【文章翻译+笔记】Towards the Next Generation of Recommender Systems:A Survey of the State-of-the-Art and Pos
Towards the Next Generation of Recommender Systems:A Survey of the State-of-the-Art and Possible Extensions
下一代推荐系统: 最新技术和可能扩展的综述
作者:Gediminas Adomavicius and Alexander Tuzhilin
【渣渣晴手翻,只可意会】
Abstract –The paper presents an overview of the field of recommender systems and describes the current generation of recommendation methods that are usually classified into the following three main categories: content-based, collaborative, and hybrid recommendation approaches. The paper also describes various limitations of current recommendation methods and discusses possible extensions that can improve recommendation capabilities and make recommender systems applicable to an even broader range of applications. These extensions include, among others, improvement of understanding of users and items, incorporation of the contextual information into the recommendation process, support for multi-criteria ratings, and provision of more flexible and less intrusive types of recommendations.
Index Terms–Recommender systems, collaborative filtering, rating estimation methods, extensions to
recommender systems.
摘要:这篇文章主要介绍了一下推荐系统领域的概况,描述了当前推荐系统的方法经常被分为三类:基于内容的content-based,协同collaborative,和混合hybrid推荐系统。这篇文章也描述了当前推荐系统的各种限制,讨论了提升推荐能力、在更大范围商品推荐的扩展可能性。这些扩展包括:提升对用户和物品的理解能力、将上下文信息融入到推荐过程里面、支持多规则打分、提供更灵活少打扰的推荐。
索引-推荐系统、协同滤波、打分预测方法、推荐系统的扩展
1. Introduction 介绍
Recommender systems became an important research area since the appearance of the first papers on collaborative filtering since the mid-1990s [45, 86, 97]. There has been much work done both in the industry and academia on developing new approaches to recommender systems over the last decade. The interest in this area still remains high because it constitutes a problemrich research area and because of the abundance of practical applications that help users to deal with information overload and provide personalized recommendations, content and services to them. Examples of such applications include recommending books, CDs and other products at Amazon.com [61], movies by MovieLens [67], and news at VERSIFI Technologies (formerly AdaptiveInfo.com) [14]. Moreover, some of the vendors have incorporated recommendation capabilities into their commerce servers [78].
自从90年代中期,第一篇协同滤波的论文出现之后,推荐系统变成一个重要的研究领域。在过去的十年里,工业界和学术界都做了很多工作去提升推荐系统。大家对这个领域一直有很高的兴趣,因为它是一个很多问题的领域,并且因为大量的实际应用帮助用户解决了信息过载并提供了个性化内容和服务的推荐。比如 Amazon推荐书籍、CD和其他产品,MovieLens推荐电影,VERSIFI Technologies推荐新闻。此外,许多公司也把推荐系统融入了他们的商业服务里面。
However, despite all these advances, the current generation of recommender systems still requires further improvements to make recommendation methods more effective and applicable to an even broader range of real-life applications, including recommending vacations, certain types of financial services to investors, and products to purchase in a store made by a “smart”
shopping cart [106]. These improvements include better methods for representing user behavior and the information about the items to be recommended, more advanced recommendation modeling methods, incorporation of various contextual information into the recommendation process, utilization of multi-criteria ratings, development of less intrusive and more flexible recommendation methods that also rely on the measures that more effectively determine performance of recommender systems.
然而尽管有很多提升,当前推荐系统仍然有更多可以提升的空间,使得推荐系统更加有效,能够在更广泛的真实商品中进行推荐,包括度假推荐、给某些投资者推荐金融服务、用“智能购物车”在商店里面买东西。这些提升包括许多很棒的方法,比如使用用户行为、被推荐物品的信息、更先进的推荐模型、将上下文信息融入到推荐过程里面、利用多规则打分、提供更灵活少打扰的推荐,这些也依赖于更有效的推荐系统的确定性的测量。
In this paper, we describe various ways to extend capabilities of recommender systems. However, before doing this, we first present a comprehensive survey of the state-of-the-art in recommender systems in Section 2. Then we identify various limitations of the current generation of recommendation methods and discuss some initial approaches to extending their
capabilities in Section 3.
在本文中,我们描述了许多扩展推荐系统性能的不同方法。然而,在此之前,我们将在第2章先展示许多最新的推荐系统。然后我们将在第3章介绍当前不同推荐方法的限制并讨论初步的扩展方法。
2. The Survey of Recommender Systems 推荐系统综述
Although the roots of recommender systems can be traced back to the extensive work in the cognitive science [87], approximation theory [81], information retrieval [89], forecasting theories [6], and also have links to management science [71], and also to the consumer choice modeling in marketing [60], recommender systems emerged as an independent research area in the mid-1990’s when researchers started focusing on recommendation problems that explicitly rely on the ratings structure. In its most common formulation, the recommendation problem is reduced to the problem of estimating ratings for the items that have not been seen by a user. Intuitively, this estimation is usually based on the ratings given by this user to other items and on some other information that will be formally described below. Once we can estimate ratings for the yet unrated items, we can recommend to the user the item(s) with the highest estimated rating(s).
尽管推荐系统的根源可以被追溯到认知科学的大量工作中,近似理论、信息检索、预测理论,它和管理科学也有一些联系,和市场的消费者选择模型有关,推荐系统作为一个独立的研究领域是从90年代中期开始,当研究者开始关注依赖于评分结构的推荐系统问题。一般来说,推荐系统问题是从预测用户没见过的物品评分问题化简而来。直观地说,这个预测通常基于用户给其他物品的打分和一些其他可以被形式化描述的信息。一旦我们可以预测未打分的物品,我们可以推荐最高分的物品给 用户。
More formally, the recommendation problem can be formulated as follows. Let C be the set of all users and let S be the set of all possible items that can be recommended, such as books, movies, or restaurants. The space S of possible items can be very large, ranging in hundreds of thousands or even millions of items in some applications, such as recommending books or CDs. Similarly, the user space can also be very large – millions in some cases. Let u be a utility function that measures usefulness of item s to user c, i.e., u :C × S → R , where R is a totally ordered set (e.g., non-negative integers or real numbers within a certain range). Then for each user c∈C , we want to choose such item s′∈S that maximizes the user’s utility. More formally:
更正式地说,推荐问题可以被如下定义。令C为全体用户,S为所有可能被推荐的物品,比如书、电影、餐厅。物品S的空间可能非常大,在一些应用里面可能有成百上千或成千上万个,比如推荐书或CD。近似的,用户空间也可能非常大,比如千万级。令u为效用函数utility function,测量物品s对用户c的有用度,即u :C × S → R,R是所有的有序集合(如,某个区间的非负整数或实数)。对于每个用户c∈C ,我们想选一个物品s′∈S,使得用户的效用最大。公式如下:
![]() ......公式(1)
......公式(1)
In recommender systems the utility of an item is usually represented by a rating, which indicates how a particular user liked a particular item, e.g., John Doe gave the movie “Harry Potter” the rating of 7 (out of 10). However, as indicated earlier, in general utility can be an arbitrary function, including a profit function. Depending on the application, utility u can either be specified by the user, as is often done for the user-defined ratings, or is computed by the application, as can be the case for a profit-based utility function.
在推荐系统里,一个物品的效用通常用评分代表,表示了某个用户有有多喜欢某个物品,如John Doe给电影Harry Potter打了7分(10分制)。然而,在早期,一般效用函数可以是一个随机函数,包括利润函数。基于应用,效用函数可以随用户使用改变,在用户打分或者应用计算后改变,也可以用基于利润的效用函数。
Each element of the user space C can be defined with a profile that includes various user characteristics, such as age, gender, income, marital status, etc. In the simplest case, the profile can contain only a single (unique) element, such as User ID. Similarly, each element of the item space S is defined with a set of characteristics. For example, in a movie recommendation application, where S is a collection of movies, each movie can be represented not only by its ID, but also by its title, genre, director, year of release, leading actors, etc.
用户空间C中的每个元素,可以由用户的画像定义,包括不同特征,如年龄、性别、收入、婚姻状况等。举个简单的例子,画像可以包括单一元素,比如用户ID。相似的,物品空间S的每个元素,可以被一系列特征定义。举个例子,如电影推荐系统,S是收集到的电影,每个电影不仅可以被其ID表示,还可以用名字、类型、导演、发布时间、领衔主演等。
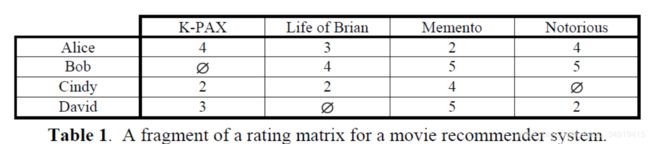
The central problem of recommender systems lies in that utility u is usually not defined on the whole C× S space, but only on some subset of it. This means u needs to be extrapolated to the whole space C× S . In recommender systems, utility is typically represented by ratings and is initially defined only on the items previously rated by the users. For example, in a movie recommendation application (such as the one at MovieLens.org), users initially rate some subset of movies that they have already seen. An example of a user-item rating matrix for a movie recommendation application is presented in Table 1, where ratings are specified on the scale of 1 to 5. The “∅” symbol for some of the ratings in Table 1 means that the users have not rated the corresponding movies. Therefore, the recommendation engine should be able to estimate (predict) the ratings of the non-rated movie/user combinations and issue appropriate recommendations based on these predictions.
推荐系统的主要问题是,效用u不是由C× S空间定义的,而只是由它的子集。这就意味着,u要从C× S空间里被推断出来。在推荐系统里面,评分代表效用,最开始的时候用户之前打过分的物品定义。例如,在电影推荐应用里,用户最初给子集看过的一些电影子集打过分。举个例子,一个电影推荐应用的用户-物品打分矩阵如表1,打分区间1-5。表1中的∅表示用户没给相关电影打过分。因此,推荐系统引擎需要能够预测∅位置的分数(ps:原文说的很麻烦……),根据这些预测给出正确建议。
Extrapolations from known to unknown ratings are usually done by (a) specifying heuristics that define the utility function and empirically validating its performance, and (b) estimating the utility function that optimizes certain performance criterion, such as the mean square error.
从已知评分到未知评分的预测通常是通过(a)指定启发式方法来定义效用函数,并通过经验验证其性能;(b)估计效用函数来优化某些性能标准,例如均方误差。
Once the unknown ratings are estimated, actual recommendations of an item to a user are made by selecting the highest rating among all the estimated ratings for that user, according to formula (1). Alternatively, we can recommend N best items to a user or a set of users to an item.
一旦不知道的打分被预测了,真正的推荐系统(一个物品推荐给一个用户)会选择预测打分中的最高者推荐给用户,使用公式(1)。或者,我们可以推荐N个最好的物品给用户,或者给许多用户推荐一个物品。
The new ratings of the not-yet-rated items can be estimated in many different ways using the methods from machine learning, approximation theory and various heuristics. Recommender systems are usually classified according to their approach to rating estimation, and in the next section, we will present such a classification that was proposed in the literature and will provide a survey of different types of recommender systems. The commonly accepted formulation of the recommendation problem was first stated in [45, 86, 97] and this problem has been studied extensively since then. Moreover, recommender systems are usually classified into the following categories, based on how recommendations are made [8]:
• Content-based recommendations: the user is recommended items similar to the ones the user preferred in the past;
• Collaborative recommendations: the user is recommended items that people with similar tastes and preferences liked in the past;
• Hybrid approaches: these methods combine collaborative and content-based methods.
给没分的打分,可以使用很多种不同的方法预测,比如机器学习、近似理论和不同的启发式方法。推荐系统通常根据它们的评分预测方法分类,在下一章,我们要展示一个在文献中提到的、用于不同推荐系统的分类。推荐系统问题普遍接收的提法首先提于文献【45,86,97】,这个问题被广泛研究至今。此外,推荐系统普遍被分为以下几类,基于推荐系统如何工作分的:
- 基于内容的推荐系统:给用户推荐的物品是和他之前喜欢的物品相似的
- 协同过滤推荐系统(CF):给用户推荐的物品是和他喜好相似的人群喜欢的物品。
- 混合方法:包括CF和基于内容的方法
In addition to recommender systems that predict the absolute values of ratings that individual users would give to the yet unseen items (as discussed above), there has been work done on preference-based filtering, i.e., predicting the relative preferences of users [22, 35, 51, 52]. For example, in a movie recommendation application preference-based filtering techniques would focus on predicting the correct relative order of the movies, rather than their individual ratings. However, this paper focuses primarily on the rating-based recommenders, since it constitutes the most popular approach to recommender systems.
推荐系统除了给用户没见过的物品预测打分外,还能做基于爱好的过滤,即预测用户相关爱好。举个例子,一个电影推荐应用是基于爱好过滤技术的,将会注重预测相关电影,而不是个人评分。然而,虽然它组成了大多数流行的推荐系统,但是本文注主要重于基于分数的推荐。
2.1 Content-based Methods 基于内容的方法
In content-based recommendation methods, the utility u(c, s) of item s for user c is estimated based on the utilities u(c ,![]() ) assigned by user c to items
) assigned by user c to items ![]() ∈S that are “similar” to item s. For example, in a movie recommendation application, in order to recommend movies to user c, the content-based recommender system tries to understand the commonalities among the movies user c has rated highly in the past (specific actors, directors, genres, subject matter, etc.). Then, only the movies that have a high degree of similarity to whatever user’s preferences are would get recommended.
∈S that are “similar” to item s. For example, in a movie recommendation application, in order to recommend movies to user c, the content-based recommender system tries to understand the commonalities among the movies user c has rated highly in the past (specific actors, directors, genres, subject matter, etc.). Then, only the movies that have a high degree of similarity to whatever user’s preferences are would get recommended.
基于内容的推荐系统方法,用户c对物品s的效用u(c, s)是基于效用u(c ,![]() ) ,也就是用户c对
) ,也就是用户c对![]() 的效用,其中
的效用,其中![]() 属于S且与s相似。举个例子,在一个电影推荐应用里,为了给用户c推荐电影,基于内容的推荐系统要尝试去理解用户c过去打高分的电影的共性(如演员、导演、类型、主要事件等等)。然后,只有和用户喜好高度相似的电影才会被推荐。
属于S且与s相似。举个例子,在一个电影推荐应用里,为了给用户c推荐电影,基于内容的推荐系统要尝试去理解用户c过去打高分的电影的共性(如演员、导演、类型、主要事件等等)。然后,只有和用户喜好高度相似的电影才会被推荐。
The content-based approach to recommendation has its roots in information retrieval [7, 89] and information filtering [10] research. Because of the significant and early advancements made by the information retrieval and filtering communities and because of the importance of several text-based applications, many current content-based systems focus on recommending
items containing textual information, such as documents, Web sites (URLs), and Usenet news messages. The improvement over the traditional information retrieval approaches comes from the use of user profiles that contain information about users’ tastes, preferences, and needs. The profiling information can be elicited from users explicitly, e.g., through questionnaires, or
implicitly – learned from their transactional behavior over time.
基于内容的推荐,其根本是信息检索和信息过滤的研究。因为早期重要的进步是使用信息检索和过滤的,并且因为一些基于文本应用的重要性,近期许多基于内容的系统都注重使用文本信息推荐物品,比如文档,网站(URL),新闻组的新闻信息。传统信息检索的提升来自于用户画像,包括用户的品味、爱好、需求信息。画像信息可以明确地描述用户,比如通过问卷,或者从一些从之前交易行为学到的隐藏信息。
More formally, let Content(s) be an item profile, i.e., a set of attributes characterizing item s. It is usually computed by extracting a set of features from item s (its content) and is used to determine appropriateness of the item for recommendation purposes. Since, as mentioned earlier, content-based systems are designed mostly to recommend text-based items, the content in
these systems is usually described with keywords. For example, a content-based component of the Fab system [8], which recommends Web pages to users, represents Web page content with the 100 most important words. Similarly, the Syskill & Webert system [77] represents documents with the 128 most informative words. The “importance” (or “informativeness”) of
word ![]() in document
in document ![]() is determined with some weighting measure
is determined with some weighting measure ![]() that can be defined in several different ways.
that can be defined in several different ways.
