Python 数据分析三剑客之 Pandas(一):认识 Pandas 及其 Series、DataFrame 对象
CSDN 课程推荐:《迈向数据科学家:带你玩转Python数据分析》,讲师齐伟,苏州研途教育科技有限公司CTO,苏州大学应用统计专业硕士生指导委员会委员;已出版《跟老齐学Python:轻松入门》《跟老齐学Python:Django实战》、《跟老齐学Python:数据分析》和《Python大学实用教程》畅销图书。
Pandas 系列文章(正在更新中…):
- Python 数据分析三剑客之 Pandas(一):认识 Pandas 及其 Series、DataFrame 对象
- Python 数据分析三剑客之 Pandas(二):Index 索引对象以及各种索引操作
另有 NumPy、Matplotlib 系列文章已更新完毕,欢迎关注:
- NumPy 系列文章:https://itrhx.blog.csdn.net/category_9780393.html
- Matplotlib 系列文章:https://itrhx.blog.csdn.net/category_9780418.html
推荐学习资料与网站(博主参与部分文档翻译):
- NumPy 官方中文网:https://www.numpy.org.cn/
- Pandas 官方中文网:https://www.pypandas.cn/
- Matplotlib 官方中文网:https://www.matplotlib.org.cn/
- NumPy、Matplotlib、Pandas 速查表:https://github.com/TRHX/Python-quick-reference-table
文章目录
- 【01x00】了解 Pandas
- 【02x00】Pandas 数据结构
- 【03x00】Series 对象
- 【03x01】通过 list 构建 Series
- 【03x02】通过 dict 构建 Series
- 【03x03】获取其数据和索引
- 【03x04】通过索引获取数据
- 【03x05】使用函数运算
- 【03x06】name 属性
- 【04x00】DataFrame 对象
- 【03x01】通过 ndarray 构建 DataFrame
- 【03x02】通过 dict 构建 DataFrame
- 【03x03】获取其数据和索引
- 【03x04】通过索引获取数据
- 【03x05】修改列的值
- 【03x06】增加 / 删除列
- 【03x07】name 属性
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/106676693
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!
【01x00】了解 Pandas
Pandas 是 Python 的一个数据分析包,是基于 NumPy 构建的,最初由 AQR Capital Management 于 2008 年 4 月开发,并于 2009 年底开源出来,目前由专注于 Python 数据包开发的 PyData 开发团队继续开发和维护,属于 PyData 项目的一部分。
Pandas 最初被作为金融数据分析工具而开发出来,因此,Pandas 为时间序列分析提供了很好的支持。Pandas 的名称来自于面板数据(panel data)和 Python 数据分析(data analysis)。panel data 是经济学中关于多维数据集的一个术语,在 Pandas 中也提供了 panel 的数据类型。
Pandas 经常和其它工具一同使用,如数值计算工具 NumPy 和 SciPy,分析库 statsmodels 和 scikit-learn,数据可视化库 Matplotlib 等,虽然 Pandas 采用了大量的 NumPy 编码风格,但二者最大的不同是 Pandas 是专门为处理表格和混杂数据设计的。而 NumPy 更适合处理统一的数值数组数据。
【以下对 Pandas 的解释翻译自官方文档:https://pandas.pydata.org/docs/getting_started/overview.html#package-overview】
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。经过多年不懈的努力,Pandas 离这个目标已经越来越近了。
Pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
Pandas 的主要数据结构是 Series(一维数据)与 DataFrame(二维数据),这两种数据结构足以处理- 金融、统计、社会科学、工程等领域里的大多数典型用例。对于 R 语言用户,DataFrame 提供了比 R 语言 data.frame 更丰富的功能。Pandas 基于 NumPy 开发,可以与其它第三方科学计算支持库完美集成。
Pandas 就像一把万能瑞士军刀,下面仅列出了它的部分优势 :
- 处理浮点与非浮点数据里的缺失数据,表示为 NaN;
- 大小可变:插入或删除 DataFrame 等多维对象的列;
- 自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在 Series、DataFrame 计算时自动与数据对齐;
- 强大、灵活的分组(group by)功能:拆分-应用-组合数据集,聚合、转换数据;
- 把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象;
- 基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作;
- 直观地合并和连接数据集;
- 灵活地重塑和旋转数据集;
- 轴支持分层标签(每个刻度可能有多个标签);
- 强大的 IO 工具,读取平面文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,以及从超快 HDF5 格式保存 / 加载数据;
- 时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
