利用python爬虫调用百度翻译

听说转发文章
会给你带来好运
写在前面的话
今天我们来通过一个实例学习一下python的爬虫,非常适合刚开始学Python爬虫的朋友,我会尽可能详细的给大家讲解每一行代码,界面可能有点粗糙,但是内容都是资源君一个一个码上去的。这个实例是利用爬虫来使用百度翻译的功能,大家主要会学习到urllib里面的request和parse以及json等技术,话不多说!(完整代码在最底下)
1.百度翻译网页分析
首先我们打开百度翻译:
然后按F12,打开调试,然后点击network
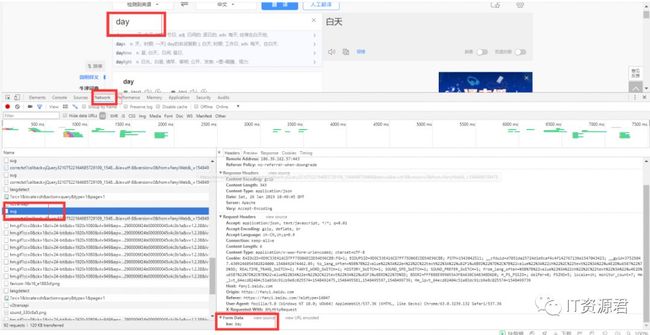
经过我们的分析,我们可以分析到百度翻译的真实post提交页面是Request URL:https://fanyi.baidu.com/sug 并且我们可以发现form data 里面有一个键值对kw:day
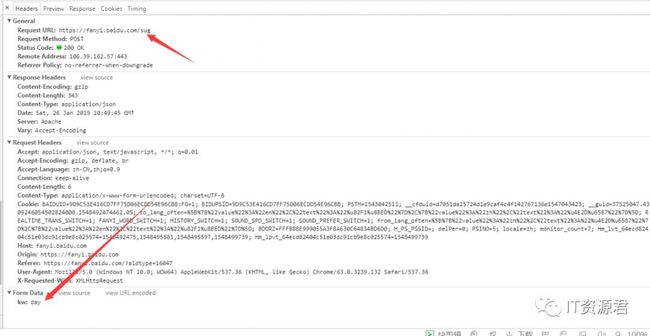
经过初步分析,我们应该有个大概的思路了,无非就是通过这个网址,我们post提交一些数据给他,然后他会返回一个值给我们(其实到后面我们知道这个数据它是通过json格式返回给我们的)
2.开始写代码
1.首先我们都要导入我们需要的库以及定义一下我们的网址和要翻译的单词(这里我们是用户输入)
from urllib import request, parse
import json
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入您想输入的单词:")2.因为我们通过上面的分析,知道了我们传给它的值(也就是我们要翻译的单词)是通过键值对的形式来传递的,所以我们就可以使用python里面的字典格式进行定义
# 我们需要传送过去的数据
datas = {
'kw': word
}3.然后我们会通过parse来对这个datas进行编码,因为此时的字典类型是字符串类型,我们传送过去的应该是一个bytes类型,如果不进行编码,后面会报错滴!
# 对数据进行编码
data = parse.urlencode(datas).encode()4.其次,我们要写出访问百度翻译网站的headers,这个headers可以模拟浏览器进行访问,当然我们这种访问只需要写出我们传输的值得长度就够了,其他的参数没有必要去写。
# 写http头部,至少需要Content-Length
headers = {
# 此处为编码后的长度
'Content-Length': len(data),
}5.我们把要传输的数据(单词)和访问该网站的headers写好了之后,就进行最关键的一步,就是把我们写好的这些东西传输到百度翻译的网站上
# 将数据传送
req = request.Request(url=baseurl, data=data, headers=headers)
res = request.urlopen(req)我们首先使用request里面的Request对象将 url网址,data数据, headers头文件传入到req对象。然后再将req这个对象写入request的urlopen。
6. 此时,post数据部分我们已经完成了,res就是返回给我们的数据对象。我们再通过read方法,把这个返回的数据对象读取出来,然后通过decode方法进行编码(此时编码后就成了一个json格式的数据),最后我们将它进行json格式解析。
json_data = res.read()
json_data = json_data.decode()
json_data = json.loads(json_data)我们打印一下json_data
![]()
7.最后一步就是将我们用户想看到的东西提取出来,我们分析这个json里面的data所对应的值是一个list对象,所以我们提取data的值之后就可以像list一样去处理数据了!
data_list = json_data.get('data')
for item in data_list:
print(item['k'], '---', item['v'])最后结果:

完整代码
'''
利用爬虫调用百度翻译----power:IT资源君
'''
from urllib import request, parse
import json
if __name__ == '__main__':
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入您想输入的单词:")
# 我们需要传送过去的数据
datas = {
'kw': word
}
# 对数据进行编码
data = parse.urlencode(datas).encode()
# 写http头部,至少需要Content-Length
headers = {
# 此处为编码后的长度
'Content-Length': len(data),
}
# 将数据传送
req = request.Request(url=baseurl, data=data, headers=headers)
res = request.urlopen(req)
json_data = res.read()
json_data = json_data.decode()
json_data = json.loads(json_data)
# data里面是一个list
data_list = json_data.get('data')
for item in data_list:
print(item['k'], '---', item['v'])温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我。----IT资源君
![]()
点击上方蓝色字关注我们~