【2018】Python面试题【web框架】
1、谈谈你对http协议的认识。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。端口号为80
2、谈谈你对websocket协议的认识。
WebSocket是HTML5开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。
在WebSocket API中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。
浏览器通过 JavaScript 向服务器发出建立 WebSocket 连接的请求,连接建立以后,客户端和服务器端就可以通过 TCP 连接直接交换数据。
3、什么是magic string ?
有触发时机在满足条件时自动触发就是魔术方法
4、如何创建响应式布局?
使用媒体查询的方式,创建多个元素宽度是相对的的布局理想的响应式布局是指的对PC/移动各种终端进行响应的
5、你曾经使用过哪些前端框架?
Bootstrap / vue
6、什么是ajax请求?并使用jQuery和对象实现一个ajax请求。
AJAX是在不加载整个页面的情况异步下与服务器发送请求交换数据并更新部分网页的艺术
$.ajax({
url:'user/add',//当前请求的url地址
type:'get',//当前请求的方式 get post
data:{id:100},//请求时发送的参数
dataType:'json',//返回的数据类型
success:function(data){
//ajax请求成功后执行的代码
console.log(data);
},
error:function(){
//ajax执行失败后执行的代码
alert('ajax执行错误');
},
timeout:2000,//设置当前请求的超时时间 异步请求生效
async:true //是否异步 false同步 true异步
})7、如何在前端实现轮训?
特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP request,然后由服务器返回最新的数据给客户端的浏览器。
8、如何在前端实现长轮训?
ajax实现:在发送ajax后,服务器端会阻塞请求直到有数据传递或超时才会返回,客户端js响应处理函数会在处理完服务器返回的信息后在次发出请求,重新建立连接
9、vuex的作用?
Vue 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件。
10、vue中的路由的拦截器的作用?
判断每一个页面的http请求的状态获取内容做响应的处理
11、axios的作用?
- 在浏览器中发送 XMLHttpRequests 请求
- 在 node.js 中发送 http请求
- 支持 Promise API
- 拦截请求和响应
- 转换请求和响应数据
- 自动转换 JSON 数据
- 客户端支持保护安全免受 XSRF 攻击
12、列举vue的常见指令。
- 条件判断使用
v-if指令 - 循环使用
v-for指令。 - 事件监听可以使用
v-on指令:
13、简述jsonp及实现原理?
JSONP是用来解决跨域请求问题的
跨域:协议 域名 端口号有一个不一样就是跨域
实现原理:
script标签src属性中的链接却可以访问跨域的js脚本,利用这个特性,服务端不再返回JSON格式的数据,而是返回一段调用某个函数的js代码,在src中进行了调用,这样实现了跨域。
14、什么是cors ?
CORS 全称是跨域资源共享(Cross-Origin Resource Sharing),是一种 AJAX 跨域请求资源的方式,支持现代浏览器,IE支持10以上。
15、列举Http请求中常见的请求方式?
GET / POST
16、列举Http请求中的状态码?
404 请求的url地址不存在
503 访问限制有权限
200 访问成功
302 重定向
17、列举Http请求中常见的请求头?
- User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。
- Cookie:这是最重要的请求头信息之一
- Content-Type:请求类型
18、看图写结果:
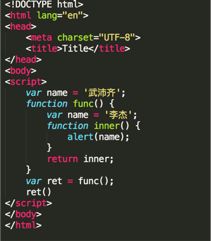
alert(李杰)
19、看图写结果:
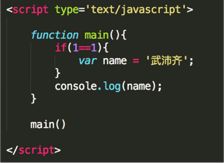
console.log(‘武沛齐’)
20、看图写结果:
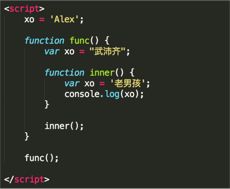
console.log(‘老男孩’)
21、看图写结果:

结果什么也没有 因为console.log.的时候xo还没有定义
22、看图写结果:

alert(”武沛齐’)
23、看图写结果:

alert(”武沛齐’)
24、django、flask、tornado框架的比较?