这些功能主要是为了解决其它编程语言、科研环境的痛点。处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想工具。
其它说明:
- Pandas 速度很快。Pandas 的很多底层算法都用 Cython 优化过。然而,为了保持通用性,必然要牺牲一些性能,如果专注某一功能,完全可以开发出比 Pandas 更快的专用工具。
- Pandas 是 statsmodels 的依赖项,因此,Pandas 也是 Python 中统计计算生态系统的重要组成部分。
- Pandas 已广泛应用于金融领域。

【02x00】Pandas 数据结构
Pandas 的主要数据结构是 Series(带标签的一维同构数组)与 DataFrame(带标签的,大小可变的二维异构表格)。
Pandas 数据结构就像是低维数据的容器。比如,DataFrame 是 Series 的容器,Series 则是标量的容器。使用这种方式,可以在容器中以字典的形式插入或删除对象。
此外,通用 API 函数的默认操作要顾及时间序列与截面数据集的方向。当使用 Ndarray 存储二维或三维数据时,编写函数要注意数据集的方向,这对用户来说是一种负担;如果不考虑 C 或 Fortran 中连续性对性能的影响,一般情况下,不同的轴在程序里其实没有什么区别。Pandas 里,轴的概念主要是为了给数据赋予更直观的语义,即用更恰当的方式表示数据集的方向。这样做可以让用户编写数据转换函数时,少费点脑子。
处理 DataFrame 等表格数据时,对比 Numpy,index(行)或 columns(列)比 axis 0 和 axis 1 更直观。用这种方式迭代 DataFrame 的列,代码更易读易懂:
for col in df.columns:
series = df[col]
# do something with series
【03x00】Series 对象
Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引。调用 pandas.Series 函数即可创建 Series,基本语法如下:
pandas.Series(data=None[, index=None, dtype=None, name=None, copy=False, fastpath=False])
| 参数 | 描述 |
|---|---|
| data | 数组类型,可迭代的,字典或标量值,存储在序列中的数据 |
| index | 索引(数据标签),值必须是可哈希的,并且具有与数据相同的长度, 允许使用非唯一索引值。如果未提供,将默认为RangeIndex(0,1,2,…,n) |
| dtype | 输出系列的数据类型。可选项,如果未指定,则将从数据中推断,具体参考官网 dtypes 介绍 |
| name | str 类型,可选项,给 Series 命名 |
| copy | bool 类型,可选项,默认 False,是否复制输入数据 |

【03x01】通过 list 构建 Series
一般情况下我们只会用到 data 和 index 参数,可以通过 list(列表) 构建 Series,示例如下:
>>> import pandas as pd
>>> obj = pd.Series([1, 5, -8, 2])
>>> obj
0 1
1 5
2 -8
3 2
dtype: int64
由于我们没有为数据指定索引,于是会自动创建一个 0 到 N-1(N 为数据的长度)的整数型索引,左边一列是自动创建的索引(index),右边一列是数据(data)。
此外,还可以自定义索引(index):
>>> import pandas as pd
>>> obj = pd.Series([1, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> obj
a 1
b 5
c -8
d 2
dtype: int64
索引(index)也可以通过赋值的方式就地修改:
>>> import pandas as pd
>>> obj = pd.Series([1, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> obj
a 1
b 5
c -8
d 2
dtype: int64
>>> obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
>>> obj
Bob 1
Steve 5
Jeff -8
Ryan 2
dtype: int64
【03x02】通过 dict 构建 Series
通过 字典(dict) 构建 Series,字典的键(key)会作为索引(index),字典的值(value)会作为数据(data),示例如下:
>>> import pandas as pd
>>> data = {'Beijing': 21530000, 'Shanghai': 24280000, 'Wuhan': 11210000, 'Zhejiang': 58500000}
>>> obj = pd.Series(data)
>>> obj
Beijing 21530000
Shanghai 24280000
Wuhan 11210000
Zhejiang 58500000
dtype: int64
如果你想按照某个特定的顺序输出结果,可以传入排好序的字典的键以改变顺序:
>>> import pandas as pd
>>> data = {'Beijing': 21530000, 'Shanghai': 24280000, 'Wuhan': 11210000, 'Zhejiang': 58500000}
>>> cities = ['Guangzhou', 'Wuhan', 'Zhejiang', 'Shanghai']
>>> obj = pd.Series(data, index=cities)
>>> obj
Guangzhou NaN
Wuhan 11210000.0
Zhejiang 58500000.0
Shanghai 24280000.0
