从零开始SpringCloud Alibaba电商系统(十三)——ElasticSearch介绍、logback写入ES
文章目录
- 零、系列
- 一、需求简述
- 二、ElasticSearch简介
- 三、ElasticSearch REST基本操作
- 四、使用SpringData ElasticSearch
- 五、Logback日志写入ES
- 五.一 ELK是什么
- 五.二 Logback
- 六、Kibana将数据展示
- 七、demo地址
零、系列
欢迎来嫖从零开始SpringCloud Alibaba电商系列:
- 从零开始SpringCloud Alibaba电商系统(一)——Alibaba与Nacos服务注册与发现
- 从零开始SpringCloud Alibaba电商系统(二)——Nacos配置中心
- 从零开始SpringCloud Alibaba电商系统(三)——Sentinel流量防卫兵介绍、流量控制demo
- 从零开始SpringCloud Alibaba电商系统(四)——Sentinel的fallback和blockHandler
- 从零开始SpringCloud Alibaba电商系统(五)——Feign Demo,Sentinel+Feign实现多节点间熔断/服务降级
- 从零开始SpringCloud Alibaba电商系统(六)——Sentinel规则持久化到Nacos配置中心
- 从零开始SpringCloud Alibaba电商系统(七)——Spring Security实现登录认证、权限控制
- 从零开始SpringCloud Alibaba电商系统(八)——用一个好看的Swagger接口文档
- 从零开始SpringCloud Alibaba电商系统(九)——基于Spring Security OAuth2实现SSO-认证服务器(非JWT)
- 从零开始SpringCloud Alibaba电商系统(十)——基于Redis Session的认证鉴权
- 从零开始SpringCloud Alibaba电商系统(十一)——spring security完善之动态url控制
- 从零开始SpringCloud Alibaba电商系统(十二)——spring aop记录用户操作日志
一、需求简述
前文我们介绍了如何使用AOP拦截,记录所有访问controller的用户即请求参数、请求的执行结果、执行异常的结果。
今天我们来聊一聊大名鼎鼎的ELK中的ElasticSearch(简称ES),以及如何在将ES与logback结合,存储业务日志。
二、ElasticSearch简介
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索。”Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。 ————wiki百科
概括:
- ES是一个搜索引擎,同时是一个可存储数据的nosql。
- ES的搜索是近实时搜索,不是real time。
- ES的分片与数据库横向分表相同,就是将一份数据按照一个路由(hash)规则划分为几个分片。
- 为了保证数据的安全,ES的分片可以配置副本数,多一份副本就多一份安全,就提高一些读取的速度,当然数据写入就会变慢。
- ES是天然分布式的,我们只需要增加节点它就可以自动的管理好内部的分片数据和副本数据。
- 另外,ES的一致性实现方案是参考了微软的PacificA算法,有兴趣的同学可以研究研究。
总之,我们知道ES可以存储结构化数据、而且搜索很快、还容易扩展,再加上kibana提供ES数据的可视化,这完全符合我们日志系统存/查的需求。
三、ElasticSearch REST基本操作
ES的安装就跳过了,推荐大家直接用docker一拉,简单配一下映射的路径,然后一run,完事儿。
- ES集群状态查看,对于一个分布式系统,ES这个api很有用,我们可以知道它当前有多少可用节点,有多少可用的分片等信息。
GET http://127.0.0.1:9200/_cluster/health
返回结果:
{
"cluster_name": "elasticsearch", # 集群名称
"status": "yellow", # 集群状态,分为red、yellow、green。当前因为副本分片未分配所以yellow。
"timed_out": false, # 是否有搜索的超时限制
"number_of_nodes": 1, # 所有节点数
"number_of_data_nodes": 1, # data节点,即存放数据的节点数
"active_primary_shards": 7, # 可用的主分片数(所有index的主分片数之和)
"active_shards": 7, # 所有可用的分片数(包括副本分片)
"relocating_shards": 0, # 迁移分片的数量,例如上面所说新加入节点后会导致各个节点间的分片重新分配
"initializing_shards": 0,
"unassigned_shards": 7, # 未分配的分片数,因为我只有一个节点,副本分片和主分片都放在这里也无法保证数据安全,所以干脆没有副本分片,当多一个节点接入集群时,这些副本分片将被分配