Django:Python 界最全能的 web 开发框架,battery-include 各种功能完备,可维护性和开发速度一级棒。常有人说 Django 慢,其实主要慢在 Django ORM 与数据库的交互上,所以是否选用 Django,取决于项目对数据库交互的要求以及各种优化。而对于 Django 的同步特性导致吞吐量小的问题,其实可以通过 Celery 等解决,倒不是一个根本问题。Django 的项目代表:Instagram,Guardian。
Tornado:天生异步,性能强悍是 Tornado 的名片,然而 Tornado 相比 Django 是较为原始的框架,诸多内容需要自己去处理。当然,随着项目越来越大,框架能够提供的功能占比越来越小,更多的内容需要团队自己去实现,而大项目往往需要性能的保证,这时候 Tornado 就是比较好的选择。Tornado项目代表:知乎。
Flask:微框架的典范,号称 Python 代码写得最好的项目之一。Flask 的灵活性,也是双刃剑:能用好 Flask 的,可以做成 Pinterest,用不好就是灾难(显然对任何框架都是这样)。Flask 虽然是微框架,但是也可以做成规模化的 Flask。加上 Flask 可以自由选择自己的数据库交互组件(通常是 Flask-SQLAlchemy),而且加上 celery +redis 等异步特性以后,Flask 的性能相对 Tornado 也不逞多让,也许Flask 的灵活性可能是某些团队更需要的。
25、什么是wsgi?
- WSGI(Web Server Gateway Interface,Web 服务器网关接口)则是Python语言中1所定义的Web服务器和Web应用程序之间或框架之间的通用接口标准。
- WSGI就是一座桥梁,桥梁的一端称为服务端或网关端,另一端称为应用端或者框架端,WSGI的作用就是在协议之间进行转化。WSGI将Web组件分成了三类:Web 服务器(WSGI Server)、Web中间件(WSGI Middleware)与Web应用程序(WSGI Application)。
- Web Server接收HTTP请求,封装一系列环境变量,按照WSGI接口标准调用注册的WSGI Application,最后将响应返回给客户端。
26、django请求的生命周期?
前端请求—>nginx—>uwsgi.—>中间件—>url路由—->view试图—>orm—->拿到数据返回给view—->试图将数据渲染到模版中拿到字符串—->中间件—>uwsgi—->nginx—->前端渲染
27、列举django的内置组件?
url 、view、model、template、中间件
28、列举django中间件的5个方法?以及django中间件的应用场景?
- process_request(self,request)
- process_view(self, request, callback, callback_args, callback_kwargs)
- process_exception(self, request, exception)
- process_response(self, request, response)
29、简述什么是FBV和CBV?
django中请求处理方式有2种:FBV 和 CBV
FBV(function base views) 就是在视图里使用函数处理请求。
CBV(class base views)就是在视图里使用类处理请求 类需要继承view
30、django的request对象是在什么时候创建的?
当请求一个页面时,Django会建立一个包含请求元数据的 HttpRequest 对象。 当Django 加载对应的视图时,HttpRequest 对象将作为视图函数的第一个参数。每个视图会返回一个HttpResponse 对象。
31、如何给CBV的程序添加装饰器?
from django.views import View
from django.utils.decorators import method_decorator
def auth(func):
def inner(*args,**kwargs):
return func(*args,**kwargs)
return inner
class UserView(View):
@method_decorator(auth)
def get(self,request,*args,**kwargs):
return HttpResponse('...')32、列举django orm 中所有的方法(QuerySet对象的所有方法)
返回Query Set对象的方法有:
* all()
* filter()
* exclude()
* order_by()
* reverse()
* dictinct()
特殊的QuerySet:
* values() 返回一个可迭代的字典序列
* values_list() 返回一个可迭代的元祖序列
返回具体对象的:
* get()
* first()
* last()
返回布尔值的方法有:
* existe()
返回数学的方法有:
* count( )
33、only和defer的区别?
- defer : 映射中排除某列数据
- only : 仅取某个列中的数据
34、select_related和prefetch_related的区别?
- select_related通过多表join关联查询,一次性获得所有数据,通过降低数据库查询次数来提升性能,但关联表不能太多,因为join操作本来就比较消耗性能
- prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系!
都是为了减少SQL查询的数量
35、filter和exclude的区别?
filter是查询满足条件的数据
exclude是查询不满足添加的数据
36、列举django orm中三种能写sql语句的方法。
# 1.使用execute执行自定义SQL
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
# 2.使用extra方法
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
# 3.使用raw方法
# 解释:执行原始sql并返回模型
# 说明:依赖model多用于查询
# 用法:
# book = Book.objects.raw("select * from hello_book")
# for item in book:
# print(item.title)37、django orm 中如何设置读写分离?
class Router1:
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
All non-auth models end up in this pool.
