数据结构与算法--概述及基础知识储备
文章目录
- 概述
- 数据结构与算法定义
- 衡量算法好坏的标准以及效率度量
- 好坏标准
- 效率度量
- 时间复杂度
- 空间复杂度
- 时间复杂度 vs 空间复杂度
- 预备知识
- 1、指针
- **1)指针**
- **2)指针和数组**
- **2、结构体**
- **3、动态内存的分配和释放**
概述
数据结构与算法定义
我们如何把现实中大量存在而复杂的问题以**特定的数据类型**和**特定的存储结构**保存到主存储器(内存)中,以及在此基础上为实现某个功能(例如:查找某个元素、删除某个元素,对所有元素进行排序)而执行的相应操作,这个相应的操作叫算法。
数据结构 =>个体+个体的关系
算法 => 对存储数据的操作
即解决两个问题——个体如何保存?个体与个人之间的关系是怎么保存的?
是解题的方法和步骤
衡量算法好坏的标准以及效率度量
好坏标准
1、时间复杂度——程序要执行的次数,而非执行时间
2、空间复杂度——算法执行过程中大概所占用的最大内存
3、难易程度——别人是否能看懂你的程序
4、健壮性——当程序进行一些非法输入时,程序是否会崩溃
效率度量
1、算法采用的策略和方案
2、编译产生的代码质量
3、问题的输入规模
4、机器执行指令的速度
时间复杂度
1、定义
非用运行时间去度量,而是用运行时进行的基本操作执行次数来度量
2、计算方法:大O推导法
(1)用常数 1 取代运行时间中的所有加法常数
(2)在修改后的运行次数函数中,只保留最高阶项
(3)如果最高阶项存在且不是 1,则去除与这个项相乘的常数,得到的结果就是大 O 阶
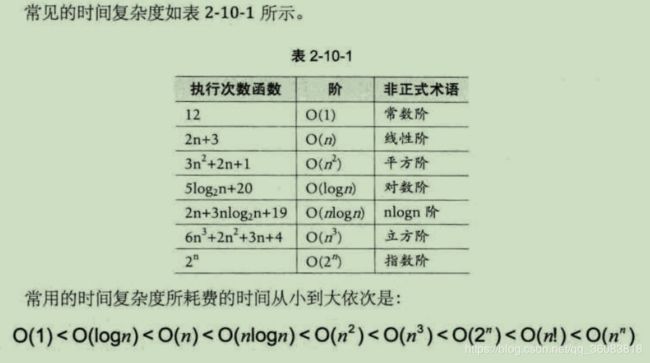
3、大O阶大小比较
(1)可以忽略加法常数
O(2n + 3) = O(2n)
(2)与最高次项相乘的常数可忽略
O(2n^2) = O(n^2)
(3) 最高次项的指数大的,函数随着 n 的增长,结果也会变得增长得更快
O(n^3) > O(n^2)
(4)判断一个算法的(时间)效率时,函数中常数和其他次要项常常可以忽略,而更应该关注主项(最高阶项)的阶数
O(2n^2) = O(n^2+3n+1)
O(n^3) > O(n^2)
4、常见时间复杂度:
空间复杂度
1、定义
算法的空间复杂度通过计算算法所需的存储空间实现,即运行完一个程序所需内存的大小
2、空间复杂度的计算
利用程序的空间复杂度,可以对程序的运行所需要的内存多少有个预先估计
一个算法所需的存储空间用f(n)表示
空间复杂度的计算公式记作:S(n)=O(f(n))
其中n为问题的规模
S(n)表示空间复杂度
(1)忽略常数,用O(1)表示
(2)递归算法的空间复杂度=递归深度N*每次递归所要的辅助空间
(3)对于单线程来说,递归有运行时堆栈,求的是递归最深的那一次压栈所耗费的空间的个数
因为递归最深的那一次所耗费的空间足以容纳它所有递归过程
一般情况下,一个程序在机器上执行时:
除了需要存储程序本身的指令,常数,变量和输入数据外
还需要存储对数据操作的存储单元的辅助空间
若输入数据所占空间只取决于问题本身,和算法无关
这样就只需要分析该算法在实现时所需的辅助单元即可。若算法执行时所需的辅助空间相对于输入数据量而言是个常数,则称此算法为原地工作,空间复杂度为O(1)
3、需存储的空间
1)固定部分
