贝壳面试(2)
1:手写快排 时间空间复杂度分析(第一次手写代码,突然脑子空白)
public class Test {
public static void main(String []args) {
int a[]={289789,200,3,7777,9,1,17,18,0,4};
int k=a.length-1;
sort(a,0,k);
for(int i=0;i= mid)
high--;
array[low] = array[high];
while (low < high && array[low] <= mid)
low++;
array[high] = array[low];
}
array[low] = mid;
return low;
}
public static void sort(int[]array,int low,int high){
if(low 2,用两个栈实现一个队列(主要说思路)
import java.util.Stack;
public class Solution{
Stack stack1=new Stack();
Stack stack2 = new Stack();
public void push(int node){
stack1.push(node);
}
public int pop(){
if(stack1.empty()&&stack2.empty()){
throw new RuntimeException("queue is empty!!");
}
if(stack2.empty()){
while(!stack1.empty()){
stack2.push(stack1.pop());
}
}
return stack2.pop();
}
}
3:平衡二叉树是什么
查询啊删除啊,二叉树的基本结构弥补了这些不足,但是二叉树有一个很麻烦的问题,随机数据,效果会好一些,要是排序了,就会比较麻烦,就失去了二叉树的优势,二叉树本身就是非平衡的,下面就是非平衡树的做法)
平衡二叉搜索树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。平衡二叉树的常用实现方法有红黑树,
什么是红黑树?
a:什么是红黑树:增加了某些特点的二叉搜索树。-》平衡树。
1:节点都有颜色。
2:在插入和删除的过程中,要遵循保持这些颜色的不同排列规则。
b:红黑的规则:
1:每个节点不是红色就是黑色。
2:根节点只能是黑色。
3:如果节点是红色,则它的子节点必须是黑色(反之不一定必须)。
4:从根节点到叶子节点或者空的子节点的每条路径,每条路径必须包含相同数目的黑色节点。 我们成为上述为:“黑色高度”。
红黑树的效率: 查找和插入删除的效率(log(2n))和二叉树几乎相同(都是随机数的情况下)。 其次,插入和删除时间增加了一个常数的因素,平均插入一次数据,需要一个旋转。 代码是在插入或者旋转的时候判断黑色节点的数目,加上旋转或者颜色变换.
4:树的深度,高度,层数?
高度:所以高度就是以从下往上对比,这是我们的习惯。而在树中,树的高度也是从下往上数。高度的定义为:从结点x向下到某个叶结点最长简单路径中边的条数。
理解了高度,则深度的理解就很容易了,深度是从根节点往下。
层数:根节点是在第0层。
总结:
1对于整棵树来说,最深的叶结点的深度就是树的深度;树根的高度就是树的高度。这样树的高度和深度是相等的。
2对于树中相同深度的每个结点来说,它们的高度不一定相同,这取决于每个结点下面的叶结点的深度。
5:双向链表是什么
从链表的实现方式可以把链表分为单链表,循环链表,双向链表。
单链表指的是链表中的元素的指向只能指向链表中的下一个元素或者为空,元素之间不能相互指向。也就是一种线性链表。
双向链表即是这样一个有序的结点序列,每个链表元素既有指向下一个元素的指针,又有指向前一个元素的指针,其中每个结点都有两种指针,即left和right。left指针指向左边结点,right指针指向右边结点。
template
class Node
{
private:
T data;
Node *left, *right;
}
循环链表指的是在单向链表和双向链表的基础上,将两种链表的最后一个结点指向第一个结点从而实现循环。
表的顺序表示的优点是随机存取表中的任意元素,但是在做插入或删除操作时,需移动大量元素。
表的链式表示,在随机插入元素时没有顺序表示的缺陷,但同时不能对元素进行随机存取。
6:https为什么是安全的
ttps本质: 1次非对称加密,n 次对称加密.
为什么能安全: 证书最终被 root 证书校验,root 证书是正版系统内置的,只要系统正版,就能保证安全性. 故即使证书机构的证书下载过程被拦截也不怕.因为会被 root 证书验证. “信用链”
为什么不怕中间人拦截: 如上所说.
颁发的证书: 证书公钥部分, 证书私钥部分.证书公钥部分传递给客户端,客户端验证后,用此来加密,通信获取对称加密串.
核心是: 加密 + 签名
加密: 1.防止被看 2. 防止篡改, 被改后也不怕,解密数据后就无意义了 (乱码, 只是造成骚扰,但业务数据不会错乱)
签名作用: 签名一定要加密,签名不加密其实也没啥作用. 非对称加密的意义.
安全的前提是:
- 有签名
- 有非对称加密
HTTPS就等于HTTP加上TLS(SSL),HTTPS协议的目标主要有三个:
数据保密性。保证内容在传输过程中不会被第三方查看到。就像快递员传递包裹时都进行了封装,别人无法知道里面装了什么东西。
数据完整性。及时发现被第三方篡改的传输内容。就像快递员虽然不知道包裹里装了什么东西,但他有可能中途掉包,数据完整性就是指如果被掉包,我们能轻松发现并拒收。
身份校验。保证数据到达用户期望的目的地。就像我们邮寄包裹时,虽然是一个封装好的未掉包的包裹,但必须确定这个包裹不会送错地方。
通俗地描述上述三个目标就是封装加密,防篡改掉包,防止身份冒充。
7:负载均衡了解吗
负载均衡是高可用网络基础架构的的一个关键组成部分,有了负载均衡,我们通常可以将我们的应用服务器部署多台,然后通过负载均衡将用户的请求分发到不同的服务器用来提高网站、应用、数据库或其他服务的性能以及可靠性。