"""
if db=='db1' and app_label == 'app02':
return True
elif db == 'default' and app_label == 'app01':
return True
else:
return False
# 如果返回None,那么表示交给后续的router,如果后续没有router,则相当于返回True
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.app_label == 'app01':
return 'default'
else:
return 'db1'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
if model._meta.app_label == 'app01':
return 'default'
else:
return 'db1'
38、F和Q的作用?
F:操作数据表中的某列值,F( )允许Django在未实际链接数据的情况下具有对数据库字段的值的引用,不用获取对象放在内存中再对字段进行操作,直接执行原生产sql语句操作。
通常情况下我们在更新数据时需要先从数据库里将原数据取出后方在内存里,然后编辑某些属性,最后提交
Q:对对象进行复杂查询,并支持&(and),|(or),~(not)操作符。
39、values和values_list的区别?
- values方法可以获取number字段的字典列表。
- values_list可以获取number的元组列表。
- values_list方法加个参数flat=True可以获取number的值列表。
40、如何使用django orm批量创建数据?
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)41、django的Form和ModeForm的作用?
- 作用:
- 对用户请求数据格式进行校验
- 自动生成HTML标签
- 区别:
- Form,字段需要自己手写。
class Form(Form):
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
- ModelForm,可以通过Meta进行定义
class MForm(ModelForm):
class Meta:
fields = "__all__"
model = UserInfo
- 应用:只要是客户端向服务端发送表单数据时,都可以进行使用,如:用户登录注册42、django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新。
方式一:重写构造方法,在构造方法中重新去数据库获取值
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = fields.ChoiceField(
# choices=[(1,'二B用户'),(2,'山炮用户')]
choices=[]
)
def __init__(self,*args,**kwargs):
super(UserForm,self).__init__(*args,**kwargs)
self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id','title')
方式二: ModelChoiceField字段
from django.forms import Form
from django.forms import fields
from django.forms.models import ModelChoiceField
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
依赖:
class UserType(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title43、django的Model中的ForeignKey字段中的on_delete参数有什么作用?
on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值
CASCADE:此值设置,是级联删除。
PROTECT:此值设置,是会报完整性错误。
SET_NULL:此值设置,会把外键设置为null,前提是允许为null。
SET_DEFAULT:此值设置,会把设置为外键的默认值。
SET():此值设置,会调用外面的值,可以是一个函数。
44、django中csrf的实现机制?
Django预防CSRF攻击的方法是在用户提交的表单中加入一个csrftoken的隐含值,这个值和服务器中保存的csrftoken的值相同,这样做的原理如下:
1、在用户访问django的可信站点时,django反馈给用户的表单中有一个隐含字段csrftoken,这个值是在服务器端随机生成的,每一次提交表单都会生成不同的值
2、当用户提交django的表单时,服务器校验这个表单的csrftoken是否和自己保存的一致,来判断用户的合法性
3、当用户被csrf攻击从其他站点发送精心编制的攻击请求时,由于其他站点不可能知道隐藏的csrftoken字段的信息这样在服务器端就会校验失败,攻击被成功防御
具体配置如下:
template中添加{%csrf_token%}标签
45、django如何实现websocket?
利用dwebsocket在Django中使用Websocket
https://www.cnblogs.com/huguodong/p/6611602.html
46、基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
https://www.cnblogs.com/wxp5257/p/7834090.html
47、django中如何实现orm表中添加数据时创建一条日志记录。
在settings.py中添加:
LOGGING = {
'disable_existing_loggers': False,
'version': 1,
'handlers': {
'console': {
# logging handler that outputs log messages to terminal
'class': 'logging.StreamHandler',
'level': 'DEBUG', # message level to be written to console
},
},
'loggers': {
'': {
# this sets root level logger to log debug and higher level
# logs to console. All other loggers inherit settings from
# root level logger.
'handlers': ['console'],
'level': 'DEBUG',
'propagate': False, # this tells logger to send logging message
# to its parent (will send if set to True)
},
'django.db': {
# # django also has database level logging
'handlers': ['console'],
'level': 'DEBUG',
'propagate': False,
},
},
}48、django缓存如何设置?