这部分属于静态空间
这部分空间的大小与输入/输出的数据的个数多少、数值无关
主要包括指令空间(即代码空间)、数据空间(常量、简单变量)等所占的空间
(2)可变空间
这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等
这部分的空间大小与算法有关
时间复杂度 vs 空间复杂度
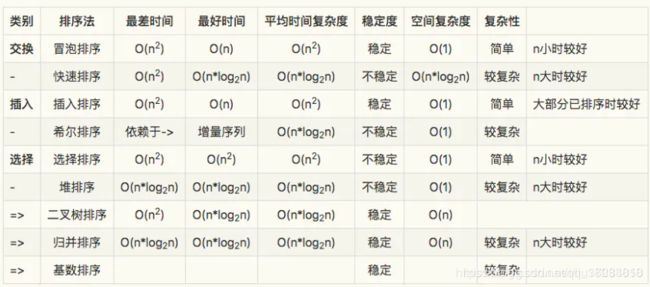
1、算法的时间复杂度和空间复杂度是可以相互转化的
2、常用的算法的时间复杂度和空间复杂度
预备知识
1、指针
1)指针
指针就是地址,地址就是指针。
指针的本质是一个操作受限的非负整数。(虽说是整数,但不能用来做加减乘除运算)
指针变量:存放内存单元地址的变量。
指针的重要性:表示一些复杂的数据结构
快速的传送数据
使函数返回一个以上的值
能否直接访问硬件
能够方便的使用数组和字符串
是理解面向对象语言中引用的基础
指针是C语言的灵魂。

#include ①P保存i的地址,p就指向i(*p和i是一个东西)
②修改p的值不影响i的值,修改i的值不影响p的值。
③*p 是i
一个指针变量,无论其指向的变量占几个字节,其自身都是占4个字节。(一个字节一个地址)
无论什么类型的变量,实参,返回类型又是void,若想修改其值,**参数必须是其地址**。
注意:
指针变量也是变量,只不过它存放的不能是内存单元的内容,只能存放内存单元的地址
普通变量前不能加*
常量和表达式前不能加&
#include 如何通过被调函数修改主调函数中普通变量的值
Ⅰ 实参(主函数里调用时)为相关变量的地址
Ⅱ 形参为以该变量的类型为类型的指针变量
Ⅲ 在被调函数中通过 ** 形参变量名* 的方式就可以修改主函数相关变量的值
=>将实参中的地址传递给形参
2)指针和数组
指针 和 一维数组
数组名
一维数组名是个指针常量,
它存放的是一维数组第一个元素的地址,
它的值不能被改变
**一维数组名指向的是数组的第一个元素**
下标和指针的关系
a[i] <<==>> *(a+i)
#include 
假设指针变量的名字为p
则p+i的值是p+i*(p所指向的变量所占的字节数)
**指针变量的运算**
指针变量不能相加,不能相乘,不能相除
如果两指针变量属于同一数组,则可以相减
指针变量可以加减一整数,前提是最终结果不能超过指针允许指向的范围
p+i的值是p+i*(p所指向的变量所占的字节数)
p-i的值是p-i*(p所指向的变量所占的字节数)
p++ <==> p+1
p-- <==> p-1
如何通过被调函数修改主调函数中一维数组的内容【如何界定一维数组】
**需要确定两个参数**
存放数组首元素的指针变量
存放数组元素长度的整型变量
#include 2、结构体
为什么会出现结构体:
为了表示一些复杂的数据,而普通的基本类型变量无法满足要求
什么叫结构体
结构体是用户根据自己需要自己定义的复合数据类型
如何使用结构体
注意事项
区别Java里的“类”与“结构体”
class Student
{
int sid;
String name;
int sage; //定义数据类型
void inputStudent()
{
}
void outputStudent()
{
} //具体操作
}
//java的“类”,包含定义的数据类型和操作