负载均衡的出现可以很好的解决上面两个问题,通过引入一个负载均衡器和至少两个web 服务器,可以有效的解决上面两个问题。注:通常情况下,所有的后端服务器会保证提供相同的内容,以便用户无论哪个服务器响应,都能收到一致的内容。

如上图架构,现在,即使App 01即使挂了,负载均衡会将用户的请求转发到正常工作的App 02上,这解决了上面的第一个问题;其次,根据业务需要,负载均衡后端的App可以很方便的扩展,这样就能解决第上面的第二个问题。但是,现在单点故障问题转移到了负载均衡器,可以通过引入第二个负载均衡器来缓解,后面还会讲到。




8:索引的作用 为什么可以加快查询速度?
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
当表中有大量记录时,若要对表进行查询,第一种搜索信息方式是全表搜索,是将所有记录一一取出,和查询条件进行一一对比,然后返回满足条件的记录,这样做会消耗大量数据库系统时间,并造成大量磁盘I/O操作;第二种就是在表中建立索引,然后在索引中找到符合查询条件的索引值,最后通过保存在索引中的ROWID(相当于页码)快速找到表中对应的记录。
9:所有的都可以加索引吗 为什么
表结构中字段是否添加索引判断依据是什么? – 字段是否是查询条件或者是排序条件。
是否将所有的字段都添加索引,来加快查询? – 不行的
1、 索引会占用存储空间,索引越多,使用的存储空间越多
2、 插入数据,存储索引也会消耗时间,索引越多,插入数据的速度越慢
10:第一范式和第二范式是什么
第一范式,每一个列不可再分。
对应我们设计就是不能出现重复的列。这个是关系数据库的基础没有人会犯这个错误(数据库也不让)。
下面举一个我们可能会犯错的例子。
学生表,(姓名,班级,年龄,性别,家庭住址,班主任姓名,班主任职称,所选课程,课程学分)。
这里如果是教育局查看所有所有的表,可能会出现,统计一下北京通州区的学生数量,统计一下北京海淀区的学生数量。这样没有办法统计了。所以在这个背景下,我们设计应该是。学生表(姓名,班级,年龄,性别,家庭所在市,家庭所在区,班主任姓名,班主任职称,所选课程,课程学分)。
理解:设计数据库的时候,根据业务最好把东西拆分成合适的粒子。我们还出现一个2的情况,就是字段不够了,也不能随便加数据库字段,我就把一个备用字段,中间用,“,”作为分隔符,放了好多东西,最后要分类统计,就2了。
第二范式,在第一范式的基础上,非主属性依赖于主属性。
还是上面的例子。
主属性,候选码,都是唯一的意思(也就是数据库中的主键)。
如果学生姓名是唯一的,学生姓名也就是码,那么就有了主属性。如果每个学生只选择一门课程。那么课程也是唯一依赖于姓名。但是实际生活中,学生很容易重名,学生也要选择多门课程。所以以上违背第二范式。
改变为,学生表(学号,姓名,班级,年龄,性别,家庭所在市,家庭所在区,班主任姓名,班主任职称,所选课程号) ,课程表(课程号,课程名称,课程学分)。
