前言
经过前面系列文章的学习,我们的已经理解了SurfaceFlinger运行机制以及同步机制,但是SurfaceFlinger又是以什么方法是把需要刷新的信号发送给App进程的,本文将会和探讨这个问题。
如果遇到问题可以来本文进行讨论:https://www.jianshu.com/p/82c0556e9c76
正文
还记得我写的SurfaceFlinger的第一篇SurfaceFlinger初始化一文里面有探讨过一个十分重要的类EventThread,在EventThread初始化中,持有一个十分核心对象DispSyncSource。而DispSyncSource又持有DispSync。
mEventThreadSource =
std::make_unique(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs,
true, "app");
mEventThread = std::make_unique(mEventThreadSource.get(),
[this]() { resyncWithRateLimit(); },
impl::EventThread::InterceptVSyncsCallback(),
"appEventThread");
mSfEventThreadSource =
std::make_unique(&mPrimaryDispSync,
SurfaceFlinger::sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread =
std::make_unique(mSfEventThreadSource.get(),
[this]() { resyncWithRateLimit(); },
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp);
},
"sfEventThread");
分别创建两个EventThread,一个是名字为sf,一个是app。我在初始化一文就说过,这两个对象在控制着什么时候发送vsync信号。首先来看看DispSync的初始化方法:
dispSyncPresentTimeOffset = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::presentTimeOffsetFromVSyncNs>(0);
mPrimaryDispSync.init(SurfaceFlinger::hasSyncFramework, SurfaceFlinger::dispSyncPresentTimeOffset);
DispSync 初始化
文件:/frameworks/native/services/surfaceflinger/DispSync.cpp
DispSync::DispSync(const char* name)
: mName(name), mRefreshSkipCount(0), mThread(new DispSyncThread(name)) {}
DispSync::~DispSync() {}
void DispSync::init(bool hasSyncFramework, int64_t dispSyncPresentTimeOffset) {
mIgnorePresentFences = !hasSyncFramework;
mPresentTimeOffset = dispSyncPresentTimeOffset;
mThread->run("DispSync", PRIORITY_URGENT_DISPLAY + PRIORITY_MORE_FAVORABLE);
// set DispSync to SCHED_FIFO to minimize jitter
struct sched_param param = {0};
param.sched_priority = 2;
if (sched_setscheduler(mThread->getTid(), SCHED_FIFO, ¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO for DispSyncThread");
}
reset();
beginResync();
if (kTraceDetailedInfo) {
if (!mIgnorePresentFences && kEnableZeroPhaseTracer) {
mZeroPhaseTracer = std::make_unique();
addEventListener("ZeroPhaseTracer", 0, mZeroPhaseTracer.get());
}
}
}
在DispSync中初始化了DispSyncThread线程,并且在init方法中运行起来,并且设置该线程的task_struct处于最高优先级,调用beginResync初始化所有Vsync中的参数。
DispSyncThread 初始化
Android中native中的Thread最后会走到threadLoop中:
virtual bool threadLoop() {
status_t err;
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
while (true) {
Vector callbackInvocations;
nsecs_t targetTime = 0;
{ // Scope for lock
Mutex::Autolock lock(mMutex);
if (kTraceDetailedInfo) {
ATRACE_INT64("DispSync:Frame", mFrameNumber);
}
ALOGV("[%s] Frame %" PRId64, mName, mFrameNumber);
++mFrameNumber;
if (mStop) {
return false;
}
if (mPeriod == 0) {
err = mCond.wait(mMutex);
if (err != NO_ERROR) {
ALOGE("error waiting for new events: %s (%d)", strerror(-err), err);
return false;
}
continue;
}
targetTime = computeNextEventTimeLocked(now);
bool isWakeup = false;
if (now < targetTime) {
if (kTraceDetailedInfo) ATRACE_NAME("DispSync waiting");
if (targetTime == INT64_MAX) {
ALOGV("[%s] Waiting forever", mName);
err = mCond.wait(mMutex);
} else {
ALOGV("[%s] Waiting until %" PRId64, mName, ns2us(targetTime));
err = mCond.waitRelative(mMutex, targetTime - now);
}
if (err == TIMED_OUT) {
isWakeup = true;
} else if (err != NO_ERROR) {
ALOGE("error waiting for next event: %s (%d)", strerror(-err), err);
return false;
}
}
now = systemTime(SYSTEM_TIME_MONOTONIC);
// Don't correct by more than 1.5 ms
static const nsecs_t kMaxWakeupLatency = us2ns(1500);
if (isWakeup) {
mWakeupLatency = ((mWakeupLatency * 63) + (now - targetTime)) / 64;
mWakeupLatency = min(mWakeupLatency, kMaxWakeupLatency);
}
callbackInvocations = gatherCallbackInvocationsLocked(now);
}
if (callbackInvocations.size() > 0) {
fireCallbackInvocations(callbackInvocations);
}
}
return false;
}
-
- 每一次循环都会把mFrameNumber 代表帧数加1.
-
- 如果mPeriod(周期)为0,则进行等待有人通过updateModel方法更新了mPeriod为一个有效的数值,才继续线程的计算。
-
- 每一次执行都会通过computeNextEventTimeLocked计算下一次vsync发送的时间。
-
- 如果目标时间大于当前时间,则会通过Condtion进行等待target时间和now时间差,如果超过最大的int64(也就是long最大数值),则会直接阻塞等待更新。如果当前时间超过目标时间,则需要立即唤醒需要,isWakeup 设置为true。
-
- 每一次计算,都会记录上一次的时间差值。在下一次计算会把当前的差值计算下去,进行一次调整。其实就是把计算出来需要等待的差值获得64分之一保存起来。当下一次获得新的差值,把时间向后推移当前差值63倍数,这样就有最后一份的调整时间,加上下一次的新的差值,就能找到间隔相似的时间点。但是要注意,每一次发送最大不能超过1500ms,超过了就取1500ms。
-
- 在每一次的发送都会计算调整每一个mEventListeners监听的回调时间,只有当前时间大于预期发送时间,才会加入发送集合中,并把时间和回调时间保存在CallbackInvocation。
Vector gatherCallbackInvocationsLocked(nsecs_t now) {
if (kTraceDetailedInfo) ATRACE_CALL();
ALOGV("[%s] gatherCallbackInvocationsLocked @ %" PRId64, mName, ns2us(now));
Vector callbackInvocations;
nsecs_t onePeriodAgo = now - mPeriod;
for (size_t i = 0; i < mEventListeners.size(); i++) {
nsecs_t t = computeListenerNextEventTimeLocked(mEventListeners[i], onePeriodAgo);
if (t < now) {
CallbackInvocation ci;
ci.mCallback = mEventListeners[i].mCallback;
ci.mEventTime = t;
ALOGV("[%s] [%s] Preparing to fire", mName, mEventListeners[i].mName);
callbackInvocations.push(ci);
mEventListeners.editItemAt(i).mLastEventTime = t;
}
}
return callbackInvocations;
}
-
- 如果发现需要发送集合大于0,将会调用fireCallbackInvocations,发送信号回调
void fireCallbackInvocations(const Vector& callbacks) {
if (kTraceDetailedInfo) ATRACE_CALL();
for (size_t i = 0; i < callbacks.size(); i++) {
callbacks[i].mCallback->onDispSyncEvent(callbacks[i].mEventTime);
}
}
那么这个监听是哪里注册的呢?我们稍后解析。mCallback回调就是DispSyncSource,mCallback在这个方法调用onVSyncEvent。这个逻辑我们稍后再看。
让我们回到持有DispSync的对象DispSyncSource。DispSyncSource这个对象只是简单的调用了构造函数,我们需要看看持有DispSyncSource的EventThread对象。
EventThread初始化中DispSync的工作
EventThread::EventThread(VSyncSource* src, ResyncWithRateLimitCallback resyncWithRateLimitCallback,
InterceptVSyncsCallback interceptVSyncsCallback, const char* threadName)
: mVSyncSource(src),
mResyncWithRateLimitCallback(resyncWithRateLimitCallback),
mInterceptVSyncsCallback(interceptVSyncsCallback) {
for (auto& event : mVSyncEvent) {
event.header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
event.header.id = 0;
event.header.timestamp = 0;
event.vsync.count = 0;
}
....
}
EventThread自己本身也是一个线程,它持有一个方法指针,这个方法是SF的resyncWithRateLimit(),该方法实际上就是DispSync中重新设置mPeriod的关键函数。
同时设置初始化了mVSyncEvent每一个时间的类型为DISPLAY_EVENT_VSYNC。mVSyncEvent这个集合大小其实就是Android允许接入的屏幕个数,这个id也是对应屏幕的type类型,在这里是2.
