global which_ip
global which_port
# 输入ip:port
which_ip = input('请输入对方IP:\t')
which_port = input("请输入对方的port:\t")
# create socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# bind local info
udp_socket.bind('', 6666)
# create threading
tr = Thread(target=recv_data)
ts = Thread(target=send_data)
# start threading
tr.start()
ts.start()
# blocking
tr.join()
ts.join()
if __name__=='__main__':
main()
TFTP客户端
TFTP 协议介绍
TFTP(Trivial File Transfer Protocol,简单文件传输协议)是TCP/IP协议族中的一个用来在客户端与服务器之间进行简单文件传输的协议
TFTP特点:
简单
占用资源小
适合传递小文件
适合在局域网进行传递
端口号为69
基于UDP实现
TFTP下载过程
TFTP服务器默认监听69号端口
当客户端发送“下载”请求(即读请求)时,需要向服务器的69端口发送
服务器若批准此请求,则使用一个新的、临时的端口进行数据传输
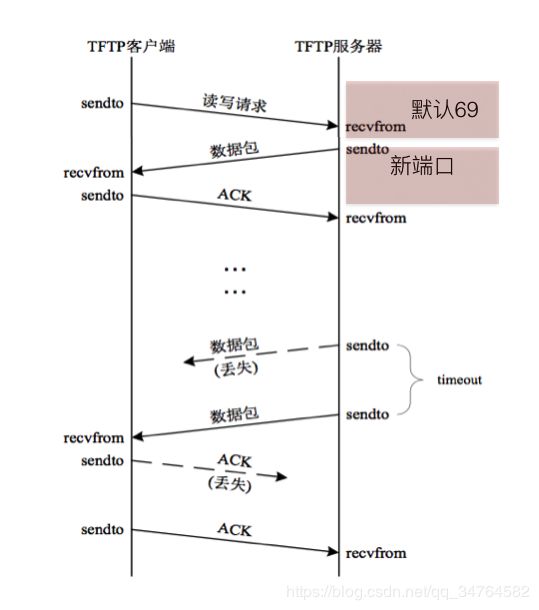
当服务器找到需要现在的文件后,会立刻打开文件,把文件中的数据通过TFTP协议发送给客户端
如果文件的总大小较大(比如3M),那么服务器分多次发送,每次会从文件中读取512个字节的数据发送过来
因为发送的次数有可能会很多,所以为了让客户端对接收到的数据进行排序,所以在服务器发送那512个字节数据的时候,会多发2个字节的数据,用来存放序号,并且放在512个字节数据的前面,序号是从1开始的
因为需要从服务器上下载文件时,文件可能不存在,那么此时服务器就会发送一个错误的信息过来,为了区分服务发送的是文件内容还是错误的提示信息,所以又用了2个字节 来表示这个数据包的功能(称为操作码),并且在序号的前面
| 操作码 | 功能 |
|---|---|
| 1 | 读请求(下载) |
| 2 | 写请求(上传) |
| 3 | 表示数据包(DATA) |
| 4 | 确认码(ACK) |
| 5 | 错误 |
TFTP协议中规定,服务器确认客户端收到刚刚发送的数据包:当客户端接收到一个数据包的时候需要向服务器进行发送确认信息,这样的包成为ACK(应答包)
发送完:客户端接收到的数据小于516(2字节操作码+2字节序号+512字节数据)
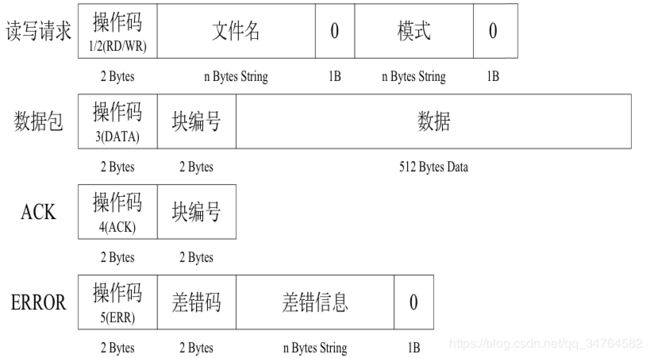
'''
同一时刻只能为一个客户进行服务,不能同时为多个客户服务
类似于找一个“明星”签字一样,客户需要耐心等待才可以获取到服务
当服务器为一个客户端服务时,而另外的客户端发起了connect,
只要服务器listen的队列有空闲的位置,就会为这个新客户端进行连接,
并且客户端可以发送数据,但当服务器为这个新客户端服务时,
可能一次性把所有数据接收完毕
