石杉笔记(1) synchronized、CAS、ConcurrentHashMap、AQS、ReetrantLock、线程相关、内存模型、volatile
BAT 面试官问并发编程相关的问题
连环问: synchronized 实现原理、CAS 无锁化的原理、AQS 是什么、Lock锁、ConcurrentHashMap 的分段加锁的原理、线程池的原理、java内存模型、volatile 说一下、对java并发包有什么了解一连串的问题
1、说说synchronized 关键字的底层原理
在并发编程中存在线程安全问题,主要原因有:
a.存在共享数据
b.多线程共同操作共享数据。关键字synchronized可以保证在同一时刻,只有一个线程可以执行某个方法或某个代码块,同时synchronized可以保证一个线程的变化可见(可见性),即可以代替volatile。
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性
使用synchronized 关键字,在底层编译后的 jvm 指令中, 会有 moitorenter 和 monitorexit 两个指令
monitorenter
// 代码对应的指令
monitorexit

线程2 ,最终加锁成功
2、CAS (compare and set)的理解和底层原理
取值、询问、修改
在底层的硬件级别保证一定是原子的, 同一时间只有一个线程可以执行CAS,先比较再设置,其他的线程的CAS 同时间去执行时会失败
// 会有多个线程进行执行
public class MyObject {
int i = 0;
// 对myObject对象,同一个时间,只有一个线程可以进入这个方法
public synchronized void increment() {
i++;
}
}
// 多个线程同时基于MyObject 这个对象,来执行increment() 方法
MyObject myObject = new MyObject();
myObject.increment();只有一个线程可以成功的对myObject 加锁,可以对他关联的monitor 的计数器 去加 1,加锁,一旦多个线程并发的去进行synchronized 加锁,串行化,效率并不是太高,很多线程,都需要排队去执行
// 会有多个线程进行执行
public class MyObject {
AtomicInteger i = new AtomicInteger();
// 多个线程此时来执行这段代码
// 不需要 synchronized 加锁,也是线程安全的
public void increment() {
i.incrementAndGet();
}
}
// 多个线程同时基于MyObject 这个对象,来执行increment() 方法
MyObject myObject = new MyObject();
myObject.increment();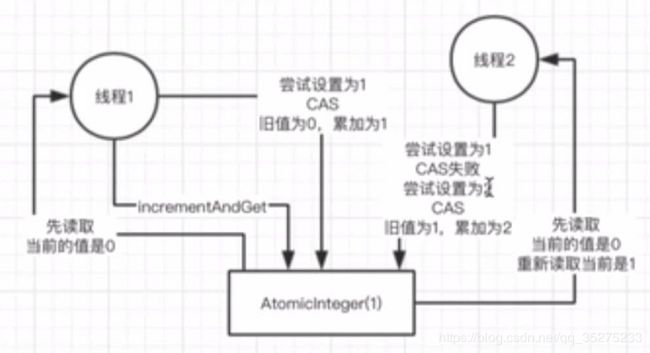
AtomicInteger 底层就是基于Cas实现的
3、ConcurrentHashMap 实现线程安全的底层原理
jdk 1.8 之前,多个数组,分段加锁,一个数组一个锁
jdk 1.8 之后,优化细粒度,一个数组,每个元素进行CAS,如果失败说明有人了,此时synchronized 对数组元素加锁,链表 + 红黑树处理,对数组每个元素加锁
应用实例:
当多个线程读写一个hashMap,没有必要用synchronized 进行加锁,直接使用ConcurrentHashMap
HashMap map = new HashMap();
// 多个线程过来,线程1 要put 的位置是数组[5], 线程 2 要 put 的位置是数组 [21]
synchronized(map) {
map.put(xxx,xxx);
}这样明显不好,数组里有很多的元素,除非是对同一个元素执行 put 操作,此时需要多线程是需要进行同步的
jdk并发包推出了ConcurrentHashMap,默认线程安全性
jdk 1.7 以及之前的版本里,数组进行分段加锁 , 粒度是 数组
[数组1],[数组2],[数组3],每个数组都对应一个锁,分段加锁
jdk 1.8 以及之后,做了一些优化和改进,锁粒度的细化 -- 粒度是 元素
[一个大的数组],数组里每个元素进行 put 操作 ,都是有一个不同的锁,刚开始进行put 的时候,如果两个线程都是在数组[5] 这个位置进行put,这个时候,对数组[5]这个位置进行put的时候,采用的是CAS 的策略
同一个时间,只有一个线程能成功执行这个 CAS,就是说它刚开始先获取一下数组 [5] 这个位置的值, 为null,然后执行 CAS,线程1,比较一下,put 进去我的这条数据,同时间,其他的线程执行CAS,都会失败
分段加锁,通过对数组每个元素执行 CAS 的策略,如果很多线程对数组里不同的元素执行 put,大家是没有关系的,如果其他人失败了,其他人此时会发现说,数组[5]已经有人放了,就需要通过 链表 + 红黑树进行处理,synchronized 数组【5】,加锁,基于链表或者红黑树在这个位置插进去自己的数据
4、对JDK 中的AQS 理解,AQS 的实现原理是什么
AQS - Abstract Queue Synchronizer 抽象队列同步器
ReentrantLock
state 变量 -> CAS -> 失败后进入队列等待 -> 释放锁后唤醒
非公平锁,公平锁
多线程同时访问一个共享数据,synchronized、CAS、ConcurrentHashMap(并发安全的数据结构可以来用)、Lock
ReentrantLock lock = new ReentrantLock(); => 非公平锁
// 多个线程过来,都尝试
lock.lock();
// 相关业务
lock.unlock();