EventThread发送Vsync信号
还记得图元的消费一文中有提到过,当SF执行完queueBuffer方法之后,通过onFrameAvailable回调到MessageQueue::invalidate方法中。这个方法如下:
void MessageQueue::invalidate() {
mEvents->requestNextVsync();
}
接下来会调用如下方法:
void EventThread::requestNextVsync(const sp& connection) {
std::lock_guard lock(mMutex);
if (mResyncWithRateLimitCallback) {
mResyncWithRateLimitCallback();
}
if (connection->count < 0) {
connection->count = 0;
mCondition.notify_all();
}
}
能看到此时就调用了EventThread中持有的mResyncWithRateLimitCallback方法指针,进行Period设定之后,才唤醒EventThread中的阻塞。这个方法就是resyncWithRateLimit。
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::resyncWithRateLimit() {
static constexpr nsecs_t kIgnoreDelay = ms2ns(500);
static nsecs_t sLastResyncAttempted = 0;
const nsecs_t now = systemTime();
if (now - sLastResyncAttempted > kIgnoreDelay) {
resyncToHardwareVsync(false);
}
sLastResyncAttempted = now;
}
这里的方法很简单,其实就是如果两次进行resyncWithRateLimit 同步信号的采样调整时间差小于50纳秒就忽略。
void SurfaceFlinger::resyncToHardwareVsync(bool makeAvailable) {
Mutex::Autolock _l(mHWVsyncLock);
if (makeAvailable) {
mHWVsyncAvailable = true;
} else if (!mHWVsyncAvailable) {
return;
}
const auto& activeConfig = getBE().mHwc->getActiveConfig(HWC_DISPLAY_PRIMARY);
const nsecs_t period = activeConfig->getVsyncPeriod();
mPrimaryDispSync.reset();
mPrimaryDispSync.setPeriod(period);
if (!mPrimaryHWVsyncEnabled) {
mPrimaryDispSync.beginResync();
//eventControl(HWC_DISPLAY_PRIMARY, SurfaceFlinger::EVENT_VSYNC, true);
mEventControlThread->setVsyncEnabled(true);
mPrimaryHWVsyncEnabled = true;
}
}
此时会从HWC的Hal层拿到硬件层中的Vsync周期,并且设置到DispSync。如果,此时主屏幕的HWC的Vsync标志mPrimaryHWVsyncEnabled是挂壁,会通过EventControlThread通过setVsyncEnabled为true。
DispSync setPeriod
void DispSync::setPeriod(nsecs_t period) {
Mutex::Autolock lock(mMutex);
mPeriod = period;
mPhase = 0;
mReferenceTime = 0;
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
}
把周期交给给DispSyncThread.updateModel处理。mPhase,mReferenceTime都设置为0
DispSyncThread updateModel
void updateModel(nsecs_t period, nsecs_t phase, nsecs_t referenceTime) {
if (kTraceDetailedInfo) ATRACE_CALL();
Mutex::Autolock lock(mMutex);
mPeriod = period;
mPhase = phase;
mReferenceTime = referenceTime;
mCond.signal();
}
在updateModel中就会开始唤醒阻塞调整等待时间差的DispSyncThread线程。
EventControlThread setVsyncEnabled
void EventControlThread::threadMain() NO_THREAD_SAFETY_ANALYSIS {
auto keepRunning = true;
auto currentVsyncEnabled = false;
while (keepRunning) {
mSetVSyncEnabled(currentVsyncEnabled);
std::unique_lock lock(mMutex);
mCondition.wait(lock, [this, currentVsyncEnabled, keepRunning]() NO_THREAD_SAFETY_ANALYSIS {
return currentVsyncEnabled != mVsyncEnabled || keepRunning != mKeepRunning;
});
currentVsyncEnabled = mVsyncEnabled;
keepRunning = mKeepRunning;
}
}
在这个线程循环中,会被mCondition阻塞起来,直到currentVsyncEnabled当前设置的状态和mVsyncEnabled不同就会进入下一个循环,调用mSetVSyncEnabled方法。这个方法其实是从SF传进来的SurfaceFlinger::setVsyncEnabled方法指针:
mEventControlThread = std::make_unique(
[this](bool enabled) { setVsyncEnabled(HWC_DISPLAY_PRIMARY, enabled); });
HWC setVsyncEnabled
void SurfaceFlinger::setVsyncEnabled(int disp, int enabled) {
ATRACE_CALL();
Mutex::Autolock lock(mStateLock);
getHwComposer().setVsyncEnabled(disp,
enabled ? HWC2::Vsync::Enable : HWC2::Vsync::Disable);
}
此时调用了HWC的setVsyncEnabled方法,设置了vsync信号是否允许被发出。由于我们已经熟悉整个SurfaceFlinger的Hal层设计,我们直奔其中的Hal层的核心方法:
Error HWC2On1Adapter::Display::setVsyncEnabled(Vsync enable) {
if (!isValid(enable)) {
return Error::BadParameter;
}
if (enable == mVsyncEnabled) {
return Error::None;
}
std::unique_lock lock(mStateMutex);
int error = mDevice.mHwc1Device->eventControl(mDevice.mHwc1Device,
mHwc1Id, HWC_EVENT_VSYNC, enable == Vsync::Enable);
mVsyncEnabled = enable;
return Error::None;
}
本质上就是调用了硬件对接层的eventControl方法指针。
文件:/hardware/qcom/display/msm8960/libhwcomposer/hwc.cpp
这里继续用msm8960的源码看看做了什么。
static int hwc_eventControl(struct hwc_composer_device_1* dev, int dpy,
int event, int enable)
{
int ret = 0;
hwc_context_t* ctx = (hwc_context_t*)(dev);
if(!ctx->dpyAttr[dpy].isActive) {
ALOGE("Display is blanked - Cannot %s vsync",
enable ? "enable" : "disable");
return -EINVAL;
}
switch(event) {
case HWC_EVENT_VSYNC:
if (ctx->vstate.enable == enable)
break;
ret = hwc_vsync_control(ctx, dpy, enable);
if(ret == 0)
ctx->vstate.enable = !!enable;
break;
default:
ret = -EINVAL;
}
return ret;
}
还记得我在SurfaceFlinger的Hal层初始化一文就有解析过,其实vsync是基于一个线程在底层运转,等到硬件发送vsync同步信号后唤醒线程继续发送回调。
当然在hwc_eventControl此时会记录把当前的标志记录在ctx->vstate.enable中。
int hwc_vsync_control(hwc_context_t* ctx, int dpy, int enable)
{
int ret = 0;
if(!ctx->vstate.fakevsync &&
ioctl(ctx->dpyAttr[dpy].fd, MSMFB_OVERLAY_VSYNC_CTRL,
&enable) < 0) {
ret = -errno;
}
return ret;
}
此时会通过ioctl发送一个MSMFB_OVERLAY_VSYNC_CTRL命令,告诉底层GPU是否继续发送vsync。
此时如果是软件模拟vsync,则只是在用户空间创建的一个线程在模拟运作,每一次停止16.666ms后,判断enable标志为,判断是否需要回调到SF中:
do {
if (LIKELY(!ctx->vstate.fakevsync)) {
//阻塞获取硬件发送的vsync信号
...
} else {
usleep(16666);
cur_timestamp = systemTime();
}
// send timestamp to HAL
if(ctx->vstate.enable) {
ctx->proc->vsync(ctx->proc, dpy, cur_timestamp);
}
} while (true);
我们探明了本质上vsync在底层中的暂停和运行机制,那么哪里进行了整个vsync的监听呢?其实在SurfaceFlinger的Hal层初始化已经提到过了。EventThread::requestNextVsync方法中把EventThread的阻塞打开了,将会运行监听添加删除以及监听回调的工作。
Vsync 监听逻辑
EventThread中的线程中有这么一个Looper:
文件:/frameworks/native/services/surfaceflinger/EventThread.cpp
void EventThread::threadMain() NO_THREAD_SAFETY_ANALYSIS {
std::unique_lock lock(mMutex);
while (mKeepRunning) {
DisplayEventReceiver::Event event;
Vector > signalConnections;
signalConnections = waitForEventLocked(&lock, &event);
// dispatch events to listeners...
const size_t count = signalConnections.size();
for (size_t i = 0; i < count; i++) {
const sp& conn(signalConnections[i]);
status_t err = conn->postEvent(event);
if (err == -EAGAIN || err == -EWOULDBLOCK) {
} else if (err < 0) {
removeDisplayEventConnectionLocked(signalConnections[i]);
}
}
}
}
在这个Looper会被waitForEventLocked调用Condition给阻塞起来。
Vector > EventThread::waitForEventLocked(
std::unique_lock* lock, DisplayEventReceiver::Event* event) {
Vector > signalConnections;
while (signalConnections.isEmpty() && mKeepRunning) {
bool eventPending = false;
bool waitForVSync = false;
size_t vsyncCount = 0;
nsecs_t timestamp = 0;
for (int32_t i = 0; i < DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES; i++) {
timestamp = mVSyncEvent[i].header.timestamp;
if (timestamp) {
// we have a vsync event to dispatch
if (mInterceptVSyncsCallback) {
mInterceptVSyncsCallback(timestamp);
}
*event = mVSyncEvent[i];
mVSyncEvent[i].header.timestamp = 0;
vsyncCount = mVSyncEvent[i].vsync.count;
break;
}
}
if (!timestamp) {
// no vsync event, see if there are some other event
eventPending = !mPendingEvents.isEmpty();
if (eventPending) {
*event = mPendingEvents[0];
mPendingEvents.removeAt(0);
}
}
// find out connections waiting for events
size_t count = mDisplayEventConnections.size();
for (size_t i = 0; i < count;) {
sp connection(mDisplayEventConnections[i].promote());
if (connection != nullptr) {
bool added = false;
if (connection->count >= 0) {
waitForVSync = true;
if (timestamp) {
if (connection->count == 0) {
// fired this time around
connection->count = -1;
signalConnections.add(connection);
added = true;
} else if (connection->count == 1 ||
(vsyncCount % connection->count) == 0) {
signalConnections.add(connection);
added = true;
}
}
}
if (eventPending && !timestamp && !added) {
signalConnections.add(connection);
}
++i;
} else {
// we couldn't promote this reference, the connection has
// died, so clean-up!
