深度学习中常见的loss函数汇总
损失函数(Loss Function)分为经验风险损失函数和结构风险损失函数,经验风险损失函数反映的是预测结果和实际结果之间的差别,结构风险损失函数则是经验风险损失函数加上正则项(L1或L2)。深度学习中的损失函数被用于模型参数的估计,通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。
机器学习任务中的损失函数可以大体分为两种类型:回归损失和分类损失。在此基础上,在深度学习任务中又发展了很多不同的损失函数,由于在网络训练过程中损失函数指导着网络的学习,因此选择合适的损失函数也很重要。常见的有下面几种:
- 回归损失:平均绝对误差(MAE/L1损失),平均平方误差(MSE/L2损失),smooth L1 loss,Huber损失,log cosh loss,quantile loss;
- 分类损失:0-1损失,logistic loss(对数损失),hinge loss(铰链损失),exponential loss(指数损失),KL散度;
- 识别、检测和分割常用的损失:softmax cross-entropy loss,weighted cross-entropy loss,focal loss,OHEM,center loss,triplet loss,contrastive loss,L-softmax,LMCL,IOU loss,GIOU loss,DIOU loss,CIOU loss,dice loss。
回归损失
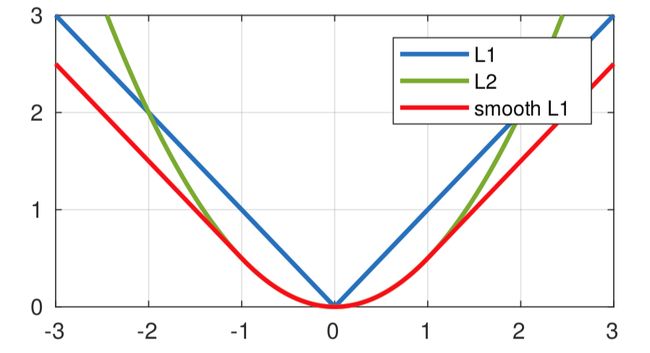
- MAE/L1 loss:
M A E = 1 n ∑ i = 1 n ∣ f ( x i ) − y i ∣ MAE = \frac1n\sum \limits_{i=1}^{n}|f(x_i)-y_i| MAE=n1i=1∑n∣f(xi)−yi∣
平均绝对误差(Mean Absolute Error,MAE)是对估计值和真实值之差取绝对值的平均值。由上图可以看出,(1)MAE曲线连续,但是在 f ( x i ) − y i = 0 f(x_i)-y_i=0 f(xi)−yi=0 处不可导,求解效率低;(2)梯度较为稳定,但是即使损失很小梯度仍然保持不变,不利于模型的收敛;(3)对异常值更鲁棒(相比于L2 loss)。由于神经网络的问题较为复杂,因此很少使用,但是可以利用L1进行正则化,即将L1损失(权重1范数的和)加在其他损失的后面,作为正则项。正规化是防止过拟合的一种重要技巧,L1正则项的好处是能保持解的稀疏性,即为了使损失最小化,一些影响小的权重参数经过学习设置为0,可以用于特征选择。 - MSE/L2 loss:
M S E = 1 n ∑ i = 1 n ( f ( x i ) − y i ) 2 MSE = \frac1n\sum \limits_{i=1}^{n}(f(x_i)-y_i)^2 MSE=n1i=1∑n(f(xi)−yi)2
均方误差(Mean Square Error,MSE)是对估计值和真实值之差取平方和的平均值。由上图可以看出,(1)MSE是平滑函数、处处可导,因此在求解优化问题时有利于误差梯度的计算;(2)随着误差的减小,梯度也在减小,因此使用固定的学习速率,也能较快的收敛到最小值;(3)通过平方计算放大了估计值和真实值的距离,因此对于异常值带来很大的惩罚,从而降低正常值的预测效果;(4)误差很大时梯度也很大,在训练初期不稳定,容易梯度爆炸。L2进行正则化可以防止过拟合,在正则化后的梯度下降迭代公式中,会给权重参数乘以一个小于1的因子 1 − α λ m 1-\alpha\frac{\lambda}m 1−αmλ,其中 λ \lambda λ为正则化参数,因此权重值减小,从而得到的模型越平滑。 - Smooth L1 loss:
S m o o t h L 1 = 1 n ∑ i = 1 n { 0.5 ( f ( x i ) − y i ) 2 i f ∣ f ( x i ) − y i ∣ < 1 ∣ f ( x i ) − y i ∣ − 0.5 o t h e r w i s e Smooth\space L1 = \frac1n\sum \limits_{i=1}^{n}\left\{ \begin{array}{rcl} 0.5(f(x_i)-y_i)^2 & &if \space {|f(x_i)-y_i| <1}\\ |f(x_i)-y_i|-0.5 & & {otherwise}\\ \end{array} \right. Smooth L1=n1i=1∑n{0.5(f(xi)−yi)2∣f(xi)−yi∣−0.5if ∣f(xi)−yi∣<1otherwise
Smooth L1 是L1和L2两种损失的结合,目前多用于目标检测中(例如Faster RCNN)的边框回归损失,能从两个方面限制梯度:(1)当预测框与 ground truth 差别过大时,梯度值不至于过大;(2)当预测框与 ground truth 差别很小时,梯度值足够小。 - Huber loss:
H u b e r l o s s = 1 n ∑ i = 1 n { 1 2 ( f ( x i ) − y i ) 2 i f ∣ f ( x i ) − y i ∣ ≤ δ δ ∣ f ( x i ) − y i ∣ − 1 2 δ 2 o t h e r w i s e Huber \space loss = \frac1n\sum \limits_{i=1}^{n}\left\{ \begin{array}{rcl} \frac12(f(x_i)-y_i)^2 & &if \space {|f(x_i)-y_i| \leq \delta}\\ \delta|f(x_i)-y_i|- \frac12\delta^2 & & {otherwise}\\ \end{array} \right. Huber loss=n1i=1∑n{21(f(xi)−yi)2δ∣f(xi)−yi∣−21δ2if ∣f(xi)−yi∣≤δotherwise
Huber loss对于离群点非常的有效,它与smooth L1一样同时结合了L1和L2的优点,不过多出来了一个 δ \delta δ 参数需要进行训练。 δ \delta δ 趋于0时,Huber loss会趋向于MAE; δ \delta δ 趋于无穷时,Huber loss会趋向于MSE。
还有log cosh loss(预测误差的双曲余弦的对数)、quantile loss(通过选择分位数的值为估计过高或不足做出不同的惩罚)等其他回归损失,由于深度学习中使用较少仅做了解。
分类损失
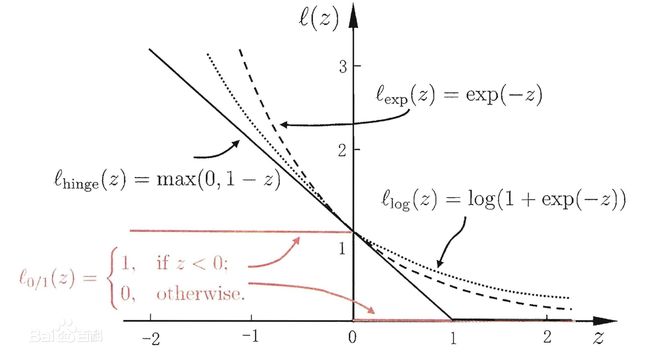
- 0-1 loss:
L 0 / 1 = 1 n ∑ i = 1 n { 0 i f y i f ( x i ) ≥ 0 1 i f y i f ( x i ) < 0 L_{0/1} = \frac1n\sum \limits_{i=1}^{n}\left\{ \begin{array}{rcl} 0 & &if \space {y_if(x_i) \geq 0}\\ 1 & &if \space {y_if(x_i) < 0}\\ \end{array} \right. L0/1=n1i=1∑n{01if yif(xi)≥0if yif(xi)<0
y ∈ { + 1 , − 1 } y \in \{{+1,-1}\} y∈{+1,−1},由于对每个错分类点都施以相同的惩罚,这样对分类误差更大的点不会得到更多的关注;另外,该函数不连续且非凸,优化困难。 - logistic loss:
L l o g = 1 n ∑ i = 1 n l o g ( 1 + e − y i f ( x i ) ) L_{log} = \frac1n\sum \limits_{i=1}^{n}log(1+e^{-y_if(x_i)}) Llog=n1i=1∑nlog(1+e−yif(xi))
y ∈ { + 1 , − 1 } y \in \{{+1,-1}\} y∈{+1,−1},则当 f ( x ) f(x) f(x) 越接近正无穷或负无穷时,损失越接近于0;