更一般的来说,令Content(s)为一个物品的画像,即物品s的一些属性特征。通常由物品s的一些特征(内容)提取计算画像,并且画像用来决定推荐适当的物品。因此,像之前提到的那样,基于内容的系统通常用来推荐基于文本的物品,这些内容通常用一些关键词存在系统里。举个例子,外事局的系统由一个基于内容的部分组成,它会给用户推荐网页,是基于网页内容中100个最重要的单词推荐的。相似的,Syskill & Webert系统使用文章里128个提供最多信息的词语。最单词 ![]() 在文章
在文章 ![]() 里的“重要性”(“信息量”),是由一些用不同方法定义的权重测量
里的“重要性”(“信息量”),是由一些用不同方法定义的权重测量![]() 所决定的。
所决定的。
One of the best-known measures for specifying keyword weights in Information Retrieval is the term frequency/inverse document frequency (TF-IDF) measure [89] that is defined as follows. Assume that N is the total number of documents that can be recommended to users and that keyword ![]() appears in
appears in ![]() of them. Moreover, assume that
of them. Moreover, assume that ![]() is the number of times keyword
is the number of times keyword ![]() appears in document
appears in document ![]() . Then
. Then ![]() , the term frequency (or normalized frequency) of keyword
, the term frequency (or normalized frequency) of keyword ![]() in document
in document ![]() , is defined as
, is defined as
其中,信息检索中确定关键词的权重的最有名的一个测量方法,是TF-IDF(词频/逆文本频率),下面介绍一下它的定义。假设N是所有可以被推荐给用户的文本的总数,并且关键词 ![]() 出现在N中的
出现在N中的![]() 文章中。设
文章中。设![]() 为关键词
为关键词![]() 出现在文章
出现在文章![]() 的次数。因此
的次数。因此![]() 是关键词
是关键词![]() 出现在文章
出现在文章![]() 的词频,定义如下:
的词频,定义如下:
![]() ......公式(2)
......公式(2)
where the maximum is computed over the frequencies ![]() of all keywords
of all keywords ![]() that appear in the document
that appear in the document ![]() . However, keywords that appear in many documents are not useful in distinguishing between a relevant document and a non-relevant one. Therefore, the measure of inverse document frequency (
. However, keywords that appear in many documents are not useful in distinguishing between a relevant document and a non-relevant one. Therefore, the measure of inverse document frequency (![]() ) is often used in combination with simple term frequency (
) is often used in combination with simple term frequency ( ![]() ). The inverse document frequency for keyword
). The inverse document frequency for keyword ![]() is usually defined as
is usually defined as
其中最大值max(ps:就是分母),是所有关键词![]() 出现在文章
出现在文章![]() 的频率
的频率![]() 计算而来的。然而,有些关键词可能出现在很多文章里面,对区分相关和不相关没有什么用途。因此,通常计算逆文本频率
计算而来的。然而,有些关键词可能出现在很多文章里面,对区分相关和不相关没有什么用途。因此,通常计算逆文本频率![]() ,结合词频
,结合词频![]() 。关键词
。关键词![]() 的
的![]() 定义为:
定义为:
![]() ......公式(3)
......公式(3)
Then the TF-IDF weight for keyword ki in document dj is defined as
因此关键词![]() 在文章
在文章![]() 的TF-IDF权重定义为:
的TF-IDF权重定义为:
![]() ......公式(4)
......公式(4)
and the content of document ![]() is defined as:
is defined as:![]()
文章![]() 的内容被定义为:
的内容被定义为:![]()
As stated earlier, content-based systems recommend items similar to those that a user liked in the past [56, 69, 77]. In particular, various candidate items are compared with items previously rated by the user, and the best-matching item(s) are recommended. More formally, let ContentBasedProfile(c) be the profile of user c containing tastes and preferences of this user. These profiles are obtained by analyzing the content of the items previously seen and rated by the user and are usually constructed using keyword analysis techniques from information retrieval. For example, ContentBasedProfile(c) can be defined as a vector of weights ![]() , where each weight
, where each weight ![]() denotes the importance of keyword
denotes the importance of keyword ![]() to user c and can be computed from individually rated content vectors using a variety of techniques. For example, some averaging approach, such as Rocchio algorithm [85], can be used to compute ContentBasedProfile(c) as an “average” vector from an individual content vectors [8, 56]. On the other hand, [77] use a Bayesian classifier in order to estimate the probability that a document is liked. The Winnow algorithm [62] has also been shown to work well for this purpose, especially in the situations where there are many possible features [76].
to user c and can be computed from individually rated content vectors using a variety of techniques. For example, some averaging approach, such as Rocchio algorithm [85], can be used to compute ContentBasedProfile(c) as an “average” vector from an individual content vectors [8, 56]. On the other hand, [77] use a Bayesian classifier in order to estimate the probability that a document is liked. The Winnow algorithm [62] has also been shown to work well for this purpose, especially in the situations where there are many possible features [76].
在初期,基于内容的系统推荐物品时总是和用户过去喜欢的东西近似。特别是,不同候选物品和用户之前打过分的物品比较,最佳匹配的物品会被推荐的这种情况。更正式的来说,令ContentBasedProfile(c)为用户c的画像,包括该用户的品味和喜好。这些画像是通过分析用户先前看到和评价的项目的内容获得的,通常使用信息检索中的关键字分析技术得到。举个例子,ContentBasedProfile(c)可以被定义为一个权重的向量![]() ,其中每个权重
,其中每个权重![]() 表示为关键词
表示为关键词![]() 对于用户c的重要性,并且可以使用各种技术,通过计算个人打分内容向量得到。举个例子,一些平均的方法,比如Rocchio算法。另一方面,可以用一个贝叶斯分类器 Bayesian classifier 来预测文章被喜欢的可能性。Winnow算法也被证明可以很好的达到目的,特别是可能存在很多特征的情况。
对于用户c的重要性,并且可以使用各种技术,通过计算个人打分内容向量得到。举个例子,一些平均的方法,比如Rocchio算法。另一方面,可以用一个贝叶斯分类器 Bayesian classifier 来预测文章被喜欢的可能性。Winnow算法也被证明可以很好的达到目的,特别是可能存在很多特征的情况。
In content-based systems, the utility function u(c, s) is usually defined as:
在基于内容的系统,效用函数u(c, s)被定义为:
![]() .....公式(5)
.....公式(5)
Using the above-mentioned information retrieval-based paradigm of recommending Web pages, Web site URLs, or Usenet news messages, both ContentBasedProfile(c) of user c and Content(s) of document s can be represented as TF-IDF vectors ![]() and
and ![]() of keyword weights. Moreover, utility function u(c, s) is usually represented in information retrieval literature by some scoring heuristic defined in terms of vectors
of keyword weights. Moreover, utility function u(c, s) is usually represented in information retrieval literature by some scoring heuristic defined in terms of vectors ![]() and
and ![]() , such as cosine similarity measure [7, 89]:
, such as cosine similarity measure [7, 89]:
使用上述基于信息检索范式去推荐网页、网站URLs或者新闻组的新闻信息,用户c的ContentBasedProfile(c) 和文章的Content(s) 可以被TF-IDF向量![]() 和关键词的权重
和关键词的权重![]() 表示。此外,在信息检索中,效用函数u(c, s)通常被表示为一些被
表示。此外,在信息检索中,效用函数u(c, s)通常被表示为一些被![]() 和
和![]() 定义的启发式的评分,比如余弦相似测量方法:
定义的启发式的评分,比如余弦相似测量方法:
......公式(6)
where K is the total number of keywords in the system.
其中K为系统中关键词的总数。
(启发式算法(heuristic algorithm)是相对于最优化算法提出的。一个问题的最优算法求得该问题每个实例的最优解。启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。现阶段,启发式算法以仿自然体算法为主,主要有蚁群算法、模拟退火法、神经网络等。)
For example, if user c reads many online articles on the topic of bioinformatics, then content-based recommendation techniques will be able to recommend other bioinformatics articles to user c. This is the case, because these articles will have more bioinformatics-related terms (e.g., “genome”, “sequencing”, “proteomics”) than articles on other topics, and, therefore,
ContentBasedProfile(c), as defined by vector ![]() , will represent such terms ki with high weights
, will represent such terms ki with high weights 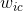 . Consequently, a recommender system using the cosine or a related similarity measure will assign higher utility u(c, s) to those articles s that have high-weighted bioinformatics terms in
. Consequently, a recommender system using the cosine or a related similarity measure will assign higher utility u(c, s) to those articles s that have high-weighted bioinformatics terms in ![]() and lower utility to the ones where bioinformatics terms are weighted less.
and lower utility to the ones where bioinformatics terms are weighted less.
举个例子,如果用户c在网上读了很多生物学的文章,那么基于内容的推荐系统技术将能够给用户c推荐其他的生物文章。在这个例子中,因为这些文章中生物学的词汇(比如“基因组”、“排序”、“蛋白质组学”)比别的文章多,因此被![]() 定义的ContentBasedProfile(c) 将代表一个有着高权重的词
定义的ContentBasedProfile(c) 将代表一个有着高权重的词![]() 。因此,一个推荐系统使用余弦或者一个相关的相似测量方法时,将对
。因此,一个推荐系统使用余弦或者一个相关的相似测量方法时,将对![]() 中生物词汇高权重的这些文章s有一个很高的效用u(c, s),生物词汇权重低的文章有很低的效用。
中生物词汇高权重的这些文章s有一个很高的效用u(c, s),生物词汇权重低的文章有很低的效用。
Besides the traditional heuristics that are based mostly on information retrieval methods, other techniques for content-based recommendation have also been used, such as Bayesian classifiers [70, 77] and various machine learning techniques, including clustering, decision trees, and artificial neural networks [77]. These techniques differ from information retrieval-based
approaches in that they calculate utility predictions based not on a heuristic formula, such as a cosine similarity measure, but rather are based on a model learned from the underlying data using statistical learning and machine learning techniques. For example, based on a set of Web pages that were rated as “relevant” or “irrelevant” by the user, [77] use the naïve Bayesian classifier [31] to classify unrated Web pages. More specifically, the naïve Bayesian classifier is used to estimate the following probability that page ![]() belongs to a certain class
belongs to a certain class ![]() (e.g., relevant or irrelevant) given the set of keywords
(e.g., relevant or irrelevant) given the set of keywords 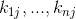 on that page:
on that page:
除了传统的基于信息检索的启发式方法,其他技术也被用于基于内容的推荐系统,比如贝叶斯分类器和其他机器学习的技术,包括聚类,决策树,人工神经网络。这些技术和基于信息检索的方式不同,他们不适用启发式的公式计算效用的预测,如余弦相似测试方法,而是以从基础数据,使用统计学习和机器学习技术学出的模型为基础。举个例子,一些网页对于一个用户来说,可以分为“相关的”和“不相关的”,使用朴素贝叶斯分类器去区分哪些没有被划分的网页。更具体地说,朴素贝叶斯分类器可以用来预测:在给出网页上关键词的条件下,网页![]() 是否属于某个类
是否属于某个类![]() (比如:相关或不相关)。公式如下:
(比如:相关或不相关)。公式如下:
![]() ......公式(7)
......公式(7)
Moreover, [77] use the assumption that keywords are independent and, therefore, the above probability is proportional to
此外,假设所有的关键词都是相互独立的,因此,上述的概率(ps:由贝叶斯定理,公式7=公式8/p(k),p(k)为各个关键词在网页j中出现的概率的乘积,是固定的)正比于:
![]() ......公式(8)
......公式(8)
While the keyword independence assumption does not necessarily apply in many applications, experimental results demonstrate that naïve Bayesian classifiers still produce high classification accuracy [77]. Furthermore, both ![]() and
and ![]() can be estimated from the underlying training data. Therefore, for each page
can be estimated from the underlying training data. Therefore, for each page ![]() , the probability
, the probability ![]() is computed for each class
is computed for each class ![]() , and page
, and page ![]() is assigned to class
is assigned to class ![]() having the highest probability [77].
having the highest probability [77].
虽然在许多应用里,关键词独立的假设不一定适用,但是实验结果表明,贝叶斯分类器仍然有很高的准确率。因此,![]() 和
和![]() 可以从基础训练数据预测到。因此,对于每个网页
可以从基础训练数据预测到。因此,对于每个网页![]() ,
,![]() 可以由类别
可以由类别![]() 和网页
和网页![]() 最可能属于类别
最可能属于类别![]() 计算得到。
计算得到。
While not explicitly dealing with providing recommendations, the text retrieval community has contributed several techniques that are being used in content-based recommender systems. One example of such technique would be the research on adaptive filtering [101, 112], which focuses on becoming more accurate at identifying relevant documents incrementally, by observing the documents one-by-one in a continuous document stream. Another example would be the work on threshold setting [84, 111], which focuses on determining the extent to which documents should match a given query in order to be relevant to the user. Other text retrieval methods are described in [50] and can also be found in the proceedings of the Text Retrieval Conference (TREC) (http://trec.nist.gov).
虽然没有明确的解决推荐系统的问题,文本检索已经有许多技术被用于基于内容的推荐系统。一个例子就是自适应滤波的技术,它注重于在识别相关递增文档的时候更加准确,通过一个连续的文档流,一个一个观察文档。另一个例子就是阈值设置,它侧重于确定文档与给定查询匹配的程度,以便与用户相关。其他文本检索的方法在TREC中可以找到。
As was observed in [8, 97], content-based recommender systems have several limitations that are described in the rest of this section.
本章节的后面介绍一下基于内容的推荐系统的一些限制。
Limited content analysis. Content-based techniques are limited by the features that are explicitly associated with the objects that these systems recommend. Therefore, in order to have a sufficient set of features, the content must either be in a form that can be parsed automatically by a computer (e.g., text), or the features should be assigned to items manually. While information retrieval techniques work well in extracting features from text documents, some other domains have an inherent problem with automatic feature extraction. For example, automatic feature extraction methods are much harder to apply to the multimedia data, e.g.,graphical images, audio and video streams. Moreover, it is often not practical to assign attributes by hand due to limitations of resources [97].
有限制的内容分析。基于内容的技术经常被系统物品的显示关联的特征所限制。因此,为了有充分多的特征,内容必须使用一个计算机可以自动分析的格式(如:文本),或者特征被人工分配。信息检索技术在文本抽取特征表现不错,其他领域在自动特征提取方面是一个固有的问题。举个例子,自动特征提取方法对于多媒体数据来说非常困难,比如图形图像、音频、视频流。此外,由于资源的限制,手工分配属性往往是不现实的。
Another problem with limited content analysis is that, if two different items are represented by the same set of features, they are indistinguishable. Therefore, since text-based documents are usually represented by their most important keywords, content-based systems cannot distinguish between a well-written article and a badly written one, if they happen to use the same terms [97].
另一个限制内容分析的问题就是,如果两个不一样的物品有着相同的特征,他们是不能被区别开的。因此,因为都是用关键词来表示文本的,如果他们都用一样的词,基于内容的系统不能区别谁好谁坏。
Over-specialization. When the system can only recommend items that score highly against a user’s profile, the user is limited to being recommended items similar to those already rated. For example, a person with no experience with Greek cuisine would never receive a recommendation for even the greatest Greek restaurant in town. This problem, which has also been studied in other domains, is often addressed by introducing some randomness. For example, the use of genetic algorithms has been proposed as a possible solution in the context of information filtering [98]. In addition, the problem with over-specialization is not only that the content-based systems cannot recommend items that are different from anything the user has seen before. In certain cases, items should not be recommended if they are too similar to something the user has already seen, such as different news article describing the same event. Therefore, some contentbased recommender systems, such as DailyLearner [13], filter out items not only if they are too different from user’s preferences, but also if they are too similar to something the user has seen before. Furthermore, [112] provide a set of five redundancy measures to evaluate whether a document that is deemed to be relevant contains some novel information as well. In summary, the diversity of recommendations is often a desirable feature in recommender systems. Ideally, the user should be presented with a range of options and not with a homogeneous set of alternatives. For example, it is not necessarily a good idea to recommend all movies by Woody Allen to a user who liked one of them.
过度特殊化。当系统根据通过用户画像来推荐高分系统的时候,用户只能被推荐和他们打过分的相似物品。举个例子,一个人没尝过希腊菜,所以永远都不会给他推荐希腊菜餐馆,即使这是全镇最好的希腊菜餐馆。这个问题,也被其他领域研究过,解决办法就是随机介绍一些别的东西。比如,在信息过滤的环境下,用遗传算法是一个可能的方法。另外,过度特殊化的问题不仅仅是基于内容的系统不能推荐用户之前没见过的东西。在某些情况下,与用户见过的物品不应该被推荐,比如一样的文章不同的标题。因此,一些基于内容的推荐系统,比如DailyLearner,过滤物品不仅仅依靠他们和用户的喜好不同,还有和之前看过的东西是否过度相似。此外,提供五个冗余措施去评估是否一个被认为相关的文章也包含一些新的信息。总的来说,推荐系统的多样性一般是一个好的推荐系统。理想上地,用户应该有许多选项,而不是同类的替代物。举个例子,把Woody Allen的所有电源推荐给一个喜欢其中一部片子的用户,这可不是一个太好的建议。
New user problem. The user has to rate a sufficient number of items before a content-based recommender system can really understand user’s preferences and present the user with reliable recommendations. Therefore, a new user, having very few ratings, would not be able to get accurate recommendations.
新用户问题。(ps:冷启动问题)用户只有给许多物品打分之后,基于内容的推荐系统才能够理解用户的喜好,并且展现给用户可靠的推荐。因此,如果是一个新的用户,只有非常少的打分,是不能给到准确的推荐的。
2.2 Collaborative Methods
Unlike content-based recommendation methods, collaborative recommender systems (or collaborative filtering systems) try to predict the utility of items for a particular user based on the items previously rated by other users. More formally, the utility u(c, s) of item s for user c is estimated based on the utilities 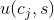 assigned to item s by those users
assigned to item s by those users ![]() who are “similar” to user c. For example, in a movie recommendation application, in order to recommend movies to user c, the collaborative recommender system tries to find the “peers” of user c, i.e., other users that have similar tastes in movies (rate the same movies similarly). Then, only the movies that are most liked by the “peers” of user c would get recommended.
who are “similar” to user c. For example, in a movie recommendation application, in order to recommend movies to user c, the collaborative recommender system tries to find the “peers” of user c, i.e., other users that have similar tastes in movies (rate the same movies similarly). Then, only the movies that are most liked by the “peers” of user c would get recommended.