当recv接收数据时,返回值为空,即没有返回数据,
那么意味着客户端已经调用了close关闭了;
因此服务器通过判断recv接收数据是否为空 来判断客户端是否已经下线
'''
# tftp 客户端 示例代码
# -*- coding:utf-8 -*-
import struct
from socket import *
import time
import os
def main():
#0. 获取要下载的文件名字:
downloadFileName = raw_input("请输入要下载的文件名:")
#1.创建socket
udpSocket = socket(AF_INET, SOCK_DGRAM)
# 这里对下面的!H8sb5sb解释:
# !H占两个,表示操作码,8s是文件名的占位长度,b是0的占位长度,5sb同理
requestFileData = struct.pack("!H%dsb5sb"%len(downloadFileName), 1, downloadFileName, 0, "octet", 0)
#2. 发送下载文件的请求
udpSocket.sendto(requestFileData, ("192.168.119.215", 69))
flag = True #表示能够下载数据,即不擅长,如果是false那么就删除
num = 0
f = open(downloadFileName, "w")
while True:
#3. 接收服务发送回来的应答数据
responseData = udpSocket.recvfrom(1024)
# print(responseData)
recvData, serverInfo = responseData
opNum = struct.unpack("!H", recvData[:2])
packetNum = struct.unpack("!H", recvData[2:4])
print(packetNum[0])
# print("opNum=%d"%opNum)
# print(opNum)
# if 如果服务器发送过来的是文件的内容的话:
if opNum[0] == 3: #因为opNum此时是一个元组(3,),所以需要使用下标来提取某个数据
#计算出这次应该接收到的文件的序号值,应该是上一次接收到的值的基础上+1
num = num + 1
# 如果一个下载的文件特别大,即接收到的数据包编号超过了2个字节的大小
# 那么会从0继续开始,所以这里需要判断,如果超过了65535 那么就改为0
if num==65536:
num = 0
# 判断这次接收到的数据的包编号是否是 上一次的包编号的下一个
# 如果是才会写入到文件中,否则不能写入(因为会重复)
if num == packetNum[0]:
# 把收到的数据写入到文件中
f.write(recvData[4:])
num = packetNum[0]
#整理ACK的数据包
ackData = struct.pack("!HH", 4, packetNum[0])
udpSocket.sendto(ackData, serverInfo)
elif opNum[0] == 5:
print("sorry,没有这个文件....")