ReentrantLock lock = new ReentrantLock(true); => 公平锁
// 多个线程过来,都尝试
lock.lock();
// 相关业务
lock.unlock();

5、线程池的底层工作原理
系统是不可能无限制的创建线程,会构建一个线程池,有一定数量的线程,让他们执行各种各样的任务,线程执行完任务之后,不要销毁掉自己,继续去等待执行下一个任务
ExecutorService threadPool = Executors.newFixedThreadPool(10);
threadPool.submit(new Callable() {
pubblic void run() {}
}); 提交任务,先看一下线程池里的线程数量是否小于 corePoolSize,也就是 10,如果小于,直接创建一个线程出来执行你的任务
如果执行完你的任务之后,这个线程是不会死掉的,会尝试从一个无界的 LinkedBlockingQueue 里获取新的任务,如果没有新的任务,此时就会阻塞住,等待新的任务的到来
你持续提交任务,上述流程反复执行,只要线程池的线程数量小于corePoolSize,都会直接创建新线程来执行这个任务,执行完了,就会尝试从无界队列里获取任务,直到线程池里有corePoolSize 个线程

其中每个线程会在执行任务时,有其他任务会进行阻塞

6、线程池的核心配置参数,平时应该如何用
newFixedThreadPool(3);
底层的线程实现方法如下所示:
return new ThreadPoolExecutor(nThreads,
nThreads,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()); 代表线程池的类是 ThreadPoolExecutor,可以根据这个构造方法自己构造一个线程池
创建一个线程池就是这个样子的,corePoolSize、maximumPoolSize、keepAliveTime、queue 这几个东西,如果不使用 fixed之类的线程池,自己可以根据以上的构造器实现
corePoolSize: 3
maximumPoolSize: Integer.MAX_VALUE
keepAliveTime:60s
new ArrayBlockingQueue
如果说把queue 做成有界队列,比如说new ArrayBlockingQueue

