drools规则引擎可视化_智能风控决策引擎系统可落地实现方案(六)风控监控大盘实现...
I.前文提要
通过之前五篇文章,分别介绍了决策引擎的主要功能:基于规则流程的规则集、决策流、决策树、决策表、决策矩阵等,以及基于风控模型的模型引擎和评分卡模型等功能,文章参考:
规则引擎实现
决策流实现
模型引擎实现
决策树、决策表、决策矩阵实现
评分卡模型
II.完整决策流
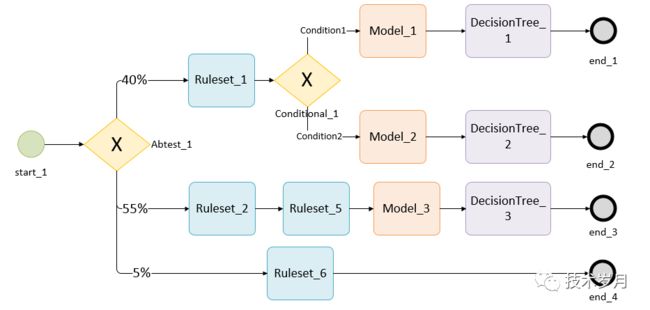 通过之前章节,决策引擎执行结果,可以输出通过或拒绝结果,决策流执行路径,如命中某个规则集,命中某条规则,触发某个条件分支,执行模型得分,以及风险评级、额度等,这些都作为决策引擎数据输出结果。
通过之前章节,决策引擎执行结果,可以输出通过或拒绝结果,决策流执行路径,如命中某个规则集,命中某条规则,触发某个条件分支,执行模型得分,以及风险评级、额度等,这些都作为决策引擎数据输出结果。
III.风控结果数据分析监控
决策引擎输出了风控结果,如何保障输出结果的准确性?如果风控分析师 “ 配置错了 ” 如何能及时发现?如果风控策略被黑产突破了如何及时补救?也就是风控系统的 “ 风控 ” 如何做?
如果能分渠道,分场景实时对风控通过率,规则触发率,模型触发率,特征缺失率等指标进行统计计算,那么就可以分析趋势或者设置阈值监控报警。
一般来说使用传统 Mysql 数据库即可轻松实现,将每次引擎结果数据和过程数据详情保存入库,然后再写个定时任务去查询分析结果,比如要查看每分钟的风控通过率(风控通过率 = 风控通过数 / 总风控数),使用 SQL 查询按时间和决策流(一个决策流代表一个决策场景)做数据聚合。

#获取每分钟通过数据SELECT scene_key,DATE_FORMAT(create_time, '%Y-%m-%d %H:%i:00') AS time, COUNT(*) AS numFROM risk_result WHERE scene_key = 'credit' AND result = 'pass'GROUP BY timeORDER BY time;#获取每分钟总数SELECT scene_key,DATE_FORMAT(create_time, '%Y-%m-%d %H:%i:00') AS time, COUNT(*) AS numFROM risk_result WHERE scene_key = 'credit'GROUP BY timeORDER BY time; 其原理是依赖 Mysql 数据 SQL 执行使用 DATE_FORMAT 和 GROUP 来做时间的切分和数据的聚合。随着数据量增大,如每分钟几万数据,靠每分钟执行脚本的方式不够优雅,面对大量数据性能较差,周期性的查询对数据库也有压力。
其原理是依赖 Mysql 数据 SQL 执行使用 DATE_FORMAT 和 GROUP 来做时间的切分和数据的聚合。随着数据量增大,如每分钟几万数据,靠每分钟执行脚本的方式不够优雅,面对大量数据性能较差,周期性的查询对数据库也有压力。
对 30 天甚至更长时间这种场景可以将数据导入离线 hive 库,进行离线计算分析,离线数据分析一般是 T+1(依赖 ETL 导入离线库的时间),有较长的延时,适用于做离线回溯,但对实时监控就比较困难了,对监控来说,数据分析结果越实时越好,毕竟金融风控中一分钟可能就放款几万乃至几百万,能实时监控发现问题,及时止损,才能保障风控更健壮。
那么有没有办法做到更优雅、更实时分析计算呢?这里引入 Flink 项目。
IV.引入 Fink
Flink 介绍
Flink 是 Apache 的一个顶级开源项目,是一个流式计算引擎,要搞懂 Flink 先来看看什么是流式计算?
大数据的计算模式主要分为批量计算 ( batch computing)、流式计算(stream computing)、图计算(graph computing)、交互计算(interactive computing )。图计算和交互计算这里不展开讨论,主要说下批量计算和流式计算。
批量计算是收集数据入库,然后对一批数据批量处理的计算方式。其特点是要计算的数据已固定,是“静态数据”,所以它一批次只计算一次。
流式计算则是对数据流进行计算,是实时计算。数据流数据特点是数据源源不断,没有边界,是“动态数据”,所以它将会不停的计算。