y ∈ { 0 , 1 } y \in \{{0,1}\} y∈{0,1},则该函数与二元交叉熵损失等价 L = 1 n ∑ i = 1 n ( y i l o g f ( x i ) + ( 1 − y i ) l o g ( 1 − f ( x i ) ) ) L= \frac1n\sum \limits_{i=1}^{n}(y_ilogf(x_i)+(1-y_i)log(1-f(x_i))) L=n1i=1∑n(yilogf(xi)+(1−yi)log(1−f(xi))),用于逻辑回归。 - hinge loss:
L h i n g e = 1 n ∑ i = 1 n max ( 0 , 1 − y i f ( x i ) ) L_{hinge} = \frac1n\sum \limits_{i=1}^{n}\max(0,1-y_if(x_i)) Lhinge=n1i=1∑nmax(0,1−yif(xi))
hinge loss作为SVM的损失函数,标签 y ∈ { + 1 , − 1 } y \in \{{+1,-1}\} y∈{+1,−1},铰链损失的性质决定了SVM具有稀疏性,即分类正确但概率不足1和分类错误的样本被识别为支持向量被用于划分决策边界,其余分类完全正确的样本没有参与模型求解。 - exponential loss:
L e x p = 1 n ∑ i = 1 n e − y i f ( x i ) L_{exp} = \frac1n\sum \limits_{i=1}^{n}e^{-y_if(x_i)} Lexp=n1i=1∑ne−yif(xi)
Exponential loss是指数形式,是图中对错误分类施加最大惩罚的损失函数。它的特点就是梯度比较大,使用梯度算法时求解速度快,主要用于Adaboost集成学习算法中。自适应提升算法(Adaptive Boosting, AdaBoost)利用指数损失易于计算的特点,构建多个可快速求解的“弱”分类器成员并按成员表现进行赋权和迭代,组合得到一个“强”分类器并输出结果。
其他常用损失
-
Softmax Cross-Entropy loss:
f ( x ) = e w c T ⋅ x ∑ k = 1 C e w k T ⋅ x L C E = − 1 n ∑ i = 1 n log f ( x i ) f(x)=\frac{e^{w_c^T\cdot x}}{\sum_{k=1}^C e^{w_k^T \cdot x}}\\ L_{CE}=-\frac1n\sum_{i=1}^n \log f(x_i) f(x)=∑k=1CewkT⋅xewcT⋅xLCE=−n1i=1∑nlogf(xi)
max作为分类是非黑即白的,引入soft的概念最后输出的是每个分类的概率。上述损失中的softmax计算的是 y i = c y_i=c yi=c ,即真实类别的预测概率,交叉熵损失函数通过缩小概率分布的差异,来使预测概率分布尽可能达到真实概率分布。y 代表标签的 one-hot 编码。 -
下面三种损失函数常用来解决正负样本(类别)不平衡的问题。
2-1. Weighted Cross-Entropy loss:
L W C E = − ( β ∑ i ∈ y = 1 y i log ( s o f t m a x ( f ( x i ) ) ) + ( 1 − β ) ∑ i ∈ y = 0 ( 1 − y i ) log ( s o f t m a x ( f ( x i ) ) ) ) L_{WCE}=-(\beta\sum_{i \in y=1} y_i\log (softmax(f(x_i)))+(1-\beta)\sum_{i \in y=0} (1-y_i)\log (softmax(f(x_i)))) LWCE=−(βi∈y=1∑yilog(softmax(f(xi)))+(1−β)i∈y=0∑(1−yi)log(softmax(f(xi))))
2-2. Focal loss:
Focal loss出自于2017的论文《Focal Loss for Dense Object Detection》,主要是解决one-stage目标检测中正负样本之间的不平衡问题,可以理解为困难样本挖掘,是在二分类交叉熵的基础上进行的改进。
