爬虫(三)bs4库
0.Beautiful Soup库的安装
在cmd以管理员身份输入:
pip install beautifulsoup4BS库的安装小测 演示HTML页面地址 http://python123.io/ws/demo.html
获得该链接的源代码:
(1)右键点击 查看源代码
(2)IDLE输入:(对demo进行html的解析)
>>> import requests
>>> r=requests.get("http://python123.io/ws/demo.html")
>>> r.text
'This is a python demo page \r\n\r\nThe demo python introduces several python courses.
\r\nPython is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\nBasic Python and Advanced Python.
\r\n'
>>> demo=r.text
>>> from bs4 import BeautifulSoup
>>> soup=BeautifulSoup(demo,"html.parser")
>>> print(soup.prettify())结果输出其网页源代码:
This is a python demo page
The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python
and
Advanced Python
.
1.Beautiful Soup库的基本元素
Beautiful Soup库是解析、遍历、维护“标签树”的功能库。

from bs4 import BeautifulSoup
soup=BeautifulSoup("data","html.parser")
soup2=BeautifulSoup(open("D://demo.html"),"html.parser")BeautifulSoup对应一个HTML/XML文档的全部内容。

BS类的基本元素
...
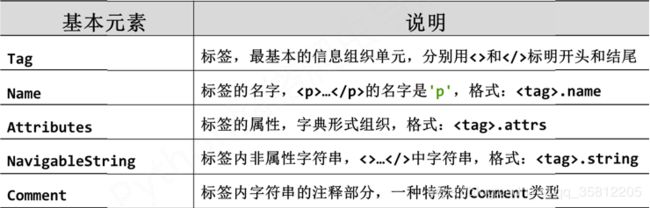
Tag标签
说明:Tag是最基本的信息组织单元,分别用<>和表明开头和结尾。
>>> import requests
>>> r=requests.get("http://python123.io/ws/demo.html")
>>> demo=r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.title
This is a python demo page
>>> tag=soup.a
>>> tag
Basic Python
>>> type(tag)
任何存在于HTML语法中的标签都可以用soup.
Tag的name(名字)
说明:标签的名字,
...
的名字是'p',格式:>>> soup.a.name
'a'
>>> soup.a.parent.name
'p'
>>> soup.a.parent.parent.nameTag的attrs(属性)
说明:标签的属性,字典形式组织,格式:
每个
>>> tag=soup.a
>>> tag.attrs
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> tag.attrs['class']
['py1']
>>> tag.attrs['href']
'http://www.icourse163.org/course/BIT-268001'
>>> type(tag.attrs)
Tag的NavigableString
说明:标签内非属性字符串,<>...中字符串,格式:
>>> soup.a
Basic Python
>>> soup.a.string
'Basic Python'
>>> soup.p
The demo python introduces several python courses.
>>> soup.p.string
'The demo python introduces several python courses.'
>>> type(soup.p.string)
Tag的Comment
说明:标签内字符串的注释部分,一种特殊的Comment类型
Comment是一种特殊的文字类型。
>>> newsoup=BeautifulSoup("This is not a comment
","html.parser")
>>> newsoup.b.string
'This is a comment'
>>> type(newsoup.b.string)
>>> newsoup.p.string
'This is not a comment'
>>> type(newsoup.p.string)

2.基于bs4库的HTML内容遍历方法

A.标签树的下行遍历

标签树的下行遍历代码举例:

from bs4 import BeautifulSoup
new_soup=BeautifulSoup("A
BC
","html.parser")
print("儿子结点:")
for i,child in enumerate(new_soup.div.children):
print(i+1,child)
print("子孙结点:")
for i,child in enumerate(new_soup.div.descendants):
print(i+1,child)
结果输出:
儿子结点:
1 A
2 B
3 C
子孙结点:
1 A
2 A
3 B
4 C
5 C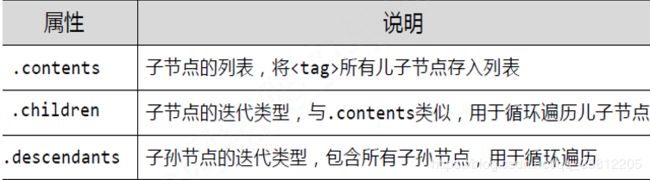
BeautifulSoup类型是标签树的根结点。
>>> soup=BeautifulSoup(demo,"html.parser")
>>> soup.head
This is a python demo page
>>> soup.head.contents
[This is a python demo page ]
>>> soup.body.contents
['\n', The demo python introduces several python courses.
, '\n', Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python and Advanced Python.
, '\n']
>>> len(soup.body.contents)
5
>>> soup.body.contents[1]
The demo python introduces several python courses.
B.标签树的上行遍历

1
遍历所有先辈结点,包括soup本身,所以要区别判断。
C.标签树的平行遍历

>>> from bs4 import BeautifulSoup
>>> soup=BeautifulSoup(demo,"html.parser")
>>> soup.a.next_sibling
' and '
>>> soup.a.next_sibling.next_sibling
Advanced Python
>>> soup.a.previous_sibling
'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n'
>>> soup.a.previous_sibling.previous_sibling
>>> soup.a.parent
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python and Advanced Python.
注意:

平行遍历(all):

3.基于bs4库的HTML格式化和编码
bs4库的prettify()方法
方法:
使HTML内容更加“友好”的显示,为HTML标签及其内容添加'\n',标签对象和soup对象均可调用此方法。
>>> from bs4 import BeautifulSoup
>>> soup=BeautifulSoup(demo,"html.parser")
>>> soup.prettify()
'\n \n \n This is a python demo page\n \n \n \n \n \n The demo python introduces several python courses.\n \n
\n \n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\n \n Basic Python\n \n and\n \n Advanced Python\n \n .\n
\n \n'
>>> print(soup.prettify())
This is a python demo page
The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python
and
Advanced Python
.
由上面可以看出print可以打印出\n换行。
bs4库将任何HTML输入都变成utf-8编码(国际通用的编码格式)。
Pyhton 3.x默认支持编码是utf-8,解析无障碍。
>>> soup=BeautifulSoup("中文
","html.parser")
>>> soup.p.string
'中文'
>>> print(soup.p.prettify())
中文