mDisplayEventConnections.removeAt(i);
--count;
}
}
// Here we figure out if we need to enable or disable vsyncs
if (timestamp && !waitForVSync) {
disableVSyncLocked();
} else if (!timestamp && waitForVSync) {
enableVSyncLocked();
}
if (!timestamp && !eventPending) {
if (waitForVSync) {
bool softwareSync = mUseSoftwareVSync;
auto timeout = softwareSync ? 16ms : 1000ms;
if (mCondition.wait_for(*lock, timeout) == std::cv_status::timeout) {
if (!softwareSync) {
ALOGW("Timed out waiting for hw vsync; faking it");
}
mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[0].header.id = DisplayDevice::DISPLAY_PRIMARY;
mVSyncEvent[0].header.timestamp = systemTime(SYSTEM_TIME_MONOTONIC);
mVSyncEvent[0].vsync.count++;
}
} else {
mCondition.wait(*lock);
}
}
}
return signalConnections;
}
在这个过程中,timestamp为0且waitForVSync为true则会通过enableVSyncLocked打开进行Vsync信号的监听,说明是第一次打开。如果timestamp不为0,且waitForVSync为false,则说明是从打开到关闭的状态,将会调用disableVSyncLocked。
timestamp是记录每一次打开开始之后开始记录每一次Vsync的时间,waitForVSync则是判断是否有外部应用设置监听到EventThread中。有则会为true。
还记得在EventThread::requestNextVsync中唤醒的阻塞的Condition实际上就是这个循环最后的mCondition。
打开阻塞之后,将会到threadMain中,把信号发送出去。
EventThread::enableVSyncLocked
void EventThread::enableVSyncLocked() {
if (!mUseSoftwareVSync) {
// never enable h/w VSYNC when screen is off
if (!mVsyncEnabled) {
mVsyncEnabled = true;
mVSyncSource->setCallback(this);
mVSyncSource->setVSyncEnabled(true);
}
}
mDebugVsyncEnabled = true;
}
如果不是使用软件渲染,则会把EventThread添加一个监听到mVSyncSource也就是DispSyncSource中,并且调用DispSyncSource的setVSyncEnabled。
DispSyncSource setCallback
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void setCallback(VSyncSource::Callback* callback) override{
Mutex::Autolock lock(mCallbackMutex);
mCallback = callback;
}
记住就在这里设置监听了,免得之后找不到了。
DispSyncSource setVSyncEnabled
void setVSyncEnabled(bool enable) override {
Mutex::Autolock lock(mVsyncMutex);
if (enable) {
status_t err = mDispSync->addEventListener(mName, mPhaseOffset,
static_cast(this));
if (err != NO_ERROR) {
ALOGE("error registering vsync callback: %s (%d)",
strerror(-err), err);
}
//ATRACE_INT(mVsyncOnLabel.string(), 1);
} else {
status_t err = mDispSync->removeEventListener(
static_cast(this));
if (err != NO_ERROR) {
ALOGE("error unregistering vsync callback: %s (%d)",
strerror(-err), err);
}
//ATRACE_INT(mVsyncOnLabel.string(), 0);
}
mEnabled = enable;
}
如果允许Vsync的监听,则把DispSyncSource注册到DispSync中,否则则移除出来。
DispSync addEventListener
文件:/frameworks/native/services/surfaceflinger/DispSync.cpp
status_t addEventListener(const char* name, nsecs_t phase, DispSync::Callback* callback) {
if (kTraceDetailedInfo) ATRACE_CALL();
Mutex::Autolock lock(mMutex);
for (size_t i = 0; i < mEventListeners.size(); i++) {
if (mEventListeners[i].mCallback == callback) {
return BAD_VALUE;
}
}
EventListener listener;
listener.mName = name;
listener.mPhase = phase;
listener.mCallback = callback;
listener.mLastEventTime = systemTime() - mPeriod / 2 + mPhase - mWakeupLatency;
mEventListeners.push(listener);
mCond.signal();
return NO_ERROR;
}
实际上很简答,这里就解释了DispSync中threadLoop需要唤醒的监听是从哪里来的,就是在DispSyncSource的setVsyncEnable方法时候,把Callback添加到DispSync的mEventListeners集合中,等待被唤醒。
Vsync监听回调逻辑
让我们把目光集中回DispSync中。当DispSync计算出需要唤醒的时间之后,进行解锁,将会调用如下方法:
void fireCallbackInvocations(const Vector& callbacks) {
if (kTraceDetailedInfo) ATRACE_CALL();
for (size_t i = 0; i < callbacks.size(); i++) {
callbacks[i].mCallback->onDispSyncEvent(callbacks[i].mEventTime);
}
}
而此时的Callback实际上就是DispSyncSource的onDispSyncEvent。
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
virtual void onDispSyncEvent(nsecs_t when) {
VSyncSource::Callback* callback;
{
Mutex::Autolock lock(mCallbackMutex);
callback = mCallback;
if (mTraceVsync) {
mValue = (mValue + 1) % 2;
ATRACE_INT(mVsyncEventLabel.string(), mValue);
}
}
if (callback != nullptr) {
callback->onVSyncEvent(when);
}
}
而这个callback其实就是EventThread注册的回调,也就是EventThread::onVSyncEvent。
EventThread::onVSyncEvent
文件:/frameworks/native/services/surfaceflinger/EventThread.cpp
void EventThread::onVSyncEvent(nsecs_t timestamp) {
std::lock_guard lock(mMutex);
mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[0].header.id = 0;
mVSyncEvent[0].header.timestamp = timestamp;
mVSyncEvent[0].vsync.count++;
mCondition.notify_all();
}
能看到此时会把DispSync通过computeNextEventTimeLocked计算出来Vsync预期需要发送的时间。此时通过mCondition唤醒waitForEventLocked中的阻塞,发送通过socket正在监听EventThread。这一块的逻辑可以阅读,我写的SurfaceFlinger 的初始化一文。
在SurfaceFlinger中有2中EventThread,一种是名为sf的EventThread,一种是名为app的EventThread。
最终在名字为sf的EventThread中最终以Vsync信号到达的基准,执行对应的Handler的回调。
sf的EventThread,我们明白了,那么app的EventThread又是做了什么。这两者又有什么区别呢?
sf的EventThread和app的EventThread的区别
app的EventThread
先来看看app的EventThread:
mEventThreadSource =
std::make_unique(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs,
true, "app");
mEventThread = std::make_unique(mEventThreadSource.get(),
[this]() { resyncWithRateLimit(); },
impl::EventThread::InterceptVSyncsCallback(),
"appEventThread");
vsyncPhaseOffsetNs = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::vsyncEventPhaseOffsetNs>(1000000);
设置了DispSyncSource的的Phase为vsyncPhaseOffsetNs,也就是1000000ns(VSYNC_EVENT_PHASE_OFFSET_NS mk中配置0.002s)。其中EventThread::InterceptVSyncsCallback()是一个空函数,我们不用去管它。
sf的EventThread
再来看看sf中的EventThread的实例化
mSfEventThreadSource =
std::make_unique(&mPrimaryDispSync,
SurfaceFlinger::sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread =
std::make_unique(mSfEventThreadSource.get(),
[this]() { resyncWithRateLimit(); },
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp);
},
"sfEventThread");
mEventQueue->setEventThread(mSFEventThread.get());
sfVsyncPhaseOffsetNs = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::vsyncSfEventPhaseOffsetNs>(1000000);
同理,sf的EventThread的也是基于同一个mPrimaryDispSync也就是DispSync,设置了SF_VSYNC_EVENT_PHASE_OFFSET_NS(mk中的设置0.006s)的phase。
app和sf中设置的10ms的Phase(相位), 就是我在概述中聊到过的两个控制同步信号的Phase。
同时设置了mInterceptor->saveVSyncEvent(timestamp)方法指针到其中进行拦截。而这个方法其实就是记录每一次发送的Vsync到一个SurfaceInterceptor。
唯一和app的EventThread不同的是,SF中的MessageQueue注册了对sf的EventThread的监听。
那么哪里监听了代表了app应用进程的EventThread呢?
App应用监听SF中的appEventThread
Choreographer的初始化
如果熟知View的绘制流程的哥们应该就能清楚,在ViewRootImpl中如何知道什么开始刷新View,其实有一个核心类Choregrapher。这个类,经常出现在我们视野里面。如果阅读Lottie的源码还是性能优化的帧数检测,都是通过注册这个类的监听得到的。监听方法如下:
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
其实,我们猜都能猜到Choreographer肯定是监听了SurfaceFlinger的VSync同步信号。我们来看看Choreographer的构造函数:
文件:/frameworks/base/core/java/android/view/Choreographer.java
是一个单例:
public static Choreographer getInstance() {
return sThreadInstance.get();
}
private static final ThreadLocal sThreadInstance =
new ThreadLocal() {
@Override
protected Choreographer initialValue() {
Looper looper = Looper.myLooper();
if (looper == null) {
throw new IllegalStateException("The current thread must have a looper!");
}
Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);
if (looper == Looper.getMainLooper()) {
mMainInstance = choreographer;
}
return choreographer;
}
};
能看到实际上Choreographer是一个线程本地对象,在其里面实例化了choreographer。这种方式很值得我们学习,这样就没必要使用volatile和synchronized修饰属性和方法。
这种方式可以提高JVM下的性能,因为volatile在解释执行中,判断到属性带了volatile,则会使用order和atomic的模版类修饰Object。如果带了synchronized修饰,则会为方法带上monitor_enter的指令,会对该代码区域进行胖锁瘦锁的策略调整,瘦锁通过scheme简单的切换进程(超过50次没机会获取转化胖锁),胖锁则是通过一个mmap内存映射的锁futex(可以不访问内核)进行上锁。详细等后面有时间开启的JVM源码解析和大家聊聊。
private Choreographer(Looper looper, int vsyncSource) {
mLooper = looper;
mHandler = new FrameHandler(looper);
mDisplayEventReceiver = USE_VSYNC
? new FrameDisplayEventReceiver(looper, vsyncSource)
: null;
mLastFrameTimeNanos = Long.MIN_VALUE;
mFrameIntervalNanos = (long)(1000000000 / getRefreshRate());
mCallbackQueues = new CallbackQueue[CALLBACK_LAST + 1];
for (int i = 0; i <= CALLBACK_LAST; i++) {
mCallbackQueues[i] = new CallbackQueue();
}
// b/68769804: For low FPS experiments.
