Drools从入门到精通之KIE
KIE即Knowledge Is EveryThing的缩写
KIE包含以下不同但相关的项目,为业务自动化和管理提供完整的解决方案组合:
-
Drools是一个业务规则管理系统,具有前向链接和后向链接推理的规则引擎,允许快速可靠地评估业务规则和复杂的事件处理。规则引擎也是创建专家系统的基本构建块,在人工智能中,该专家系统是模拟人类专家的决策能力的计算机系统。
-
jBPM是一个灵活的业务流程管理套件,允许您通过描述为实现这些目标而需要执行的步骤来建模您的业务目标。
-
OptaPlanner是一种约束求解器,可优化员工排班,车辆路径,任务分配和云优化等用例。
-
Business Central是一个功能齐全的Web应用程序,用于自定义业务规则和流程的可视化组合。
-
UberFire是一个基于Web的工作台框架,受Eclipse富客户端平台的启发

Kie项目具有普通Maven项目的结构,其唯一的特点是包含一个kmodule.xml文件,以声明方式从中定义并创建KieBases和KieSessions。kmodule.xml必须放在Maven项目的resources / META-INF文件夹中,而所有其他Kie工件(如DRL或Excel文件)必须存储在resources文件夹或其下的任何其他子文件夹中。
空的kmodule.xml文件
通过这种方式,kmodule将包含一个默认的KieBase。存储在resources文件夹或其任何子文件夹下的所有Kie Resources都将被编译并添加到其中。要触发构建这些工件,通过KieContainer为它们创建一个内部容器。

通过下面的代码可以从类路径中读取要构建的文件。
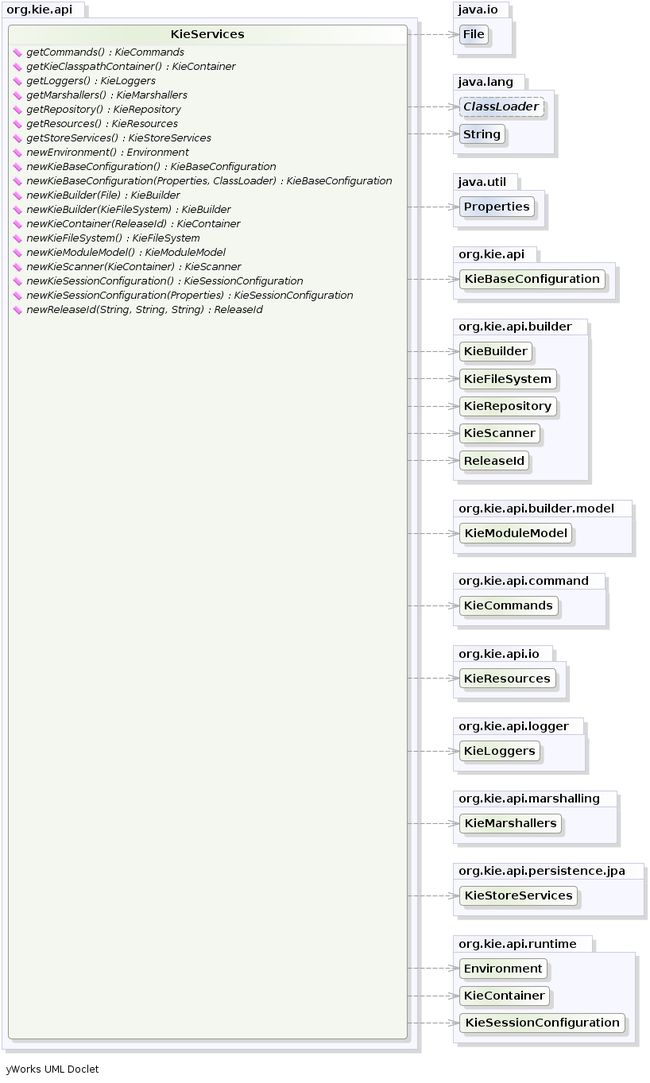
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();通过这种方式,所有Java源和Kie资源都被编译并部署到KieContainer中,使其内容可在运行时使用。
而`KieServices`是可以访问所有Kie构建和运行时设施的接口,下面看下类图:
kmodule.xml文件详细解析
kmodule.xml文件可以声明性地配置KIE项目所需创建的KieBases和KieSessions。
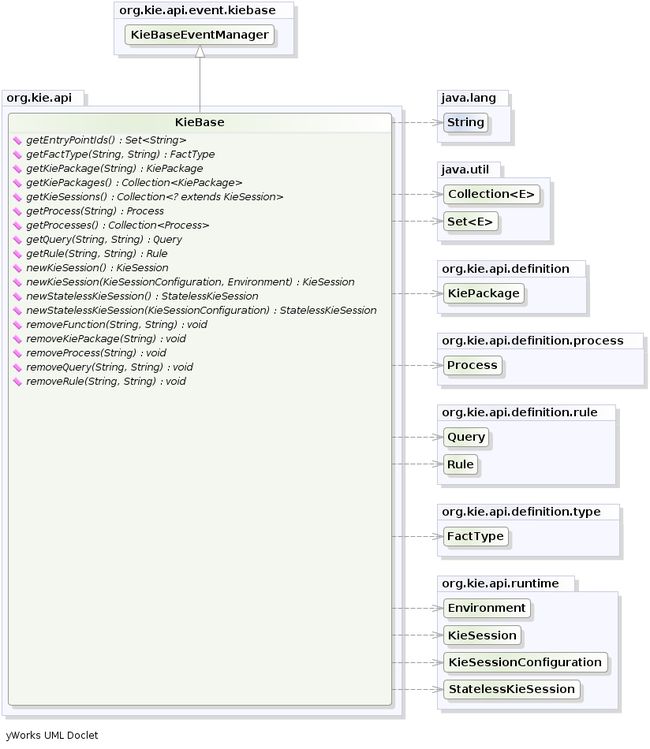
KieBase是所有应用程序知识定义的存储库。它包含rules, processes, functions和type models。KieBase本身不包含数据; 相反,KieBase可以插入数据以及可以确定从哪个流程实例开始创建session。KieBase的创建相对重量级,而会话的创建就显得非常轻量级,因此建议KieBase尽可能缓存重复创建的session。最终用户通常不用担心,因为KieContainer已经自动提供了相关的缓存机制。
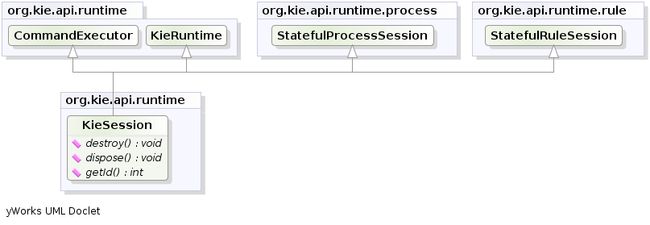
KieSession存储和执行运行时数据。如果已经在kmodule.xml文件中定义,KieBase则可以直接创建它或者更容易创建KieContainer。
kmodule.xml允许定义和配置一个或多个KieBases以及可以从中创建的KieBase所有不同KieSessions,如下面的示例所示:
此处标记包含键值对列表,这些键值对是用于配置KieBase构建过程的可选属性。例如,此示例kmodule.xml文件定义了supersetOf由org.mycompany.SupersetOfEvaluatorDefinition该类命名和实现的其他自定义运算符。
在KieBase定义了这2 秒之后,可以KieSession从第一个实例中获得2种不同类型,而从第二种中只有一种。可以在kbase标记上定义的属性列表及其含义和默认值如下:
| Attribute name | Default value | Admitted values | Meaning |
|---|---|---|---|
| name |
none |
any |
从KieContainer中检索此KieBase的名称。这是唯一的强制属性。 |
| includes |
none |
any comma separated list |
此kmodule中包含的其他KieBase的逗号分隔列表。所有这些KieBases的工件也将包含在这个工具中。 |
| packages |
all |
any comma separated list |
