hadoop大数据平台搭建
大数据平台搭建
- 大数据平台搭建
- 虚拟机环境准备
- 修改ip,映射IP地址
- ssh无密码通信
- 同步时间
- 关闭防火墙
- 安装jdk
- hadoop平台正式搭建
- 安装hadoop
- 安装 kafka
- 安装spark
大数据平台搭建
zookeeper+kafka+spark + Hadoop+ yarn
虚拟机环境准备
我们在搭建大数据分布式系统之前需要对软件和虚拟机的环境机型准备:
修改ip,映射IP地址
1.修改主机名
vim /etc/sysconfig/network
修改完主机名之后,别忘了用:wq命令保存退出
然后我们来设置虚拟机的IP地址
首先输入命令 cd /etc/sysconfig/network-scripts
然后用ls命令查看一下目录
修改第一块网卡 ifcfg-eth0
首先要把ONBOOT改为yes,BOOTPROTO改为静态static
然后设置IP地址 IPADDR 这里要注意的是虚拟机的IP地址
的网段必须主机的网段一样,
查看方法是点击虚拟机上的 编辑-虚拟网络编辑器-NAT模式
在里面可以查看IP网段,只要是一个网段都可以
设置子网掩码 NETMASK
设置网关 GATEWAY 不知道的查看方法和上面一样
最后:wq保存退出
或者你可以通过命令行直接修改,但是如果你的电脑或者虚拟机有保护机制,在下一次可能ip地址会发生变化。
#ifconfig eth0 192.168.1.155 netmask 255.255.255.0
ifconfig ##查看一下
然后要配置IP与主机名之间的映射
命令为 vi /etc/hosts=
IP就是你刚刚设置的IP 主机名也是你刚刚设置的主机名

做到这里基本上就OK了,最后检测配置好了没有就用命令
ping www.baidu.com##可以查看一下配置的是否可以上网
ssh无密码通信
首先,展示配置完ssh无密码通信时什么状态的
![]()
可以对其他节点的机器进行操作。接下来开始配置
1.输入命令ssh-keygen生成密钥对,按照提示空格三下(其实就是设置密钥对存储位置)
3.测试本机实现SSH登录.
本机输入命令:ssh-copy-id IP(目标节点)
按照提示输入yes,提示输入密码时是输入目标主机,即使是本机也算作SSH登录目标主机
4.测试命令:ssh ip(目标节点) {可以直接加命令进行操作,例如上述图片}
5.命令:exit 退出远程连接
同步时间
搭建集群环境时,需要各个节点主机的时间是一致的,否则由于心跳什么什么的 会出问题的。
1、查看当前主机的时间 date
2、yum -y install ntp #下载ntp
3、service ntpd start #启动
service ntpd status#查看ntpd当前状态
chkconfig ntpd start#设置开机启动
#ps:如果过了一段时间之后,你发现时间和当前本地的时间还是不一致的话,可能是你的配置文件的本地地址不是本地。
ntpdate -u ntp.api.bz
clock -w
如果你的时间还是不能同步则对文件进行修改:
vim /etc/sysconfig/clock
本文是将时间设置为上海
![]()
ntp常用服务器:
中国国家授时中心:210.72.145.44
NTP服务器(上海) :ntp.api.bz
美国:time.nist.gov
复旦:ntp.fudan.edu.cn
微软公司授时主机(美国) :time.windows.com
台警大授时中心(台湾):asia.pool.ntp.org
关闭防火墙
最后一步把虚拟机的防火墙关闭
service iptables status#查看防火墙是否在运行
service iptables stop #停止
chkconfig iptables off #设置开机关闭
安装jdk
我这提供的是官方的地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html。如果你已经下载好了之后就可以跳过这步。如果你需要全套下载的东西,可以给我留言,发百度网盘链接。最好下载jdk1.8版本的。因为在spark2.0之后不再支持1.7版本。
下载完之后,进行解压 tar -zxvf jdk(自己的版本)
vim /etc/profile
加export的就看可以了