setFPSDivisor(SystemProperties.getInt(ThreadedRenderer.DEBUG_FPS_DIVISOR, 1));
}
注意这里面有两个核心的类FrameDisplayEventReceiver和FrameHandler,他们共用一个Looper。这两个类才是真正的核心,先来看看FrameDisplayEventReceiver的初始化。
先来看简单的FrameHandler。
private final class FrameHandler extends Handler {
public FrameHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_DO_FRAME:
doFrame(System.nanoTime(), 0);
break;
case MSG_DO_SCHEDULE_VSYNC:
doScheduleVsync();
break;
case MSG_DO_SCHEDULE_CALLBACK:
doScheduleCallback(msg.arg1);
break;
}
}
}
FrameHandler处理了三个消息:
- 1.MSG_DO_FRAME 处理注册在Choreographer 的Runnable
- 2.MSG_DO_SCHEDULE_VSYNC 直接请求下一帧的VSync信号
- 3.MSG_DO_SCHEDULE_CALLBACK 根据Choreographer的配置执行合适的Handler延时处理。
FrameDisplayEventReceiver 初始化
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
这个类基础了DisplayEventReceiver,我们再去看看DisplayEventReceiver的实现。
DisplayEventReceiver 初始化
public DisplayEventReceiver(Looper looper, int vsyncSource) {
if (looper == null) {
throw new IllegalArgumentException("looper must not be null");
}
mMessageQueue = looper.getQueue();
mReceiverPtr = nativeInit(new WeakReference(this), mMessageQueue,
vsyncSource);
mCloseGuard.open("dispose");
}
在这个过程,把MessageQueue设置到native层中,初始化了native层中DisplayEventReceiver。
native中DisplayEventReceiver的初始化
文件:/frameworks/base/core/jni/android_view_DisplayEventReceiver.cpp
static jlong nativeInit(JNIEnv* env, jclass clazz, jobject receiverWeak,
jobject messageQueueObj, jint vsyncSource) {
sp messageQueue = android_os_MessageQueue_getMessageQueue(env, messageQueueObj);
if (messageQueue == NULL) {
jniThrowRuntimeException(env, "MessageQueue is not initialized.");
return 0;
}
sp receiver = new NativeDisplayEventReceiver(env,
receiverWeak, messageQueue, vsyncSource);
status_t status = receiver->initialize();
...
receiver->incStrong(gDisplayEventReceiverClassInfo.clazz); // retain a reference for the object
return reinterpret_cast(receiver.get());
}
在这里实际上就是从MessageQueue中获取native队形设置到NativeDisplayEventReceiver,进行初始化,并调用initialize方法。
DisplayEventDispatcher::DisplayEventDispatcher(const sp& looper,
ISurfaceComposer::VsyncSource vsyncSource) :
mLooper(looper), mReceiver(vsyncSource), mWaitingForVsync(false) {
ALOGV("dispatcher %p ~ Initializing display event dispatcher.", this);
}
status_t DisplayEventDispatcher::initialize() {
status_t result = mReceiver.initCheck();
if (result) {
ALOGW("Failed to initialize display event receiver, status=%d", result);
return result;
}
int rc = mLooper->addFd(mReceiver.getFd(), 0, Looper::EVENT_INPUT,
this, NULL);
if (rc < 0) {
return UNKNOWN_ERROR;
}
return OK;
}
整个方法实际上就是实例化了DisplayEventDispatcher对象,并获取mReceiver中的文件描述符,加入到Looper的监听。而mReceiver就是指DisplayEventReceiver对象,不过这个是在native对应的对象。
DisplayEventReceiver初始化
DisplayEventReceiver::DisplayEventReceiver(ISurfaceComposer::VsyncSource vsyncSource) {
sp sf(ComposerService::getComposerService());
if (sf != NULL) {
mEventConnection = sf->createDisplayEventConnection(vsyncSource);
if (mEventConnection != NULL) {
mDataChannel = std::make_unique();
mEventConnection->stealReceiveChannel(mDataChannel.get());
}
}
}
DisplayEventReceiver::~DisplayEventReceiver() {
}
status_t DisplayEventReceiver::initCheck() const {
if (mDataChannel != NULL)
return NO_ERROR;
return NO_INIT;
}
能看到在DisplayEventReceiver会通过ComposerService获取SurfaceFlinger对应的Binder服务端的代理对象。
- 1.调用createDisplayEventConnection 监听SF的Vsync的事件
- 2.stealReceiveChannel 获取BitTube中接收端的socket 的文件句柄。
我们直接看SurfaceFlinger的createDisplayEventConnection。
SurfaceFlinger的createDisplayEventConnection
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
sp SurfaceFlinger::createDisplayEventConnection(
ISurfaceComposer::VsyncSource vsyncSource) {
if (vsyncSource == eVsyncSourceSurfaceFlinger) {
return mSFEventThread->createEventConnection();
} else {
return mEventThread->createEventConnection();
}
}
其实面向App应用可以注册监听两者Vsync事件,一个是SurfaceFlinger的EventThread,不过这在Choreographer是隐藏的。另一个就是调用mEventThread的createEventConnection,注册一个EventThread::Connection到appEventThread。
从这里开始就可以通过EventThread进行appEventThread的监听,后续的原理可以阅读SurfaceFlinger 的初始化一文。
由于此时把EventThread对应的socket注册到Looper中监听,如果一旦appEventThread有VSync事件来了,将会唤醒Looper的阻塞。
当VSync事件来了将会执行native中MessageQueue的如下代码:
for (size_t i = 0; i < mResponses.size(); i++) {
Response& response = mResponses.editItemAt(i);
if (response.request.ident == POLL_CALLBACK) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
int callbackResult = response.request.callback->handleEvent(fd, events, data);
if (callbackResult == 0) {
removeFd(fd, response.request.seq);
}
response.request.callback.clear();
result = POLL_CALLBACK;
}
}
换句话说就是回调到当前DisplayEventReceiver的handleEvent方法。
DisplayEventReceiver handleEvent接受处理SF的VSync事件
int DisplayEventDispatcher::handleEvent(int, int events, void*) {
...
// Drain all pending events, keep the last vsync.
nsecs_t vsyncTimestamp;
int32_t vsyncDisplayId;
uint32_t vsyncCount;
if (processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount)) {
mWaitingForVsync = false;
dispatchVsync(vsyncTimestamp, vsyncDisplayId, vsyncCount);
}
return 1; // keep the callback
}
bool DisplayEventDispatcher::processPendingEvents(
nsecs_t* outTimestamp, int32_t* outId, uint32_t* outCount) {
bool gotVsync = false;
DisplayEventReceiver::Event buf[EVENT_BUFFER_SIZE];
ssize_t n;
while ((n = mReceiver.getEvents(buf, EVENT_BUFFER_SIZE)) > 0) {
for (ssize_t i = 0; i < n; i++) {
const DisplayEventReceiver::Event& ev = buf[i];
switch (ev.header.type) {
case DisplayEventReceiver::DISPLAY_EVENT_VSYNC:
gotVsync = true;
*outTimestamp = ev.header.timestamp;
*outId = ev.header.id;
*outCount = ev.vsync.count;
break;
case DisplayEventReceiver::DISPLAY_EVENT_HOTPLUG:
dispatchHotplug(ev.header.timestamp, ev.header.id, ev.hotplug.connected);
break;
default:
break;
}
}
}
if (n < 0) {
}
return gotVsync;
}
这段函数会通过processPendingEvents从socket中读取数据出来,并且通过dispatchVsync传递vsync的时间戳,ID,迭代次数等。
NativeDisplayEventReceiver dispatchVsync
void NativeDisplayEventReceiver::dispatchVsync(nsecs_t timestamp, int32_t id, uint32_t count) {
JNIEnv* env = AndroidRuntime::getJNIEnv();
ScopedLocalRef receiverObj(env, jniGetReferent(env, mReceiverWeakGlobal));
if (receiverObj.get()) {
env->CallVoidMethod(receiverObj.get(),
gDisplayEventReceiverClassInfo.dispatchVsync, timestamp, id, count);
}
mMessageQueue->raiseAndClearException(env, "dispatchVsync");
}
能看到实际上就是反射Java层的dispatchVsync方法。
Java层的dispatchVsync
文件:/frameworks/base/core/java/android/view/DisplayEventReceiver.java
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
onVsync(timestampNanos, builtInDisplayId, frame);
}
会继续回调到FrameDisplayEventReceiver中的onVsync回调。
FrameDisplayEventReceiver onVsync
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
if (builtInDisplayId != SurfaceControl.BUILT_IN_DISPLAY_ID_MAIN) {
scheduleVsync();
return;
}
long now = System.nanoTime();
if (timestampNanos > now) {
...
timestampNanos = now;
}
if (mHavePendingVsync) {
...
} else {
mHavePendingVsync = true;
}
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
如果不是主屏幕,则调用scheduleVsync,进行下一帧的请求。如果回调回来的时间比当前大,则timestampNanos直接取当前时间。直接执行sendMessageAtTime,在timestampNanos执行当前的run方法,因为FrameDisplayEventReceiver实现了Runnable。核心是doFrame方法,执行从Choreographer通过postCallback注册进来的Runnable方法。
Choreographer postCallbackDelayedInternal
在Choreographer调用postCallback时候,判断如果需要回调的时间小于当前时间,如果开启了则会走scheduleFrameLocked;如果当前时间大于回调时间,则不需要VSync的回调,立即走FrameHandler逻辑,如下:
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
scheduleFrameLocked(now);
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
scheduleFrameLocked
private void scheduleFrameLocked(long now) {
if (!mFrameScheduled) {
mFrameScheduled = true;
if (USE_VSYNC) {
if (isRunningOnLooperThreadLocked()) {
scheduleVsyncLocked();
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);
mHandler.sendMessageAtFrontOfQueue(msg);
}
} else {
final long nextFrameTime = Math.max(
mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);
Message msg = mHandler.obtainMessage(MSG_DO_FRAME);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, nextFrameTime);
}
}
}
1.如果使用了VSync信号的监听,如果通过isRunningOnLooperThreadLocked判断注册的监听是主线程准确点说是Choreograoher注册的线程,则会走scheduleVsyncLocked。否则通过Handler发送一个MSG_DO_SCHEDULE_VSYNC消息到handler的MessageQueue的顶部。
-
- 如果关闭了VSync信号的监听,则会直接延时10ms发送MSG_DO_FRAME处理下一帧的绘制行为.
private static final long DEFAULT_FRAME_DELAY = 10;
scheduleVsyncLocked
private void scheduleVsyncLocked() {
mDisplayEventReceiver.scheduleVsync();
}
对应的native方法如下:
status_t DisplayEventDispatcher::scheduleVsync() {
if (!mWaitingForVsync) {
// Drain all pending events.
nsecs_t vsyncTimestamp;
int32_t vsyncDisplayId;
uint32_t vsyncCount;
if (processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount)) {
...