默认情况下,资源文件夹下任何级别的所有Drools工件都包含在KieBase中。此属性允许将在此KieBase中编译的工件限制为仅属于包列表的工件。 |
| default |
false |
true, false |
定义此KieBase是否为此模块的默认值,因此可以从KieContainer创建它而不向其传递任何名称。每个模块中最多只能有一个默认的KieBase。 |
| equalsBehavior |
identity |
identity, equality |
在将新事实插入工作记忆时定义Drools的行为。除了身份之外,它总是创建一个新的FactHandle,除非工作内存中不存在相同的对象,而只有当新插入的对象与已存在的事实不相等(根据其相等的方法)时才相等。 |
| eventProcessingMode |
cloud |
cloud, stream |
在云模式下编译时,KieBase将事件视为正常事实,而在流模式下则允许对它们进行时间推理 |
| declarativeAgenda |
disabled |
disabled, enabled |
定义是否启用声明性议程。 |
类似地,ksession标记的所有属性(当然除了名称)都具有有意义的默认值。它们在下表中列出并描述:
| Attribute name | Default value | Admitted values | Meaning |
|---|---|---|---|
| name |
none |
any |
此KieSession的唯一名称。用于从KieContainer获取KieSession。这是唯一的强制属性。 |
| type |
stateful |
stateful, stateless |
有状态会话允许迭代地使用工作存储器,而无状态会话是使用提供的数据集一次性执行工作存储器。 |
| default |
false |
true, false |
定义此KieSession是否是此模块的默认值,因此可以从KieContainer创建它而不向其传递任何名称。在每个模块中,每种类型最多只能有一个默认的KieSession。 |
| clockType |
realtime |
realtime, pseudo |
定义事件时间戳是由系统时钟还是由应用程序控制的伪时钟确定的。该时钟对于单元测试时间规则特别有用。 |
| beliefSystem |
simple |
simple, jtms, defeasible |
定义KieSession使用的信念系统的类型。 |
如前一个kmodule.xml示例中所述,还可以在每个KieSession文件(或控制台)记录器上声明性地创建一个或多个WorkItemHandlers和Calendars以及一些可以是3种不同类型的侦听器:ruleRuntimeEventListener,agendaEventListener和processEventListener
定义了像前一个示例中的kmodule.xml之类的kmodule.xml,现在可以使用它们的名称从KieContainer中简单地检索KieBases和KieSessions。
KieServices kieServices = KieServices.Factory.get(); KieContainer kContainer =
kieServices.getKieClasspathContainer(); KieBase kBase1 = kContainer.getKieBase("KBase1");
KieSession kieSession1 = kContainer.newKieSession("KSession2_1"); StatelessKieSession
kieSession2 = kContainer.newStatelessKieSession("KSession2_2");需要注意的是,由于KSession2_1和KSession2_2有两种不同的类型(第一种是有状态的,而第二种是无状态的),因此必须KieContainer根据它们声明的类型调用2种不同的方法。如果KieSession请求的类型KieContainer与kmodule.xml文件中声明的类型不对应,KieContainer则会抛出一个RuntimeException。此外,由于KieBase和KieSession已被标记为默认值,因此可以KieContainer从不通过任何名称获取它们。
从KieContainer中重新获取默认的KieBase和KieSession
KieContainer kContainer = ...