不想基于内容的推荐方法那样,协同过滤的推荐系统是预测一个特定用户对物品的效用,基于别人对该物品的打分结果。更正式的说,用户c对物品s的效用u(c,s),是基于效用,也就是用户![]() 对物品s的效用,用户cj是和用户c相似的人。举个例子,在电影推荐系统里面,为了给用户c推荐电影,协同过滤推荐系统要寻找用户c的“伙伴”,即其他有着相似品味的用户(打分相近)。然后,只有“伙伴”都喜欢的电影,才能推荐给用户c。
对物品s的效用,用户cj是和用户c相似的人。举个例子,在电影推荐系统里面,为了给用户c推荐电影,协同过滤推荐系统要寻找用户c的“伙伴”,即其他有着相似品味的用户(打分相近)。然后,只有“伙伴”都喜欢的电影,才能推荐给用户c。
There have been many collaborative systems developed in the academia and the industry. It can be argued that the Grundy system [87] was the first recommender system, which proposed to use stereotypes as a mechanism for building models of users based on a limited amount of information on each individual user. Using stereotypes, the Grundy system would build individual user models and use them to recommend relevant books to each user. Later on, the Tapestry system relied on each user to identify like-minded users manually [38]. GroupLens [53, 86], Video Recommender [45], and Ringo [97] were the first systems to use collaborative filtering algorithms to automate prediction. Other examples of collaborative recommender
systems include the book recommendation system from Amazon.com, the PHOAKS system that helps people find relevant information on the WWW [103], and the Jester system that recommends jokes [39].
在学术界和工业界,已经有很多协同滤波的推荐系统。可以说Grundy系统是第一个推荐系统,它建议采用模式化的方法作为搭建每个用户信息有限的用户模型的机制。使用模式化,Grundy系统建立了每个用户的模型,用其给他们推荐相关书籍。之后,Tapestry系统,依赖各个用户人工的标记喜好相同的人。GroupLens [53, 86], Video Recommender [45], and Ringo [97],是第一个使用协同滤波算法去自动预测的系统。其他协同滤波推荐系统的例子,包括Amazon的图书推荐系统,PHOAKS帮助人们在万维网上查找相关信息,Jester系统用来推荐笑话。
According to [15], algorithms for collaborative recommendations can be grouped into two general classes: memory-based (or heuristic-based) and model-based.
根据文献15,协同滤波的算法通常可以被分为两类:基于记忆的(基于启发的),基于模型的。
Memory-based algorithms [15, 27, 72, 86, 97] essentially are heuristics that make rating predictions based on the entire collection of previously rated items by the users. That is, the value of the unknown rating ![]() for user c and item s is usually computed as an aggregate of the ratings of some other (usually the N most similar) users for the same item s:
for user c and item s is usually computed as an aggregate of the ratings of some other (usually the N most similar) users for the same item s:
基于记忆的算法本质上来说是启发式的,他们预测打分是基于收集到的所有用户之前的打分物品。用户c对物品s的位置打分![]() 通常是由(通常是N个最相似的)其他用户给物品s的打分的聚合计算的:
通常是由(通常是N个最相似的)其他用户给物品s的打分的聚合计算的:
![]() ........公式(9)
........公式(9)
where ![]() denotes the set of N users that are the most similar to user c and who have rated item s (N can range anywhere from 1 to the number of all users). Some examples of the aggregation function are:
denotes the set of N users that are the most similar to user c and who have rated item s (N can range anywhere from 1 to the number of all users). Some examples of the aggregation function are:
其中![]() 是与用户c的N个最相似的给物品s打过分的用户的集合(N可以从1~所有用户),一些聚合函数的举例:
是与用户c的N个最相似的给物品s打过分的用户的集合(N可以从1~所有用户),一些聚合函数的举例:
..........公式(10)
where multiplier k serves as a normalizing factor and is usually selected as ![]() , and where the average rating of user c,
, and where the average rating of user c, ![]() , in (10c) is defined as
, in (10c) is defined as
其中乘数k是归一化的因子,通常为![]() 。公式10(c)里面的c用户的平均打分
。公式10(c)里面的c用户的平均打分![]() ,定义为:
,定义为:
![]() ......公式(11)
......公式(11) ![]() 必须由打过分的物品计算!
必须由打过分的物品计算!
In the simplest case, the aggregation can be a simple average, as defined by expression (10a). However, the most common aggregation approach is to use the weighted sum, shown in (10b). The similarity measure between the users c and c’, sim(c, c’), is essentially a distance measure and is used as a weight, i.e., the more similar users c and c’ are, the more weight rating ![]() will carry in the prediction of
will carry in the prediction of ![]() . Note that sim(x,y) is a heuristic artifact that is introduced in order to be able to differentiate between levels of user similarity (i.e., to be able to find a set of “closest peers” or “nearest neighbors” for each user) and at the same time simplify the rating estimation procedure. As shown in (10b), different recommendation applications can use their own user similarity measure, as long as the calculations are normalized using the normalizing factor k, as shown above. The two most commonly used similarity measures will be described below. One problem with using the weighted sum, as in (10b), is that it does not take into account the fact that different users may use the rating scale differently. The adjusted weighted sum, shown in (10c), has been widely used to address this limitation. In this approach, instead of using the absolute values of ratings, the weighted sum uses their deviations from the average rating of the corresponding user. Another way to overcome the differing uses of the rating scale is to deploy preference-based filtering [22, 35, 51, 52], which focuses on predicting the relative preferences of users instead of absolute rating values, as was pointed out earlier in Section 2.
. Note that sim(x,y) is a heuristic artifact that is introduced in order to be able to differentiate between levels of user similarity (i.e., to be able to find a set of “closest peers” or “nearest neighbors” for each user) and at the same time simplify the rating estimation procedure. As shown in (10b), different recommendation applications can use their own user similarity measure, as long as the calculations are normalized using the normalizing factor k, as shown above. The two most commonly used similarity measures will be described below. One problem with using the weighted sum, as in (10b), is that it does not take into account the fact that different users may use the rating scale differently. The adjusted weighted sum, shown in (10c), has been widely used to address this limitation. In this approach, instead of using the absolute values of ratings, the weighted sum uses their deviations from the average rating of the corresponding user. Another way to overcome the differing uses of the rating scale is to deploy preference-based filtering [22, 35, 51, 52], which focuses on predicting the relative preferences of users instead of absolute rating values, as was pointed out earlier in Section 2.
在简单的例子里,聚类可以使简单的平均,就像公式10(a)里面那样。然而,最常用的聚类经常用权重求和,就像公式10(b)那样。用户c和c'的相似度计算sim(c,c'),本质上是距离,被用做了权重。即,最相似的用户c和c’,在计算![]() 的时候有最大的权重
的时候有最大的权重![]() 。注意,sim(x,y)是一个启发式的人为制定的公式,为了区别用户相似的不同等级(即,为用户找到“最近的伙伴”,或者“最近的邻居”),同时简化评分预测的过程。像公式10(b)中,不同的推荐应用可以有自己的相似测量,只要用归一化因子k去归一计算结果。下面说两个最常用的相似测量。一个问题是使用权重求和,像公式10(b)那样,他没有考虑到用户打分的时候标准不统一。调整加权求和,像公式10(c)那样,是广泛用于解决这个问题的。为了达到目的,不适用打分的绝对值,加权求和的时候用的用户打分平均值的偏差。克服打分标准不同的另一种方法是做一个基于爱好的滤波,主要注重于预测相关爱好,而不是打分的绝对值,这第2章前面说过。
。注意,sim(x,y)是一个启发式的人为制定的公式,为了区别用户相似的不同等级(即,为用户找到“最近的伙伴”,或者“最近的邻居”),同时简化评分预测的过程。像公式10(b)中,不同的推荐应用可以有自己的相似测量,只要用归一化因子k去归一计算结果。下面说两个最常用的相似测量。一个问题是使用权重求和,像公式10(b)那样,他没有考虑到用户打分的时候标准不统一。调整加权求和,像公式10(c)那样,是广泛用于解决这个问题的。为了达到目的,不适用打分的绝对值,加权求和的时候用的用户打分平均值的偏差。克服打分标准不同的另一种方法是做一个基于爱好的滤波,主要注重于预测相关爱好,而不是打分的绝对值,这第2章前面说过。
Various approaches have been used to compute the similarity sim(c,c′) between users in collaborative recommender systems. In most of these approaches, the similarity between two users is based on their ratings of items that both users have rated. The two most popular approaches are correlation- and cosine-based. To present them, let  be the set of all items corated by both users x and y, i.e.,
be the set of all items corated by both users x and y, i.e.,![]() . In collaborative recommender systems is used mainly as an intermediate result for calculating the “nearest neighbors” of user x and is often computed in a straightforward manner, i.e., by computing the intersection of sets
. In collaborative recommender systems is used mainly as an intermediate result for calculating the “nearest neighbors” of user x and is often computed in a straightforward manner, i.e., by computing the intersection of sets ![]() and
and ![]() . However, some methods, such as the graph-theoretic approach to collaborative filtering [4], can determine the nearest neighbors of x without computing for all users y. In the correlation-based approach, the Pearson correlation coefficient is used to measure the similarity [86, 97]:
. However, some methods, such as the graph-theoretic approach to collaborative filtering [4], can determine the nearest neighbors of x without computing for all users y. In the correlation-based approach, the Pearson correlation coefficient is used to measure the similarity [86, 97]:
在协同滤波推荐系统里,计算相似性sim(c,c′)有很多种方法。大多数的方法,就是基于双方都打过分的物品进行二者的相似度计算。最常用的两种方法是基于相关性或基于余弦。令为用户x和y都打分的物品的集合,即![]() 。在协同滤波推荐系统,主要用来计算x的“最近邻居”的中间结果,通常使用直接计算的方法得到,即算集合
。在协同滤波推荐系统,主要用来计算x的“最近邻居”的中间结果,通常使用直接计算的方法得到,即算集合![]() 和
和![]() 的交集。然而一些别的方法,比如协同过滤的图论方法,可以采用x的最近邻居,而不需要计算所有用户y的。在基于相关的方法,人和人的相关系数被相似度测量:
的交集。然而一些别的方法,比如协同过滤的图论方法,可以采用x的最近邻居,而不需要计算所有用户y的。在基于相关的方法,人和人的相关系数被相似度测量:
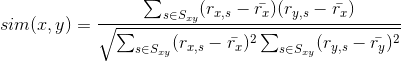 ......公式(12)
......公式(12)
In the cosine-based approach [15, 91], the two users x and y are treated as two vectors in m-dimensional space, where ![]() . Then, the similarity between two vectors can be measured by computing the cosine of the angle between them:
. Then, the similarity between two vectors can be measured by computing the cosine of the angle between them:
在基于余弦的方法里,两个用户x和y被当做两个m维的向量,![]() 。所以,两个向量之间的相似度可以用余弦计算:
。所以,两个向量之间的相似度可以用余弦计算:
where ![]() denotes the dot-product between the vectors
denotes the dot-product between the vectors ![]() and
and ![]() . Still another approach to measuring similarity between users uses the mean squared difference measure and is described in [97]. Note that different recommender systems may take different approaches in order to implement the user similarity calculations and rating estimations as efficiently as possible. One common strategy is to calculate all user similarities sim(x, y) (including the calculation of ) in advance and recalculate them only once in a while (since the network of peers usually does not change dramatically in a short time). Then, whenever the user asks for a recommendation, the ratings can be efficiently calculated on demand using pre-computed similarities.
. Still another approach to measuring similarity between users uses the mean squared difference measure and is described in [97]. Note that different recommender systems may take different approaches in order to implement the user similarity calculations and rating estimations as efficiently as possible. One common strategy is to calculate all user similarities sim(x, y) (including the calculation of ) in advance and recalculate them only once in a while (since the network of peers usually does not change dramatically in a short time). Then, whenever the user asks for a recommendation, the ratings can be efficiently calculated on demand using pre-computed similarities.
其中![]() 是向量
是向量![]() 和
和![]() 的点乘。计算用户相似度的另一种方法在文献97里面提到,使用平方根差计算。注意,不同的推荐系统可能使用不同的方法去计算用户相似度和尽可能有效的打分预测。一种常见的策略是提前计算所有用户的相似度sim(x, y)(包括计算),过了一段时间之后(因为网络同伴通常不会在短时间内改变很多)重新计算。然后,不论何时用户访问推荐系统,可以用预先计算的相似性根据需要有效地计算评级。
的点乘。计算用户相似度的另一种方法在文献97里面提到,使用平方根差计算。注意,不同的推荐系统可能使用不同的方法去计算用户相似度和尽可能有效的打分预测。一种常见的策略是提前计算所有用户的相似度sim(x, y)(包括计算),过了一段时间之后(因为网络同伴通常不会在短时间内改变很多)重新计算。然后,不论何时用户访问推荐系统,可以用预先计算的相似性根据需要有效地计算评级。
Note, that both the content-based and the collaborative approaches use the same cosine measure from information retrieval literature. However, in content-based recommender systems it is used to measure the similarity between vectors of TF-IDF weights, whereas in collaborative systems it measures the similarity between vectors of the actual user-specified ratings.
要注意,基于内容的和协同滤波都使用一样的信息检索文献的余弦测量方法。然而,基于内容的推荐系统,用TF-IDF权重的向量计算相似度,然而,协同滤波系统使用实际用户的打分来计算相似度。
Many performance-improving modifications, such as default voting, inverse user frequency, case amplification [15], and weighted-majority prediction [27, 72], have been proposed as extensions to these standard correlation-based and cosine-based techniques. For example, the default voting [15] is an extension to the memory-based approaches described above. It was observed that whenever there are relatively few user-specified ratings, these methods would not work well in computing similarity between users x and y since the similarity measure is based on the intersection of the itemsets, i.e., sets of items rated by both users x and y. It was empirically shown that the rating prediction accuracy could improve if we assume some default rating value for the missing ratings [15].
许多提升性能的修改,比如默认打分、用户频率的逆、事例引申,已经作为协同滤波和基于余弦技术的标准扩展。举个例子,默认打分是基于记忆方法的扩展。可以观察到,不论何时,用户打分的相关性是非常少的,这些方法在计算用户x和y的相似度的时候效果不是很好,因为相似度计算是基于物品交际的,即被用户x和y打分的物品的集合。实证结果表明,对于缺失的打分,如果我们可以设置默认打分,可以提高评级预测的精度。
Also, while the above techniques traditionally have been used to compute similarities between users, [91] proposed to use the same correlation-based and cosine-based techniques to compute similarities between items instead and obtain the ratings from them. This idea has been further extended in [29] for top-N item recommendations. In addition, [29, 91] present empirical
evidence that item-based algorithms can provide better computational performance than traditional user-based collaborative methods, while at the same time providing comparable or better quality than the best available user-based algorithms.
当上述传统技术被用于计算用户的相似度,用同样的基于协同滤波和基于余弦技术去计算物品的相似度并获得它们的打分。这个方法进一步扩展了top N的推荐系统。此外,目前实验表明,基于物品的算法比传统的基于用户的系统方法得到更好的计算结果,同时比现在基于用户的算法提供同等的或者更好的质量。
In contrast to memory-based methods, model-based algorithms [11, 15, 37, 39, 47, 64, 75, 105] use the collection of ratings to learn a model, which is then used to make rating predictions. For example, [15] proposes a probabilistic approach to collaborative filtering, where the unknown ratings are calculated as
对比基于记忆的方法,基于模型的方法就是用收集的打分训练一个模型,用来做打分预测的模型。举个例子,提出了一种基于概率的协同滤波的方法,其中计算打分的方法:
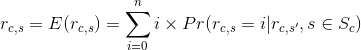 ......公式(14)
......公式(14)
and it is assumed that rating values are integers between 0 and n, and the probability expression is the probability that user c will give a particular rating to item s given that user’s ratings of the previously rated items. To estimate this probability, [15] proposes two alternative probabilistic models: cluster models and Bayesian networks. In the first model, like-minded users are
clustered into classes. Given the user’s class membership, the user ratings are assumed to be independent, i.e., the model structure is that of a naïve Bayesian model. The number of classes and the parameters of the model are learned from the data. The second model represents each item in the domain as a node in a Bayesian network, where the states of each node correspond to the possible rating values for each item. Both the structure of the network and the conditional probabilities are learned from the data. One limitation of this approach is that each user can be clustered into a single cluster, whereas some recommendation applications may benefit from the ability to cluster users into several categories at once. For example, in a book recommendation application, a user may be interested in one topic (e.g., programming) for work purposes and a completely different topic (e.g., fishing) for leisure.
假设打分可以使0~n,概率表达式为:在给定之前给物品打过分的情况下,用户c给物品s一个特定的打分。去预测可能性,有两个可选择的概率模型:聚类模型和贝叶斯网络。在第一个模型中,志趣相投的用户被放到一个类里。在给定的用户类别关系下,假设用户打分是独立的,即:朴素贝叶斯模型的模型结构。类别的数量与模型的参数都从数据中学到。第二个模型代表各个物品都是贝叶斯网络的一个节点,其中每个节点的状态都是连接着每个物品可能的打分值。网络的结构和条件概率都是从数据学到的。这个方法的限制是,一个用户可以被聚类到同一个类别,然而一些推荐应用可能受益于把一个用户同时分成多类。举个例子,在图书推荐系统应用,一个用户可能由于工作(比如编程)对一个类别感兴趣,但是出于休闲(比如钓鱼)对完全不通的类别感兴趣。
Moreover, [11] proposed a collaborative filtering method in a machine learning framework, where various machine learning techniques (such as artificial neural networks) coupled with feature extraction techniques (such as singular value decomposition – an algebraic technique for reducing dimensionality of matrices) can be used. Both [15] and [11] compare their respective model-based approaches with standard memory-based approaches and report that in some applications model-based methods outperform memory-based approaches in terms of accuracy of recommendations. However, the comparison in both cases is purely empirical and no underlying theoretical evidence supporting this claim is provided.