dtype: float64
注意:data 为字典,且未设置 index 参数时:
- 如果 Python >= 3.6 且 Pandas >= 0.23,Series 按字典的插入顺序排序索引。
- 如果 Python < 3.6 或 Pandas < 0.23,Series 按字母顺序排序索引。
【03x03】获取其数据和索引
我们可以通过 Series 的 values 和 index 属性获取其数据和索引对象:
>>> import pandas as pd
>>> obj = pd.Series([1, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> obj.values
array([ 1, 5, -8, 2], dtype=int64)
>>> obj.index
Index(['a', 'b', 'c', 'd'], dtype='object')
【03x04】通过索引获取数据
与普通 NumPy 数组相比,Pandas 可以通过索引的方式选取 Series 中的单个或一组值,获取一组值时,传入的是一个列表,列表中的元素是索引值,另外还可以通过索引来修改其对应的值:
>>> import pandas as pd
>>> obj = pd.Series([1, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> obj
a 1
b 5
c -8
d 2
dtype: int64
>>> obj['a']
1
>>> obj['a'] = 3
>>> obj[['a', 'b', 'c']]
a 3
b 5
c -8
dtype: int64
【03x05】使用函数运算
在 Pandas 中可以使用 NumPy 函数或类似 NumPy 的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等):
>>> import pandas as pd
>>> import numpy as np
>>> obj = pd.Series([1, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> obj[obj > 0]
a 1
b 5
d 2
dtype: int64
>>> obj * 2
a 2
b 10
c -16
d 4
dtype: int64
>>> np.exp(obj)
a 2.718282
b 148.413159
c 0.000335
d 7.389056
dtype: float64
除了这些运算函数以外,还可以将 Series 看成是一个定长的有序字典,因为它是索引值到数据值的一个映射。它可以用在许多原本需要字典参数的函数中:
>>> import pandas as pd
>>> obj = pd.Series([1, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> 'a' in obj
True
>>> 'e' in obj
False
和 NumPy 类似,Pandas 中也有 NaN(即非数字,not a number),在 Pandas 中,它用于表示缺失值,Pandas 的 isnull 和 notnull 函数可用于检测缺失数据:
>>> import pandas as pd
>>> import numpy as np
>>> obj = pd.Series([np.NaN, 5, -8, 2], index=['a', 'b', 'c', 'd'])
>>> obj
a NaN
b 5.0
c -8.0
d 2.0
dtype: float64
>>> pd.isnull(obj)
a True
b False
c False
d False
dtype: bool
>>> pd.notnull(obj)
a False
b True
c True
d True
dtype: bool
>>> obj.isnull()
a True
b False
c False
d False
dtype: bool
>>> obj.notnull()
a False
b True
c True
d True
dtype: bool
【03x06】name 属性
可以在 pandas.Series 方法中为 Series 对象指定一个 name:
>>> import pandas as pd
>>> data = {'Beijing': 21530000, 'Shanghai': 24280000, 'Wuhan': 11210000, 'Zhejiang': 58500000}
>>> obj = pd.Series(data, name='population')
>>> obj
Beijing 21530000
Shanghai 24280000
Wuhan 11210000
Zhejiang 58500000
Name: population, dtype: int64
也可以通过 name 和 index.name 属性为 Series 对象和其索引指定 name:
>>> import pandas as pd
>>> data = {'Beijing': 21530000, 'Shanghai': 24280000, 'Wuhan': 11210000, 'Zhejiang': 58500000}
>>> obj = pd.Series(data)
>>> obj.name = 'population'
>>> obj.index.name = 'cities'
>>> obj
cities
Beijing 21530000
Shanghai 24280000
Wuhan 11210000
Zhejiang 58500000
Name: population, dtype: int64
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/106676693
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!