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50.0
}
- 其他查看ES集群信息的API可以通过cat来拿到:
http://127.0.0.1:9200/_cat
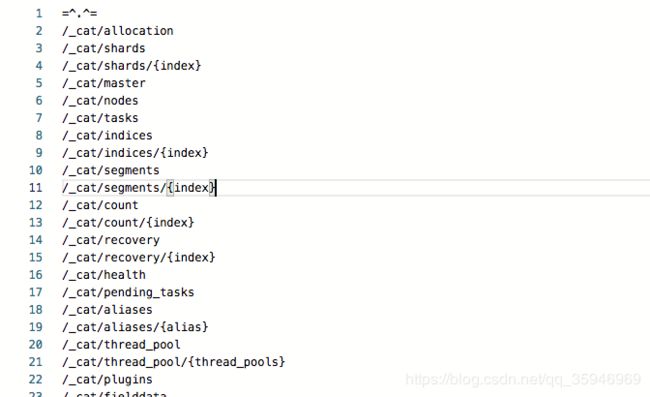
- 添加一个名为logs的索引,索引类似mysql的
database,在6.x及之后的版本索引更类似与mysql的table,因为一个索引中只允许一种类型(这个类型中定义了本索引内数据所用到的所有字段。)
PUT /logs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
- 添加一个
文档document,即添加一条数据。这条数据的字段由上述索引定义,如果文档中的某个字段不存在与索引中,那么该字段将被自动创建到索引的元信息中。
POST http://127.0.0.1:9200/logs/systemLog
{
"id": "ac6d46ad-b50d-437f-a47d-70562c08e475",
"requestMethod": "UserController下的saveUser",
"requestParam": "id:113213123",
"requestUrl": "127.0.0.2",
"result": "success",
"sourceUrl": "127.0.0.1",
"userDetails": "{\"Details:lele\"}"
"errMessage": "is error",
}
这里字段的含义解释放在下面的java类中。
- 此时我们查看当前
索引,即logs的类型结构,可以发现它多了很多字段并自动提供分析得到了字段类型,这些都是上一步创建文档之前生成的,之后再保存同样字段的数据将会直接 使用这些字段(这些字段也称为mappings)。
GET http://127.0.0.1:9200/logs

值得一提,除了int、date等一系列基础类型外,字符串类的基础类型还有keyword和text,keyword用于精准匹配,而text类型用于建立倒排索引并提供相似度查找,下次再聊查询
图片中可以看到我这里的每个字段都被自动生成为text类型,但是下面还有一个fields是做什么的?当我们将类型定义为text,es会为这个字段建立倒排索引进行查询,这样就不能对这个字段进行精准查询了,fileds就可以解决这种问题,可以再为该字段定义一个keyword类型。
四、使用SpringData ElasticSearch
- 在简单demo的基础上,增加maven依赖,以及es的配置信息。
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.repositories.enabled=true
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
- 增加一个实体类来对应系统访问日志这个数据结构。
注意:@Document的index和type必填,下面的字段@Field必填,其他都属于lombok和swagger。
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
@ApiModel("系统访问日志")
@Document(indexName="logs",type="systemLog")
public class SystemLog {
@Field
@ApiModelProperty("日志id,uuid生成")
private String id;
@Field
@ApiModelProperty("日志类型")
private LogConstant.LogType type;
@Field
@ApiModelProperty("日志记录时间")
private Long logTime;
@Field
@ApiModelProperty("常规日志信息")
private String messgae;
@Field
@ApiModelProperty("来源地址")
private String sourceUrl;
@Field
@ApiModelProperty("访问者信息")
private String userDetails;
@Field
@ApiModelProperty("访问节点")
private String requestUrl;
@Field
@ApiModelProperty("访问方法")
private String requestMethod;
@Field
@ApiModelProperty("请求参数")
private String requestParam;
@Field
@ApiModelProperty("处理成功返回结果:与errMessage二者有一")
private String result;
@Field
@ApiModelProperty("处理失败返回结果:与result二者有一")
private String errMessage;