此外,协同过滤的方法使用机器学习的框架,可以采用机器学习的技术(比如人工神经网络)结合特征提取技术(比如奇异值分解——一种给矩阵降维的代数方法)的方法。文献15和11中,他们各自的基于模型的方法与标准的基于记忆的方法比较,指出了在一些应用中,基于模型的方法要比基于记忆的准确率更高。然而,这两个例子都是纯实验的,没有理论支持。
There have been several other model-based collaborative recommendation approaches proposed in the literature. A statistical model for collaborative filtering was proposed in [105], and several different algorithms for estimating the model parameters were compared, including K-means clustering and Gibbs sampling. Other collaborative filtering methods include a Bayesian model [20], a probabilistic relational model [37], a linear regression [91], and a maximum entropy model [75]. More recently, a significant amount of research has been done in trying to model the recommendation process using more complex probabilistic models. For instance, [96] view the recommendation process as a sequential decision problem and propose to use Markov decision processes (a well known stochastic technique for modeling sequential decisions) for generating recommendations. Other probabilistic modeling techniques for recommender systems include probabilistic latent semantic analysis [47, 48] and a combination of multinomial mixture and aspect models using generative semantics of Latent Dirichlet Allocation [64]. Similarly, [99] also use probabilistic latent semantic analysis to propose a flexible mixture model that allows modeling the classes of users and items explicitly with two sets of latent variables. Furthermore, [55] use a simple probabilistic model to demonstrate that collaborative filtering is valuable with relatively little data on each user, and that, in certain restricted settings, simple collaborative filtering algorithms are almost as effective as the best possible algorithms in terms of utility.
在文献里面提到了几种其他的基于模型的协同滤波的推荐系统。文献105提出了一个统计模型的协同滤波的方法,比较了一些不同的模型参数预测算法,包括K-平均聚类和吉布斯采样。其他协同滤波方法,包括一个贝叶斯模型,一个概率关系模型,线性回归,和最大熵模型。最近,为了在推荐过程中用更复杂的概率模型,做了大量的研究。举个例子,把推荐系统当成连续判定问题,使用用马尔可夫判定过程(一个著名的解决模型顺序决定的随机过程技术)生成建议。推荐系统的其他概率模型技术包括潜在概率的语义分析和一个结合了多项式混合和方位(???)的模型,并使用Latent Dirichlet Allocation生成语义。相似的,也可以用潜在概率语义分析去做一个灵活混合模型,用两组潜在变量明确地建模用户类和物品类。进一步,用简单的概率模型去证明协同滤波在小数据的情况下非常有用,在某些受限制的条件下,简单的协同滤波算法在实用上可能是最有效的算法。
As in the case of content-based techniques, the main difference between collaborative model-based techniques and heuristic-based approaches is that the model-based techniques calculate utility (rating) predictions based not on some ad-hoc heuristic rules, but rather based on a model learned from the underlying data using statistical and machine learning techniques. A
method combining both memory-based and model-based approaches was proposed in [79], where it was empirically demonstrated that the use of this combined approach can provide better recommendations than pure memory-based and model-based collaborative approaches.
像基于内容的技术提到的例子一样,协同滤波基于模型的技术和基于启发式的方法的主要不同就是,基于模型的技术计算效用时不是用专门的启发规则,而是用统计学和机器学习的技术从基础数据中学习模型。文献79中提到结合了基于记忆和基于模型的方法,从实验表明结合的方法比纯记忆或纯模型的方法都好。
A different approach to improving the performance of existing collaborative filtering algorithms was taken in [108], where the input set of user-specified ratings is carefully selected using several techniques that exclude noise, redundancy, and exploit the sparsity of the ratings’ data. The empirical results demonstrate the increase in accuracy and efficiency for model-based collaborative filtering algorithms. It is also suggested that the proposed input selection techniques may help the model-based algorithms to address the problem of learning from large databases [108]. Furthermore, among the latest developments, [109] propose a probabilistic approach to collaborative filtering that constitutes yet another way to combine the memory-based and model-based techniques. In particular, [109] propose (a) to use an active learning approach to learn the probabilistic model of each user’s preferences and (b) to use the stored user profiles in a mixture model to calculate recommendations. The latter aspect of the proposed approach deploys some of the ideas used in the traditional memory-based algorithms.
文献108中提到了改进现有协同滤波算法表现的不同方法,输入集是使用一些技术精心挑选的用户打分,这些技术排除了噪音、冗余,利用了打分数据的稀疏性。实验结果证明这提升了基于模型的协同滤波算法的准确率和有效性。文献108页建议到,选择技术也许帮助基于模型的算法解决从大量数据库学习的问题。此外,在最新的进展中,文献109提出一个协同滤波的概率方法,它提出了用另一种方法去结合基于记忆和基于模型的技术。特别的,在文献109中提到(a)用主动学习去学到每个用户喜好的概率模型(b)用混合模型储存用户画像,再去计算推荐。在这个建议方法的最后使用了一些传统的基于记忆算法的思想。
The pure collaborative recommender systems do not have some of the shortcomings that content-based systems have. In particular, since collaborative systems use other users’ recommendations (ratings), they can deal with any kind of content and recommend any items, even the ones that are dissimilar to those seen in the past. However, collaborative systems have their own limitations [8, 57], as described below.
纯协同滤波推荐系统没有基于内容系统的某些问题。特别是,因为协同滤波系统使用其他用户(打分)推荐,这些系统可以处理任何内容和任何物品,甚至那个东西和过去看见的都不相似。然而,协同滤波系统有自己的局限性,下面将会提到:
New user problem. It is the same problem as with content-based systems. In order to make accurate recommendations, the system must first learn the user’s preferences from the ratings that the user makes. Several techniques have been proposed to address this problem. Most of them use hybrid recommendation approach, which combines content-based and collaborative
techniques. The next section describes hybrid recommender systems in more detail. An alternative approach is presented in [83, 109], where various techniques are explored for determining the best (i.e., most informative to a recommender system) items for a new user to rate. These techniques use strategies that are based on item popularity, item entropy, user personalization, and combinations of the above [83, 109].
新用户问题(冷启动)。和基于内容的系统由同样的问题。为了做准确的推荐,系统必须首先从用户的打分学习用户的喜好。一些技术可以解决这个问题。大部分使用混合推荐的方法,结合了基于内容的和协同滤波的技术。在下一章介绍混合推荐系统的更多细节。文献83、109提供了一个可选择的方法,有许多技术被开发出来去预测给新用户去打分最佳物品(即为推荐系统提供最多信息的物品)。这些技术使用了基于物品流行度、物品熵、用户个性化或者结合上面方法的策略。
New item problem. New items are added regularly to recommender systems. Collaborative systems rely solely on users’ preferences to make recommendations. Therefore, until the new item is rated by a substantial number of users, the recommender system would not be able to recommend it. This problem can also be addressed using hybrid recommendation approaches, described in the next section.
新物品问题。新物品定期被加入到推荐系统里。协同滤波系统只依赖用户的喜好去做推荐。因此知道一个新的物品被一些用户打分之后,系统才能推荐它。这个问题也可以被下一章提到的混合推荐方法解决。
Sparsity. In any recommender system, the number of ratings already obtained is usually very small compared to the number of ratings that need to be predicted. Effective prediction of ratings from a small number of examples is important. Also, the success of the collaborative recommender system depends on the availability of a critical mass of users. For example, in the
movie recommendation system there may be many movies that have been rated only by few people and these movies would be recommended very rarely, even if those few users gave high ratings to them. Also, for the user whose tastes are unusual compared to the rest of the population there will not be any other users who are particularly similar, leading to poor recommendations [8]. One way to overcome the problem of rating sparsity is to use user profile information when calculating user similarity. That is, two users could be considered similar not only if they rated the same movies similarly, but also if they belong to the same demographic segment. For example, [76] uses gender, age, area code, education, and employment information of users in the restaurant recommendation application. This extension of traditional collaborative filtering techniques is sometimes called “demographic filtering” [76]. Another approach that also explores similarities among users has been proposed in [49], where the sparsity problem is addressed by applying associative retrieval framework and related spreading activation algorithms to explore transitive associations among consumers through their past transactions and feedback. A different approach for dealing with sparse rating matrices was used in [11, 90], where a dimensionality reduction technique, Singular Value Decomposition (SVD), was used to reduce dimensionality of sparse ratings matrices. SVD is a well-known method for matrix factorization that provides the best lower rank approximations of the original matrix [90].
稀疏性。在任何推荐系统中,已经获得的打分数量与需要预测的打分的数量相比是非常小的。从小数据量有效预测打分是非常重要的。协同滤波推荐系统的成功依赖于关键用户的有效性。举个例子,在电影推荐系统里,有很多电影只被很少的人打分,这些电影将很少被推荐,甚至那些用户给了高分也很难推荐。口味不寻常的用户比其他人,可能很少有人跟他那么像,推荐系统表现就会非常差。一个解决打分稀疏的方法是使用计算用户相似度的时候用户画像信息。两个用户被认为相似,不仅可以因为他们电影打分相似,也可以是因为他们属于同一人口划分。举个例子,在餐厅推荐应用里,可以使用用户的性别、年龄、邮编、教育和工作信息。传统协同滤波技术的扩展,有时候也叫做“人口滤波”。文献49中提到了另一种方法也是从用户中找到相似性,其中稀疏性问题可以被解决,使用联合检索框架和相关扩散激活算法根据他们过去的交易和反馈区传递用户之间的关系。文献11和90用了一个不同的方法去解决稀疏的打分矩阵,降维技术SVD,用来减少稀疏打分矩阵的维度。SVD是在矩阵分解中一个非常有名的方法,提供原始矩阵的最佳低阶近似矩阵。
2.3. Hybrid Methods 混合方法
Several recommendation systems use a hybrid approach by combining collaborative and content-based methods, which helps to avoid certain limitations of content-based and collaborative systems [8, 9, 21, 76, 94, 100, 105]. Different ways to combine collaborative and content-based methods into a hybrid recommender system can be classified as follows: (1) implementing collaborative and content-based methods separately and combining their predictions, (2) incorporating some content-based characteristics into a collaborative approach, (3) incorporating some collaborative characteristics into a content-based approach, and (4) constructing a general unifying model that incorporates both content-based and collaborative characteristics. All of the above approaches have been used by recommender systems researchers, as described below.
一些推荐系统使用混合的方法,结合了协同滤波和基于内容的方法,帮助避免这两种方法的限制。不同的方式去结合着两种方法可以被分为以下几类:(1)分别使用两种方法,在结合他们的预测。(2)把基于内容的一些特征结合到协同滤波。(3)把协同滤波的一些特征结合到基于内容的方法。(4)构造一个综合模型,结合了基于内容和协同滤波的特征。以上的方法都在推荐系统研究中用过,下面将会提到。
1. Combining separate recommenders. One way to build hybrid recommender systems is to implement separate collaborative and content-based systems. Then we can have two different scenarios. First, we can combine the outputs (ratings) obtained from individual recommender systems into one final recommendation using either a linear combination of ratings [21] or a voting scheme [76]. Alternatively, we can use one of the individual recommenders, at any given moment choosing to use the one that is “better” than others based on some recommendation “quality” metric. For example, the DailyLearner system [13] selects the recommender system that can give the recommendation with the higher level of confidence, while [104] chooses the one whose recommendation is more consistent with past ratings of the user.
1.结合两个分开的推荐系统。做一个混合推荐系统的一种方法就是将分离的协同滤波和基于内容的系统结合起来。我们有两个不同的情景。一种方法是,我们可以使用评级的线性组合或投票方案将单个推荐系统获得的输出(打分)组合成一个最终推荐。另一种,我们可以用其中一个推荐系统,在提意见的时候,根据推荐系统的“质量”标准,选择效果更好的那个。举个例子,DailyLearner选择可信度较高的那个,而文献104中选择的是和用户过去打分更一致的。
2. Adding content-based characteristics to collaborative models. Several hybrid recommender systems, including Fab [8] and the “collaboration via content” approach, described in [76], are based on traditional collaborative techniques but also maintain the content-based profiles for each user. These content-based profiles, and not the commonly rated items, are then used to calculate the similarity between two users. As mentioned in [76], this allows to overcome some sparsity-related problems of a purely collaborative approach, since typically not many pairs of users will have a significant number of commonly rated items. Another benefit of this approach is that users can be recommended an item not only when this item is rated highly by users with similar profiles, but also directly, i.e., when this item scores highly against the user’s profile [8]. [40] employs a somewhat similar approach in using the variety of different filterbots – specialized content-analysis agents that act as additional participants in a collaborative filtering community. As a result, the users whose ratings agree with some of the filterbots’ ratings would be able to receive better recommendations [40]. Similarly, [65] uses a collaborative approach where the traditional user’s ratings vector is augmented with additional ratings, which are calculated using a pure content-based predictor.
2.在协同滤波模型里面加入基于内容的特征。一些混合的推荐系统,包括Fab和文献76提到的“通过内容的协同滤波”方法,他们都是基于传统的协同滤波技术但是为每个用户保存了基于内容的画像。这些基于内容的画像用来计算两个用户的相似度,而不是用平常的打分的物品。像文献76中提到的,它克服了一些纯协同滤波方法的稀疏相关问题,因为通常用户很少有那么多打分的物品。这个方法的另一个好处是,用户被推荐的物品不仅仅是和画像相似用户打高分的物品,还有直接的,即和用户画像相比得分很高的物品。文献40用了相似的方法,用了许多不同的滤波器——这是在协同滤波里属于专门的内容分析代理的附加品。结果是,打分与一些滤波器打分一致的用户会受到更好的推荐结果。相似的,文献65使用了协同滤波的方法,其中传统用户的打分向量被一个附加打分增强,附加打分使用纯基于内容的预测器来计算。
3. Adding collaborative characteristics to content-based models. The most popular approach in this category is to use some dimensionality reduction technique on a group of content-based profiles. For example, [100] use latent semantic indexing (LSI) to create a collaborative view of a collection of user profiles, where user profiles are represented by term vectors (as discussed in Section 2.1), resulting in a performance improvement compared to the pure content-based approach.
3.在基于内容的模型加入协同滤波的特征。最流行的方法就是一组在基于内容的画像上使用降维技术。举个例子,文献100中使用潜在语义索引(LSI)去为用户画像建立了一个协同滤波的视角,其中用户画像被向量代表(2.1中提到),结果比纯基于内容的表现要好。
4. Developing a single unifying recommendation model. Many researchers have followed this approach in recent years. For instance, [9] propose to use content-based and collaborative characteristics (e.g., the age or gender of users or the genre of movies) in a single rule-based classifier. [80] and [94] propose a unified probabilistic method for combining collaborative and
content-based recommendations, which is based on the probabilistic latent semantic analysis [46]. Yet another approach is proposed by [25] and [5], where Bayesian mixed-effects regression models are used that employ Markov chain Monte Carlo methods for parameter estimation and prediction. In particular, [5] uses the profile information of users and items in a single statistical model that estimates unknown ratings ![]() for user i and item j:
for user i and item j:
4.构建一个综合的推荐系统模型。最近几年,许多研究者都在做。举个例子,文献9中提到将基于内容和协同滤波的特征(比如:用户的年龄、性别;电影题材)用于一个基于规则的分类器中。文献80和94提到一个结合协同过滤和基于内容的推荐系统的统一概率方法,这是一个基于概率的潜在语义分析。文献25和5的另一种方法,采用贝叶斯混合效应回归模型,采用马尔可夫链蒙特卡罗方法进行参数估计和预测。特别的,文献5预测用户i和物品j的未知打分![]() 的数据统计模型使用了用户和物品的画像信息:
的数据统计模型使用了用户和物品的画像信息:
![]() ......公式(15)
......公式(15)
where i =1,…, I and j =1,…, J represent users and items respectively, and  ,
,  , and
, and ![]() are random variables taking into effect noise, unobserved sources of user heterogeneity and item heterogeneity respectively. Also,
are random variables taking into effect noise, unobserved sources of user heterogeneity and item heterogeneity respectively. Also,  is a matrix containing user and item characteristics,
is a matrix containing user and item characteristics,  is a vector of user characteristics, and
is a vector of user characteristics, and  is a vector of item characteristics. The unknown parameters of this model are μ ,
is a vector of item characteristics. The unknown parameters of this model are μ ,  , Λ, and Γ , and they are estimated from the data of already known ratings using Markov chain Monte Carlo methods. In summary, [5] uses user attributes
, Λ, and Γ , and they are estimated from the data of already known ratings using Markov chain Monte Carlo methods. In summary, [5] uses user attributes ![]() constituting a part of a user profile, item attributes
constituting a part of a user profile, item attributes ![]() constituting a part of an item profile and their interactions
constituting a part of an item profile and their interactions ![]() to estimate the rating of an item.
to estimate the rating of an item.
i、j分别代表用户和物品 。 , , 和 ![]() 为效果噪声的随机变量,分别是未观测到的用户和物品的异质性。是一个包含用户和物品特征的矩阵,是用户特征向量,为物品特征向量。未知参数μ , , Λ, 和 Γ,他们从已知打分数据,使用马尔可夫链蒙特卡罗方法预测。总结一下,用户属性
为效果噪声的随机变量,分别是未观测到的用户和物品的异质性。是一个包含用户和物品特征的矩阵,是用户特征向量,为物品特征向量。未知参数μ , , Λ, 和 Γ,他们从已知打分数据,使用马尔可夫链蒙特卡罗方法预测。总结一下,用户属性![]() 为用户画像的一部分,物品属性
为用户画像的一部分,物品属性![]() 为物品画像一部分,他们的交集
为物品画像一部分,他们的交集![]() 用来预测一个物品的打分。
用来预测一个物品的打分。
Hybrid recommendation systems can also be augmented by knowledge-based techniques [17], such as case-based reasoning, in order to improve recommendation accuracy and to address some of the limitations (e.g., new user, new item problems) of traditional recommender systems. For example, knowledge-based recommender system Entrée [17] uses some domain knowledge about restaurants, cuisines, and foods (e.g., that “seafood” is not “vegetarian”) to recommend restaurants to its users. The main drawback of knowledge-based systems is a need for knowledge acquisition – a well-known bottleneck for many artificial intelligence applications. However, knowledge-based recommendation systems have been developed for application domains where domain knowledge is readily available in some structured machine-readable form, e.g., as an ontology. For example, Quickstep and Foxtrot systems [66] use research paper topic ontology to recommend online research articles to the users.