struct Student
{
int sid;
String name;
int sage; //定义数据类型
};
//结构体只包含一系列自定义的数据类型
例①:
#include #include 3、动态内存的分配和释放
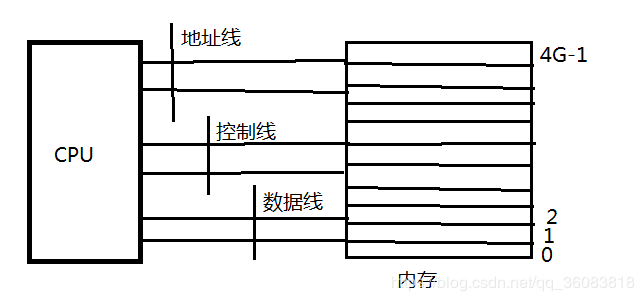
内存是CPU唯一可以直接访问的大容量存储区域,CPU只能访问内存,不能访问硬盘。
1、地址线:对哪个编号(地址)的单元进行操作 0-(4G-1):32位的电脑,2(32)-1=4G
地址:内存单元的编号
从0开始的非负整数,范围0-FFFFFFFF 0-(4G-1)
可以将地址看做一种数据类型,其int *或是String *
2、控制线:决定读还是写,只读或是只写
3、数据线:数据的双向传输。
**传统数组的缺点:**(传统数组即静态数组)
1、数组的长度必须事先制定,且只能是常整数,不能为变量
eg:
int a[5]; //ok
int len = 5; int a[len]; //error
2、传统形式定义的数组,该数组的内存,程序员无法手动释放。因此在一个函数运行期间,系统为该函数中的数组所分配的空间会一直存在。**直到函数运行完毕时,数组的空间才会被系统释放。**
3、数组的长度一旦被定义,其长度就不能再更改。
数组的长度不能在函数运行过程中动态地扩充或缩小。
4、A函数定义的数组,在A函数运行期间可以被其他函数使用,但在A函数运行完毕之后,A函数中的数组将无法被其他函数使用。
传统方式定义的数组不能跨函数使用。
**为什么要动态分配内存:**
1、动态分配内存很好地解决了传统数组的这四个缺陷
2、传统数组即静态数组
**动态数组的构造**
eg:
假设动态构造一个int型一维数组:
int *p = (int *)malloc(int len);
1、malloc是memory(内存)allocate(分配)的缩写
2、头文件添加# include
3、malloc函数只有一个形参,形参是整型
4、形参表示请求系统为程序分配的字节数
5、malloc函数只能返回第一个字节的地址 ,再通过强制类型转换,告诉分配的类型占几个字节,例如int 占4个,char占1个
6、p本身占4个字节,是静态的;p所指向的8个字节,是动态的
7、动态内存可以直接free(指针)掉 ,p本身的内存函数结束才自动释放
动态内存分配举例:
//动态地构造一维数组
int len;
printf("请输入需要构造的数组长度:");
scanf("%d",&len);
int * arr= (int *)malloc(4*len);
//对一维数组操作:赋值
printf("请输入数组的元素:");
for (i = 0;i<len;i++)
{
scanf("%d",&*(arr+i));
}
//输出
for (i = 0;i<len;i++)
{
printf("%d\n",*(arr+i));//也可以写成arr[i]
}
#include 5、realloc(数组名,字节数):可以重定义已有的动态数组
静态内存和动态内存的比较
静态内存由系统自动分配,自动释放;
静态内存是在栈分配的
动态内存由程序员手动分配,手动释放
动态内存是在堆分配的
6、跨函数使用内存的问题
1、静态变量不可以跨函数使用内存
2、动态内存可以跨函数使用