三种粒度缓存
1 中间件级别
'django.middleware.cache.UpdateCacheMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware',
CACHE_MIDDLEWARE_SECONDS=10
2 视图级别
from django.views.decorators.cache import cache_page
@cache_page(15)
def index(request):
import time
t=time.time()
return render(request,"index.html",locals())
3 局部缓存
{% load cache %}
...
...
{% cache 15 "time_cache" %}
缓存时间:{{ t }}
{% endcache %}49、django的缓存能使用redis吗?如果可以的话,如何配置?
pip install django-redis
apt-get install redis-server
然后在settings.py 里面添加CACHES = {
'default': {
'BACKEND': 'redis_cache.cache.RedisCache',
'LOCATION': '127.0.0.1:6379',
"OPTIONS": {
"CLIENT_CLASS": "redis_cache.client.DefaultClient",
},
}50、django路由系统中name的作用?
name 可以用于在 templates, models, views ……中得到对应的网址,相当于“给网址取了个小名”,只要这个名字不变,网址变了也能通过名字获取到。
51、django的模板中filter和simple_tag的区别?
simple_tag
-参数任意,但是不能作为if条件判断的条件
filter
-参数最多只能有两个,但是可以作为if条件判断的条件。
52、django-debug-toolbar的作用?
django_debug_toolbar 是django的第三方工具包,给django扩展了调试功能。
包括查看执行的sql语句,db查询次数,request,headers,调试概览等。
https://blog.csdn.net/weixin_39198406/article/details/78821677
53、django中如何实现单元测试?
https://www.jianshu.com/p/34267dd79ad6
54、解释orm中 db first 和 code first的含义?
datebase first就是代表数据库优先,那么前提就是先创建数据库。
model first就是代表model优先,那么前提也就是先创建model,然后根据model自动建立数据库。
55、django中如何根据数据库表生成model中的类?
Django附带一个名为inspectdb的实用程序,可以通过检查现有的数据库来创建Model(模型)
56、使用orm和原生sql的优缺点?
ORM框架:
对象关系映射,通过创建一个类,这个类与数据库的表相对应!类的对象代指数据库中的一行数据。
简述ORM原理:
让用户不再写SQL语句,而是通过类以及对象的方式,和其内部提供的方法,进行数据库操作!把用户输入的类或对象转换成SQL语句,转换之后通过pymysql执行完成数据库的操作。
ORM的优缺点:
优点:
* 提高开发效率,降低开发成本
* 使开发更加对象化
* 可移植
* 可以很方便地引入数据缓存之类的附加功能
缺点:
* 在处理多表联查、where条件复杂之类的查询时,ORM的语法会变得复杂。就需要写入原生SQL。
57、简述MVC和MTV
MTV和MVC?
MVC: 模型 视图 控制器
MTV: 模型 模板 视图
58、django的contenttype组件的作用?
django内置的ContentType组件就是帮我们做连表操作
如果一个表与其他表有多个外键关系,我们可以通过ContentType来解决这种关联
http://www.cnblogs.com/iyouyue/p/8810464.html
59. 谈谈你对restfull 规范的认识?
- restful其实就是一套编写接口的协议,协议规定如何编写以及如何设置返回值、状态码等信息。
- 最显著的特点:
restful: 给用户一个url,根据method不同在后端做不同的处理,比如:post 创建数据、get获取数据、put和patch修改数据、delete删除数据。
no rest: 给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/ - 当然,还有协议其他的,比如:
- 版本,来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数
- 状态码,200/300/400/500
- url中尽量使用名词,restful也可以称为“面向资源编程”
- api标示:
api.YueNet.com
www.YueNet.com/api/
- 最显著的特点:
60、接口的幂等性是什么意思?
一个接口通过首先进行1次访问,然后对该接口进行N次相同访问的时候,对访问对象不造成影响,那么就认为接口具有幂等性。
比如:
* GET, 第一次获取数据、第二次也是获取结果,幂等。
* POST, 第一次新增数据,第二次也会再次新增,非幂等。
* PUT, 第一次更新数据,第二次不会再次更新,幂等。
* PATCH,第一次更新数据,第二次可能再次更新,非幂等。
* DELTE,第一次删除数据,第二次不会再次删除,幂等。
61、什么是RPC?
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
62. Http和Https的区别?
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
63、为什么要使用django rest framework框架?
1.客户端-服务端分离
优点:提高用户界面的便携性,通过简化服务器提高可伸缩性….