混合推荐系统可以用基于知识的技术增强,比如基于案例推理,可以去增强推荐系统的准确性并且解决传统推荐系统的一些限制(比如新用户、新物品问题)。举个例子,基于知识的推荐系统Entrée用一些关于餐馆、饭菜、食物(比如“海鲜”不是“素食主义”)领域的知识来给用户推荐餐馆。基于知识系统的主要缺点就是需要知识的获取——许多人工智能应用的常见瓶颈。然而已经为这些领域的应用开发了基于知识的推荐系统,这些领域的知识已经是机器可读结构的了,比如正交。举个例子,Quickstep 和Foxtrot系统使用研究话题正交去给用户在线推荐研究文章。
Moreover, several papers, such as [8, 65, 76, 100], empirically compare the performance of the hybrid with the pure collaborative and content-based methods and demonstrate that the hybrid methods can provide more accurate recommendations than pure approaches.
此外,一些论文,比如文献8、65、76、100,实验比较了混合方法和纯协同滤波和基于内容的方法,证明混合方法比其他方法更精确。
2.4. Summary and Conclusions 总结
As described in Sections 2.1-2.3, there has been much research done on recommendation technologies over the past several years that have used a broad range of statistical, machine learning, information retrieval and other techniques and that significantly advanced the state-of-art in comparison to early recommender systems that utilized collaborative- and content-based heuristics. As was discussed above, recommender systems can be categorized as being (a) content-based, collaborative, or hybrid, based on the recommendation approach used, and (b) heuristic-based or model-based based on the types of recommendation techniques used for the rating estimation. We use these two orthogonal dimensions to classify the recommender systems research in the 2×3 matrix presented in Table 2.
在2.1-2.3中提到的,在鼓秋的纪念里,在推荐系统技术方面已经做了很多研究,使用了广泛的统计范围、机器学习、信息检索和其他技术,最新的技术比起早期利用基于启发式的协同滤波、内容推荐系统有了重大进步。像之前讨论的那样,推荐系统可以可以被分为:(a)基于内容的,协同滤波或者混合的,用于推荐系统(b)基于启发式或者基于模型的推荐技术,用于打分预测。我们用两个正交的维度(大小2x3的矩阵)去分类推荐系统,见表2。
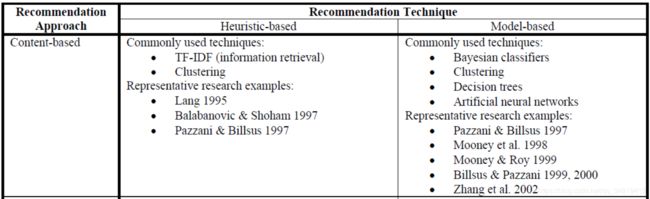
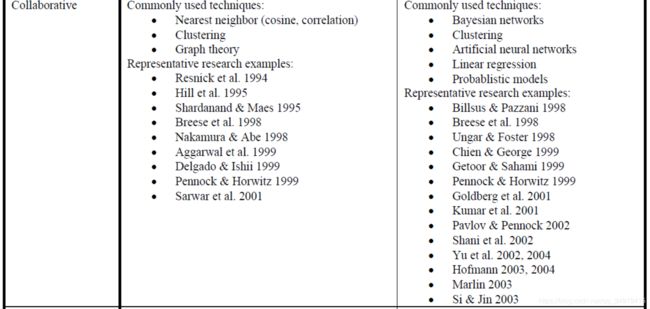

The recommendation methods described in this section have performed well in several applications, including the ones for recommending books, CDs, and news articles [64, 88], and some of these methods are used in the “industrial-strength” recommender systems, such as the ones deployed at Amazon [61], MovieLens [67], and VERSIFI Technologies (formerly AdapiveInfo.com) [14]. However, both collaborative and content-based methods have certain limitations described earlier in this section. Moreover, in order to provide better recommendations and to be able to use recommender systems in arguably more complex types of applications, such as recommending vacations or certain types of financial services, most of the methods reviewed in this section would need significant extensions. For example, even for a traditional movie recommendation application, [3] showed that, by extending the traditional memory-based collaborative filtering approach to take into the consideration the contextual information, such as when, where and with whom a movie is seen, the resulting recommender system could outperform the pure traditional collaborative filtering method. Many real-life recommendation applications, including several business applications, such as the ones described above, are arguably more complex than a movie recommender system, and would require taking more factors into the recommendation consideration. Therefore, the need to develop more advanced recommendation methods is even more pressing for such types of applications. In the next section, we review various ways to extend recommendation methods in order to support more complex types of recommendation applications.
本章介绍的推荐方法在几个应用中表现很不错,包括推荐书、CD、新闻;和一些用于工业级推荐系统的其他方法,比如部署于 Amazon、MovieLens、VERSIFI Technologies 。然而,协同滤波和基于内容的方法都有某些限制,这在前面的章节中提到过。此外,为了更好的推荐、在更复杂的应用中用推荐系统,比如推荐假日或者某些金融服务,本章节讨论的大部分方法都要被扩展。举个例子,即使传统电影推荐应用,文献3提到,为了扩展传统的基于记忆的协同滤波方法去考虑上下文信息,比如何时、何地、和谁看电影,推荐系统的结果比纯传统的协同滤波方法要好很多。许多真实的推荐系统应用,包括许多商业应用,比如上面说到的,可以说是比电影推荐系统更加复杂,需要再建议的时候考虑更多的因素。因此,提升更好的推荐系统方法对于这些应用来说是更加迫切的。在下一章,我们将回顾这些扩展推荐系统的方法,去支持更加复杂的推荐系统应用。
3. Extending Capabilities of Recommender Systems 推荐系统的扩展能力
Recommender systems, as described in Section 2 and summarized in Table 2, can be extended in several ways that include improving the understanding of users and items, incorporating the contextual information into the recommendation process, supporting multi-criteria ratings, and providing more flexible and less intrusive types of recommendations. Such more comprehensive models of recommender systems can provide better recommendation capabilities. In the remainder of this section we describe the proposed extensions and also identify various research opportunities for developing them.
就像第2章讲的和表2总结的那样,推荐系统可以用一些方法进行扩展,包括提升对用户和物品的理解力,在推荐过程中加入上下文信息,支持多规则打分,和更灵活少打扰的推荐。很多推荐系统的综合模型能够提供更好的推荐能力。在本章的后面,我们要讲讲这些扩展方法,支持提升他们的各种研究机会。
3.1. Comprehensive understanding of users and items 全面了解用户和物品
As was pointed out in [2, 8, 54, 105], most of the recommendation methods produce ratings that are based on a limited understanding of users and items as captured by user and item profiles and do not take full advantage of the information in the user's transactional histories and other available data. For example, classical collaborative filtering methods [45, 86, 97] do not use user and item profiles at all for the recommendation purposes and rely exclusively on the ratings information to make recommendations. Although there has been some progress made on incorporating user and item profiles into some of the methods since the earlier days of recommender systems [13, 76, 79], still these profiles tend to be quite simple and do not utilize some of the more advanced profiling techniques. In addition to using traditional profile features, such as keywords and simple user demographics [69, 77], more advanced profiling techniques based on data mining rules [1, 34], sequences [63], and signatures [26] that describe user’s interests can be used to build user profiles. Also, in addition to using the traditional item profile features, such as keywords [9, 76], similar advanced profiling techniques can also be used to build comprehensive item profiles. With respect to recommender systems, advanced profiling techniques that are based on data mining have been used mainly in the context of Web usage analysis [59, 68, 110], i.e., to discover navigational Web usage patterns (i.e., page view sequences) of users in order to provide better Web site recommendations; however, such techniques have not been widely adopted in rating-based recommender systems.
文献2、8、54、105中指出,大部分推荐方法产生打分,是基于一个对用户和物品有限的理解,是被用户和物品画像所限制的,没有充分利用用户交易历史和其他有用的信息。举个例子,传统的协同滤波方法在做出建议的时候根本没有使用用户和物品的画像,仅仅依赖于打分信息去给出推荐。从早期的推荐系统依赖,尽管一些方法在结合用户和物品画像方面有一些进步,但是这些画像仍然是特别简单的那种,不能利用一些更先进的画像技术。除了使用传统的画像特征,比如关键词和简单的用户统计资料,更先进的画像技术是基于数据挖掘规则、序列、签名来描述用户的喜好,进而构成用户画像。而且,除了传统物品画像特征,比如关键词,类似的更先进的画像技术可以被用来建立综合的物品画像。关于推荐系统,先进的画像技术可以用数据挖掘来进行Web使用情况分析,即发现用户的导航Web使用模式(网页视图序列),从而提供更好的网站推荐;然而,一些技术还没有广泛的用到基于打分的推荐系统里。
Once user and item profiles are built, the most general ratings estimation function can be defined in terms of these profiles and the previously specified ratings as follows. Let profile of user i be defined as a vector of p features, i.e.,  . Also, let profile of item j be defined as a vector of r features, i.e.,
. Also, let profile of item j be defined as a vector of r features, i.e., ![]() . We deliberately did not define precisely the meanings of features
. We deliberately did not define precisely the meanings of features 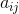 and
and ![]() because they can mean different concepts in different applications, such as numbers, categories, rules, sequences, etc. Also, let
because they can mean different concepts in different applications, such as numbers, categories, rules, sequences, etc. Also, let ![]() be a vector of all user profiles, i.e.,
be a vector of all user profiles, i.e., ![]() , and let
, and let ![]() be a vector of all item profiles, i.e.,
be a vector of all item profiles, i.e., ![]() . Then the most general rating estimation procedure can be defined as
. Then the most general rating estimation procedure can be defined as
一旦用户和物品的画像建立起来了,最一般的打分预测函数就可以用这些画像和之前的打分来定义。令用户i的画像为p个特征的向量,即。同样的,物品j的画像为r个特征的向量,即![]() 。我们故意不精确定义特征 和
。我们故意不精确定义特征 和![]() 的含义,因为他们在不同应用中可以有不同的定义,比如数字、类型、规则、序列等等。同样的,令向量
的含义,因为他们在不同应用中可以有不同的定义,比如数字、类型、规则、序列等等。同样的,令向量![]() 为所有用户的画像,即
为所有用户的画像,即![]() ,向量
,向量![]() 为所有物品的画像,即
为所有物品的画像,即![]() 。然后最一般的打分预测过程可以被定义为:
。然后最一般的打分预测过程可以被定义为:
![]() ......公式(16)
......公式(16)
that estimates each unknown rating ![]() in terms of known ratings
in terms of known ratings ![]() , user profiles
, user profiles ![]() , and item profiles
, and item profiles ![]() . We can use various methods for estimating utility function
. We can use various methods for estimating utility function 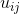 , including various heuristics, nearest neighbor classifiers, decision trees, spline methods, radial basis functions, regressions, and neural networks. Moreover, we would like to point out that equation (16) presents the most general model that depends on a whole range of inputs, including the characteristics of user
, including various heuristics, nearest neighbor classifiers, decision trees, spline methods, radial basis functions, regressions, and neural networks. Moreover, we would like to point out that equation (16) presents the most general model that depends on a whole range of inputs, including the characteristics of user ![]() and possibly other users
and possibly other users ![]() , characteristics of item
, characteristics of item ![]() , and possibly other items
, and possibly other items ![]() , ratings (preferences)
, ratings (preferences) 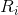 expressed by user i and ratings (preferences) expressed by all other users
expressed by user i and ratings (preferences) expressed by all other users ![]() . Therefore, function clearly subsumes collaborative, content-based and hybrid methods discussed in Section 2. However, most of the existing recommender systems make function dependent only on a (small) subset of the whole input space R,
. Therefore, function clearly subsumes collaborative, content-based and hybrid methods discussed in Section 2. However, most of the existing recommender systems make function dependent only on a (small) subset of the whole input space R, ![]() , and
, and ![]() . For example, function for traditional memory-based collaborative filtering methods does not depend on inputs
. For example, function for traditional memory-based collaborative filtering methods does not depend on inputs ![]() and
and 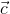 and restricts R only to column
and restricts R only to column ![]() and usually only to the set of N nearest neighbors
and usually only to the set of N nearest neighbors ![]() for column
for column ![]() .
.
预测位置的打分![]() 是依据已知的打分
是依据已知的打分![]() 、用户画像
、用户画像![]() 和物品画像
和物品画像![]() 。我们可以用不同的方法去预测效用函数,包括许多启发式的方法、最近邻居分类器、决策树、样条函数法、径向基函数、回归函数和神经网络。此外,我们可以指出公式16展现了依赖所有输入的最普通的模型,包括用户i的特征
。我们可以用不同的方法去预测效用函数,包括许多启发式的方法、最近邻居分类器、决策树、样条函数法、径向基函数、回归函数和神经网络。此外,我们可以指出公式16展现了依赖所有输入的最普通的模型,包括用户i的特征![]() ,和可能的其他用户
,和可能的其他用户![]() ,物品j的特征
,物品j的特征![]() ,和可能的其他物品
,和可能的其他物品![]() ,用户i的打分(喜好)和其他所有用户的打分(喜好)
,用户i的打分(喜好)和其他所有用户的打分(喜好)![]() 。因此,函数清晰地包含了第2章提到的协同滤波、基于内容和混合的方法。然而,大部分现有的推荐系统所用的函数,只是依赖于一个R,
。因此,函数清晰地包含了第2章提到的协同滤波、基于内容和混合的方法。然而,大部分现有的推荐系统所用的函数,只是依赖于一个R, ![]() , 和
, 和![]() 的一个很小的子集。举个例子,传统基于记忆的协同滤波方法的函数没有用到
的一个很小的子集。举个例子,传统基于记忆的协同滤波方法的函数没有用到![]() ,并且和约束R只对列
,并且和约束R只对列![]() 起作用,并且通常只对列
起作用,并且通常只对列![]() 的N近邻
的N近邻![]() 的集合有用。
的集合有用。
An interesting research problem would be to extend the attribute-based profiles, as defined by ![]() and
and ![]() , to utilize more advanced profiling techniques described above, such as rule-, sequence-, and signature-based methods.
, to utilize more advanced profiling techniques described above, such as rule-, sequence-, and signature-based methods.
一个有趣的研究问题就是扩展基于属性的画像,像定义![]() 和
和![]() ,去利用前面提到的更先进的画像技术,比如基于规则的、序列的、签名的方法。
,去利用前面提到的更先进的画像技术,比如基于规则的、序列的、签名的方法。
3.2. Extensions for Model-Based Recommendation Techniques 扩展基于模型的推荐系统技术
As discussed in Section 2, some of the model-based approaches provide rigorous rating estimation methods utilizing various statistical and machine learning techniques. However, other areas of mathematics and computer science, such as mathematical approximation theory [16, 73,81], can also contribute to developing better rating estimation methods defined by equation (16). One example of an approximation-based approach to defining function in (16) constitutes radial basis functions [16, 30, 92] that are defined as follows. Given a set of points ![]() and the values of an unknown function f (e.g., the rating function) at these points, i.e.,
and the values of an unknown function f (e.g., the rating function) at these points, i.e., ![]() , a radial basis function
, a radial basis function ![]() estimates the values of f in the whole
estimates the values of f in the whole ![]() , given
, given ![]() for all i =1,…,m , as
for all i =1,…,m , as
像在第2章讨论的那样,一些基于模型的方法提供了严格的打分预测方法,它们利用了统计学和机器学习的技术。然而,数学和计算机科学的其他领域,比如数学近似理论,也能有助于提升更好的打分预测方法,定义见公式(16)。基于近似方法的一个例子就是公式(16)里面定义的函数构成了下面将要定义的径向基函数。给出点集合![]() ,未知函数f(比如打分函数)在这些点的值,即
,未知函数f(比如打分函数)在这些点的值,即![]() ,一个径向基函数
,一个径向基函数![]() 在整个
在整个![]() 中预测f的值,给定对于所有的 i =1,…,m,
中预测f的值,给定对于所有的 i =1,…,m,![]() ,有
,有
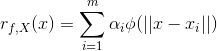 ......公式(17)
......公式(17)
where ![]() are coefficients from
are coefficients from ![]() , ||x|| is a norm (e.g.,
, ||x|| is a norm (e.g.,  ) and
) and  is a positive definite function, i.e., a function satisfying the condition
is a positive definite function, i.e., a function satisfying the condition
其中![]() 为实数系数,||x||是一个标准(比如),是一个正定函数,即满足条件的函数
为实数系数,||x||是一个标准(比如),是一个正定函数,即满足条件的函数
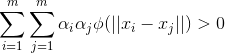 ......公式(18)
......公式(18)
for all distinct points ![]() and all the coefficients
and all the coefficients ![]() from
from ![]() . Then a wellknown theorem [92] states that if is a positive definite function then there exists a unique function
. Then a wellknown theorem [92] states that if is a positive definite function then there exists a unique function ![]() of the form (17) satisfying the conditions
of the form (17) satisfying the conditions ![]() for all i =1,…,m . Some popular examples of positive definite functions are:
for all i =1,…,m . Some popular examples of positive definite functions are:
其中所有离散点![]() ,和所有实数系数
,和所有实数系数![]() 。一个著名理论说道,如果是一个正定函数,则存在形如公式(17)的唯一函数
。一个著名理论说道,如果是一个正定函数,则存在形如公式(17)的唯一函数![]() 满足条件,对于所有 i =1,…,m,有
满足条件,对于所有 i =1,…,m,有 ![]() 。一些流行的正定函数例子:
。一些流行的正定函数例子:
One of the advantages of radial basis functions is that they have been extensively studied in the approximation theory, and their theoretical properties and utilization of radial basis functions in many practical applications have been understood very well [16, 92]. Therefore, it should be interesting to apply them for estimating unknown ratings in recommender systems.