(图片来自Flink官网)
那么对比来看,在时效上,流式计算更实时,低延时;在数据上,流式计算是数据流,批量计算是静态数据;流式计算是先计算再存储(保存计算结果),批量计算是先存储再计算。不同的特性也意味着不同的应用场景,流式计算在时效性高的实时场景有更好的应用,事件驱动型应用、实时数据分析应用,如业务流程监控、实时推荐系统等。
Flink 特性及工作原理
Flink 算是目前最火流式计算引擎,相比于之前的 Storm、Spark Streaming而言,其具有如下显著优势:
支持集高吞吐、低延时、高性能三大特性于一身;
支持多种时间概念,系统处理时间(process Time)、事件时间(event time),有效解决流传输乱序问题;
支持灵活的窗口操作,滚动窗口、滑动窗口、Session窗口等;
支持有状态计算,可以将 n 天的中间结果数据都保存到内存和文件系统;
真正的流处理框架,支持原生流,支持批流一体,批作为特殊的流处理,Spark Streaming 正好相反,通过微批来做到“流计算”;
良好的容错能力,基于分布式快照技术的 Checkpoints ;
...
Flink 各种优点说了一大堆,那么其实现原理如何?先看下 Flink 的基本架构:

(图片来自Flink官网)
Flink 架构主要包括:Client , JobManager , TaskManager 几部分,Client 负责提交任务,JobManager 负责任务调度及资源管理,TaskManager 负责具体执行任务。
Flink 部署时,支持 on YARN 调度以及最新云原生 on K8s 调度,结合公司大数据服务一般使用 on YARN 管理。
Flink 部署完成了,我们就可以编写任务代码,通过 Flink 提供的后台进行任务提交及查看执行结果。
Flink 编程应用
Flink 开发支持 Java 和 Scala 语言,并提供不同层级的抽象接口和丰富的算子,满足各种开发需求。

(图片来自Flink官网)
通过将数据决策引擎的结果数据发送到 Kafka,在 Flink 订阅相应 Topic ( Source ),再进行数据加工计算 ( Transformation Operators ),最后结果指标存储到 Mysql / ES 等介质,供查询分析使用。
- Source:数据源,可以基于文件、socket、Kafka 等;
Transformation:数据转换操作,Map / FlatMap / Filter / KeyBy / Reduce / Aggregations / Window / Union 等;
Sink:接收落地,可以写入文件、存储到数据库或发送到下一个队列中。
以风控通过率场景为例,将 risk_result 数据流(DataStream)转换为动态表,在动态表上定义持续查询,使用 Flink 支持的 SQL 语法,通过使用滚动时间窗口 (TUMBLE)函数,采用 event time 事件时间 (这里对应 create_time),每分钟聚合一次,TUMBLE(create_time, INTERVAL '1' MINUTE),对时间做 GROUP BY 聚合,算出每分钟的通过数及每分钟总数,最后将持续查询的实时结果转为动态表,进一步转为 DataStream 发送到下游存储介质中。
具体 SQL 如下:
SELECT TUMBLE_START(create_time, INTERVAL '1' MINUTE) AS start_time, TUMBLE_END(create_time, INTERVAL '1' MINUTE) AS end_time, scene_key, COUNT(id) AS num, COUNT(CASE WHEN result = 'pass' THEN id ELSE NULL END) AS pass_num, FROM risk_resultWHERE scene_key = 'credit'GROUP BY TUMBLE(create_time, INTERVAL '1' MINUTE);可视化监控大盘
有了监控数据,可以通过可视化方式将结果应用起来,比如做成折线图、柱状图,可以加入同比(昨天相同时段),环比(上一个时段)做对比分析。