KieBase kBase1 = kContainer.getKieBase(); // returns KBase1
KieSession kieSession1 = kContainer.newKieSession(); // returns KSession2_1由于Kie项目也是Maven项目,因此在pom.xml文件中声明的groupId,artifactId和version用于生成ReleaseId在应用程序中唯一标识此项目的项目。这允许通过简单地将其传递ReleaseId给项目来从项目中创建新的KieContainer KieServices。
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0" );
KieContainer kieContainer = kieServices.newKieContainer( releaseId );Maven的KIE插件可确保工件资源经过验证和预编译,建议始终使用它。要使用该插件,只需将其添加到Maven pom.xml的构建部分,然后使用打包将其激活kjar。
kjar
...
org.kie
kie-maven-plugin
7.23.0.Final
true
该插件支持所有Drools / jBPM知识资源。但是,如果您在Java类中使用特定的KIE注释,例如@kie.api.Position,您需要将编译时依赖项添加kie-api到项目中。我们建议为所有其他KIE依赖项使用提供的范围。这样,kjar尽可能保持轻量级,并且不依赖于任何特定的KIE版本。
在没有Maven插件的情况下构建KIE模块会将所有资源按原样复制到生成的JAR中。当运行时加载JAR时,它将尝试构建所有资源。如果有编译问题,它将返回null KieContainer。它还将编译开销推送到运行时。通常不建议这样做,并且应始终使用Maven插件。
以编程方式定义KieModule
也可以通过编程方式定义属于KieModule 的KieBases和KieSessions,而不是kmodule.xml文件中的声明性定义。相同的编程API还允许显式添加包含Kie工件的文件,而不是从项目的resources文件夹中自动读取它们。为此,有必要创建一种KieFileSystem虚拟文件系统,并将项目中包含的所有资源添加到其中。

像所有其他的Kie核心部件,你可以得到的一个实例KieFileSystem从KieServices。必须将kmodule.xml配置文件添加到文件系统中。这是必须的步骤。Kie还提供了一个方便的流畅API,由以下方式实现KieModuleModel,以编程方式创建此文件。
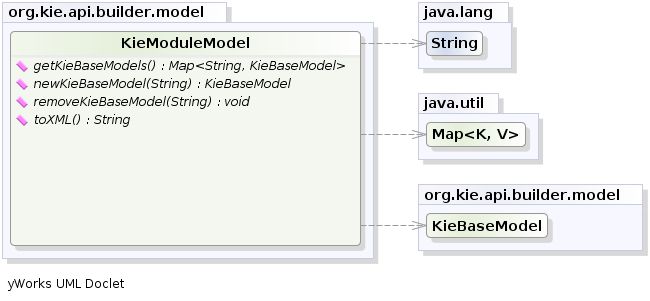
要在实践中执行此操作,必须创建一个KieModuleModelfrom KieServices,使用所需的KieBases和KieSessions 对其进行配置,将其转换为XML并将XML添加到KieFileSystem。以下示例显示了此过程:
KieServices kieServices = KieServices.Factory.get();
KieModuleModel kieModuleModel = kieServices.newKieModuleModel();
KieBaseModel kieBaseModel1 = kieModuleModel.newKieBaseModel( "KBase1 ")
.setDefault( true )
.setEqualsBehavior( EqualityBehaviorOption.EQUALITY )
.setEventProcessingMode( EventProcessingOption.STREAM );
KieSessionModel ksessionModel1 = kieBaseModel1.newKieSessionModel( "KSession1" )
.setDefault( true )
.setType( KieSessionModel.KieSessionType.STATEFUL )
.setClockType( ClockTypeOption.get("realtime") );
KieFileSystem kfs = kieServices.newKieFileSystem();
kfs.writeKModuleXML(kieModuleModel.toXML());此时,还需要KieFileSystem通过其流畅的API 添加构成项目的所有其他Kie工件。必须将这些工件添加到相应的常规Maven项目的相同位置。
KieFileSystem kfs = ...
kfs.write( "src/main/resources/KBase1/ruleSet1.drl", stringContainingAValidDRL )
.write( "src/main/resources/dtable.xls",
kieServices.getResources().newInputStreamResource( dtableFileStream ) );此示例显示可以将Kie工件添加为纯字符串和Resources。在后一种情况下,Resources可以由KieResources工厂创建,也由工厂提供KieServices。在KieResources提供了许多便捷的工厂方法,将一个InputStream,一个URL,一个File,或String代表你的文件系统的路径Resource可以由管理KieFileSystem。
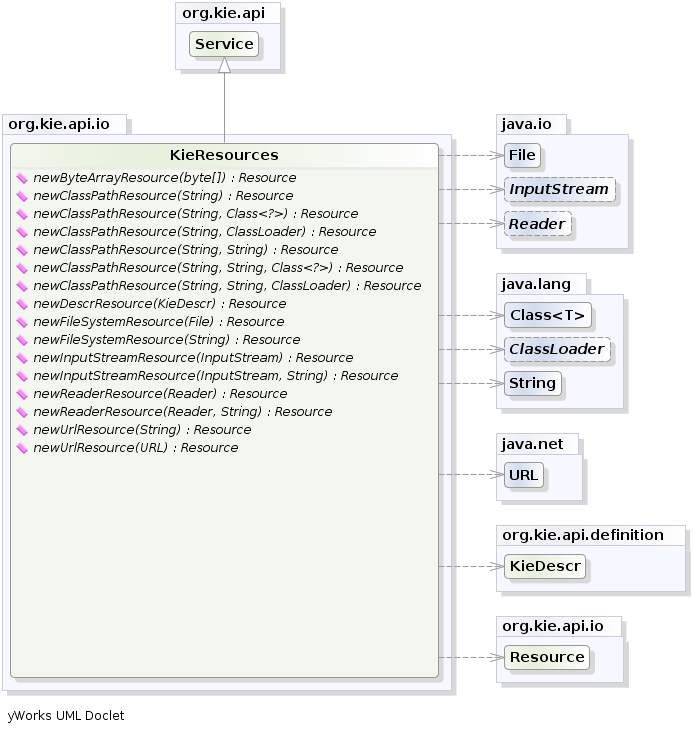
通常,a的类型Resource可以从用于将其添加到的名称的扩展名推断出来KieFileSystem。但是,也可以不遵循有关文件扩展名的Kie约定,并明确地将特定分配ResourceType给a Resource,如下所示:
KieFileSystem kfs = ...
