NNLM原理及简单pytorch实现
前置:
- 以前的处理办法会出现维度灾难和数据稀疏性问题
- N-gram无法体现出词之间的相似性关系
- 传统的处理办法如果出现了语料中没有出现的情况, 则最后的概率就会变成0.解决办法是平滑,插值,回退等方法。不过这些方法的使用是要付出一定代价的。
NNLM-神经网络语言模型的出现使之能建模比n-gram更远的关系,并且能考虑到词之间的相似性。前者是因为神经网络,后者是因为使用了词向量。
NNLM如下所示:
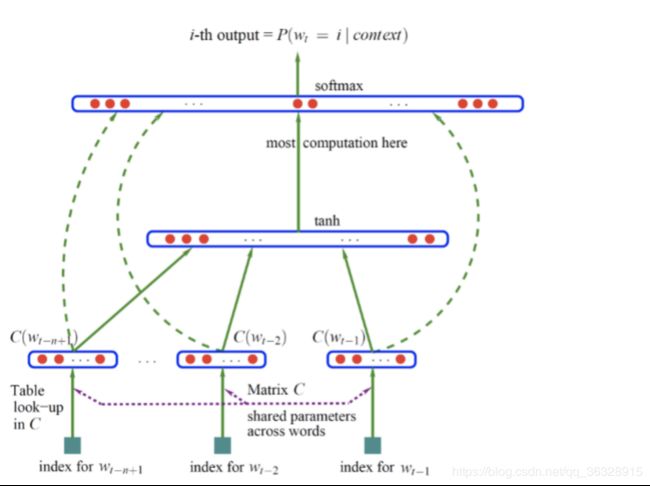
符号说明:
b (|V|维):隐层-输出层的bias
d (h维):输入-隐层的bias
U (|V|*h matrix):隐层-输出层的权重矩阵
H (h*(n-1)m matrix):输入-隐层的权重矩阵
C (|V|*m):词向量
假如现在我们要根据文档中出现的前3个词,来预测下一个词,则初始化部分:
1.对所有的文档提取单词制作一个词汇表,每个单词有一个唯一的索引,即词汇表每行代表一个单词的embedding
2.模型参数的初始化,除了神经网络的连接权重初始化之外,还需要初始化一张词汇表
前向传播部分:
1.从文档中提取模型的输入,输入为3个单词的索引
2.模型根据输入的3个单词的索引从词汇表中拿出对应的embedding表示得到每个单词的词向量。假如我们打算将每个单词转换为1个50维的向量,此时3个单词就转换为3个向量,每个都是50维
3.将3个50维向量串在一起,变为一个150维的向量作为网络的输入层,传送给隐层
对于隐层的每个神经元,150维输入乘以与每个神经元链接的权重,求和后输入给tanh激活函数
4.激活函数的输出作为输出层(softmax)的输入,假设隐层的神经元数量为300个,则输出层的输入就是一个300维向量
5.softmax层的单元数量为词汇表的单词数量|V|,对每个单元,输入的300维乘以与输出层连接的权重后求和,并计算各个单元输出的概率作为下一个单词是第i个单词的概率。在这里例子中为300维向量,则对第i个softmax单元,权重为1个300维向量,转置后与输入相乘
6.每一个softmax单元的输出为一个概率值,指示在词汇表中第i个单词为第四个单词的概率
7.整个softmax的输出为一个长度为词汇表长度的概率分布,其和为1
反向部分:
1.计算softmax的代价函数,用softmax的输出向量与真实的第四个单词的one-hot向量做点乘再取-log
2.使用BP,一层一层求出网络连接权重的偏导数,并使用梯度下降更新
3.对词向量层也需要求偏导数使用梯度下降来更新词向量表,整个过程反复迭代,词汇表就得到了不断的更新
目标函数:

参数更新:
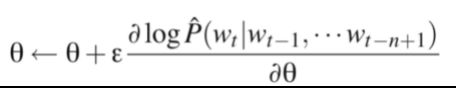
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
dtype = torch.FloatTensor
sentences = ['i like dog', 'i love coffee', 'i hate milk']
words = ' '.join(sentences).split()
words_dict = list(set(words))
num2word = {index:word for index, word in enumerate(words_dict)}
word2num = {word:index for index, word in enumerate(words_dict)}
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word2num[w] for w in word[:-1]]
target = word2num[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
input_batch,target_batch = make_batch(sentences)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
class NNLM(nn.Module):
def __init__(self):
super().__init__()
self.emb = nn.Embedding(n_class, embedding_size)
self.H = nn.Parameter(torch.randn(n_word*embedding_size, n_hidden).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.W = nn.Parameter(torch.randn(n_word*embedding_size, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self, x):
X = self.emb(x)
X = X.view(-1, n_word*embedding_size)
tanh = torch.tanh(torch.mm(X, self.H) + self.d)
return torch.mm(tanh, self.U) + torch.mm(X, self.W) + self.b
n_class = len(words_dict)
embedding_size = 10
n_word = 2 #表示每句话中作为输入的单词数
n_hidden = 2 #隐藏层个数,可以自行设置
loss_fn = nn.CrossEntropyLoss()
model = NNLM()
optimizer = optim.Adam(model.parameters(),lr=0.001)
for epoch in range(1, 5000):
optimizer.zero_grad()
predict = model(input_batch)
loss = loss_fn(predict, target_batch)
if epoch%500== 0:
print('epoch:%d loss:%f' % (epoch, loss))
loss.backward()
optimizer.step()
优点:使用NNLM模型生成的词向量是可以自定义维度的,维度并不会因为新扩展词而发生改变,而且这里生成的词向量能够很好的根据特征距离度量词与词之间的相似性。
缺点:
1.计算复杂度过大,参数较多,训练依然太慢(word2vec是一种改进)
2.只对词的左侧文本进行建模,所以得到的词向量并不是语境的充分表征
3.不能很好的解决长程依赖关系
word2vec:word2vec中删除隐藏层的操作以及层级softmax和负采样的优化技术。(http://hanyaopeng.coding.me/2019/04/30/word2vec/)