【04x00】DataFrame 对象
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共用同一个索引)。DataFrame 中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
- 类似多维数组/表格数据 (如Excel、R 语言中的 data.frame);
- 每列数据可以是不同的类型;
- 索引包括列索引和行索引
基本语法如下:
pandas.DataFrame(data=None, index: Optional[Collection] = None, columns: Optional[Collection] = None, dtype: Union[str, numpy.dtype, ExtensionDtype, None] = None, copy: bool = False)
| 参数 | 描述 |
|---|---|
| data | ndarray 对象(结构化或同类的)、可迭代的或者字典形式,存储在序列中的数据 |
| index | 数组类型,索引(数据标签),如果未提供,将默认为 RangeIndex(0,1,2,…,n) |
| columns | 列标签。如果未提供,则将默认为 RangeIndex(0、1、2、…、n) |
| dtype | 输出系列的数据类型。可选项,如果未指定,则将从数据中推断,具体参考官网 dtypes 介绍 |
| copy | bool 类型,可选项,默认 False,是否复制输入数据,仅影响 DataFrame/2d ndarray 输入 |
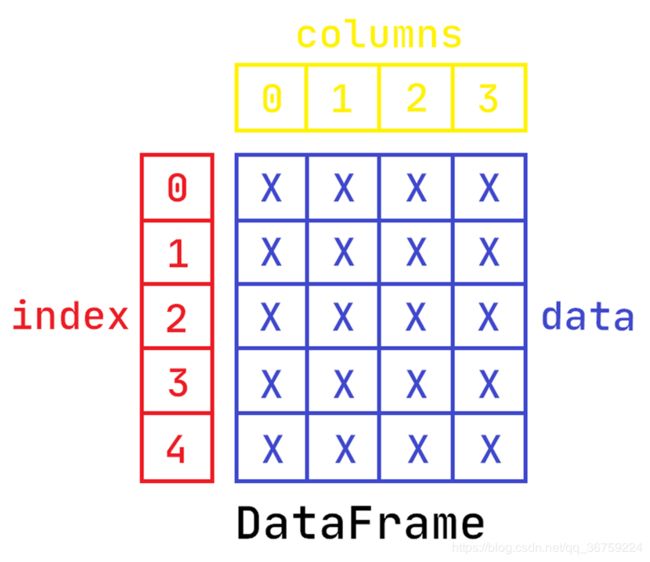
【03x01】通过 ndarray 构建 DataFrame
>>> import numpy as np
>>> import pandas as pd
>>> data = np.random.randn(5,3)
>>> data
array([[-2.16231157, 0.44967198, -0.73131523],
[ 1.18982913, 0.94670798, 0.82973421],
[-1.57680831, -0.99732066, 0.96432 ],
[-0.77483149, -1.23802881, 0.44061227],
[ 1.77666419, 0.24931983, -1.12960153]])
>>> obj = pd.DataFrame(data)
>>> obj
0 1 2
0 -2.162312 0.449672 -0.731315
1 1.189829 0.946708 0.829734
2 -1.576808 -0.997321 0.964320
3 -0.774831 -1.238029 0.440612
4 1.776664 0.249320 -1.129602
指定索引(index)和列标签(columns),和 Series 对象类似,可以在构建的时候添加索引和标签,也可以直接通过赋值的方式就地修改:
>>> import numpy as np
>>> import pandas as pd
>>> data = np.random.randn(5,3)
>>> index = ['a', 'b', 'c', 'd', 'e']
>>> columns = ['A', 'B', 'C']
>>> obj = pd.DataFrame(data, index, columns)
>>> obj
A B C
a -1.042909 -0.238236 -1.050308
b 0.587079 0.739683 -0.233624
c -0.451254 -0.638496 1.708807
d -0.620158 -1.875929 -0.432382
e -1.093815 0.396965 -0.759479
>>>
>>> obj.index = ['A1', 'A2', 'A3', 'A4', 'A5']
>>> obj.columns = ['B1', 'B2', 'B3']
>>> obj
B1 B2 B3
A1 -1.042909 -0.238236 -1.050308
A2 0.587079 0.739683 -0.233624
A3 -0.451254 -0.638496 1.708807
A4 -0.620158 -1.875929 -0.432382
A5 -1.093815 0.396965 -0.759479
【03x02】通过 dict 构建 DataFrame
通过 字典(dict) 构建 DataFrame,字典的键(key)会作为列标签(columns),字典的值(value)会作为数据(data),示例如下:
>>> import pandas as pd
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000]}
>>> obj = pd.DataFrame(data)
>>> obj
city year people
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
5 Beijing 2019 21536000
如果指定了列序列,则 DataFrame 的列就会按照指定顺序进行排列,如果传入的列在数据中找不到,就会在结果中产生缺失值(NaN):
>>> import pandas as pd
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000]}
>>> pd.DataFrame(data)
city year people
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
5 Beijing 2019 21536000