kfs.write( "src/main/resources/myDrl.txt",
kieServices.getResources().newInputStreamResource( drlStream )
.setResourceType(ResourceType.DRL) ); 将所有资源添加到KieFileSystem并通过传递KieFileSystem给a来构建它KieBuilder
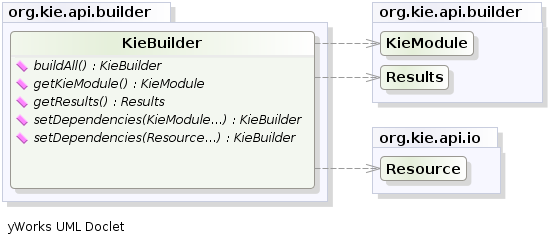
KieFileSystem成功构建a的内容后,结果KieModule会自动添加到KieRepository。这KieRepository是一个单例,充当所有可用KieModules 的存储库。
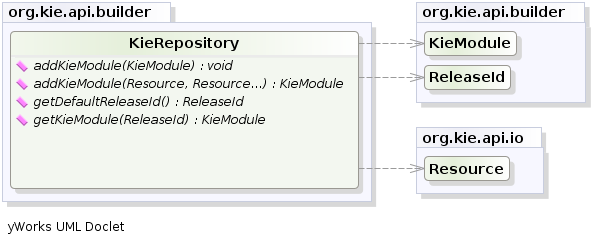
在此之后,可以通过创建KieServices一个新的KieContainer为KieModule使用它的ReleaseId。然而,由于在这种情况下,KieFileSystem不包含任何pom.xml文件(它是可以添加使用一个KieFileSystem.writePomXML方法),纪伊不能确定ReleaseId的KieModule,并分配给它一个默认的。此默认值ReleaseId可以从中获取KieRepository并用于标识自身KieModule内部KieRepository。以下示例显示了整个过程。
KieServices kieServices = KieServices.Factory.get();
KieFileSystem kfs = ...
kieServices.newKieBuilder( kfs ).buildAll();
KieContainer kieContainer = kieServices.newKieContainer(kieServices.getRepository().getDefaultReleaseId());此时,可以KieBase通过与直接从类路径创建的情况相同的方式获取并从中创建新的KieSessions 。KieContainerKieContainer
检查编译结果是最佳做法。在KieBuilder3个不同的严重性报道编译结果:ERROR,WARNING和INFO。错误表示项目的编译失败,如果没有KieModule生成,则没有添加任何内容KieRepository。警告和INFO结果可以忽略,但可供检查。
KieBuilder kieBuilder = kieServices.newKieBuilder( kfs ).buildAll();
assertEquals( 0, kieBuilder.getResults().getMessages( Message.Level.ERROR ).size() );更改默认构建结果严重性
在某些情况下,可以更改某种构建结果的默认严重性。例如,当将具有相同名称的现有规则的新规则添加到包时,默认行为是用新规则替换旧规则并将其报告为INFO。这可能是大多数用例的理想选择,但在某些部署中,用户可能希望阻止规则更新并将其报告为错误。
更改结果类型的默认严重性(配置为Drools中的任何其他选项)可以通过API调用,系统属性或配置文件来完成。从此版本开始,Drools支持规则更新和功能更新的可配置结果严重性。要使用系统属性或配置文件对其进行配置,用户必须使用以下属性:
使用属性设置严重性
// sets the severity of rule updates
drools.kbuilder.severity.duplicateRule =
// sets the severity of function updates
drools.kbuilder.severity.duplicateFunction = Building and running Drools in a fat jar
Drools的许多模块(例如drools-core,drools-compiler)都有一个名为的文件,kie.conf其中包含实现相应模块提供的服务的类的名称。当在胖JAR中运行Drools时,例如由Maven Shade插件创建,kie.conf需要合并这些各种文件,否则,胖JAR将仅包含来自单个依赖项的1个kie.conf,从而导致错误。您可以使用变换器合并Maven Shade插件中的资源,如下所示:
META-INF/kie.conf
例如,在Vert.x应用程序中运行Drools时需要这样做。在这种情况下,可以按照以下方式配置Maven Shade插件:
org.apache.maven.plugins
maven-shade-plugin
3.1.0
package
shade
io.vertx.core.Launcher
${main.verticle}
META-INF/services/io.vertx.core.spi.VerticleFactory
META-INF/kie.conf
${project.build.directory}/${project.artifactId}-${project.version}-fat.jar
KieBase
KieBase是所有应用程序知识定义的存储库。它将包含规则,流程,函数和类型模型。它KieBase本身不包含数据; 相反,可以从KieBase可以插入数据以及可以从哪个流程实例开始创建会话。在KieBase可以从能够得到KieContainer含有KieModule的其中KieBase已被定义。
有时,例如在OSGi环境中,KieBase需要解析不在默认类加载器中的类型。在这种情况下,有必要创建一个KieBaseConfiguration带有额外的类加载器,并在从中KieContainer创建新的时将其传递给KieBase
使用自定义ClassLoader创建新的KieBase
KieServices kieServices = KieServices.Factory.get();
KieBaseConfiguration kbaseConf = kieServices.newKieBaseConfiguration( null, MyType.class.getClassLoader() );
KieBase kbase = kieContainer.newKieBase( kbaseConf );KieSessions和KieBase修改
KieSessions将在“Running”部分中详细讨论。在KieBase创建并返回KieSession的对象,它可以选择保留这些引用。当KieBase发生修改时,将对会话中的数据应用这些修改。此引用是弱引用,它也是可选的,由布尔标志控制。
KieScanner
将KieScanner让你的Maven仓库的连续监测,检查项目乃纪伊的新版本是否已安装。在该KieContainer项目的包装中部署了一个新版本。使用KieScannerkie-ci.jar需要在类路径上。

A KieScanner可以在a上注册,KieContainer如下例所示。
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0-SNAPSHOT" );
KieContainer kContainer = kieServices.newKieContainer( releaseId );
KieScanner kScanner = kieServices.newKieScanner( kContainer );
// Start the KieScanner polling the Maven repository every 10 seconds