这个时候假设你的 maximumPoolSize 是比 corePoolSize 大的,此时会继续创建额外的线程放入线程池里,来处理这些任务,然后超过 corePoolSize 数量的线程如果处理完了一个任务,也会尝试从队列里去获取任务来执行
如果额外线程都创建完了去处理任务,队列还是满的,此时还有任务来了怎么办?只能 reject 掉,他有几种 reject 策略,可以传入 RejectedExecutionHandler
(1)AbortPolicy (2)DiscardPolicy (3)DiscardOldestPolicy (4)CallerRunsPolicy (5)自定义
如果后续慢慢的队列里没有任务了,线程空闲了,超过了corePoolSize 的线程会自动释放掉,在 keepAliveTime 之后就会释放
根据上述原理去定制自己的线程池,考虑到 corePoolSize 的数量,队列类型,最大线程数量,拒绝策略,线程释放时间
7、线程池中使用无界阻塞队列会发生什么问题 -- 内存耗尽
面试题: 在远程服务异常的情况下,使用无界阻塞队列,是否会导致内存异常飙升
线程调用远程服务超时,队列会变得原来越大,此时导致内存飙升起来,而且还可能会导致出现OOM,内存溢出

8、线程池的队列满了之后,会发生什么事情
有界队列,可以避免内存溢出
corePoolSize: 10
maximumPoolSize: 200
ArrayBlockingQueue(200)
自定义一个 reject策略,如果线程池无法执行更多的任务了, 此时建议可以把这个任务信息持久化写入磁盘里去,后台专门启动一个线程,后续等待你的线程池的工作负载降低了,可以慢慢的从磁盘里读取之前持久化的任务,重新提交到线程池里去执行
你可以无限制的不停的创建额外的线程出来,一台机器上,有几千个线程,甚至是几万个线程,每个线程都有自己的栈内存,占用一定的内存资源,会导致内存资源耗尽,系统也会崩溃掉
即使内存没有崩溃,会导致你的机器的cpu load,负载特别高
9、线上机器突然宕机,线程池的阻塞队列中的请求怎么办
必然会导致线程池里的积压的任务,实际上来说是会丢失的
解决:
如果说你要提交一个任务到线程池里去,在提交之前,麻烦先在数据库里插入这个任务的信息,更新它的状态:未提交、已提交、已完成。提交成功之后,更新状态为已提交状态
系统重启后,后台线程去扫描数据库里的未提交 和 已提交状态的任务,可以把任务的信息读取出来,更新提交到线程池里去,继续执行
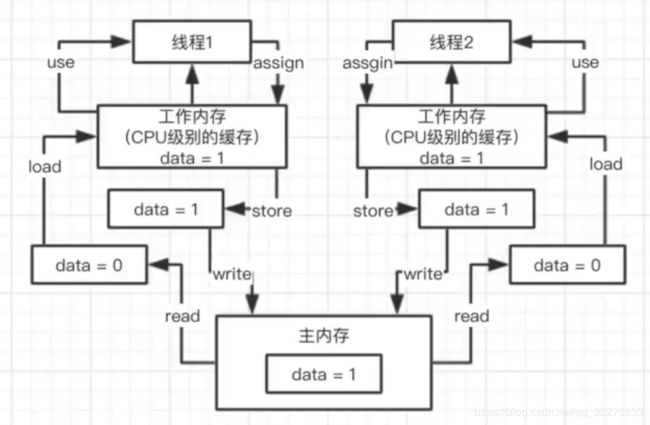
10、java 内存模型
read、load 、 use、assign、store、write
public class HelloWorld {
private int data;
public void increment() {
data ++;
}
}
HelloWorld helloWorld = new HelloWorld(); // 对象其实在堆内存里
// 线程1
new Thread() {
public void run() {
helloworld.increment();
}
}
// 线程2
new Thread() {
public void run() {
helloworld.increment();
}
}前三个阶段 read/load/use