2.无状态(Stateless):从客户端的每个请求要包含服务器所需要的所有信息
优点:提高可见性(可以单独考虑每个请求),提高了可靠性(更容易从局部故障中修复),提高可扩展性(降低了服务器资源使用)
3.缓存(Cachable):服务器返回信息必须被标记是否可以缓存,如果缓存,客户端可能会重用之前的信息发送请求
优点:减少交互次数,减少交互的平均延迟
4.统一接口
优点:提高交互的可见性,鼓励单独改善组件
5.支持按需代码(Code-On-Demand 可选)
优点:提高可扩展性
64、django rest framework框架中都有那些组件?
- 路由,自动帮助开发者快速为一个视图创建4个url
www.oldboyedu.com/api/v1/student/$
www.oldboyedu.com/api/v1/student(?P\w+)$
www.oldboyedu.com/api/v1/student/(?P\d+)/$
www.oldboyedu.com/api/v1/student/(?P\d+)(?P\w+)$
- 版本处理
- 问题:版本都可以放在那里?
- url
- GET
- 请求头
- 认证
- 问题:认证流程?
- 权限
- 权限是否可以放在中间件中?以及为什么?
- 访问频率的控制
- 匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。
如果要封IP,使用防火墙来做。
- 登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,也无法防止。
- 视图
- 解析器 ,根据Content-Type请求头对请求体中的数据格式进行处理。request.data
- 分页
- 序列化
- 序列化
- source
- 定义方法
- 请求数据格式校验
- 渲染器 65、django rest framework框架中的视图都可以继承哪些类?
a. 继承 APIView
这个类属于rest framework中顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制,但凡是数据库、分页等操作都需要手动去完成,比较原始。
class GenericAPIView(APIView)
def post(...):
pass
b. 继承 GenericViewSet(ViewSetMixin, generics.GenericAPIView)
如果继承它之后,路由中的as_view需要填写对应关系 .as_view({‘get’:’list’,’post’:’create’})
在内部也帮助我们提供了一些方便的方法:
- get_queryset
- get_object
- get_serializer
注意:要设置queryset字段,否则会跑出断言的异常。
# 只提供增加功能
class TestView(GenericViewSet):
serializer_class = XXXXXXX
def create(self,*args,**kwargs):
pass # 获取数据并对数据进行操作
c. 继承
- ModelViewSet
- mixins.CreateModelMixin,GenericViewSet
- mixins.CreateModelMixin,DestroyModelMixin,GenericViewSet
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。
示例:只提供增加功能
class TestView(mixins.CreateModelMixin,GenericViewSet):
serializer_class = XXXXXXX
66、简述 django rest framework框架的认证流程。
- 如何编写?写类并实现authticate
- 方法中可以定义三种返回值:
- (user,auth),认证成功
- None , 匿名用户
- 异常 ,认证失败
- 流程:
- dispatch
- 再去request中进行认证处理
67、django rest framework如何实现的用户访问频率控制?
a. 基于用户IP限制访问频率
b. 基于用户IP显示访问频率(利于Django缓存)
c. view中限制请求频率
d. 匿名时用IP限制+登录时用Token限制
68、Flask框架的优势?
一、整体设计方面
首先,两者都是非常优秀的框架。整体来讲,两者设计的哲学是区别最大的地方。Django提供一站式的解决方案,从模板、ORM、Session、Authentication等等都分配好了,连app划分都做好了,总之,为你做尽量多的事情,而且还有一个killer级的特性,就是它的admin,配合django-suit,后台就出来了,其实最初Django就是由在新闻发布公司工作的人设计的。Flask只提供了一些核心功能,非常简洁优雅。它是一个微框架,其他的由扩展提供,但它的blueprint使它也能够很方便的进行水平扩展。
二、路由设计
Django的路由设计是采用集中处理的方法,利用正则匹配。Flask也能这么做,但更多的是使用装饰器的形式,这个有优点也有缺点,优点是读源码时看到函数就知道怎么用的,缺点是一旦源码比较长,你要查路由就不太方便了,但这也促使你去思考如何更合理的安排代码。
三、应用模块化设计
Django的模块化是集成在命令里的,也就是说一开始Django的目标就是为以后玩大了做准备的。每个都是一个独立的模块,为以后的复用提供了便利。Flask通过Blueprint来提供模块化,自己对项目结构划分成不同的模块进行组织。
69、Flask框架依赖组件?