kScanner.start( 10000L );在此示例中,KieScanner配置为以固定的时间间隔运行,但也可以通过调用其上的scanNow()方法按需运行它。如果KieScanner在Maven存储库中找到所使用的Kie项目的更新版本,KieContainer它会自动下载新版本并触发新项目的增量构建。在这一点上,现有的KieBases和KieSession控制项下的KieContainer会得到它自动升级-特别是那些KieBase具有的粘度getKieBase()与它们相关的一起KieSession second,任何KieSession直接获得KieContainer.newKieSession()这样引用默认KieBase。此外,从这一刻开始,所有新的KieBases和KieSessions都是由此创建的KieContainer将使用新的项目版本。请注意,在KieScanner升级之前KieBase获得的任何现有产品newKieBase()及其任何相关产品KieSession都不会自动升级; 这是因为KieBase获得的通过newKieBase()不受直接控制KieContainer。
将KieScanner只会如果使用快照,版本范围,最新的,或松开设置拾音器更改已部署的罐子。固定版本不会在运行时自动更新。
如果您不想安装maven存储库,也可以KieScanner通过简单地从普通文件系统的文件夹中获取更新来实现。你可以KieScanner简单地创建这样的
KieServices kieServices = KieServices.Factory.get();
KieScanner kScanner = kieServices.newKieScanner( kContainer, "/myrepo/kjars" );其中“/ myrepo / kjars”将是KieScanner寻找kjar更新的文件夹。放置在此文件夹中的jar文件必须遵循maven约定,然后必须是{artifactId} - {versionId} .jar形式的名称。
Maven版本和依赖项
Maven支持许多机制来管理应用程序中的版本控制和依赖关系。可以使用特定版本号发布模块,也可以使用SNAPSHOT后缀。依赖关系可以指定要使用的版本范围,或者采用SNAPSHOT机制的优势。
这是一个说明各种选项的示例。在Maven存储库中,com.foo:my-foo具有以下元数据:
com.foo
my-foo
2.0.0
1.1.1
1.0
1.0.1
1.1
1.1.1
2.0.0
20090722140000
如果需要依赖于该工件,则可以使用以下选项(当然可以指定其他版本范围,只显示相关的版本范围):声明确切版本(将始终解析为1.0.1):
[1.0.1] 声明一个显式版本(除非发生冲突,否则将始终解析为1.0.1,当Maven将选择匹配的版本时):1.0.1 声明所有1.x的版本范围(目前将解析为1.1.1):[1.0.0,2.0.0) 声明一个开放式版本范围(将解析为2.0.0):[1.0.0,) 声明所有1.x的版本范围(目前将解析为1.1.1):
RELEASE 请注意,默认情况下,您自己的部署将更新Maven元数据中的“最新”条目,但要更新“发布”条目,您需要激活Maven超级POM中的“发布配置文件”。您可以使用“-Prelease-profile”或“-DperformRelease = true”执行此操作
Settings.xml和远程存储库设置
settings.xml文件可以位于3个位置,使用的实际设置是这3个位置的合并。
-
Maven安装:
$M2_HOME/conf/settings.xml -
用户的安装:
${user.home}/.m2/settings.xml -
系统属性指定的文件夹位置
kie.maven.settings.custom
settings.xml用于指定远程存储库的位置。激活指定远程存储库的配置文件非常重要,通常可以使用“activeByDefault”来完成:
profile-1
true
...
Run
KieBase是所有应用程序知识定义的存储库。它将包含规则,流程,函数和类型模型。它KieBase本身不包含数据; 相反,可以从KieBase可以插入数据以及可以从哪个流程实例开始创建会话。在KieBase可以从能够得到KieContainer含有KieModule的其中KieBase已被定义。
从KieContainer获取KieBase
KieBase kBase = kContainer.getKieBase();KieSession
在KieSession对运行时数据存储和执行。它是由...创建的KieBase。
KieSession
从KieBase创建KieSession
KieSession ksession = kbase.newKieSession();KieRuntime
KieRuntime规定,均适用于规则和过程的方法,如设置全局变量和注册信道。(“退出点”是“频道”的过时同义词。)
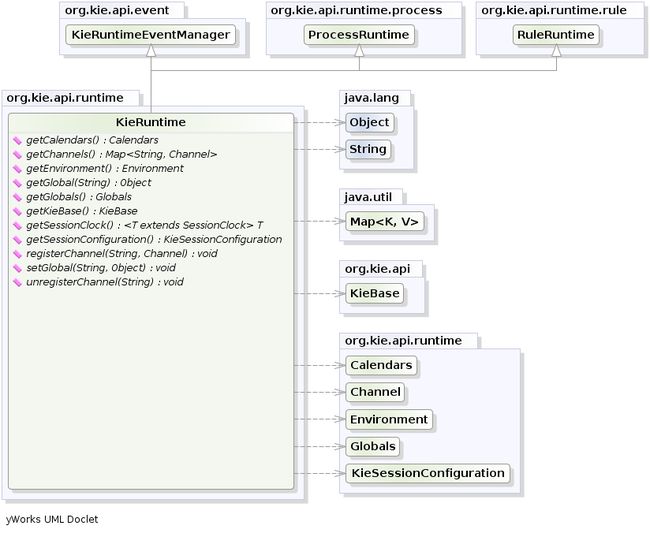
Globals是Drools引擎可见的命名对象,但其方式与事实基本不同:支持全局的对象中的更改不会触发规则的重新评估。尽管如此,全局变量对于提供静态信息非常有用,作为提供规则的RHS中使用的服务的对象,或者作为从Drools引擎返回对象的手段。当您在规则的LHS上使用全局时,请确保它是不可变的,或者至少不要指望更改会对规则的行为产生任何影响。必须在规则文件中声明全局,然后需要使用Java对象进行备份。
global java.util.List list现在KIE基础知道全局标识符及其类型,现在可以ksession.setGlobal()使用全局名称和对象调用任何会话,以将对象与全局关联。如果未在DRL代码中声明全局类型和标识符,将导致从此调用中抛出异常。
List list = new ArrayList();
ksession.setGlobal("list", list);确保在评估规则之前设置任何全局。如果不这样做会导致a NullPointerException。
事件模型
事件包提供了通知Drools引擎事件的方法,包括触发规则,声明对象等。这允许将日志记录和审计活动与应用程序的主要部分(以及规则)分开。
该KieRuntimeEventManager接口由实施KieRuntime,其提供两个接口,RuleRuntimeEventManager和ProcessEventManager。我们只会在RuleRuntimeEventManager这里report。
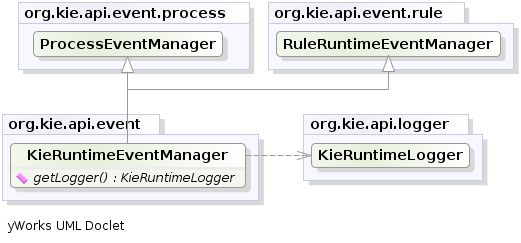
KieRuntimeEventManager
在RuleRuntimeEventManager允许添加和删除侦听程序,因此,对于工作记忆和议程事件就可以听了。

RuleRuntimeEventManager
以下代码段显示了如何声明简单的议程侦听器并将其附加到会话。它会在射击后打印匹配。
添加AgendaEventListener
ksession.addEventListener( new DefaultAgendaEventListener() {
public void afterMatchFired(AfterMatchFiredEvent event) {
super.afterMatchFired( event );
System.out.println( event );
}
});Drools还提供DebugRuleRuntimeEventListener并DebugAgendaEventListener使用debug print语句实现每个方法。要打印所有工作内存事件,请添加如下监听器:
添加DebugRuleRuntimeEventListener
ksession.addEventListener( new DebugRuleRuntimeEventListener() );有发出的事件都实现了KieRuntimeEvent可用于检索实际发生KnowlegeRuntime的事件的接口。