source /etc/profile
hadoop平台正式搭建
安装hadoop
Hadoop生态系统:2.7.7 cdh5.7.0(ps:尾号必须相同)
所有的hadoop生态的软件下载地址:http://archive.cloudera.com/cdh5/cdh/5/
这是我安装的配置
centos6.5
jdk:1.8
spark:2.2(要求jdk必须是1.8)
kafka:由scala构建选择与scala对应的版本
scala:2.11.8
app 存放我们所有的软件的安装目录
data 存放我们的测试数据
lib 存放我们开发的jar
software 存放软件安装的目录
source 存放我们的框架源码
tmp 存在log日志文件
vim /etc/core-site.xml
修改以下部分,保存

vim /etc/mapred-site.xml
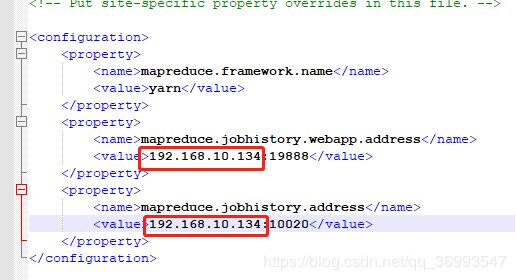
Vim /etc/yarn-site.xml
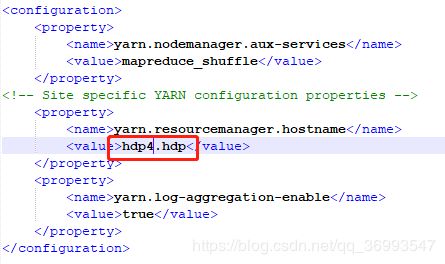
Vim /etc/hdfs-site
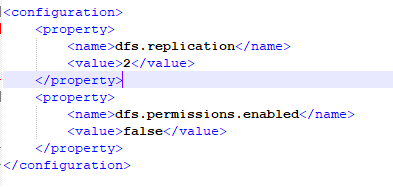
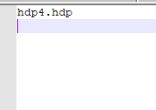
Vim /etc/Hadoop-env.sh

Vim /etc/slaves
配置完成之后进行一次格式化
Bin/hdfs namenode -format
显示successfully formatted
将hadoop目录加到~/.bash_profile
Vim ~/.bash_profle 或者vim /etc/profile 都是一样的(大神感觉有问题的希望指出)
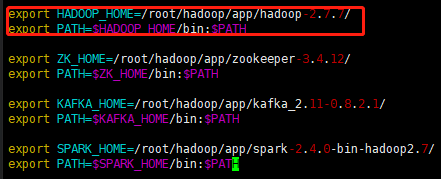
配置完成 监控页面: ip:50070
测试
./start-dfs.sh
Jps #查看一下启动的进程
bin/hdfs dfs -mkdir -p /user/hdp2/data/
/bin/hdfs dfs -put /root/hadoop/hadoop/etc/hadoop/core /user/hdp2/data
启动yarn 监控页面 ip:8088
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-history-daemon.sh start historyserver
安装 kafka
### 安装kafka之前那一定要先安装zookeeper。、
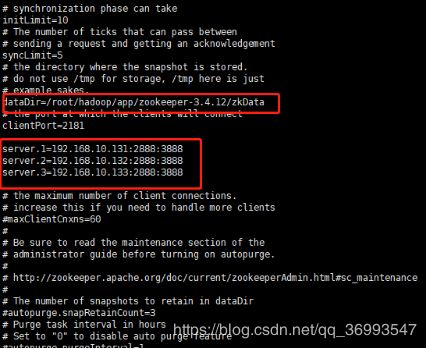
1、安装zookeeper
Conf
Zoo.cfg
2)kafka配置
Server.properties
Host.name= localhost
kafka启动
Bin/kafka-server-start.sh config/server.propertoes
安装spark
1.下载spark-2.1.0-bin-hadoop2.7.tgz#这个根据自己的hadoop版本进项下载
…
2.解压
tar -zxvf spark-(压缩文件)
…
3.环境变量
[/etc/profile]
SPARK_HOME=/soft/spark
PATH= P A T H : PATH: PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
[source]
$>source /etc/profile
4.验证spark
$>cd /soft/spark
$>./spark-shell
我的自己搭建完成之后写的。如果有什么问题,希望多多指教!!!!