- Route(路由)
- templates(模板)
- Models(orm模型)
- blueprint(蓝图)
- Jinja2模板引擎
70、Flask蓝图的作用?
- 将不同的功能模块化
- 构建大型应用
- 优化项目结构
- 增强可读性,易于维护(跟Django的view功能相似)
71、列举使用过的Flask第三方组件?
内置:
- 配置
- 路由
- 视图
- 模板
- session
- 闪现
- 蓝图
- 中间件
- 特殊装饰器
第三方:
- Flask组件:
- flask-session
- flask-SQLAlchemy
- flask-migrate
- flask-script
- blinker
- 公共组件:
- wtforms
- dbutile
- sqlalchemy
- 自定义Flask组件
- auth ,参考flask-login组件
72、简述Flask上下文管理流程?
每次有请求过来的时候,flask 会先创建当前线程或者进程需要处理的两个重要上下文对象,把它们保存到隔离的栈里面,这样视图函数进行处理的时候就能直接从栈上获取这些信息。
73、Flask中的g的作用?
g 相当于一次请求的全局变量,当请求进来时将g和current_app封装为一个APPContext类,在通过LocalStack将Appcontext放入Local中,取值时通过偏函数,LocalStack、loca l中取值,响应时将local中的g数据删除
74、Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
- flask
- requestcontext
- request
- securecookiesessioninterface
- securecookiesession
75、为什么要Flask把Local对象中的的值stack 维护成一个列表?
当是web应用时:不管是单线程还是多线程,栈中只有一个数据
- 服务端单线程:
{
111:{stack: [ctx, ]}
}
- 服务端多线程:
{
111:{stack: [ctx, ]}
112:{stack: [ctx, ]}
}
76、Flask中多app应用是怎么完成?
请求进来时,可以根据URL的不同,交给不同的APP处理
77、在Flask中实现WebSocket需要什么组件?
Flask-SocketIO
Flask-Sockets是Flask框架的一个扩展,通过它,Flask应用程序可以使用WebSocket。
78、wtforms组件的作用?
WTForms是一个支持多个web框架的form组件,主要用于对用户请求数据进行验证。
https://www.cnblogs.com/big-handsome-guy/p/8552079.html
79、Flask框架默认session处理机制?
Flask的默认session利用了Werkzeug的SecureCookie,把信息做序列化(pickle)后编码(base64),放到cookie里了。
过期时间是通过cookie的过期时间实现的。
为了防止cookie内容被篡改,session会自动打上一个叫session的hash串,这个串是经过session内容、SECRET_KEY计算出来的,看得出,这种设计虽然不能保证session里的内容不泄露,但至少防止了不被篡改。
80、解释Flask框架中的Local对象和threading.local对象的区别?
a. threading.local
作用:为每个线程开辟一块空间进行数据存储。
b. 自定义Local对象
作用:为每个线程(协程)开辟一块空间进行数据存储。
https://www.jianshu.com/p/3f38b777a621
81、Flask中 blinker 是什么?
Flask框架中的信号基于blinker,可以让开发者在flask请求过程中 定制一些用户行为执行。
在请求前后,模板渲染前后,上下文前后,异常 的时候
82、SQLAlchemy中的 session和scoped_session 的区别?
使用scoped_session的目的主要是为了线程安全。
scoped_session类似单例模式,当我们调用使用的时候,会先在Registry里找找之前是否已经创建session了。
要是有,就把这个session返回。
要是没有,就创建新的session,注册到Registry中以便下次返回给调用者。
这样就实现了这样一个目的:在同一个线程中,call scoped_session 的时候,返回的是同一个对象
83、SQLAlchemy如何执行原生SQL?
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('mysql://root:*****@127.0.0.1/database?charset=utf8')
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
session.execute('alter table mytablename drop column mycolumn ;')84、ORM的实现原理?