理解:程序中必须设置主键,一对多关系必须差分开,多对多也是一样。有的时候为了连表方便也把名称和主键都放在另一个表里。这样就省去连表了,但是会出现一种情况
教师的名称改变了,但是你学生表的老师名称没有改变。、
第三范式,消除非主属性传递依赖。
学生表(学号,姓名,班级,年龄,性别,家庭所在市,家庭所在区,班主任姓名,班主任职称,所选课程号)
这时候,班主任依赖于学号,班主任名称依赖于班主任,间接依赖于学号,这就是传递依赖应该变为。
学生表(学号,姓名,班级,年龄,性别,家庭所在市,家庭所在区,班主任编号,所选课程号)
教师表(教师编号,姓名,职称)
理解:程序中除了主键其他信息不能出现在其他表中。(也就是任意两个表,不能出现重复的非主键字段)
BC范式,消除主属性传递依赖
假设学校脑抽,让录指纹方便打卡。学生表(学号,姓名,班级,年龄,性别,家庭所在市,家庭所在区,指纹
这里就会出现指纹是唯一的,指纹依赖于学号,那么就出现了主属性依赖。
如果学生退学了,指纹信息也消失了,这个系统如果想要建立一个指纹库,那么不符合需求了。
这是候差分成,学生表(学号,姓名,班级,年龄,性别,家庭所在市,家庭所在区,指纹ID)。指纹表(指纹ID,指纹)
理解:1对1关系,最好也进行差分。
11:输入网址后的全过程(细节!)
贼详细,大佬。












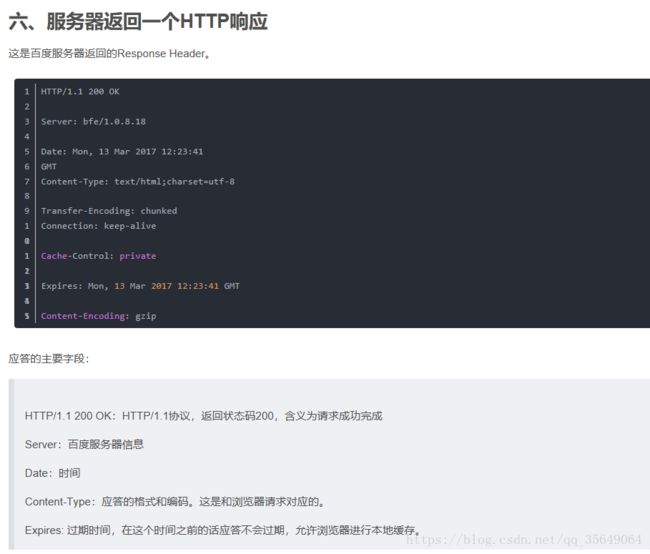


12:TCP和UDP的区别
TCP的优点: 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。
TCP的缺点: 慢,效率低,占用系统资源高,易被攻击 TCP在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。 而且,因为TCP有确认机制、三次握手机制,这些也导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。
UDP的优点: 快,比TCP稍安全 UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:
UDP Flood攻击…… UDP的缺点: 不可靠,不稳定 因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
基于上面的优缺点,那么: 什么时候应该使用TCP: 当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。 在日常生活中,常见使用TCP协议的应用如下: 浏览器,用的HTTP FlashFXP,用的FTP Outlook,用的POP、SMTP Putty,用的Telnet、SSH QQ文件传输 ………… 什么时候应该使用UDP: 当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。 比如,日常生活中,常见使用UDP协议的应用如下: QQ语音 QQ视频 TFTP ……