L f l = { − ( 1 − f ( x i ) ) γ l o g f ( x i ) y i = 1 − f ( x i ) γ l o g ( 1 − f ( x i ) ) y i = 0 L_{fl}=\left\{ \begin{array}{rcl} -(1-f(x_i))^\gamma logf(x_i) & & y_i=1\\ -f(x_i)^\gamma log(1-f(x_i)) & & y_i= 0\\ \end{array} \right. Lfl={−(1−f(xi))γlogf(xi)−f(xi)γlog(1−f(xi))yi=1yi=0
γ > 0 \gamma>0 γ>0 使得易分类损失减少,更关注于困难的、错分的样本。此外,还可以加入平衡因子 α \alpha α,用来平衡正负样本本身比例不均,类似于上述的Weighted Cross-Entropy loss中的 β \beta β。
L f l = { − α ( 1 − f ( x i ) ) γ l o g f ( x i ) y i = 1 − ( 1 − α ) f ( x i ) γ l o g ( 1 − f ( x i ) ) y i = 0 L_{fl}=\left\{ \begin{array}{rcl} -\alpha(1-f(x_i))^\gamma logf(x_i) & & y_i=1\\ -(1-\alpha)f(x_i)^\gamma log(1-f(x_i)) & & y_i= 0\\ \end{array} \right. Lfl={−α(1−f(xi))γlogf(xi)−(1−α)f(xi)γlog(1−f(xi))yi=1yi=0
2-3. OHEM:
OHEM(Online Hard Example Mining) 出自2016的论文《Training Region-based Object Detectors with Online Hard Example Mining》。通过改进 Hard Example Mining 方法,使其适应online learning算法特别是基于SGD的神经网络方法。将所有sample进行前向传播,根据当前CE loss排序选出最大的前几个误差用于反向传播,其余的抛弃。相比较于Focal loss,这个方法只处理了简单样本的问题。 -
下面三种损失函数常用来训练具有内聚性的特征,即增大类间差异并且减小类内差异。
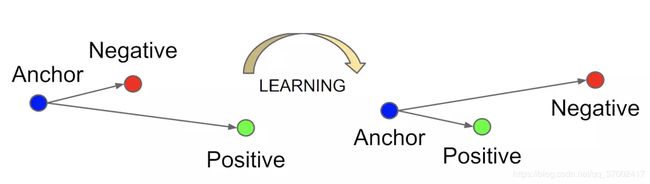
3-1. Triplet loss:
Triplet 是Google在2015年的论文《FaceNet: A Unified Embedding for Face Recognition and Clustering》提出来的,用于训练差异性较小的样本,如人脸等。输入的数据包括锚(Anchor)示例、正(Positive)示例、负(Negative)示例,通过优化锚示例与正示例的距离小于锚示例与负示例的距离,实现样本的相似性计算。合理的 margin 值很关键,这是衡量相似度的重要指标。
L = = 1 n ∑ i = 1 n max ( ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 + ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 + m a r g i n , 0 ) L==\frac1n\sum_{i=1}^n \max(||f(x_i^a)-f(x_i^p)||^2+||f(x_i^a)-f(x_i^n)||^2+margin,0) L==n1i=1∑nmax(∣∣f(xia)−f(xip)∣∣2+∣∣f(xia)−f(xin)∣∣2+margin,0)
3-2. Contrastive loss:
Contrastive 最早是在Yann LeCun的论文《Dimensionality Reduction by Learning an Invariant Mapping》提出来的,这种损失函数可以有效的处理孪生神经网络(siamese network)中的paired data的关系。