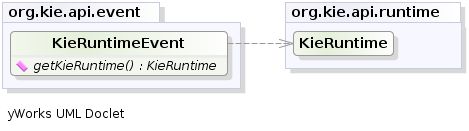
KieRuntimeEvent
目前支持的事件是:
MatchCreatedEvent
MatchCancelledEvent
BeforeMatchFiredEvent
AfterMatchFiredEvent
AgendaGroupPushedEvent
AgendaGroupPoppedEvent
ObjectInsertEvent
ObjectDeletedEvent
ObjectUpdatedEvent
ProcessCompletedEvent
ProcessNodeLeftEvent
ProcessNodeTriggeredEvent
ProcessStartEventKieRuntimeLogger
KieRuntimeLogger使用Drools中的综合事件系统创建审计日志,该日志可用于记录应用程序的执行,以便以后使用Eclipse审计查看器等工具进行检查。
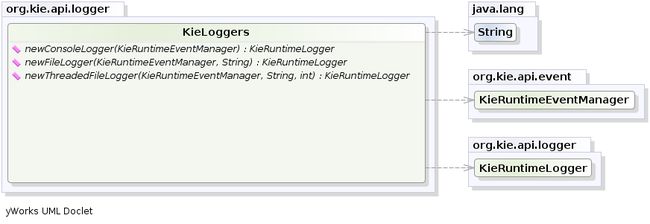
KieLoggers
FileLogger
KieRuntimeLogger logger =
KieServices.Factory.get().getLoggers().newFileLogger(ksession, "logdir/mylogfile");
...
logger.close();命令和CommandExecutor
KIE拥有有状态或无状态会话的概念。已经涵盖了使用标准KieRuntime的有状态会话,并且可以随着时间的推移迭代地进行。Stateless是使用提供的数据集一次性执行KieRuntime。它可能返回一些结果,会话在最后处理,禁止进一步的迭代交互。您可以将无状态视为将函数调用视为具有可选返回结果的引擎。
其基础是CommandExecutor有状态和无状态接口扩展的接口。这返回一个ExecutionResults:
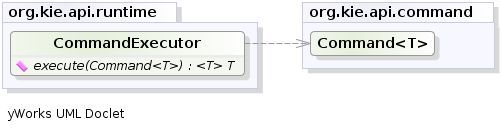
CommandExecutor
在CommandExecutor允许在这些会话要被执行的命令,唯一的区别在于StatelessKieSession执行fireAllRules()在端设置会话之前。可以使用CommandExecutor。创建命令.Javadocs使用提供的允许命令的完整列表CommandExecutor。
setGlobal和getGlobal是两个与Drools和jBPM相关的命令。
在下面设置全局调用setGlobal。可选的boolean指示命令是否应该返回全局值作为的一部分ExecutionResults。如果为true,则它使用与全局名称相同的名称。如果需要替代名称,可以使用String代替布尔值。
设置全局命令
StatelessKieSession ksession = kbase.newStatelessKieSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.newSetGlobal( "stilton", new Cheese( "stilton" ), true);
Cheese stilton = bresults.getValue( "stilton" );允许返回现有的全局。第二个可选的String参数允许使用备用返回名称。
获取全局命令
StatelessKieSession ksession = kbase.newStatelessKieSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.getGlobal( "stilton" );
Cheese stilton = bresults.getValue( "stilton" );以上所有示例都执行单个命令。所述BatchExecution表示的复合命令,从命令的列表创建。它将遍历列表并依次执行每个命令。这意味着您可以在一次execute(…)调用中插入一些对象,启动进程,调用fireAllRules并执行查询,这非常强大。
StatelessKieSession将fireAllRules()在结束时自动执行。然而,敏锐的读者可能已经注意到该FireAllRules命令,并想知道如何使用StatelessKieSession。FireAllRules允许该命令,使用它将在结束时禁用自动执行; 考虑将其用作一种手动覆盖功能。
批处理中具有out标识符集的任何命令都会将其结果添加到返回的ExecutionResults实例中。让我们看一个简单的例子来看看它是如何工作的。出于说明的目的,所呈现的示例包括来自Drools和jBPM的命令。它们在Drool和jBPM特定部分中有更详细的介绍。
BatchExecution命令
StatelessKieSession ksession = kbase.newStatelessKieSession();
List cmds = new ArrayList();
cmds.add( CommandFactory.newInsertObject( new Cheese( "stilton", 1), "stilton") );
cmds.add( CommandFactory.newStartProcess( "process cheeses" ) );
cmds.add( CommandFactory.newQuery( "cheeses" ) );
ExecutionResults bresults = ksession.execute( CommandFactory.newBatchExecution( cmds ) );
Cheese stilton = ( Cheese ) bresults.getValue( "stilton" );
QueryResults qresults = ( QueryResults ) bresults.getValue( "cheeses" );在上面的例子中,执行了多个命令,其中两个命令填充了ExecutionResults。query命令默认使用与查询名称相同的标识符,但也可以映射到不同的标识符。
StatelessKieSession
该StatelessKieSession包装的KieSession,而不是扩展它。其主要重点是决策服务类型方案。它避免了call的需要dispose()。无状态会话不支持迭代插入和fireAllRules()Java代码调用方法; 调用的行为execute()是一个单击方法,它将在内部实例化a KieSession,添加所有用户数据并执行用户命令,调用fireAllRules(),然后调用dispose()。虽然使用此类的主要方法是通过BatchExecution接口Command支持的(子接口)CommandExecutor,但提供了两种便捷方法,用于简单对象插入所需的全部内容。该CommandExecutor和BatchExecution在自己的部分谈到细节。
我们的简单示例显示了使用便捷API执行给定Java对象集合的无状态会话。它将迭代集合,依次插入每个元素。
使用Collection执行简单的StatelessKieSession
StatelessKieSession ksession = kbase.newStatelessKieSession();
ksession.execute( collection );如果这是作为单个命令完成的,它将如下:
使用InsertElements命令执行简单的StatelessKieSession
ksession.execute( CommandFactory.newInsertElements( collection ) );如果你想插入集合本身,以及集合的各个元素,那么CommandFactory.newInsert(collection)就可以完成这项工作。