}```
3. 开启ES的repository层扫描,和mybatis的@mapperscan差不多。
```java
@Configuration
@EnableElasticsearchRepositories(basePackages = "org.lele.common.repository")
public class JPAConfig {
}
- 编写一个repository接口用于支持systemlog的简单增删改查(JPA方式)。
@Repository
public interface SystemLogRepository extends ElasticsearchCrudRepository<SystemLog,String> {
}
- 用enum定义日志类型。
public class LogConstant {
public enum LogType{
/**
* INFO级别日志
*/
INFO,
/**
* WARN级别日志
*/
WARN,
/**
* ERROR级别日志
*/
ERROR,
/**
* aop日志,在controller层方法之前。
*/
BEFORE,
/**
* aop日志,在controller层方法之后,成功返回时写入。
*/
AFTER_RETURN,
/**
* aop日志,在controller层方法之后,抛异常时写入。
*/
AFTER_EXCEPTION
}
}
- 在用户访问日志的Aspect里面增加日志写入的逻辑。(不需要用户访问日志的同学可以忽略)
@Before("logPointCut()")
public void before(JoinPoint jp) {
HttpServletRequest request = ((ServletRequestAttributes)RequestContextHolder.getRequestAttributes()).getRequest();
UserDTO userDTO = sessionUtils.getCurrentUser();
SystemLog log = SystemLog.builder()
.id( UUID.randomUUID().toString() )
.type(LogConstant.LogType.BEFORE )
.logTime( System.currentTimeMillis() )
.sourceUrl( request.getRemoteAddr() )
.userDetails( userDTO.toString() )
.requestUrl( HostNameUtil.getIp() )
.requestMethod( jp.getTarget().getClass().getName() + "." + jp.getSignature().getName() + "()" )
.requestParam( JSONObject.toJSONString( jp.getArgs() ) )
.build();
systemLogRepository.save(log);
}
- 启动项目,任意访问一个controller,可以发现,es中多了一些数据——这就是我们前文中提到的要采集的用户访问日志。
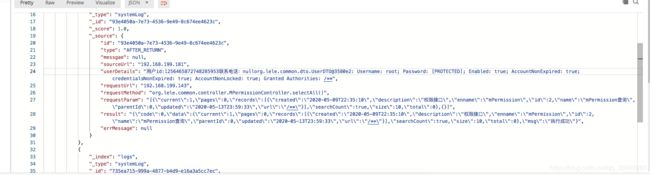
用户访问日志解决了,其他的日志,如logback的日志如何收集到es中呢?
五、Logback日志写入ES
一般说到ES做日志处理,大家一般应该会想到ELK。
五.一 ELK是什么
ELK是ES+LogsTash+Kibana(都是elastic公司自家的),通过前面的介绍我们已经知道ES是搜索引擎(兼nosql),kibana是配合ES的可视化界面,LogsTash则是日志收集兼数据处理过滤的地方,是ELK的起点。
LogTash的场景: 当我们的日志输出到文件或kafka等消息队列又或是其他东西里面的时候,LogsTash可以从中获取日志,然后简单处理之后放入ES中。
有了解过Hadoop生态的同学可能会意识到,LogTash和Flume的场景是很类似的。
LogTash的缺点: 无法直接同时收集多节点的日志文件,当然可以通过消息队列但是不够方便,于是elastic又推出了专门面向日志收集的工具集合——Beats,这些都是题外话。
对于我们的系统来说: ELK目前不是必须的(笔者比较穷,机器hold不住了…),所以我们直接采用另外一种方式来对接日志与ES——Logbak Appender。
五.二 Logback
日志永远是一个系统不可缺少的部分,我们一般项目中或多或少会接触到日志,最多的可能就是logback和log4j,而这两者的区别不过是logback是log4j的升级版,因为两者都是一个作者的作品。
另:slf4j不是日志框架,而是日志适配器,我们使用了slf4j就可以随意切换底层的日志组件,而不会影响到业务的代码逻辑。
Appender : Appender是logback提供的一种可以自定义数据写出的方式,可以写出的console,文件,也可以写出到ES或是其他任何可用java连通的介质中。
talk is cheap,show me the code!