L = = 1 2 n ∑ i = 1 n ( y i ∣ ∣ f ( x i a ) − f ( x i b ) ∣ ∣ 2 + ( 1 − y i ) max ( m a r g i n − ∣ ∣ f ( x i a ) − f ( x i b ) ∣ ∣ , 0 ) 2 ) L==\frac1{2n}\sum_{i=1}^n(y_i||f(x_i^a)-f(x_i^b)||^2+(1-y_i)\max(margin-||f(x_i^a)-f(x_i^b)||,0)^2) L==2n1i=1∑n(yi∣∣f(xia)−f(xib)∣∣2+(1−yi)max(margin−∣∣f(xia)−f(xib)∣∣,0)2)
∣ ∣ f ( x i a ) − f ( x i b ) ∣ ∣ ||f(x_i^a)-f(x_i^b)|| ∣∣f(xia)−f(xib)∣∣代表两个样本的欧式距离,y=1代表两个样本相似或者匹配,y=0则代表不匹配,margin为设定的阈值。
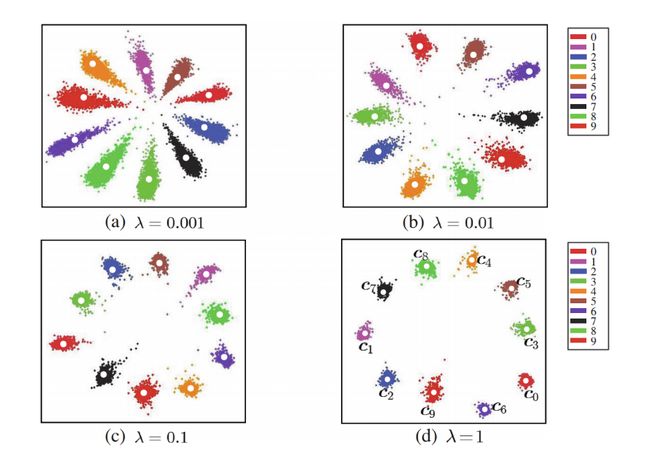
3-3. Center loss:
Center loss 是2016年在论文《A Discriminative Feature Learning Approach for Deep Face Recognition》中提出来的,为了解决类间虽然可分,但是类内差距较大的问题。在人脸识别中,同一个人的类内变化很可能会大于类间的变化,只有保持类内紧凑,才能对那些类内变化大的样本有一个更加鲁棒的判定结果。
在Softmax Cross-Entropy loss后面增加了Center loss:
L = L C E + λ L c e n t e r = − ∑ i = 1 n log f ( x i ) + λ 2 ∑ i = 1 n ∣ ∣ x i − c y i ∣ ∣ 2 L=L_{CE}+\lambda L_{center}=-\sum_{i=1}^n \log f(x_i)+\frac\lambda2\sum_{i=1}^n ||x_i-c_{y_i}||^2 L=LCE+λLcenter=−i=1∑nlogf(xi)+2λi=1∑n∣∣xi−cyi∣∣2
c y i c_{y_i} cyi代表的是类中心特征,也通过网络学习,希望在一个类中的所有图像特征与类中心特征的距离总和最小。
还有L-softmax、LMCL等其他人脸识别中常用损失,由于我没有做过人脸识别这个方向,暂不过多描述,感兴趣可以自行查找。
-
IOU loss 系列:
该系列的代码实现可以参考知乎《IoU、GIoU、DIoU、CIoU损失函数的那点事儿》。
4-1. IOU loss是旷视在2016年在《UnitBox: An Advanced Object Detection Network》中提出的。主要是解决检测任务中边框评价指标使用了IOU,而回归坐标框的时候又使用4个坐标变量,这两者是不等价的,导致了具有相同的欧式距离的框,其IOU值却不是唯一的。因此将常用的回归损失 L2 loss 改为了IOU loss:
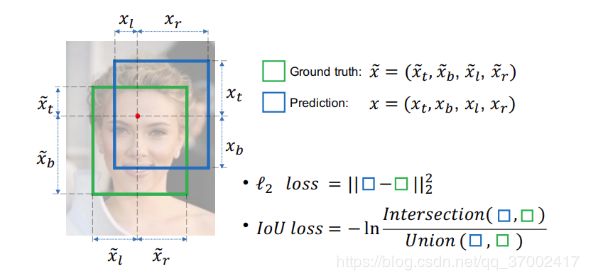
4-2. GIOU loss 是斯坦福2019年在《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》中提出的,发表在CVPR 2019。针对上面的 IOU loss 中,无法对两个不重叠的框进行优化,而且 IOU loss 无法反映出两个框到底距离有多远。为了解决这个问题,作者提了GIOU来作为损失函数:
G I O U = I O U − C − ( A ⋃ B ) C L G I O U = 1 − G I O U GIOU=IOU-\frac{C-(A\bigcup B)}{C}\\ L_{GIOU}=1-GIOU GIOU=IOU−CC−(A⋃B)LGIOU=1−GIOU