CommandFactory创建支持的命令,所有这些都可以使用XStream的和被整理BatchExecutionHelper。BatchExecutionHelper提供有关XML格式的详细信息,以及如何使用Drools Pipeline自动化编组BatchExecution和格式化ExecutionResults。
StatelessKieSession支持全局变量,以多种方式支持。我们首先介绍非命令方式,因为命令的作用域是特定的执行调用。Globals可以通过三种方式解决。
StatelessKieSession方法getGlobals()返回一个Globals实例,该实例提供对会话的全局变量的访问。这些是所有执行调用共享的。关于可变全局变量请谨慎,因为执行调用可以在不同的线程中同时执行。
会话作用域全局
StatelessKieSession ksession = kbase.newStatelessKieSession(); // Set a global hbnSession,
that can be used for DB interactions in the rules. ksession.setGlobal( "hbnSession",
hibernateSession ); // Execute while being able to resolve the "hbnSession" identifier.
ksession.execute( collection );使用委托是另一种全球解决方式。为全局(with setGlobal(String, Object))赋值会导致值存储在内部集合中,将标识符映射到值。此内部集合中的标识符将优先于任何提供的委托。仅当在此内部集合中找不到标识符时,才会使用全局委托(如果有)。
解决全局变量的第三种方法是使用执行范围的全局变量。这里,a Command设置一个全局传递给CommandExecutor。
该CommandExecutor界面还提供通过“输出”参数导出数据的功能。插入的事实,全局变量和查询结果都可以返回。
输出标识符
// Set up a list of commands
List cmds = new ArrayList();
cmds.add( CommandFactory.newSetGlobal( "list1", new ArrayList(), true ) );
cmds.add( CommandFactory.newInsert( new Person( "jon", 102 ), "person" ) );
cmds.add( CommandFactory.newQuery( "Get People" "getPeople" );
// Execute the list
ExecutionResults results =
ksession.execute( CommandFactory.newBatchExecution( cmds ) );
// Retrieve the ArrayList
results.getValue( "list1" );
// Retrieve the inserted Person fact
results.getValue( "person" );
// Retrieve the query as a QueryResults instance.
results.getValue( "Get People" );编组
将KieMarshallers用于编组和取消编组KieSessions。
KieMarshallers
KieMarshallers可以从中检索一个实例KieServices。一个简单的例子如下所示:
/ ksession is the KieSession
// kbase is the KieBase
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Marshaller marshaller = KieServices.Factory.get().getMarshallers().newMarshaller( kbase );
marshaller.marshall( baos, ksession );
baos.close();但是,通过编组,在处理引用的用户数据时,您将需要更大的灵活性。要实现这一点,请使用ObjectMarshallingStrategy界面。提供了两种实现,但用户可以实现自己的实现。提供的两个策略是IdentityMarshallingStrategy和SerializeMarshallingStrategy。SerializeMarshallingStrategy是默认值,如上例所示,它只调用用户实例上的Serializable或Externalizable方法。IdentityMarshallingStrategy为每个用户对象创建一个整数id,并将它们存储在Map中,同时将id写入流中。解组时,它会访问IdentityMarshallingStrategy地图以检索实例。这意味着,如果你使用IdentityMarshallingStrategy,它对Marshaller实例的生命是有状态的,并将创建id并保持对它试图编组的所有对象的引用。以下是使用身份编组策略的代码。
IdentityMarshallingStrategy
ByteArrayOutputStream baos = new ByteArrayOutputStream(); KieMarshallers kMarshallers =
KieServices.Factory.get().getMarshallers() ObjectMarshallingStrategy oms =
kMarshallers.newIdentityMarshallingStrategy() Marshaller marshaller =
kMarshallers.newMarshaller( kbase, new ObjectMarshallingStrategy[]{ oms } );
marshaller.marshall( baos, ksession ); baos.close();
在大多数情况下,单一策略是不够的。为了增加灵活性,ObjectMarshallingStrategyAcceptor可以使用界面。这个Marshaller有一系列策略,在读取或编写用户对象时,它会迭代策略,询问他们是否承担编组用户对象的责任。提供的实现之一是ClassFilterAcceptor。这允许字符串和通配符用于匹配类名。默认值为“ 。 ”,因此在上面的示例中,使用了具有默认“ 。 ”接受器的身份编组策略。
假设我们要序列化除一个给定包之外的所有类,我们将使用身份查找,我们可以执行以下操作:
具有Acceptor的IdentityMarshallingStrategy
ByteArrayOutputStream baos = new ByteArrayOutputStream();
KieMarshallers kMarshallers = KieServices.Factory.get().getMarshallers()
ObjectMarshallingStrategyAcceptor identityAcceptor =
kMarshallers.newClassFilterAcceptor( new String[] { "org.domain.pkg1.*" } );
ObjectMarshallingStrategy identityStrategy =
kMarshallers.newIdentityMarshallingStrategy( identityAcceptor );