flag = False
# time.sleep(0.1)
if len(recvData)<516:
break
if flag == True:
f.close()
else:
os.unlink(downloadFileName)#如果没有要下载的文件,那么就需要把刚刚创建的文件进行删除
if __name__ == '__main__':
main()
单进程 TCP服务器
# 单进程 TCP服务器
from socket import *
server_socket = socket(AF_INET, SOCK_STREAM)
# 重用绑定的信息
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
local_addr = ('', 6666)
server_socket.bind(local_addr)
server_socket.listen(5)
while True:
print('主进程,等待新客户端的到来')
new_socket, dest_addr = server_socket.accept()
print('主进程, 接下来负责数据处理{}'.format(str_dest_addr))
try:
while True:
recv_data = new_socket.recv(1024)
if len(recv_data)>0:
print('recv[{}]:{}'.format(str(dest_addr), recv_data))
else:
print('{}客户端已经关闭'.format(str(dest_addr)))
finally:
new_socket.close()
server_socket.close()
主进程,等待新客户端的到来
多进程服务器
# 多进程服务器
'''
通过为每个客户端创建一个进程的方式,能够同时为多个客户端进行服务
当客户端不是特别多的时候,这种方式还行,如果有几百上千个,就不可取了,
因为每次创建进程等过程需要较大的资源
'''
import socket
from multiprocessing import Process
from time import sleep
# 处理客户端请求,并为其服务
def deal_with_client(new_socket, dest_addr):
while True:
recv_data = enw_socket.recv(1024)
if len(recv_data)>0:
print('recv[{}]: {}'.format(str(dest_addr), recv_data))
else:
print('[{}]客户端已经关闭'.format(str(dest_addr)))
break
new_socket.close()
def main():
server_socket = socket(AF_INET, SOCK_STREAM)
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
local_addr = ('', 6666)
server_socket.bind(local_addr)
server_socket.listen(5)
try:
while True:
print('主进程,等待新客户端的到来')
new_socket, dest_addr = server_socket.accept()
print('主进程, 接下来创建一个新的进程负责数据处理[{}]'.format(str(dest_addr)))
client = Process(target=deal_with_client, args=(new_socket, dest_addr))
client.start()
# 因为已经向子进程copy了一份(引用),并且父进程中这个套接字也没有用处了
# 所以关闭
new_socket.close()
finally:
3 当为所有的客户端服务完后再关闭,表示不再接收新的客户端的连接
server_socket.close()
if __name__=='__main__':
main()
多线程服务器
# 多线程服务器
# -*- coding: utf-8 -*-
from socket import *
from threading import Thread
from thime import sleep
# 处理客户的请求并执行事情
def deal_with_client(new_socket, dest_addr):
while True:
recv_data = new_socket.recv(1024)
if len(recv_data)>0:
print('recv[{}]: {}'.format(str(dest_addr), recv_data))
else:
print('[{}]客户端已经关闭'.format(dest_addr))
break
new_socket.close()
def main():
server_socket = socket(AF_INET, SOCK_STREAM)
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
local_addr = ('',6666)
server_socket.bind(local_addr)
server_socket.listen(5)
try:
while True:
print('-----主进程,,等待新客户端的到来------')
new_socket, dest_addr = server_socket.accept()
print('主进程,接下来创捷一个新的进程负责数据处理[{}]'.format(
str(dest_addr)
))
client = Thread(target=deal_with_client, args=(new_socket, dest_addr))
client.start()
# 线程中共享socket, 若关闭会导致套接字不可用
# 但是此时在线程中这个socket可能还在收数据,因此不可关闭
# new_socket.close()
finally:
server_socket.close()
if __name__ =='__main__':
main()
单进程服务器,非阻塞模式
# 服务器
# -*- coding: utf-8 -*-
from socket import *
import time
# 存储所有的新连接的socket
g_socket_list = []
def main():