- 定义一个ApplicationContextHolder用来获取ApplicationContext,ApplicationContext是为了帮助我们在Appender中获取Bean(这里要用到systemLogRepository)使用的。
获取Application的方式有很多种,这里采用实现ApplicationAware的方式,Aware是感知的意思,继承该接口可以让Holder类获取到application实例。
@Component
public class ApplicationContextHolder implements ApplicationContextAware {
private static ApplicationContext context;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
context = applicationContext;
}
/**
* 直接获取applicationContext
* @return applicationContext
*/
public static ApplicationContext getContext() {
return context;
}
/**
* 根据名称获取Bean
*
* @param beanName bean名称
* @return Bean实例
*/
public static Object getBean(String beanName) {
if (context == null || StringUtils.isBlank(beanName)) {
return null;
}
return context.getBean(beanName);
}
/**
* 根据类型获取Bean
*
* @param className bean类型
* @param bean类型
* @return Bean实例
*/
public static <T> T getBean(Class<T> className) {
if (context == null || className == null) {
return null;
}
return context.getBean(className);
}
}
- 定义我们的Appender,主要需要重写append方法。
public class ElasticsearchAppender extends AppenderBase<LoggingEvent> implements java.io.Serializable {
private SystemLogRepository systemLogRepository;
@Override
public void stop() {
super.stop();
}
@Override
protected void append(LoggingEvent e) {
try {
doLogging(e);
} catch (Exception exception) {
addError("日志写入ES失败", exception);
} finally {
MDC.clear();
}
}
private void doLogging(LoggingEvent e) {
if (systemLogRepository == null) {
systemLogRepository = ApplicationContextHolder.getBean(SystemLogRepository.class);
if (systemLogRepository == null) {
addWarn("systemLogRepository is null.");
return;
}
}
String errorMessage = buildMessage(e);
Function<Level, LogConstant.LogType> getLogType = level->{
switch( level.toInt() ){
case Level.ERROR_INT:
return LogConstant.LogType.ERROR;
case Level.INFO_INT:
return LogConstant.LogType.INFO;
case Level.WARN_INT:
return LogConstant.LogType.WARN;
default:
return LogConstant.LogType.INFO;
}
};
SystemLog systemLog = SystemLog.builder()