}
status_t status = mReceiver.requestNextVsync();
if (status) {
return status;
}
mWaitingForVsync = true;
}
return OK;
}
该方法很简单,只是往SurfaceFlinger请求一个VSync的请求,直到SurfaceFlinger发出回调后,到FrameDisplayEventReceiver的onVSync的onVysnc通过doFrame统一处理应用程序需要刷新界面的时机。
doFrame 处理注册在Choreographer的回调函数
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
return; // no work to do
}
...
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
...
}
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
frameTimeNanos = startNanos - lastFrameOffset;
}
if (frameTimeNanos < mLastFrameTimeNanos) {
scheduleVsyncLocked();
return;
}
if (mFPSDivisor > 1) {
long timeSinceVsync = frameTimeNanos - mLastFrameTimeNanos;
if (timeSinceVsync < (mFrameIntervalNanos * mFPSDivisor) && timeSinceVsync > 0) {
scheduleVsyncLocked();
return;
}
}
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
try {
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
}
}
在doFrame中依次处理了四种不同的类型Runnable:
- 1.CALLBACK_INPUT 处理点击事件的回调
- 2.Choreographer.CALLBACK_ANIMATION 处理动画的回调
- 3.CALLBACK_TRAVERSAL 处理View的绘制流程的回调
- 4.CALLBACK_COMMIT 该处理是View 的绘制流程结束之后,进行的绘制结束后的处理,在这里可以进行绘制延时报告等处理,还有onTrimMemory分发到主线程后在进行回收等。
至此就分析完了整个Vsync的回调流程,如何从SurfaceFlinger回调到app进程。
VSync 推算计算原理
在这个过程中,DispSync有一个十分关键的函数computeNextEventTimeLocked用于计算下一个Vsync信号发送的时间,我们来看看这个方法究竟做了什么。
SurfaceFlinger接收到VSync信号进行采样
不过在推算这个方法之前,我们需要看看SurfaceFlinger接受到硬件的VSync信号的调整函数,回调流程在SurfaceFlinger 的HAL层初始化一文中已经讲解过了,和热插拔的回调流程一致:
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::onVsyncReceived(int32_t sequenceId,
hwc2_display_t displayId, int64_t timestamp) {
Mutex::Autolock lock(mStateLock);
// Ignore any vsyncs from a previous hardware composer.
if (sequenceId != getBE().mComposerSequenceId) {
return;
}
int32_t type;
if (!getBE().mHwc->onVsync(displayId, timestamp, &type)) {
return;
}
bool needsHwVsync = false;
{ // Scope for the lock
Mutex::Autolock _l(mHWVsyncLock);
if (type == DisplayDevice::DISPLAY_PRIMARY && mPrimaryHWVsyncEnabled) {
needsHwVsync = mPrimaryDispSync.addResyncSample(timestamp);
}
}
if (needsHwVsync) {
enableHardwareVsync();
} else {
disableHardwareVsync(false);
}
}
- 1.调用DispSync 的addResyncSample对同步信号进行采样校准
- 2.enableHardwareVsync 在EventControlThread打开Vysnc的开关。
我们主要看addResyncSample的核心原理。
DispSync addResyncSample
文件:/frameworks/native/services/surfaceflinger/DispSync.cpp
enum { MAX_RESYNC_SAMPLES = 32 };
bool DispSync::addResyncSample(nsecs_t timestamp) {
Mutex::Autolock lock(mMutex);
size_t idx = (mFirstResyncSample + mNumResyncSamples) % MAX_RESYNC_SAMPLES;
mResyncSamples[idx] = timestamp;
if (mNumResyncSamples == 0) {
mPhase = 0;
mReferenceTime = timestamp;
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
}
if (mNumResyncSamples < MAX_RESYNC_SAMPLES) {
mNumResyncSamples++;
} else {
mFirstResyncSample = (mFirstResyncSample + 1) % MAX_RESYNC_SAMPLES;
}
updateModelLocked();
if (mNumResyncSamplesSincePresent++ > MAX_RESYNC_SAMPLES_WITHOUT_PRESENT) {
resetErrorLocked();
}
if (mIgnorePresentFences) {
return mThread->hasAnyEventListeners();
}
bool modelLocked = mModelUpdated && mError < (kErrorThreshold / 2);
return !modelLocked;
}
该方法实际上是记录mNumResyncSamples目标当前是周期第几个采样点,同时把mFirstResyncSample除余一次得到此时开始计算的时间点在周期哪里,这些周期是什么意思,等下就明白了。最核心的方法是updateModelLocked进行DispSync的模型的更新。
updateModelLocked DispSync 模型更新的核心方法
在聊这个方法之前,我补充了一点便于理解概念。
我发现有的人曾经试着解释这一段代码的逻辑,但是解释显得有点麻烦。这个方法实际上就是构造一个三角函数一样的函数模型。在聊里面实现细节之前,我们回顾一下简单的初中函数sin 正弦函数的模型。
正弦函数定义:
一般正弦函数:Asin(ωt+Φ)+k
最简单的正弦函数是sin(t),随着时间变化而周期性变化的函数。
我记得,我在模电中第一次接触了和正弦函数表示形式一致的正弦波,其中有几个参数有特殊定义,其中ωt+Φ 就是我们说的相位(phase);Φ就是初相决定函数的左右移动;A是幅度;ω角速度,决定了正弦波的周期(T=2π/|ω|);k代表偏距,控制图像的上下移动;两个同频率(ω相同)正弦波之间相位之差称为相位差。
表示在图里面就是如下:
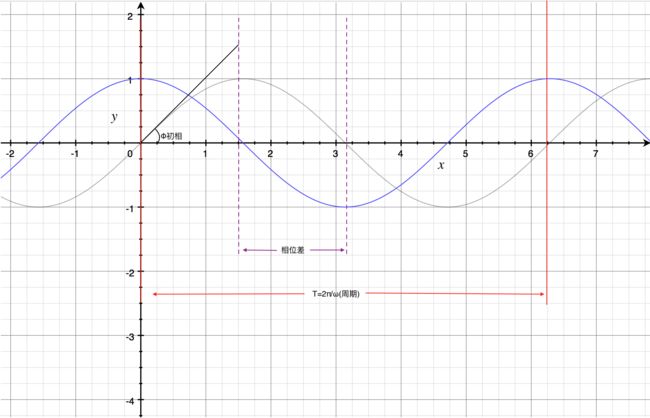
这种特性可以让两个不同正弦波有着不变的相位差,很符合我们appEventThread和sfEventThread的推导。
有了这些概念之后,我们来解析这个函数就简单了。
void DispSync::updateModelLocked() {
if (mNumResyncSamples >= MIN_RESYNC_SAMPLES_FOR_UPDATE) {
nsecs_t durationSum = 0;
nsecs_t minDuration = INT64_MAX;
nsecs_t maxDuration = 0;
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
size_t prev = (idx + MAX_RESYNC_SAMPLES - 1) % MAX_RESYNC_SAMPLES;
nsecs_t duration = mResyncSamples[idx] - mResyncSamples[prev];
durationSum += duration;
minDuration = min(minDuration, duration);
maxDuration = max(maxDuration, duration);
}
durationSum -= minDuration + maxDuration;
mPeriod = durationSum / (mNumResyncSamples - 3);
double sampleAvgX = 0;
double sampleAvgY = 0;
double scale = 2.0 * M_PI / double(mPeriod);
// Intentionally skip the first sample
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
nsecs_t sample = mResyncSamples[idx] - mReferenceTime;
double samplePhase = double(sample % mPeriod) * scale;
sampleAvgX += cos(samplePhase);
sampleAvgY += sin(samplePhase);
}
sampleAvgX /= double(mNumResyncSamples - 1);
sampleAvgY /= double(mNumResyncSamples - 1);
mPhase = nsecs_t(atan2(sampleAvgY, sampleAvgX) / scale);
if (mPhase < -(mPeriod / 2)) {
mPhase += mPeriod;
}
mPeriod += mPeriod * mRefreshSkipCount;
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
mModelUpdated = true;
}
}
我们带入上一段addResyncSample代码,以及图来解释。对于这种线性代数来说,我们使用数学模型无疑能减少理解的难度。
先来看看几个比较重要的宏:
- 1.MAX_RESYNC_SAMPLES 为 32 为采样个数点
- 2.MAX_RESYNC_SAMPLES_WITHOUT_PRESENT 为 4
- 3.MIN_RESYNC_SAMPLES_FOR_UPDATE 为 6
VSync重新采样计算周期
继续思考一个问题,怎么样才能把软件VSync信号的发送间隔或者说周期在整个系统环境中是是相对合理,或者说是正确的。因为硬件到软件是有时间消耗的,软件自己处理也是有时间消耗的,要找到一个适合的周期告诉应用刷新View。不能太快,太快SF处理不过来,或者说能耗过高。太慢了,就导致帧数太低。
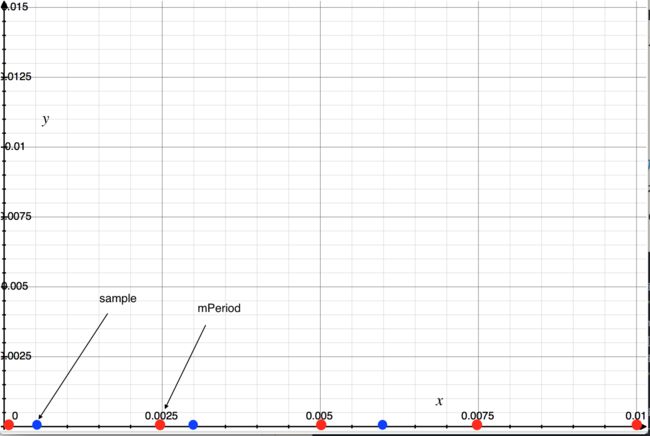
addResyncSample中计算的第一件事情计算mFirstResyncSample 和 mNumResyncSamples。
这两个参数代表了什么含义呢?首先看这两行代码:
size_t idx = (mFirstResyncSample + mNumResyncSamples) % MAX_RESYNC_SAMPLES;
mResyncSamples[idx] = timestamp;
mResyncSamples是存在于DispSync中的缓存64个大小数组,保存每一个VSync后的时间戳。
不难能看出,mResyncSamples的index 是通过:
index = (mFirstResyncSample + mNumResyncSamples) % 32
通过这种方法能看出,其实mResyncSamples的数组就是存储每一次的VSync到达的时间,只存储32份。
用一幅图来表示,实际上就是在这个一次函数中,取32点,如下图:
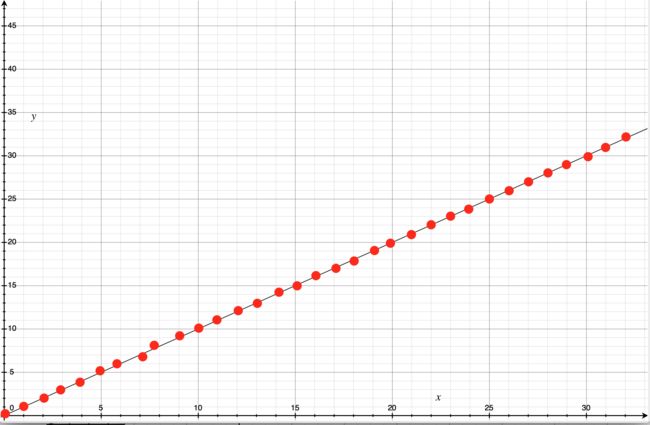
每一次通过设定的周期mPeriod中采样32个点,而且希望实在第一个周期中进行计算。因为在第一个周期中,每一个点就对应上mResyncSamples时间戳数组的下标。
也只有这样才能解释是这样计算的。比如mFirstResyncSample在第一次唤醒VSync是0,mNumResyncSamples也是0,找到mResyncSamples也就是第0次VSync(不存在)和第一次VSync时间差就是0,找到第0个位置把当前时间戳缓存下来。
第二段代码:
if (mNumResyncSamples < MAX_RESYNC_SAMPLES) {
mNumResyncSamples++;
} else {
mFirstResyncSample = (mFirstResyncSample + 1) % MAX_RESYNC_SAMPLES;
}
如果mNumResyncSamples小于32 则mNumResyncSamples = mNumResyncSamples +1;否则则mFirstResyncSample = (mFirstResyncSample + 1)% 32
到这里我们就能理解了mFirstResyncSample和mNumResyncSamples分别代表什么。我们分为2种情况:
-
1.一开始mFirstResyncSample和mNumResyncSamples必定是0.那么每一次递增都会递增mNumResyncSamples。假如此时mNumResyncSamples已经叠加了六次,对应到上图采样点位置如下:
 采样情况一.png
采样情况一.png -
-
不断的递增mNumResyncSamples,如果超出了32个采样点,则会把mFirstResyncSample对应第一周期第一个位置。
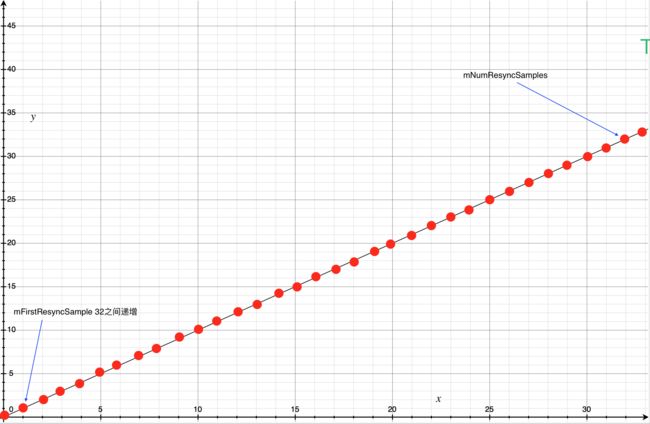 采样情况二.png
采样情况二.png
-
接下来看看updateModelLock,第三段代码:
if (mNumResyncSamples >= MIN_RESYNC_SAMPLES_FOR_UPDATE) {
nsecs_t durationSum = 0;
nsecs_t minDuration = INT64_MAX;
nsecs_t maxDuration = 0;
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
size_t prev = (idx + MAX_RESYNC_SAMPLES - 1) % MAX_RESYNC_SAMPLES;
nsecs_t duration = mResyncSamples[idx] - mResyncSamples[prev];
durationSum += duration;
minDuration = min(minDuration, duration);
maxDuration = max(maxDuration, duration);
}
durationSum -= minDuration + maxDuration;
mPeriod = durationSum / (mNumResyncSamples - 3);
首先mNumResyncSamples要6以上才需要更新。换句话说要VSync要经过5次到来(差不多过了20%)才会进行调整周期。应该是VSync在5次以内,采样起来就很少样本,推算出来的软件周期就不准确。
假如是第一次渲染到第六次,那么这6次过程中,mNumResyncSamples会递增到6,mFirstResyncSample为0.
理想是每一次VSync从硬件到SF,SF从第一次VSync消费到第二次的间隔是一致的,但是实际上是不太可能,这个间隔和当前的CPU环境相关。在第一次的时候,会基于硬件传递上来的VSync周期计算处一个新的软件周期出来。
如下图:

假如要处理第2帧对应的VSync,此时会遍历mResyncSamples中index为1,和0的时间戳,计算两者之间的差值,找到最大的时间差和最小的时间差。并把时间差都累计起来,计算到从第0次到第6次之间总时间差。
总时间差减去最大和最小。新的周期mPeriod的计算如下:
新VSync 软件发送周期 = durationSum / (mNumResyncSamples - 3)
拿到总的时间差除以mNumResyncSamples - 3(因为剔除了最大和最小的时间间隙),其实就是变相找到这6个Vsync采样点时间戳的平均值。
通过这种方法能找到比较合适的软件发送VSync周期,因为硬件发送信号到软件,软件处理完。这是需要一个时间周期,直接使用硬件的VSync的周期是不可取,需要结合当前软件和硬件的运行情况进行动态调整。
VSync重新采样计算相位
到了这里周期算出来了,好像已经完成了整个逻辑了,因为Android已经找到了相对合适的VSync发送周期时间了。一般的工程师到这里的就放弃思考了,但是Google工程做的更加的完备。
我们依照上面,把点都还在一个时间轴上
我们思考一下,如果我们直接把每一次计算好新的软件发送VSync周期作为基准通知SF和App进程。这样会造成什么?我们先把部分的VSync间隔mPeriod周期的点画在时间轴上。
因为硬件发出的VSync 必定是周期性的,我们不妨使用有着类似性质的数学工具正弦函数来看这个计算结果(虽然数学上不严谨,因为VSync并非是连续性的)。
假设硬件发出的VSync 发出的周期,我们把这一整个周期看成一个正弦函数(经过原点,无初相,忽略偏距):
由于硬件发出的VSync的信号要经过内核中断,经过用户空间等一些系列CPU参与的工作必定有一定耗时,同时从当前的VSync到下一次的VSync也有消耗。
那么处理方案有2个:
- 1.扩大周期,也就是进一步减小ω的数值。但是这个方案是不可能的.因为无论如何硬件发出VSync的频率要和软件发出的VSync的频率是一致,不然软硬件处理的时机没办法对应上。
- 2.在ω相等的前提下,增加初相,做一个正弦函数的相位差。换句话说就是延时操作,这样做可以找到CPU处理硬件VSync到软件这一部分的消耗。
说明软件如果需要发送VSync必定带着初相Φ,同时又要和原来的硬件发送的VSync频率几乎相同(因为计算mPeriod是基于硬件VSync发送周期计算),那么,由此可得
软件发送VSync的频率函数=
换句话说,我们求这个Φ(初相)大小。
如下图:

因此有了这一层的数学原理,所以Google工程师会计算两种VSync发送频率的相位差。
再来看第四段代码:
double sampleAvgX = 0;
double sampleAvgY = 0;
double scale = 2.0 * M_PI / double(mPeriod);
// Intentionally skip the first sample
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
nsecs_t sample = mResyncSamples[idx] - mReferenceTime;
double samplePhase = double(sample % mPeriod) * scale;
sampleAvgX += cos(samplePhase);
sampleAvgY += sin(samplePhase);
}
sampleAvgX /= double(mNumResyncSamples - 1);
sampleAvgY /= double(mNumResyncSamples - 1);
mPhase = nsecs_t(atan2(sampleAvgY, sampleAvgX) / scale);
scale = 2 * PI / mPeriod
实际上就是把 2 * PI切分成已经动态获取到的周期切割成360份,比如mPeriod动态计算后是16ms,那么scale代表 360 / 16,1ms代表22度。
mReferenceTime 代表第一帧进来硬件的VSync时间戳,作为之后所有VSync的时间基础。
首先先跳开第一次VSync的时间。遍历后面的VSync对应的时间。这里实际上是计算每一次VSync的时间和调用addResyncSample保存当前时间的mReferenceTime。
样本相对时间戳sample = mResyncSamplesindex - mReferenceTime(第一次硬件VSync时间)
这里理解起来有点困难。sample的计算实际上是告诉我们当前的时间点和第一次硬件VSync的差。这是一个校准的过程,这样就能保证计算出来的结果都是基于第一次VSync的硬件发送时间为基准。如果mReferenceTime记录上一次软件的VSync会把上一次的软件运行误差一起记录下来。
samplePhase又是什么意思呢?记住在这个过程中两个角色:
- 1.真实的VSync发送时间点
- 2.经过均值化后,理想的VSync发送的时间点。
下图中,红色点是均值化后理想的发送时机,蓝色的点是真正的VSync时机
实际上每一次请求VSync周期和均值周期是有偏差的,我们来找找看这个偏差数值比起一个周期mPeriod偏移了多少,如果能求出前后两次软件发送VSync请求偏移量的均值,就说明我们能够找到在当前CPU环境下软件发送前后两次VSync在CPU中消耗了多少。
换句话说,我们就找到了软件VSync应该理想下应该距离硬件发送VSync的时间点。
因此samplePhase的计算法则其实就是把时间转化为角度(前面已经求出1ms是多少度):
样本相位samplePhase = (sample % mPeriod) * scale
sample % mPeriod代表当前距离第一次硬件发送上来的VSync有多少个周期了,同时余数在mPeriod的哪个位置,最后乘以度数就能得到当前的样本相位。
接下来这一段要这么看:
for (size_t i = 1; i < mNumResyncSamples; i++) {
....