其中 C 表示两个框的最小外接矩形面积,可以看出当A与B重叠时, G I O U = I O U ( A , B ) GIOU=IOU(A,B) GIOU=IOU(A,B),当A与B没有重叠时, G I O U GIOU GIOU 随着距离增大逼近-1。所以,GIOU包含了IOU的优点,同时克服了IOU的不足。
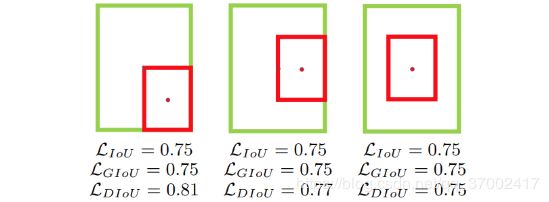
4-3. DIOU和CIOU是天津大学于2019年在《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》中提出,发表在AAAI 2020。当出现下图的情况(GT框完全包含预测框)时,IOU与GIOU的值相同,此时GIOU会退化成IOU,无法区分其相对位置关系。同时由于严重依赖于IOU项,GIOU会致使收敛变慢。作者提出目标框回归损失应该考虑三个重要的几何因素:重叠面积,中心点距离,长宽比。因此,作者在DIOU(Distance-IoU Loss)中进一步加入了中心点距离,而在CIOU中又加入了长宽比。
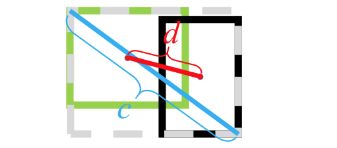
L D I O U = 1 − G I O U + d 2 ( b , b g t ) c 2 L_{DIOU}=1-GIOU+\frac{d ^2(b,b^{gt})}{c^2} LDIOU=1−GIOU+c2d2(b,bgt)
其中 b b b 和 b g t b_{gt} bgt 表示预测框与GT框的中心点, d ( ) d() d() 表示欧式距离, c c c 表示预测框 b b b 和 GT框 b g t b_{gt} bgt 的最小外接矩阵的对角线距离。
L C I O U = 1 − I O U + d 2 ( b , b g t ) c 2 + α υ L_{CIOU}=1-IOU+\frac{d ^2(b,b^{gt})}{c^2}+\alpha \upsilon LCIOU=1−IOU+c2d2(b,bgt)+αυ
其中, α \alpha α表示trade-off参数, υ \upsilon υ表示宽高比一致性参数。
α = υ ( 1 − I O U ) + υ υ = 4 π 2 ( a r c t a n w g t h g t − a r c t a n w h ) 2 \alpha =\frac{\upsilon }{(1-IOU)+\upsilon }\\ \upsilon =\frac{4}{\pi ^2}\left ( arctan\frac{w^{gt}}{h^{gt}}-arctan\frac{w}{h} \right )^2 α=(1−IOU)+υυυ=π24(arctanhgtwgt−arctanhw)2 -
Dice loss:
Dice loss 最早是在《V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation》这篇文章中被提出,后来被广泛的应用在了医学影像分割之中。在医学影像中,感兴趣的解剖结构经常仅占扫描的非常小的区域,这经常导致学习过程陷入损失函数的局部最小值,从而产生预测强烈偏向背景的网络。Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]。
L D i c e = 1 − 2 ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ L_{Dice} =1-\frac{2|A\cap B|}{|A|+|B|} LDice=1−∣A∣+∣B∣2∣A∩B∣
其中,|A|和|B|分别表示A(GT图)和B(预测图)的元素的个数,逐元素相加得到。 ∣ A ∩ B ∣ |A\cap B| ∣A∩B∣ 是 A 和 B 点乘后计算元素个数。
参考链接:
[1] https://www.cnblogs.com/dengshunge/p/12252820.html
[2] https://blog.csdn.net/LittleStudent12/article/details/80777566