然后开始assign操作 ,两线程并发执行,经过工作内存取得值就是一样的了,
11、java 内存模型中的原子性、有序性、可见性
连环炮: java内存模型 -> 原子性、可见性、有序性 -> volatile (保证可见性、无法保证原子性) -> happen-before / 内存屏障
也就是并发编程过程中,可能会产生的三类问题
(1)可见性
线程2,在执行时每次都重新从工作内存中重新读取data的值,这就是工作内存,对于两个线程都是可见的
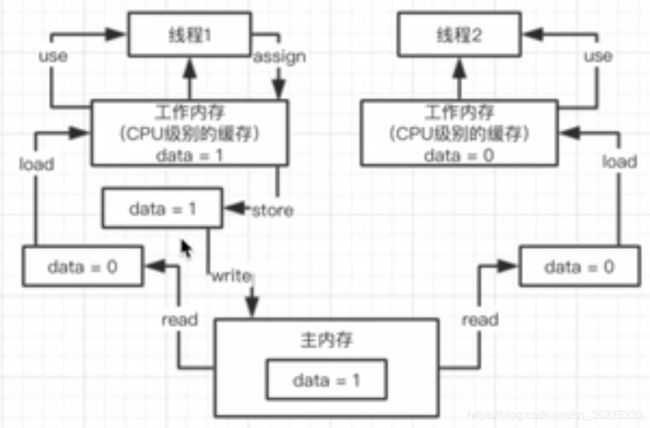
// 线程2
new Thread() {
public void run() {
while (data == 0) {
helloworld.increment();
}
}
}
(2)原子性
线程2,在从工作内存中获取到data = 1后,不会再对data进行加 一 操作
原子性: data++ ,必须是独立执行的,一定是我自己执行成功之后,别人才能来进行下一次 data++ 的执行
(3)有序性
对于代码,同时还有一个指令重排序,编译器和指令器,有的时候为了提高代码执行效率,会将指令重排序,就是比如下面的代码
flag = false;
// 线程1
prepare(); // 准备资源
flag=true;
// 线程2
while(!flag) {
Thread.sleep(1000);
}
execute();// 基于准备好的资源执行操作具有有序性,prepare() 和 flag=true 不会发生顺序的错乱,不会因为指令重排导致我们的代码异常;不具有有序性,可能会发生一些指令重排,导致代码可能会出现一些问题
12、从java 底层角度聊聊 volatile 关键字的原理
讲清楚 volatile 关键字,直接问你 volatile 关键字的理解,对前面的一些问题,这个时候就应该自己主动去从内存模型开始讲起,原子性,可见性,有序性的理解,volatile 关键字的原理
volatile 关键字是用来解决可见性和有序性,在有些罕见的条件下,可以有限的保证原子性,它主要不是用来保证原子性的
public class HelloWorld {
private volatile int data;
public void increment() {
data ++;
}
}
HelloWorld helloWorld = new HelloWorld(); // 对象其实在堆内存里
// 线程1
new Thread() {
public void run() {
helloworld.increment();
}
}
// 线程2
new Thread() {
public void run() {
while(data == 0) {
helloworld.increment();
}
}
}

添加volatile后线程1 执行完后,在自己工作内存修改data后,将data = 1 ,刷回主内存,并强制将其他线程的工作内存失效,其他线程的工作内存在读取时,必须重新从主内存进行获取值
13、volatile 底层是如何基于内存屏障保障可见性 和 有序性的
连环炮: 内存模型 -> 原子性、可见性、有序性 -> volatile + 可见性 -> volatile + 有序性(指令重排 + happens-before)
-> volitile + 原子性 -> volatile 底层的原理(内存屏障级别的原理)
volatile + 原子性: 不能保证原子性
保证原子性: 还是需要通过synchronized,lock,加锁
(1)lock 指令: volatile 保证可见性
对volatile 修饰的变量,执行写操作的话,JVM 会发送一条 lock 前缀指令给CPU, cpu在计算完之后会立即将这个值写回主内存,同时因为有 MESI 缓存一致性协议,所以各个 CPU 都会对总线进行嗅探,自己本地缓存中的数据是否被别人修改
如果发现别人修改了某个缓存的数据,那么CPU 就会将自己缓存的数据过期掉,然后这个CPU 上执行的线程在读取那个变量的时候,就会从主内存重新加载最新的数据了
lock 前缀指令 + MESI 缓存一致性协议
(2)内存屏障:
对某一个元素添加volatile之后,会在元素前后加入,内存屏障(禁止重排序),Load1,Load2