sampleAvgX += cos(samplePhase);
sampleAvgY += sin(samplePhase);
}
sampleAvgX /= double(mNumResyncSamples - 1);
sampleAvgY /= double(mNumResyncSamples - 1);
mPhase = nsecs_t(atan2(sampleAvgY, sampleAvgX) / scale);
能看到本质上就是找到每一个采样点,也就是获取每一次软件VSync的偏差角度,求其平均值。由于角度的计算特殊,所以使用了atan的方式进行计算。
换算过程图里面如下
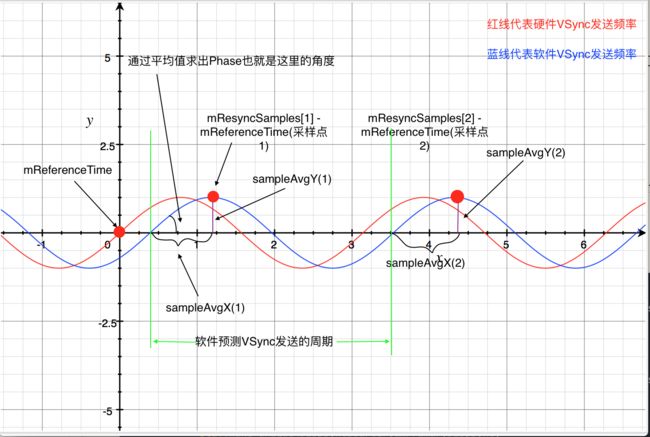
记住我们是不知道蓝色的先是长什么样子的,其实是只有红色点独立在坐标中,这里只是为了好理解才画出来。只有经过计算了mPhase,已知硬件VSync频率的角速度,我们就可以画出蓝色曲线。
其实在这里我们可以这里理解,应该每一次VSync发送的点就是在这个周期上的某一个点左右,这样我们能够通过计算出mPhase来得到新的phase也就是对应Φ初相。
当x为0的时候,就能找到距离原点的距离(也就是距离mReferenceTime位置)。但是我们需要的是时间,因此需要如下的计算得到从角度转化回真实的时间:
DispSync computeNextEventTimeLocked
文件:/frameworks/native/services/surfaceflinger/DispSync.cpp
nsecs_t computeNextEventTimeLocked(nsecs_t now) {
if (kTraceDetailedInfo) ATRACE_CALL();
ALOGV("[%s] computeNextEventTimeLocked", mName);
nsecs_t nextEventTime = INT64_MAX;
for (size_t i = 0; i < mEventListeners.size(); i++) {
nsecs_t t = computeListenerNextEventTimeLocked(mEventListeners[i], now);
if (t < nextEventTime) {
nextEventTime = t;
}
}
return nextEventTime;
}
在这个方法中会为每一个加入到DispSync监听的对象通过computeListenerNextEventTimeLocked计算下一次应该发送的Vsync的时间点。
nsecs_t computeListenerNextEventTimeLocked(const EventListener& listener, nsecs_t baseTime) {
nsecs_t lastEventTime = listener.mLastEventTime + mWakeupLatency;
if (baseTime < lastEventTime) {
baseTime = lastEventTime;
}
baseTime -= mReferenceTime;
nsecs_t phase = mPhase + listener.mPhase;
baseTime -= phase;
if (baseTime < 0) {
baseTime = -mPeriod;
}
nsecs_t numPeriods = baseTime / mPeriod;
nsecs_t t = (numPeriods + 1) * mPeriod + phase;
t += mReferenceTime;
if (t - listener.mLastEventTime < (3 * mPeriod / 5)) {
t += mPeriod;
}
t -= mWakeupLatency;
return t;
}
理解了上述VSync是怎么进行周期和相位计算的,理解这里就很简单了。VSync周期是分为32份进行管理的,这里mWakeupLatency也就是添加了一个唤醒延时,这个延时就是VSync周期中每一份的1/2作为开销。
如果当前的时间比上一次的唤醒时间加上唤醒开销都要小,则取
listener.mLastEventTime + mWakeupLatency
记住这里的listener是什么呢?实际上就是appEventThread中的DispSyncSource以及sfEventThread中的DispSyncSource,也就是上文中设置setVsyncEnable进来的。
这里的计算是和常规的思路是反过来的,对应整个Android系统来说,首先注册了sf的DispSyncSource,之后App应用启动后,才注册了app的DispSyncSource。
baseTime是DispSync初始化线程时间。
- 1.baseTime = baseTime - mReferenceTime 以第一次硬件发送VSync时间校准了。
- 2.第一次phase = mPhase(软件VSync的相位偏移) + listener.mPhase,这个时候加的是sf的偏移量0.01s。同时baseTime 向前推移phase,找到没有偏移影响的基础时间。
- 3.如果baseTime校准异常,则baseTime -= mPeriod
- 4.查看当前baseTime 在哪一个VSync周期中,找到下一个周期并且加上偏移量就是下一次VSync发送时机,记住要加上mReferenceTime这个基准点。
- 5.如果算出来的预期时间比上次的发送Vsync时间小于3/5个周期,则说明本次时机和原来VSync的时机太接近,应该放到下一个周期。
- 6.预期时间最后还要记得,减掉唤醒时间。
- 7.第二次循环后,listener变成了app的EventThread。
那么appEventThread和sfEventThread的相位是怎么出来的呢?其实就是每一个listener的mPhase设置的0.002s和0.006s。
跳帧的计算原理
我们熟悉了VSync的计算原理以及预期计算原理之后,我们其实可以发现在SF消费阶段,有一个跳帧处理,我们来看看。
文件:/frameworks/native/services/surfaceflinger/BufferLayerConsumer.cpp
nsecs_t BufferLayerConsumer::computeExpectedPresent(const DispSync& dispSync) {
const uint32_t hwcLatency = 0;
const nsecs_t nextRefresh = dispSync.computeNextRefresh(hwcLatency);
nsecs_t extraPadding = 0;
if (SurfaceFlinger::vsyncPhaseOffsetNs == 0) {
extraPadding = 1000000; // 1ms (6% of 60Hz)
}
return nextRefresh + extraPadding;
}
文件:/frameworks/native/services/surfaceflinger/DispSync.cpp
nsecs_t DispSync::computeNextRefresh(int periodOffset) const {
Mutex::Autolock lock(mMutex);
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
nsecs_t phase = mReferenceTime + mPhase;
return (((now - phase) / mPeriod) + periodOffset + 1) * mPeriod + phase;
}
这个方法就是计算核心,periodOffset首先是0.