监控报警
可视化大盘可以作为风控分析师的分析工具使用,但它仍需借助人力主动分析,并不能及时对风险预警,那么可以采用阈值监控报警,如高峰时段连续10分钟通过率为 0 , 或通过率高于上一时段 10 倍就触发报警,可以通过短信、企业微信或电话不同级别报警,来保障风控的健壮性。
IV.更多思考
聚合粒度
这里使用 Flink 完成“原子粒度”的聚合,1 分钟作为一个原子,如果要看 10 分钟、15 分钟数据,只要把结果数据再做一次聚合即可。这样可以避免因调整聚合窗口时间,导致监控服务重启不可用。
滚动时间窗口与滑动时间窗口
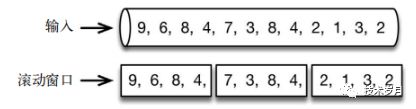
滚动窗口如下:
 滑动窗口如下:
滑动窗口如下: 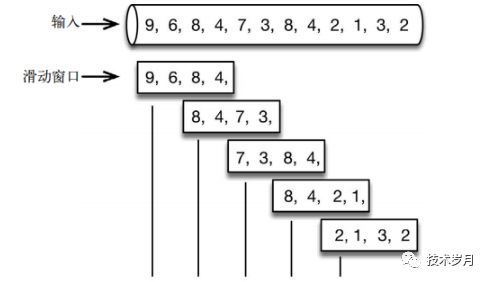 根据上图很容看出二者的区别,这里是监控每隔 1 分钟的情况,所以选择使用滚动窗口。
根据上图很容看出二者的区别,这里是监控每隔 1 分钟的情况,所以选择使用滚动窗口。
更多监控指标
除了风控通过率指标外,决策流执行过程数据也非常重要,规则命中率,可以及时发现某个规则失效,命中率持续 n 长时间一直为 0,分析可能被黑产攻破,及时调整阈值,帮助风控分析师更及时发现规则失效或规则漏洞。
特征缺失率,可能因程序上线 bug 导致,或某个三方数据源失效或发生偏移引起的特征缺失,可以通过 Flink 查询记录下来。
离线数据分析
决策引擎执行过程中,除了用到的特征指标数据外,还包括来自用户信息、设备信息、订单信息及三方数据源征信数据等大量原始数据,这种一般也会以快照记录下来,并会落到离线库,用于做离线回溯以及机器学习建模样本特征数据。
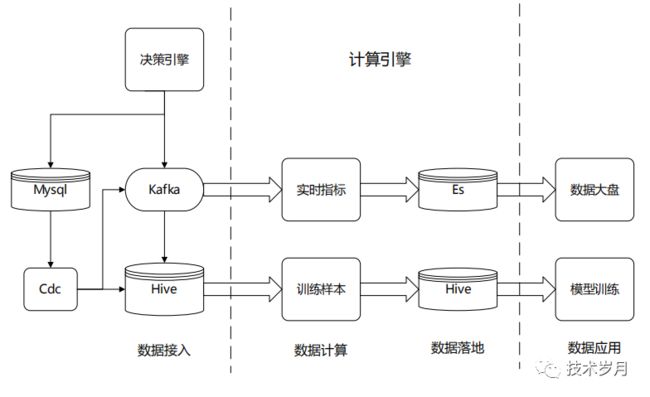 Flink其他应用
Flink其他应用
FlinkML
Flink 的 “ 野心 ” 不止于做流式计算引擎,在大数据分析和 AI 建模方向也有其尝试与探索,FlinkML 支持多种算法,并开始兼容 scikit-learn 库,tensorflow 库,应用于实时建模领域。
实时特征
对于风控使用的 “ 全局计数器 ” 类特征指标,如某 IP 最近 1 小时登录注册数,基于 Flink 的状态计算,可以轻松处理此类特征。
对于流水数据聚合统计指标,可以借助 Flink 去关系型数据库依赖,减少对生产环境的影响。
参考链接:
Flink 官网 https://flink.apache.org/
文章相关代码请关注公众号 技术岁月 ,发送关键字 决策引擎 获取。 请点赞、在看以示支持
请点赞、在看以示支持