.id( UUID.randomUUID().toString() )
.logTime( e.getTimeStamp() )
.messgae( errorMessage )
.type( getLogType.apply(e.getLevel()) )
.build();
try {
systemLogRepository.save(systemLog);
} catch (Exception ex) {
addError(ex.getMessage());
}
}
//获取完整堆栈
private String buildMessage(LoggingEvent e) {
if (e.getLevel().toInt() == Level.ERROR_INT && e.getThrowableProxy() != null) {
return e.getFormattedMessage() + CoreConstants.LINE_SEPARATOR
+ ThrowableProxyUtil.asString(e.getThrowableProxy());
}
return e.getFormattedMessage();
}
}
- 配置logback.xml(放在classpath下即可)。 appender是需要配置到配置文件的,不是任何框架都想spring一样可以用bean来丝滑的解决。
这里定义了一个默认的consoleAppender和一个自定义ESAppender。
<?xml version="1.0" encoding="UTF-8"?>
>
>
>
>%d %5p %40.40c:%4L - %m%n >
>
>
>
>
>
-ref ref="console"/>
-ref ref="elasticAppender"/>
>
>
- 在service中使用logger。这里因为还没有自己实现的service,所以暂时在controller方法中测试一下。
private Logger logger = LoggerFactory.getLogger( MUserController.class );
@GetMapping
@ApiOperation(value = "查询用户")
public R selectAll(@ApiIgnore Page<MUser> page, MUser mUser) {
logger.info( "我来查询用户了" );
return success(this.mUserService.page(page, new QueryWrapper<>(mUser)));
}
- 启动项目,访问对应接口,然后查看我们的es对应index下的数据。

数据成功写入。
六、Kibana将数据展示
我们获取数据是有目的的,我们受够了在n个机器上反复vim查看日志的操作,所以我们要用更方便的kibana来查看日志信息。
没有环境的朋友仍然推荐docker,一pull一run十分舒坦,这里只介绍如何kibana的简单操作,如何结合我们之前存入的数据来使用。
-
下面是一段docker-compose的kibana配置,有兴趣的同学可以了解一下compose,极大节约部署时间成本。这里关键点就是kibana要连接上ES,也就是划红线的这部分,无论哪种方式配置,都需要这个参数配置。

-
启动kibana,访问 localhost:5601
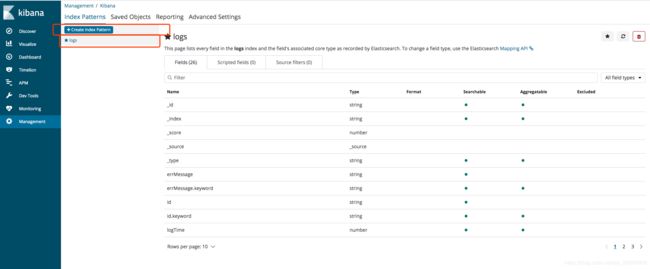
-
kibana的使用需要先建立
索引匹配集,也就是建立一个集合,用来匹配我们的一些索引,笔者这里只是匹配了logs,这是我们存储系统日志的索引。

-
建好索引就可以在
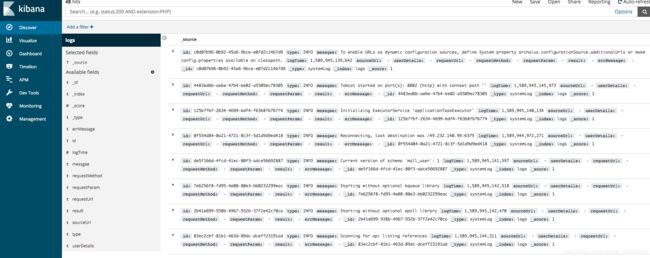
discover栏目愉快的看日志了,下面是一个全日志的列表,我们可以按照需求来过滤或展示。
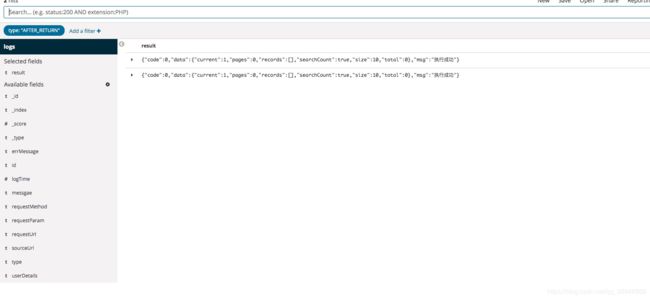
第二张图展示的是type(日志类型)为AFTER_RETURN的日志,且只显示result列的结果,日志看起来舒服多了。
-
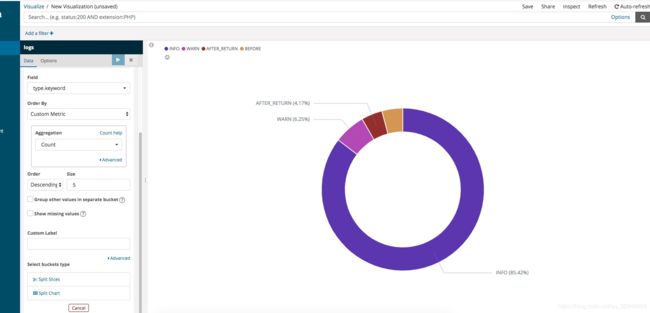
kibana还提供了图形展示的功能
Visualize,将数据导入图形模板。
笔者这里简单做了一个图:各种类型的日志各自占比多少。
kibana的介绍就到这里,实际上这对笔者收集并分析查看日志的需求来说,已经足够使用了。
七、demo地址
https://github.com/flyChineseBoy/lel-mall/tree/master/mall13