ObjectMarshallingStrategy sms = kMarshallers.newSerializeMarshallingStrategy();
Marshaller marshaller =
kMarshallers.newMarshaller( kbase,
new ObjectMarshallingStrategy[]{ identityStrategy, sms } );
marshaller.marshall( baos, ksession );
baos.close();请注意,验收检查顺序是所提供元素的自然顺序。
持久性和事务
使用Drools可以实现Java Persistence API(JPA)的长期开箱即用持久性。必须安装一些Java Transaction API(JTA)实现。出于开发目的,建议使用Bitronix事务管理器,因为它易于设置和嵌入式工作,但对于生产用途,建议使用JBoss事务。
使用事务的简单示例
KieServices kieServices = KieServices.Factory.get();
Environment env = kieServices.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY,
Persistence.createEntityManagerFactory( "emf-name" ) );
env.set( EnvironmentName.TRANSACTION_MANAGER,
TransactionManagerServices.getTransactionManager() );
// KieSessionConfiguration may be null, and a default will be used
KieSession ksession =
kieServices.getStoreServices().newKieSession( kbase, null, env );
int sessionId = ksession.getId();
UserTransaction ut =
(UserTransaction) new InitialContext().lookup( "java:comp/UserTransaction" );
ut.begin();
ksession.insert( data1 );
ksession.insert( data2 );
ksession.startProcess( "process1" );
ut.commit();要使用JPA,环境必须与这两个被设置EntityManagerFactory和TransactionManager。如果发生回滚,ksession状态也会回滚,因此可以在回滚后继续使用它。要加载以前保留的KieSession,您需要id,如下所示:
KieSession ksession =
kieServices.getStoreServices().loadKieSession( sessionId, kbase, null, env );配置JPA
org.hibernate.ejb.HibernatePersistence
jdbc/BitronixJTADataSource
org.drools.persistence.info.SessionInfo
org.drools.persistence.info.WorkItemInfo
配置JTA DataSource
PoolingDataSource ds = new PoolingDataSource();
ds.setUniqueName( "jdbc/BitronixJTADataSource" );
ds.setClassName( "org.h2.jdbcx.JdbcDataSource" );
ds.setMaxPoolSize( 3 );
ds.setAllowLocalTransactions( true );
ds.getDriverProperties().put( "user", "sa" );
ds.getDriverProperties().put( "password", "sasa" );
ds.getDriverProperties().put( "URL", "jdbc:h2:mem:mydb" );
ds.init();Bitronix还提供简单的嵌入式JNDI服务,非常适合测试。要使用它,请将jndi.properties文件添加到META-INF文件夹并向其添加以下行:
JNDI属性
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory安装和部署备忘单

安全
KIE引擎是一个用于建模和执行业务行为的平台,使用大量的声明性抽象和隐喻,如规则,流程,决策表等。
很多时候,这些隐喻的创作是由第三方团体完成的,无论是同一家公司内部的不同团体,合作伙伴公司的团体,还是互联网上的匿名第三方。
规则和流程旨在执行任意代码以完成其工作,但在这种情况下,可能需要限制他们可以执行的操作。例如,不太可能允许规则创建类加载器(什么可以打开系统进行攻击),当然不应该允许它进行调用System.exit()。
Java平台提供了一个非常全面且定义明确的安全框架,允许用户定义系统可以执行的操作的策略。KIE平台利用该框架,并允许应用程序开发人员定义一个特定的策略,以应用于用户提供的代码的任何执行,无论是在规则,流程,工作项处理程序等。
如何定义KIE政策
规则和流程可以使用非常有限的权限运行,但引擎本身需要执行许多复杂的操作才能工作。例如:它需要创建类加载器,读取系统属性,访问文件系统等。
但是,一旦安装了安全管理器,它将根据定义的策略对JVM中执行的所有代码应用限制。因此,KIE允许用户定义两个不同的策略文件:一个用于引擎本身,另一个用于部署到引擎中并由引擎执行的资产。
设置环境的一个简单方法是为引擎本身提供一个非常宽松的策略,同时为规则和流程提供约束策略。
引擎的许可策略文件可能如下所示:
grant {
permission java.security.AllPermission;
}规则的示例安全策略可以是:
示例rules.policy文件
grant { permission java.util.PropertyPermission "*", "read"; permission java.lang.RuntimePermission "accessDeclaredMembers"; }
请注意,根据规则和进程应该执行的操作,可能需要授予更多权限,例如访问文件系统,数据库等中的文件。
为了使用这些策略文件,所有必要的是使用这些文件作为JVM的参数来执行应用程序。需要三个参数:
| 参数 | 含义 |
|---|---|
| -Djava.security.manager |
启用安全管理器 |
| -Djava.security.policy = |
定义要应用于整个应用程序的全局策略文件,包括引擎 |
| -Dkie.security.policy = |
定义要应用于规则和流程的策略文件 |
例如:
java -Djava.security.manager -Djava.security.policy=global.policy
-Dkie.security.policy=rules.policy foo.bar.MyApp| 在容器内执行引擎时,请使用容器的文档来了解如何配置安全管理器以及如何定义全局安全策略。如上所述定义kie安全策略并设置 |
| 请注意,除非配置了安全管理器,否则 |
| 安全管理器在JVM中具有高性能影响。强烈建议不要使用具有严格性能要求的应用程序使用安全管理器。另一种方法是使用其他安全过程,例如在测试和部署之前审核规则/流程,以防止将恶意代码部署到环境中。 |