>>> pd.DataFrame(data, columns=['year', 'city', 'people'])
year city people
0 2017 Wuhan 10892900
1 2018 Wuhan 11081000
2 2019 Wuhan 11212000
3 2017 Beijing 21707000
4 2018 Beijing 21542000
5 2019 Beijing 21536000
>>> pd.DataFrame(data, columns=['year', 'city', 'people', 'money'])
year city people money
0 2017 Wuhan 10892900 NaN
1 2018 Wuhan 11081000 NaN
2 2019 Wuhan 11212000 NaN
3 2017 Beijing 21707000 NaN
4 2018 Beijing 21542000 NaN
5 2019 Beijing 21536000 NaN
注意:data 为字典,且未设置 columns 参数时:
-
Python > = 3.6 且 Pandas > = 0.23,DataFrame 的列按字典的插入顺序排序。
-
Python < 3.6 或 Pandas < 0.23,DataFrame 的列按字典键的字母排序。
【03x03】获取其数据和索引
和 Series 一样,DataFrame 也可以通过其 values 和 index 属性获取其数据和索引对象:
>>> import numpy as np
>>> import pandas as pd
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000]}
>>> obj = pd.DataFrame(data)
>>> obj.index
RangeIndex(start=0, stop=6, step=1)
>>> obj.values
array([['Wuhan', 2017, 10892900],
['Wuhan', 2018, 11081000],
['Wuhan', 2019, 11212000],
['Beijing', 2017, 21707000],
['Beijing', 2018, 21542000],
['Beijing', 2019, 21536000]], dtype=object)
【03x04】通过索引获取数据
通过类似字典标记的方式或属性的方式,可以将 DataFrame 的列获取为一个 Series 对象;
行也可以通过位置或名称的方式进行获取,比如用 loc 属性;
对于特别大的 DataFrame,有一个 head 方法可以选取前五行数据。
用法示例:
>>> import numpy as np
>>> import pandas as pd
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000]}
>>> obj = pd.DataFrame(data)
>>> obj
city year people
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
5 Beijing 2019 21536000
>>>
>>> obj['city']
0 Wuhan
1 Wuhan
2 Wuhan
3 Beijing
4 Beijing
5 Beijing
Name: city, dtype: object
>>>
>>> obj.year
0 2017
1 2018
2 2019
3 2017
4 2018
5 2019
Name: year, dtype: int64
>>>
>>> type(obj.year)
<class 'pandas.core.series.Series'>
>>>
>>> obj.loc[2]
city Wuhan
year 2019
people 11212000
Name: 2, dtype: object
>>>
>>> obj.head()
city year people
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
【03x05】修改列的值
列可以通过赋值的方式进行修改。在下面示例中,分别给"money"列赋上一个标量值和一组值:
>>> import pandas as pd
>>> import numpy as np
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000],
'money':[np.NaN, np.NaN, np.NaN, np.NaN, np.NaN, np.NaN]}
>>> obj = pd.DataFrame(data, index=['A', 'B', 'C', 'D', 'E', 'F'])
>>> obj
city year people money
A Wuhan 2017 10892900 NaN
B Wuhan 2018 11081000 NaN
C Wuhan 2019 11212000 NaN
D Beijing 2017 21707000 NaN
E Beijing 2018 21542000 NaN
F Beijing 2019 21536000 NaN
>>>
>>> obj['money'] = 6666666666
>>> obj
city year people money
A Wuhan 2017 10892900 6666666666
B Wuhan 2018 11081000 6666666666
C Wuhan 2019 11212000 6666666666
D Beijing 2017 21707000 6666666666