server_socket = socket(AF_INET, SOCK_STREAM)
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
local_addr = ('', 6666)
server_socket.bind(local_addr)
# 可以适当修改listen中的值来看看不同的现象
server_socket.listen(1000)
# 设置套接字为非阻塞
# 设置为非阻塞后,若accept时,无客户端connect,accept会抛出一个异常,
# 所以需要try处理异常
server_socket.setblocking(False)
while True:
# 测试
# time.sleep(0.5)
try:
new_client_info = server_socket.accept()
except Exception as result:
pass
else:
print('一个新的客户端到来:{}'.format(str(new_client_info))
new_client_infp[0].setblocking(False)
g_socket_list.append(new_client_info)
# 存储需要删除的客户端信息
need_del_client_info_list = []
for client_socket, client_addr in g_socket_list:
try:
recv_data = client_socket.recv(1024)
if len(recv_data)>0:
print('recv[{}]:{}'.format(str(client_addr), recv_data))
else:
print('[{}]客户端已经关闭'.format(client_addr))
client_socket.close()
g_need_del_client_info_list.append(client_socket, client_addr)
except Exception as result:
pass
for need_del_client_info in need_del_client_info_list:
g_socket_list.remove(need_del_client_info)
if __name__=='__main__':
main()
# 客户端
#coding=utf-8
from socket import *
import random
import time
serverIp = input("请输入服务器的ip:")
connNum = input("请输入要链接服务器的次数(例如1000):")
g_socketList = []
for i in range(int(connNum)):
s = socket(AF_INET, SOCK_STREAM)
s.connect((serverIp, 7788))
g_socketList.append(s)
print(i)
while True:
for s in g_socketList:
s.send(str(random.randint(0,100)))
# 用来测试用
#time.sleep(1)
select版 TCP服务器
select原理
多路复用的模型中,较常用的有select,epoll模型。这两个都是系统接口,
由操作系统提供。当然,Python的select模块进行了更高级的封装。
网络通信被Unix系统抽象为文件的读写,通常是一个设备,由设备驱动程序提供,驱动可以知道自身的数据是否可用。支持阻塞操作的设备驱动通常会实现一组自身的等待队列,如读/写等待队列用于支持上层(用户层)所需的block或non-block操作。设备的文件的资源如果可用(可读或者可写)则会通知进程,反之则会让进程睡眠,等到数据到来可用的时候,再唤醒进程。
这些设备的文件描述符被放在一个数组中,然后select调用的时候遍历这个数组,如果对于的文件描述符可读则会返回改文件描述符。当遍历结束之后,如果仍然没有一个可用设备文件描述符,select让用户进程则会睡眠,直到等待资源可用的时候在唤醒,遍历之前那个监视的数组。每次遍历都是依次进行判断的。
select 优缺点
优点
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。
缺点
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
对socket进行扫描时是依次扫描的,即采用轮询的方法,效率较低。
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。
# select 回显服务器
# 当客户端向服务器发送数据后,服务器会把客户端发送的数据发回客户端
# 当服务器端键入数据后,打印键入的数据,关闭服务器
# 当服务器运行超过30s后,自动关闭服务器
import select
import socket
import sys
from time import time
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('', 6660))
server.listen(5)
inputs = [server, sys.stdin]
running = True
# 设置服务时间控制
start_time = time()
run_time = 0
while run_time <30:
# 调用select函数,阻塞等待
readable, writeable, exceptional = select.select(inputs, [], [])
flag = False # 键入数据后关闭服务器
# 数据到达,循环
for sock in readable:
# 监听到新的连接
if sock == server:
conn, addr = server.accept()
# select 监听的socket
inputs.append(conn)
# 监听到键盘有输入
elif sock == sys.stdin:
cmd = sys.stdin.readline()
print(
"find the data input. The input is:\n\t{}\nThe server will EXIT."
.format(cmd))
flag = True
running = False
break
# 有数据到达
else:
# 读取客户端连接发送的数据
data = sock.recv(1024)
if data:
sock.send(data)
else:
# 移除select监听的socket
inputs.remove(sock)
sock.close()
# 如果检测到用户输入敲击键盘,那么就退出
if not running:
break
if flag:
break
stop_time = time()
run_time = stop_time - start_time
server.close()
# select回显服务器测试客户端代码
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import socket
from time import time
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_addr = ('127.0.0.1', 6666)
client_socket.connect_ex(server_addr)
msg = "hello world".encode("utf-8")
client_socket.send(msg)
recv_data = client_socket.recv(1024)
print("client receive data is:\n\t {}".format(recv_data.decode("utf-8")))
client_socket.close()
# 包含writeList服务器
# -*- coding: utf-8 -*-
import socket
import Queue
form select import select
server_ip = ('', 8888)
# 保存客户端发过来的消息,存入消息队列
message_queue = {}
input_list = []
output_list = []
if __name__ == '__main__':
server = socket.socket()
server.bind(server_ip)
server.listen(10)
# 设置为非阻塞
server.setblocking(False)
# 初始化将服务器加入监听列表
input_list.append(server)
while True:
# 开始select监听,对input_list中的服务端server进行监听
stdinput, stdoutput, stderr = select(inut_list, out_list, input_list)
# 循环判断是否有客户端连接进来,有客户端连接时select将触发
for obj in stdinput:
# 判断当前出发的是不是服务端对象,当触发的对象是服务端对象时,
# 说明有新客户连接进来了
if obj == server:
# 接收客户端的连接, 获取客户端对象和客户端地址信息
conn, addr = server.accept()
print('client {} connected!'.format(addr))
# 将客户端对象也加入到监听的列表中,当客户端发送消息时select将触发
input_list.append(conn)
# 为连接的客户端单独创建一个消息队列,用来保存客户端发送的消息
message_queue[conn] = Queue.Queue()
else:
# 将客户端加入到了监听列表(input_list),客户端发送消息就触发
try:
recv_data = obj.recv(1024)
# 客户端未断开
print('received {} from client {} '.format(recv_data, str(addr)))
# 将收到的消息放入到各客户端的消息队列中
message_queue[obj].put(recv_data)
# 将回复操作放到output列表中,让select监听
if obj not in output_list:
output_list.append(obj)
except ConnectionResetError:
# 客户端断开连接了,将客户端的监听中input列表中移除
input_list.remove(obj)
# 移除客户端的消息队列
del message_queue[obj]
print("\n[input] Client %s disconnected"%str(addr))
# 如果现在没有客户端请求,也没有客户端发送消息时,
# 开始对发送消息队列进行处理,是否需要发送消息
for sendobj in output_list:
try:
# 如果消息队列中有消息,从消息队列中获取要发送的消息
if not message_queue[sendobj].empty():
# 从该客户端对象的消息队列中获取要发送的消息
send_data = message_queue[sendobj].get()
sendobj.send(send_data)
else:
# 将监听移除等待下一次客户端发送消息
output_list.remove(sendobj)
except ConnectResetError:
# 客户端连接断开
del message_queue[sendobj]
output_list.remove(sendobj)
print("\n[output] Client %s disconnected"%str(addr))
epoll版-TCP服务器
epoll的优点
没有最大并发连接的限制,能打开的FD(指的是文件描述符,通俗的理解就是套接字对应的数字编号)的上限远大于1024
效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;即epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,epoll的效率就会远远高于select和poll。
epoll使用说明
EPOLLIN (可读)
EPOLLOUT (可写)
EPOLLET (ET模式)
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
LT模式:当epoll检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll时,会再次响应应用程序并通知此事件。
ET模式:当epoll检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll时,不会再次响应应用程序并通知此事件。