径向基函数的其中给一个好处就是可以在近似理论中广泛学习,并且它们的理论性质和径向基函数在许多实际应用中的应用已经被很好地理解。因此,在推荐系统中使用他们进行预测应该很有趣。
One caveat with using radial basis functions in recommender systems, though, is that the recommendation space ![]() does not usually constitute an N-dimensional Euclidean space
does not usually constitute an N-dimensional Euclidean space ![]() . Therefore, one research challenge is to extend radial basis methods from the real numbers to other domains and apply them to recommender systems problems. The applicability of other approximation methods for estimating in (16) constitutes another interesting research topic.
. Therefore, one research challenge is to extend radial basis methods from the real numbers to other domains and apply them to recommender systems problems. The applicability of other approximation methods for estimating in (16) constitutes another interesting research topic.
在推荐系统中使用径向基函数有一点需要注意,虽然推荐空间为![]() ,但是通常不构成一个N维欧几里德空间
,但是通常不构成一个N维欧几里德空间![]() 。因此,将径向基方法从实数推广到其他领域,并将其应用于推荐系统问题是一个研究难题。其他近似方法对预测公式(16)中的的适用性构成了另一个有趣的研究课题。
。因此,将径向基方法从实数推广到其他领域,并将其应用于推荐系统问题是一个研究难题。其他近似方法对预测公式(16)中的的适用性构成了另一个有趣的研究课题。
3.3. Multidimensionality of recommendations 多维度推荐系统
Current generation of recommender systems operates in the two-dimensional User×Item space. That is, they make their recommendations based only on the user and item information and do not take into the consideration additional contextual information that may be crucial in some applications. However, in many situations the utility of a certain product to a user may depend significantly on time (e.g., the time of the year, such as season or month, or the day of the week). It may also depend on the person(s) with whom the product will be consumed or shared and under which circumstances. In such situations it may not be sufficient to simply recommend items to users; the recommender system must take additional contextual information, such as time, place, and the company of a user, into the consideration when recommending a product. For example, when recommending a vacation package, the system should also consider the time of the year, with whom the user plans to travel, traveling conditions and restrictions at that time, and other contextual information. As another example, a user can have significantly different preferences for the types of movies she wants to see when she is going out to a movie theater with a boyfriend on a Saturday night as opposed to watching a rental movie at home with her parents on a Wednesday evening. As was argued in [2], it is important to extend traditional two dimensional User×Item recommendation methods to multidimensional settings. In addition, [43] argued that the inclusion of the knowledge about user’s task into the recommendation algorithm in certain applications can lead to better recommendations.
最近的推荐系统都用的两个维度,用户x物品。他们做推荐的时候基于用户和物品的信息,不考虑在其他应用中可能很重要的额外的上下文信息。然而,在许多情况下,某产品对用户的效用可能在很大程度上取决于时间(例如,一年中的时间,如季节、月份或星期几)。它也可能取决于产品将在何种情况下与谁一起消费或共享。在这种情况下,仅仅向用户推荐物品可能是不够的;推荐系统在推荐产品时必须考虑额外的上下文信息,例如时间、地点和用户的公司。举个例子,当推荐度假套餐时,系统还应该考虑一年中的时间,用户计划和谁一起旅行,当时的旅行条件和限制,以及其他相关信息。另一个例子,当用户周六晚上和男友一起去电影院看电影,而不是周三晚上和父母一起在家看租来的电影时,她对想看的电影类型可能会有明显不同的喜好。像文献2说的那样,扩展传统两维推荐方法(用户x物品)到多维是非常重要的。此外,文献43提到,在某些应用程序中,将用户任务的知识包含到推荐算法中可以得到更好的推荐。
In order to take into the consideration the contextual information, [2] propose to define the utility (or ratings) function over a multidimensional space ![]() (as opposed to the raditional 2-dimensional User×Item space) as
(as opposed to the raditional 2-dimensional User×Item space) as
为了考虑上下文信息,定义了多维度![]() 上的效用(打分)函数(与传统2维空间不同):
上的效用(打分)函数(与传统2维空间不同):
![]() ......公式(19)
......公式(19)
Then a recommendation problem is defined by selecting certain “what” dimensions 1, , ![]() and certain “for whom” dimensions
and certain “for whom” dimensions ![]() that do not overlap, i.e.,
that do not overlap, i.e., ![]() , and recommending for each tuple
, and recommending for each tuple ![]() the tuple
the tuple ![]() that maximizes the utility
that maximizes the utility ![]() , i.e.,
, i.e.,
一个推荐问题可以被定义为:选择“某个”维度![]() ,选择与它不重叠的“某个”维度
,选择与它不重叠的“某个”维度![]() ,即
,即![]() (二者相交为空);为
(二者相交为空);为![]() 推荐
推荐![]() 就是最大化效用函数
就是最大化效用函数![]() ,即
,即
......公式(20)
For example, in the case of a movie recommender system one needs to consider not only characteristics of the movie  and of the person who wants to see the movie
and of the person who wants to see the movie  , but also such contextual information as (a)
, but also such contextual information as (a) ![]() : where and how the movie will be seen (e.g., in the movie theater, at home on TV, on video or DVD), (b)
: where and how the movie will be seen (e.g., in the movie theater, at home on TV, on video or DVD), (b) ![]() : with whom the movie will be seen (e.g., alone, with girlfriend/boyfriend, friends, parents, etc.), and (c)
: with whom the movie will be seen (e.g., alone, with girlfriend/boyfriend, friends, parents, etc.), and (c) ![]() : when will the movie be seen (e.g., on weekdays or weekends, in the morning/afternoon/evening, during the opening night, etc.). As discussed earlier, each of the components
: when will the movie be seen (e.g., on weekdays or weekends, in the morning/afternoon/evening, during the opening night, etc.). As discussed earlier, each of the components ![]() can be defined as a vector of its characteristics, and the overall utility function
can be defined as a vector of its characteristics, and the overall utility function ![]() can be quite complex and take into consideration various interaction effects among vectors
can be quite complex and take into consideration various interaction effects among vectors ![]() .
.
举个例子,电影推荐系统里,需要考虑的不只有电影特征 ,还有谁想看,还有上下文信息:(a)![]() 在哪里、怎么看(比如:电影院、在家看电视、DVD等)(b)
在哪里、怎么看(比如:电影院、在家看电视、DVD等)(b)![]() 和谁一起去看(比如:独自、和女/男朋友,朋友,父母等)(c)
和谁一起去看(比如:独自、和女/男朋友,朋友,父母等)(c)![]() 什么时候看(工作日、周末、早中晚、首发夜等)。像之前讨论的那样,每个
什么时候看(工作日、周末、早中晚、首发夜等)。像之前讨论的那样,每个![]() 部分都用一个向量表示他的特征,全部的效用函数
部分都用一个向量表示他的特征,全部的效用函数![]() 可能很复杂,要考虑到向量
可能很复杂,要考虑到向量![]() 之间的互相影响。
之间的互相影响。
As was argued in [2, 3], many of the two-dimensional recommendation algorithms cannot be directly extended to the multidimensional case. Furthermore, [3] proposes a reduction-based recommendation approach which uses only the ratings that pertain to the context of the userspecified criteria in which a recommendation is made. For example, to recommend a movie to a person who wants to see it in a movie theater on a Saturday night, the reduction-based approach would use only the available ratings of the movies seen in the movie theaters over the weekends, if it is determined from the data that the place and the time of the week dimensions affect the moviegoers’ behavior. By selecting only the ratings relevant to a recommendation context, the reduction-based approach projects the multi-dimensional cube of ratings on the two primary User and Item dimensions. Then any standard two-dimensional recommendation method described in Section 2 can be used to produce a recommendation. Since these recommendations are based only on the context-specific set of ratings, this amounts to building a local model producing context-specific recommendations.
像文献2,3提到,许多二维推荐系统不能直接扩展多维的方法。此外,此外,文献3提出了一种基于化简的推荐方法,该方法仅使用与用户指定的推荐标准上下文相关的评级。举个例子,给一个想周六晚上在电影院看电影的人做推荐,基于化简的方法就会只给可以那些周末在电影院看的电影打分,如果根据地点和时间维度确定了电影就会影响观影者的行为。只选择打分与上下文相关的电影,基于化简的方法就可以把多维度的打分化简到用户和物品两个维度。第2章提到的任何标准的两维度推荐方法,都可以用到推荐系统。由于这些推荐系统只是基于特定上下文的打分,这相当于构建一个生成特定上下文推荐的本地模型的。
Another possible approach to producing multi-dimensional recommendations would be to deploy the hierarchical Bayesian method presented in [5], which can be extended from 2- to multi-dimensional case as follows. Instead of considering the two-dimensional case, as defined in (15), where user characteristics are defined with vector and item characteristics with
vector , we can also add contextual dimensions ![]() , where
, where ![]() is a vector of characteristics for dimension
is a vector of characteristics for dimension  . Then the rating function
. Then the rating function ![]() is extended from (15) to the linear combination of
is extended from (15) to the linear combination of ![]() and also includes interaction effects among these dimensions (i.e., interaction effects, as defined by matrix
and also includes interaction effects among these dimensions (i.e., interaction effects, as defined by matrix ![]() in (15), should be extended to include other dimensions). One of the research challenges is to make these extensions scalable for large values of n.
in (15), should be extended to include other dimensions). One of the research challenges is to make these extensions scalable for large values of n.
另一个可能产生多维度推荐系统的方法,就是部署文献5中提出的分层贝叶斯方法,可以从2维扩展到多维。不考虑定义2维,像公式15那样,用户特征被定义成向量,物品特征被定义为,我们还可以加入上下文维度![]() ,其中
,其中![]() ,是的特征向量。打分函数
,是的特征向量。打分函数![]() 被公式15扩展,线性结合
被公式15扩展,线性结合![]() ,并且也包括这些维度之间的相互影响(即公式15定义的
,并且也包括这些维度之间的相互影响(即公式15定义的![]() 需要扩展包含其他维度)。研究的挑战之一,就是这些扩展可以使用n很大的时候。
需要扩展包含其他维度)。研究的挑战之一,就是这些扩展可以使用n很大的时候。
3.4. Multi-criteria ratings 多规则打分
Most of the current recommender systems deal with single-criterion ratings, such as ratings of movies and books. However, in some applications, such as restaurant recommenders, it is crucial to incorporate multi-criteria ratings into recommendation methods. For example, many restaurant guides, such as Zagat’s Guide, provide three criteria for restaurant ratings: food, decor
and service. Although multi-criteria ratings have not yet been examined in the recommender systems literature, they have been extensively studied in the Operations Research community [33, 102]. Typical solutions to the multi-criteria optimization problems include (a) finding Pareto optimal solutions, (b) taking a linear combination of multiple criteria and reducing the problem to a single-criterion optimization problem, (c) optimizing the most important criterion and converting other criteria to constraints, (d) consecutively optimizing one criterion at a time, converting an optimal solution to constraint(s) and repeating the process for other criteria. An example of the latter approach is the method of successive concessions [102].
现在大部分的推荐系统都是处理单一规则打分,比如给电影和图书打分。然而,在一些应用,比如餐馆推荐,将多规则打分结合到推荐方法中是非常重要的。比如,许多餐厅导航,像Zagat’s Guide,提供三个餐厅打分规则:事物、装修、服务。尽管还没有推荐系统的文献检测过多规则打分,他们已经在运筹学界被广泛研究很久了。多规则优化问题的典型解法包括找到(a)Pareto最优解(b)采用多准则的线性组合,将问题简化为单准则优化问题(c)优化最重要的准则,并将其他准则转换为约束条件(d)每次连续优化一个准则,将最优解转换为约束条件,并对其他准则重复此过程。后一种方法的一个例子是连续让步法。
To illustrate how some of these methods can be used in recommender systems, consider the application of approach (c) to the problem of recommending restaurants r to user c based on the user’s criteria of food quality ![]() , décor
, décor ![]() , and service
, and service ![]() . We can take food quality
. We can take food quality ![]() to be the primary criterion and use others as constraints, i.e., we want to find restaurants r that maximize
to be the primary criterion and use others as constraints, i.e., we want to find restaurants r that maximize ![]() , subject to the constraints
, subject to the constraints ![]() and
and ![]() , where
, where ![]() and
and ![]() are minimal ratings for décor and service (e.g., user c will not go to any restaurant having décor and service ratings below 10, out of possible 30, regardless of the quality of food there). This problem is complicated by the fact that we usually will not have the user’s decor
are minimal ratings for décor and service (e.g., user c will not go to any restaurant having décor and service ratings below 10, out of possible 30, regardless of the quality of food there). This problem is complicated by the fact that we usually will not have the user’s decor ![]() and service
and service ![]() ratings for all the restaurants. Then the task of a recommender system is to estimate unknown ratings
ratings for all the restaurants. Then the task of a recommender system is to estimate unknown ratings ![]() and
and ![]() , e.g., using the rating estimation methods described in Section 2, and find all the restaurants r satisfying constraints
, e.g., using the rating estimation methods described in Section 2, and find all the restaurants r satisfying constraints ![]() and
and ![]() . Once we find all the restaurants satisfying the constraints with these estimated ratings, we can use those restaurants in search for the maximum of
. Once we find all the restaurants satisfying the constraints with these estimated ratings, we can use those restaurants in search for the maximum of ![]() . However, as with décor and service ratings, we might not have the user’s food ratings
. However, as with décor and service ratings, we might not have the user’s food ratings ![]() for all such restaurants and, thus, will also need to use rating estimation procedure for
for all such restaurants and, thus, will also need to use rating estimation procedure for ![]() before making any recommendations.
before making any recommendations.
为了说明怎样将这些方法应用到推荐系统里,考虑使用方法c的应用解决推荐餐馆的问题:给用户c推荐餐馆r,并且基于用户对食物![]() 、装修
、装修![]() 、服务
、服务![]() 的规则。我们可以把食物质量
的规则。我们可以把食物质量![]() 当作基本规则,并且使用其他的当作约束,即:我们想找到餐厅r使得
当作基本规则,并且使用其他的当作约束,即:我们想找到餐厅r使得![]() 最大,并服从约束
最大,并服从约束![]() 和
和![]() ,
,![]() 和
和![]() 都是装修和服务的最小打分值(比如:用户c超过30%的可能性不会去装修和服务打分低于10的,不管食物如何)。这个问题事实上很复杂,因为我们通常没有用户对所有餐厅的装修
都是装修和服务的最小打分值(比如:用户c超过30%的可能性不会去装修和服务打分低于10的,不管食物如何)。这个问题事实上很复杂,因为我们通常没有用户对所有餐厅的装修![]() 和服务
和服务![]() 打分。推荐系统的任务是预测一个未知的
打分。推荐系统的任务是预测一个未知的 ![]() 和
和![]() ,例如:使用第2章里面提到的打分预测方法,找到所有满足约束
,例如:使用第2章里面提到的打分预测方法,找到所有满足约束 ![]() 和
和![]() 。一旦我们找到符合约束餐厅和他们的预测打分,我们可以找到最大的
。一旦我们找到符合约束餐厅和他们的预测打分,我们可以找到最大的![]() 。然而,像装修和服务打分那样,我们也没有用户对所有餐厅的食物打分
。然而,像装修和服务打分那样,我们也没有用户对所有餐厅的食物打分![]() ,因此我们也需要在做推荐前用打分预测去产生
,因此我们也需要在做推荐前用打分预测去产生![]() 。
。
We believe that the problem of finding Pareto-optimal solution set and the iterative method of consecutive single criterion optimizations for multi-criteria recommendation problems mentioned above should also constitute interesting and challenging problems.
我们相信,对于上述多准则推荐问题,寻找Pareto最优解集的问题以及连续单准则优化的迭代方法也应该是一个有趣且具有挑战性的问题。
3.5. Non-intrusiveness 无打扰
Many recommender systems are intrusive in the sense that they require explicit feedback from the user and often at a significant level of user involvement. For example, before recommending any newsgroup articles, the system needs to acquire ratings of previously read articles, and often many of them. Since it is impractical to elicit many ratings of these articles from the user, some recommender systems use non-intrusive rating determination methods where certain proxies are used to estimate real ratings. For example, the amount of time a user spends reading a newsgroup article can serve as a proxy of the article’s rating given by this user. Some nonintrusive methods of getting user feedback are presented in [18, 53, 66, 74, 94]. However, nonintrusive ratings (such as time spent reading an article) are often inaccurate and cannot fully replace explicit ratings provided by the user. Therefore, the problem of minimizing intrusiveness while maintaining certain levels of accuracy of recommendations needs to be addressed by the recommender systems researchers.