E Beijing 2018 21542000 6666666666
F Beijing 2019 21536000 6666666666
>>>
>>> obj['money'] = np.arange(100000000, 700000000, 100000000)
>>> obj
city year people money
A Wuhan 2017 10892900 100000000
B Wuhan 2018 11081000 200000000
C Wuhan 2019 11212000 300000000
D Beijing 2017 21707000 400000000
E Beijing 2018 21542000 500000000
F Beijing 2019 21536000 600000000
将列表或数组赋值给某个列时,其长度必须跟 DataFrame 的长度相匹配。如果赋值的是一个 Series,就会精确匹配 DataFrame 的索引:
>>> import pandas as pd
>>> import numpy as np
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000],
'money':[np.NaN, np.NaN, np.NaN, np.NaN, np.NaN, np.NaN]}
>>> obj = pd.DataFrame(data, index=['A', 'B', 'C', 'D', 'E', 'F'])
>>> obj
city year people money
A Wuhan 2017 10892900 NaN
B Wuhan 2018 11081000 NaN
C Wuhan 2019 11212000 NaN
D Beijing 2017 21707000 NaN
E Beijing 2018 21542000 NaN
F Beijing 2019 21536000 NaN
>>>
>>> new_data = pd.Series([5670000000, 6890000000, 7890000000], index=['A', 'C', 'E'])
>>> obj['money'] = new_data
>>> obj
city year people money
A Wuhan 2017 10892900 5.670000e+09
B Wuhan 2018 11081000 NaN
C Wuhan 2019 11212000 6.890000e+09
D Beijing 2017 21707000 NaN
E Beijing 2018 21542000 7.890000e+09
F Beijing 2019 21536000 NaN
【03x06】增加 / 删除列
为不存在的列赋值会创建出一个新列,关键字 del 用于删除列:
>>> import pandas as pd
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000]}
>>> obj = pd.DataFrame(data)
>>> obj
city year people
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
5 Beijing 2019 21536000
>>>
>>> obj['northern'] = obj['city'] == 'Beijing'
>>> obj
city year people northern
0 Wuhan 2017 10892900 False
1 Wuhan 2018 11081000 False
2 Wuhan 2019 11212000 False
3 Beijing 2017 21707000 True
4 Beijing 2018 21542000 True
5 Beijing 2019 21536000 True
>>>
>>> del obj['northern']
>>> obj
city year people
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
5 Beijing 2019 21536000
【03x07】name 属性
可以通过 index.name 和 columns.name 属性设置索引(index)和列标签(columns)的 name,注意 DataFrame 对象是没有 name 属性的:
>>> import pandas as pd
>>> data = {'city': ['Wuhan', 'Wuhan', 'Wuhan', 'Beijing', 'Beijing', 'Beijing'],
'year': [2017, 2018, 2019, 2017, 2018, 2019],
'people': [10892900, 11081000, 11212000, 21707000, 21542000, 21536000]}
>>> obj = pd.DataFrame(data)
>>> obj.index.name = 'index'
>>> obj.columns.name = 'columns'
>>> obj
columns city year people
index
0 Wuhan 2017 10892900
1 Wuhan 2018 11081000
2 Wuhan 2019 11212000
3 Beijing 2017 21707000
4 Beijing 2018 21542000
5 Beijing 2019 21536000
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/106676693
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!