13:内存分配方式
堆,由程序员手动分配和释放,如果程序员没有释放,在程序结束时由系统回收,分配方式类似于链表。由于堆是程序员管理的,如果管理不当会导致内存泄露的问题,内存泄露指已经分配的内存空间无法被系统回收也无法被继续使用。
解决这个问题,C++可以使用智能指针对象去指向分配的内存,在对象析构时释放内存防止内存泄露。
在JAVA中由于有垃圾回收期,因此可以不用担心内存泄露的问题。(但java还是会存在内存泄露,什么样的情况下java会发生内存泄露?java中内存泄露的对象特点是:
1.对象可达,
2.对象无用,这些对象因为可达,因此不会被垃圾回收机制回收,但又会一直占用内存,java中不可达的对象都会被系统回收。
java中内存泄露的情况:长生命周期对象持有短生命周期对象的引用,例如一个全局变量持有了局部对象的引用,或者成员对象持有了成员函数中局部对象的引用。


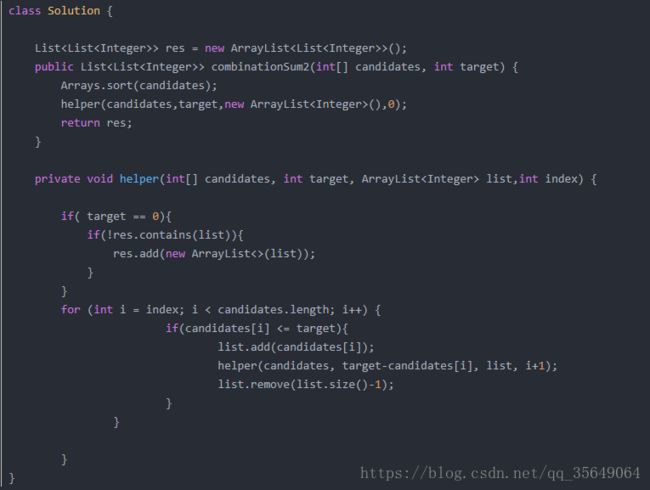
14:在一个数组中找到任意个和为target的数(指路LeetCode 40)
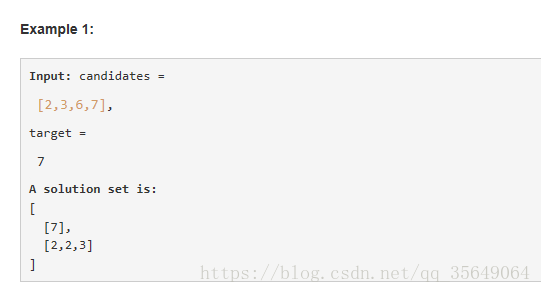
思路:回溯法的练习题。因为可以重复,注意递归调用时可以从当前位置开始取。


16:找到数组中出现频次最高的数()
import java.util.*;
public class Test
{
//用HashMap的key来存放数组中存在的数字,value存放该数字在数组中出现的次数
public static void main(String[] args)
{
int[] array = {2, 1, 2, 3, 4, 5, 2, 2,5,5,5,5,5,5,5,5, 2, 2};
//map的key存放数组中存在的数字,value存放该数字在数组中出现的次数
HashMap map = new HashMap();
for(int i = 0; i < array.length; i++)
{
if(map.containsKey(array[i]))
{
int temp = map.get(array[i]);
map.put(array[i], temp + 1);
}
else
{
map.put(array[i], 1);
}
}
Collection count = map.values();
//找出map的value中最大的数字,也就是数组中数字出现最多的次数
int maxCount = Collections.max(count);
int maxNumber = 0;
for(Map.Entry entry : map.entrySet())
{
//得到value为maxCount的key,也就是数组中出现次数最多的数字
if(maxCount == entry.getValue())
{
maxNumber = entry.getKey();
}
}
System.out.println("出现次数最多的数字为:" + maxNumber);
System.out.println("该数字一共出现" + maxCount + "次");
}
}
如果不使用hashmap呢 emmm:


在开始的时候可以初始化第一个数字就是第一个元素出现的次数。