许多推荐系统都可以感觉到它在打扰你,他们需要从用户得到显示的反馈,经常是重要的用户参与。举个例子,在推荐新闻文章前,系统需要获取之前读过的文章的打分,而且一般需要很多。因为从用户抽取很多文章打分是不现实的,有些推荐系统用无打扰打分决定方法,其中某些代理被用来估计真实的打分。举个例子,用户阅读新闻文章的时间,可以作为该用户给出的文章评级的代理。文献[18,53,66,74,94]中给出了一些获取无打扰用户反馈方法。然而,无打扰打分(比如读文章的时间)总是不准确的,不能完全代替用户的显示打分。因此,为了维持推荐系统某个级别的准确性,最小打扰的问题还需要被研究解决。
One way to explore the intrusiveness problem is to determine an optimal number of ratings the system should ask from a new user. For example, before recommending any movies, MovieLens.org first asks the user to rate a predefined number of movies (e.g., 20). This request incurs certain costs on the end-user that can be modeled in various ways, the simplest model being a fixed-cost model (i.e., the cost of rating each movie is C and the cost of rating n movies is C⋅n). Then the intrusiveness problem can be formulated as an optimization problem that tries to find an optimal number of initial rating requests n as follows. Each additional rating supplied by the user increases the accuracy of recommendations (or any other effectiveness measure) and,
therefore, results in certain benefits for the user. One interesting intrusiveness-related research problem would be to develop formal models for defining and measuring benefit B(n) of supplying n initial ratings in terms of the increased accuracy of predictions based on these ratings. Once it is known how to measure benefits B(n) (e.g., by measuring the predictive accuracy of a recommender system), we need to determine an optimal number of initial ratings n that maximizes expression B(n) – C⋅n. Clearly, optimal value of n is reached when marginal benefits are equal to marginal costs, i.e., when ΔB(n) = C. The optimal solution should exist under the assumption that B(n) is a monotonically increasing function in n with decreasing marginal benefits ΔB(n) that asymptotically converge to zero.
一个探索无打扰问题的方法,就是确定系统询问新用户去打分的最佳次数。举个例子,在推荐电影前,MovieLens.org会先让用户去打分一些电影(比如20个)。这个请求会给最终用户带来某些成本,最终用户可以用多种方式建模,最简单的模型是固定成本模型(即,给每个电影打分花费成本C,给n个电影打分花费成本C·n)。然后,无打扰问题可以被定义为找到最开始给n个打分的优化问题。用户每增加一个打分,就增加了推荐的准确率(或者其他一些有效测量)并且对给用户的结果有某些好处。一个有趣的无打扰相关研究问题,就是提升规范模型,定义和测量效益 B(n),n为初始打分个数,看看基于这些打分能提升多少准确率。一旦知道怎样测量效益 B(n)(比如:测量推荐系统预测的准确率),我们需要确定最佳的最初打分n到底是几个,使得表达式B(n) – C⋅n最大。需要明确,最佳值n是边际效益等于边际成本时得到的,即ΔB(n) = C。最佳结果需要假设B(n)对n是单调增加的函数,边际效益ΔB(n)渐进收敛于0。
(PS:边际收益与边际成本的比较。卖主在市场上多投入一单位产量所得到的追加收入与所支付的追加成本的比较。当这种追加收入大于追加成本时,卖主会扩大生产; 当这种追加收入等于追加成本时,卖主可以得到最大利润,即达到最大利润点; 如果再扩大生产,追加收入就有可能小于追加成本,卖主会亏损。为此,边际效益概念对卖主来说至关重要。卖主追求最大利润点而决不乐于亏损。)(这是一个经济学概念……不要问我为什么……)
Another interesting research opportunity lies in developing marginal cost models that are more advanced than the fixed-cost model described above and that can potentially include cost/benefit analysis of using both implicit and explicit ratings in a recommender system.
另一个有趣的研究机会是开发比上面描述的固定成本模型更先进的边际成本模型,它可能包括在推荐系统中使用隐式和显式评级的成本/效益分析。
Finally, the issue of incrementally selecting good training data for modeling purposes is the problem of active learning, which is a fairly well-studied area in the machine learning literature, and numerous approaches have been proposed to addressing this problem [23, 24, 36, 58]. We believe that applying active learning methods to address the non-intrusiveness issue constitutes another interesting research opportunity.
最后,增量选择用于建模的良好训练数据的问题是主动学习问题,这是机器学习文献中研究得相当深入的一个领域,已经提出了许多方法来解决这个问题。我们认为运用主动学习的方法来解决无打扰问题是另一个有趣的研究机会。
3.6. Flexibility 灵活性
Most of the recommendation methods are inflexible in the sense that they are “hard-wired” into the systems by the vendors and therefore support only a predefined and fixed set of recommendations. Therefore, the end-user cannot customize recommendations according to his or her needs in real time. This problem has been identified in [2], and Recommendation Query Language (RQL) has been proposed to address it [2]. RQL is an SQL-like language for expressing flexible user-specified recommendation requests. For example, the request “recommend to each user from New York the best three movies that are longer than two hours” can be expressed in RQL as:
大部分推荐系统方法都可以感觉到是非灵活的,他们被供应商“硬连接”进系统,因此只能提供预定义的固定的一套推荐。因此,终端用户不能根据他真实需要定制推荐系统。这个问题在文献2中被提出,RQL被提出来解决这个问题。RQL很像SQL,来灵活的表达用户特定的推荐需求。举个例子,需求为“给每个纽约用户推荐三部超过2小时的最佳电影”,可以给RQL表达为:

Also, most of the recommender systems recommend only individual items to individual users and do not deal with aggregation. However, it is important to be able to provide aggregated recommendations in a number of applications, such as recommend brands or categories of products to certain segments of users. For example, a travel-related recommender system may want to recommend vacations in Florida (category of products) to the undergraduate students from the Northeast (user segment) during the spring break. One way to support aggregated recommendations is by utilizing the OLAP-based approach [19] to multidimensional recommendations. OLAP-based systems naturally support aggregation hierarchies, and the initial approaches to deploying OLAP-based methods in recommender systems are presented in [2, 3]. However, more work is required to develop a more comprehensive understanding of how to use the OLAP approach in recommender systems, and this constitutes an interesting and challenging research problem.
大部分推荐系统只能推荐给个别用户推荐个别物品,不能处理群体。然而,提供群体推荐对于很多应用来说很重要,比如推荐某些品牌或者种类的产品给某些群体用户。举个例子,在旅游相关推荐系统里,可能会给东北的大学生(用户群体)在春假的时候推荐去弗洛里达度假(某个种类的产品)。一种支持群体推荐的方法是,使用基于OLAP的方法去多维度推荐。基于OLAP的系统一般支持群体层次,部署在基于OLAP系统的初级方法在文献2,3中提到。然而,提升对于“如何在推荐系统使用OLAP方法”的全面理解还需要做很多工作,这个将会是一个有趣且有挑战的研究问题。
3.7. Effectiveness of recommendations 推荐系统的有效性
The problem of developing good metrics to measure effectiveness of recommendations has been extensively addressed in the recommender systems literature. Some examples of this work include [41, 44, 69, 107]. In most of the recommender systems literature, the performance evaluation of recommendation algorithms is usually done in terms of the coverage and accuracy
metrics. Coverage measures the percentage of items for which a recommender system is capable of making predictions [41]. Accuracy measures can be either statistical or decision-support [41]. Statistical accuracy metrics mainly compare the estimated ratings (e.g., as defined in (16)) against the actual ratings R in the User×Item matrix, and include Mean Absolute Error (MAE),
root mean squared error, and correlation between predictions and ratings. Decision-support measures determine how well a recommender system can make predictions of high-relevance items (i.e., items that would be rated highly by the user). They include classical IR measures of precision (the percentage of truly “high” ratings among those that were predicted to be “high” by the recommender system), recall (the percentage of correctly predicted “high” ratings among all the ratings known to be “high”), F-measure (a harmonic mean of precision and recall), and Receiver Operating Characteristic (ROC) measure demonstrating the tradeoff between true positive and false positive rates in recommender systems [41].
提升测量推荐系统的有效性是一个在推荐系统文献中被广泛解决的问题。文献[41, 44, 69, 107]中有很多关于它的例子。大部分推荐系统文献,对于推荐算法的表现评价都是依照覆盖率和准确度量。覆盖率测量的是推荐系统能够预测物品占的应推荐物品的百分比。准确性测量可以是统计的,也可以是决策支持的。统计准确率度量主要是比较预测打分和User×Item矩阵中的实际打分R,包括平均绝对误差MAE,均方根误差,预测和打分的相关度。决策支持测量是推荐系统可以预测高相关度的物品的程度(即,物品是否被用户打高分)。他们包括经典IR测试:精确率(预测对的真正高分的占预测高分的比例),召回率(正确预测的高分占所有已知高分的比例),F测试(精确率和召回率的调和平均),ROC测量,展示了推荐系统中真正例和假正例的权衡。
(PS:
TP:True Positive,被判定为正样本,事实上也是正样本。
FN:False Negative,被判定为负样本,但事实上是正样本。
FP:False Positive,被判定为正样本,但事实上是负样本。
TN:True Negative,被判定为负样本,事实上也是负样本。
精确率 precision=TP/(TP+FP) 预测为正且为本身正/所有预测为正
召回率 recall=TP/(TP+FN) 预测为正且为本身正/真正的正样本
F1 score= 2*precision*recall/(precision+recall)
)
Although popular, these empirical evaluation measures have certain limitations. One limitation is that these measures are typically performed on test data that the users chose to rate. However, items that users choose to rate are likely to constitute a skewed sample, e.g., users may rate mostly the items that they like. In other words, the empirical evaluation results typically
only show how accurate the system is on items the user decided to rate, whereas the ability of the system to properly evaluate a random item (which it should be able to do during its normal reallife use) is not tested. Understandably, it is expensive and time-consuming to conduct controlled experiments with users in the recommender systems settings, therefore, the experiments that test recommendation quality on an unbiased random sample are rare, e.g., [69]. However, the highquality experiments are necessary in order to truly understand the benefits and limitations of the proposed recommendation techniques.
尽管很流行,这些实验测量方法也有一些局限性。一个限制就是,这些测量只能代表用户选择的测试数据上表现好坏。然而,用户选择打分的物品可能构成一个倾斜的样本,比如用户大部分给自己喜欢的打分。换句话说,实验预测结果只能表明系统在用户决定打分的物品上准确率有多好,然而,系统预测一个随机物品(它应该在现实生活中能够正常使用)的能力没有被测试到。可以理解,在推荐系统设置中对用户进行受控实验既昂贵又费时,因此,在无偏随机样本上检验推荐质量的实验并不多见,比如文献69。然而,为了真正了解所建议的推荐技术的优点和局限性,需要进行高质量的实验。
In addition, although crucial for measuring accuracy of recommendations, the technical measures mentioned earlier often do not capture adequately “usefulness” and “quality” of recommendations. For example, as [107] observe for a supermarket application, recommending obvious items (such as milk or bread) that the consumer will buy anyway will produce high accuracy rates; however, it will not be very helpful to the consumer. Therefore, it is also important to develop economics-oriented measures that capture the business value of recommendations, such as return on investments (ROI) and customer lifetime value (LTV) measures [32, 88, 95]. Developing and studying the measures that would remedy the limitations described in this section constitutes an interesting and important research topic.
此外,尽管测量推荐系统的准确率十分重要,前面提到的技术措施往往没有充分体现建议的“有用性”和“质量”。举个例子,像文献107说到,一个超市应用,推荐显而易见的物品(比如牛奶或者面包)给用户去买会有很高的准确率,但是对于用户来说没什么用。因此,提升商业推荐系统的经济方面的测量是很重要的,比如投资报酬率(ROI)和顾客终身价值(LTV)测量。提升和研究将弥补本章所述限制的方法是一个有趣和重要的研究课题
3.8. Other Extensions 其它扩展
Other important research issues that have been explored in recommender systems literature include explainability [12, 42], trustworthiness [28], scalability [4, 39, 91, 93], and privacy [82, 93] issues of recommender systems. However, we will not review this work and will not discuss research opportunities in these areas because of the space limitation.
推荐系统文献中还探索了其他重要的研究问题,包括可解释性、可信度、可伸缩性和推荐系统的隐私问题。但是,由于篇幅有限,我们将不回顾这项工作,也不讨论这些领域的研究机会。
4. Conclusions 总结
Recommender systems made a significant progress over the last decade when numerous contentbased, collaborative and hybrid methods were proposed and several “industrial-strength” systems have been developed. However, despite all these advances, the current generation of recommender systems surveyed in this paper still requires further improvements to make recommendation methods more effective in a broader range of applications. In this paper, we reviewed various limitations of the current recommendation methods and discussed possible extensions that can provide better recommendation capabilities. These extensions include, among others, the improved modeling of users and items, incorporation of the contextual information into the recommendation process, support for multi-criteria ratings, and provision of a more flexible and less intrusive recommendation process. We hope that the issues presented in this paper would advance the discussion in the recommender systems community about the next generation of recommendation technologies.
在过去十年中,推荐系统取得了重大进展,提出了许多基于内容、协同和混合的方法,并开发了几个“工业级”的系统。然而,尽管有这些进步,本文所调查的当代推荐系统仍然需要进一步的改进,使得推荐方法在更广泛的应用范围内更有效。在本文中,我们回顾了当前推荐方法的各种局限性,并讨论了可以提供更好推荐功能的可能扩展。这些扩展包括:用户和物品的改进模型、将上下文信息结合到推荐过程中、支持多规则打分以及提供更灵活、更少打扰的推荐过程。我们希望本文提出的问题能够促进推荐系统界对下一代推荐技术的讨论。
References 参考文献
1. Adomavicius, G. and A. Tuzhilin. Expert-driven validation of rule-based user models in personalization applications. Data Mining and Knowledge Discovery, 5(1/2):33-58, 2001a.
2. Adomavicius, G. and A. Tuzhilin. Multidimensional recommender systems: a data warehousing approach. In Proc. of the 2nd Intl. Workshop on Electronic Commerce (WELCOM’01). Lecture Notes in Computer Science, vol. 2232, Springer, 2001b.
3. Adomavicius, G., R. Sankaranarayanan, S. Sen, and A. Tuzhilin. Incorporating Contextual Information in Recommender Systems Using a Multidimensional Approach. ACM Transactions on Information Systems, 23(1), January 2005.
4. Aggarwal, C. C., J. L. Wolf, K-L. Wu, and P. S. Yu. Horting hatches an egg: A new graphtheoretic approach to collaborative filtering. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August 1999.
5. Ansari, A., S. Essegaier, and R. Kohli. Internet recommendations systems. Journal of Marketing Research, pages 363-375, August 2000.
6. Armstrong, J. S. Principles of Forecasting – A Handbook for Researchers and Practitioners, Kluwer Academic Publishers, 2001.
7. Baeza-Yates, R., B. Ribeiro-Neto. Modern Information Retrieval. Addison-Wesley, 1999.
8. Balabanovic, M. and Y. Shoham. Fab: Content-based, collaborative recommendation. Communications of the ACM, 40(3):66-72, 1997.
9. Basu, C., H. Hirsh, and W. Cohen. Recommendation as classification: Using social and content-based information in recommendation. In Recommender Systems. Papers from 1998 Workshop. Technical Report WS-98-08. AAAI Press, 1998.
10. Belkin, N. and B. Croft. Information filtering and information retrieval. Communications of the ACM, 35(12):29-37, 1992.
11. Billsus, D. and M. Pazzani. Learning collaborative information filters. In International Conference on Machine Learning, Morgan Kaufmann Publishers, 1998.
12. Billsus, D. and M. Pazzani. A Personal News Agent That Talks, Learns and Explains. In Proceedings of the Third Annual Conference on Autonomous Agents, 1999.
13. Billsus, D. and M. Pazzani. User modeling for adaptive news access. User Modeling and User-Adapted Interaction, 10(2-3):147-180, 2000.
14. Billsus, D., C. A. Brunk, C. Evans, B. Gladish, and M. Pazzani. Adaptive interfaces for ubiquitous web access. Commnications of the ACM, 45(5):34-38, 2002.
15. Breese, J. S., D. Heckerman, and C. Kadie. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, July 1998.
16. Buhmann, M. D. Approximation and interpolation with radial functions. In Multivariate Approximation and Applications. Eds. N. Dyn, D. Leviatan, D. Levin, and A. Pinkus. Cambridge University Press, 2001.
17. Burke, R. Knowledge-based recommender systems. In A. Kent (ed.), Encyclopedia of Library and Information Systems. Volume 69, Supplement 32. Marcel Dekker, 2000.
18. Caglayan, A., M. Snorrason, J. Jacoby, J. Mazzu, R. Jones, and K. Kumar. Learn Sesame – a learning agent engine. Applied Artificial Intelligence, 11:393-412, 1997.
19. Chaudury, S. and U. Dayal. An overview of data warehousing and OLAP technology. ACM SIGMOD Record, 26(1):65-74, 1997.
20. Chien, Y-H. and E. I. George. A bayesian model for collaborative filtering. In Proc. of the 7th International Workshop on Artificial Intelligence and Statistics, 1999.
21. Claypool, M., A. Gokhale, T. Miranda, P. Murnikov, D. Netes, and M. Sartin. Combining content-based and collaborative filters in an online newspaper. In ACM SIGIR'99. Workshop on Recommender Systems: Algorithms and Evaluation, August 1999.
22. Cohen, W. W., R. E. Schapire, and Y. Singer. Learning to order things. Journal of Articial Intelligence Research, 10:243-270, 1999.
23. Cohn, D., L. Atlas, and R. Ladner. Improving Generalization with Active Learning. Machine Learning, 15(2):201-221, 1994.