计算当前的时间和软件开始发送VSync之间差除以mPeriod从而找到是第几个的VSync周期,拿到下一个周期加回原来的因计算减去的软件Vsync相位,同时加上appEventThread的相位。
下一帧显示时间 = 软件VSync下一次发送时间点 + appEventThread的相位偏移。
到这里就把整个VSync的计算原理全部解析了一遍。
总结
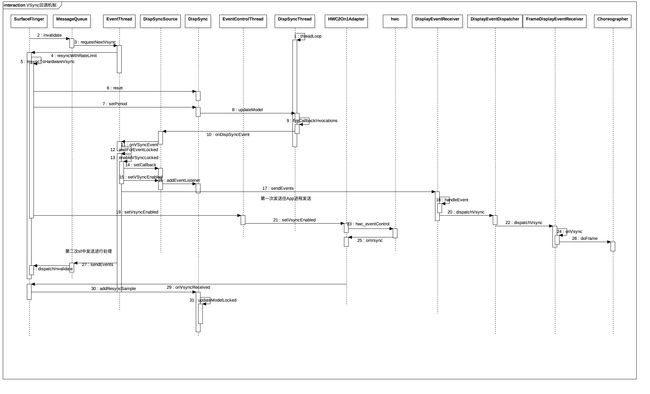
老规矩,我们先上一副时序图来总结VSync的发送与监听流程。
VSync和Fence都是SF中的同步机制。可以说,两者都是SF渲染机制的核心。不过两者之间的角色不一样。
Fence的要旨是控制GraphicBuffer的状态,是否允许工作,因为Fence是一段共享内存,很可能被多个进程修改,维护的是GraphicBuffer资源的资源竞争的问题,保证资源一次只被一个进程绘制。
VSync的要旨是协调硬件,软件之间工作的时序性,如下图:
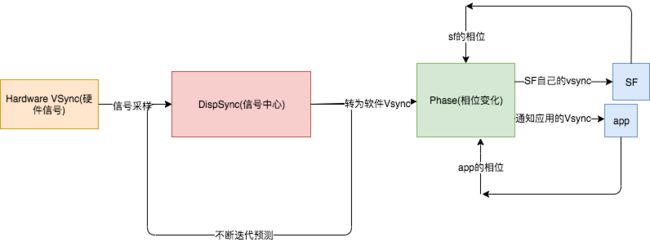
为什么需要拿到硬件VSync发送周期后,动态计算软件的VSync周期呢(当时间不足的时候,进行阻塞)?原因很简单,实际上就是因为VSync从硬件触发后,途径内核,SF的处理会有一定的消耗,所以软件发送VSync需要一定的延时,周期也会比原来硬件VSync的大一点(近似相等)。
软件发送VSync的周期是怎么计算的呢?会把每一次VSync存储在一个大小为32的采样数组中。每一次取出6个采样点,取出间隔最大和最小,找到这个6个点的平均间隔,这就是软件发送VSync周期。
软件发送VSync的延时是怎么计算的呢?
会把每一次VSync采样点和刚才计算的软件发送周期进行比对。按照道理采样点应该和软件发送周期是吻合的,但是出现了偏差,Google工程师认为这就是软件消耗的时间。那么这个消耗的时间同样可以作为整个周期性函数的初相,也就是和硬件发送VSync周期函数的偏移量(相位差)。
VSync请求发送时候,是怎么推算下一次分发VSync呢?
我们通过上面两个条件计算出了,关键的两个参数,相位和周期,就能通过当前的时间点所属的周期往后推一个点,那个点就是VSync下一次发送的时间。
SF是怎么进行跳帧处理呢?
因为每一次App应用的View绘制流程都是等到VSync进行刷新的。那么每一次VSync时间必定和GraphicBuffer入队时间是相对应。因此只需要推算出下一个周期的VSync加上appEventThread的相位偏移,就能找到预计显示的时间。
为了避免SF进程和app进程之间处理VSync之间工作时序出现异常,如下图:
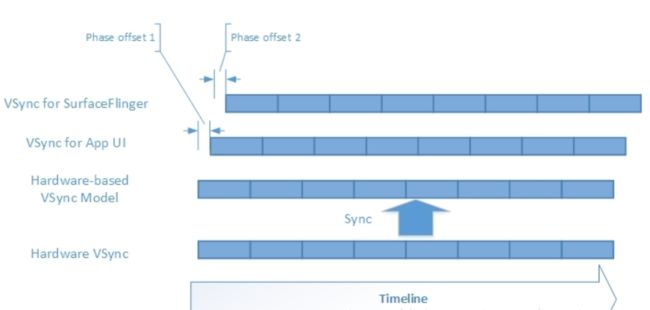
这两个时间差是以硬件传递过来的VSync周期为基准,计算出软件的周期和延时。再以软件的延时相位为基准,app和sf向后延时一段各自固定的时间。
为什要做这两个EventThread处理的事件,先来看看各自做了什么:
- 1.app 进程接收到VSync,开始进行View的构建,最后把GraphicBuffer交给SF处理。
- 2.sf进程则是收到VSync之后,采集足够的样本,重新计算当前的周期和相位。
无论是哪一方当做完当前的事件之后会调用requestNextVsync,请求下一次VSync。最后计算出预期VSync的那个,选出最小的那个最为下一次DispSync发出VSync时机。
app以VSync信号为基准刷新View把GraphicBuffer交给SF处理。VSync的周期又是根据前后两次计算的。如果VSync周期太大了,就会导致app刷新太慢。因此软件发送VSync周期的计算是把app刷新的CPU开销一起计算进来。因此必须先完成app对应的VSync信号,才能处理SF的VSync重新调整周期。不然会得到一个不是很准确的VSync周期。
假如没有这个相位差,会发生什么?sf一定比app快(因为处于task最高优先级的FIFO队列中)。这样就是出现SF提前进行VSync计算,计算平局值没算入app绘制消耗。导致了周期计算失误,同时在推算下一个VSync的时候,会提前点。导致第一帧还没算完,就要准备显示第二帧造成类似下图jank的情况。
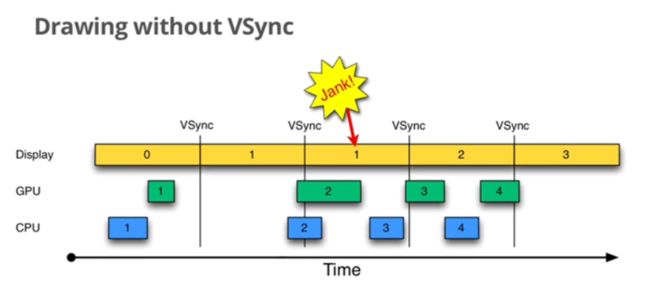
不过,一般的jank是因为绘制一帧的事件太长,导致后面的帧全部造成延时。而VSync的相位混淆,则是因为VSync软件周期太短了,导致GraphicBuffer多显示了一个VSync周期。
第二次讨论多缓冲中的作用
为了避免在VSync模型的jank异常,SF使用了多缓冲(多GraphicBuffer)方式进行处理
纵览对应整个SF并行模型:

App进程通过Surface的图元生产者的dequeue获取GraphicBuffer,在方法waitForFreeSlotThenRelock从mFreeSlots和mFreeBuffer中分配Buffer时候有这么一段:
const int maxBufferCount = mCore->getMaxBufferCountLocked();
bool tooManyBuffers = mCore->mQueue.size()
> static_cast(maxBufferCount);
if (tooManyBuffers) {
BQ_LOGV("%s: queue size is %zu, waiting", callerString,
mCore->mQueue.size());
} else {
...
}
换句话说每一次分配都校验,当前消费的缓冲队列中是否大于了maxBufferCount。而这个maxBufferCount是通过getMaxBufferCountLocked获取的。
int BufferQueueCore::getMaxBufferCountLocked() const {
int maxBufferCount = mMaxAcquiredBufferCount + mMaxDequeuedBufferCount +
((mAsyncMode || mDequeueBufferCannotBlock) ? 1 : 0);
maxBufferCount = std::min(mMaxBufferCount, maxBufferCount);
return maxBufferCount;
}
注意这里面mMaxDequeuedBufferCount,就是SF判断是否打开了3重缓冲开关时候获取的,关闭则设置2,打开则设置默认1.
if (mFlinger->isLayerTripleBufferingDisabled()) {
mProducer->setMaxDequeuedBufferCount(2);
}
为什么会这样呢?因为9.0抛弃了三重缓冲,改用动态缓冲。实际上我们可以看看4.4的源码:
#ifdef TARGET_DISABLE_TRIPLE_BUFFERING
#warning "disabling triple buffering"
mSurfaceFlingerConsumer->setDefaultMaxBufferCount(2);
#else
mSurfaceFlingerConsumer->setDefaultMaxBufferCount(3);
#endif
4.4很粗暴的直接设置了消费者消费的数量。而在9.0的源码中,当Surface进行connect的时候就会开始调整可分配的mSlot插槽的数量:
int delta = mCore->getMaxBufferCountLocked(mCore->mAsyncMode,
mDequeueTimeout < 0 ?
mCore->mConsumerControlledByApp && producerControlledByApp : false,
mCore->mMaxBufferCount) -
mCore->getMaxBufferCountLocked();
if (!mCore->adjustAvailableSlotsLocked(delta)) {
return BAD_VALUE;
}
通过当前的模式计算出最大需要多少的图元,和当前的图元最大的图元相比。进行调整,大了则扩容到mSlots;小了则缩容量,多余放到mUnusedSlots中。动态的扩充可申请容量比起原来的粗暴设置多缓冲,显得优化的更多性能。
后话
到这里SurfaceFlinger的全系列文章已经结束了,从12月末尾一直写到现在,耗时近3个月。我也在大大小小的细节品味了一次高版本的渲染原理。比起低版本性能上确实优化了很多。我也学习很多之前没有接触过知识,就差没有拿出一个GPU的内核模块源码进行分析。可以说应该是目前全网最全的解剖源码了。
但是学习到这个地步,你就精通了SurfaceFlinger吗?不,并没有。最多算是熟悉,这仅仅只是一个开始,SurfaceFlinger只是展露了冰山一角,还有很多内容没有和大家聊,如DataSpace是如何运作,GraphicBuffer中HDR映射的句柄又是什么东西又是怎么运作的,还有GPU底层irq,同步栅是如何唤醒等等。
但是对应一个中级的应用开发工程师就足够了。特别是需要经常接触音视频开发的工程师,这些东西都是必须懂得的。不然写不出好代码。
不知道VSync原理,不知道dequeue原理,你会发现如果音视屏生产者过快会造成jank的效果,甚至因为dequeue动态调整的slot的问题可能出现丢帧等各种各样的问题。甚至不知道OpenGL es的swapBuffer在Android中实际上做的是dequeue和queue的工作,和Canvas.lock以及unlockAndPost一样的工作。
闲话就不多说了,之后可能会暂时停笔一小段时间,因为有一个比较感兴趣的业务接下来做了,对我来说也是一个挑战。等下一段的开始,就是和大家聊聊Skia的源码和大家熟知的View的绘制流程。有了这个基础,我就可以横向比对flutter engine中是如何渲染画面,比较双方的优劣。