# epoll 参考代码
import socket
import select
from select import epoll
# 创建socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置可以重复使用绑定的信息
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本机信息
s.bind('', 1234)
# 绑定本机信息
s.listen(10)
# 创建一个epoll对象
# 测试,用来打印套接字对应的文件描述符
# print s.fileno()
# print select.EPOLLIN|select.EPOLLET
# 注册事件到epoll中
# epoll.register(fd[, eventmask])
# 注意,如果fd已经注册过,则会发生异常
# 将创建的套接字添加到epoll的事件监听中
epoll.register(s.fileno(), select.EPOLLIN|select.EPOLLET)
connections = {}
addresses = {}
# 循环等待客户端的到来或者对方发送数据
while True:
# epoll 进行fd扫描的地方 -- 未指定超时时间为阻塞等待
epoll_list = epoll.poll()
# 对事件进行判断
for fd, events in epoll_list:
# print fd
# print event
# 如果是socket创建的socket被激活
if fd == s.fileno():
conn, addr = s.accept()
print('有新的客户端到来{}'.format(str(addr)))
# 将conn和addr信息分别保存起来
connections[conn.fileno()] = conn
addresses[conn.fileno()] = addr
# 向epoll中注册连接socket 的可读事件
epoll.register(conn.fileno(), select.EPOLLIN|select.EPOLLET)
elif events == select.EPOLLIN:
# 从激活fd上接收
recv_data = connections[fd].recv(1024)
if len(recv_data)>0:
print('recv: {} '.format(recv_data))
else:
# 从epoll中移除该连接 fd
epoll.unregister(fd)
# server 侧主动关闭该连接 fd
connections[fd].close()
print('{} ---offline---'.format(str(addresses[fd])))
# gevent版TCP服务器
import sys
import time
import gevent
from gevent import socket, monkey
monkey.patch_all()
def handle_request(conn):
data = conn.recv(1024)
if not data:
conn.close()
break
print('recv: {}'.format(data))
conn.send(data)
def server(port):
s = socket.socket()
s.bind(('', port))
s.listen(5)
while True:
cli, addr = s.accept()
gevent,spawn(handle_request, cli)
if __name__ == '__main__':
server(4567)
File "", line 17
break
^
SyntaxError: 'break' outside loop
C:\MyPrograms\Anaconda3\lib\site-packages\gevent\hub.py:154: UserWarning: libuv only supports millisecond timer resolution; all times less will be set to 1 ms
with loop.timer(seconds, ref=ref) as t:
网络分析工具
wireshark
linux 下可能出现问题:打开wireshark提示权限不足
解决方法:
参考网址
添加组,wireshark,但是安装软件时已经创建,这里可以省略
sudo groupadd wireshark
将自己添加到wireshark组
sudo usermod -a -G wireshark 'username'
newgrp wireshark
更改组别
sudo chgrp wireshark /usr/bin/dumpcap
添加权限(1-x, 2-w, 4-r)
sudo chmod 754 /usr/bin/dumpcap
这里原作者有两个方法,我选择一个简单的
sudo setcap cap_net_raw,cap_netadmin=eip /usr/bin/dumpcap
sudo reboot now
至此,问题解决
Packet Tracer
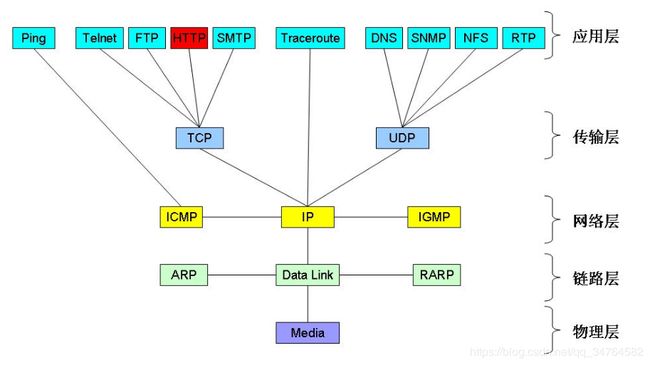
**hub(集线器)**能够完成多个电脑的链接
每个数据包的发送都是以广播的形式进行的,容易堵塞网络
交换机能够完成多个电脑的链接
每个数据包的发送都是以广播的形式进行的,容易堵塞网络
如果PC不知目标IP所对应的的MAC,那么可以看出,pc会先发送arp广播,得到对方的MAC然后,在进行数据的传送
当switch第一次收到arp广播数据,会把arp广播数据包转发给所有端口(除来源端口);如果以后还有pc询问此IP的MAC,那么只是向目标的端口进行转发数据
**路由器(Router)**又称网关设备(Gateway)是用于连接多个逻辑上分开的网络
在同一网段的pc,需要设置默认网关才能把数据传送过去 通常情况下,都会把路由器默认网关
当路由器收到一个其它网段的数据包时,会根据“路由表”来决定,把此数据包发送到哪个端口;路由表的设定有静态和动态方法
每经过一次路由器,那么TTL值就会减一
Ciso 的packet tracer
hub集线器现在基本已经废弃,现在一般用交换机
路由器:链接不同网段的网络,使不同网段的设备可以通讯
mac地址在通信传输中,是动态的,在两个设备之间会发生变话
IP地址在通信传输中,是静态的,在整个传输中不会发生变化