概念: 对象关系映射(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
详细介绍: 让我们从O/R开始。字母O起源于”对象”(Object),而R则来自于”关系”(Relational)。几乎所有的程序里面,都存在对象和关系数据库。在业务逻辑层和用户界面层中,我们是面向对象的。当对象信息发生变化的时候,我们需要把对象的信息保存在关系数据库中。
当你开发一个应用程序的时候(不使用O/R Mapping),你可能会写不少数据访问层的代码,用来从数据库保存,删除,读取对象信息,等等。你在DAL中写了很多的方法来读取对象数据,改变状态对象等等任务。而这些代码写起来总是重复的。
ORM解决的主要问题是对象关系的映射。域模型和关系模型分别是建立在概念模型的基础上的。域模型是面向对象的,而关系模型是面向关系的。一般情况下,一个持久化类和一个表对应,类的每个实例对应表中的一条记录,类的每个属性对应表的每个字段。
ORM技术特点:
* 提高了开发效率。由于ORM可以自动对Entity对象与数据库中的Table进行字段与属性的映射,所以我们实际可能已经不需要一个专用的、庞大的数据访问层。
* ORM提供了对数据库的映射,不用sql直接编码,能够像操作对象一样从数据库获取数据。
85、DBUtils模块的作用?
使用DBUtils模块
两种使用模式:
1. 为每个线程创建一个连接,连接不可控,需要控制线程数
1. 创建指定数量的连接在连接池,当线程访问的时候去取,如果不够了线程排队,直到有人释放。平时建议使用这种!
86、以下SQLAlchemy的字段是否正确?如果不正确请更正:
fromdatetime importdatetime
fromsqlalchemy.ext.declarative
importdeclarative_base
fromsqlalchemy importColumn, Integer, String, DateTime
Base = declarative_base()
classUserInfo(Base):
__tablename__ = 'userinfo'
id = Column(Integer, primary_key= True, autoincrement= True)
name = Column(String( 64), unique= True)
ctime = Column(DateTime, default=datetime.now())
ctime字段中的参数应该为default=datetime.now, now后面不应该加括号.如果加了,字段不会随时更新87、SQLAchemy中如何为表设置引擎和字符编码?
sqlalchemy设置编码字符集一定要在数据库访问的URL上增加charset=utf8,否则数据库的连接就不是utf8的编码格式
eng = create_engine(‘mysql://root:root@localhost:3306/test2?charset=utf8’,echo=True)
88. SQLAlchemy中如何设置联合唯一索引?
UniqueConstraint 设置联合唯一索引
89、简述Tornado框架的特点。
Tornado的独特之处在于其所有开发工具能够使用在应用开发的任意阶段以及任何档次的硬件资源上。而且,完整集的Tornado工具可以使开发人员完全不用考虑与目标连接的策略或目标存储区大小。
Tornado 结构的专门设计为开发人员和第三方工具厂商提供了一个开放环境。已有部分应用程序接口可以利用并附带参考书目,内容从开发环境接口到连接实现。Tornado包括强大的开发和调试工具,尤其适用于面对大量问题的嵌入式开发人员。这些工具包括C和C++源码级别的调试器,目标和工具管理,系统目标跟踪,内存使用分析和自动配置. 另外,所有工具能很方便地同时运行,很容易增加和交互式开发。
90、简述Tornado框架中Future对象的作用?
http://python.jobbole.com/87310/
91. Tornado框架中如何编写WebSocket程序?
https://www.cnblogs.com/aguncn/p/5665916.html
92、Tornado中静态文件是如何处理的?如:
处理方法:
static_path = os.path.join(os.paht.dirname(file), “static”) #这里增加设置了静态路径
另外一个修改就是在实例化 tornado.web.Application() 的时候,在参数中,出了有静态路径参数 static_path ,还有一个参数设置 debug=True
93、Tornado操作MySQL使用的模块?
torndb是一个轻量级的基于MySQLdb封装的一个模块,从tornado3.0版本以后,其已经作为一个独立模块发行了。torndb依赖于MySQLdb模块,因此,在使用torndb模块时,要保证系统中已经有MySQLdb模块。
94、Tornado操作redis使用的模块?
tornado-redis
95、简述Tornado框架的适用场景?
Tornado是使用Python编写的一个强大的、可扩展的Web服务器。它在处理严峻的网络流量时表现得足够强健,但却在创建和编写时有着足够的轻量级,并能够被用在大量的应用和工具中。
我们现在所知道的Tornado是基于Bret Taylor和其他人员为FriendFeed所开发的网络服务框架,当FriendFeed被Facebook收购后得以开源。不同于那些最多只能达到10,000个并发连接的传统网络服务器,Tornado在设计之初就考虑到了性能因素,旨在解决C10K问题,这样的设计使得其成为一个拥有非常高性能的框架。此外,它还拥有处理安全性、用户验证、社交网络以及与外部服务(如数据库和网站API)进行异步交互的工具。