24. Cohn, D., Z. Ghahramani, and M. Jordan. Active Learning with Statistical Models. Journal of Artificial Intelligence Research, 4:129-145, 1996.
25. Condliff, M., D. Lewis, D. Madigan, and C. Posse. Bayesian mixed-effects models for recommender systems. In ACM SIGIR'99 Workshop on Recommender Systems: Algorithms and Evaluation, August 1999.
26. Cortes, C., K. Fisher, D. Pregibon, A. Rogers, and F. Smith. Hancock: a language for extracting signatures from data streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2000.
27. Delgado, J. and N. Ishii. Memory-based weighted-majority prediction for recommender systems. In ACM SIGIR'99 Workshop on Recommender Systems: Algorithms and Evaluation, 1999.
28. Dellarocas, C. The Digitization of Word of Mouth: Promise and Challenges of Online Feedback Mechanisms. Management Science, 49(10):1407-1424, 2003.
29. Deshpande, M. and G. Karypis. Item-Based Top-N Recommendation Algorithms. ACM Transactions on Information Systems, 22(1):143-177, 2004.
30. Duchon, J. Splines minimizing rotation-invariate semi-norms in Sobolev spaces. In Constructive Theory of Functions of Several Variables, ed. W. Schempp & Zeller, pp. 85-100, Springer, 1979.
31. Duda, R. O., P. E. Hart, and D. G. Stork. Pattern Classification, John Wiley & Sons, 2001.
32. Dwyer, F. R. Customer Lifetime Valuation to Support Marketing Decision Making. Journal of Direct Marketing, Vol 3(4), 1989.
33. Ehrgott, M. Multicriteria Optimization. Springer Verlag, September 2000.
34. Fawcett, T., and F. Provost. Combining data mining and machine learning for efficient user profiling. In Proceedings of the Second International Conference On Knowledge Discovery and Data Mining (KDD-96), 1996.
35. Freund, Y., R. Iyer, R.E. Schapire, and Y. Singer. An efficient boosting algorithm for combining preferences. In Proc. of the 15th Intl. Conference on Machine Learning, 1998.
36. Freund, Y., H. S. Seung, E. Shamir, and N. Tishby. Selective sampling using the query by committee algorithm. Machine Learning, 28(2-3):133-168, 1997.
37. Getoor, L. and M. Sahami. Using probabilistic relational models for collaborative filtering. In Workshop on Web Usage Analysis and User Profiling (WEBKDD'99), August 1999.
38. Goldberg, D., D. Nichols, B. M. Oki, and D. Terry. Using collaborative filtering to weave an information tapestry. Communications of the ACM, 35(12):61-70, 1992.
39. Goldberg, K., T. Roeder, D. Gupta, and C. Perkins. Eigentaste: A constant time collaborative filtering algorithm. Information Retrieval Journal, 4(2):133-151, July 2001.
40. Good, N., J. B. Schafer, J. A. Konstan, A. Borchers, B. Sarwar, J. L. Herlocker, and J. Riedl. Combining Collaborative Filtering with Personal Agents for Better Recommendations. In Proceedings of the Conference of the American Association of
Artificial Intelligence (AAAI-99), pp. 439-446, Orlando, Florida, July 1999,
41. Herlocker, J. L., J. A. Konstan, A. Borchers, and J. Riedl. An algorithmic framework for performing collaborative filtering. In Proc. of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’99). 1999.
42. Herlocker, J. L., J. A. Konstan, and J. Riedl. Explaining collaborative filtering recommendations. In Proceedings of the ACM Conference on Computer Supported Cooperative Work, 2000.
43. Herlocker, J. L. and J. A. Konstan. Content-Independent Task-Focused Recommendation. IEEE Internet Computing, 5(6):40-47, 2001.
44. Herlocker, J. L., J. A. Konstan, L. G. Terveen, and J. T. Riedl. Evaluating Collaborative Filtering Recommender Systems. ACM Transactions on Information Systems, 22(1):5-53, 2004.
45. Hill, W., L. Stead, M. Rosenstein, and G. Furnas. Recommending and evaluating choices in a virtual community of use. In Proceedings of CHI’95.
46. Hofmann, T. Probabilistic Latent Semantic Analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, pp. 289-296, 1999.
47. Hofmann, T. Collaborative Filtering via Gaussian Probabilistic Latent Semantic Analysis. In Proc. of the 26th Annual International ACM SIGIR Conference, Toronto, Canada, 2003.
48. Hofmann, T. Latent Semantic Models for Collaborative Filtering. ACM Transactions on Information Systems, 22(1):89-115, 2004.
49. Huang, Z., H. Chen, and D. Zeng. Applying Associative Retrieval Techniques to Alleviate the Sparsity Problem in Collaborative Filtering. ACM Transactions on Information Systems, 22(1):116-142, 2004.
50. Hull, D. A. The TREC-7 Filtering Track: Description and Analysis. In Proceedings of the 7th Text Retrieval Conference (TREC-7), pp., 1999.
51. Jin, R., L. Si, and C. Zhai. Preference-based Graphic Models for Collaborative Filtering. In Proceedings of the 19th Conference on Uncertainty in Artificial Intelligence (UAI 2003), Acapulco, Mexico, August 2003a.
52. Jin, R., L. Si, C. Zhai, and J. Callan. Collaborative Filtering with Decoupled Models for Preferences and Ratings. In Proc. of the 12th International Conference on Information and Knowledge Management (CIKM 2003), New Orleans, LA, November 2003b.
53. Konstan, J. A., B. N. Miller, D. Maltz, J. L. Herlocker, L. R. Gordon, and J. Riedl. GroupLens: Applying collaborative filtering to Usenet news. Communications of the ACM, 40(3):77-87, 1997.
54. Konstan, J. A., J. Riedl, A. Borchers, and J. L. Herlocker. Recommender systems: a GroupLens perspective. In Recommender Systems. Papers from 1998 Workshop. Technical Report WS-98-08. AAAI Press, 1998.
55. Kumar, R., P. Raghavan, S. Rajagopalan, and A. Tomkins. Recommendation Systems: A Probabilistic Analysis. Journal of Computer and System Sciences, 63(1):42-61, 2001.
56. Lang, K. Newsweeder: Learning to filter netnews. In Proceedings of the 12th International Conference on Machine Learning, 1995.
57. Lee, W. S. Collaborative learning for recommender systems. In Proccedings of the International Conference on Machine Learning, 2001.
58. Lewis, D. and J. Catlett. Heterogeneous uncertainty sampling for supervised learning. In Proceedings of 11th International Conference on Machine Learning, pp. 148-156, 1994.
59. Li, J. and O. R. Zaïane. Combining Usage, Content and Structure Data to Improve Web Site Recommendation. In Proceedings of the 5th International Conference on Electronic Commerce and Web Technologies (EC-Web 04), pp. 305-315, Zaragoza, Spain, 2004.
60. Lilien, G. L., P. Kotler, K. S. Moorthy. Marketing Models, Prentice Hall, 1992.
61. Linden, G., B. Smith, and J. York. Amazon.com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Computing, Jan.-Feb. 2003.
62. Littlestone, N. and M. Warmuth. The Weighted Majority Algorithm. Information and Computation, 108(2):212-261, 1994.
63. Mannila, H., H. Toivonen, and A. I. Verkamo. Discovering Frequent Episodes in Sequences. In Proceedings of the First International Conference on Knowledge Discovery and Data Mining (KDD-95), 1995.
64. Marlin, B. Modeling User Rating Profiles for Collaborative Filtering. In Proceedings of the 17th Annual Conference on Neural Information Processing Systems (NIPS’03), 2003.
65. Melville, P., R. J. Mooney, and R. Nagarajan. Content-Boosted Collaborative Filtering for Improved Recommendations. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, Canada, 2002.
66. Middleton, S. E., N. R. Shadbolt, and D. C. de Roure. Ontological User Profiling in Recommender Systems. ACM Transactions on Information Systems, 22(1):54-88, 2004.
67. Miller, B. N., I. Albert, S. K. Lam, J. A. Konstan, and J. Riedl. MovieLens Unplugged: Experiences with an Occasionally Connected Recommender System. In Proceedings of the International Conference on Intelligent User Interfaces, Miami, Florida, 2003.
68. Mobasher, B., H. Dai, T. Luo, and M. Nakagawa. Discovery and Evaluation of Aggregate Usage Profiles for Web Personalization. Data Mining and Knowledge Discovery, 6(1):61- 82, 2002.
69. Mooney, R. J. and L. Roy Content-based book recommending using learning for text categorization. In ACM SIGIR'99. Workshop on Recommender Systems: Algorithms and Evaluation, 1999.
70. Mooney, R. J., P. N. Bennett, and L. Roy. Book recommending using text categorization with extracted information. In Recommender Systems. Papers from 1998 Workshop. Technical Report WS-98-08. AAAI Press, 1998.
71. Murthi, B. P. S. and S. Sarkar. The Role of the Management Sciences in Research on Personalization. Management Science, 49(10):1344-1362, 2003.
72. Nakamura, A. and N. Abe. Collaborative filtering using weighted majority prediction algorithms. In Proc. of the 15th International Conference on Machine Learning, 1998.
73. Nurnberger, G. Approximation by Spline Functions. Springer-Verlag, 1989.
74. Oard, D. W. and J. Kim. Implicit feedback for recommender systems. In Recommender Systems. Papers from 1998 Workshop. Technical Report WS-98-08. AAAI Press, 1998.
75. Pavlov, D. and D. Pennock. A Maximum Entropy Approach To Collaborative Filtering in Dynamic, Sparse, High-Dimensional Domains. In Proceedings of the 16th Annual Conference on Neural Information Processing Systems (NIPS’02), 2002.
76. Pazzani, M. A framework for collaborative, content-based and demographic filtering. Artificial Intelligence Review, pages 393-408, December 1999.
77. Pazzani, M. and D. Billsus. Learning and revising user profiles: The identification of interesting web sites. Machine Learning, 27:313-331, 1997.
78. Peddy, C. C., and D. Armentrout. Building Solutions with Microsoft Commerce Server 2002. Microsoft Press, 2003.
79. Pennock, D. M. and E. Horvitz. Collaborative filtering by personality diagnosis: A hybrid memory- and model-based approach. In IJCAI'99 Workshop: Machine Learning for Information Filtering, August 1999.
80. Popescul, A., L. H. Ungar, D. M. Pennock, and S. Lawrence. Probabilistic Models for Unified Collaborative and Content-Based Recommendation in Sparse-Data Environments. In Proc. of the 17th Conf. on Uncertainty in Artificial Intelligence, Seattle, WA, 2001.
81. Powell, M. J. D. Approximation Theory and Methods, Cambridge University Press, 1981.
82. Ramakrishnan, N., B. J. Keller, B. J. Mirza, A. Y. Grama, and G. Karypis. Privacy Risks in Recommender Systems. IEEE Internet Computing, 5(6):54-62, 2001.
83. Rashid, A. M., I. Albert, D. Cosley, S. K. Lam, S. M. McNee, J. A. Konstan, and J. Riedl. Getting to Know You: Learning New User Preferences in Recommender Systems. In Proceedings of the International Conference on Intelligent User Interfaces, 2002.
84. Robertson S. and S. Walker. Threshold Setting in Adaptive Filtering. Journal of Documentation, 56:312-331, 2000.
85. Rocchio, J. J. Relevance Feedback in Information Retrieval. SMART Retrieval System – Experiments in Automatic Document Processing, G. Salton ed., PrenticeHall, Ch. 14, 1971.
86. Resnick, P., N. Iakovou, M. Sushak, P. Bergstrom, and J. Riedl. GroupLens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 Computer Supported Cooperative Work Conference, 1994.
87. Rich, E. User Modeling via Stereotypes. Cognitive Science, 3(4):329-354, 1979.
88. Rosset, S., E. Neumann, U. Eick, N. Vatnik, and Y. Idan. Customer Lifetime Value Modeling and Its Use for Customer Retention Planning. In Proc. of the 8th ACM SIGKDD International Conf. on Knowledge Discovery and Data Mining (KDD-2002), July 2002.
89. Salton, G. Automatic Text Processing. Addison-Wesley, 1989.
90. Sarwar B., G. Karypis, J. Konstan, and J. Riedl. Application of dimensionality reduction in recommender systems – a case study. In Proc. of the ACM WebKDD Workshop, 2000.
91. Sarwar, B., G. Karypis, J. Konstan, and J. Riedl. Item-based Collaborative Filtering Recommendation Algorithms. In Proc. of the 10th International WWW Conference, 2001.
92. Schaback, R. and H. Wendland. Characterization and construction of radial basis functions. In Multivariate Approximation and Applications. Eds. N. Dyn, D. Leviatan, D. Levin and A. Pinkus. Cambridge University Press, 2001.
93. Schafer, J. B., J. A. Konstan, and J. Riedl. E-commerce recommendation applications. Data Mining and Knowledge Discovery, 5(1/2):115-153, 2001.
94. Schein, A. I., A. Popescul, L. H. Ungar, and D. M. Pennock. Methods and metrics for cold-start recommendations. In Proc. of the 25th Annual Intl. ACM SIGIR Conf., 2002.
95. Schmittlein, D. C., D. G. Morrison, and R. Colombo. Counting Your Customers: Who are they and what will they do next? Management Science, Vol. 33(1), 1987.
96. Shani, G., R. Brafman, and D. Heckerman. An MDP-based recommender system. In Proc. of Eighteenth Conference on Uncertainty in Artificial Intelligence, August 2002.
97. Shardanand, U. and P. Maes. Social information filtering: Algorithms for automating ‘word of mouth’. In Proc. of the Conf. on Human Factors in Computing Systems, 1995.
98. Sheth, B. and Maes P. Evolving agents for personalized information filtering. In Proceedings of the 9th IEEE Conference on Artificial Intelligence for Applications, 1993.
99. Si, L. and R. Jin. Flexible Mixture Model for Collaborative Filtering. In Proceedings of the 20th International Conference on Machine Learning, Washington, D.C., August 2003.
100. Soboroff, I. and C. Nicholas. Combining content and collaboration in text filtering. In IJCAI'99 Workshop: Machine Learning for Information Filtering, August 1999.
101. Somlo, G. and A. Howe. Adaptive Lightweight Text Filtering. In Proceedings of the 4th International Symposium on Intelligent Data Analysis, Lisbon, Portugal, September 2001.
102. Statnikov, R. B. and J. B. Matusov. Multicriteria Optimization and Engineering. Chapman & Hall, 1995.
103. Terveen, L., W. Hill, B. Amento, D. McDonald, and J. Creter. PHOAKS: A system for sharing recommendations. Communications of the ACM, 40(3):59-62, 1997.
104. Tran, T. and R. Cohen. Hybrid Recommender Systems for Electronic Commerce. In Knowledge-Based Electronic Markets, Papers from the AAAI Workshop, Technical Report WS-00-04, AAAI Press, 2000.
105. Ungar, L. H., and D. P. Foster. Clustering methods for collaborative filtering. In Recommender Systems. Papers from 1998 Workshop. Technical Report WS-98-08. AAAI Press, 1998.
106. Wade, W. A grocery cart that holds bread, butter and preferences. NY Times, Jan. 16, 2003.
107. Yang, Y. and B. Padmanabhan. On Evaluating Online Personalization, in Proceedings of the Workshop on Information Technology and Systems, pp. 35-41, December 2001.
108. Yu, K., X. Xu, J. Tao, M. Ester, and H.-P. Kriegel. Instance Selection Techniques for Memory-Based Collaborative Filtering. In Proceedings of Second SIAM International Conference on Data Mining (SDM’02), 2002.
109. Yu, K., A. Schwaighofer, V. Tresp, X. Xu, and H.-P. Kriegel. Probabilistic Memory-Based Collaborative Filtering. IEEE Transactions on Knowledge and Data Engineering, 16(1):56-69, 2004. 110. Zaïane, O. R., J. Srivastava, M. Spiliopoulou, B. M. Masand (eds.). WEBKDD 2002 – Mining Web Data for Discovering Usage Patterns and Profiles (Lecture Notes in Computer Science 2703), Springer, 2003.
111. Zhang Y. and J. Callan. Maximum Likelihood Estimation for Filtering Thresholds. In Proc. of the 24th Annual International ACM SIGIR Conference, New Orleans, LA, 2001.
112. Zhang, Y, J. Callan, and T. Minka. Novelty and redundancy detection in adaptive filtering. In Proceedings of the 25th Annual International ACM SIGIR Conference, pp. 81-88, 2002. Gediminas Adomavicius received the PhD degree in computer science from New York University in 2002. He is an assistant professor in the Department of Information and Decision Sciences at the Carlson School of Management, University of Minnesota. Dr. Adomavicius’ research focuses on personalization technologies, data mining, and combinatorial auction mechanisms. He has published more than 20 refereed journal and conference papers in these areas. He is a member of the ACM, IEEE, and IEEE Computer Society. Alexander Tuzhilin received Ph.D. in Computer Science from the Courant Institute of Mathematical Sciences, NYU. He is currently an Associate Professor of Information Systems at the Stern School of Business, NYU. His current research interests include knowledge discovery in databases, personalization and CRM technologies. He published widely in leading CS and IS journals and conference proceedings and served on program committees of numerous CS and IS conferences. Dr. Tuzhilin was as a Co-Chair of the Third IEEE International Conference on Data Mining in 2003. He currently serves on the Editorial Boards of the IEEE Transactions on Knowledge and Data Engineering, the Data Mining and Knowledge Discovery Journal, the INFORMS Journal on Computing, and the Electronic Commerce Research Journal.