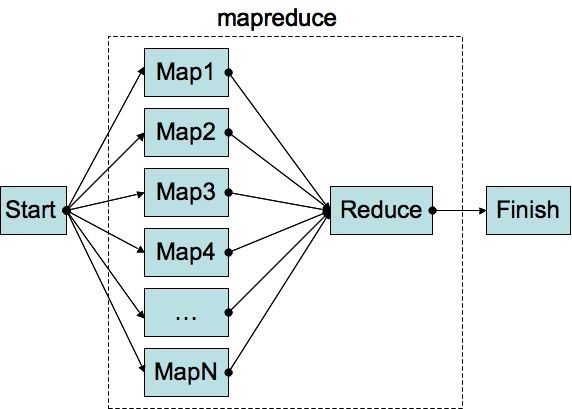
什么是MapReduce
摘自wiki中关于MapReduce的说明
MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。[1]
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
简单来说,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如,有人发现所有学生的成绩都被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。)。事实上,每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。
而归纳操作指的是对一个列表的元素进行适当的合并(继续看前面的例子,如果有人想知道班级的平均分该怎么做?他可以定义一个归纳函数,通过让列表中的奇数(odd)或偶数(even)元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到了平均分)。虽然他不如映射函数那么并行,但是因为归纳总是有一个简单的答案,大规模的运算相对独立,所以归纳函数在高度并行环境下也很有用。
python中的map和reduce
python中内置支持map和reduce操作
map和reduce的原型
map函数原型为
map(*function*, *iterable*, *...*) -> list
意思是map函数对第二个参数(或者后面更多的参数)进行迭代,将迭代的元素作为参数传递给function,function将处理过的结果保存在一个list里面并返回这个list
reduce函数原型为
reduce(*function*, *iterable*[, *initializer*]) -> value
实现差不多等同于下面的代码
def reduce(function, iterable, initializer=None):
it = iter(iterable)
if initializer is None:
try:
initializer = next(it)
except StopIteration:
raise TypeError('reduce() of empty sequence with no initial value')
accum_value = initializer
for x in it:
accum_value = function(accum_value, x)
return accum_value
举例,假设现在有几个list,想要统计它们总的元素个数,利用map-reduce的思想可以这样实现
a = [1, 2, 3]
b = [4, 5, 6, 7]
c = [8, 9, 1, 2, 3]
L = map(lambda x: len(x), [a, b, c])
N = reduce(lambda x, y: x + y, L)
可以看到,上面的代码
- 没有写出一个循环
- 没有临时变量的状态被改变
却简洁有力地描述了问题的解决办法,因此可读性是很高的。这也是函数式编程的特性。
但是上面的写法和下面的方法解决问题的效率几乎是一样的。
result = sum([len(item) for item in [a, b, c]])
在面对非常大的数据量的时候,这样的处理方式效率并不理想。
并行的解法
提到并行,首先想到的是多线程。但是,python中有GIL,并不能很好地利用多处理器的进行并发的计算。
所以想到python中的multiprocessing模块,这个模块提供了Pool这个类来管理任务的进程池,并且这个类提供了并行的map方法。这个map方法和之前提到的概念是很类似的,但是并不是说它处理的是MapReduce中的map步骤。
以经典的wordcount问题为例,直接上代码。
def my_map(l):
results = []
for w in l:
# True if w contains non-alphanumeric characters
if not w.isalnum():
w = sanitize(w)
# True if w is a title-cased token
results.append((w.lower(), 1))
return results
def my_partition(l):
tf = {}
for sublist in l:
for p in sublist:
# Append the tuple to the list in the map
tf[p[0]] = tf.get(p[0], []) + [p]
return tf
def my_reduce(mapping):
return (mapping[0], sum(pair[1] for pair in mapping[1]))
整个计算流程被拆成了Map, Partition, Reduce三个步骤
- my_map方法
传入一个token的list,去掉token首尾的标点符号,并且返回(token.lower(), 1)的一个list - my_partition方法
传入上面my_map处理的结果,返回一个dict,key为token,value为所有(token, 1)的一个list - my_reduce方法
统计各个单词出现的次数
def sanitize(w):
# 去除字符串首尾的标点符号
while len(w) > 0 and not w[0].isalnum():
w = w[1:] # String punctuation from the back
while len(w) > 0 and not w[-1].isalnum():
w = w[:-1]
return w
def load(path):
word_list = []
f = open(path, "r")
for line in f:
word_list.append(line)
return (''.join(word_list)).split()
def chunks(l, n):
for i in xrange(0, len(l), n):
yield l[i:i + n]
def tuple_sort(a, b):
if a[1] < b[1]:
return 1
elif a[1] > b[1]:
return -1
else:
return cmp(a[0], b[0])
if __name__ == '__main__':
if len(sys.argv) != 2:
print "Program requires path to file for reading!"
sys.exit(1)
text = load(sys.argv[1])
pool = Pool(processes=8, )
partitioned_text = list(chunks(text, len(text) / 8))
single_count_tuples = pool.map(my_map, partitioned_text)
token_to_tuples = my_partition(single_count_tuples)
term_frequencies = pool.map(my_reduce, token_to_tuples.items())
term_frequencies.sort(tuple_sort)
这里利用了multiprocess的map方法,对map和reduce方法进行了多进程的处理。共设立了8个进程,把读取到的文件分成8块进行处理。
需要说明的是,这里完全是为了仿照hadoop的流程进行的计算。效率可能并不是最优的。